Compare commits
73 Commits
de3d196e11
...
main
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
fa42853d41 | ||
|
|
70926de445 | ||
|
|
898c0988db | ||
|
|
79d0cf6f3b | ||
|
|
c992c04c7c | ||
|
|
79ee33be7c | ||
|
|
83df8a7373 | ||
|
|
d84fd8934e | ||
|
|
f5b51c8863 | ||
|
|
8ceff84776 | ||
|
|
fc0b7b2cc9 | ||
|
|
fd640631fc | ||
|
|
11d2bf228a | ||
|
|
3ab77361a1 | ||
|
|
3118fa4f1b | ||
|
|
32c77d9f8e | ||
|
|
b75a4e4564 | ||
|
|
94ff0c13f7 | ||
|
|
ae9ca74dbc | ||
|
|
5bacd45419 | ||
|
|
034c190373 | ||
|
|
4356813820 | ||
|
|
ef8076d87f | ||
|
|
97402674cd | ||
|
|
9ff85984e4 | ||
|
|
a606b5766a | ||
|
|
21d46e7440 | ||
|
|
e392062a4b | ||
|
|
4fb906a84d | ||
|
|
0457f2edd1 | ||
|
|
a3ff72e575 | ||
|
|
81fa34669a | ||
|
|
b2053760be | ||
|
|
ed6e0ab282 | ||
|
|
b610ee0a8f | ||
|
|
b2d4d32375 | ||
|
|
ddce6638ad | ||
|
|
d24b371929 | ||
|
|
e325beea4b | ||
|
|
889d385709 | ||
|
|
b34988e830 | ||
|
|
37dcab1597 | ||
|
|
74c4f798a5 | ||
|
|
19b70a4abd | ||
|
|
b35fe51d60 | ||
|
|
9199ed7c29 | ||
|
|
184c232cc8 | ||
|
|
ef0a99ea30 | ||
|
|
303715f82c | ||
|
|
ba569dafad | ||
|
|
87f530ca55 | ||
|
|
24ceec5cc3 | ||
|
|
46cc8a254a | ||
|
|
49742f6219 | ||
|
|
fd256025b3 | ||
|
|
edba1f049e | ||
|
|
a9b47f776b | ||
|
|
cdc0a466b4 | ||
|
|
b513565f30 | ||
|
|
a1ac879c6c | ||
|
|
73274300ec | ||
|
|
9137ae3063 | ||
|
|
497ebfba9f | ||
|
|
4784fcb23f | ||
|
|
bcfcc4b40a | ||
|
|
504156fb95 | ||
|
|
6ca5e235b4 | ||
|
|
73510a3b74 | ||
|
|
85eb3ab3da | ||
|
|
266b10a23b | ||
|
|
cb34c927d4 | ||
|
|
91eaa37283 | ||
|
|
3f85b0ff78 |
98
.dockerignore
Normal file
98
.dockerignore
Normal file
@@ -0,0 +1,98 @@
|
||||
node_modules
|
||||
npm-debug.log*
|
||||
yarn-debug.log*
|
||||
yarn-error.log*
|
||||
pnpm-debug.log*
|
||||
lerna-debug.log*
|
||||
|
||||
dist
|
||||
dist-ssr
|
||||
*.local
|
||||
|
||||
# Editor directories and files
|
||||
.vscode/*
|
||||
!.vscode/extensions.json
|
||||
.idea
|
||||
.DS_Store
|
||||
*.suo
|
||||
*.ntvs*
|
||||
*.njsproj
|
||||
*.sln
|
||||
*.sw?
|
||||
|
||||
# Git
|
||||
.git
|
||||
.gitignore
|
||||
|
||||
# Docker
|
||||
Dockerfile*
|
||||
docker-compose*
|
||||
.dockerignore
|
||||
|
||||
# Environment files (keep only production)
|
||||
.env
|
||||
.env.local
|
||||
.env.development.local
|
||||
.env.test.local
|
||||
|
||||
# Logs
|
||||
logs
|
||||
*.log
|
||||
|
||||
# Coverage directory used by tools like istanbul
|
||||
coverage
|
||||
*.lcov
|
||||
|
||||
# nyc test coverage
|
||||
.nyc_output
|
||||
|
||||
# Dependency directories
|
||||
jspm_packages/
|
||||
|
||||
# Optional npm cache directory
|
||||
.npm
|
||||
|
||||
# Optional eslint cache
|
||||
.eslintcache
|
||||
|
||||
# Microbundle cache
|
||||
.rpt2_cache/
|
||||
.rts2_cache_cjs/
|
||||
.rts2_cache_es/
|
||||
.rts2_cache_umd/
|
||||
|
||||
# Optional REPL history
|
||||
.node_repl_history
|
||||
|
||||
# Output of 'npm pack'
|
||||
*.tgz
|
||||
|
||||
# Yarn Integrity file
|
||||
.yarn-integrity
|
||||
|
||||
# parcel-bundler cache (https://parceljs.org/)
|
||||
.cache
|
||||
.parcel-cache
|
||||
|
||||
# Next.js build output
|
||||
.next
|
||||
|
||||
# Nuxt.js build / generate output
|
||||
.nuxt
|
||||
|
||||
# Storybook build outputs
|
||||
.out
|
||||
.storybook-out
|
||||
|
||||
# Temporary folders
|
||||
tmp/
|
||||
temp/
|
||||
|
||||
# Runtime data
|
||||
pids
|
||||
*.pid
|
||||
*.seed
|
||||
*.pid.lock
|
||||
|
||||
# Stores VSCode versions used for testing VSCode extensions
|
||||
.vscode-test
|
||||
7
.env
7
.env
@@ -1,5 +1,8 @@
|
||||
VITE_API_BASE_URL = http://150.158.121.95
|
||||
# VITE_API_BASE_URL = http://154.9.253.114:9380
|
||||
# VITE_API_BASE_URL
|
||||
VITE_API_BASE_URL = http://154.9.253.114:9380
|
||||
# VITE_API_BASE_URL = http://150.158.121.95
|
||||
# VITE_FLASK_API_BASE_URL
|
||||
VITE_FLASK_API_BASE_URL = http://150.158.121.95
|
||||
|
||||
VITE_RSA_PUBLIC_KEY="-----BEGIN PUBLIC KEY-----
|
||||
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArq9XTUSeYr2+N1h3Afl/z8Dse/2yD0ZGrKwx+EEEcdsBLca9Ynmx3nIB5obmLlSfmskLpBo0UACBmB5rEjBp2Q2f3AG3Hjd4B+gNCG6BDaawuDlgANIhGnaTLrIqWrrcm4EMzJOnAOI1fgzJRsOOUEfaS318Eq9OVO3apEyCCt0lOQK6PuksduOjVxtltDav+guVAA068NrPYmRNabVKRNLJpL8w4D44sfth5RvZ3q9t+6RTArpEtc5sh5ChzvqPOzKGMXW83C95TxmXqpbK6olN4RevSfVjEAgCydH6HN6OhtOQEcnrU97r9H0iZOWwbw3pVrZiUkuRD1R56Wzs2wIDAQAB
|
||||
|
||||
6
.env.flask
Normal file
6
.env.flask
Normal file
@@ -0,0 +1,6 @@
|
||||
# Flask 后台服务配置
|
||||
VITE_API_BASE_URL = http://150.158.121.95
|
||||
|
||||
VITE_RSA_PUBLIC_KEY="-----BEGIN PUBLIC KEY-----
|
||||
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArq9XTUSeYr2+N1h3Afl/z8Dse/2yD0ZGrKwx+EEEcdsBLca9Ynmx3nIB5obmLlSfmskLpBo0UACBmB5rEjBp2Q2f3AG3Hjd4B+gNCG6BDaawuDlgANIhGnaTLrIqWrrcm4EMzJOnAOI1fgzJRsOOUEfaS318Eq9OVO3apEyCCt0lOQK6PuksduOjVxtltDav+guVAA068NrPYmRNabVKRNLJpL8w4D44sfth5RvZ3q9t+6RTArpEtc5sh5ChzvqPOzKGMXW83C95TxmXqpbK6olN4RevSfVjEAgCydH6HN6OhtOQEcnrU97r9H0iZOWwbw3pVrZiUkuRD1R56Wzs2wIDAQAB
|
||||
-----END PUBLIC KEY-----"
|
||||
8
.env.production
Normal file
8
.env.production
Normal file
@@ -0,0 +1,8 @@
|
||||
# 生产环境 FastAPI 后台服务配置
|
||||
# VITE_API_BASE_URL = http://150.158.121.95
|
||||
# FastAPI 后台服务配置 154 内存不够,使用 150 作为后台
|
||||
VITE_API_BASE_URL = http://154.9.253.114:9380
|
||||
|
||||
VITE_RSA_PUBLIC_KEY="-----BEGIN PUBLIC KEY-----
|
||||
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArq9XTUSeYr2+N1h3Afl/z8Dse/2yD0ZGrKwx+EEEcdsBLca9Ynmx3nIB5obmLlSfmskLpBo0UACBmB5rEjBp2Q2f3AG3Hjd4B+gNCG6BDaawuDlgANIhGnaTLrIqWrrcm4EMzJOnAOI1fgzJRsOOUEfaS318Eq9OVO3apEyCCt0lOQK6PuksduOjVxtltDav+guVAA068NrPYmRNabVKRNLJpL8w4D44sfth5RvZ3q9t+6RTArpEtc5sh5ChzvqPOzKGMXW83C95TxmXqpbK6olN4RevSfVjEAgCydH6HN6OhtOQEcnrU97r9H0iZOWwbw3pVrZiUkuRD1R56Wzs2wIDAQAB
|
||||
-----END PUBLIC KEY-----"
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -24,5 +24,4 @@ dist-ssr
|
||||
*.sw?
|
||||
|
||||
# rag core
|
||||
rag_web_core_v0.20.5
|
||||
rag_web_core_deprecated
|
||||
# ragflow_core_v0.21.1
|
||||
3
.npmrc
3
.npmrc
@@ -4,4 +4,5 @@ engine-strict=true
|
||||
registry=https://registry.npmmirror.com/
|
||||
# 为 Yarn 和 pnpm 设置相同的镜像源(确保一致性)
|
||||
ELECTRON_MIRROR=https://npmmirror.com/mirrors/electron/
|
||||
ELECTRON_BUILDER_BINARIES_MIRROR=https://npmmirror.com/mirrors/electron-builder-binaries/
|
||||
ELECTRON_BUILDER_BINARIES_MIRROR=https://npmmirror.com/mirrors/electron-builder-binaries/
|
||||
include-workspace-root=true
|
||||
98
Dockerfile
98
Dockerfile
@@ -1,12 +1,100 @@
|
||||
FROM node:20-alpine
|
||||
# 多阶段构建 - 构建阶段
|
||||
FROM node:20-alpine AS builder
|
||||
|
||||
# 接受构建参数
|
||||
ARG BUILD_MODE=production
|
||||
ARG RAGFLOW_BASE=/ragflow/
|
||||
ENV RAGFLOW_BASE=${RAGFLOW_BASE}
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
COPY package.json pnpm-lock.yaml ./
|
||||
RUN npm install -g pnpm && pnpm install
|
||||
# 安装 pnpm 和依赖(工作空间)
|
||||
RUN npm install -g pnpm
|
||||
|
||||
# 复制源代码
|
||||
COPY . .
|
||||
# 复制完工作空间后,安装并链接所有子包依赖
|
||||
RUN pnpm -r install
|
||||
|
||||
EXPOSE 5173
|
||||
# 设置环境文件(用于根应用的构建)
|
||||
RUN if [ "$BUILD_MODE" = "flask" ]; then \
|
||||
cp .env.flask .env; \
|
||||
else \
|
||||
cp .env.production .env; \
|
||||
fi
|
||||
|
||||
CMD ["pnpm", "dev"]
|
||||
|
||||
# 构建 @teres/iframe-bridge
|
||||
RUN pnpm --filter @teres/iframe-bridge run build
|
||||
|
||||
# 复制完工作空间后,安装并链接所有子包依赖
|
||||
RUN pnpm -r install
|
||||
|
||||
# 构建根 Vite 应用
|
||||
RUN pnpm --filter ./ run build
|
||||
|
||||
# 构建 ragflow_web 前端(Umi 应用)
|
||||
RUN pnpm --filter ragflow_web run build
|
||||
|
||||
# 生产阶段 - nginx
|
||||
FROM nginx:alpine AS production
|
||||
|
||||
# 接受端口与子路径参数
|
||||
ARG PORT=5173
|
||||
ARG RAGFLOW_BASE=/ragflow/
|
||||
|
||||
# 复制自定义 nginx 配置,分别部署两个前端
|
||||
RUN cat > /etc/nginx/conf.d/default.conf << EOF
|
||||
server {
|
||||
listen ${PORT};
|
||||
server_name localhost;
|
||||
root /usr/share/nginx/html;
|
||||
index index.html;
|
||||
|
||||
# 根应用(Vite)SPA 路由
|
||||
location / {
|
||||
try_files \$uri \$uri/ /index.html;
|
||||
}
|
||||
|
||||
# ragflow_web(Umi)部署在子路径,支持 SPA 路由
|
||||
location ${RAGFLOW_BASE} {
|
||||
alias /usr/share/nginx/html/ragflow/;
|
||||
# 注意:使用别名目录时,SPA 回退必须指向子路径下的 index.html
|
||||
# 否则会错误地回退到根应用的 index.html,导致页面刷新后空白或错路由
|
||||
try_files \$uri \$uri/ ${RAGFLOW_BASE}index.html;
|
||||
}
|
||||
|
||||
# 为 pdfjs worker 提供正确的 Content-Type(避免 .mjs 被当作 application/octet-stream)
|
||||
location ^~ /pdfjs-dist/ {
|
||||
# 统一按 application/javascript 返回,确保浏览器可作为模块脚本加载
|
||||
default_type application/javascript;
|
||||
}
|
||||
|
||||
# 静态资源缓存
|
||||
location ~* \.(js|css|png|jpg|jpeg|gif|ico|svg)$ {
|
||||
expires 1y;
|
||||
add_header Cache-Control "public, immutable";
|
||||
}
|
||||
|
||||
# 安全头
|
||||
add_header X-Frame-Options "SAMEORIGIN" always;
|
||||
add_header X-Content-Type-Options "nosniff" always;
|
||||
add_header X-XSS-Protection "1; mode=block" always;
|
||||
|
||||
# Gzip 压缩
|
||||
gzip on;
|
||||
gzip_vary on;
|
||||
gzip_min_length 1024;
|
||||
gzip_types text/plain text/css text/xml text/javascript application/javascript application/xml+rss application/json;
|
||||
}
|
||||
EOF
|
||||
|
||||
# 从构建阶段复制构建产物:根应用与 ragflow_web
|
||||
COPY --from=builder /app/dist /usr/share/nginx/html
|
||||
COPY --from=builder /app/ragflow_web/dist /usr/share/nginx/html/ragflow
|
||||
|
||||
# 暴露端口
|
||||
EXPOSE ${PORT}
|
||||
|
||||
# 启动 nginx
|
||||
CMD ["nginx", "-g", "daemon off;"]
|
||||
213
deploy.sh
Normal file
213
deploy.sh
Normal file
@@ -0,0 +1,213 @@
|
||||
#!/usr/bin/env bash
|
||||
# filepath: deploy.sh
|
||||
# git clone https://code.deep-pilot.chat/AI_POC/TERES_web_frontend.git
|
||||
|
||||
set -e
|
||||
if [ -n "${BASH_VERSION:-}" ]; then
|
||||
set -o pipefail
|
||||
fi
|
||||
|
||||
# 固定镜像名(兼容你原 stop.sh 的做法)
|
||||
IMAGE_NAME="teres_web_frontend:latest"
|
||||
FLASK_IMAGE_NAME="teres_web_frontend_flask:latest"
|
||||
SERVICE_NAME="teres_web_frontend"
|
||||
NETWORK_NAME="proxy-net"
|
||||
|
||||
usage() {
|
||||
cat <<'EOF'
|
||||
用法: ./deploy.sh <命令> [选项]
|
||||
|
||||
常用命令:
|
||||
start 拉最新代码并构建启动(docker compose up -d --build)
|
||||
stop 按固定镜像名停止并删除容器,同时删除镜像
|
||||
restart 先 stop 再 start
|
||||
clean 同 stop(停止容器并删除镜像)
|
||||
|
||||
增强命令:
|
||||
status 查看服务状态(compose ps + 过滤容器)
|
||||
logs [--follow] 查看日志(加 --follow 跟随)
|
||||
health 健康检查(HTTP 200)
|
||||
set [opts] 更新 .env 中 PORT/BUILD_MODE/RAGFLOW_BASE
|
||||
pull 仅拉取最新代码
|
||||
prune 清理悬空镜像与缓存
|
||||
|
||||
set 支持的选项:
|
||||
--port <N> 设置端口(映射和构建参数)
|
||||
--mode <production|flask> 设置构建模式,选择 .env.production 或 .env.flask
|
||||
--base <path> 设置 ragflow 子路径(默认 /ragflow/)
|
||||
|
||||
示例:
|
||||
./deploy.sh start
|
||||
./deploy.sh set --port 5173 --mode production --base /ragflow/
|
||||
./deploy.sh logs --follow
|
||||
./deploy.sh health
|
||||
EOF
|
||||
}
|
||||
|
||||
# 检查命令存在
|
||||
require_cmd() {
|
||||
local cmd="$1"; command -v "$cmd" >/dev/null 2>&1 || {
|
||||
echo "错误: 未找到命令 '$cmd'"; exit 1; }
|
||||
}
|
||||
|
||||
# 选择 compose 命令
|
||||
compose_cmd() {
|
||||
if command -v docker-compose >/dev/null 2>&1; then
|
||||
echo docker-compose
|
||||
else
|
||||
echo docker compose
|
||||
fi
|
||||
}
|
||||
|
||||
ensure_network() {
|
||||
if ! docker network inspect "$NETWORK_NAME" >/dev/null 2>&1; then
|
||||
echo "--- 创建网络: $NETWORK_NAME ---"
|
||||
docker network create "$NETWORK_NAME"
|
||||
fi
|
||||
}
|
||||
|
||||
git_pull() {
|
||||
echo "--- 拉取最新的代码 ---"
|
||||
git fetch --all --prune || true
|
||||
git pull
|
||||
}
|
||||
|
||||
compose_up() {
|
||||
local cmd; cmd=$(compose_cmd)
|
||||
ensure_network
|
||||
echo "--- docker compose 构建并启动 ---"
|
||||
$cmd up -d --build
|
||||
}
|
||||
|
||||
compose_down() {
|
||||
local cmd; cmd=$(compose_cmd)
|
||||
echo "--- docker compose down ---"
|
||||
$cmd down || true
|
||||
}
|
||||
|
||||
stop_by_image() {
|
||||
local image="$1"
|
||||
echo "--- 停止并删除镜像对应的容器: $image ---"
|
||||
local ids
|
||||
ids=$(docker ps -a --filter "ancestor=$image" --format "{{.ID}}" || true)
|
||||
if [[ -n "$ids" ]]; then
|
||||
for id in $ids; do
|
||||
docker stop "$id" || true
|
||||
docker rm "$id" || true
|
||||
done
|
||||
fi
|
||||
echo "--- 删除镜像: $image ---"
|
||||
docker rmi "$image" || true
|
||||
}
|
||||
|
||||
status() {
|
||||
local cmd; cmd=$(compose_cmd)
|
||||
echo "--- compose ps ---"
|
||||
$cmd ps || true
|
||||
echo "--- docker ps (过滤 $SERVICE_NAME) ---"
|
||||
docker ps --format '{{.ID}}\t{{.Image}}\t{{.Names}}\t{{.Status}}' | grep -E "$SERVICE_NAME|$IMAGE_NAME" || true
|
||||
}
|
||||
|
||||
logs() {
|
||||
local follow="false"
|
||||
if [[ "${1:-}" == "--follow" ]]; then follow="true"; fi
|
||||
local cmd; cmd=$(compose_cmd)
|
||||
if [[ "$follow" == "true" ]]; then
|
||||
$cmd logs -f "$SERVICE_NAME"
|
||||
else
|
||||
$cmd logs --tail=300 "$SERVICE_NAME"
|
||||
fi
|
||||
}
|
||||
|
||||
# 更新 .env 中某个键值(若不存在则追加)
|
||||
update_env_var() {
|
||||
local key="$1"; shift
|
||||
local val="$1"; shift
|
||||
touch .env
|
||||
if grep -qE "^\s*${key}\s*=\s*" .env; then
|
||||
# 使用正则替换整行,保留键名
|
||||
sed -i.bak -E "s|^\s*(${key})\s*=\s*.*|\1=${val}|" .env
|
||||
else
|
||||
echo "${key}=${val}" >> .env
|
||||
fi
|
||||
}
|
||||
|
||||
health() {
|
||||
# 从 .env 读取,带默认值
|
||||
local PORT=${PORT:-$(grep -E '^\s*PORT\s*=' .env | sed -E 's/.*=\s*//g' || echo 5173)}
|
||||
local BASE=${RAGFLOW_BASE:-$(grep -E '^\s*RAGFLOW_BASE\s*=' .env | sed -E 's/.*=\s*//g' || echo /ragflow/)}
|
||||
local host="http://127.0.0.1:${PORT}"
|
||||
echo "--- 健康检查: ${host} 与 ${host}${BASE} ---"
|
||||
if command -v curl >/dev/null 2>&1; then
|
||||
curl -fsS -o /dev/null "${host}" && echo "根应用 OK" || echo "根应用失败"
|
||||
curl -fsS -o /dev/null "${host}${BASE}" && echo "ragflow 子路径 OK" || echo "ragflow 子路径失败"
|
||||
else
|
||||
wget -q --spider "${host}" && echo "根应用 OK" || echo "根应用失败"
|
||||
wget -q --spider "${host}${BASE}" && echo "ragflow 子路径 OK" || echo "ragflow 子路径失败"
|
||||
fi
|
||||
}
|
||||
|
||||
prune() {
|
||||
echo "--- 清理悬空镜像与构建缓存 ---"
|
||||
docker image prune -f || true
|
||||
docker builder prune -f || true
|
||||
}
|
||||
|
||||
cmd_start() {
|
||||
git_pull
|
||||
compose_up
|
||||
}
|
||||
|
||||
cmd_stop() {
|
||||
compose_down
|
||||
stop_by_image "$IMAGE_NAME"
|
||||
stop_by_image "$FLASK_IMAGE_NAME"
|
||||
}
|
||||
|
||||
cmd_restart() {
|
||||
cmd_stop
|
||||
cmd_start
|
||||
}
|
||||
|
||||
cmd_clean() { cmd_stop; }
|
||||
|
||||
cmd_pull() { git_pull; }
|
||||
|
||||
cmd_set() {
|
||||
# 解析选项
|
||||
local port="" mode="" base=""
|
||||
while [[ $# -gt 0 ]]; do
|
||||
case "$1" in
|
||||
--port) port="$2"; shift 2;;
|
||||
--mode) mode="$2"; shift 2;;
|
||||
--base) base="$2"; shift 2;;
|
||||
*) echo "未知选项: $1"; usage; exit 1;;
|
||||
esac
|
||||
done
|
||||
[[ -n "$port" ]] && update_env_var PORT "$port"
|
||||
[[ -n "$mode" ]] && update_env_var BUILD_MODE "$mode"
|
||||
[[ -n "$base" ]] && update_env_var RAGFLOW_BASE "$base"
|
||||
echo "--- .env 已更新 ---"
|
||||
}
|
||||
|
||||
main() {
|
||||
require_cmd docker
|
||||
local subcmd="${1:-}"
|
||||
case "$subcmd" in
|
||||
start) shift; cmd_start "$@" ;;
|
||||
stop) shift; cmd_stop "$@" ;;
|
||||
restart) shift; cmd_restart "$@" ;;
|
||||
clean) shift; cmd_clean "$@" ;;
|
||||
status) shift; status "$@" ;;
|
||||
logs) shift; logs "${1:-}" ;;
|
||||
health) shift; health "$@" ;;
|
||||
set) shift; cmd_set "$@" ;;
|
||||
pull) shift; cmd_pull "$@" ;;
|
||||
prune) shift; prune "$@" ;;
|
||||
""|help|-h|--help) usage ;;
|
||||
*) echo "未知命令: $subcmd"; usage; exit 1 ;;
|
||||
esac
|
||||
echo "--- 完成 ---"
|
||||
}
|
||||
|
||||
main "$@"
|
||||
22
docker-compose.yml
Normal file
22
docker-compose.yml
Normal file
@@ -0,0 +1,22 @@
|
||||
version: '3.8'
|
||||
|
||||
networks:
|
||||
proxy-net:
|
||||
external: true # 使用已存在的 proxy-net 网络
|
||||
|
||||
services:
|
||||
teres_web_frontend:
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
args:
|
||||
BUILD_MODE: ${BUILD_MODE:-production}
|
||||
RAGFLOW_BASE: ${RAGFLOW_BASE:-/ragflow/}
|
||||
PORT: ${PORT:-5173}
|
||||
image: teres_web_frontend:latest
|
||||
container_name: teres_web_frontend
|
||||
networks:
|
||||
- proxy-net # 加入 NPM 的网络
|
||||
ports:
|
||||
- "${PORT:-5173}:${PORT:-5173}"
|
||||
restart: unless-stopped
|
||||
308
docs/agent-hooks-guide.md
Normal file
308
docs/agent-hooks-guide.md
Normal file
@@ -0,0 +1,308 @@
|
||||
# Agent Hooks GUI 学习与复现指南
|
||||
|
||||
本指南逐一梳理 `src/pages/agent/hooks` 目录下的所有 Agent 相关 Hooks,帮助你理解画布、抽屉、运行与日志的全链路逻辑,并可据此复现功能。文档涵盖职责、导出、参数与返回、关键逻辑、典型用法及注意事项。
|
||||
|
||||
> 约定:`useGraphStore` 为画布状态中心(维护 `nodes`/`edges` 及更新方法);`@xyflow/react` 用于节点/边渲染与交互;`Operator`、`NodeHandleId`、`NodeMap` 定义节点类型、句柄及渲染映射。
|
||||
|
||||
---
|
||||
|
||||
## 图数据获取与构建
|
||||
|
||||
### use-fetch-data.ts
|
||||
- 作用:页面挂载时获取 Agent 详情并注入画布。
|
||||
- 导出:`useFetchDataOnMount()` → `{ loading, flowDetail }`
|
||||
- 关键逻辑:
|
||||
- 读取 `useFetchAgent()` 的 `data.dsl.graph`,通过 `useSetGraphInfo()` 写入 `nodes/edges`。
|
||||
- 首次挂载 `refetch()` 刷新详情。
|
||||
- 用法:在页面 `useEffect` 中调用以初始化画布。
|
||||
- 注意:`data.dsl.graph` 可能为空,已做空处理。
|
||||
|
||||
### use-set-graph.ts
|
||||
- 作用:将后端返回的 `IGraph` 写入画布。
|
||||
- 导出:`useSetGraphInfo()` → `setGraphInfo({ nodes = [], edges = [] }: IGraph)`
|
||||
- 关键逻辑:有数据才更新,避免清空现有状态。
|
||||
- 关联:与 `useFetchDataOnMount` 搭配使用。
|
||||
|
||||
### use-build-dsl.ts
|
||||
- 作用:根据当前 `nodes/edges` 构建可保存的 DSL 数据对象,并过滤占位符节点(`Operator.Placeholder`)。
|
||||
- 导出:`useBuildDslData()` → `{ buildDslData(currentNodes?) }`
|
||||
- 关键逻辑:
|
||||
- 过滤占位符节点与相关边。
|
||||
- `buildDslComponentsByGraph(filteredNodes, filteredEdges, data.dsl.components)` 生成组件列表。
|
||||
- 返回 `{ ...data.dsl, graph, components }`。
|
||||
- 用法:保存前构建 DSL;导出 JSON 时使用。
|
||||
|
||||
### use-export-json.ts
|
||||
- 作用:导出当前画布图为 JSON 文件。
|
||||
- 导出:`useHandleExportJsonFile()` → `{ handleExportJson }`
|
||||
- 关键逻辑:`downloadJsonFile(buildDslData().graph, \
|
||||
\`\${data.title}.json\`)`
|
||||
|
||||
### use-save-graph.ts
|
||||
- 作用:保存画布到后端;在打开调试时确保最新 DSL。
|
||||
- 导出:
|
||||
- `useSaveGraph(showMessage?: boolean)` → `{ saveGraph(currentNodes?), loading }`
|
||||
- `useSaveGraphBeforeOpeningDebugDrawer(show)` → `{ handleRun(nextNodes?), loading }`
|
||||
- `useWatchAgentChange(chatDrawerVisible)` → 自动 debounce 保存,并回显更新时间字符串。
|
||||
- 关键逻辑:
|
||||
- 基于路由 `id` + `data.title` + `buildDslData` 组装 `dsl` 调用 `useSetAgent`。
|
||||
- 打开调试前先 `saveGraph()`,再 `resetAgent()` 清空旧消息。
|
||||
- `useDebounceEffect`:每 20 秒在节点/边变化时自动保存(聊天抽屉打开时不保存)。
|
||||
|
||||
---
|
||||
|
||||
## 节点创建与拖拽
|
||||
|
||||
### use-add-node.ts
|
||||
- 作用:核心节点添加逻辑,含初始参数、坐标计算、特殊类型处理(Agent/Tool/Iteration/Note)。
|
||||
- 导出:
|
||||
- `useInitializeOperatorParams()` → `{ initializeOperatorParams, initialFormValuesMap }`
|
||||
- `useGetNodeName()` → 根据 `Operator` 返回国际化默认名称。
|
||||
- `useCalculateNewlyChildPosition()` → 计算新增子节点位置避免覆盖。
|
||||
- `useAddNode(reactFlowInstance?)` → `{ addCanvasNode, addNoteNode }`
|
||||
- 内部逻辑:`useAddChildEdge()`、`useAddToolNode()`、`useResizeIterationNode()`。
|
||||
- 关键逻辑:
|
||||
- 初始化各 `Operator` 的 `form` 默认值;Agent/Extractor 等会注入 `llm_id`、默认 prompts。
|
||||
- 迭代节点 `Operator.Iteration` 自动创建 `Operator.IterationStart` 子节点并设为 `extent='parent'`。
|
||||
- Agent 底部子 Agent 的水平分布通过已有子节点 `x` 轴最大值计算,避免重叠;Tool 节点仅允许一个(检查是否已有 `NodeHandleId.Tool` 连接)。
|
||||
- 通过 `reactFlowInstance.screenToFlowPosition` 将点击位置转换为画布坐标;右侧新增子节点时自动用 `NodeHandleId` 连线。
|
||||
- 容器内新增子节点时可能触发父容器宽度调整以容纳子节点。
|
||||
- 典型用法:
|
||||
```ts
|
||||
const { addCanvasNode } = useAddNode(reactFlowInstance);
|
||||
// 在菜单点击或连接拖拽结束时:
|
||||
addCanvasNode(Operator.Agent, { nodeId, position: Position.Right, id: NodeHandleId.Start })(event);
|
||||
```
|
||||
- 注意:
|
||||
- `Operator.Placeholder` 节点 `draggable=false`。
|
||||
- Tool 节点唯一性;容器内节点可能触发 resize。
|
||||
|
||||
### use-connection-drag.ts
|
||||
- 作用:连接拖拽起止处理;在拖拽终止位置弹出节点选择下拉,创建占位符节点并连线。
|
||||
- 导出:`useConnectionDrag(reactFlowInstance, onConnect, showModal, hideModal, setDropdownPosition, setCreatedPlaceholderRef, calculateDropdownPosition, removePlaceholderNode, clearActiveDropdown, checkAndRemoveExistingPlaceholder)` → `{ nodeId, onConnectStart, onConnectEnd, handleConnect, getConnectionStartContext, shouldPreventClose, onMove }`
|
||||
- 关键逻辑:
|
||||
- `onConnectStart` 记录起点节点/句柄及鼠标起始位置,区分点击/拖拽(<5px 移动视为点击)。
|
||||
- `onConnectEnd` 计算下拉面板位置;点击则清理状态并关闭下拉;拖拽时先移除旧占位符,再创建新占位符并连线。
|
||||
- `onMove` 在画布滚动/缩放时隐藏下拉并清理占位符。
|
||||
|
||||
### use-dropdown-position.ts
|
||||
- 作用:屏幕与 Flow 坐标互转,计算下拉菜单位置使其对齐占位节点。
|
||||
- 导出:`useDropdownPosition(reactFlowInstance)` → `{ calculateDropdownPosition, getPlaceholderNodePosition, flowToScreenPosition, screenToFlowPosition }`
|
||||
- 关键逻辑:按常量 `HALF_PLACEHOLDER_NODE_WIDTH`、`DROPDOWN_HORIZONTAL_OFFSET`、`DROPDOWN_VERTICAL_OFFSET` 计算偏移。
|
||||
|
||||
### use-placeholder-manager.ts
|
||||
- 作用:占位符节点的创建、删除与状态追踪;替换为真实节点后自动建立连接并同步位置。
|
||||
- 导出:`usePlaceholderManager(reactFlowInstance)` → `{ removePlaceholderNode, onNodeCreated, setCreatedPlaceholderRef, resetUserSelectedFlag, checkAndRemoveExistingPlaceholder, createdPlaceholderRef, userSelectedNodeRef }`
|
||||
- 关键逻辑:
|
||||
- 保证面板上仅有一个占位符。
|
||||
- `onNodeCreated(newNodeId)`:真实节点位置与占位符对齐;按占位符的起点连线;删除占位符及相关边。
|
||||
- 使用 `reactFlowInstance.deleteElements` 执行批量删除。
|
||||
|
||||
### use-before-delete.tsx
|
||||
- 作用:拦截删除操作,保护 `Operator.Begin`、容器首节点(`Operator.IterationStart` 非成对删除时阻止)及下游 Agent/Tool 的联动删除。
|
||||
- 导出:`useBeforeDelete()` → `{ handleBeforeDelete }`
|
||||
- 关键逻辑:
|
||||
- `UndeletableNodes`:Begin 与 IterationStart 的特殊保护。
|
||||
- 当包含 Agent 节点时,额外删除其下游 Agent/Tool(节点与边)。
|
||||
- 用法:作为 React Flow 的 `onBeforeDelete` 回调。
|
||||
|
||||
### use-change-node-name.ts
|
||||
- 作用:处理节点名称与 Tool 名称变更,避免重复命名并同步到画布。
|
||||
- 导出:`useHandleNodeNameChange({ id, data })` → `{ name, handleNameBlur, handleNameChange }`
|
||||
- 关键逻辑:
|
||||
- Tool 名称变更写入父 Agent 的 `tools` 字段,通过 `updateNodeForm(agentId, nextTools, ['tools'])`。
|
||||
- 普通节点名通过 `updateNodeName(id, name)` 更新;同一画布内不可重名,重复则提示 `message.error('The name cannot be repeated')`。
|
||||
|
||||
### use-agent-tool-initial-values.ts
|
||||
- 作用:为 Agent Tool(非画布节点)生成初始参数(裁剪/重组)以适配对话调用。
|
||||
- 导出:`useAgentToolInitialValues()` → `{ initializeAgentToolValues(operatorName) }`
|
||||
- 关键逻辑:对不同 `Operator` 精简参数,如去除 `query/sql/stock_code`,或仅保留 `smtp_*` 邮件字段等。
|
||||
|
||||
### use-form-values.ts
|
||||
- 作用:表单初始值合并,优先使用节点已有 `data.form`,否则回退为 `defaultValues`。
|
||||
- 导出:`useFormValues(defaultValues, node?)`
|
||||
|
||||
### use-watch-form-change.ts
|
||||
- 作用:监听 `react-hook-form` 表单变化并同步到画布节点 `form`。
|
||||
- 导出:`useWatchFormChange(id?, form?)`
|
||||
- 关键逻辑:手动获取 `form.getValues()`,再 `updateNodeForm(id, values)`。
|
||||
|
||||
### use-move-note.ts
|
||||
- 作用:便签(Note)悬浮预览位置跟随鼠标。
|
||||
- 导出:`useMoveNote()` → `{ ref, showImage, hideImage, mouse, imgVisible }`
|
||||
- 关键逻辑:使用 `useMouse()` 监听坐标,更新 `ref.current.style.top/left`。
|
||||
|
||||
---
|
||||
|
||||
## 运行与日志
|
||||
|
||||
### use-run-dataflow.ts
|
||||
- 作用:保存画布后触发数据流运行(SSE),打开日志抽屉并设置当前 `messageId`。
|
||||
- 导出:`useRunDataflow({ showLogSheet, setMessageId })` → `{ run(fileResponseData), loading, uploadedFileData }`
|
||||
- 关键逻辑:
|
||||
- 先 `saveGraph()`,再 `send({ id, query: '', session_id: null, files: [file] })` 到 `api.runCanvas`。
|
||||
- 校验响应成功后设置 `uploadedFileData/file` 与 `messageId`。
|
||||
|
||||
### use-cancel-dataflow.ts
|
||||
- 作用:取消当前数据流,并停止日志拉取。
|
||||
- 导出:`useCancelCurrentDataflow({ messageId, stopFetchTrace })` → `{ handleCancel }`
|
||||
- 关键逻辑:`cancelDataflow(messageId)` 返回 `code===0` 时调用 `stopFetchTrace()`。
|
||||
|
||||
### use-fetch-pipeline-log.ts
|
||||
- 作用:拉取运行日志(trace),判断是否完成与是否为空,控制轮询。
|
||||
- 导出:`useFetchPipelineLog(logSheetVisible)` → `{ logs, isLogEmpty, isCompleted, loading, isParsing, messageId, setMessageId, stopFetchTrace }`
|
||||
- 关键逻辑:
|
||||
- `END` 且 `trace[0].message` 非空视为完成,随后 `stopFetchTrace()`;抽屉打开时重置 `isStopFetchTrace=false` 继续拉取。
|
||||
|
||||
### use-download-output.ts
|
||||
- 作用:从日志中提取 `END` 节点输出并下载 JSON。
|
||||
- 导出:`findEndOutput(list)`, `isEndOutputEmpty(list)`, `useDownloadOutput(data?)` → `{ handleDownloadJson }`
|
||||
|
||||
---
|
||||
|
||||
## 抽屉与面板显示
|
||||
|
||||
### use-show-drawer.tsx
|
||||
- 作用:统一管理“运行/聊天抽屉”、“单节点调试抽屉”、“表单抽屉”、“日志抽屉”的显示逻辑。
|
||||
- 导出:
|
||||
- `useShowFormDrawer()` → `{ formDrawerVisible, hideFormDrawer, showFormDrawer(e, nodeId), clickedNode }`
|
||||
- `useShowSingleDebugDrawer()` → `{ singleDebugDrawerVisible, hideSingleDebugDrawer, showSingleDebugDrawer }`
|
||||
- `useShowDrawer({ drawerVisible, hideDrawer })` → `{ chatVisible, runVisible, onPaneClick, singleDebugDrawerVisible, showSingleDebugDrawer, hideSingleDebugDrawer, formDrawerVisible, showFormDrawer, clickedNode, onNodeClick, hideFormDrawer, hideRunOrChatDrawer, showChatModal }`
|
||||
- `useShowLogSheet({ setCurrentMessageId })` → `{ logSheetVisible, hideLogSheet, showLogSheet(messageId) }`
|
||||
- `useHideFormSheetOnNodeDeletion({ hideFormDrawer })` → 在节点被删除时自动关闭表单抽屉。
|
||||
- 关键逻辑:
|
||||
- 当 `drawerVisible=true`:若 Begin 有输入则显示“运行”抽屉;否则显示“聊天”抽屉。
|
||||
- 点击节点打开表单抽屉(排除 Note/Placeholder/File);点击节点上的“播放”图标打开单节点调试抽屉。
|
||||
- `hideRunOrChatDrawer` 同时关闭运行/聊天抽屉与外层抽屉。
|
||||
|
||||
---
|
||||
|
||||
## Begin 相关选项与变量
|
||||
|
||||
### use-get-begin-query.tsx
|
||||
- 作用:围绕 Begin 节点数据构建输入、输出、变量与组件引用选项。
|
||||
- 导出:
|
||||
- `useSelectBeginNodeDataInputs()` → Begin 的输入 `BeginQuery[]`
|
||||
- `useIsTaskMode(isTask?)` → 返回是否任务模式(从 Begin 的 `form.mode` 或传入)。
|
||||
- `useGetBeginNodeDataQuery()` → 读取 Begin 的 `inputs` 并转换为列表。
|
||||
- `useBuildNodeOutputOptions(nodeId?)` → 输出引用选项(带 `OperatorIcon`)。
|
||||
- `useBuildVariableOptions(nodeId?, parentId?)` → Begin 变量与节点输出选项合并。
|
||||
- `useBuildComponentIdOptions(nodeId?, parentId?)` → 组件引用(排除某些节点,容器内仅引用同层或外部节点)。
|
||||
- `useBuildComponentIdAndBeginOptions(nodeId?, parentId?)` → Begin + 组件引用。
|
||||
- `useGetComponentLabelByValue(nodeId)` / `useGetVariableLabelByValue(nodeId)` → 根据值反查标签。
|
||||
- 注意:容器内节点引用受限:子节点只能引用同容器同层节点或外部节点,不能引用父节点。
|
||||
|
||||
### use-build-options.tsx
|
||||
- 作用:轻量版,仅构建节点输出选项。
|
||||
- 导出:`useBuildNodeOutputOptions(nodeId?)`
|
||||
|
||||
### use-is-pipeline.ts
|
||||
- 作用:读取路由查询判断是否显示数据流画布(`AgentQuery.Category === DataflowCanvas`)。
|
||||
- 导出:`useIsPipeline()`
|
||||
|
||||
---
|
||||
|
||||
## 聊天与共享
|
||||
|
||||
### use-chat-logic.ts
|
||||
- 作用:对话中处理“等待用户填写”的表单组件逻辑,组装提交时的 `beginInputs`。
|
||||
- 导出:`useAwaitCompentData({ derivedMessages, sendFormMessage, canvasId })` → `{ getInputs, buildInputList, handleOk, isWaitting }`
|
||||
- 关键逻辑:将消息中的 `data.inputs` 与用户填写值合并后发送。
|
||||
|
||||
### use-cache-chat-log.ts
|
||||
- 作用:聊天事件按 `message_id` 分片缓存,支持过滤与清空。
|
||||
- 导出:`useCacheChatLog()` → `{ eventList, currentEventListWithoutMessage, currentEventListWithoutMessageById, setEventList, clearEventList, addEventList, filterEventListByEventType, filterEventListByMessageId, setCurrentMessageId, currentMessageId }`
|
||||
- 关键逻辑:排除 `Message/MessageEnd` 事件,保留节点事件日志用于“运行日志”展示。
|
||||
|
||||
### use-send-shared-message.ts
|
||||
- 作用:分享页的消息发送逻辑(可任务模式),包含参数弹窗与自动触发任务。
|
||||
- 导出:
|
||||
- `useSendButtonDisabled(value)` → 空字符串时禁用。
|
||||
- `useGetSharedChatSearchParams()` → 从 URL 解析 `from/shared_id/locale` 等。
|
||||
- `useSendNextSharedMessage(addEventList)` → `{ sendMessage, hasError, parameterDialogVisible, inputsData, isTaskMode, hideParameterDialog, showParameterDialog, ok }`
|
||||
- 关键逻辑:
|
||||
- `url` 动态拼接:`agentbots` 或 `chatbots`。
|
||||
- 任务模式且 `inputs` 为空时自动触发一次空参数运行。
|
||||
|
||||
---
|
||||
|
||||
## 外部资源与工具
|
||||
|
||||
### use-find-mcp-by-id.ts
|
||||
- 作用:在 MCP 服务列表中按 ID 查找服务器对象。
|
||||
- 导出:`useFindMcpById()` → `{ findMcpById(id) }`
|
||||
|
||||
### use-open-document.ts
|
||||
- 作用:打开在线文档(Agent 组件说明)。
|
||||
- 导出:`useOpenDocument()` → `openDocument()`(`window.open` 到 `https://ragflow.io/docs/dev/category/agent-components`)。
|
||||
|
||||
### use-show-dialog.ts
|
||||
- 作用:系统 API Key 管理与分享预览。
|
||||
- 导出:
|
||||
- `useOperateApiKey(idKey, dialogId?)` → `{ removeToken, createToken, tokenList, creatingLoading, listLoading }`
|
||||
- `usePreviewChat(idKey)` → `{ handlePreview }`
|
||||
- `useSelectChartStatsList()` → 将统计数据转换为图表用的 `{ xAxis, yAxis }[]`。
|
||||
- 关键逻辑:创建/删除系统 token;打开分享页预览 URL(根据 `idKey` 判断 Agent 或 Chat)。
|
||||
|
||||
---
|
||||
|
||||
## 布局与其他
|
||||
|
||||
### use-calculate-sheet-right.ts
|
||||
- 作用:根据 `body` 宽度返回抽屉的右侧定位类名。
|
||||
- 导出:`useCalculateSheetRight()` → `'right-[620px]' | 'right-1/3'`
|
||||
|
||||
### use-iteration.ts
|
||||
- 作用:当前文件为空,预留迭代相关的后续逻辑。
|
||||
- 导出:暂无(空文件)。
|
||||
|
||||
---
|
||||
|
||||
## 复现建议与流程
|
||||
|
||||
- 画布初始化:
|
||||
- 页面挂载时调用 `useFetchDataOnMount()`,保证 `nodes/edges` 与后端一致。
|
||||
- 如需区分是否数据流画布,调用 `useIsPipeline()` 控制界面模式。
|
||||
|
||||
- 节点与连接交互:
|
||||
- 连接拖拽中,使用 `useConnectionDrag` 的 `onConnectStart/onConnectEnd/onMove` 管理占位符与下拉。
|
||||
- 选择节点类型后,配合 `usePlaceholderManager.onNodeCreated(newNodeId)` 落地真实节点并连线。
|
||||
- 添加节点通过 `useAddNode.addCanvasNode(type,{ nodeId, position, id })(event)`,自动计算位置与连线。
|
||||
|
||||
- 表单与抽屉:
|
||||
- 点击节点打开 `useShowFormDrawer.showFormDrawer(e, nodeId)`;点击“播放”打开 `useShowSingleDebugDrawer`。
|
||||
- 外层抽屉控制 `useShowDrawer`;运行/聊天抽屉根据 Begin 输入状态切换。
|
||||
- 表单变更用 `useWatchFormChange(id, form)` 将 `react-hook-form` 值同步到 `data.form`。
|
||||
|
||||
- 运行与日志:
|
||||
- 上传文件后,调用 `useRunDataflow.run(fileResponseData)`;在日志抽屉中用 `useFetchPipelineLog(logSheetVisible)` 拉取状态。
|
||||
- 取消运行用 `useCancelCurrentDataflow.handleCancel()`;下载输出用 `useDownloadOutput.handleDownloadJson()`。
|
||||
|
||||
- 保存与导出:
|
||||
- 使用 `useSaveGraphBeforeOpeningDebugDrawer` 在每次调试前保存并重置状态。
|
||||
- 自动保存:`useWatchAgentChange(chatDrawerVisible)` 在无聊天抽屉时 debounce 落库。
|
||||
- 导出 JSON:`useHandleExportJsonFile.handleExportJson()`。
|
||||
|
||||
---
|
||||
|
||||
## 易踩坑与注意事项
|
||||
|
||||
- 占位符节点必须在保存 DSL 时过滤,否则会污染组件图(`useBuildDslData` 已处理)。
|
||||
- Tool 节点只允许有一个;`useAddNode` 中对 Tool 的添加有唯一性校验。
|
||||
- 容器类(Iteration)中的引用受限:子节点只能引用同容器同层节点或外部节点,不能引用父节点(`useBuildComponentIdOptions`)。
|
||||
- 名称唯一性:画布内节点与 Agent 下的 Tool name 均需唯一(`useChangeNodeName`)。
|
||||
- 聊天日志拉取需在 END 且 trace 有 message 时停止,否则会持续轮询(`useFetchPipelineLog`)。
|
||||
- 运行/聊天抽屉切换逻辑依赖 Begin 输入是否存在(`useShowDrawer`)。
|
||||
|
||||
---
|
||||
|
||||
## 关联常量与工具(理解 hooks 需要)
|
||||
|
||||
- `Operator`、`NodeHandleId`、`NodeMap`:定义节点类型和画布渲染类型。
|
||||
- `generateNodeNamesWithIncreasingIndex`:为新增节点生成不重复的默认名称。
|
||||
- `getNodeDragHandle(type)`:为不同节点类型定义可拖拽句柄范围。
|
||||
- `buildNodeOutputOptions`、`buildBeginInputListFromObject`、`buildBeginQueryWithObject`:构建下拉选项与输入/变量结构。
|
||||
|
||||
---
|
||||
|
||||
如需按模块拆分为多页或增加“最小复现代码片段”,可进一步细化。也可以优先从“连接拖拽 + 占位符 + 节点添加”链路开始,逐步验证 UI 与数据正确性。
|
||||
309
docs/agent-page-guide.md
Normal file
309
docs/agent-page-guide.md
Normal file
@@ -0,0 +1,309 @@
|
||||
# Agent 页面功能与结构说明(ragflow_core_v0.21.1)
|
||||
|
||||
本文档面向实现与维护,系统性梳理 `src/pages/agent` 的页面结构、数据流、关键组件与 Hook,以及常见功能点的改造入口,便于快速定位与扩展。
|
||||
|
||||
---
|
||||
|
||||
## 目录
|
||||
|
||||
- 入口与路由
|
||||
- 上下文与状态
|
||||
- 页面生命周期与数据加载
|
||||
- 画布层(渲染与交互)
|
||||
- 表单层(节点配置)
|
||||
- 保存与 DSL 构建
|
||||
- 运行与日志
|
||||
- 设置与头像
|
||||
- 常量与类型
|
||||
- 关键数据流(端到端)
|
||||
- 常见功能点定位(修改入口)
|
||||
- 报错与排查建议(头像 ERR_INVALID_URL)
|
||||
- 扩展与实现建议
|
||||
- 快速定位清单
|
||||
- 附:新增节点类型操作指南
|
||||
- 附:运行与日志调用流程
|
||||
- 附:术语与约定
|
||||
|
||||
---
|
||||
|
||||
## 入口与路由
|
||||
|
||||
- `src/pages/agent/index.tsx`
|
||||
- 页面主入口,渲染核心区域与抽屉/对话框:
|
||||
- 画布:`AgentCanvas`
|
||||
- 配置:`FormSheet`
|
||||
- 调试运行:`RunSheet`
|
||||
- 日志:`LogSheet`
|
||||
- 版本:`VersionDialog`
|
||||
- 嵌入:`EmbedDialog`
|
||||
- 设置:`SettingDialog`
|
||||
- 流水线:`PipelineRunSheet`、`PipelineLogSheet`
|
||||
- 使用 `useParams` 读取 `agentId`;用 `useTranslation` 做国际化。
|
||||
- 使用 `useSetModalState` 管理抽屉/对话框开关;与多个 Hook 交互。
|
||||
|
||||
- `src/routes/index.tsx`
|
||||
- 路由注册,包含 `AgentList` 和 `Agent` 详情入口。
|
||||
|
||||
---
|
||||
|
||||
## 上下文与状态
|
||||
|
||||
- `src/pages/agent/context.ts`
|
||||
- `AgentFormContext`:表单上下文(当前节点配置、提交、重置)。
|
||||
- `AgentInstanceContext`:Agent 实例与持久化相关数据。
|
||||
- `AgentChatContext` / `AgentChatLogContext`:聊天与日志面板状态。
|
||||
- `HandleContext`:画布句柄事件(连接、拖拽、选择)。
|
||||
|
||||
- `src/pages/agent/store.ts`(Zustand + Immer)
|
||||
- 全局画布状态:`nodes`、`edges`、选择状态、连接处理。
|
||||
- 常用方法:`addNode`、`updateNode`、`removeNode`、`addEdge`、`removeEdge`、`setNodes`、`setEdges`、`getNode`。
|
||||
- 用于画布交互与保存 DSL 的数据源。
|
||||
|
||||
---
|
||||
|
||||
## 页面生命周期与数据加载
|
||||
|
||||
- `src/pages/agent/hooks/use-fetch-data.ts`
|
||||
- `useFetchDataOnMount`:组件挂载时加载 Agent 数据(含图信息),并调用 `useSetGraphInfo` 设置 `nodes`/`edges`。
|
||||
|
||||
- `src/pages/agent/hooks/use-set-graph.ts`
|
||||
- `useSetGraphInfo(IGraph)`:批量设置 `nodes` 与 `edges`,用于从后端 DSL/存储中初始化画布。
|
||||
|
||||
---
|
||||
|
||||
## 画布层(渲染与交互)
|
||||
|
||||
- `src/pages/agent/canvas/index.tsx`
|
||||
- 基于 `ReactFlow` 的主画布组件,注册节点类型与边类型:
|
||||
- 节点:如 `BeginNode`、`RagNode`、`GenerateNode`、`CategorizeNode` 等。
|
||||
- 边:`ButtonEdge`(包含自定义交互按钮)。
|
||||
- 交互逻辑:
|
||||
- 连接(`onConnect`)、拖拽(`onDragStart`/`onDrop`)、选择与删除。
|
||||
- 与表单抽屉联动(选中节点时打开对应配置)。
|
||||
- 与调试运行、日志抽屉联动(运行前保存、展示日志)。
|
||||
- 与 Store 对接:读写 `nodes`、`edges`;对接上下文与 Hooks。
|
||||
|
||||
- 典型交互 Hook:`src/pages/agent/hooks/use-add-node.ts`
|
||||
- `useInitializeOperatorParams`:各 `Operator` 的初始表单值(含 `llm_id` 注入)。
|
||||
- `useGetNodeName`:本地化节点名生成(依赖 i18n 文案键 `flow.*`)。
|
||||
- `useCalculateNewlyBackChildPosition`:新增子节点坐标计算(避免覆盖)。
|
||||
- `useAddChildEdge`:按句柄类型自动连边(例如右侧输出到目标节点 `End`)。
|
||||
- `useAddToolNode`:在 `Agent` 节点下添加 `Tool` 子节点,并限制工具节点唯一性与坐标位置。
|
||||
- 句柄约定:`NodeHandleId`(如 `End`、`Tool` 等),用于源/目标句柄命名与连边规则。
|
||||
|
||||
---
|
||||
|
||||
## 表单层(节点配置)
|
||||
|
||||
- `src/pages/agent/form-sheet/next.tsx`
|
||||
- `FormSheet`:节点配置侧边抽屉。
|
||||
- 根据当前选中节点类型渲染对应表单组件(通过类型映射)。
|
||||
- 支持节点重命名、单步调试入口、关闭重置。
|
||||
- 与 `AgentFormContext` 协作(提交、校验、状态)。
|
||||
|
||||
- `src/pages/agent/agent-form/index.tsx`
|
||||
- `AgentForm`:Agent 节点核心配置:
|
||||
- 系统提示与用户提示、LLM 设置(模型、温度、`top_p`、`max_tokens`)。
|
||||
- 消息历史窗口、重试次数、错误延迟、异常处理方法等。
|
||||
- 使用 `react-hook-form + zod` 进行表单状态与校验。
|
||||
- 表单保存与 DSL 映射在 `useSaveGraph` 中完成。
|
||||
|
||||
- 表单映射入口说明
|
||||
- 类型到表单组件的映射一般在 `FormSheet` 内部维护;若寻找 `form-config-map.ts` 未找到,建议在 `FormSheet` 内搜索类型映射来源或相关导入。
|
||||
|
||||
---
|
||||
|
||||
## 保存与 DSL 构建
|
||||
|
||||
- `src/pages/agent/hooks/use-save-graph.ts`
|
||||
- `useSaveGraph`:将画布上的 `nodes` 与 `edges` 构建为 DSL 数据并提交后端保存 Agent(包含图与表单配置)。
|
||||
- `useSaveGraphBeforeOpeningDebugDrawer`:打开调试抽屉前保存图,并重置 Agent 实例数据。
|
||||
- `useWatchAgentChange`:监听 Agent 变化进行自动保存(防丢失)。
|
||||
|
||||
- `src/pages/agent/utils.ts`
|
||||
- 工具方法:构建 Agent 异常跳转、判断上下游关系、Agent 工具分类、操作符参数转换等。
|
||||
- 与保存逻辑配合,确保 DSL 参数与 UI 表单一致。
|
||||
|
||||
---
|
||||
|
||||
## 运行与日志
|
||||
|
||||
- `src/pages/agent/hooks/use-run-dataflow.ts`
|
||||
- `useRunDataflow`:运行前保存图、拉起日志面板;通过 SSE 发送运行请求,处理返回的消息 ID 与文件数据(如图像、附件)。
|
||||
|
||||
- `src/pages/agent/log-sheet/index.tsx`
|
||||
- `LogSheet`:侧边日志面板,展示工作流时间线与事件列表(`WorkFlowTimeline`)。
|
||||
|
||||
- `src/pages/agent/hooks/use-fetch-pipeline-log.ts`
|
||||
- `useFetchPipelineLog`:获取流水线日志,处理加载/完成状态与停止逻辑。
|
||||
|
||||
- `src/pages/agent/run-sheet/index.tsx`
|
||||
- `RunSheet`:测试运行抽屉(集成 `DebugContent`),使用 `useSaveGraphBeforeOpeningDebugDrawer` 与 `useGetBeginNodeDataInputs` 获取初始输入。
|
||||
|
||||
- `src/pages/agent/pipeline-run-sheet/index.tsx`
|
||||
- `PipelineRunSheet`:流水线运行面板,集成 `UploaderForm`(上传输入文件)。
|
||||
|
||||
---
|
||||
|
||||
## 设置与头像
|
||||
|
||||
- `src/pages/agent/setting-dialog/index.tsx`
|
||||
- `SettingDialog`:Agent 设置保存对话框。
|
||||
- 处理头像文件转 base64,并随保存 payload 一并提交。
|
||||
|
||||
> 说明:如果后端截断 `data:image/png;base64,...` 导致前端加载 `ERR_INVALID_URL`,需要后端允许存储完整 base64 或改用文件存储 + URL 返回。前端转码逻辑本身是正确的。
|
||||
|
||||
---
|
||||
|
||||
## 常量与类型
|
||||
|
||||
- `src/pages/agent/options.ts`
|
||||
- 常量选项,如 `LanguageOptions` 等。
|
||||
|
||||
- `src/pages/agent/interface.ts`
|
||||
- 类型与接口定义:`IOperatorForm`、`IGenerateParameter`、`IInvokeVariable`、`IPosition`、`BeginQuery`、`IInputs` 等。
|
||||
|
||||
- `src/pages/agent/constant.ts`(在 `use-add-node.ts` 中引用)
|
||||
- `Operator` 枚举与各节点初始值 `initial*Values`(如 `initialAgentValues`、`initialRetrievalValues` 等)。
|
||||
|
||||
---
|
||||
|
||||
## 关键数据流(端到端)
|
||||
|
||||
1. 初始化
|
||||
- 进入详情页时,`useFetchDataOnMount` 拉取当前 Agent 的图与配置。
|
||||
- `useSetGraphInfo` 将后端返回的 `nodes`、`edges` 写入 `useGraphStore`。
|
||||
- 画布 `AgentCanvas` 根据 Store 渲染节点与边。
|
||||
|
||||
2. 编辑
|
||||
- 在画布上添加/连接节点(`use-add-node.ts` 管理初值与连边)。
|
||||
- 选中节点打开 `FormSheet`,填写并校验表单(如 `AgentForm`)。
|
||||
- 表单更改更新 Store 中的节点数据(通过上下文与 Hook)。
|
||||
|
||||
3. 保存
|
||||
- 点击保存或运行前,`useSaveGraph` 将 `nodes`/`edges` 转为 DSL 并提交后端。
|
||||
|
||||
4. 运行与日志
|
||||
- `useRunDataflow` 触发运行,后端通过 SSE 推送消息。
|
||||
- `LogSheet` 展示运行过程与结果,`PipelineRunSheet` 支持文件输入场景。
|
||||
|
||||
5. 设置与外层能力
|
||||
- `SettingDialog` 保存头像与显示配置;`VersionDialog` 管理版本;`EmbedDialog` 提供嵌入能力。
|
||||
|
||||
---
|
||||
|
||||
## 常见功能点定位(修改入口)
|
||||
|
||||
- 画布行为
|
||||
- 新增节点初始参数:`hooks/use-add-node.ts` → `useInitializeOperatorParams`
|
||||
- 节点命名与本地化:`useGetNodeName`(依赖 `locales` 文案键 `flow.*`)
|
||||
- 子节点自动布局:`useCalculateNewlyBackChildPosition`
|
||||
- 工具节点添加与唯一性限制:`useAddToolNode`
|
||||
|
||||
- 保存与 DSL
|
||||
- 转换/提交:`hooks/use-save-graph.ts`(调整 DSL 结构或保存字段)
|
||||
- 参数转换与分类:`utils.ts`
|
||||
|
||||
- 运行与日志
|
||||
- 运行触发与 SSE 处理:`hooks/use-run-dataflow.ts`
|
||||
- 流水线日志轮询:`hooks/use-fetch-pipeline-log.ts`
|
||||
- 时间线展示:`log-sheet/index.tsx`
|
||||
|
||||
- 表单渲染
|
||||
- 抽屉入口与类型映射:`form-sheet/next.tsx`(及类型映射配置)
|
||||
- Agent 节点表单字段与校验:`agent-form/index.tsx`
|
||||
|
||||
- 全局状态
|
||||
- 节点/边增删改查:`store.ts`
|
||||
- 初始图设置:`hooks/use-set-graph.ts`
|
||||
|
||||
- 页面装配
|
||||
- 入口聚合与抽屉/对话框组织:`index.tsx`
|
||||
|
||||
---
|
||||
|
||||
## 报错与排查建议(头像 ERR_INVALID_URL)
|
||||
|
||||
- 问题表现:控制台出现对 `data:image/png;base64,...` 的 `GET`,报错 `ERR_INVALID_URL`。
|
||||
- 根因:后端字段长度或存储策略导致 Base64 被截断,前端加载失败。
|
||||
- 方案:
|
||||
- 后端允许存储完整 Base64;或改用文件存储并返回 URL。
|
||||
- 前端无需改动转码逻辑,仅需按后端新策略使用头像 URL。
|
||||
|
||||
---
|
||||
|
||||
## 扩展与实现建议
|
||||
|
||||
- 新增节点类型
|
||||
- 在 `src/pages/agent/constant.ts` 增加 `Operator` 枚举与 `initial*Values`。
|
||||
- 在 `src/pages/agent/canvas/index.tsx` 注册节点组件。
|
||||
- 在 `src/pages/agent/form-sheet/next.tsx` 添加表单类型映射。
|
||||
- 在 `src/pages/agent/utils.ts` 中处理新节点 DSL 字段与参数转换。
|
||||
- 如需新表单组件:在 `src/pages/agent/agent-form/` 或对应目录编写组件并导出。
|
||||
|
||||
- 调整保存策略
|
||||
- 在 `useSaveGraph` 中扩展 DSL 构建、校验与错误提示。
|
||||
- `useWatchAgentChange` 可增加节流或差异保存,降低后端压力。
|
||||
|
||||
- 增强运行体验
|
||||
- 在 `useRunDataflow` 中处理更多事件类型与文件数据(图像/附件流转)。
|
||||
- 在 `LogSheet` 增加过滤与分组能力,提升可读性。
|
||||
|
||||
---
|
||||
|
||||
## 快速定位清单
|
||||
|
||||
- 入口渲染与抽屉组织:`src/pages/agent/index.tsx`
|
||||
- 全局画布状态:`src/pages/agent/store.ts`
|
||||
- 画布渲染与交互:`src/pages/agent/canvas/index.tsx`
|
||||
- 初始化加载:`src/pages/agent/hooks/use-fetch-data.ts`、`src/pages/agent/hooks/use-set-graph.ts`
|
||||
- 保存 DSL:`src/pages/agent/hooks/use-save-graph.ts`
|
||||
- 运行数据流:`src/pages/agent/hooks/use-run-dataflow.ts`
|
||||
- 日志与流水线:`src/pages/agent/log-sheet/index.tsx`、`src/pages/agent/pipeline-run-sheet/index.tsx`、`src/pages/agent/hooks/use-fetch-pipeline-log.ts`
|
||||
- 表单抽屉:`src/pages/agent/form-sheet/next.tsx`
|
||||
- Agent 表单:`src/pages/agent/agent-form/index.tsx`
|
||||
- 工具与类型:`src/pages/agent/utils.ts`、`src/pages/agent/options.ts`、`src/pages/agent/interface.ts`
|
||||
- 添加节点与连边:`src/pages/agent/hooks/use-add-node.ts`
|
||||
- 列表页与基础查询:`src/hooks/agent-hooks.ts`、`src/pages/agent/list.tsx`(若存在)
|
||||
|
||||
---
|
||||
|
||||
## 附:新增节点类型操作指南(示例)
|
||||
|
||||
1. 在 `constant.ts` 中:
|
||||
- 增加枚举:`Operator.MyNode`
|
||||
- 增加初始值:`initialMyNodeValues`
|
||||
|
||||
2. 在 `canvas/index.tsx` 中:
|
||||
- 注册节点类型映射:`nodeTypes = { MyNode: MyNodeComponent, ... }`
|
||||
|
||||
3. 在 `form-sheet/next.tsx` 中:
|
||||
- 在类型映射里添加表单组件:`{ Operator.MyNode: MyNodeForm, ... }`
|
||||
|
||||
4. 在 `utils.ts` 中:
|
||||
- 扩展 DSL 构建逻辑,确保 `MyNode` 的参数能正确序列化到后端期望的字段。
|
||||
|
||||
5. 若需要服务端对接:
|
||||
- 查看/扩展 `src/services/agent_service.ts` 中相关接口调用。
|
||||
|
||||
---
|
||||
|
||||
## 附:运行与日志调用流程(简化时序)
|
||||
|
||||
1. 点击运行 → `useRunDataflow`
|
||||
2. 调 `useSaveGraph` 保存当前图(DSL)
|
||||
3. 发送运行请求(SSE)到后端
|
||||
4. 打开 `LogSheet` 并持续接收事件
|
||||
5. 显示工作流时间线与每步输出(含文件数据)
|
||||
|
||||
---
|
||||
|
||||
## 附:术语与约定
|
||||
|
||||
- `Operator`:画布节点的类型枚举。
|
||||
- `NodeHandleId`:节点句柄标识,控制连边的输入输出端(如 `End`、`Tool`)。
|
||||
- `DSL`:后端可执行的流程定义 JSON,由画布 `nodes`/`edges` 转换而来。
|
||||
|
||||
---
|
||||
|
||||
如需我导出一份“节点 → DSL 字段”对照表或补充类型映射的完整清单,请告诉我具体节点范围,我将进一步扫描相关目录并生成结构化手册,帮助你在实现新节点或对接后端时做到“改哪里、加什么、传什么”一目了然。
|
||||
287
docs/ahooks-usage-guide.md
Normal file
287
docs/ahooks-usage-guide.md
Normal file
@@ -0,0 +1,287 @@
|
||||
# Ahooks 使用指南(基础、进阶与常见用法)
|
||||
|
||||
Ahooks 是一套高质量、可复用的 React Hooks 集合,适合在业务工程中快速构建稳定的交互与数据逻辑。本文档覆盖快速上手、基础用法、`useRequest` 核心与进阶、常见场景模板、最佳实践与坑位排查,结合本项目技术栈(React 18 + Vite + MUI)。
|
||||
|
||||
目录
|
||||
- 为什么选 Ahooks
|
||||
- 安装与类型支持
|
||||
- 快速上手:页面标题(`useTitle`)
|
||||
- 基础能力:状态/事件/定时/存储/性能
|
||||
- useRequest 基础与进阶(自动/手动、轮询、缓存、SWR、重试等)
|
||||
- 常见场景模板(搜索防抖、任务轮询、分页、依赖请求、自动保存)
|
||||
- 最佳实践与常见坑位
|
||||
- 速查表与参考资料
|
||||
|
||||
## 为什么选用 Ahooks
|
||||
|
||||
- 大量生产验证的 Hooks,覆盖状态管理、请求、DOM、浏览器、性能优化等场景。
|
||||
- API 统一、可组合,适合封装成业务级自定义 Hook。
|
||||
- 降低维护成本:内置防抖/节流、轮询、缓存、并发控制、卸载安全、SWR 等复杂能力。
|
||||
|
||||
## 安装与类型支持
|
||||
|
||||
```bash
|
||||
pnpm add ahooks
|
||||
```
|
||||
|
||||
TypeScript 用户无需额外配置,Ahooks 提供完整的类型提示。
|
||||
|
||||
## 快速上手:更新页面标题(useTitle)
|
||||
|
||||
最直接的需求就是“更新页面标题”。`useTitle` 在组件挂载时设置 `document.title`,卸载时可恢复。
|
||||
|
||||
```tsx
|
||||
import { useTitle } from 'ahooks';
|
||||
|
||||
export default function KnowledgeListPage() {
|
||||
useTitle('TERES · 知识库列表', { restoreOnUnmount: true });
|
||||
return (<div>...</div>);
|
||||
}
|
||||
```
|
||||
|
||||
如需统一加前后缀,可封装:
|
||||
|
||||
```tsx
|
||||
import { useTitle } from 'ahooks';
|
||||
|
||||
export function usePageTitle(title?: string, opts?: { prefix?: string; suffix?: string }) {
|
||||
const final = [opts?.prefix, title, opts?.suffix].filter(Boolean).join(' · ');
|
||||
useTitle(final || 'TERES', { restoreOnUnmount: true });
|
||||
}
|
||||
```
|
||||
|
||||
## 基础能力(常用 Hooks)
|
||||
|
||||
- useBoolean / useToggle:布尔与枚举状态切换
|
||||
```tsx
|
||||
const [visible, { setTrue, setFalse, toggle }] = useBoolean(false);
|
||||
```
|
||||
|
||||
- useDebounceFn / useThrottleFn:防抖与节流(输入、滚动、窗口变化)
|
||||
```tsx
|
||||
const { run: onSearchChange, cancel } = useDebounceFn((kw: string) => setKeywords(kw), { wait: 300 });
|
||||
```
|
||||
|
||||
- useEventListener:声明式事件监听(自动清理)
|
||||
```tsx
|
||||
useEventListener('resize', () => console.log(window.innerWidth), { target: window });
|
||||
```
|
||||
|
||||
- useLocalStorageState / useSessionStorageState:状态持久化
|
||||
```tsx
|
||||
const [lang, setLang] = useLocalStorageState('lang', { defaultValue: 'zh' });
|
||||
```
|
||||
|
||||
- useInterval / useTimeout:定时任务(自动清理)
|
||||
```tsx
|
||||
useInterval(() => refresh(), 30000);
|
||||
```
|
||||
|
||||
- useMemoizedFn:稳定函数引用,避免子组件无谓重渲染/解绑
|
||||
```tsx
|
||||
const onNodeClick = useMemoizedFn((id: string) => openDetail(id));
|
||||
```
|
||||
|
||||
- useLatest:防陈旧闭包,异步/周期函数读取最新数据
|
||||
```tsx
|
||||
const latestState = useLatest(state);
|
||||
useInterval(() => { doSomething(latestState.current); }, 1000);
|
||||
```
|
||||
|
||||
- useSafeState / useUnmount:卸载安全,避免内存泄漏或报错
|
||||
```tsx
|
||||
const [data, setData] = useSafeState<any>(null);
|
||||
useUnmount(() => cancelRequest());
|
||||
```
|
||||
|
||||
## useRequest(核心与进阶)
|
||||
|
||||
`useRequest` 是 Ahooks 的异步数据管理核心,内置自动/手动触发、轮询、防抖/节流、屏幕聚焦重新请求、错误重试、loading 延迟、SWR(stale-while-revalidate)缓存等能力。[0][1]
|
||||
|
||||
### 基础用法(自动请求)
|
||||
|
||||
```tsx
|
||||
import { useRequest } from 'ahooks';
|
||||
import agentService from '@/services/agent_service';
|
||||
|
||||
export default function AgentList() {
|
||||
const { data, loading, error, refresh } = useRequest(() => agentService.fetchAgentList());
|
||||
if (loading) return <div>Loading...</div>;
|
||||
if (error) return <div>Error: {String(error)}</div>;
|
||||
return <div>{JSON.stringify(data)}</div>;
|
||||
}
|
||||
```
|
||||
|
||||
### 手动触发与参数管理
|
||||
|
||||
```tsx
|
||||
const { run, runAsync, loading, params } = useRequest((kw: string) => agentService.searchAgents({ keywords: kw }), {
|
||||
manual: true,
|
||||
onSuccess: (data, [kw]) => console.log('searched', kw, data),
|
||||
});
|
||||
|
||||
// 触发
|
||||
run('rag');
|
||||
// 或 await runAsync('rag').catch(console.error);
|
||||
```
|
||||
|
||||
### 生命周期回调
|
||||
|
||||
```tsx
|
||||
useRequest(api, {
|
||||
onBefore: (p) => console.log('before', p),
|
||||
onSuccess: (d) => console.log('success', d),
|
||||
onError: (e) => console.error('error', e),
|
||||
onFinally: (p, d, e) => console.log('finally'),
|
||||
});
|
||||
```
|
||||
|
||||
### 刷新上一次请求(refresh)与数据变更(mutate)
|
||||
|
||||
```tsx
|
||||
const { run, refresh, mutate, data } = useRequest(() => api.getUser(1), { manual: true });
|
||||
|
||||
// 修改页面数据,不等待接口返回
|
||||
mutate((old) => ({ ...old, name: 'New Name' }));
|
||||
// 使用上一次参数重新发起请求
|
||||
refresh();
|
||||
```
|
||||
|
||||
### 取消响应(cancel)与竞态取消
|
||||
|
||||
```tsx
|
||||
const { run, cancel } = useRequest(api.longTask, { manual: true });
|
||||
run();
|
||||
// 某些场景需要忽略本次 promise 的响应
|
||||
cancel();
|
||||
```
|
||||
|
||||
### 轮询与停止条件
|
||||
|
||||
```tsx
|
||||
const { data, cancel } = useRequest(() => agentService.getJobStatus(), {
|
||||
pollingInterval: 5000,
|
||||
pollingWhenHidden: false,
|
||||
onSuccess: (res) => { if (res.done) cancel(); },
|
||||
});
|
||||
```
|
||||
|
||||
### 防抖 / 节流 / 重试 / 延迟 / 焦点刷新
|
||||
|
||||
```tsx
|
||||
useRequest(searchService.query, {
|
||||
manual: true,
|
||||
debounceWait: 300,
|
||||
throttleWait: 1000,
|
||||
retryCount: 2,
|
||||
loadingDelay: 200,
|
||||
refreshOnWindowFocus: true,
|
||||
});
|
||||
```
|
||||
|
||||
### 缓存(cacheKey)与过期时间(staleTime)
|
||||
|
||||
```tsx
|
||||
const { data } = useRequest(() => agentService.fetchAgentList(), {
|
||||
cacheKey: 'agent:list',
|
||||
staleTime: 60_000, // 1分钟内复用缓存(SWR 策略)
|
||||
});
|
||||
```
|
||||
|
||||
### 条件就绪(ready)与依赖刷新(refreshDeps)
|
||||
|
||||
```tsx
|
||||
useRequest(() => api.getById(id), {
|
||||
ready: !!id,
|
||||
refreshDeps: [id],
|
||||
});
|
||||
```
|
||||
|
||||
### 默认参数(defaultParams)
|
||||
|
||||
```tsx
|
||||
const { data } = useRequest((id: number) => api.getById(id), {
|
||||
defaultParams: [1],
|
||||
});
|
||||
```
|
||||
|
||||
## 常见场景模板
|
||||
|
||||
### 搜索输入防抖
|
||||
|
||||
```tsx
|
||||
const { run: search } = useRequest((kw: string) => api.search({ keywords: kw }), { manual: true });
|
||||
const { run: onChange, cancel } = useDebounceFn((kw: string) => search(kw), { wait: 300 });
|
||||
```
|
||||
|
||||
### 任务状态轮询,完成后停止
|
||||
|
||||
```tsx
|
||||
const { data, cancel } = useRequest(() => api.getJobStatus(jobId), {
|
||||
pollingInterval: 5000,
|
||||
pollingWhenHidden: false,
|
||||
onSuccess: (res) => { if (res.done) cancel(); },
|
||||
});
|
||||
```
|
||||
|
||||
### 分页列表(前端分页)
|
||||
|
||||
```tsx
|
||||
const { data, loading } = useRequest(() => api.list({ page, pageSize, keywords }), {
|
||||
refreshDeps: [page, pageSize, keywords],
|
||||
});
|
||||
```
|
||||
|
||||
### 依赖请求(根据上游结果触发下游)
|
||||
|
||||
```tsx
|
||||
const userReq = useRequest(() => api.getUser(userId), { ready: !!userId });
|
||||
const postsReq = useRequest(() => api.getPosts(userReq.data?.id), {
|
||||
ready: !!userReq.data?.id,
|
||||
});
|
||||
```
|
||||
|
||||
### 自动保存(组件生命周期安全)
|
||||
|
||||
```tsx
|
||||
useInterval(async () => {
|
||||
if (!graphValid) return;
|
||||
await api.setAgentDSL(payload);
|
||||
}, 30_000);
|
||||
```
|
||||
|
||||
## 最佳实践与常见坑位
|
||||
|
||||
- 顶层调用 Hooks,避免条件语句中调用,保持顺序一致。
|
||||
- 依赖项变动可能导致频繁触发;`useMemoizedFn` 可保持函数引用稳定。
|
||||
- 轮询需显式停止;结合 `cancel()` 与 `pollingWhenHidden=false`。
|
||||
- 缓存需设置合理 `staleTime`,避免过时数据;SWR 适合只读列表数据。
|
||||
- 组件卸载时自动忽略响应,避免卸载后 setState。
|
||||
- SSR 环境下注意 `window/document` 可用性,必要时使用 `useIsomorphicLayoutEffect`。
|
||||
|
||||
## 与本项目的结合建议
|
||||
|
||||
- 知识库列表搜索:将 `setTimeout` 防抖替换为 `useDebounceFn`,代码更简洁且可取消。
|
||||
- 任务状态轮询:用 `useRequest` 的 `pollingInterval + cancel()` 替代手写 `setInterval`。
|
||||
- 自动保存:使用 `useInterval`,确保随组件生命周期清理(我们已修复泄漏问题)。
|
||||
- 事件绑定:用 `useEventListener` 管理 `window`/`document` 事件,自动清理。
|
||||
- 页面标题:用 `useTitle` 或统一的 `usePageTitle` 封装。
|
||||
|
||||
## 速查表(精选)
|
||||
|
||||
- 状态:`useBoolean`、`useToggle`、`useSetState`、`useControllableValue`
|
||||
- 请求:`useRequest`
|
||||
- DOM/事件:`useEventListener`、`useInViewport`、`useClickAway`
|
||||
- 定时:`useInterval`、`useTimeout`
|
||||
- 存储:`useLocalStorageState`、`useSessionStorageState`
|
||||
- 性能/安全:`useDebounceFn`、`useThrottleFn`、`useMemoizedFn`、`useLatest`、`useSafeState`
|
||||
|
||||
## 参考资料
|
||||
|
||||
- 官方文档(useRequest 快速上手)[0] https://ahooks.js.org/zh-CN/hooks/use-request/index
|
||||
- 官方文档(useRequest 基础用法)[1] https://ahooks.js.org/zh-CN/hooks/use-request/basic
|
||||
- 项目仓库:https://github.com/alibaba/hooks
|
||||
|
||||
---
|
||||
|
||||
实战建议:如果只需要“更新 web 标题”,直接在页面组件里使用 `useTitle`;若需统一标题规范或根据路由动态拼接,封装一个 `usePageTitle` 更可维护。`useRequest` 作为核心请求管理,优先在网络交互中使用它的自动/手动、轮询、缓存与重试能力,替代手写的定时器与状态机。
|
||||
8
docs/contribution/_category_.json
Normal file
8
docs/contribution/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Contribution",
|
||||
"position": 8,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Miscellaneous contribution guides."
|
||||
}
|
||||
}
|
||||
57
docs/contribution/contributing.md
Normal file
57
docs/contribution/contributing.md
Normal file
@@ -0,0 +1,57 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /contributing
|
||||
---
|
||||
|
||||
# Contribution guidelines
|
||||
|
||||
General guidelines for RAGFlow's community contributors.
|
||||
|
||||
---
|
||||
|
||||
This document offers guidelines and major considerations for submitting your contributions to RAGFlow.
|
||||
|
||||
- To report a bug, file a [GitHub issue](https://github.com/infiniflow/ragflow/issues/new/choose) with us.
|
||||
- For further questions, you can explore existing discussions or initiate a new one in [Discussions](https://github.com/orgs/infiniflow/discussions).
|
||||
|
||||
## What you can contribute
|
||||
|
||||
The list below mentions some contributions you can make, but it is not a complete list.
|
||||
|
||||
- Proposing or implementing new features
|
||||
- Fixing a bug
|
||||
- Adding test cases or demos
|
||||
- Posting a blog or tutorial
|
||||
- Updates to existing documents, codes, or annotations.
|
||||
- Suggesting more user-friendly error codes
|
||||
|
||||
## File a pull request (PR)
|
||||
|
||||
### General workflow
|
||||
|
||||
1. Fork our GitHub repository.
|
||||
2. Clone your fork to your local machine:
|
||||
`git clone git@github.com:<yourname>/ragflow.git`
|
||||
3. Create a local branch:
|
||||
`git checkout -b my-branch`
|
||||
4. Provide sufficient information in your commit message
|
||||
`git commit -m 'Provide sufficient info in your commit message'`
|
||||
5. Commit changes to your local branch, and push to GitHub: (include necessary commit message)
|
||||
`git push origin my-branch.`
|
||||
6. Submit a pull request for review.
|
||||
|
||||
### Before filing a PR
|
||||
|
||||
- Consider splitting a large PR into multiple smaller, standalone PRs to keep a traceable development history.
|
||||
- Ensure that your PR addresses just one issue, or keep any unrelated changes small.
|
||||
- Add test cases when contributing new features. They demonstrate that your code functions correctly and protect against potential issues from future changes.
|
||||
|
||||
### Describing your PR
|
||||
|
||||
- Ensure that your PR title is concise and clear, providing all the required information.
|
||||
- Refer to a corresponding GitHub issue in your PR description if applicable.
|
||||
- Include sufficient design details for *breaking changes* or *API changes* in your description.
|
||||
|
||||
### Reviewing & merging a PR
|
||||
|
||||
Ensure that your PR passes all Continuous Integration (CI) tests before merging it.
|
||||
8
docs/develop/_category_.json
Normal file
8
docs/develop/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Developers",
|
||||
"position": 4,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides for hardcore developers"
|
||||
}
|
||||
}
|
||||
18
docs/develop/acquire_ragflow_api_key.md
Normal file
18
docs/develop/acquire_ragflow_api_key.md
Normal file
@@ -0,0 +1,18 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /acquire_ragflow_api_key
|
||||
---
|
||||
|
||||
# Acquire RAGFlow API key
|
||||
|
||||
An API key is required for the RAGFlow server to authenticate your HTTP/Python or MCP requests. This documents provides instructions on obtaining a RAGFlow API key.
|
||||
|
||||
1. Click your avatar in the top right corner of the RAGFlow UI to access the configuration page.
|
||||
2. Click **API** to switch to the **API** page.
|
||||
3. Obtain a RAGFlow API key:
|
||||
|
||||
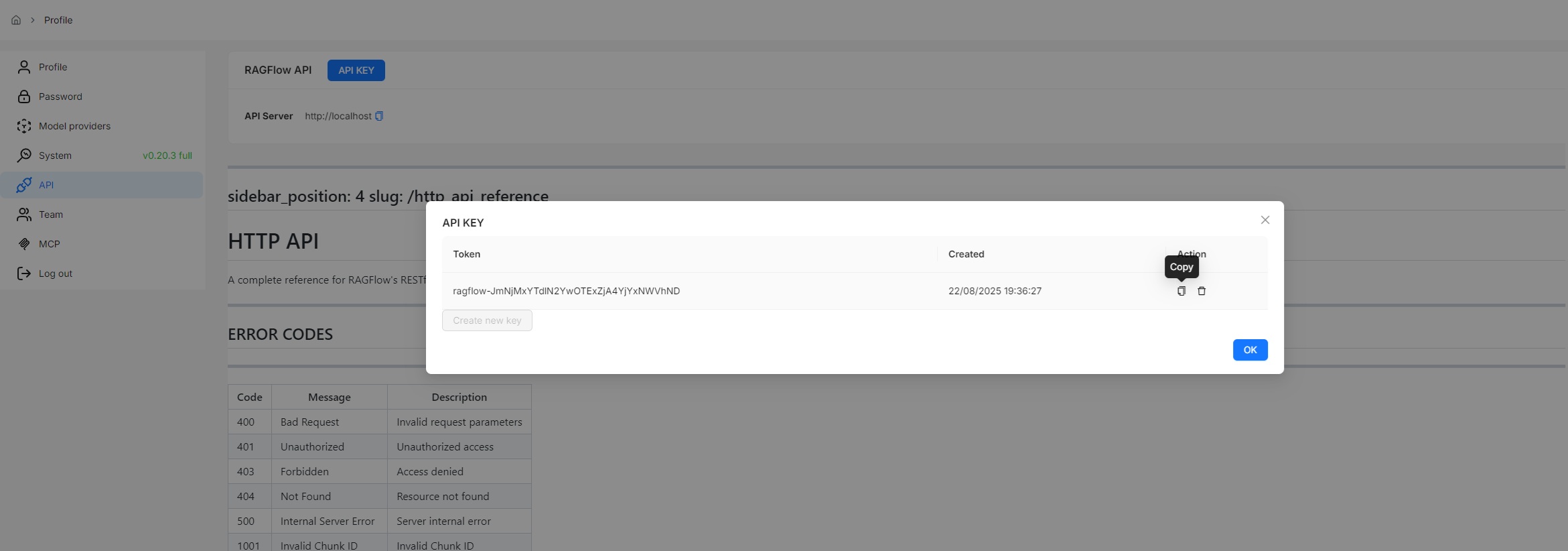
|
||||
|
||||
:::tip NOTE
|
||||
See the [RAGFlow HTTP API reference](../references/http_api_reference.md) or the [RAGFlow Python API reference](../references/python_api_reference.md) for a complete reference of RAGFlow's HTTP or Python APIs.
|
||||
:::
|
||||
92
docs/develop/build_docker_image.mdx
Normal file
92
docs/develop/build_docker_image.mdx
Normal file
@@ -0,0 +1,92 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /build_docker_image
|
||||
---
|
||||
|
||||
# Build RAGFlow Docker image
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
A guide explaining how to build a RAGFlow Docker image from its source code. By following this guide, you'll be able to create a local Docker image that can be used for development, debugging, or testing purposes.
|
||||
|
||||
## Target Audience
|
||||
|
||||
- Developers who have added new features or modified the existing code and require a Docker image to view and debug their changes.
|
||||
- Developers seeking to build a RAGFlow Docker image for an ARM64 platform.
|
||||
- Testers aiming to explore the latest features of RAGFlow in a Docker image.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- CPU ≥ 4 cores
|
||||
- RAM ≥ 16 GB
|
||||
- Disk ≥ 50 GB
|
||||
- Docker ≥ 24.0.0 & Docker Compose ≥ v2.26.1
|
||||
|
||||
## Build a Docker image
|
||||
|
||||
<Tabs
|
||||
defaultValue="without"
|
||||
values={[
|
||||
{label: 'Build a Docker image without embedding models', value: 'without'},
|
||||
{label: 'Build a Docker image including embedding models', value: 'including'}
|
||||
]}>
|
||||
<TabItem value="without">
|
||||
|
||||
This image is approximately 2 GB in size and relies on external LLM and embedding services.
|
||||
|
||||
:::danger IMPORTANT
|
||||
- While we also test RAGFlow on ARM64 platforms, we do not maintain RAGFlow Docker images for ARM. However, you can build an image yourself on a `linux/arm64` or `darwin/arm64` host machine as well.
|
||||
- For ARM64 platforms, please upgrade the `xgboost` version in **pyproject.toml** to `1.6.0` and ensure **unixODBC** is properly installed.
|
||||
:::
|
||||
|
||||
```bash
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv run download_deps.py
|
||||
docker build -f Dockerfile.deps -t infiniflow/ragflow_deps .
|
||||
docker build --build-arg LIGHTEN=1 -f Dockerfile -t infiniflow/ragflow:nightly-slim .
|
||||
```
|
||||
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="including">
|
||||
|
||||
This image is approximately 9 GB in size. As it includes embedding models, it relies on external LLM services only.
|
||||
|
||||
:::danger IMPORTANT
|
||||
- While we also test RAGFlow on ARM64 platforms, we do not maintain RAGFlow Docker images for ARM. However, you can build an image yourself on a `linux/arm64` or `darwin/arm64` host machine as well.
|
||||
- For ARM64 platforms, please upgrade the `xgboost` version in **pyproject.toml** to `1.6.0` and ensure **unixODBC** is properly installed.
|
||||
:::
|
||||
|
||||
```bash
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
uv run download_deps.py
|
||||
docker build -f Dockerfile.deps -t infiniflow/ragflow_deps .
|
||||
docker build -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
## Launch a RAGFlow Service from Docker for MacOS
|
||||
|
||||
After building the infiniflow/ragflow:nightly-slim image, you are ready to launch a fully-functional RAGFlow service with all the required components, such as Elasticsearch, MySQL, MinIO, Redis, and more.
|
||||
|
||||
## Example: Apple M2 Pro (Sequoia)
|
||||
|
||||
1. Edit Docker Compose Configuration
|
||||
|
||||
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.21.1-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
||||
|
||||
|
||||
2. Launch the Service
|
||||
|
||||
```bash
|
||||
cd docker
|
||||
$ docker compose -f docker-compose-macos.yml up -d
|
||||
```
|
||||
|
||||
3. Access the RAGFlow Service
|
||||
|
||||
Once the setup is complete, open your web browser and navigate to http://127.0.0.1 or your server's \<IP_ADDRESS\>; (the default port is \<PORT\> = 80). You will be directed to the RAGFlow welcome page. Enjoy!🍻
|
||||
145
docs/develop/launch_ragflow_from_source.md
Normal file
145
docs/develop/launch_ragflow_from_source.md
Normal file
@@ -0,0 +1,145 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /launch_ragflow_from_source
|
||||
---
|
||||
|
||||
# Launch service from source
|
||||
|
||||
A guide explaining how to set up a RAGFlow service from its source code. By following this guide, you'll be able to debug using the source code.
|
||||
|
||||
## Target audience
|
||||
|
||||
Developers who have added new features or modified existing code and wish to debug using the source code, *provided that* their machine has the target deployment environment set up.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- CPU ≥ 4 cores
|
||||
- RAM ≥ 16 GB
|
||||
- Disk ≥ 50 GB
|
||||
- Docker ≥ 24.0.0 & Docker Compose ≥ v2.26.1
|
||||
|
||||
:::tip NOTE
|
||||
If you have not installed Docker on your local machine (Windows, Mac, or Linux), see the [Install Docker Engine](https://docs.docker.com/engine/install/) guide.
|
||||
:::
|
||||
|
||||
## Launch a service from source
|
||||
|
||||
To launch a RAGFlow service from source code:
|
||||
|
||||
### Clone the RAGFlow repository
|
||||
|
||||
```bash
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
cd ragflow/
|
||||
```
|
||||
|
||||
### Install Python dependencies
|
||||
|
||||
1. Install uv:
|
||||
|
||||
```bash
|
||||
pipx install uv
|
||||
```
|
||||
|
||||
2. Install Python dependencies:
|
||||
- slim:
|
||||
```bash
|
||||
uv sync --python 3.10 # install RAGFlow dependent python modules
|
||||
```
|
||||
- full:
|
||||
```bash
|
||||
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||
```
|
||||
*A virtual environment named `.venv` is created, and all Python dependencies are installed into the new environment.*
|
||||
|
||||
### Launch third-party services
|
||||
|
||||
The following command launches the 'base' services (MinIO, Elasticsearch, Redis, and MySQL) using Docker Compose:
|
||||
|
||||
```bash
|
||||
docker compose -f docker/docker-compose-base.yml up -d
|
||||
```
|
||||
|
||||
### Update `host` and `port` Settings for Third-party Services
|
||||
|
||||
1. Add the following line to `/etc/hosts` to resolve all hosts specified in **docker/service_conf.yaml.template** to `127.0.0.1`:
|
||||
|
||||
```
|
||||
127.0.0.1 es01 infinity mysql minio redis
|
||||
```
|
||||
|
||||
2. In **docker/service_conf.yaml.template**, update mysql port to `5455` and es port to `1200`, as specified in **docker/.env**.
|
||||
|
||||
### Launch the RAGFlow backend service
|
||||
|
||||
1. Comment out the `nginx` line in **docker/entrypoint.sh**.
|
||||
|
||||
```
|
||||
# /usr/sbin/nginx
|
||||
```
|
||||
|
||||
2. Activate the Python virtual environment:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
```
|
||||
|
||||
3. **Optional:** If you cannot access HuggingFace, set the HF_ENDPOINT environment variable to use a mirror site:
|
||||
|
||||
```bash
|
||||
export HF_ENDPOINT=https://hf-mirror.com
|
||||
```
|
||||
|
||||
4. Check the configuration in **conf/service_conf.yaml**, ensuring all hosts and ports are correctly set.
|
||||
|
||||
5. Run the **entrypoint.sh** script to launch the backend service:
|
||||
|
||||
```shell
|
||||
JEMALLOC_PATH=$(pkg-config --variable=libdir jemalloc)/libjemalloc.so;
|
||||
LD_PRELOAD=$JEMALLOC_PATH python rag/svr/task_executor.py 1;
|
||||
```
|
||||
```shell
|
||||
python api/ragflow_server.py;
|
||||
```
|
||||
|
||||
### Launch the RAGFlow frontend service
|
||||
|
||||
1. Navigate to the `web` directory and install the frontend dependencies:
|
||||
|
||||
```bash
|
||||
cd web
|
||||
npm install
|
||||
```
|
||||
|
||||
2. Update `proxy.target` in **.umirc.ts** to `http://127.0.0.1:9380`:
|
||||
|
||||
```bash
|
||||
vim .umirc.ts
|
||||
```
|
||||
|
||||
3. Start up the RAGFlow frontend service:
|
||||
|
||||
```bash
|
||||
npm run dev
|
||||
```
|
||||
|
||||
*The following message appears, showing the IP address and port number of your frontend service:*
|
||||
|
||||

|
||||
|
||||
### Access the RAGFlow service
|
||||
|
||||
In your web browser, enter `http://127.0.0.1:<PORT>/`, ensuring the port number matches that shown in the screenshot above.
|
||||
|
||||
### Stop the RAGFlow service when the development is done
|
||||
|
||||
1. Stop the RAGFlow frontend service:
|
||||
```bash
|
||||
pkill npm
|
||||
```
|
||||
|
||||
2. Stop the RAGFlow backend service:
|
||||
```bash
|
||||
pkill -f "docker/entrypoint.sh"
|
||||
```
|
||||
8
docs/develop/mcp/_category_.json
Normal file
8
docs/develop/mcp/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "MCP",
|
||||
"position": 40,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides and references on accessing RAGFlow's datasets via MCP."
|
||||
}
|
||||
}
|
||||
212
docs/develop/mcp/launch_mcp_server.md
Normal file
212
docs/develop/mcp/launch_mcp_server.md
Normal file
@@ -0,0 +1,212 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /launch_mcp_server
|
||||
---
|
||||
|
||||
# Launch RAGFlow MCP server
|
||||
|
||||
Launch an MCP server from source or via Docker.
|
||||
|
||||
---
|
||||
|
||||
A RAGFlow Model Context Protocol (MCP) server is designed as an independent component to complement the RAGFlow server. Note that an MCP server must operate alongside a properly functioning RAGFlow server.
|
||||
|
||||
An MCP server can start up in either self-host mode (default) or host mode:
|
||||
|
||||
- **Self-host mode**:
|
||||
When launching an MCP server in self-host mode, you must provide an API key to authenticate the MCP server with the RAGFlow server. In this mode, the MCP server can access *only* the datasets of a specified tenant on the RAGFlow server.
|
||||
- **Host mode**:
|
||||
In host mode, each MCP client can access their own datasets on the RAGFlow server. However, each client request must include a valid API key to authenticate the client with the RAGFlow server.
|
||||
|
||||
Once a connection is established, an MCP server communicates with its client in MCP HTTP+SSE (Server-Sent Events) mode, unidirectionally pushing responses from the RAGFlow server to its client in real time.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure RAGFlow is upgraded to v0.18.0 or later.
|
||||
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](../acquire_ragflow_api_key.md).
|
||||
|
||||
:::tip INFO
|
||||
If you wish to try out our MCP server without upgrading RAGFlow, community contributor [yiminghub2024](https://github.com/yiminghub2024) 👏 shares their recommended steps [here](#launch-an-mcp-server-without-upgrading-ragflow).
|
||||
:::
|
||||
|
||||
## Launch an MCP server
|
||||
|
||||
You can start an MCP server either from source code or via Docker.
|
||||
|
||||
### Launch from source code
|
||||
|
||||
1. Ensure that a RAGFlow server v0.18.0+ is properly running.
|
||||
2. Launch the MCP server:
|
||||
|
||||
|
||||
```bash
|
||||
# Launch the MCP server to work in self-host mode, run either of the following
|
||||
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base-url=http://127.0.0.1:9380 --api-key=ragflow-xxxxx
|
||||
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base-url=http://127.0.0.1:9380 --mode=self-host --api-key=ragflow-xxxxx
|
||||
|
||||
# To launch the MCP server to work in host mode, run the following instead:
|
||||
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base-url=http://127.0.0.1:9380 --mode=host
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
- `host`: The MCP server's host address.
|
||||
- `port`: The MCP server's listening port.
|
||||
- `base_url`: The address of the running RAGFlow server.
|
||||
- `mode`: The launch mode.
|
||||
- `self-host`: (default) self-host mode.
|
||||
- `host`: host mode.
|
||||
- `api_key`: Required in self-host mode to authenticate the MCP server with the RAGFlow server. See [here](../acquire_ragflow_api_key.md) for instructions on acquiring an API key.
|
||||
|
||||
### Transports
|
||||
|
||||
The RAGFlow MCP server supports two transports: the legacy SSE transport (served at `/sse`), introduced on November 5, 2024 and deprecated on March 26, 2025, and the streamable-HTTP transport (served at `/mcp`). The legacy SSE transport and the streamable HTTP transport with JSON responses are enabled by default. To disable either transport, use the flags `--no-transport-sse-enabled` or `--no-transport-streamable-http-enabled`. To disable JSON responses for the streamable HTTP transport, use the `--no-json-response` flag.
|
||||
|
||||
### Launch from Docker
|
||||
|
||||
#### 1. Enable MCP server
|
||||
|
||||
The MCP server is designed as an optional component that complements the RAGFlow server and disabled by default. To enable MCP server:
|
||||
|
||||
1. Navigate to **docker/docker-compose.yml**.
|
||||
2. Uncomment the `services.ragflow.command` section as shown below:
|
||||
|
||||
```yaml {6-13}
|
||||
services:
|
||||
ragflow:
|
||||
...
|
||||
image: ${RAGFLOW_IMAGE}
|
||||
# Example configuration to set up an MCP server:
|
||||
command:
|
||||
- --enable-mcpserver
|
||||
- --mcp-host=0.0.0.0
|
||||
- --mcp-port=9382
|
||||
- --mcp-base-url=http://127.0.0.1:9380
|
||||
- --mcp-script-path=/ragflow/mcp/server/server.py
|
||||
- --mcp-mode=self-host
|
||||
- --mcp-host-api-key=ragflow-xxxxxxx
|
||||
# Optional transport flags for the RAGFlow MCP server.
|
||||
# If you set `mcp-mode` to `host`, you must add the --no-transport-streamable-http-enabled flag, because the streamable-HTTP transport is not yet supported in host mode.
|
||||
# The legacy SSE transport and the streamable-HTTP transport with JSON responses are enabled by default.
|
||||
# To disable a specific transport or JSON responses for the streamable-HTTP transport, use the corresponding flag(s):
|
||||
# - --no-transport-sse-enabled # Disables the legacy SSE endpoint (/sse)
|
||||
# - --no-transport-streamable-http-enabled # Disables the streamable-HTTP transport (served at the /mcp endpoint)
|
||||
# - --no-json-response # Disables JSON responses for the streamable-HTTP transport
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
- `mcp-host`: The MCP server's host address.
|
||||
- `mcp-port`: The MCP server's listening port.
|
||||
- `mcp-base-url`: The address of the running RAGFlow server.
|
||||
- `mcp-script-path`: The file path to the MCP server’s main script.
|
||||
- `mcp-mode`: The launch mode.
|
||||
- `self-host`: (default) self-host mode.
|
||||
- `host`: host mode.
|
||||
- `mcp-host-api_key`: Required in self-host mode to authenticate the MCP server with the RAGFlow server. See [here](../acquire_ragflow_api_key.md) for instructions on acquiring an API key.
|
||||
|
||||
:::tip INFO
|
||||
If you set `mcp-mode` to `host`, you must add the `--no-transport-streamable-http-enabled` flag, because the streamable-HTTP transport is not yet supported in host mode.
|
||||
:::
|
||||
|
||||
#### 2. Launch a RAGFlow server with an MCP server
|
||||
|
||||
Run `docker compose -f docker-compose.yml up` to launch the RAGFlow server together with the MCP server.
|
||||
|
||||
*The following ASCII art confirms a successful launch:*
|
||||
|
||||
```bash
|
||||
ragflow-server | Starting MCP Server on 0.0.0.0:9382 with base URL http://127.0.0.1:9380...
|
||||
ragflow-server | Starting 1 task executor(s) on host 'dd0b5e07e76f'...
|
||||
ragflow-server | 2025-04-18 15:41:18,816 INFO 27 ragflow_server log path: /ragflow/logs/ragflow_server.log, log levels: {'peewee': 'WARNING', 'pdfminer': 'WARNING', 'root': 'INFO'}
|
||||
ragflow-server |
|
||||
ragflow-server | __ __ ____ ____ ____ _____ ______ _______ ____
|
||||
ragflow-server | | \/ |/ ___| _ \ / ___|| ____| _ \ \ / / ____| _ \
|
||||
ragflow-server | | |\/| | | | |_) | \___ \| _| | |_) \ \ / /| _| | |_) |
|
||||
ragflow-server | | | | | |___| __/ ___) | |___| _ < \ V / | |___| _ <
|
||||
ragflow-server | |_| |_|\____|_| |____/|_____|_| \_\ \_/ |_____|_| \_\
|
||||
ragflow-server |
|
||||
ragflow-server | MCP launch mode: self-host
|
||||
ragflow-server | MCP host: 0.0.0.0
|
||||
ragflow-server | MCP port: 9382
|
||||
ragflow-server | MCP base_url: http://127.0.0.1:9380
|
||||
ragflow-server | INFO: Started server process [26]
|
||||
ragflow-server | INFO: Waiting for application startup.
|
||||
ragflow-server | INFO: Application startup complete.
|
||||
ragflow-server | INFO: Uvicorn running on http://0.0.0.0:9382 (Press CTRL+C to quit)
|
||||
ragflow-server | 2025-04-18 15:41:20,469 INFO 27 found 0 gpus
|
||||
ragflow-server | 2025-04-18 15:41:23,263 INFO 27 init database on cluster mode successfully
|
||||
ragflow-server | 2025-04-18 15:41:25,318 INFO 27 load_model /ragflow/rag/res/deepdoc/det.onnx uses CPU
|
||||
ragflow-server | 2025-04-18 15:41:25,367 INFO 27 load_model /ragflow/rag/res/deepdoc/rec.onnx uses CPU
|
||||
ragflow-server | ____ ___ ______ ______ __
|
||||
ragflow-server | / __ \ / | / ____// ____// /____ _ __
|
||||
ragflow-server | / /_/ // /| | / / __ / /_ / // __ \| | /| / /
|
||||
ragflow-server | / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
|
||||
ragflow-server | /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
|
||||
ragflow-server |
|
||||
ragflow-server |
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 project base: /ragflow
|
||||
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 Current configs, from /ragflow/conf/service_conf.yaml:
|
||||
ragflow-server | ragflow: {'host': '0.0.0.0', 'http_port': 9380}
|
||||
...
|
||||
ragflow-server | * Running on all addresses (0.0.0.0)
|
||||
ragflow-server | * Running on http://127.0.0.1:9380
|
||||
ragflow-server | * Running on http://172.19.0.6:9380
|
||||
ragflow-server | ______ __ ______ __
|
||||
ragflow-server | /_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____
|
||||
ragflow-server | / / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___/
|
||||
ragflow-server | / / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /
|
||||
ragflow-server | /_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/
|
||||
ragflow-server |
|
||||
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 TaskExecutor: RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 Use Elasticsearch http://es01:9200 as the doc engine.
|
||||
...
|
||||
```
|
||||
|
||||
#### Launch an MCP server without upgrading RAGFlow
|
||||
|
||||
:::info KUDOS
|
||||
This section is contributed by our community contributor [yiminghub2024](https://github.com/yiminghub2024). 👏
|
||||
:::
|
||||
|
||||
1. Prepare all MCP-specific files and directories.
|
||||
i. Copy the [mcp/](https://github.com/infiniflow/ragflow/tree/main/mcp) directory to your local working directory.
|
||||
ii. Copy [docker/docker-compose.yml](https://github.com/infiniflow/ragflow/blob/main/docker/docker-compose.yml) locally.
|
||||
iii. Copy [docker/entrypoint.sh](https://github.com/infiniflow/ragflow/blob/main/docker/entrypoint.sh) locally.
|
||||
iv. Install the required dependencies using `uv`:
|
||||
- Run `uv add mcp` or
|
||||
- Copy [pyproject.toml](https://github.com/infiniflow/ragflow/blob/main/pyproject.toml) locally and run `uv sync --python 3.10 --all-extras`.
|
||||
2. Edit **docker-compose.yml** to enable MCP (disabled by default).
|
||||
3. Launch the MCP server:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
|
||||
### Check MCP server status
|
||||
|
||||
Run the following to check the logs the RAGFlow server and the MCP server:
|
||||
|
||||
```bash
|
||||
docker logs ragflow-server
|
||||
```
|
||||
|
||||
## Security considerations
|
||||
|
||||
As MCP technology is still at early stage and no official best practices for authentication or authorization have been established, RAGFlow currently uses [API key](./acquire_ragflow_api_key.md) to validate identity for the operations described earlier. However, in public environments, this makeshift solution could expose your MCP server to potential network attacks. Therefore, when running a local SSE server, it is recommended to bind only to localhost (`127.0.0.1`) rather than to all interfaces (`0.0.0.0`).
|
||||
|
||||
For further guidance, see the [official MCP documentation](https://modelcontextprotocol.io/docs/concepts/transports#security-considerations).
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### When to use an API key for authentication?
|
||||
|
||||
The use of an API key depends on the operating mode of your MCP server.
|
||||
|
||||
- **Self-host mode** (default):
|
||||
When starting the MCP server in self-host mode, you should provide an API key when launching it to authenticate it with the RAGFlow server:
|
||||
- If launching from source, include the API key in the command.
|
||||
- If launching from Docker, update the API key in **docker/docker-compose.yml**.
|
||||
- **Host mode**:
|
||||
If your RAGFlow MCP server is working in host mode, include the API key in the `headers` of your client requests to authenticate your client with the RAGFlow server. An example is available [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
||||
241
docs/develop/mcp/mcp_client_example.md
Normal file
241
docs/develop/mcp/mcp_client_example.md
Normal file
@@ -0,0 +1,241 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /mcp_client
|
||||
|
||||
---
|
||||
|
||||
# RAGFlow MCP client examples
|
||||
|
||||
Python and curl MCP client examples.
|
||||
|
||||
------
|
||||
|
||||
## Example MCP Python client
|
||||
|
||||
We provide a *prototype* MCP client example for testing [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
||||
|
||||
:::info IMPORTANT
|
||||
If your MCP server is running in host mode, include your acquired API key in your client's `headers` when connecting asynchronously to it:
|
||||
|
||||
```python
|
||||
async with sse_client("http://localhost:9382/sse", headers={"api_key": "YOUR_KEY_HERE"}) as streams:
|
||||
# Rest of your code...
|
||||
```
|
||||
|
||||
Alternatively, to comply with [OAuth 2.1 Section 5](https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-12#section-5), you can run the following code *instead* to connect to your MCP server:
|
||||
|
||||
```python
|
||||
async with sse_client("http://localhost:9382/sse", headers={"Authorization": "YOUR_KEY_HERE"}) as streams:
|
||||
# Rest of your code...
|
||||
```
|
||||
:::
|
||||
|
||||
## Use curl to interact with the RAGFlow MCP server
|
||||
|
||||
When interacting with the MCP server via HTTP requests, follow this initialization sequence:
|
||||
|
||||
1. **The client sends an `initialize` request** with protocol version and capabilities.
|
||||
2. **The server replies with an `initialize` response**, including the supported protocol and capabilities.
|
||||
3. **The client confirms readiness with an `initialized` notification**.
|
||||
_The connection is established between the client and the server, and further operations (such as tool listing) may proceed._
|
||||
|
||||
:::tip NOTE
|
||||
For more information about this initialization process, see [here](https://modelcontextprotocol.io/docs/concepts/architecture#1-initialization).
|
||||
:::
|
||||
|
||||
In the following sections, we will walk you through a complete tool calling process.
|
||||
|
||||
### 1. Obtain a session ID
|
||||
|
||||
Each curl request with the MCP server must include a session ID:
|
||||
|
||||
```bash
|
||||
$ curl -N -H "api_key: YOUR_API_KEY" http://127.0.0.1:9382/sse
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
See [here](../acquire_ragflow_api_key.md) for information about acquiring an API key.
|
||||
:::
|
||||
|
||||
#### Transport
|
||||
|
||||
The transport will stream messages such as tool results, server responses, and keep-alive pings.
|
||||
|
||||
_The server returns the session ID:_
|
||||
|
||||
```bash
|
||||
event: endpoint
|
||||
data: /messages/?session_id=5c6600ef61b845a788ddf30dceb25c54
|
||||
```
|
||||
|
||||
### 2. Send an `Initialize` request
|
||||
|
||||
The client sends an `initialize` request with protocol version and capabilities:
|
||||
|
||||
```bash
|
||||
session_id="5c6600ef61b845a788ddf30dceb25c54" && \
|
||||
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"id": 1,
|
||||
"method": "initialize",
|
||||
"params": {
|
||||
"protocolVersion": "1.0",
|
||||
"capabilities": {},
|
||||
"clientInfo": {
|
||||
"name": "ragflow-mcp-client",
|
||||
"version": "0.1"
|
||||
}
|
||||
}
|
||||
}' && \
|
||||
```
|
||||
|
||||
#### Transport
|
||||
|
||||
_The server replies with an `initialize` response, including the supported protocol and capabilities:_
|
||||
|
||||
```bash
|
||||
event: message
|
||||
data: {"jsonrpc":"2.0","id":1,"result":{"protocolVersion":"2025-03-26","capabilities":{"experimental":{"headers":{"host":"127.0.0.1:9382","user-agent":"curl/8.7.1","accept":"*/*","api_key":"ragflow-xxxxxxxxxxxx","accept-encoding":"gzip"}},"tools":{"listChanged":false}},"serverInfo":{"name":"ragflow-server","version":"1.9.4"}}}
|
||||
```
|
||||
|
||||
### 3. Acknowledge readiness
|
||||
|
||||
The client confirms readiness with an `initialized` notification:
|
||||
|
||||
```bash
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"method": "notifications/initialized",
|
||||
"params": {}
|
||||
}' && \
|
||||
```
|
||||
|
||||
_The connection is established between the client and the server, and further operations (such as tool listing) may proceed._
|
||||
|
||||
### 4. Tool listing
|
||||
|
||||
```bash
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"id": 3,
|
||||
"method": "tools/list",
|
||||
"params": {}
|
||||
}' && \
|
||||
```
|
||||
|
||||
#### Transport
|
||||
|
||||
```bash
|
||||
event: message
|
||||
data: {"jsonrpc":"2.0","id":3,"result":{"tools":[{"name":"ragflow_retrieval","description":"Retrieve relevant chunks from the RAGFlow retrieve interface based on the question, using the specified dataset_ids and optionally document_ids. Below is the list of all available datasets, including their descriptions and IDs. If you're unsure which datasets are relevant to the question, simply pass all dataset IDs to the function.","inputSchema":{"type":"object","properties":{"dataset_ids":{"type":"array","items":{"type":"string"}},"document_ids":{"type":"array","items":{"type":"string"}},"question":{"type":"string"}},"required":["dataset_ids","question"]}}]}}
|
||||
|
||||
```
|
||||
|
||||
### 5. Tool calling
|
||||
|
||||
```bash
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"id": 4,
|
||||
"method": "tools/call",
|
||||
"params": {
|
||||
"name": "ragflow_retrieval",
|
||||
"arguments": {
|
||||
"question": "How to install neovim?",
|
||||
"dataset_ids": ["DATASET_ID_HERE"],
|
||||
"document_ids": []
|
||||
}
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
#### Transport
|
||||
|
||||
```bash
|
||||
event: message
|
||||
data: {"jsonrpc":"2.0","id":4,"result":{...}}
|
||||
|
||||
```
|
||||
|
||||
### A complete curl example
|
||||
|
||||
```bash
|
||||
session_id="YOUR_SESSION_ID" && \
|
||||
|
||||
# Step 1: Initialize request
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"id": 1,
|
||||
"method": "initialize",
|
||||
"params": {
|
||||
"protocolVersion": "1.0",
|
||||
"capabilities": {},
|
||||
"clientInfo": {
|
||||
"name": "ragflow-mcp-client",
|
||||
"version": "0.1"
|
||||
}
|
||||
}
|
||||
}' && \
|
||||
|
||||
sleep 2 && \
|
||||
|
||||
# Step 2: Initialized notification
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"method": "notifications/initialized",
|
||||
"params": {}
|
||||
}' && \
|
||||
|
||||
sleep 2 && \
|
||||
|
||||
# Step 3: Tool listing
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"id": 3,
|
||||
"method": "tools/list",
|
||||
"params": {}
|
||||
}' && \
|
||||
|
||||
sleep 2 && \
|
||||
|
||||
# Step 4: Tool call
|
||||
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||
-H "api_key: YOUR_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"jsonrpc": "2.0",
|
||||
"id": 4,
|
||||
"method": "tools/call",
|
||||
"params": {
|
||||
"name": "ragflow_retrieval",
|
||||
"arguments": {
|
||||
"question": "How to install neovim?",
|
||||
"dataset_ids": ["DATASET_ID_HERE"],
|
||||
"document_ids": []
|
||||
}
|
||||
}
|
||||
}'
|
||||
|
||||
```
|
||||
12
docs/develop/mcp/mcp_tools.md
Normal file
12
docs/develop/mcp/mcp_tools.md
Normal file
@@ -0,0 +1,12 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /mcp_tools
|
||||
---
|
||||
|
||||
# RAGFlow MCP tools
|
||||
|
||||
The MCP server currently offers a specialized tool to assist users in searching for relevant information powered by RAGFlow DeepDoc technology:
|
||||
|
||||
- **retrieve**: Fetches relevant chunks from specified `dataset_ids` and optional `document_ids` using the RAGFlow retrieve interface, based on a given question. Details of all available datasets, namely, `id` and `description`, are provided within the tool description for each individual dataset.
|
||||
|
||||
For more information, see our Python implementation of the [MCP server](https://github.com/infiniflow/ragflow/blob/main/mcp/server/server.py).
|
||||
34
docs/develop/switch_doc_engine.md
Normal file
34
docs/develop/switch_doc_engine.md
Normal file
@@ -0,0 +1,34 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /switch_doc_engine
|
||||
---
|
||||
|
||||
# Switch document engine
|
||||
|
||||
Switch your doc engine from Elasticsearch to Infinity.
|
||||
|
||||
---
|
||||
|
||||
RAGFlow uses Elasticsearch by default for storing full text and vectors. To switch to [Infinity](https://github.com/infiniflow/infinity/), follow these steps:
|
||||
|
||||
:::caution WARNING
|
||||
Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||
:::
|
||||
|
||||
1. Stop all running containers:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker/docker-compose.yml down -v
|
||||
```
|
||||
|
||||
:::caution WARNING
|
||||
`-v` will delete the docker container volumes, and the existing data will be cleared.
|
||||
:::
|
||||
|
||||
2. Set `DOC_ENGINE` in **docker/.env** to `infinity`.
|
||||
|
||||
3. Start the containers:
|
||||
|
||||
```bash
|
||||
$ docker compose -f docker-compose.yml up -d
|
||||
```
|
||||
8
docs/guides/_category_.json
Normal file
8
docs/guides/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Guides",
|
||||
"position": 3,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides for RAGFlow users and developers."
|
||||
}
|
||||
}
|
||||
8
docs/guides/agent/_category_.json
Normal file
8
docs/guides/agent/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Agents",
|
||||
"position": 3,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "RAGFlow v0.8.0 introduces an agent mechanism, featuring a no-code workflow editor on the front end and a comprehensive graph-based task orchestration framework on the backend."
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Agent Components",
|
||||
"position": 20,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "A complete reference for RAGFlow's agent components."
|
||||
}
|
||||
}
|
||||
233
docs/guides/agent/agent_component_reference/agent.mdx
Normal file
233
docs/guides/agent/agent_component_reference/agent.mdx
Normal file
@@ -0,0 +1,233 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /agent_component
|
||||
---
|
||||
|
||||
# Agent component
|
||||
|
||||
The component equipped with reasoning, tool usage, and multi-agent collaboration capabilities.
|
||||
|
||||
---
|
||||
|
||||
An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.5 onwards, an **Agent** component is able to work independently and with the following capabilities:
|
||||
|
||||
- Autonomous reasoning with reflection and adjustment based on environmental feedback.
|
||||
- Use of tools or subagents to complete tasks.
|
||||
|
||||
## Scenarios
|
||||
|
||||
An **Agent** component is essential when you need the LLM to assist with summarizing, translating, or controlling various tasks.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure you have a chat model properly configured:
|
||||
|
||||

|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on an **Agent** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||
|
||||
### 2. Select your model
|
||||
|
||||
Click **Model**, and select a chat model from the dropdown menu.
|
||||
|
||||
:::tip NOTE
|
||||
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||
:::
|
||||
|
||||
### 3. Update system prompt (Optional)
|
||||
|
||||
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||
|
||||
|
||||
### 4. Update user prompt
|
||||
|
||||
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||
|
||||
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||
|
||||
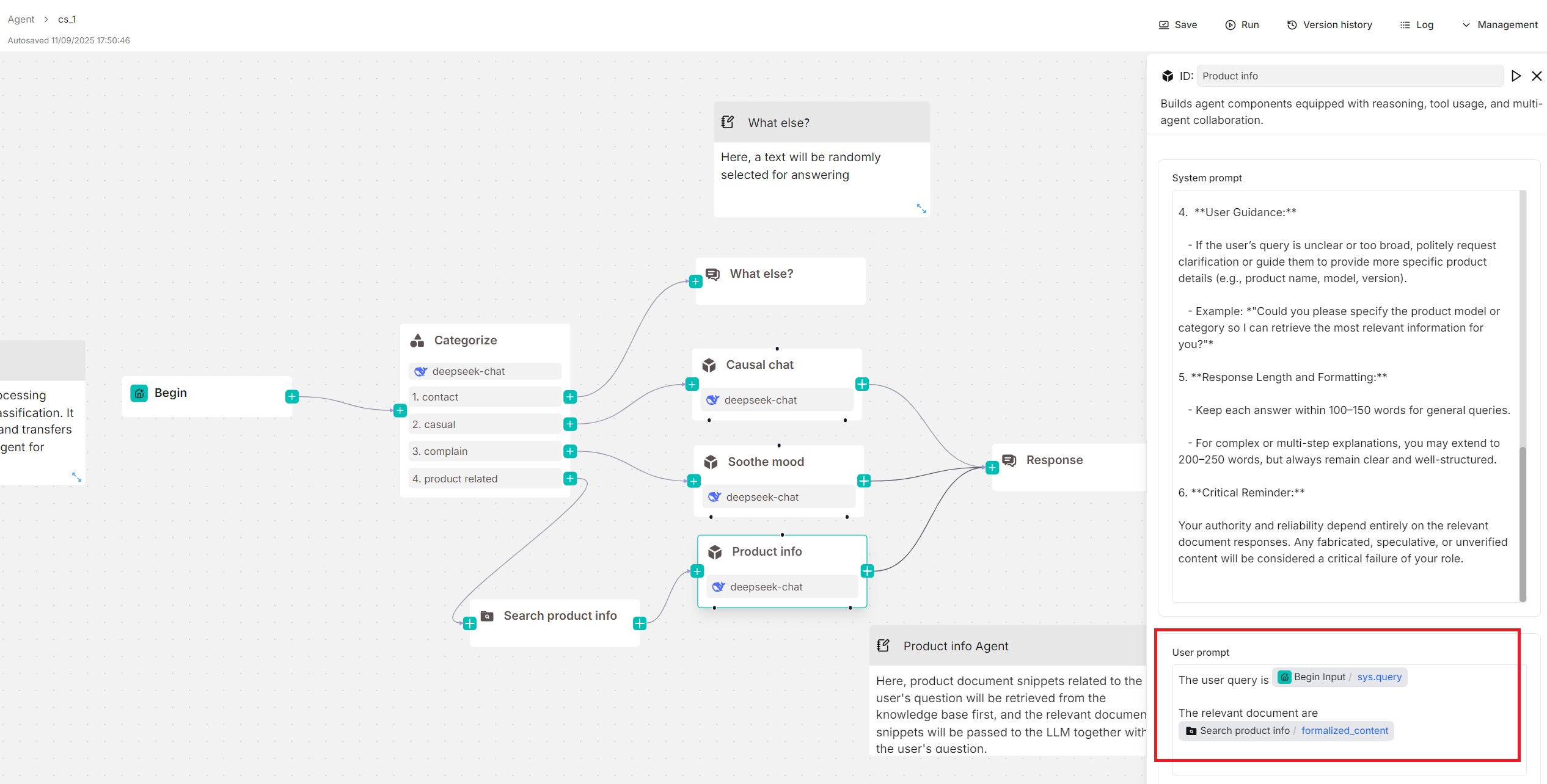
|
||||
|
||||
### 5. Skip Tools and Agent
|
||||
|
||||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||
|
||||
### 6. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
## Connect to an MCP server as a client
|
||||
|
||||
:::danger IMPORTANT
|
||||
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||
:::
|
||||
|
||||
### 1. Navigate to the MCP configuration page
|
||||
|
||||

|
||||
|
||||
### 2. Configure your Tavily MCP server
|
||||
|
||||
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||
|
||||
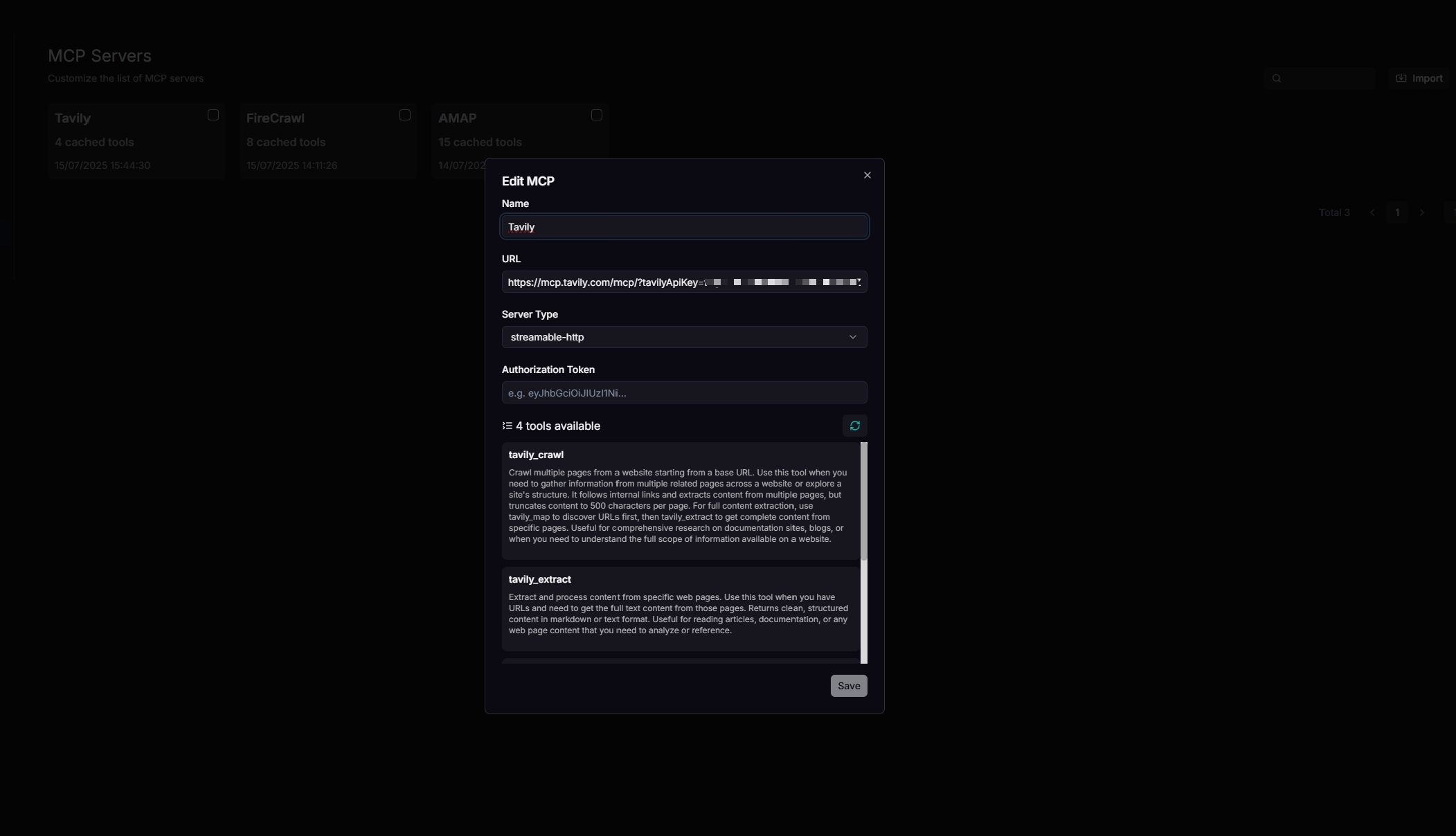
|
||||
|
||||
### 3. Navigate to your Agent's editing page
|
||||
|
||||
### 4. Connect to your MCP server
|
||||
|
||||
1. Click **+ Add tools**:
|
||||
|
||||
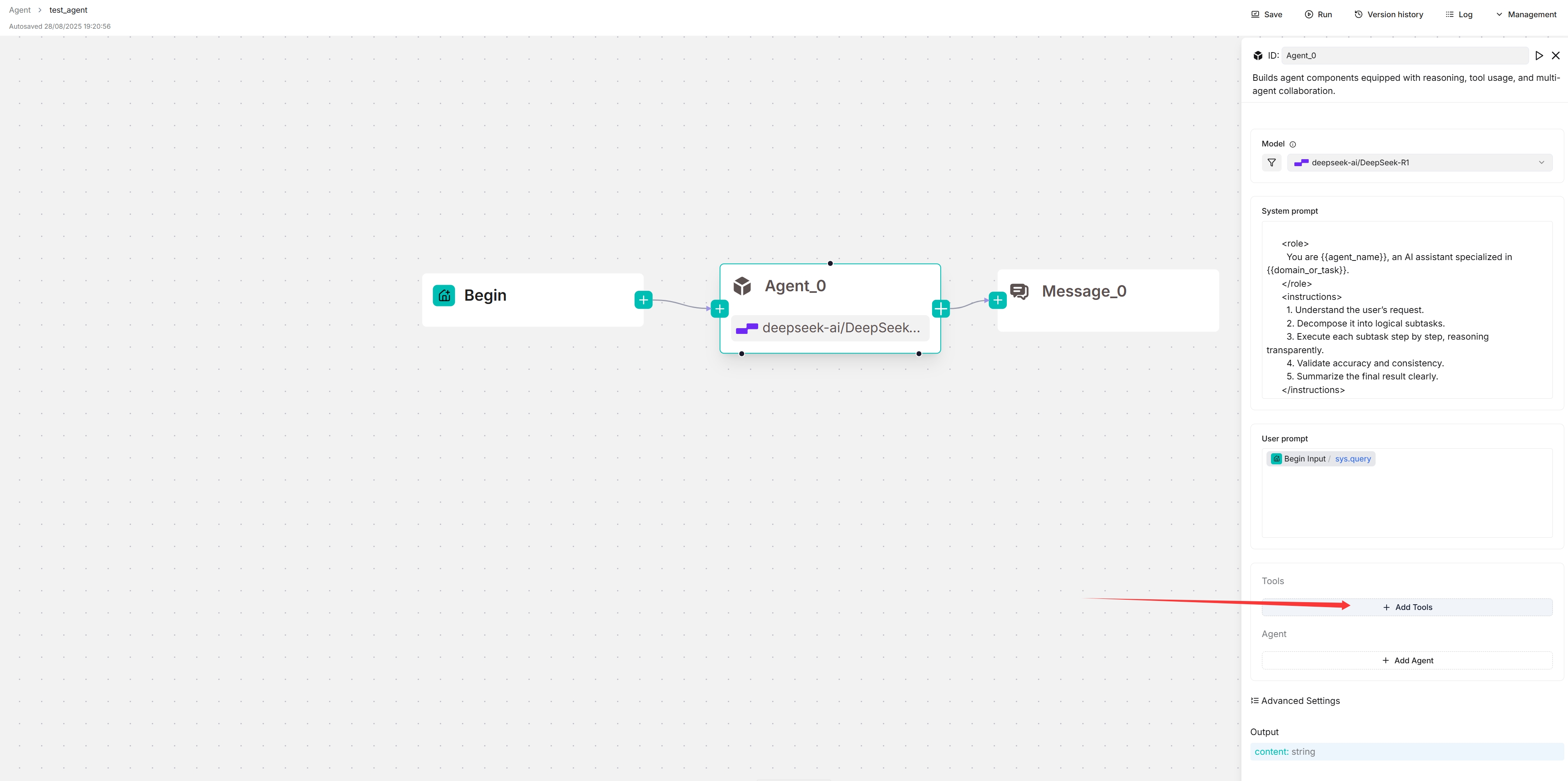
|
||||
|
||||
2. Click **MCP** to show the available MCP servers.
|
||||
|
||||
3. Select your MCP server:
|
||||
|
||||
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
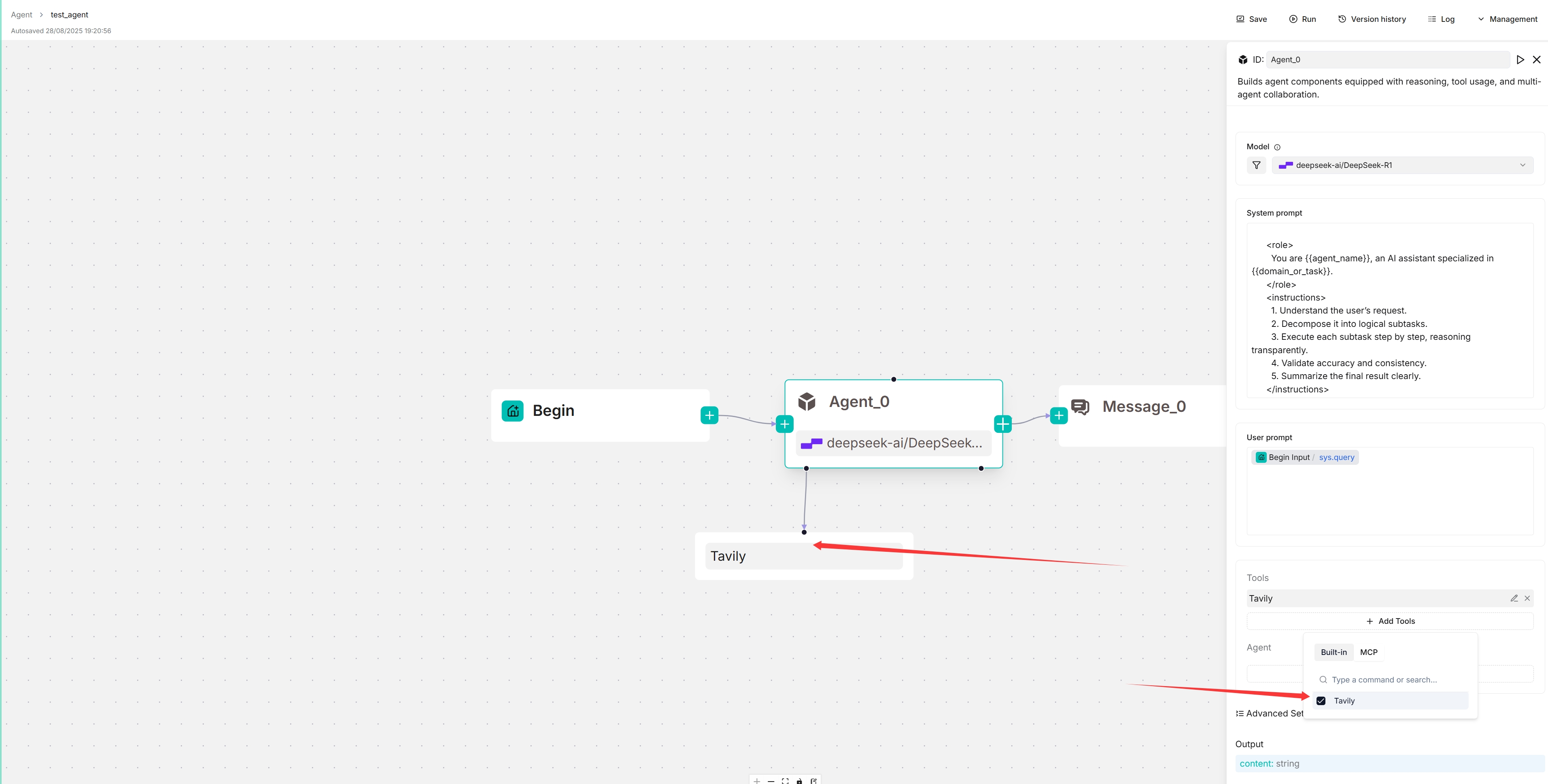
|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||
|
||||
### 6. View the availabe tools of your MCP server
|
||||
|
||||
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||
|
||||
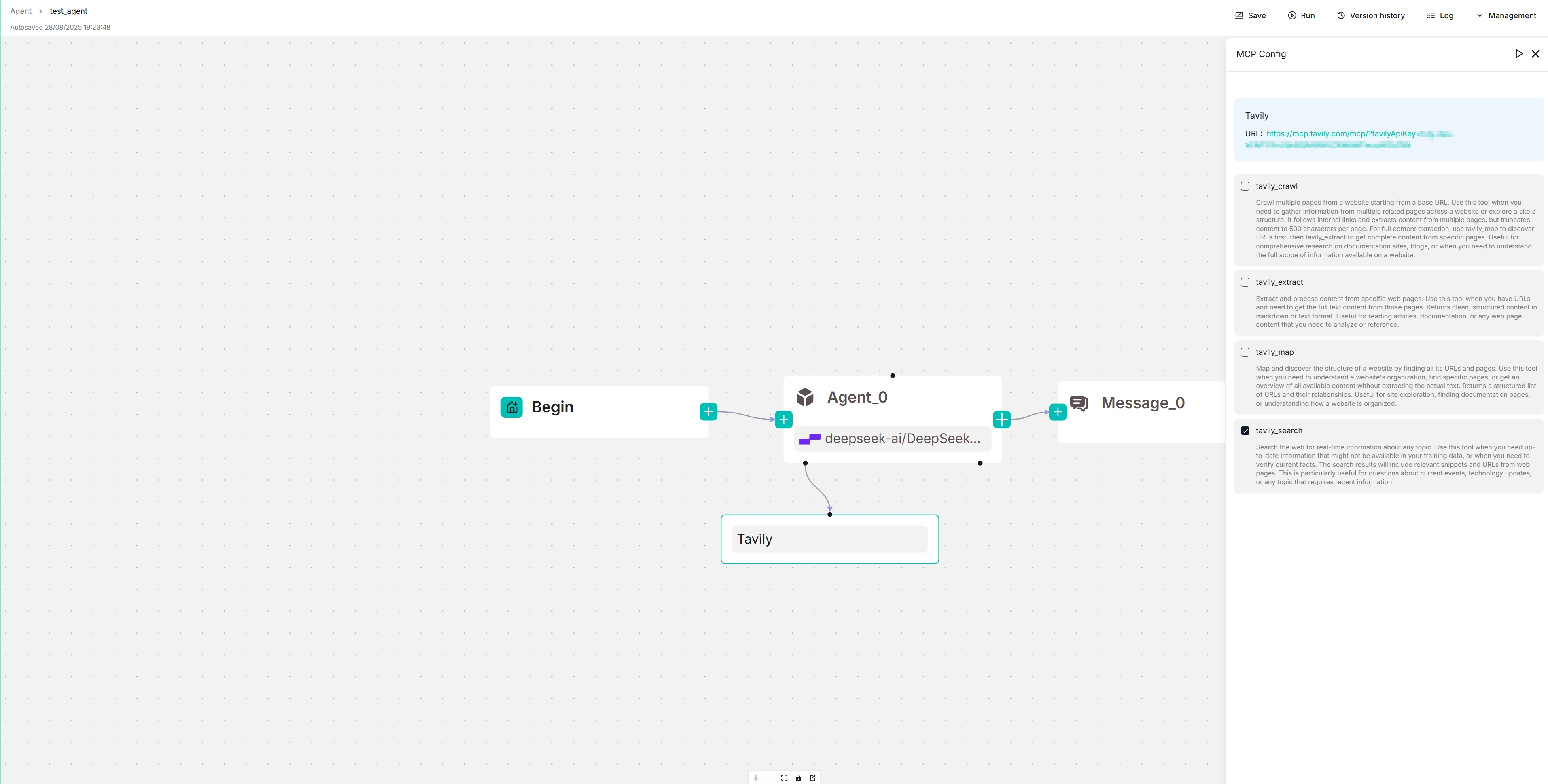
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
### Model
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
||||
:::
|
||||
|
||||
### System prompt
|
||||
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering. However, please be aware that the system prompt is often used in conjunction with keys (variables), which serve as various data inputs for the LLM.
|
||||
|
||||
An **Agent** component relies on keys (variables) to specify its data inputs. Its immediate upstream component is *not* necessarily its data input, and the arrows in the workflow indicate *only* the processing sequence. Keys in a **Agent** component are used in conjunction with the system prompt to specify data inputs for the LLM. Use a forward slash `/` or the **(x)** button to show the keys to use.
|
||||
|
||||
#### Advanced usage
|
||||
|
||||
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||
|
||||
- `task_analysis` prompt block
|
||||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||
- Reference design: [analyze_task_system.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_system.md) and [analyze_task_user.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_user.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `agent_prompt`: The system prompt.
|
||||
- `task`: The user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent when delegating tasks.
|
||||
- `tool_desc`: A description of the tools and sub_Agents that can be called.
|
||||
- `context`: The operational context, which stores interactions between the Agent, tools, and sub-agents; initially empty.
|
||||
- `plan_generation` prompt block
|
||||
- This block creates a plan for the **Agent** component to execute next, based on the task analysis results.
|
||||
- Reference design: [next_step.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/next_step.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `task_analysis`: The analysis result of the current task.
|
||||
- `desc`: A description of the tools or sub-Agents currently being called.
|
||||
- `today`: The date of today.
|
||||
- `reflection` prompt block
|
||||
- This block enables the **Agent** component to reflect, improving task accuracy and efficiency.
|
||||
- Reference design: [reflect.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/reflect.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `goal`: The goal of the current task. It is the user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent.
|
||||
- `tool_calls`: The history of tool calling
|
||||
- `call.name`:The name of the tool called.
|
||||
- `call.result`:The result of tool calling
|
||||
- `citation_guidelines` prompt block
|
||||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||
|
||||
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### User prompt
|
||||
|
||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||
|
||||
|
||||
### Tools
|
||||
|
||||
You can use an **Agent** component as a collaborator that reasons and reflects with the aid of other tools; for instance, **Retrieval** can serve as one such tool for an **Agent**.
|
||||
|
||||
### Agent
|
||||
|
||||
You use an **Agent** component as a collaborator that reasons and reflects with the aid of subagents or other tools, forming a multi-agent system.
|
||||
|
||||
### Message window size
|
||||
|
||||
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||||
|
||||
:::tip IMPORTANT
|
||||
This feature is used for multi-turn dialogue *only*.
|
||||
:::
|
||||
|
||||
### Max retries
|
||||
|
||||
Defines the maximum number of attempts the agent will make to retry a failed task or operation before stopping or reporting failure.
|
||||
|
||||
### Delay after error
|
||||
|
||||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||
|
||||
### Max reflection rounds
|
||||
|
||||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||
|
||||
:::tip NOTE
|
||||
Increasing this value will significantly extend your agent's response time.
|
||||
:::
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Agent** component, which can be referenced by other components in the workflow.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Why does it take so long for my Agent to respond?
|
||||
|
||||
See [here](../best_practices/accelerate_agent_question_answering.md) for details.
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
sidebar_position: 5
|
||||
slug: /await_response
|
||||
---
|
||||
|
||||
# Await response component
|
||||
|
||||
A component that halts the workflow and awaits user input.
|
||||
|
||||
---
|
||||
|
||||
An **Await response** component halts the workflow, initiating a conversation and collecting key information via predefined forms.
|
||||
|
||||
## Scenarios
|
||||
|
||||
An **Await response** component is essential where you need to display the agent's responses or require user-computer interaction.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Guiding question
|
||||
|
||||
Whether to show the message defined in the **Message** field.
|
||||
|
||||
### Message
|
||||
|
||||
The static message to send out.
|
||||
|
||||
Click **+ Add message** to add message options. When multiple messages are supplied, the **Message** component randomly selects one to send.
|
||||
|
||||
### Input
|
||||
|
||||
You can define global variables within the **Await response** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+** to add a global variable, each with the following attributes:
|
||||
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
The type of the variable:
|
||||
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||
- **Dropdown options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set _at least_ one option for the dropdown menu.
|
||||
- **file upload**: Requires the user to upload one or multiple files.
|
||||
- **Number**: Accepts a number as input.
|
||||
- **Boolean**: Requires the user to toggle between on and off.
|
||||
- **Key**: _Required_
|
||||
The unique variable name.
|
||||
- **Optional**: A toggle indicating whether the variable is optional.
|
||||
|
||||
:::tip NOTE
|
||||
To pass in parameters from a client, call:
|
||||
|
||||
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
||||
:::
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
||||
:::
|
||||
80
docs/guides/agent/agent_component_reference/begin.mdx
Normal file
80
docs/guides/agent/agent_component_reference/begin.mdx
Normal file
@@ -0,0 +1,80 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /begin_component
|
||||
---
|
||||
|
||||
# Begin component
|
||||
|
||||
The starting component in a workflow.
|
||||
|
||||
---
|
||||
|
||||
The **Begin** component sets an opening greeting or accepts inputs from the user. It is automatically populated onto the canvas when you create an agent, whether from a template or from scratch (from a blank template). There should be only one **Begin** component in the workflow.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Begin** component is essential in all cases. Every agent includes a **Begin** component, which cannot be deleted.
|
||||
|
||||
## Configurations
|
||||
|
||||
Click the component to display its **Configuration** window. Here, you can set an opening greeting and the input parameters (global variables) for the agent.
|
||||
|
||||
### Mode
|
||||
|
||||
Mode defines how the workflow is triggered.
|
||||
|
||||
- Conversational: The agent is triggered from a conversation.
|
||||
- Task: The agent starts without a conversation.
|
||||
|
||||
### Opening greeting
|
||||
|
||||
**Conversational mode only.**
|
||||
|
||||
An agent in conversational mode begins with an opening greeting. It is the agent's first message to the user in conversational mode, which can be a welcoming remark or an instruction to guide the user forward.
|
||||
|
||||
### Global variables
|
||||
|
||||
You can define global variables within the **Begin** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+ Add variable** to add a global variable, each with the following attributes:
|
||||
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
The type of the variable:
|
||||
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||
- **Dropdown options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set _at least_ one option for the dropdown menu.
|
||||
- **file upload**: Requires the user to upload one or multiple files.
|
||||
- **Number**: Accepts a number as input.
|
||||
- **Boolean**: Requires the user to toggle between on and off.
|
||||
- **Key**: _Required_
|
||||
The unique variable name.
|
||||
- **Optional**: A toggle indicating whether the variable is optional.
|
||||
|
||||
:::tip NOTE
|
||||
To pass in parameters from a client, call:
|
||||
|
||||
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
||||
:::
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
||||
:::
|
||||
|
||||
:::note
|
||||
You can tune document parsing and embedding efficiency by setting the environment variables `DOC_BULK_SIZE` and `EMBEDDING_BATCH_SIZE`.
|
||||
:::
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Is the uploaded file in a dataset?
|
||||
|
||||
No. Files uploaded to an agent as input are not stored in a dataset and hence will not be processed using RAGFlow's built-in OCR, DLR or TSR models, or chunked using RAGFlow's built-in chunking methods.
|
||||
|
||||
### File size limit for an uploaded file
|
||||
|
||||
There is no _specific_ file size limit for a file uploaded to an agent. However, note that model providers typically have a default or explicit maximum token setting, which can range from 8196 to 128k: The plain text part of the uploaded file will be passed in as the key value, but if the file's token count exceeds this limit, the string will be truncated and incomplete.
|
||||
|
||||
:::tip NOTE
|
||||
The variables `MAX_CONTENT_LENGTH` in `/docker/.env` and `client_max_body_size` in `/docker/nginx/nginx.conf` set the file size limit for each upload to a dataset or **File Management**. These settings DO NOT apply in this scenario.
|
||||
:::
|
||||
109
docs/guides/agent/agent_component_reference/categorize.mdx
Normal file
109
docs/guides/agent/agent_component_reference/categorize.mdx
Normal file
@@ -0,0 +1,109 @@
|
||||
---
|
||||
sidebar_position: 8
|
||||
slug: /categorize_component
|
||||
---
|
||||
|
||||
# Categorize component
|
||||
|
||||
A component that classifies user inputs and applies strategies accordingly.
|
||||
|
||||
---
|
||||
|
||||
A **Categorize** component is usually the downstream of the **Interact** component.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Categorize** component is essential when you need the LLM to help you identify user intentions and apply appropriate processing strategies.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Query variables
|
||||
|
||||
*Mandatory*
|
||||
|
||||
Select the source for categorization.
|
||||
|
||||
The **Categorize** component relies on query variables to specify its data inputs (queries). All global variables defined before the **Categorize** component are available in the dropdown list.
|
||||
|
||||
|
||||
### Input
|
||||
|
||||
The **Categorize** component relies on input variables to specify its data inputs (queries). Click **+ Add variable** in the **Input** section to add the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||
|
||||
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||
- A component ID under **Component Output**, or
|
||||
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||
|
||||
### Model
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
||||
:::
|
||||
|
||||
### Message window size
|
||||
|
||||
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||||
|
||||
Defaults to 1.
|
||||
|
||||
:::tip IMPORTANT
|
||||
This feature is used for multi-turn dialogue *only*. If your **Categorize** component is not part of a multi-turn dialogue (i.e., it is not in a loop), leave this field as-is.
|
||||
:::
|
||||
|
||||
### Category name
|
||||
|
||||
A **Categorize** component must have at least two categories. This field sets the name of the category. Click **+ Add Item** to include the intended categories.
|
||||
|
||||
:::tip NOTE
|
||||
You will notice that the category name is auto-populated. No worries. Each category is assigned a random name upon creation. Feel free to change it to a name that is understandable to the LLM.
|
||||
:::
|
||||
|
||||
#### Description
|
||||
|
||||
Description of this category.
|
||||
|
||||
You can input criteria, situation, or information that may help the LLM determine which inputs belong in this category.
|
||||
|
||||
#### Examples
|
||||
|
||||
Additional examples that may help the LLM determine which inputs belong in this category.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Examples are more helpful than the description if you want the LLM to classify particular cases into this category.
|
||||
:::
|
||||
|
||||
Once a new category is added, navigate to the **Categorize** component on the canvas, find the **+** button next to the case, and click it to specify the downstream component(s).
|
||||
|
||||
|
||||
#### Output
|
||||
|
||||
The global variable name for the output of the component, which can be referenced by other components in the workflow. Defaults to `category_name`.
|
||||
40
docs/guides/agent/agent_component_reference/chunker_title.md
Normal file
40
docs/guides/agent/agent_component_reference/chunker_title.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
sidebar_position: 31
|
||||
slug: /chunker_title_component
|
||||
---
|
||||
|
||||
# Title chunker component
|
||||
|
||||
A component that splits texts into chunks by heading level.
|
||||
|
||||
---
|
||||
|
||||
A **Token chunker** component is a text splitter that uses specified heading level as delimiter to define chunk boundaries and create chunks.
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Title chunker** component is optional, usually placed immediately after **Parser**.
|
||||
|
||||
:::caution WARNING
|
||||
Placing a **Title chunker** after a **Token chunker** is invalid and will cause an error. Please note that this restriction is not currently system-enforced and requires your attention.
|
||||
:::
|
||||
|
||||
## Configurations
|
||||
|
||||
### Hierarchy
|
||||
|
||||
Specifies the heading level to define chunk boundaries:
|
||||
|
||||
- H1
|
||||
- H2
|
||||
- H3 (Default)
|
||||
- H4
|
||||
|
||||
Click **+ Add** to add heading levels here or update the corresponding **Regular Expressions** fields for custom heading patterns.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Title chunker** component, which can be referenced by subsequent components in the ingestion pipeline.
|
||||
|
||||
- Default: `chunks`
|
||||
- Type: `Array<Object>`
|
||||
43
docs/guides/agent/agent_component_reference/chunker_token.md
Normal file
43
docs/guides/agent/agent_component_reference/chunker_token.md
Normal file
@@ -0,0 +1,43 @@
|
||||
---
|
||||
sidebar_position: 32
|
||||
slug: /chunker_token_component
|
||||
---
|
||||
|
||||
# Token chunker component
|
||||
|
||||
A component that splits texts into chunks, respecting a maximum token limit and using delimiters to find optimal breakpoints.
|
||||
|
||||
---
|
||||
|
||||
A **Token chunker** component is a text splitter that creates chunks by respecting a recommended maximum token length, using delimiters to ensure logical chunk breakpoints. It splits long texts into appropriately-sized, semantically related chunks.
|
||||
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Token chunker** component is optional, usually placed immediately after **Parser** or **Title chunker**.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Recommended chunk size
|
||||
|
||||
The recommended maximum token limit for each created chunk. The **Token chunker** component creates chunks at specified delimiters. If this token limit is reached before a delimiter, a chunk is created at that point.
|
||||
|
||||
### Overlapped percent (%)
|
||||
|
||||
This defines the overlap percentage between chunks. An appropriate degree of overlap ensures semantic coherence without creating excessive, redundant tokens for the LLM.
|
||||
|
||||
- Default: 0
|
||||
- Maximum: 30%
|
||||
|
||||
|
||||
### Delimiters
|
||||
|
||||
Defaults to `\n`. Click the right-hand **Recycle bin** button to remove it, or click **+ Add** to add a delimiter.
|
||||
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Token chunker** component, which can be referenced by subsequent components in the ingestion pipeline.
|
||||
|
||||
- Default: `chunks`
|
||||
- Type: `Array<Object>`
|
||||
205
docs/guides/agent/agent_component_reference/code.mdx
Normal file
205
docs/guides/agent/agent_component_reference/code.mdx
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
sidebar_position: 13
|
||||
slug: /code_component
|
||||
---
|
||||
|
||||
# Code component
|
||||
|
||||
A component that enables users to integrate Python or JavaScript codes into their Agent for dynamic data processing.
|
||||
|
||||
---
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Code** component is essential when you need to integrate complex code logic (Python or JavaScript) into your Agent for dynamic data processing.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
### 1. Ensure gVisor is properly installed
|
||||
|
||||
We use gVisor to isolate code execution from the host system. Please follow [the official installation guide](https://gvisor.dev/docs/user_guide/install/) to install gVisor, ensuring your operating system is compatible before proceeding.
|
||||
|
||||
### 2. Ensure Sandbox is properly installed
|
||||
|
||||
RAGFlow Sandbox is a secure, pluggable code execution backend. It serves as the code executor for the **Code** component. Please follow the [instructions here](https://github.com/infiniflow/ragflow/tree/main/sandbox) to install RAGFlow Sandbox.
|
||||
|
||||
:::tip NOTE
|
||||
If your RAGFlow Sandbox is not working, please be sure to consult the [Troubleshooting](#troubleshooting) section in this document. We assure you that it addresses 99.99% of the issues!
|
||||
:::
|
||||
|
||||
### 3. (Optional) Install necessary dependencies
|
||||
|
||||
If you need to import your own Python or JavaScript packages into Sandbox, please follow the commands provided in the [How to import my own Python or JavaScript packages into Sandbox?](#how-to-import-my-own-python-or-javascript-packages-into-sandbox) section to install the additional dependencies.
|
||||
|
||||
### 4. Enable Sandbox-specific settings in RAGFlow
|
||||
|
||||
Ensure all Sandbox-specific settings are enabled in **ragflow/docker/.env**.
|
||||
|
||||
### 5. Restart the service after making changes
|
||||
|
||||
Any changes to the configuration or environment *require* a full service restart to take effect.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Input
|
||||
|
||||
You can specify multiple input sources for the **Code** component. Click **+ Add variable** in the **Input variables** section to include the desired input variables.
|
||||
|
||||
### Code
|
||||
|
||||
This field allows you to enter and edit your source code.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If your code implementation includes defined variables, whether input or output variables, ensure they are also specified in the corresponding **Input** or **Output** sections.
|
||||
:::
|
||||
|
||||
#### A Python code example
|
||||
|
||||
```Python
|
||||
def main(arg1: str, arg2: str) -> dict:
|
||||
return {
|
||||
"result": arg1 + arg2,
|
||||
}
|
||||
```
|
||||
|
||||
#### A JavaScript code example
|
||||
|
||||
```JavaScript
|
||||
|
||||
const axios = require('axios');
|
||||
async function main(args) {
|
||||
try {
|
||||
const response = await axios.get('https://github.com/infiniflow/ragflow');
|
||||
console.log('Body:', response.data);
|
||||
} catch (error) {
|
||||
console.error('Error:', error.message);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Return values
|
||||
|
||||
You define the output variable(s) of the **Code** component here.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you define output variables here, ensure they are also defined in your code implementation; otherwise, their values will be `null`. The following are two examples:
|
||||
|
||||
|
||||
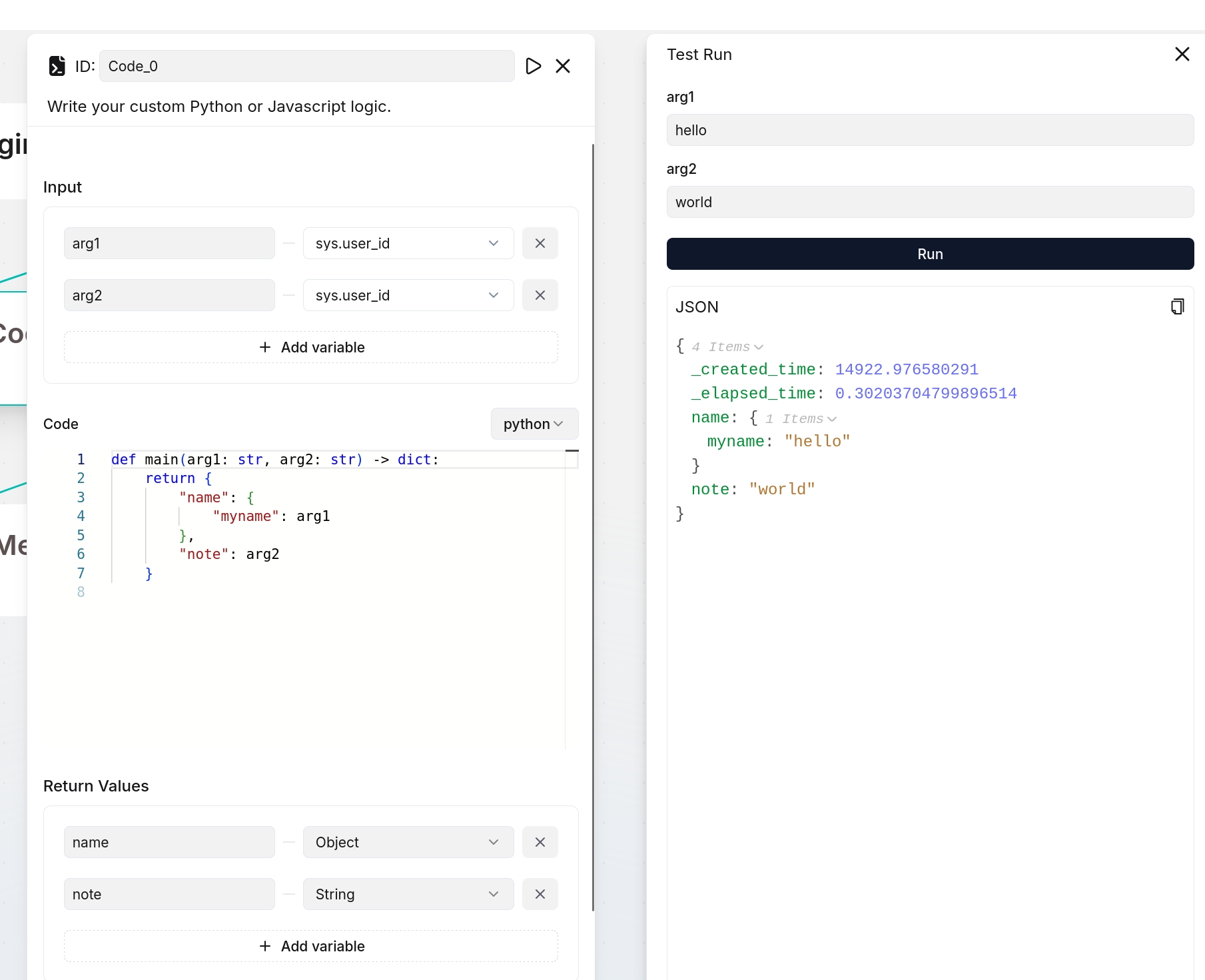
|
||||
|
||||
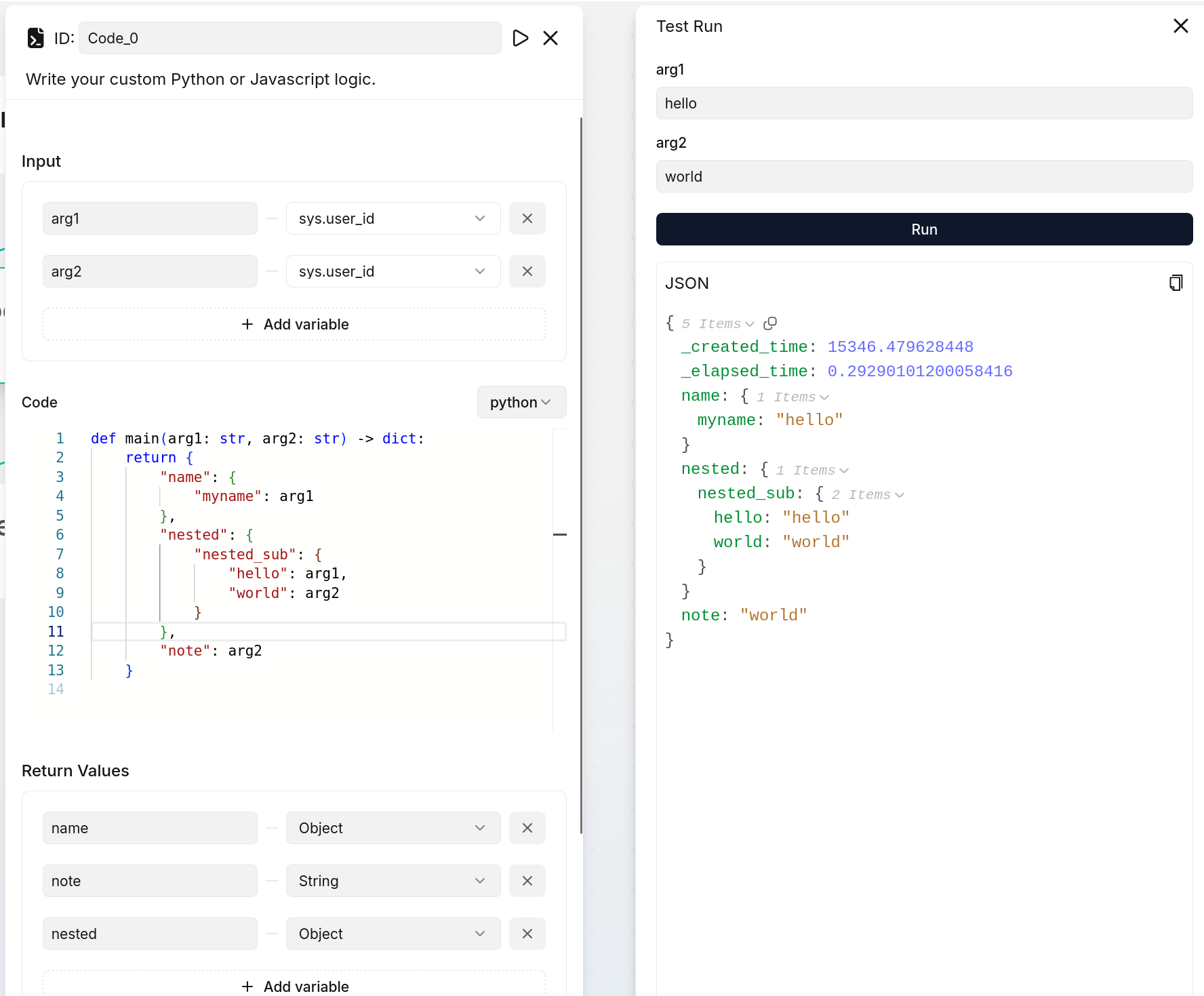
|
||||
:::
|
||||
|
||||
### Output
|
||||
|
||||
The defined output variable(s) will be auto-populated here.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### `HTTPConnectionPool(host='sandbox-executor-manager', port=9385): Read timed out.`
|
||||
|
||||
**Root cause**
|
||||
|
||||
- You did not properly install gVisor and `runsc` was not recognized as a valid Docker runtime.
|
||||
- You did not pull the required base images for the runners and no runner was started.
|
||||
|
||||
**Solution**
|
||||
|
||||
For the gVisor issue:
|
||||
|
||||
1. Install [gVisor](https://gvisor.dev/docs/user_guide/install/).
|
||||
2. Restart Docker.
|
||||
3. Run the following to double check:
|
||||
|
||||
```bash
|
||||
docker run --rm --runtime=runsc hello-world
|
||||
```
|
||||
|
||||
For the base image issue, pull the required base images:
|
||||
|
||||
```bash
|
||||
docker pull infiniflow/sandbox-base-nodejs:latest
|
||||
docker pull infiniflow/sandbox-base-python:latest
|
||||
```
|
||||
|
||||
### `HTTPConnectionPool(host='none', port=9385): Max retries exceeded.`
|
||||
|
||||
**Root cause**
|
||||
|
||||
`sandbox-executor-manager` is not mapped in `/etc/hosts`.
|
||||
|
||||
**Solution**
|
||||
|
||||
Add a new entry to `/etc/hosts`:
|
||||
|
||||
`127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager`
|
||||
|
||||
### `Container pool is busy`
|
||||
|
||||
**Root cause**
|
||||
|
||||
All runners are currently in use, executing tasks.
|
||||
|
||||
**Solution**
|
||||
|
||||
Please try again shortly or increase the pool size in the configuration to improve availability and reduce waiting times.
|
||||
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### How to import my own Python or JavaScript packages into Sandbox?
|
||||
|
||||
To import your Python packages, update **sandbox_base_image/python/requirements.txt** to install the required dependencies. For example, to add the `openpyxl` package, proceed with the following command lines:
|
||||
|
||||
```bash {4,6}
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ pwd # make sure you are in the right directory
|
||||
/home/infiniflow/workspace/ragflow/sandbox
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ echo "openpyxl" >> sandbox_base_image/python/requirements.txt # add the package to the requirements.txt file
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ cat sandbox_base_image/python/requirements.txt # make sure the package is added
|
||||
numpy
|
||||
pandas
|
||||
requests
|
||||
openpyxl # here it is
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_python_0 /bin/bash # entering container to check if the package is installed
|
||||
|
||||
|
||||
# in the container
|
||||
nobody@ffd8a7dd19da:/workspace$ python # launch python shell
|
||||
Python 3.11.13 (main, Aug 12 2025, 22:46:03) [GCC 12.2.0] on linux
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> import openpyxl # import the package to verify installation
|
||||
>>>
|
||||
# That's okay!
|
||||
```
|
||||
|
||||
To import your JavaScript packages, navigate to `sandbox_base_image/nodejs` and use `npm` to install the required packages. For example, to add the `lodash` package, run the following commands:
|
||||
|
||||
```bash
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ pwd
|
||||
/home/infiniflow/workspace/ragflow/sandbox
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ cd sandbox_base_image/nodejs
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ npm install lodash
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ cd ../.. # go back to sandbox root directory
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_nodejs_0 /bin/bash # entering container to check if the package is installed
|
||||
|
||||
# in the container
|
||||
nobody@dd4bbcabef63:/workspace$ npm list lodash # verify via npm list
|
||||
/workspace
|
||||
`-- lodash@4.17.21 extraneous
|
||||
|
||||
nobody@dd4bbcabef63:/workspace$ ls node_modules | grep lodash # or verify via listing node_modules
|
||||
lodash
|
||||
|
||||
# That's okay!
|
||||
```
|
||||
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
@@ -0,0 +1,79 @@
|
||||
---
|
||||
sidebar_position: 25
|
||||
slug: /execute_sql
|
||||
---
|
||||
|
||||
# Execute SQL tool
|
||||
|
||||
A tool that execute SQL queries on a specified relational database.
|
||||
|
||||
---
|
||||
|
||||
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A database instance properly configured and running.
|
||||
- The database must be one of the following types:
|
||||
- MySQL
|
||||
- PostgreSQL
|
||||
- MariaDB
|
||||
- Microsoft SQL Server
|
||||
|
||||
## Examples
|
||||
|
||||
You can pair an **Agent** component with the **Execute SQL** tool, with the **Agent** generating SQL statements and the **Execute SQL** tool handling database connection and query execution. An example of this setup can be found in the **SQL Assistant** Agent template shown below:
|
||||
|
||||
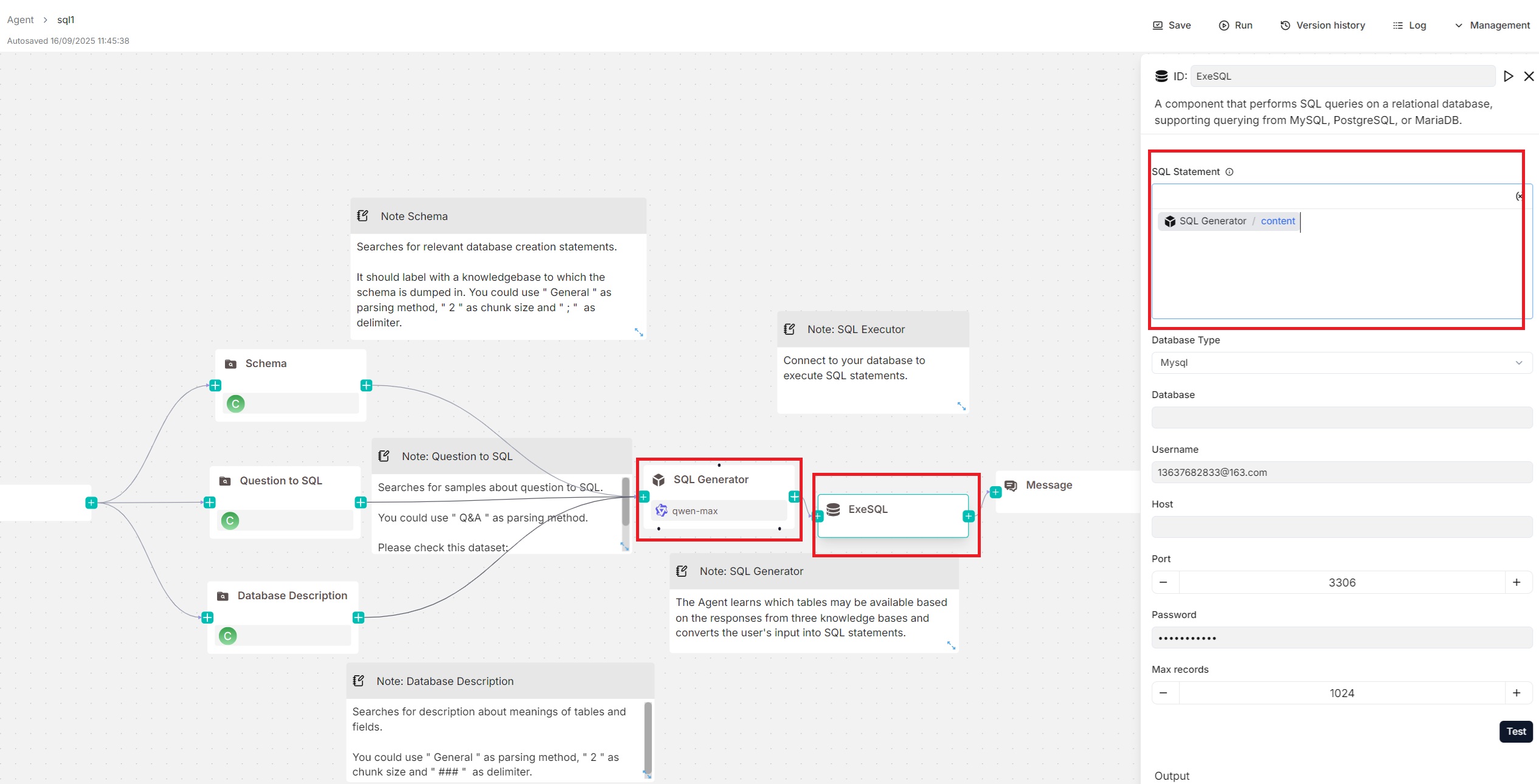
|
||||
|
||||
## Configurations
|
||||
|
||||
### SQL statement
|
||||
|
||||
This text input field allows you to write static SQL queries, such as `SELECT * FROM my_table`, and dynamic SQL queries using variables.
|
||||
|
||||
:::tip NOTE
|
||||
Click **(x)** or type `/` to insert variables.
|
||||
:::
|
||||
|
||||
For dynamic SQL queries, you can include variables in your SQL queries, such as `SELECT * FROM /sys.query`; if an **Agent** component is paired with the **Execute SQL** tool to generate SQL tasks (see the [Examples](#examples) section), you can directly insert that **Agent**'s output, `content`, into this field.
|
||||
|
||||
### Database type
|
||||
|
||||
The supported database type. Currently the following database types are available:
|
||||
|
||||
- MySQL
|
||||
- PostreSQL
|
||||
- MariaDB
|
||||
- Microsoft SQL Server (Myssql)
|
||||
|
||||
### Database
|
||||
|
||||
Appears only when you select **Split** as method.
|
||||
|
||||
### Username
|
||||
|
||||
The username with access privileges to the database.
|
||||
|
||||
### Host
|
||||
|
||||
The IP address of the database server.
|
||||
|
||||
### Port
|
||||
|
||||
The port number on which the database server is listening.
|
||||
|
||||
### Password
|
||||
|
||||
The password for the database user.
|
||||
|
||||
### Max records
|
||||
|
||||
The maximum number of records returned by the SQL query to control response size and improve efficiency. Defaults to `1024`.
|
||||
|
||||
### Output
|
||||
|
||||
The **Execute SQL** tool provides two output variables:
|
||||
|
||||
- `formalized_content`: A string. If you reference this variable in a **Message** component, the returned records are displayed as a table.
|
||||
- `json`: An object array. If you reference this variable in a **Message** component, the returned records will be presented as key-value pairs.
|
||||
29
docs/guides/agent/agent_component_reference/indexer.md
Normal file
29
docs/guides/agent/agent_component_reference/indexer.md
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
sidebar_position: 40
|
||||
slug: /indexer_component
|
||||
---
|
||||
|
||||
# Indexer component
|
||||
|
||||
A component that defines how chunks are indexed.
|
||||
|
||||
---
|
||||
|
||||
An **Indexer** component indexes chunks and configures their storage formats in the document engine.
|
||||
|
||||
## Scenario
|
||||
|
||||
An **Indexer** component is the mandatory ending component for all ingestion pipelines.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Search method
|
||||
|
||||
This setting configures how chunks are stored in the document engine: as full-text, embeddings, or both.
|
||||
|
||||
### Filename embedding weight
|
||||
|
||||
This setting defines the filename's contribution to the final embedding, which is a weighted combination of both the chunk content and the filename. Essentially, a higher value gives the filename more influence in the final *composite* embedding.
|
||||
|
||||
- 0.1: Filename contributes 10% (chunk content 90%)
|
||||
- 0.5 (maximum): Filename contributes 50% (chunk content 90%)
|
||||
65
docs/guides/agent/agent_component_reference/iteration.mdx
Normal file
65
docs/guides/agent/agent_component_reference/iteration.mdx
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /iteration_component
|
||||
---
|
||||
|
||||
# Iteration component
|
||||
|
||||
A component that splits text input into text segments and iterates a predefined workflow for each one.
|
||||
|
||||
---
|
||||
|
||||
An **Interaction** component can divide text input into text segments and apply its built-in component workflow to each segment.
|
||||
|
||||
|
||||
## Scenario
|
||||
|
||||
An **Iteration** component is essential when a workflow loop is required and the loop count is *not* fixed but depends on number of segments created from the output of specific agent components.
|
||||
|
||||
- If, for instance, you plan to feed several paragraphs into an LLM for content generation, each with its own focus, and feeding them to the LLM all at once could create confusion or contradictions, then you can use an **Iteration** component, which encapsulates a **Generate** component, to repeat the content generation process for each paragraph.
|
||||
- Another example: If you wish to use the LLM to translate a lengthy paper into a target language without exceeding its token limit, consider using an **Iteration** component, which encapsulates a **Generate** component, to break the paper into smaller pieces and repeat the translation process for each one.
|
||||
|
||||
## Internal components
|
||||
|
||||
### IterationItem
|
||||
|
||||
Each **Iteration** component includes an internal **IterationItem** component. The **IterationItem** component serves as both the starting point and input node of the workflow within the **Iteration** component. It manages the loop of the workflow for all text segments created from the input.
|
||||
|
||||
:::tip NOTE
|
||||
The **IterationItem** component is visible *only* to the components encapsulated by the current **Iteration** components.
|
||||
:::
|
||||
|
||||
### Build an internal workflow
|
||||
|
||||
You are allowed to pull other components into the **Iteration** component to build an internal workflow, and these "added internal components" are no longer visible to components outside of the current **Iteration** component.
|
||||
|
||||
:::danger IMPORTANT
|
||||
To reference the created text segments from an added internal component, simply add a **Reference** variable that equals **IterationItem** within the **Input** section of that internal component. There is no need to reference the corresponding external component, as the **IterationItem** component manages the loop of the workflow for all created text segments.
|
||||
:::
|
||||
|
||||
:::tip NOTE
|
||||
An added internal component can reference an external component when necessary.
|
||||
:::
|
||||
|
||||
## Configurations
|
||||
|
||||
### Input
|
||||
|
||||
The **Iteration** component uses input variables to specify its data inputs, namely the texts to be segmented. You are allowed to specify multiple input sources for the **Iteration** component. Click **+ Add variable** in the **Input** section to include the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||
|
||||
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||
- A component ID under **Component Output**, or
|
||||
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||
|
||||
### Delimiter
|
||||
|
||||
The delimiter to use to split the text input into segments:
|
||||
|
||||
- Comma (Default)
|
||||
- Line break
|
||||
- Tab
|
||||
- Underline
|
||||
- Forward slash
|
||||
- Dash
|
||||
- Semicolon
|
||||
21
docs/guides/agent/agent_component_reference/message.mdx
Normal file
21
docs/guides/agent/agent_component_reference/message.mdx
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /message_component
|
||||
---
|
||||
|
||||
# Message component
|
||||
|
||||
A component that sends out a static or dynamic message.
|
||||
|
||||
---
|
||||
|
||||
As the final component of the workflow, a Message component returns the workflow’s ultimate data output accompanied by predefined message content. The system selects one message at random if multiple messages are provided.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Messages
|
||||
|
||||
The message to send out. Click `(x)` or type `/` to quickly insert variables.
|
||||
|
||||
Click **+ Add message** to add message options. When multiple messages are supplied, the **Message** component randomly selects one to send.
|
||||
|
||||
17
docs/guides/agent/agent_component_reference/parser.md
Normal file
17
docs/guides/agent/agent_component_reference/parser.md
Normal file
@@ -0,0 +1,17 @@
|
||||
---
|
||||
sidebar_position: 30
|
||||
slug: /parser_component
|
||||
---
|
||||
|
||||
# Parser component
|
||||
|
||||
A component that sets the parsing rules for your dataset.
|
||||
|
||||
---
|
||||
|
||||
A **Parser** component defines how various file types should be parsed, including parsing methods for PDFs , fields to parse for Emails, and OCR methods for images.
|
||||
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Parser** component is auto-populated on the ingestion pipeline canvas and required in all ingestion pipeline workflows.
|
||||
145
docs/guides/agent/agent_component_reference/retrieval.mdx
Normal file
145
docs/guides/agent/agent_component_reference/retrieval.mdx
Normal file
@@ -0,0 +1,145 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /retrieval_component
|
||||
---
|
||||
|
||||
# Retrieval component
|
||||
|
||||
A component that retrieves information from specified datasets.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Retrieval** component is essential in most RAG scenarios, where information is extracted from designated datasets before being sent to the LLM for content generation. A **Retrieval** component can operate either as a standalone workflow module or as a tool for an **Agent** component. In the latter role, the **Agent** component has autonomous control over when to invoke it for query and retrieval.
|
||||
|
||||
The following screenshot shows a reference design using the **Retrieval** component, where the component serves as a tool for an **Agent** component. You can find it from the **Report Agent Using Knowledge Base** Agent template.
|
||||
|
||||
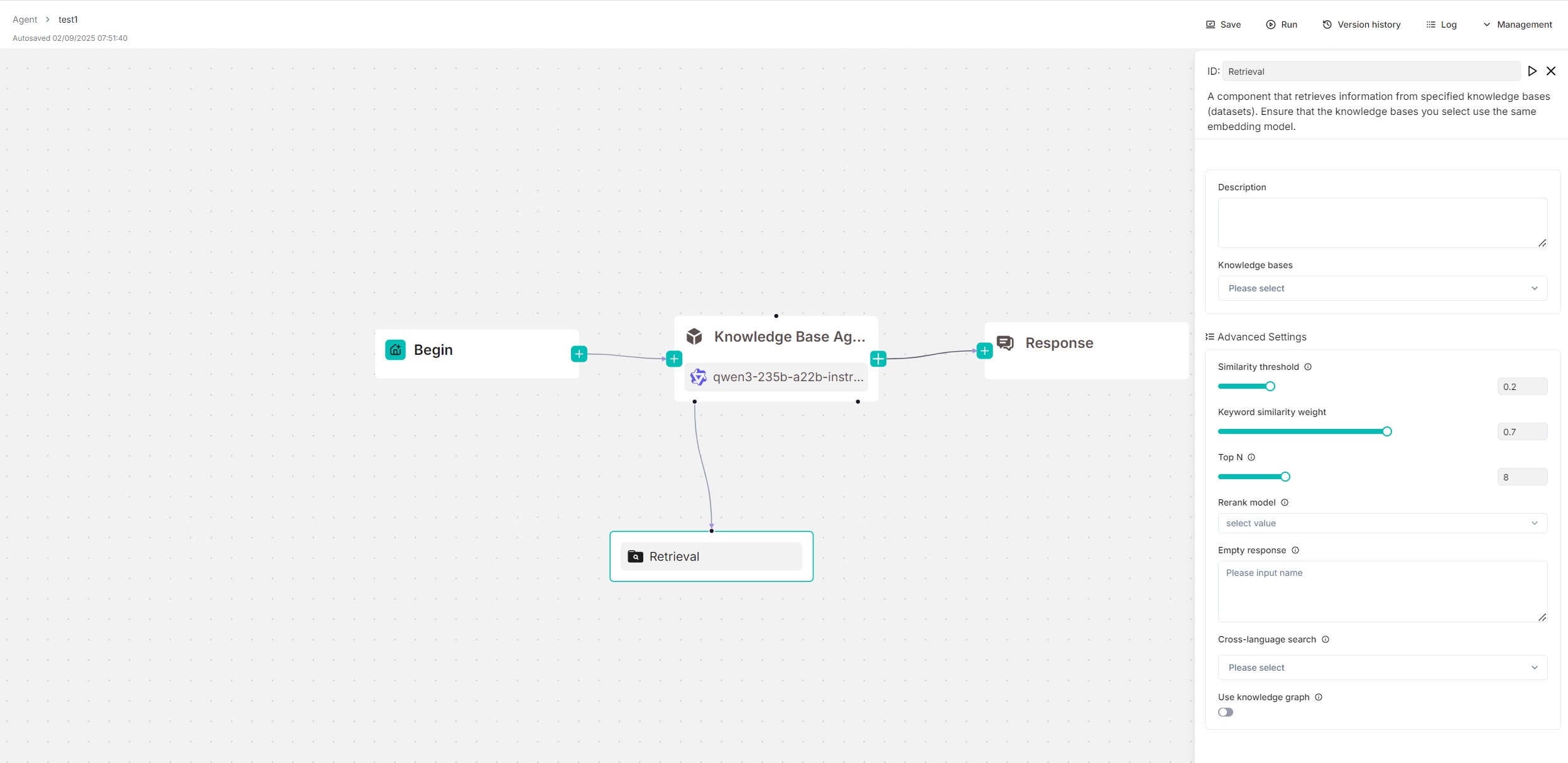
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on a **Retrieval** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Retrieval** component's search behavior.
|
||||
|
||||
### 2. Input query variable(s)
|
||||
|
||||
The **Retrieval** component depends on query variables to specify its queries.
|
||||
|
||||
:::caution IMPORTANT
|
||||
- If you use the **Retrieval** component as a standalone workflow module, input query variables in the **Input Variables** text box.
|
||||
- If it is used as a tool for an **Agent** component, input the query variables in the **Agent** component's **User prompt** field.
|
||||
:::
|
||||
|
||||
By default, you can use `sys.query`, which is the user query and the default output of the **Begin** component. All global variables defined before the **Retrieval** component can also be used as query statements. Use the `(x)` button or type `/` to show all the available query variables.
|
||||
|
||||
### 3. Select dataset(s) to query
|
||||
|
||||
You can specify one or multiple datasets to retrieve data from. If selecting mutiple, ensure they use the same embedding model.
|
||||
|
||||
### 4. Expand **Advanced Settings** to configure the retrieval method
|
||||
|
||||
By default, a combination of weighted keyword similarity and weighted vector cosine similarity is used for retrieval. If a rerank model is selected, a combination of weighted keyword similarity and weighted reranking score will be used instead.
|
||||
|
||||
As a starter, you can skip this step to stay with the default retrieval method.
|
||||
|
||||
:::caution WARNING
|
||||
Using a rerank model will *significantly* increase the system's response time. If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||
:::
|
||||
|
||||
### 5. Enable cross-language search
|
||||
|
||||
If your user query is different from the languages of the datasets, you can select the target languages in the **Cross-language search** dropdown menu. The model will then translates queries to ensure accurate matching of semantic meaning across languages.
|
||||
|
||||
|
||||
### 6. Test retrieval results
|
||||
|
||||
Click the **Run** button on the top of canvas to test the retrieval results.
|
||||
|
||||
### 7. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Retrieval** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
### Query variables
|
||||
|
||||
*Mandatory*
|
||||
|
||||
Select the query source for retrieval. Defaults to `sys.query`, which is the default output of the **Begin** component.
|
||||
|
||||
The **Retrieval** component relies on query variables to specify its queries. All global variables defined before the **Retrieval** component can also be used as queries. Use the `(x)` button or type `/` to show all the available query variables.
|
||||
|
||||
### Knowledge bases
|
||||
|
||||
Select the dataset(s) to retrieve data from.
|
||||
|
||||
- If no dataset is selected, meaning conversations with the agent will not be based on any dataset, ensure that the **Empty response** field is left blank to avoid an error.
|
||||
- If you select multiple datasets, you must ensure that the datasets you select use the same embedding model; otherwise, an error message would occur.
|
||||
|
||||
### Similarity threshold
|
||||
|
||||
RAGFlow employs a combination of weighted keyword similarity and weighted vector cosine similarity during retrieval. This parameter sets the threshold for similarities between the user query and chunks stored in the datasets. Any chunk with a similarity score below this threshold will be excluded from the results.
|
||||
|
||||
Defaults to 0.2.
|
||||
|
||||
### Vector similarity weight
|
||||
|
||||
This parameter sets the weight of vector similarity in the composite similarity score. The total of the two weights must equal 1.0. Its default value is 0.3, which means the weight of keyword similarity in a combined search is 1 - 0.3 = 0.7.
|
||||
|
||||
### Top N
|
||||
|
||||
This parameter selects the "Top N" chunks from retrieved ones and feed them to the LLM.
|
||||
|
||||
Defaults to 8.
|
||||
|
||||
|
||||
### Rerank model
|
||||
|
||||
*Optional*
|
||||
|
||||
If a rerank model is selected, a combination of weighted keyword similarity and weighted reranking score will be used for retrieval.
|
||||
|
||||
:::caution WARNING
|
||||
Using a rerank model will *significantly* increase the system's response time.
|
||||
:::
|
||||
|
||||
### Empty response
|
||||
|
||||
- Set this as a response if no results are retrieved from the dataset(s) for your query, or
|
||||
- Leave this field blank to allow the chat model to improvise when nothing is found.
|
||||
|
||||
:::caution WARNING
|
||||
If you do not specify a dataset, you must leave this field blank; otherwise, an error would occur.
|
||||
:::
|
||||
|
||||
### Cross-language search
|
||||
|
||||
Select one or more languages for cross‑language search. If no language is selected, the system searches with the original query.
|
||||
|
||||
### Use knowledge graph
|
||||
|
||||
:::caution IMPORTANT
|
||||
Before enabling this feature, ensure you have properly [constructed a knowledge graph from each target dataset](../../dataset/construct_knowledge_graph.md).
|
||||
:::
|
||||
|
||||
Whether to use knowledge graph(s) in the specified dataset(s) during retrieval for multi-hop question answering. When enabled, this would involve iterative searches across entity, relationship, and community report chunks, greatly increasing retrieval time.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Retrieval** component, which can be referenced by other components in the workflow.
|
||||
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### How to reduce response time?
|
||||
|
||||
Go through the checklist below for best performance:
|
||||
|
||||
- Leave the **Rerank model** field empty.
|
||||
- If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||
- Disable **Use knowledge graph**.
|
||||
50
docs/guides/agent/agent_component_reference/switch.mdx
Normal file
50
docs/guides/agent/agent_component_reference/switch.mdx
Normal file
@@ -0,0 +1,50 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /switch_component
|
||||
---
|
||||
|
||||
# Switch component
|
||||
|
||||
A component that evaluates whether specified conditions are met and directs the follow of execution accordingly.
|
||||
|
||||
---
|
||||
|
||||
A **Switch** component evaluates conditions based on the output of specific components, directing the flow of execution accordingly to enable complex branching logic.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Switch** component is essential for condition-based direction of execution flow. While it shares similarities with the [Categorize](./categorize.mdx) component, which is also used in multi-pronged strategies, the key distinction lies in their approach: the evaluation of the **Switch** component is rule-based, whereas the **Categorize** component involves AI and uses an LLM for decision-making.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Case n
|
||||
|
||||
A **Switch** component must have at least one case, each with multiple specified conditions. When multiple conditions are specified for a case, you must set the logical relationship between them to either AND or OR.
|
||||
|
||||
Once a new case is added, navigate to the **Switch** component on the canvas, find the **+** button next to the case, and click it to specify the downstream component(s).
|
||||
|
||||
|
||||
#### Condition
|
||||
|
||||
Evaluates whether the output of specific components meets certain conditions
|
||||
|
||||
:::danger IMPORTANT
|
||||
When you have added multiple conditions for a specific case, a **Logical operator** field appears, requiring you to set the logical relationship between these conditions as either AND or OR.
|
||||
:::
|
||||
|
||||
- **Operator**: The operator required to form a conditional expression.
|
||||
- Equals (default)
|
||||
- Not equal
|
||||
- Greater than
|
||||
- Greater equal
|
||||
- Less than
|
||||
- Less equal
|
||||
- Contains
|
||||
- Not contains
|
||||
- Starts with
|
||||
- Ends with
|
||||
- Is empty
|
||||
- Not empty
|
||||
- **Value**: A single value, which can be an integer, float, or string.
|
||||
- Delimiters, multiple values, or expressions are *not* supported.
|
||||
|
||||
@@ -0,0 +1,38 @@
|
||||
---
|
||||
sidebar_position: 15
|
||||
slug: /text_processing
|
||||
---
|
||||
|
||||
# Text processing component
|
||||
|
||||
A component that merges or splits texts.
|
||||
|
||||
---
|
||||
|
||||
A **Text processing** component merges or splits texts.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Method
|
||||
|
||||
- Split: Split the text
|
||||
- Merge: Merge the text
|
||||
|
||||
### Split_ref
|
||||
|
||||
Appears only when you select **Split** as method.
|
||||
|
||||
The variable to be split. Type `/` to quickly insert variables.
|
||||
|
||||
### Script
|
||||
|
||||
Template for the merge. Appears only when you select **Merge** as method. Type `/` to quickly insert variables.
|
||||
|
||||
### Delimiters
|
||||
|
||||
The delimiter(s) used to split or merge the text.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the component, which can be referenced by other components in the workflow.
|
||||
|
||||
80
docs/guides/agent/agent_component_reference/transformer.md
Normal file
80
docs/guides/agent/agent_component_reference/transformer.md
Normal file
@@ -0,0 +1,80 @@
|
||||
---
|
||||
sidebar_position: 37
|
||||
slug: /transformer_component
|
||||
---
|
||||
|
||||
# Transformer component
|
||||
|
||||
A component that uses an LLM to extract insights from the chunks.
|
||||
|
||||
---
|
||||
|
||||
A **Transformer** component indexes chunks and configures their storage formats in the document engine. It *typically* precedes the **Indexer** in the ingestion pipeline, but you can also chain multiple **Transformer** components in sequence.
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Transformer** component is essential when you need the LLM to extract new information, such as keywords, questions, metadata, and summaries, from the original chunks.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Model
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creativity**.
|
||||
:::
|
||||
|
||||
### Result destination
|
||||
|
||||
Select the type of output to be generated by the LLM:
|
||||
|
||||
- Summary
|
||||
- Keywords
|
||||
- Questions
|
||||
- Metadata
|
||||
|
||||
### System prompt
|
||||
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering.
|
||||
|
||||
:::tip NOTE
|
||||
The system prompt here automatically updates to match your selected **Result destination**.
|
||||
:::
|
||||
|
||||
### User prompt
|
||||
|
||||
The user-defined prompt. For example, you can type `/` or click **(x)** to insert variables of preceding components in the ingestion pipeline as the LLM's input.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Transformer** component, which can be referenced by subsequent **Transformer** components in the ingestion pipeline.
|
||||
|
||||
- Default: `chunks`
|
||||
- Type: `Array<Object>`
|
||||
51
docs/guides/agent/agent_introduction.md
Normal file
51
docs/guides/agent/agent_introduction.md
Normal file
@@ -0,0 +1,51 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /agent_introduction
|
||||
---
|
||||
|
||||
# Introduction to agents
|
||||
|
||||
Key concepts, basic operations, a quick view of the agent editor.
|
||||
|
||||
---
|
||||
|
||||
:::danger DEPRECATED!
|
||||
A new version is coming soon.
|
||||
:::
|
||||
|
||||
## Key concepts
|
||||
|
||||
Agents and RAG are complementary techniques, each enhancing the other’s capabilities in business applications. RAGFlow v0.8.0 introduces an agent mechanism, featuring a no-code workflow editor on the front end and a comprehensive graph-based task orchestration framework on the back end. This mechanism is built on top of RAGFlow's existing RAG solutions and aims to orchestrate search technologies such as query intent classification, conversation leading, and query rewriting to:
|
||||
|
||||
- Provide higher retrievals and,
|
||||
- Accommodate more complex scenarios.
|
||||
|
||||
## Create an agent
|
||||
|
||||
:::tip NOTE
|
||||
|
||||
Before proceeding, ensure that:
|
||||
|
||||
1. You have properly set the LLM to use. See the guides on [Configure your API key](../models/llm_api_key_setup.md) or [Deploy a local LLM](../models/deploy_local_llm.mdx) for more information.
|
||||
2. You have a dataset configured and the corresponding files properly parsed. See the guide on [Configure a dataset](../dataset/configure_knowledge_base.md) for more information.
|
||||
|
||||
:::
|
||||
|
||||
Click the **Agent** tab in the middle top of the page to show the **Agent** page. As shown in the screenshot below, the cards on this page represent the created agents, which you can continue to edit.
|
||||
|
||||
|
||||
|
||||
We also provide templates catered to different business scenarios. You can either generate your agent from one of our agent templates or create one from scratch:
|
||||
|
||||
1. Click **+ Create agent** to show the **agent template** page:
|
||||
|
||||
|
||||
|
||||
2. To create an agent from scratch, click **Create Agent**. Alternatively, to create an agent from one of our templates, click the desired card, such as **Deep Research**, name your agent in the pop-up dialogue, and click **OK** to confirm.
|
||||
|
||||
*You are now taken to the **no-code workflow editor** page.*
|
||||
|
||||
|
||||
|
||||
3. Click the **+** button on the **Begin** component to select the desired components in your workflow.
|
||||
4. Click **Save** to apply changes to your agent.
|
||||
8
docs/guides/agent/best_practices/_category_.json
Normal file
8
docs/guides/agent/best_practices/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Best practices",
|
||||
"position": 30,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on Agent configuration."
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,58 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /accelerate_agent_question_answering
|
||||
---
|
||||
|
||||
# Accelerate answering
|
||||
|
||||
A checklist to speed up question answering.
|
||||
|
||||
---
|
||||
|
||||
Please note that some of your settings may consume a significant amount of time. If you often find that your question answering is time-consuming, here is a checklist to consider:
|
||||
|
||||
## Balance task complexity with an Agent’s performance and speed?
|
||||
|
||||
An Agent’s response time generally depends on many factors, e.g., the LLM’s capabilities and the prompt, the latter reflecting task complexity. When using an Agent, you should always balance task demands with the LLM’s ability.
|
||||
|
||||
- For simple tasks, such as retrieval, rewriting, formatting, or structured data extraction, use concise prompts, remove planning or reasoning instructions, enforce output length limits, and select smaller or Turbo-class models. This significantly reduces latency and cost with minimal impact on quality.
|
||||
|
||||
- For complex tasks, like multi-step reasoning, cross-document synthesis, or tool-based workflows, maintain or enhance prompts that include planning, reflection, and verification steps.
|
||||
|
||||
- In multi-Agent orchestration systems, delegate simple subtasks to sub-Agents using smaller, faster models, and reserve more powerful models for the lead Agent to handle complexity and uncertainty.
|
||||
|
||||
:::tip KEY INSIGHT
|
||||
Focus on minimizing output tokens — through summarization, bullet points, or explicit length limits — as this has far greater impact on reducing latency than optimizing input size.
|
||||
:::
|
||||
|
||||
## Disable Reasoning
|
||||
|
||||
Disabling the **Reasoning** toggle will reduce the LLM's thinking time. For a model like Qwen3, you also need to add `/no_think` to the system prompt to disable reasoning.
|
||||
|
||||
## Disable Rerank model
|
||||
|
||||
- Leaving the **Rerank model** field empty (in the corresponding **Retrieval** component) will significantly decrease retrieval time.
|
||||
- When using a rerank model, ensure you have a GPU for acceleration; otherwise, the reranking process will be *prohibitively* slow.
|
||||
|
||||
:::tip NOTE
|
||||
Please note that rerank models are essential in certain scenarios. There is always a trade-off between speed and performance; you must weigh the pros against cons for your specific case.
|
||||
:::
|
||||
|
||||
## Check the time taken for each task
|
||||
|
||||
Click the light bulb icon above the *current* dialogue and scroll down the popup window to view the time taken for each task:
|
||||
|
||||
|
||||
|
||||
| Item name | Description |
|
||||
| ----------------- | --------------------------------------------------------------------------------------------- |
|
||||
| Total | Total time spent on this conversation round, including chunk retrieval and answer generation. |
|
||||
| Check LLM | Time to validate the specified LLM. |
|
||||
| Create retriever | Time to create a chunk retriever. |
|
||||
| Bind embedding | Time to initialize an embedding model instance. |
|
||||
| Bind LLM | Time to initialize an LLM instance. |
|
||||
| Tune question | Time to optimize the user query using the context of the mult-turn conversation. |
|
||||
| Bind reranker | Time to initialize an reranker model instance for chunk retrieval. |
|
||||
| Generate keywords | Time to extract keywords from the user query. |
|
||||
| Retrieval | Time to retrieve the chunks. |
|
||||
| Generate answer | Time to generate the answer. |
|
||||
15
docs/guides/agent/embed_agent_into_webpage.md
Normal file
15
docs/guides/agent/embed_agent_into_webpage.md
Normal file
@@ -0,0 +1,15 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /embed_agent_into_webpage
|
||||
---
|
||||
|
||||
# Embed agent into webpage
|
||||
|
||||
You can use iframe to embed an agent into a third-party webpage.
|
||||
|
||||
1. Before proceeding, you must [acquire an API key](../models/llm_api_key_setup.md); otherwise, an error message would appear.
|
||||
2. On the **Agent** page, click an intended agent to access its editing page.
|
||||
3. Click **Management > Embed into webpage** on the top right corner of the canvas to show the **iframe** window:
|
||||
4. Copy the iframe and embed it into your webpage.
|
||||
|
||||
|
||||
116
docs/guides/agent/sandbox_quickstart.md
Normal file
116
docs/guides/agent/sandbox_quickstart.md
Normal file
@@ -0,0 +1,116 @@
|
||||
---
|
||||
sidebar_position: 20
|
||||
slug: /sandbox_quickstart
|
||||
---
|
||||
|
||||
# Sandbox quickstart
|
||||
|
||||
A secure, pluggable code execution backend designed for RAGFlow and other applications requiring isolated code execution environments.
|
||||
|
||||
## Features:
|
||||
|
||||
- Seamless RAGFlow Integration — Works out-of-the-box with the code component of RAGFlow.
|
||||
- High Security — Uses gVisor for syscall-level sandboxing to isolate execution.
|
||||
- Customisable Sandboxing — Modify seccomp profiles easily to tailor syscall restrictions.
|
||||
- Pluggable Runtime Support — Extendable to support any programming language runtime.
|
||||
- Developer Friendly — Quick setup with a convenient Makefile.
|
||||
|
||||
## Architecture
|
||||
|
||||
The architecture consists of isolated Docker base images for each supported language runtime, managed by the executor manager service. The executor manager orchestrates sandboxed code execution using gVisor for syscall interception and optional seccomp profiles for enhanced syscall filtering.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Linux distribution compatible with gVisor.
|
||||
- gVisor installed and configured.
|
||||
- Docker version 24.0.0 or higher.
|
||||
- Docker Compose version 2.26.1 or higher (similar to RAGFlow requirements).
|
||||
- uv package and project manager installed.
|
||||
- (Optional) GNU Make for simplified command-line management.
|
||||
|
||||
## Build Docker base images
|
||||
|
||||
The sandbox uses isolated base images for secure containerised execution environments.
|
||||
|
||||
Build the base images manually:
|
||||
|
||||
```bash
|
||||
docker build -t sandbox-base-python:latest ./sandbox_base_image/python
|
||||
docker build -t sandbox-base-nodejs:latest ./sandbox_base_image/nodejs
|
||||
```
|
||||
|
||||
Alternatively, build all base images at once using the Makefile:
|
||||
|
||||
```bash
|
||||
make build
|
||||
```
|
||||
|
||||
Next, build the executor manager image:
|
||||
|
||||
```bash
|
||||
docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
```
|
||||
|
||||
## Running with RAGFlow
|
||||
|
||||
1. Verify that gVisor is properly installed and operational.
|
||||
|
||||
2. Configure the .env file located at docker/.env:
|
||||
|
||||
- Uncomment sandbox-related environment variables.
|
||||
- Enable the sandbox profile at the bottom of the file.
|
||||
|
||||
3. Add the following entry to your /etc/hosts file to resolve the executor manager service:
|
||||
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Start the RAGFlow service as usual.
|
||||
|
||||
## Running standalone
|
||||
|
||||
### Manual setup
|
||||
|
||||
1. Initialize the environment variables:
|
||||
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
|
||||
2. Launch the sandbox services with Docker Compose:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
3. Test the sandbox setup:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
|
||||
### Using Makefile
|
||||
|
||||
Run all setup, build, launch, and tests with a single command:
|
||||
|
||||
```bash
|
||||
make
|
||||
```
|
||||
|
||||
### Monitoring
|
||||
|
||||
To follow logs of the executor manager container:
|
||||
|
||||
```bash
|
||||
docker logs -f sandbox-executor-manager
|
||||
```
|
||||
|
||||
Or use the Makefile shortcut:
|
||||
|
||||
```bash
|
||||
make logs
|
||||
```
|
||||
31
docs/guides/ai_search.md
Normal file
31
docs/guides/ai_search.md
Normal file
@@ -0,0 +1,31 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /ai_search
|
||||
---
|
||||
|
||||
# Search
|
||||
|
||||
Conduct an AI search.
|
||||
|
||||
---
|
||||
|
||||
An AI search is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. The related chunks are listed below the chat model's response in descending order based on their similarity scores.
|
||||
|
||||
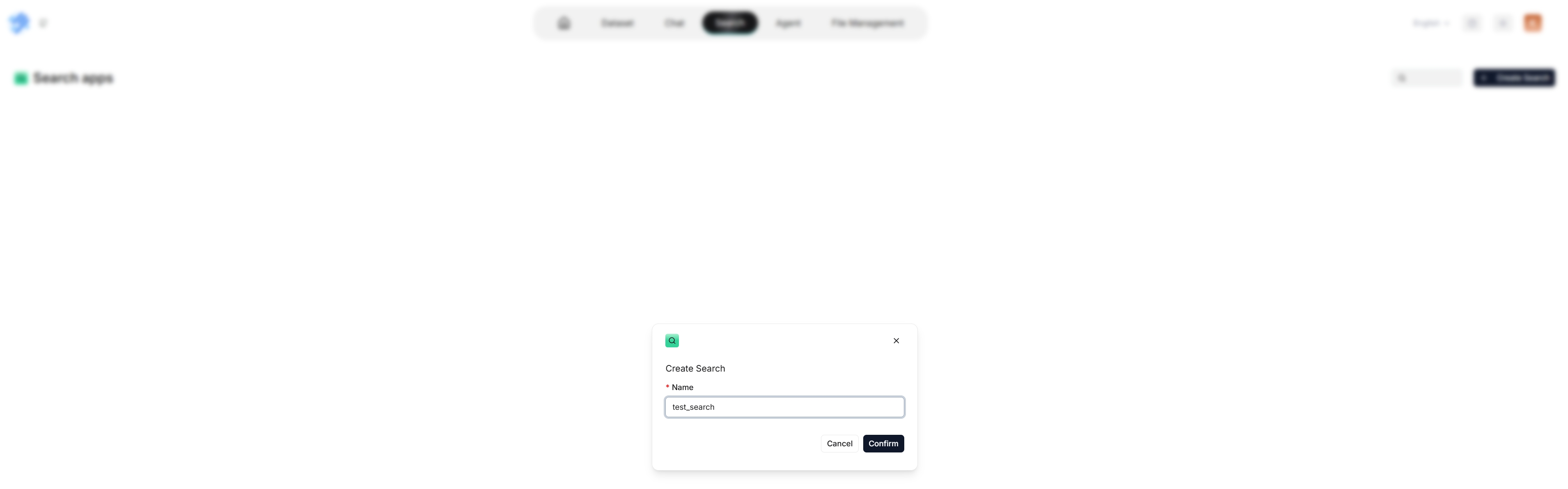
|
||||
|
||||
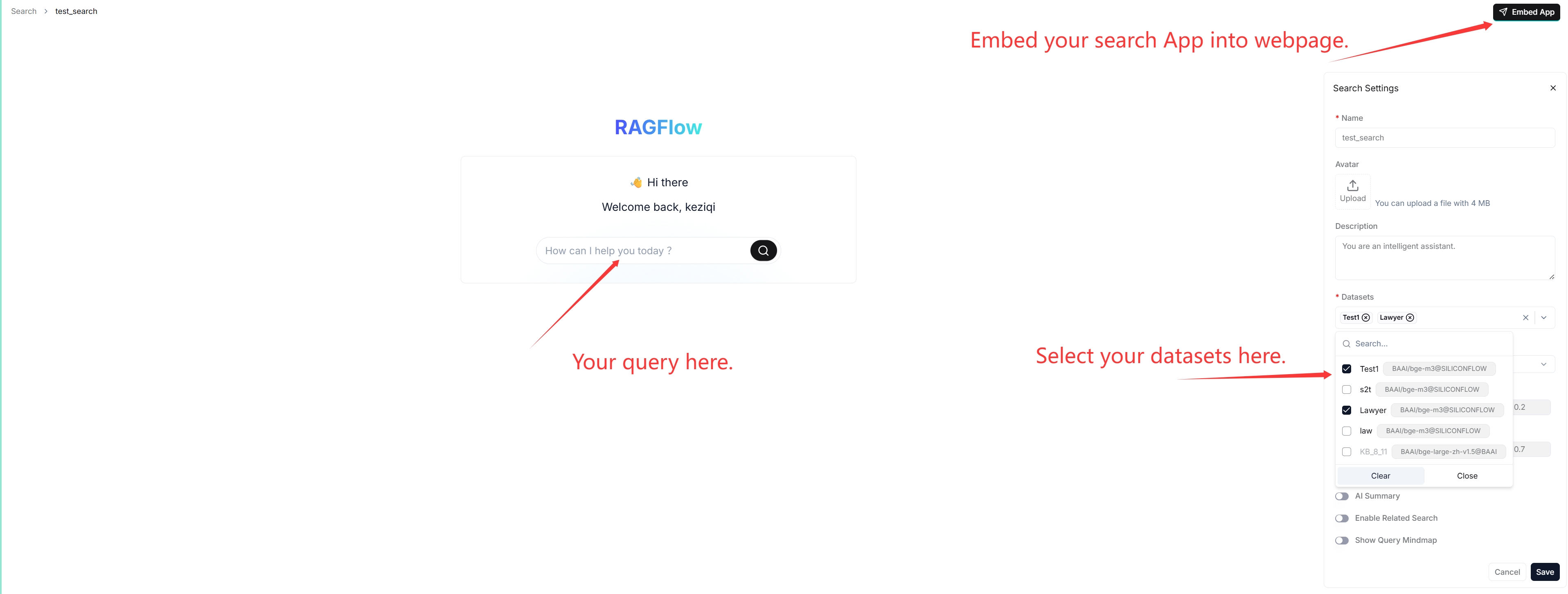
|
||||
|
||||
:::tip NOTE
|
||||
When debugging your chat assistant, you can use AI search as a reference to verify your model settings and retrieval strategy.
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Ensure that you have configured the system's default models on the **Model providers** page.
|
||||
- Ensure that the intended datasets are properly configured and the intended documents have finished file parsing.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Key difference between an AI search and an AI chat?
|
||||
|
||||
A chat is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
|
||||
8
docs/guides/chat/_category_.json
Normal file
8
docs/guides/chat/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Chat",
|
||||
"position": 1,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Chat-specific guides."
|
||||
}
|
||||
}
|
||||
8
docs/guides/chat/best_practices/_category_.json
Normal file
8
docs/guides/chat/best_practices/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Best practices",
|
||||
"position": 7,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on chat assistant configuration."
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,48 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /accelerate_question_answering
|
||||
---
|
||||
|
||||
# Accelerate answering
|
||||
import APITable from '@site/src/components/APITable';
|
||||
|
||||
A checklist to speed up question answering for your chat assistant.
|
||||
|
||||
---
|
||||
|
||||
Please note that some of your settings may consume a significant amount of time. If you often find that your question answering is time-consuming, here is a checklist to consider:
|
||||
|
||||
- Disabling **Multi-turn optimization** will reduce the time required to get an answer from the LLM.
|
||||
- Leaving the **Rerank model** field empty will significantly decrease retrieval time.
|
||||
- Disabling the **Reasoning** toggle will reduce the LLM's thinking time. For a model like Qwen3, you also need to add `/no_think` to the system prompt to disable reasoning.
|
||||
- When using a rerank model, ensure you have a GPU for acceleration; otherwise, the reranking process will be *prohibitively* slow.
|
||||
|
||||
:::tip NOTE
|
||||
Please note that rerank models are essential in certain scenarios. There is always a trade-off between speed and performance; you must weigh the pros against cons for your specific case.
|
||||
:::
|
||||
|
||||
- Disabling **Keyword analysis** will reduce the time to receive an answer from the LLM.
|
||||
- When chatting with your chat assistant, click the light bulb icon above the *current* dialogue and scroll down the popup window to view the time taken for each task:
|
||||

|
||||
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| Item name | Description |
|
||||
| ----------------- | --------------------------------------------------------------------------------------------- |
|
||||
| Total | Total time spent on this conversation round, including chunk retrieval and answer generation. |
|
||||
| Check LLM | Time to validate the specified LLM. |
|
||||
| Create retriever | Time to create a chunk retriever. |
|
||||
| Bind embedding | Time to initialize an embedding model instance. |
|
||||
| Bind LLM | Time to initialize an LLM instance. |
|
||||
| Tune question | Time to optimize the user query using the context of the mult-turn conversation. |
|
||||
| Bind reranker | Time to initialize an reranker model instance for chunk retrieval. |
|
||||
| Generate keywords | Time to extract keywords from the user query. |
|
||||
| Retrieval | Time to retrieve the chunks. |
|
||||
| Generate answer | Time to generate the answer. |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
28
docs/guides/chat/implement_deep_research.md
Normal file
28
docs/guides/chat/implement_deep_research.md
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /implement_deep_research
|
||||
---
|
||||
|
||||
# Implement deep research
|
||||
|
||||
Implements deep research for agentic reasoning.
|
||||
|
||||
---
|
||||
|
||||
From v0.17.0 onward, RAGFlow supports integrating agentic reasoning in an AI chat. The following diagram illustrates the workflow of RAGFlow's deep research:
|
||||
|
||||

|
||||
|
||||
To activate this feature:
|
||||
|
||||
1. Enable the **Reasoning** toggle in **Chat setting**.
|
||||
|
||||
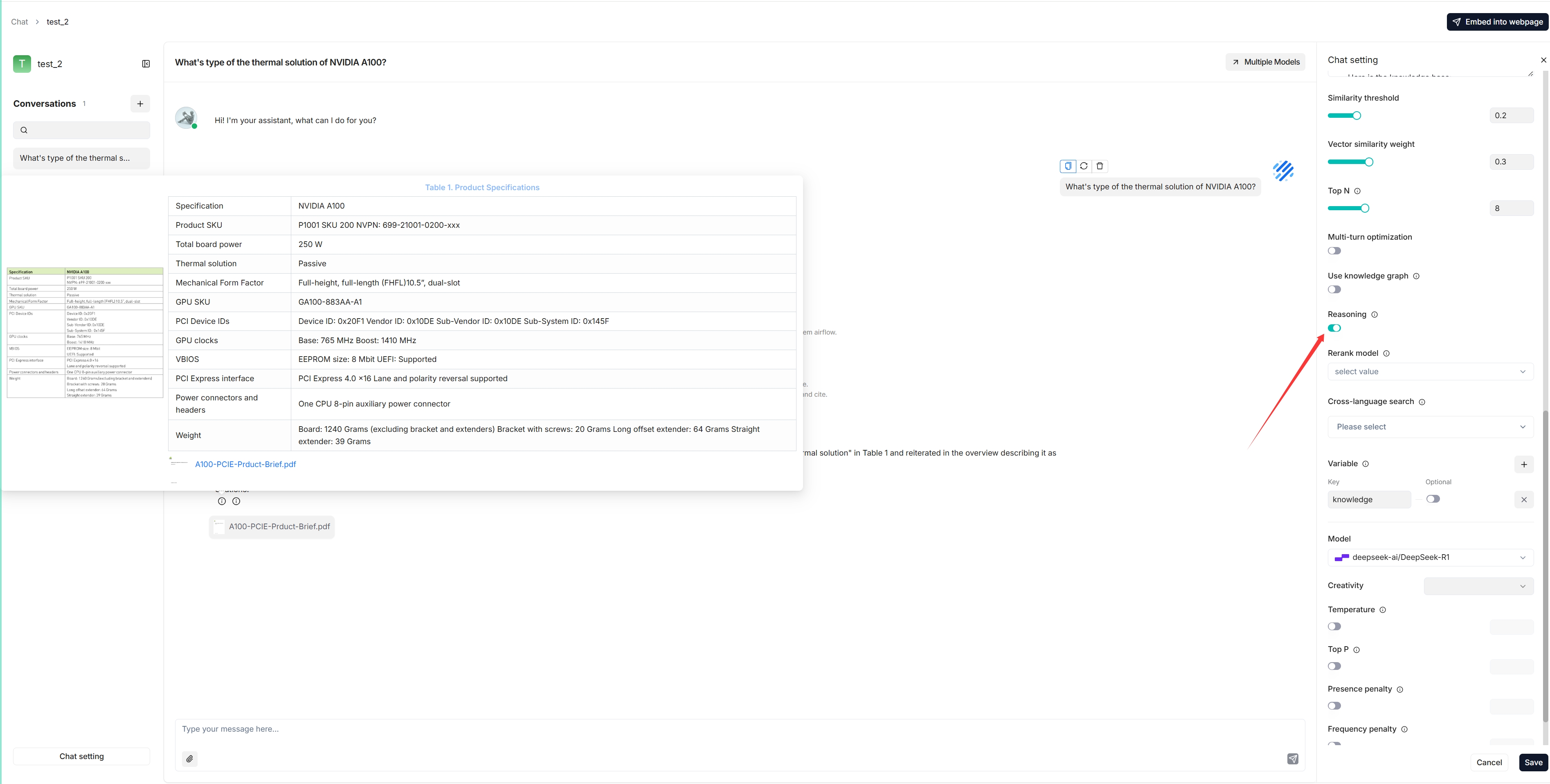
|
||||
|
||||
2. Enter the correct Tavily API key to leverage Tavily-based web search:
|
||||
|
||||
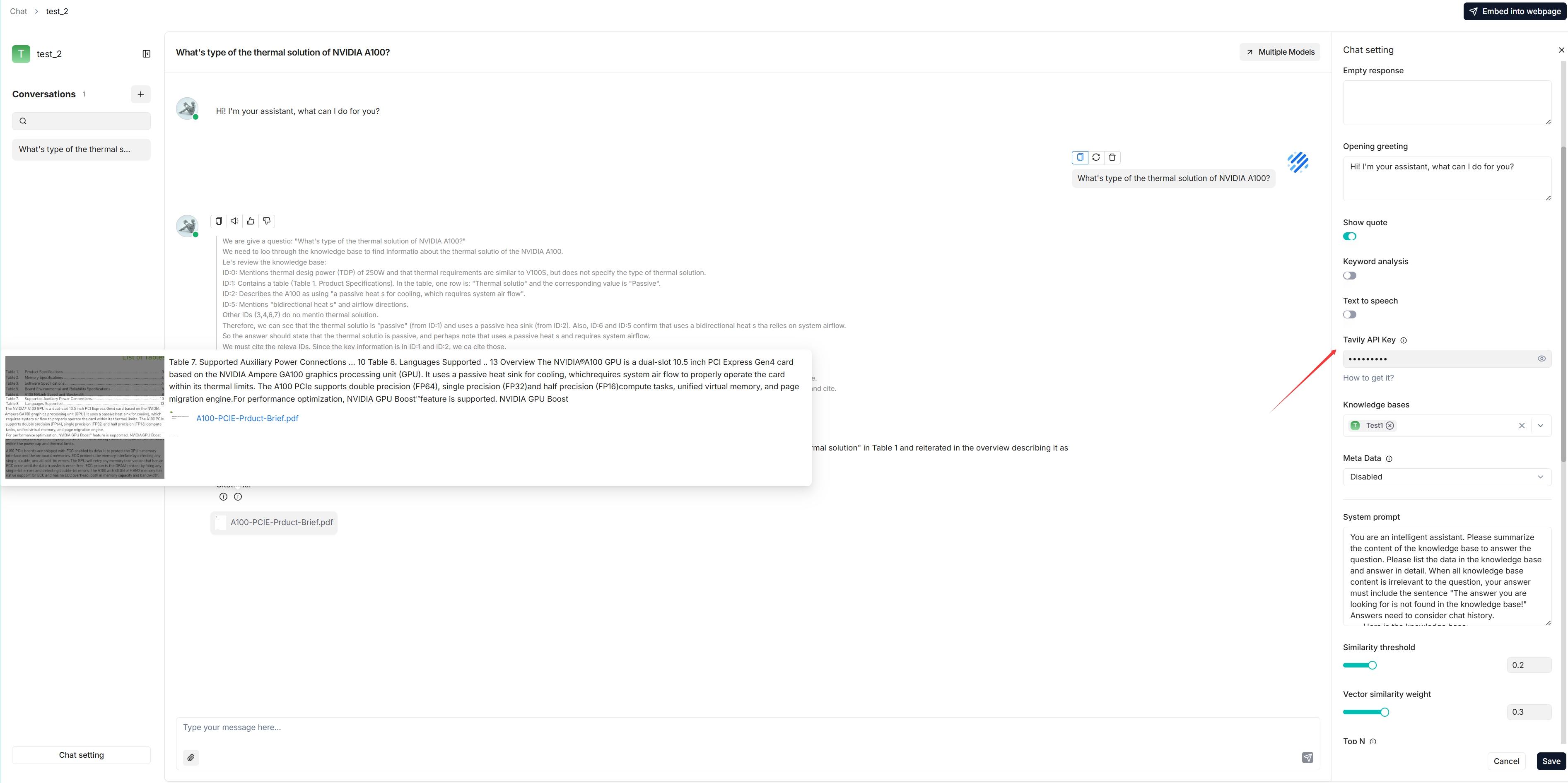
|
||||
|
||||
*The following is a screenshot of a conversation that integrates Deep Research:*
|
||||
|
||||

|
||||
110
docs/guides/chat/set_chat_variables.md
Normal file
110
docs/guides/chat/set_chat_variables.md
Normal file
@@ -0,0 +1,110 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /set_chat_variables
|
||||
---
|
||||
|
||||
# Set variables
|
||||
|
||||
Set variables to be used together with the system prompt for your LLM.
|
||||
|
||||
---
|
||||
|
||||
When configuring the system prompt for a chat model, variables play an important role in enhancing flexibility and reusability. With variables, you can dynamically adjust the system prompt to be sent to your model. In the context of RAGFlow, if you have defined variables in **Chat setting**, except for the system's reserved variable `{knowledge}`, you are required to pass in values for them from RAGFlow's [HTTP API](../../references/http_api_reference.md#converse-with-chat-assistant) or through its [Python SDK](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
:::danger IMPORTANT
|
||||
In RAGFlow, variables are closely linked with the system prompt. When you add a variable in the **Variable** section, include it in the system prompt. Conversely, when deleting a variable, ensure it is removed from the system prompt; otherwise, an error would occur.
|
||||
:::
|
||||
|
||||
## Where to set variables
|
||||
|
||||
|
||||
|
||||
## 1. Manage variables
|
||||
|
||||
In the **Variable** section, you add, remove, or update variables.
|
||||
|
||||
### `{knowledge}` - a reserved variable
|
||||
|
||||
`{knowledge}` is the system's reserved variable, representing the chunks retrieved from the dataset(s) specified by **Knowledge bases** under the **Assistant settings** tab. If your chat assistant is associated with certain datasets, you can keep it as is.
|
||||
|
||||
:::info NOTE
|
||||
It currently makes no difference whether `{knowledge}` is set as optional or mandatory, but please note this design will be updated in due course.
|
||||
:::
|
||||
|
||||
From v0.17.0 onward, you can start an AI chat without specifying datasets. In this case, we recommend removing the `{knowledge}` variable to prevent unnecessary reference and keeping the **Empty response** field empty to avoid errors.
|
||||
|
||||
### Custom variables
|
||||
|
||||
Besides `{knowledge}`, you can also define your own variables to pair with the system prompt. To use these custom variables, you must pass in their values through RAGFlow's official APIs. The **Optional** toggle determines whether these variables are required in the corresponding APIs:
|
||||
|
||||
- **Disabled** (Default): The variable is mandatory and must be provided.
|
||||
- **Enabled**: The variable is optional and can be omitted if not needed.
|
||||
|
||||
## 2. Update system prompt
|
||||
|
||||
After you add or remove variables in the **Variable** section, ensure your changes are reflected in the system prompt to avoid inconsistencies or errors. Here's an example:
|
||||
|
||||
```
|
||||
You are an intelligent assistant. Please answer the question by summarizing chunks from the specified dataset(s)...
|
||||
|
||||
Your answers should follow a professional and {style} style.
|
||||
|
||||
...
|
||||
|
||||
Here is the dataset:
|
||||
{knowledge}
|
||||
The above is the dataset.
|
||||
```
|
||||
|
||||
:::tip NOTE
|
||||
If you have removed `{knowledge}`, ensure that you thoroughly review and update the entire system prompt to achieve optimal results.
|
||||
:::
|
||||
|
||||
## APIs
|
||||
|
||||
The *only* way to pass in values for the custom variables defined in the **Chat Configuration** dialogue is to call RAGFlow's [HTTP API](../../references/http_api_reference.md#converse-with-chat-assistant) or through its [Python SDK](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
### HTTP API
|
||||
|
||||
See [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant). Here's an example:
|
||||
|
||||
```json {9}
|
||||
curl --request POST \
|
||||
--url http://{address}/api/v1/chats/{chat_id}/completions \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header 'Authorization: Bearer <YOUR_API_KEY>' \
|
||||
--data-binary '
|
||||
{
|
||||
"question": "xxxxxxxxx",
|
||||
"stream": true,
|
||||
"style":"hilarious"
|
||||
}'
|
||||
```
|
||||
|
||||
### Python API
|
||||
|
||||
See [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant). Here's an example:
|
||||
|
||||
```python {18}
|
||||
from ragflow_sdk import RAGFlow
|
||||
|
||||
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
|
||||
assistant = rag_object.list_chats(name="Miss R")
|
||||
assistant = assistant[0]
|
||||
session = assistant.create_session()
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
print("Hello. What can I do for you?")
|
||||
|
||||
while True:
|
||||
question = input("\n==================== User =====================\n> ")
|
||||
style = input("Please enter your preferred style (e.g., formal, informal, hilarious): ")
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
|
||||
cont = ""
|
||||
for ans in session.ask(question, stream=True, style=style):
|
||||
print(ans.content[len(cont):], end='', flush=True)
|
||||
cont = ans.content
|
||||
```
|
||||
|
||||
116
docs/guides/chat/start_chat.md
Normal file
116
docs/guides/chat/start_chat.md
Normal file
@@ -0,0 +1,116 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /start_chat
|
||||
---
|
||||
|
||||
# Start AI chat
|
||||
|
||||
Initiate an AI-powered chat with a configured chat assistant.
|
||||
|
||||
---
|
||||
|
||||
Knowledge base, hallucination-free chat, and file management are the three pillars of RAGFlow. Chats in RAGFlow are based on a particular dataset or multiple datasets. Once you have created your dataset, finished file parsing, and [run a retrieval test](../dataset/run_retrieval_test.md), you can go ahead and start an AI conversation.
|
||||
|
||||
## Start an AI chat
|
||||
|
||||
You start an AI conversation by creating an assistant.
|
||||
|
||||
1. Click the **Chat** tab in the middle top of the page **>** **Create an assistant** to show the **Chat Configuration** dialogue *of your next dialogue*.
|
||||
|
||||
> RAGFlow offers you the flexibility of choosing a different chat model for each dialogue, while allowing you to set the default models in **System Model Settings**.
|
||||
|
||||
2. Update Assistant-specific settings:
|
||||
|
||||
- **Assistant name** is the name of your chat assistant. Each assistant corresponds to a dialogue with a unique combination of datasets, prompts, hybrid search configurations, and large model settings.
|
||||
- **Empty response**:
|
||||
- If you wish to *confine* RAGFlow's answers to your datasets, leave a response here. Then, when it doesn't retrieve an answer, it *uniformly* responds with what you set here.
|
||||
- If you wish RAGFlow to *improvise* when it doesn't retrieve an answer from your datasets, leave it blank, which may give rise to hallucinations.
|
||||
- **Show quote**: This is a key feature of RAGFlow and enabled by default. RAGFlow does not work like a black box. Instead, it clearly shows the sources of information that its responses are based on.
|
||||
- Select the corresponding datasets. You can select one or multiple datasets, but ensure that they use the same embedding model, otherwise an error would occur.
|
||||
|
||||
3. Update Prompt-specific settings:
|
||||
|
||||
- In **System**, you fill in the prompts for your LLM, you can also leave the default prompt as-is for the beginning.
|
||||
- **Similarity threshold** sets the similarity "bar" for each chunk of text. The default is 0.2. Text chunks with lower similarity scores are filtered out of the final response.
|
||||
- **Vector similarity weight** is set to 0.3 by default. RAGFlow uses a hybrid score system to evaluate the relevance of different text chunks. This value sets the weight assigned to the vector similarity component in the hybrid score.
|
||||
- If **Rerank model** is left empty, the hybrid score system uses keyword similarity and vector similarity, and the default weight assigned to the keyword similarity component is 1-0.3=0.7.
|
||||
- If **Rerank model** is selected, the hybrid score system uses keyword similarity and reranker score, and the default weight assigned to the reranker score is 1-0.7=0.3.
|
||||
- **Top N** determines the *maximum* number of chunks to feed to the LLM. In other words, even if more chunks are retrieved, only the top N chunks are provided as input.
|
||||
- **Multi-turn optimization** enhances user queries using existing context in a multi-round conversation. It is enabled by default. When enabled, it will consume additional LLM tokens and significantly increase the time to generate answers.
|
||||
- **Use knowledge graph** indicates whether to use knowledge graph(s) in the specified dataset(s) during retrieval for multi-hop question answering. When enabled, this would involve iterative searches across entity, relationship, and community report chunks, greatly increasing retrieval time.
|
||||
- **Reasoning** indicates whether to generate answers through reasoning processes like Deepseek-R1/OpenAI o1. Once enabled, the chat model autonomously integrates Deep Research during question answering when encountering an unknown topic. This involves the chat model dynamically searching external knowledge and generating final answers through reasoning.
|
||||
- **Rerank model** sets the reranker model to use. It is left empty by default.
|
||||
- If **Rerank model** is left empty, the hybrid score system uses keyword similarity and vector similarity, and the default weight assigned to the vector similarity component is 1-0.7=0.3.
|
||||
- If **Rerank model** is selected, the hybrid score system uses keyword similarity and reranker score, and the default weight assigned to the reranker score is 1-0.7=0.3.
|
||||
- [Cross-language search](../../references/glossary.mdx#cross-language-search): Optional
|
||||
Select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||
- When selecting target languages, please ensure that these languages are present in the dataset to guarantee an effective search.
|
||||
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||
- **Variable** refers to the variables (keys) to be used in the system prompt. `{knowledge}` is a reserved variable. Click **Add** to add more variables for the system prompt.
|
||||
- If you are uncertain about the logic behind **Variable**, leave it *as-is*.
|
||||
- As of v0.21.1, if you add custom variables here, the only way you can pass in their values is to call:
|
||||
- HTTP method [Converse with chat assistant](../../references/http_api_reference.md#converse-with-chat-assistant), or
|
||||
- Python method [Converse with chat assistant](../../references/python_api_reference.md#converse-with-chat-assistant).
|
||||
|
||||
4. Update Model-specific Settings:
|
||||
|
||||
- In **Model**: you select the chat model. Though you have selected the default chat model in **System Model Settings**, RAGFlow allows you to choose an alternative chat model for your dialogue.
|
||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
|
||||
5. Now, let's start the show:
|
||||
|
||||

|
||||
|
||||
:::tip NOTE
|
||||
|
||||
1. Click the light bulb icon above the answer to view the expanded system prompt:
|
||||
|
||||
|
||||
|
||||
*The light bulb icon is available only for the current dialogue.*
|
||||
|
||||
2. Scroll down the expanded prompt to view the time consumed for each task:
|
||||
|
||||

|
||||
:::
|
||||
|
||||
## Update settings of an existing chat assistant
|
||||
|
||||

|
||||
|
||||
## Integrate chat capabilities into your application or webpage
|
||||
|
||||
RAGFlow offers HTTP and Python APIs for you to integrate RAGFlow's capabilities into your applications. Read the following documents for more information:
|
||||
|
||||
- [Acquire a RAGFlow API key](../../develop/acquire_ragflow_api_key.md)
|
||||
- [HTTP API reference](../../references/http_api_reference.md)
|
||||
- [Python API reference](../../references/python_api_reference.md)
|
||||
|
||||
You can use iframe to embed the created chat assistant into a third-party webpage:
|
||||
|
||||
1. Before proceeding, you must [acquire an API key](../../develop/acquire_ragflow_api_key.md); otherwise, an error message would appear.
|
||||
2. Hover over an intended chat assistant **>** **Edit** to show the **iframe** window:
|
||||
|
||||
|
||||
|
||||
3. Copy the iframe and embed it into your webpage.
|
||||
|
||||
|
||||
8
docs/guides/dataset/_category_.json
Normal file
8
docs/guides/dataset/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Datasets",
|
||||
"position": 0,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides on configuring a dataset."
|
||||
}
|
||||
}
|
||||
72
docs/guides/dataset/autokeyword_autoquestion.mdx
Normal file
72
docs/guides/dataset/autokeyword_autoquestion.mdx
Normal file
@@ -0,0 +1,72 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /autokeyword_autoquestion
|
||||
---
|
||||
|
||||
# Auto-keyword Auto-question
|
||||
import APITable from '@site/src/components/APITable';
|
||||
|
||||
Use a chat model to generate keywords or questions from each chunk in the dataset.
|
||||
|
||||
---
|
||||
|
||||
When selecting a chunking method, you can also enable auto-keyword or auto-question generation to increase retrieval rates. This feature uses a chat model to produce a specified number of keywords and questions from each created chunk, generating an "additional layer of information" from the original content.
|
||||
|
||||
:::caution WARNING
|
||||
Enabling this feature increases document indexing time and uses extra tokens, as all created chunks will be sent to the chat model for keyword or question generation.
|
||||
:::
|
||||
|
||||
## What is Auto-keyword?
|
||||
|
||||
Auto-keyword refers to the auto-keyword generation feature of RAGFlow. It uses a chat model to generate a set of keywords or synonyms from each chunk to correct errors and enhance retrieval accuracy. This feature is implemented as a slider under **Page rank** on the **Configuration** page of your dataset.
|
||||
|
||||
**Values**:
|
||||
|
||||
- 0: (Default) Disabled.
|
||||
- Between 3 and 5 (inclusive): Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 30 (maximum)
|
||||
|
||||
:::tip NOTE
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- An Auto-keyword value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
## What is Auto-question?
|
||||
|
||||
Auto-question is a feature of RAGFlow that automatically generates questions from chunks of data using a chat model. These questions (e.g. who, what, and why) also help correct errors and improve the matching of user queries. The feature usually works with FAQ retrieval scenarios involving product manuals or policy documents. And you can find this feature as a slider under **Page rank** on the **Configuration** page of your dataset.
|
||||
|
||||
**Values**:
|
||||
|
||||
- 0: (Default) Disabled.
|
||||
- 1 or 2: Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 10 (maximum)
|
||||
|
||||
:::tip NOTE
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- An Auto-question value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
## Tips from the community
|
||||
|
||||
The Auto-keyword or Auto-question values relate closely to the chunking size in your dataset. However, if you are new to this feature and unsure which value(s) to start with, the following are some value settings we gathered from our community. While they may not be accurate, they provide a starting point at the very least.
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| Use cases or typical scenarios | Document volume/length | Auto_keyword (0–30) | Auto_question (0–10) |
|
||||
|---------------------------------------------------------------------|---------------------------------|----------------------------|----------------------------|
|
||||
| Internal process guidance for employee handbook | Small, under 10 pages | 0 | 0 |
|
||||
| Customer service FAQs | Medium, 10–100 pages | 3–7 | 1–3 |
|
||||
| Technical whitepapers: Development standards, protocol details | Large, over 100 pages | 2–4 | 1–2 |
|
||||
| Contracts / Regulations / Legal clause retrieval | Large, over 50 pages | 2–5 | 0–1 |
|
||||
| Multi-repository layered new documents + old archive | Many | Adjust as appropriate |Adjust as appropriate |
|
||||
| Social media comment pool: multilingual & mixed spelling | Very large volume of short text | 8–12 | 0 |
|
||||
| Operational logs for troubleshooting | Very large volume of short text | 3–6 | 0 |
|
||||
| Marketing asset library: multilingual product descriptions | Medium | 6–10 | 1–2 |
|
||||
| Training courses / eBooks | Large | 2–5 | 1–2 |
|
||||
| Maintenance manual: equipment diagrams + steps | Medium | 3–7 | 1–2 |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
8
docs/guides/dataset/best_practices/_category_.json
Normal file
8
docs/guides/dataset/best_practices/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Best practices",
|
||||
"position": 11,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on configuring a dataset."
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,19 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /accelerate_doc_indexing
|
||||
---
|
||||
|
||||
# Accelerate indexing
|
||||
import APITable from '@site/src/components/APITable';
|
||||
|
||||
A checklist to speed up document parsing and indexing.
|
||||
|
||||
---
|
||||
|
||||
Please note that some of your settings may consume a significant amount of time. If you often find that document parsing is time-consuming, here is a checklist to consider:
|
||||
|
||||
- Use GPU to reduce embedding time.
|
||||
- On the configuration page of your dataset, switch off **Use RAPTOR to enhance retrieval**.
|
||||
- Extracting knowledge graph (GraphRAG) is time-consuming.
|
||||
- Disable **Auto-keyword** and **Auto-question** on the configuration page of your dataset, as both depend on the LLM.
|
||||
- **v0.17.0+:** If all PDFs in your dataset are plain text and do not require GPU-intensive processes like OCR (Optical Character Recognition), TSR (Table Structure Recognition), or DLA (Document Layout Analysis), you can choose **Naive** over **DeepDoc** or other time-consuming large model options in the **Document parser** dropdown. This will substantially reduce document parsing time.
|
||||
152
docs/guides/dataset/configure_knowledge_base.md
Normal file
152
docs/guides/dataset/configure_knowledge_base.md
Normal file
@@ -0,0 +1,152 @@
|
||||
---
|
||||
sidebar_position: -10
|
||||
slug: /configure_knowledge_base
|
||||
---
|
||||
|
||||
# Configure dataset
|
||||
|
||||
Most of RAGFlow's chat assistants and Agents are based on datasets. Each of RAGFlow's datasets serves as a knowledge source, *parsing* files uploaded from your local machine and file references generated in **File Management** into the real 'knowledge' for future AI chats. This guide demonstrates some basic usages of the dataset feature, covering the following topics:
|
||||
|
||||
- Create a dataset
|
||||
- Configure a dataset
|
||||
- Search for a dataset
|
||||
- Delete a dataset
|
||||
|
||||
## Create dataset
|
||||
|
||||
With multiple datasets, you can build more flexible, diversified question answering. To create your first dataset:
|
||||
|
||||
|
||||
|
||||
_Each time a dataset is created, a folder with the same name is generated in the **root/.knowledgebase** directory._
|
||||
|
||||
## Configure dataset
|
||||
|
||||
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
|
||||
|
||||
|
||||
This section covers the following topics:
|
||||
|
||||
- Select chunking method
|
||||
- Select embedding model
|
||||
- Upload file
|
||||
- Parse file
|
||||
- Intervene with file parsing results
|
||||
- Run retrieval testing
|
||||
|
||||
### Select chunking method
|
||||
|
||||
RAGFlow offers multiple built-in chunking template to facilitate chunking files of different layouts and ensure semantic integrity. From the **Built-in** chunking method dropdown under **Parse type**, you can choose the default template that suits the layouts and formats of your files. The following table shows the descriptions and the compatible file formats of each supported chunk template:
|
||||
|
||||
| **Template** | Description | File format |
|
||||
|--------------|-----------------------------------------------------------------------|-----------------------------------------------------------------------------------------------|
|
||||
| General | Files are consecutively chunked based on a preset chunk token number. | MD, MDX, DOCX, XLSX, XLS (Excel 97-2003), PPT, PDF, TXT, JPEG, JPG, PNG, TIF, GIF, CSV, JSON, EML, HTML |
|
||||
| Q&A | | XLSX, XLS (Excel 97-2003), CSV/TXT |
|
||||
| Resume | Enterprise edition only. You can also try it out on demo.ragflow.io. | DOCX, PDF, TXT |
|
||||
| Manual | | PDF |
|
||||
| Table | | XLSX, XLS (Excel 97-2003), CSV/TXT |
|
||||
| Paper | | PDF |
|
||||
| Book | | DOCX, PDF, TXT |
|
||||
| Laws | | DOCX, PDF, TXT |
|
||||
| Presentation | | PDF, PPTX |
|
||||
| Picture | | JPEG, JPG, PNG, TIF, GIF |
|
||||
| One | Each document is chunked in its entirety (as one). | DOCX, XLSX, XLS (Excel 97-2003), PDF, TXT |
|
||||
| Tag | The dataset functions as a tag set for the others. | XLSX, CSV/TXT |
|
||||
|
||||
You can also change a file's chunking method on the **Files** page.
|
||||
|
||||
|
||||
|
||||
<details>
|
||||
<summary>From v0.21.1 onward, RAGFlow supports ingestion pipeline for customized data ingestion and cleansing workflows.</summary>
|
||||
|
||||
To use a customized data pipeline:
|
||||
|
||||
1. On the **Agent** page, click **+ Create agent** > **Create from blank**.
|
||||
2. Select **Ingestion pipeline** and name your data pipeline in the popup, then click **Save** to show the data pipeline canvas.
|
||||
3. After updating your data pipeline, click **Save** on the top right of the canvas.
|
||||
4. Navigate to the **Configuration** page of your dataset, select **Choose pipeline** in **Ingestion pipeline**.
|
||||
|
||||
*Your saved data pipeline will appear in the dropdown menu below.*
|
||||
|
||||
</details>
|
||||
|
||||
### Select embedding model
|
||||
|
||||
An embedding model converts chunks into embeddings. It cannot be changed once the dataset has chunks. To switch to a different embedding model, you must delete all existing chunks in the dataset. The obvious reason is that we *must* ensure that files in a specific dataset are converted to embeddings using the *same* embedding model (ensure that they are compared in the same embedding space).
|
||||
|
||||
The following embedding models can be deployed locally:
|
||||
|
||||
- BAAI/bge-large-zh-v1.5
|
||||
- maidalun1020/bce-embedding-base_v1
|
||||
|
||||
:::danger IMPORTANT
|
||||
These two embedding models are optimized specifically for English and Chinese, so performance may be compromised if you use them to embed documents in other languages.
|
||||
:::
|
||||
|
||||
### Upload file
|
||||
|
||||
- RAGFlow's **File Management** allows you to link a file to multiple datasets, in which case each target dataset holds a reference to the file.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to **File Management** and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
|
||||
### Parse file
|
||||
|
||||
File parsing is a crucial topic in dataset configuration. The meaning of file parsing in RAGFlow is twofold: chunking files based on file layout and building embedding and full-text (keyword) indexes on these chunks. After having selected the chunking method and embedding model, you can start parsing a file:
|
||||
|
||||
|
||||
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
|
||||
### Intervene with file parsing results
|
||||
|
||||
RAGFlow features visibility and explainability, allowing you to view the chunking results and intervene where necessary. To do so:
|
||||
|
||||
1. Click on the file that completes file parsing to view the chunking results:
|
||||
|
||||
_You are taken to the **Chunk** page:_
|
||||
|
||||
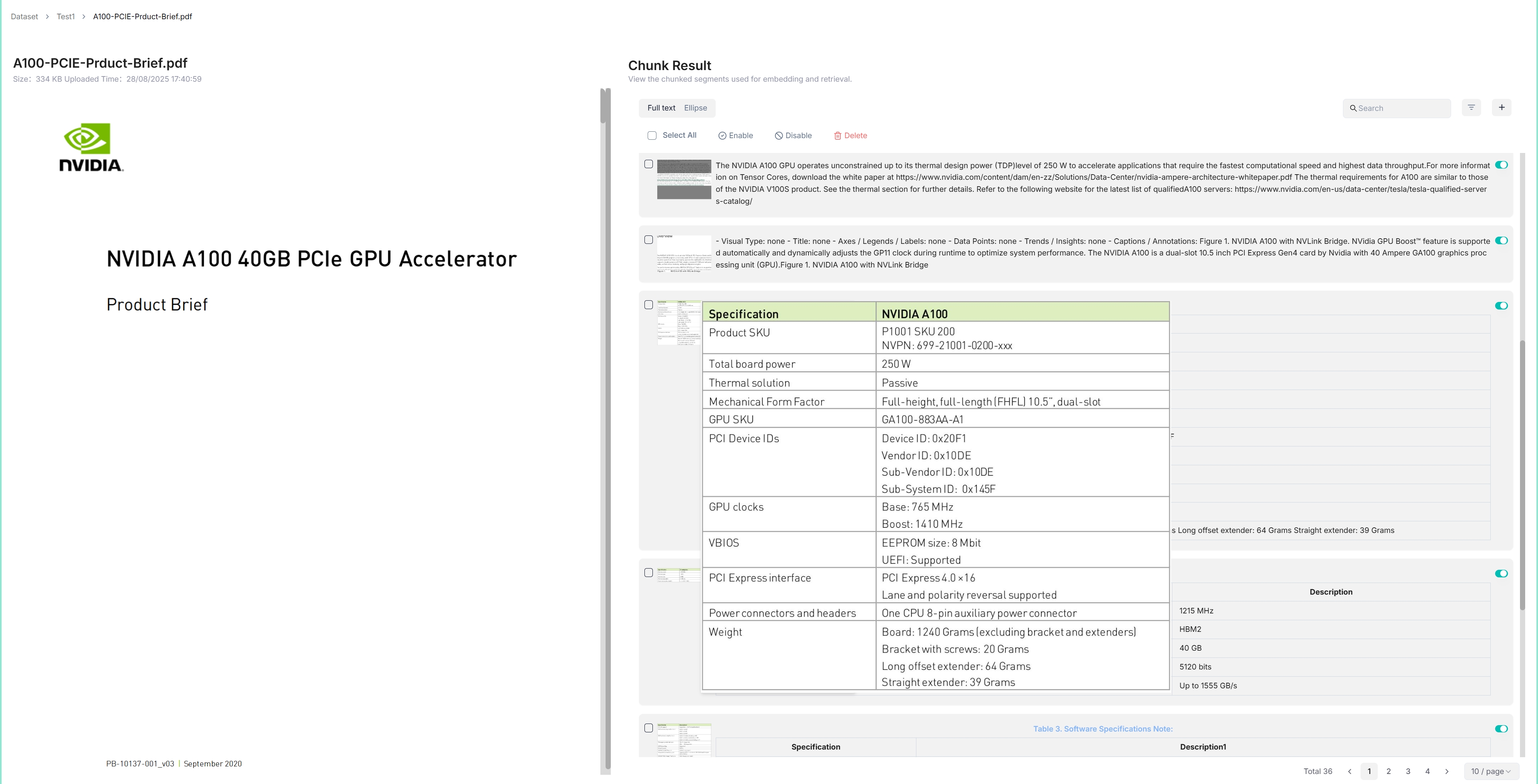
|
||||
|
||||
2. Hover over each snapshot for a quick view of each chunk.
|
||||
|
||||
3. Double-click the chunked texts to add keywords, questions, tags, or make *manual* changes where necessary:
|
||||
|
||||
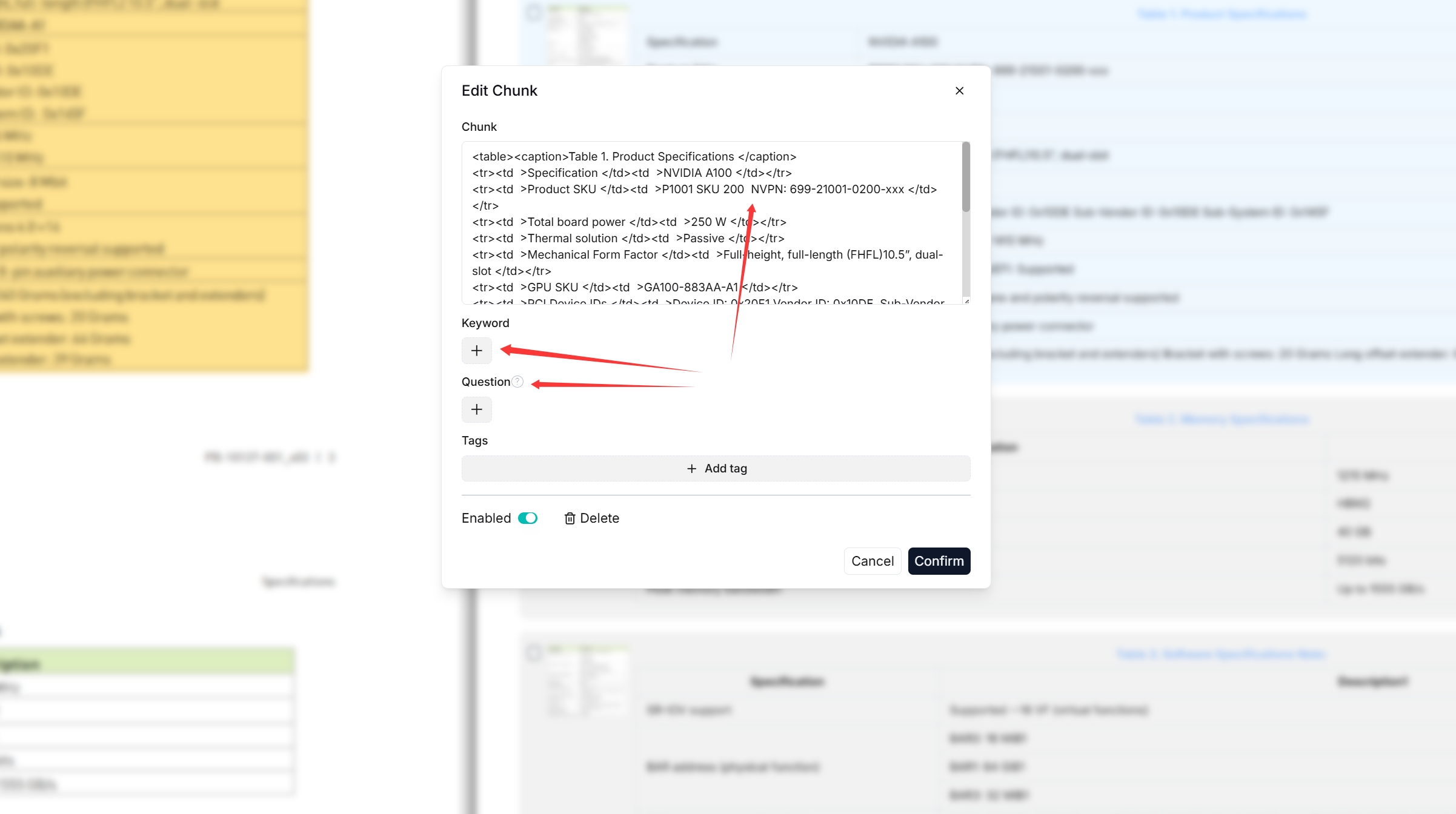
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double-check if your configurations work:
|
||||
|
||||
_As you can tell from the following, RAGFlow responds with truthful citations._
|
||||
|
||||
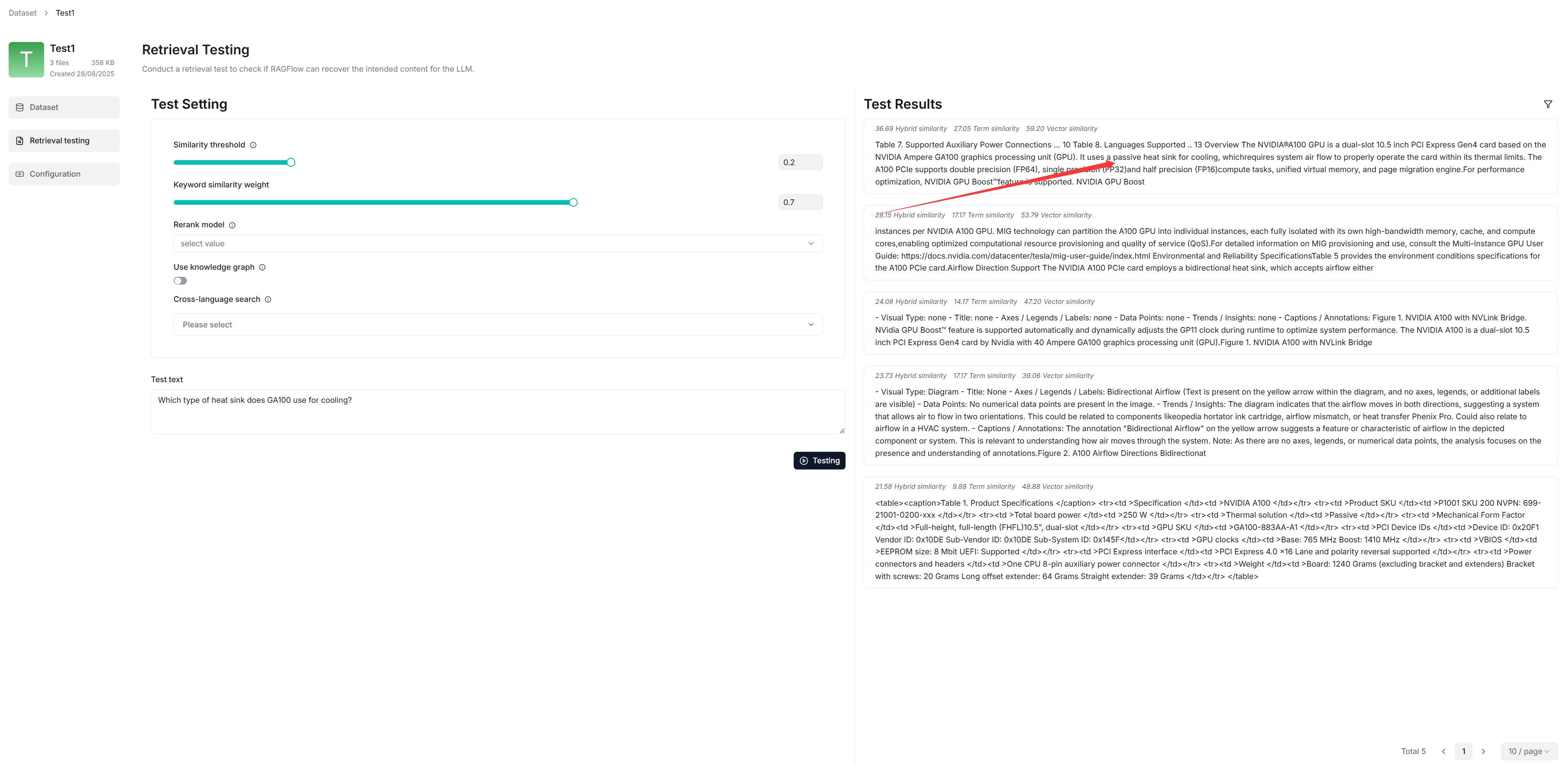
|
||||
|
||||
### Run retrieval testing
|
||||
|
||||
RAGFlow uses multiple recall of both full-text search and vector search in its chats. Prior to setting up an AI chat, consider adjusting the following parameters to ensure that the intended information always turns up in answers:
|
||||
|
||||
- Similarity threshold: Chunks with similarities below the threshold will be filtered. By default, it is set to 0.2.
|
||||
- Vector similarity weight: The percentage by which vector similarity contributes to the overall score. By default, it is set to 0.3.
|
||||
|
||||
See [Run retrieval test](./run_retrieval_test.md) for details.
|
||||
|
||||
## Search for dataset
|
||||
|
||||
As of RAGFlow v0.21.1, the search feature is still in a rudimentary form, supporting only dataset search by name.
|
||||
|
||||

|
||||
|
||||
## Delete dataset
|
||||
|
||||
You are allowed to delete a dataset. Hover your mouse over the three dot of the intended dataset card and the **Delete** option appears. Once you delete a dataset, the associated folder under **root/.knowledge** directory is AUTOMATICALLY REMOVED. The consequence is:
|
||||
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within **File Management**, are gone, but the associated files still exist in **File Management**.
|
||||
|
||||

|
||||
102
docs/guides/dataset/construct_knowledge_graph.md
Normal file
102
docs/guides/dataset/construct_knowledge_graph.md
Normal file
@@ -0,0 +1,102 @@
|
||||
---
|
||||
sidebar_position: 8
|
||||
slug: /construct_knowledge_graph
|
||||
---
|
||||
|
||||
# Construct knowledge graph
|
||||
|
||||
Generate a knowledge graph for your dataset.
|
||||
|
||||
---
|
||||
|
||||
To enhance multi-hop question-answering, RAGFlow adds a knowledge graph construction step between data extraction and indexing, as illustrated below. This step creates additional chunks from existing ones generated by your specified chunking method.
|
||||
|
||||

|
||||
|
||||
From v0.16.0 onward, RAGFlow supports constructing a knowledge graph on a dataset, allowing you to construct a *unified* graph across multiple files within your dataset. When a newly uploaded file starts parsing, the generated graph will automatically update.
|
||||
|
||||
:::danger WARNING
|
||||
Constructing a knowledge graph requires significant memory, computational resources, and tokens.
|
||||
:::
|
||||
|
||||
## Scenarios
|
||||
|
||||
Knowledge graphs are especially useful for multi-hop question-answering involving *nested* logic. They outperform traditional extraction approaches when you are performing question answering on books or works with complex entities and relationships.
|
||||
|
||||
:::tip NOTE
|
||||
RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) can also be used for multi-hop question-answering tasks. See [Enable RAPTOR](./enable_raptor.md) for details. You may use either approach or both, but ensure you understand the memory, computational, and token costs involved.
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
The system's default chat model is used to generate knowledge graph. Before proceeding, ensure that you have a chat model properly configured:
|
||||
|
||||

|
||||
|
||||
## Configurations
|
||||
|
||||
### Entity types (*Required*)
|
||||
|
||||
The types of the entities to extract from your dataset. The default types are: **organization**, **person**, **event**, and **category**. Add or remove types to suit your specific dataset.
|
||||
|
||||
### Method
|
||||
|
||||
The method to use to construct knowledge graph:
|
||||
|
||||
- **General**: Use prompts provided by [GraphRAG](https://github.com/microsoft/graphrag) to extract entities and relationships.
|
||||
- **Light**: (Default) Use prompts provided by [LightRAG](https://github.com/HKUDS/LightRAG) to extract entities and relationships. This option consumes fewer tokens, less memory, and fewer computational resources.
|
||||
|
||||
### Entity resolution
|
||||
|
||||
Whether to enable entity resolution. You can think of this as an entity deduplication switch. When enabled, the LLM will combine similar entities - e.g., '2025' and 'the year of 2025', or 'IT' and 'Information Technology' - to construct a more effective graph.
|
||||
|
||||
- (Default) Disable entity resolution.
|
||||
- Enable entity resolution. This option consumes more tokens.
|
||||
|
||||
### Community reports
|
||||
|
||||
In a knowledge graph, a community is a cluster of entities linked by relationships. You can have the LLM generate an abstract for each community, known as a community report. See [here](https://www.microsoft.com/en-us/research/blog/graphrag-improving-global-search-via-dynamic-community-selection/) for more information. This indicates whether to generate community reports:
|
||||
|
||||
- Generate community reports. This option consumes more tokens.
|
||||
- (Default) Do not generate community reports.
|
||||
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
- Entity types: *Required* - Specifies the entity types in the knowledge graph to generate. You don't have to stick with the default, but you need to customize them for your documents.
|
||||
- Method: *Optional*
|
||||
- Entity resolution: *Optional*
|
||||
- Community reports: *Optional*
|
||||
*The default knowledge graph configurations for your dataset are now set.*
|
||||
|
||||
2. Navigate to the **Files** page of your dataset, click the **Generate** button on the top right corner of the page, then select **Knowledge graph** from the dropdown to initiate the knowledge graph generation process.
|
||||
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*Once a knowledge graph is generated, the **Knowledge graph** field changes from `Not generated` to `Generated at a specific timestamp`. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
4. To use the created knowledge graph, do either of the following:
|
||||
|
||||
- In the **Chat setting** panel of your chat app, switch on the **Use knowledge graph** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the dataset(s) and switch on the **Use knowledge graph** toggle.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Does the knowledge graph automatically update when I remove a related file?
|
||||
|
||||
Nope. The knowledge graph does *not* update *until* you regenerate a knowledge graph for your dataset.
|
||||
|
||||
### How to remove a generated knowledge graph?
|
||||
|
||||
On the **Configuration** page of your dataset, find the **Knoweledge graph** field and click the recycle bin button to the right of the field.
|
||||
|
||||
### Where is the created knowledge graph stored?
|
||||
|
||||
All chunks of the created knowledge graph are stored in RAGFlow's document engine: either Elasticsearch or [Infinity](https://github.com/infiniflow/infinity).
|
||||
|
||||
### How to export a created knowledge graph?
|
||||
|
||||
Nope. Exporting a created knowledge graph is not supported. If you still consider this feature essential, please [raise an issue](https://github.com/infiniflow/ragflow/issues) explaining your use case and its importance.
|
||||
42
docs/guides/dataset/enable_excel2html.md
Normal file
42
docs/guides/dataset/enable_excel2html.md
Normal file
@@ -0,0 +1,42 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /enable_excel2html
|
||||
---
|
||||
|
||||
# Enable Excel2HTML
|
||||
|
||||
Convert complex Excel spreadsheets into HTML tables.
|
||||
|
||||
---
|
||||
|
||||
When using the **General** chunking method, you can enable the **Excel to HTML** toggle to convert spreadsheet files into HTML tables. If it is disabled, spreadsheet tables will be represented as key-value pairs. For complex tables that cannot be simply represented this way, you must enable this feature.
|
||||
|
||||
:::caution WARNING
|
||||
The feature is disabled by default. If your dataset contains spreadsheets with complex tables and you do not enable this feature, RAGFlow will not throw an error but your tables are likely to be garbled.
|
||||
:::
|
||||
|
||||
## Scenarios
|
||||
|
||||
Works with complex tables that cannot be represented as key-value pairs. Examples include spreadsheet tables with multiple columns, tables with merged cells, or multiple tables within one sheet. In such cases, consider converting these spreadsheet tables into HTML tables.
|
||||
|
||||
## Considerations
|
||||
|
||||
- The Excel2HTML feature applies only to spreadsheet files (XLSX or XLS (Excel 97-2003)).
|
||||
- This feature is associated with the **General** chunking method. In other words, it is available *only when* you select the **General** chunking method.
|
||||
- When this feature is enabled, spreadsheet tables with more than 12 rows will be split into chunks of 12 rows each.
|
||||
|
||||
## Procedure
|
||||
|
||||
1. On your dataset's **Configuration** page, select **General** as the chunking method.
|
||||
|
||||
_The **Excel to HTML** toggle appears._
|
||||
|
||||
2. Enable **Excel to HTML** if your dataset contains complex spreadsheet tables that cannot be represented as key-value pairs.
|
||||
3. Leave **Excel to HTML** disabled if your dataset has no spreadsheet tables or if its spreadsheet tables can be represented as key-value pairs.
|
||||
4. If question-answering regarding complex tables is unsatisfactory, check if **Excel to HTML** is enabled.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Should I enable this feature for PDFs with complex tables?
|
||||
|
||||
Nope. This feature applies to spreadsheet files only. Enabling **Excel to HTML** does not affect your PDFs.
|
||||
93
docs/guides/dataset/enable_raptor.md
Normal file
93
docs/guides/dataset/enable_raptor.md
Normal file
@@ -0,0 +1,93 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /enable_raptor
|
||||
---
|
||||
|
||||
# Enable RAPTOR
|
||||
|
||||
A recursive abstractive method used in long-context knowledge retrieval and summarization, balancing broad semantic understanding with fine details.
|
||||
|
||||
---
|
||||
|
||||
RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) is an enhanced document preprocessing technique introduced in a [2024 paper](https://arxiv.org/html/2401.18059v1). Designed to tackle multi-hop question-answering issues, RAPTOR performs recursive clustering and summarization of document chunks to build a hierarchical tree structure. This enables more context-aware retrieval across lengthy documents. RAGFlow v0.6.0 integrates RAPTOR for document clustering as part of its data preprocessing pipeline between data extraction and indexing, as illustrated below.
|
||||
|
||||
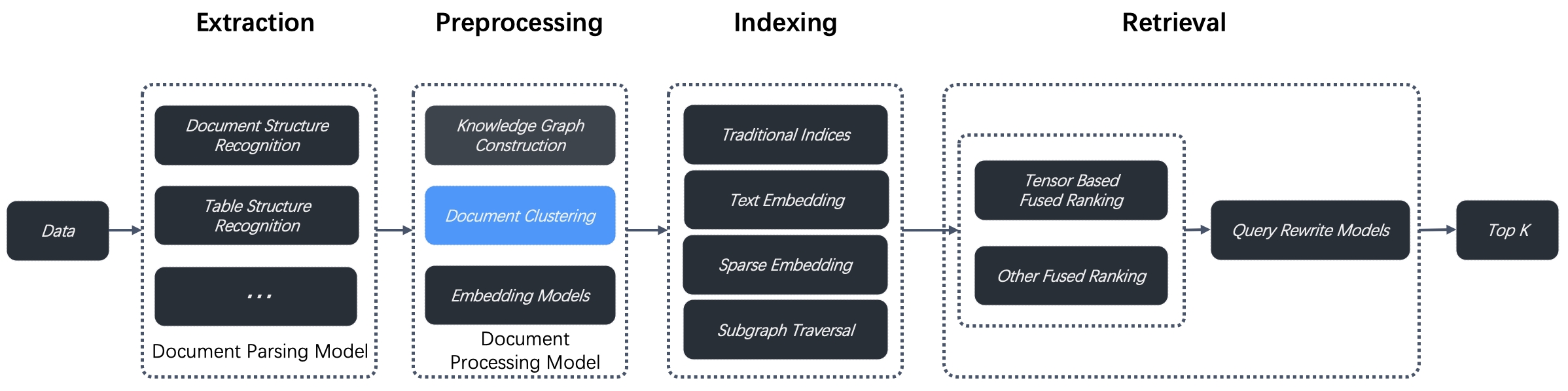
|
||||
|
||||
Our tests with this new approach demonstrate state-of-the-art (SOTA) results on question-answering tasks requiring complex, multi-step reasoning. By combining RAPTOR retrieval with our built-in chunking methods and/or other retrieval-augmented generation (RAG) approaches, you can further improve your question-answering accuracy.
|
||||
|
||||
:::danger WARNING
|
||||
Enabling RAPTOR requires significant memory, computational resources, and tokens.
|
||||
:::
|
||||
|
||||
## Basic principles
|
||||
|
||||
After the original documents are divided into chunks, the chunks are clustered by semantic similarity rather than by their original order in the text. Clusters are then summarized into higher-level chunks by your system's default chat model. This process is applied recursively, forming a tree structure with various levels of summarization from the bottom up. As illustrated in the figure below, the initial chunks form the leaf nodes (shown in blue) and are recursively summarized into a root node (shown in orange).
|
||||
|
||||
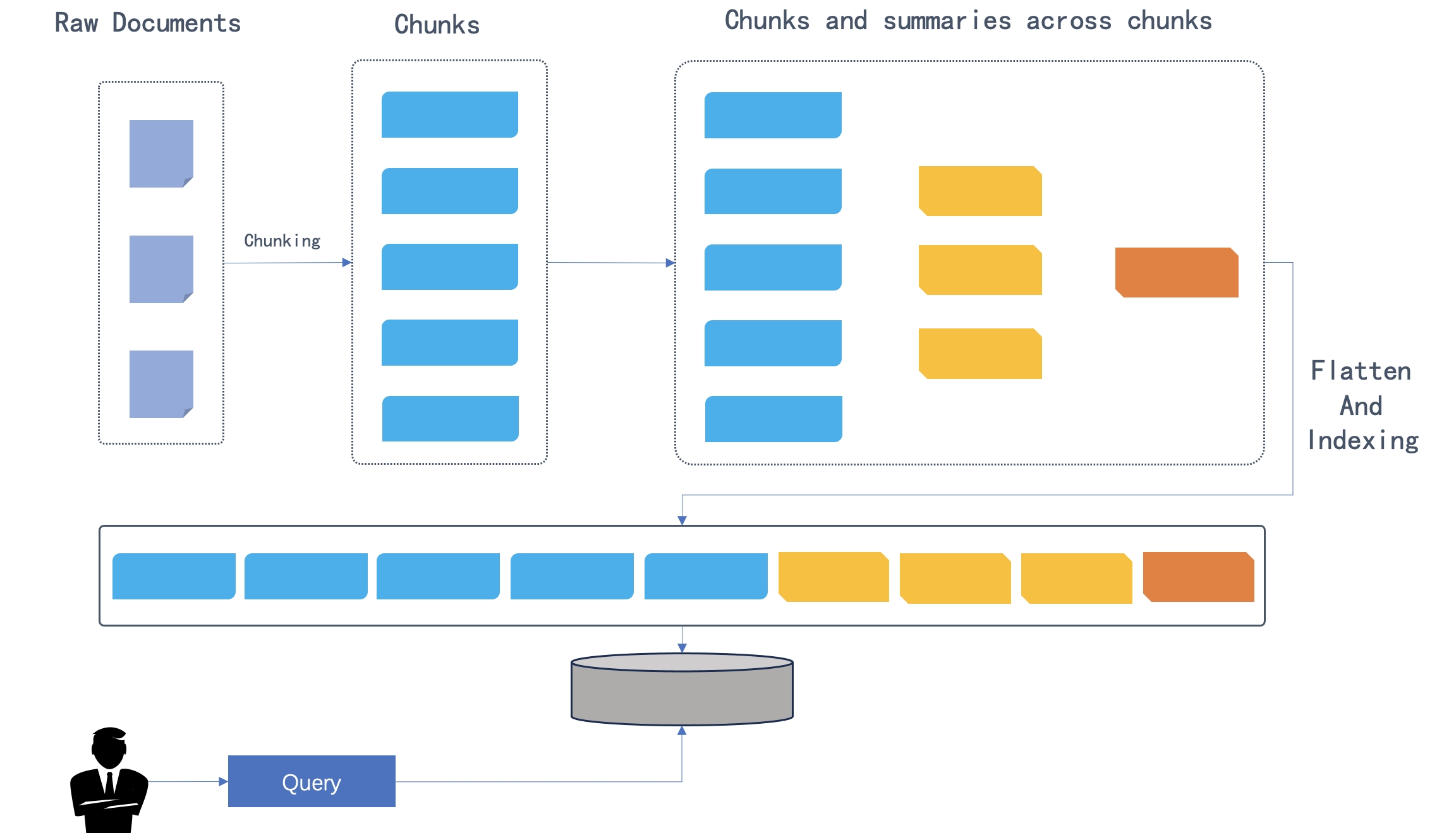
|
||||
|
||||
The recursive clustering and summarization capture a broad understanding (by the root node) as well as fine details (by the leaf nodes) necessary for multi-hop question-answering.
|
||||
|
||||
## Scenarios
|
||||
|
||||
For multi-hop question-answering tasks involving complex, multi-step reasoning, a semantic gap often exists between the question and its answer. As a result, searching with the question often fails to retrieve the relevant chunks that contribute to the correct answer. RAPTOR addresses this challenge by providing the chat model with richer and more context-aware and relevant chunks to summarize, enabling a holistic understanding without losing granular details.
|
||||
|
||||
:::tip NOTE
|
||||
Knowledge graphs can also be used for multi-hop question-answering tasks. See [Construct knowledge graph](./construct_knowledge_graph.md) for details. You may use either approach or both, but ensure you understand the memory, computational, and token costs involved.
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
The system's default chat model is used to summarize clustered content. Before proceeding, ensure that you have a chat model properly configured:
|
||||
|
||||

|
||||
|
||||
## Configurations
|
||||
|
||||
The RAPTOR feature is disabled by default. To enable it, manually switch on the **Use RAPTOR to enhance retrieval** toggle on your dataset's **Configuration** page.
|
||||
|
||||
### Prompt
|
||||
|
||||
The following prompt will be applied *recursively* for cluster summarization, with `{cluster_content}` serving as an internal parameter. We recommend that you keep it as-is for now. The design will be updated in due course.
|
||||
|
||||
```
|
||||
Please summarize the following paragraphs... Paragraphs as following:
|
||||
{cluster_content}
|
||||
The above is the content you need to summarize.
|
||||
```
|
||||
|
||||
### Max token
|
||||
|
||||
The maximum number of tokens per generated summary chunk. Defaults to 256, with a maximum limit of 2048.
|
||||
|
||||
### Threshold
|
||||
|
||||
In RAPTOR, chunks are clustered by their semantic similarity. The **Threshold** parameter sets the minimum similarity required for chunks to be grouped together.
|
||||
|
||||
It defaults to 0.1, with a maximum limit of 1. A higher **Threshold** means fewer chunks in each cluster, while a lower one means more.
|
||||
|
||||
### Max cluster
|
||||
|
||||
The maximum number of clusters to create. Defaults to 64, with a maximum limit of 1024.
|
||||
|
||||
### Random seed
|
||||
|
||||
A random seed. Click **+** to change the seed value.
|
||||
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
- Prompt: *Optional* - We recommend that you keep it as-is until you understand the mechanism behind.
|
||||
- Max token: *Optional*
|
||||
- Threshold: *Optional*
|
||||
- Max cluster: *Optional*
|
||||
|
||||
2. Navigate to the **Files** page of your dataset, click the **Generate** button on the top right corner of the page, then select **RAPTOR** from the dropdown to initiate the RAPTOR build process.
|
||||
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*The **RAPTOR** field changes from `Not generated` to `Generated at a specific timestamp` when a RAPTOR hierarchical tree structure is generated. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
4. Once a RAPTOR hierarchical tree structure is generated, your chat assistant and **Retrieval** agent component will use it for retrieval as a default.
|
||||
39
docs/guides/dataset/extract_table_of_contents.md
Normal file
39
docs/guides/dataset/extract_table_of_contents.md
Normal file
@@ -0,0 +1,39 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /enable_table_of_contents
|
||||
---
|
||||
|
||||
# Extract table of contents
|
||||
|
||||
Extract table of contents (TOC) from documents to provide long context RAG and improve retrieval.
|
||||
|
||||
---
|
||||
|
||||
During indexing, this technique uses LLM to extract and generate chapter information, which is added to each chunk to provide sufficient global context. At the retrieval stage, it first uses the chunks matched by search, then supplements missing chunks based on the table of contents structure. This addresses issues caused by chunk fragmentation and insufficient context, improving answer quality.
|
||||
|
||||
:::danger WARNING
|
||||
Enabling TOC extraction requires significant memory, computational resources, and tokens.
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
The system's default chat model is used to summarize clustered content. Before proceeding, ensure that you have a chat model properly configured:
|
||||
|
||||

|
||||
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page.
|
||||
|
||||
2. Enable **TOC Enhance**.
|
||||
|
||||
3. To use this technique during retrieval, do either of the following:
|
||||
|
||||
- In the **Chat setting** panel of your chat app, switch on the **TOC Enhance** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the dataset(s) and switch on the **TOC Enhance** toggle.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Will previously parsed files be searched using the TOC enhancement feature once I enable `TOC Enhance`?
|
||||
|
||||
No. Only files parsed after you enable **TOC Enhance** will be searched using the TOC enhancement feature. To apply this feature to files parsed before enabling **TOC Enhance**, you must reparse them.
|
||||
95
docs/guides/dataset/run_retrieval_test.md
Normal file
95
docs/guides/dataset/run_retrieval_test.md
Normal file
@@ -0,0 +1,95 @@
|
||||
---
|
||||
sidebar_position: 10
|
||||
slug: /run_retrieval_test
|
||||
---
|
||||
|
||||
# Run retrieval test
|
||||
|
||||
Conduct a retrieval test on your dataset to check whether the intended chunks can be retrieved.
|
||||
|
||||
---
|
||||
|
||||
After your files are uploaded and parsed, it is recommended that you run a retrieval test before proceeding with the chat assistant configuration. Running a retrieval test is *not* an unnecessary or superfluous step at all! Just like fine-tuning a precision instrument, RAGFlow requires careful tuning to deliver optimal question answering performance. Your dataset settings, chat assistant configurations, and the specified large and small models can all significantly impact the final results. Running a retrieval test verifies whether the intended chunks can be recovered, allowing you to quickly identify areas for improvement or pinpoint any issue that needs addressing. For instance, when debugging your question answering system, if you know that the correct chunks can be retrieved, you can focus your efforts elsewhere. For example, in issue [#5627](https://github.com/infiniflow/ragflow/issues/5627), the problem was found to be due to the LLM's limitations.
|
||||
|
||||
During a retrieval test, chunks created from your specified chunking method are retrieved using a hybrid search. This search combines weighted keyword similarity with either weighted vector cosine similarity or a weighted reranking score, depending on your settings:
|
||||
|
||||
- If no rerank model is selected, weighted keyword similarity will be combined with weighted vector cosine similarity.
|
||||
- If a rerank model is selected, weighted keyword similarity will be combined with weighted vector reranking score.
|
||||
|
||||
In contrast, chunks created from [knowledge graph construction](./construct_knowledge_graph.md) are retrieved solely using vector cosine similarity.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Your files are uploaded and successfully parsed before running a retrieval test.
|
||||
- A knowledge graph must be successfully built before enabling **Use knowledge graph**.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Similarity threshold
|
||||
|
||||
This sets the bar for retrieving chunks: chunks with similarities below the threshold will be filtered out. By default, the threshold is set to 0.2. This means that only chunks with hybrid similarity score of 20 or higher will be retrieved.
|
||||
|
||||
### Vector similarity weight
|
||||
|
||||
This sets the weight of vector similarity in the composite similarity score, whether used with vector cosine similarity or a reranking score. By default, it is set to 0.3, making the weight of the other component 0.7 (1 - 0.3).
|
||||
|
||||
### Rerank model
|
||||
|
||||
- If left empty, RAGFlow will use a combination of weighted keyword similarity and weighted vector cosine similarity.
|
||||
- If a rerank model is selected, weighted keyword similarity will be combined with weighted vector reranking score.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Using a rerank model will significantly increase the time to receive a response.
|
||||
:::
|
||||
|
||||
### Use knowledge graph
|
||||
|
||||
In a knowledge graph, an entity description, a relationship description, or a community report each exists as an independent chunk. This switch indicates whether to add these chunks to the retrieval.
|
||||
|
||||
The switch is disabled by default. When enabled, RAGFlow performs the following during a retrieval test:
|
||||
|
||||
1. Extract entities and entity types from your query using the LLM.
|
||||
2. Retrieve top N entities from the graph based on their PageRank values, using the extracted entity types.
|
||||
3. Find similar entities and their N-hop relationships from the graph using the embeddings of the extracted query entities.
|
||||
4. Retrieve similar relationships from the graph using the query embedding.
|
||||
5. Rank these retrieved entities and relationships by multiplying each one's PageRank value with its similarity score to the query, returning the top n as the final retrieval.
|
||||
6. Retrieve the report for the community involving the most entities in the final retrieval.
|
||||
*The retrieved entity descriptions, relationship descriptions, and the top 1 community report are sent to the LLM for content generation.*
|
||||
|
||||
:::danger IMPORTANT
|
||||
Using a knowledge graph in a retrieval test will significantly increase the time to receive a response.
|
||||
:::
|
||||
|
||||
### Cross-language search
|
||||
|
||||
To perform a [cross-language search](../../references/glossary.mdx#cross-language-search), select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query entered in the Test text field into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||
|
||||
:::tip NOTE
|
||||
- When selecting target languages, please ensure that these languages are present in the dataset to guarantee an effective search.
|
||||
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||
:::
|
||||
|
||||
### Test text
|
||||
|
||||
This field is where you put in your testing query.
|
||||
|
||||
## Procedure
|
||||
|
||||
1. Navigate to the **Retrieval testing** page of your dataset, enter your query in **Test text**, and click **Testing** to run the test.
|
||||
2. If the results are unsatisfactory, tune the options listed in the Configuration section and rerun the test.
|
||||
|
||||
*The following is a screenshot of a retrieval test conducted without using knowledge graph. It demonstrates a hybrid search combining weighted keyword similarity and weighted vector cosine similarity. The overall hybrid similarity score is 28.56, calculated as 25.17 (term similarity score) x 0.7 + 36.49 (vector similarity score) x 0.3:*
|
||||

|
||||
|
||||
*The following is a screenshot of a retrieval test conducted using a knowledge graph. It shows that only vector similarity is used for knowledge graph-generated chunks:*
|
||||

|
||||
|
||||
:::caution WARNING
|
||||
If you have adjusted the default settings, such as keyword similarity weight or similarity threshold, to achieve the optimal results, be aware that these changes will not be automatically saved. You must apply them to your chat assistant settings or the **Retrieval** agent component settings.
|
||||
:::
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Is an LLM used when the Use Knowledge Graph switch is enabled?
|
||||
|
||||
Yes, your LLM will be involved to analyze your query and extract the related entities and relationship from the knowledge graph. This also explains why additional tokens and time will be consumed.
|
||||
76
docs/guides/dataset/select_pdf_parser.md
Normal file
76
docs/guides/dataset/select_pdf_parser.md
Normal file
@@ -0,0 +1,76 @@
|
||||
---
|
||||
sidebar_position: -4
|
||||
slug: /select_pdf_parser
|
||||
---
|
||||
|
||||
# Select PDF parser
|
||||
|
||||
Select a visual model for parsing your PDFs.
|
||||
|
||||
---
|
||||
|
||||
RAGFlow isn't one-size-fits-all. It is built for flexibility and supports deeper customization to accommodate more complex use cases. From v0.17.0 onwards, RAGFlow decouples DeepDoc-specific data extraction tasks from chunking methods **for PDF files**. This separation enables you to autonomously select a visual model for OCR (Optical Character Recognition), TSR (Table Structure Recognition), and DLR (Document Layout Recognition) tasks that balances speed and performance to suit your specific use cases. If your PDFs contain only plain text, you can opt to skip these tasks by selecting the **Naive** option, to reduce the overall parsing time.
|
||||
|
||||
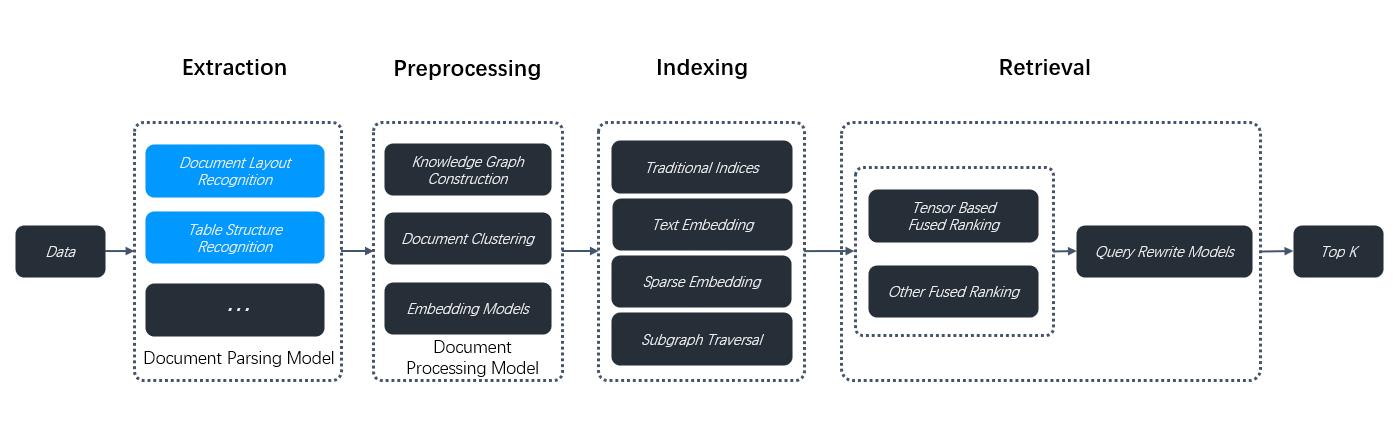
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- The PDF parser dropdown menu appears only when you select a chunking method compatible with PDFs, including:
|
||||
- **General**
|
||||
- **Manual**
|
||||
- **Paper**
|
||||
- **Book**
|
||||
- **Laws**
|
||||
- **Presentation**
|
||||
- **One**
|
||||
- To use a third-party visual model for parsing PDFs, ensure you have set a default img2txt model under **Set default models** on the **Model providers** page.
|
||||
|
||||
## Quickstart
|
||||
|
||||
1. On your dataset's **Configuration** page, select a chunking method, say **General**.
|
||||
|
||||
_The **PDF parser** dropdown menu appears._
|
||||
|
||||
2. Select the option that works best with your scenario:
|
||||
|
||||
- DeepDoc: (Default) The default visual model performing OCR, TSR, and DLR tasks on PDFs, which can be time-consuming.
|
||||
- Naive: Skip OCR, TSR, and DLR tasks if *all* your PDFs are plain text.
|
||||
- MinerU: An experimental feature.
|
||||
- A third-party visual model provided by a specific model provider.
|
||||
|
||||
:::danger IMPORTANG
|
||||
MinerU PDF document parsing is available starting from v0.21.1. To use this feature, follow these steps:
|
||||
|
||||
1. Before deploying ragflow-server, update your **docker/.env** file:
|
||||
- Enable `HF_ENDPOINT=https://hf-mirror.com`
|
||||
- Add a MinerU entry: `MINERU_EXECUTABLE=/ragflow/uv_tools/.venv/bin/mineru`
|
||||
|
||||
2. Start the ragflow-server and run the following commands inside the container:
|
||||
|
||||
```bash
|
||||
mkdir uv_tools
|
||||
cd uv_tools
|
||||
uv venv .venv
|
||||
source .venv/bin/activate
|
||||
uv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple
|
||||
```
|
||||
|
||||
3. Restart the ragflow-server.
|
||||
4. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and slect **MinerU** in **PDF parser**.
|
||||
5. If you use a custom ingestion pipeline instead, you must also complete the first three steps before selecting **MinerU** in the **Parsing method** section of the **Parser** component.
|
||||
:::
|
||||
|
||||
:::caution WARNING
|
||||
Third-party visual models are marked **Experimental**, because we have not fully tested these models for the aforementioned data extraction tasks.
|
||||
:::
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### When should I select DeepDoc or a third-party visual model as the PDF parser?
|
||||
|
||||
Use a visual model to extract data if your PDFs contain formatted or image-based text rather than plain text. DeepDoc is the default visual model but can be time-consuming. You can also choose a lightweight or high-performance img2txt model depending on your needs and hardware capabilities.
|
||||
|
||||
### Can I select a visual model to parse my DOCX files?
|
||||
|
||||
No, you cannot. This dropdown menu is for PDFs only. To use this feature, convert your DOCX files to PDF first.
|
||||
|
||||
32
docs/guides/dataset/set_metadata.md
Normal file
32
docs/guides/dataset/set_metadata.md
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
sidebar_position: -7
|
||||
slug: /set_metada
|
||||
---
|
||||
|
||||
# Set metadata
|
||||
|
||||
Add metadata to an uploaded file
|
||||
|
||||
---
|
||||
|
||||
On the **Dataset** page of your dataset, you can add metadata to any uploaded file. This approach enables you to 'tag' additional information like URL, author, date, and more to an existing file. In an AI-powered chat, such information will be sent to the LLM with the retrieved chunks for content generation.
|
||||
|
||||
For example, if you have a dataset of HTML files and want the LLM to cite the source URL when responding to your query, add a `"url"` parameter to each file's metadata.
|
||||
|
||||

|
||||
|
||||
:::tip NOTE
|
||||
Ensure that your metadata is in JSON format; otherwise, your updates will not be applied.
|
||||
:::
|
||||
|
||||
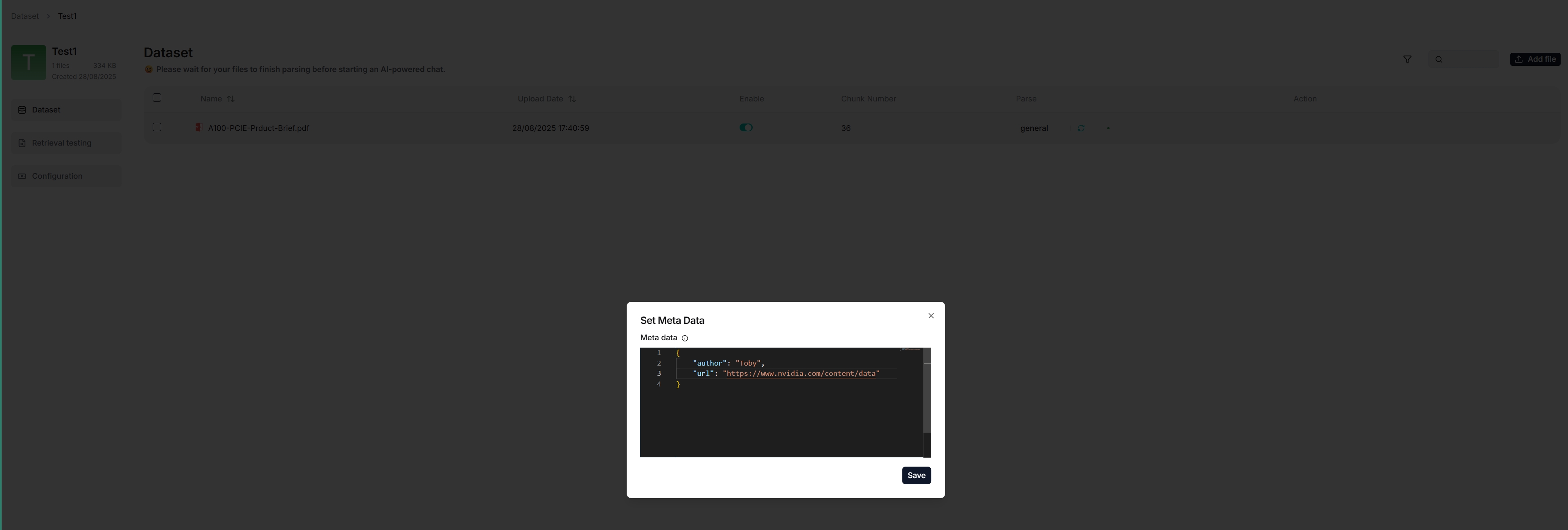
|
||||
|
||||
## Related APIs
|
||||
|
||||
[Retrieve chunks](../../references/http_api_reference.md#retrieve-chunks)
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Can I set metadata for multiple documents at once?
|
||||
|
||||
No, you must set metadata *individually* for each document, as RAGFlow does not support batch setting of metadata. If you still consider this feature essential, please [raise an issue](https://github.com/infiniflow/ragflow/issues) explaining your use case and its importance.
|
||||
39
docs/guides/dataset/set_page_rank.md
Normal file
39
docs/guides/dataset/set_page_rank.md
Normal file
@@ -0,0 +1,39 @@
|
||||
---
|
||||
sidebar_position: -2
|
||||
slug: /set_page_rank
|
||||
---
|
||||
|
||||
# Set page rank
|
||||
|
||||
Create a step-retrieval strategy using page rank.
|
||||
|
||||
---
|
||||
|
||||
## Scenario
|
||||
|
||||
In an AI-powered chat, you can configure a chat assistant or an agent to respond using knowledge retrieved from multiple specified datasets (datasets), provided that they employ the same embedding model. In situations where you prefer information from certain dataset(s) to take precedence or to be retrieved first, you can use RAGFlow's page rank feature to increase the ranking of chunks from these datasets. For example, if you have configured a chat assistant to draw from two datasets, dataset A for 2024 news and dataset B for 2023 news, but wish to prioritize news from year 2024, this feature is particularly useful.
|
||||
|
||||
:::info NOTE
|
||||
It is important to note that this 'page rank' feature operates at the level of the entire dataset rather than on individual files or documents.
|
||||
:::
|
||||
|
||||
## Configuration
|
||||
|
||||
On the **Configuration** page of your dataset, drag the slider under **Page rank** to set the page rank value for your dataset. You are also allowed to input the intended page rank value in the field next to the slider.
|
||||
|
||||
:::info NOTE
|
||||
The page rank value must be an integer. Range: [0,100]
|
||||
|
||||
- 0: Disabled (Default)
|
||||
- A specific value: enabled
|
||||
:::
|
||||
|
||||
:::tip NOTE
|
||||
If you set the page rank value to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
## Scoring mechanism
|
||||
|
||||
If you configure a chat assistant's **similarity threshold** to 0.2, only chunks with a hybrid score greater than 0.2 x 100 = 20 will be retrieved and sent to the chat model for content generation. This initial filtering step is crucial for narrowing down relevant information.
|
||||
|
||||
If you have assigned a page rank of 1 to dataset A (2024 news) and 0 to dataset B (2023 news), the final hybrid scores of the retrieved chunks will be adjusted accordingly. A chunk retrieved from dataset A with an initial score of 50 will receive a boost of 1 x 100 = 100 points, resulting in a final score of 50 + 1 x 100 = 150. In this way, chunks retrieved from dataset A will always precede chunks from dataset B.
|
||||
103
docs/guides/dataset/use_tag_sets.md
Normal file
103
docs/guides/dataset/use_tag_sets.md
Normal file
@@ -0,0 +1,103 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /use_tag_sets
|
||||
---
|
||||
|
||||
# Use tag set
|
||||
|
||||
Use a tag set to auto-tag chunks in your datasets.
|
||||
|
||||
---
|
||||
|
||||
Retrieval accuracy is the touchstone for a production-ready RAG framework. In addition to retrieval-enhancing approaches like auto-keyword, auto-question, and knowledge graph, RAGFlow introduces an auto-tagging feature to address semantic gaps. The auto-tagging feature automatically maps tags in the user-defined tag sets to relevant chunks within your dataset based on similarity with each chunk. This automation mechanism allows you to apply an additional "layer" of domain-specific knowledge to existing datasets, which is particularly useful when dealing with a large number of chunks.
|
||||
|
||||
To use this feature, ensure you have at least one properly configured tag set, specify the tag set(s) on the **Configuration** page of your dataset, and then re-parse your documents to initiate the auto-tagging process. During this process, each chunk in your dataset is compared with every entry in the specified tag set(s), and tags are automatically applied based on similarity.
|
||||
|
||||
## Scenarios
|
||||
|
||||
Auto-tagging applies in situations where chunks are so similar to each other that the intended chunks cannot be distinguished from the rest. For example, when you have a few chunks about iPhone and a majority about iPhone case or iPhone accessaries, it becomes difficult to retrieve those chunks about iPhone without additional information.
|
||||
|
||||
## 1. Create tag set
|
||||
|
||||
You can consider a tag set as a closed set, and the tags to attach to the chunks in your dataset are *exclusively* from the specified tag set. You use a tag set to "inform" RAGFlow which chunks to tag and which tags to apply.
|
||||
|
||||
### Prepare a tag table file
|
||||
|
||||
A tag set can comprise one or multiple table files in XLSX, CSV, or TXT formats. Each table file in the tag set contains two columns, **Description** and **Tag**:
|
||||
|
||||
- The first column provides descriptions of the tags listed in the second column. These descriptions can be example chunks or example queries. Similarity will be calculated between each entry in this column and every chunk in your dataset.
|
||||
- The **Tag** column includes tags to pair with the description entries. Multiple tags should be separated by a comma (,).
|
||||
|
||||
:::tip NOTE
|
||||
As a rule of thumb, consider including the following entries in your tag table:
|
||||
|
||||
- Descriptions of intended chunks, along with their corresponding tags.
|
||||
- User queries that fail to retrieve the correct responses using other methods, ensuring their tags match the intended chunks in your dataset.
|
||||
:::
|
||||
|
||||
### Create a tag set
|
||||
|
||||
:::danger IMPORTANT
|
||||
A tag set is *not* involved in document indexing or retrieval. Do not specify a tag set when configuring your chat assistant or agent.
|
||||
:::
|
||||
|
||||
1. Click **+ Create dataset** to create a dataset.
|
||||
2. Navigate to the **Configuration** page of the created dataset, select **Built-in** in **Ingestion pipeline**, then choose **Tag** as the default chunking method from the **Built-in** drop-down menu.
|
||||
3. Go back to the **Files** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||
_A tag cloud appears under the **Tag view** section, indicating the tag set is created:_
|
||||

|
||||
4. Click the **Table** tab to view the tag frequency table:
|
||||

|
||||
|
||||
## 2. Tag chunks
|
||||
|
||||
Once a tag set is created, you can apply it to your dataset:
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset.
|
||||
2. Select the tag set from the **Tag sets** dropdown and click **Save** to confirm.
|
||||
|
||||
:::tip NOTE
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||
|
||||
## 3. Update tag set
|
||||
|
||||
Creating a tag set is *not* for once and for all. Oftentimes, you may find it necessary to update or delete existing tags or add new entries.
|
||||
|
||||
- You can update the existing tag set in the tag frequency table.
|
||||
- To add new entries, you can add and parse new table files in XLSX, CSV, or TXT formats.
|
||||
|
||||
### Update tag set in tag frequency table
|
||||
|
||||
1. Navigate to the **Configuration** page in your tag set.
|
||||
2. Click the **Table** tab under **Tag view** to view the tag frequncy table, where you can update tag names or delete tags.
|
||||
|
||||
:::danger IMPORTANT
|
||||
When a tag set is updated, you must re-parse the documents in your dataset so that their tags can be updated accordingly.
|
||||
:::
|
||||
|
||||
### Add new table files
|
||||
|
||||
1. Navigate to the **Configuration** page in your tag set.
|
||||
2. Navigate to the **Dataset** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you add new table files to your tag set, it is at your own discretion whether to re-parse your documents in your datasets.
|
||||
:::
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Can I reference more than one tag set?
|
||||
|
||||
Yes, you can. Usually one tag set suffices. When using multiple tag sets, ensure they are independent of each other; otherwise, consider merging your tag sets.
|
||||
|
||||
### Difference between a tag set and a standard dataset?
|
||||
|
||||
A standard dataset is a dataset. It will be searched by RAGFlow's document engine and the retrieved chunks will be fed to the LLM. In contrast, a tag set is used solely to attach tags to chunks within your dataset. It does not directly participate in the retrieval process, and you should not choose a tag set when selecting datasets for your chat assistant or agent.
|
||||
|
||||
### Difference between auto-tag and auto-keyword?
|
||||
|
||||
Both features enhance retrieval in RAGFlow. The auto-keyword feature relies on the LLM and consumes a significant number of tokens, whereas the auto-tag feature is based on vector similarity and predefined tag set(s). You can view the keywords applied in the auto-keyword feature as an open set, as they are generated by the LLM. In contrast, a tag set can be considered a user-defined close set, requiring upload tag set(s) in specified formats before use.
|
||||
90
docs/guides/manage_files.md
Normal file
90
docs/guides/manage_files.md
Normal file
@@ -0,0 +1,90 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /manage_files
|
||||
---
|
||||
|
||||
# Files
|
||||
|
||||
RAGFlow's file management allows you to upload files individually or in bulk. You can then link an uploaded file to multiple target datasets. This guide showcases some basic usages of the file management feature.
|
||||
|
||||
:::info IMPORTANT
|
||||
Compared to uploading files directly to various datasets, uploading them to RAGFlow's file management and then linking them to different datasets is *not* an unnecessary step, particularly when you want to delete some parsed files or an entire dataset but retain the original files.
|
||||
:::
|
||||
|
||||
## Create folder
|
||||
|
||||
RAGFlow's file management allows you to establish your file system with nested folder structures. To create a folder in the root directory of RAGFlow:
|
||||
|
||||

|
||||
|
||||
:::caution NOTE
|
||||
Each dataset in RAGFlow has a corresponding folder under the **root/.knowledgebase** directory. You are not allowed to create a subfolder within it.
|
||||
:::
|
||||
|
||||
## Upload file
|
||||
|
||||
RAGFlow's file management supports file uploads from your local machine, allowing both individual and bulk uploads:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Preview file
|
||||
|
||||
RAGFlow's file management supports previewing files in the following formats:
|
||||
|
||||
- Documents (PDF, DOCS)
|
||||
- Tables (XLSX)
|
||||
- Pictures (JPEG, JPG, PNG, TIF, GIF)
|
||||
|
||||

|
||||
|
||||
## Link file to datasets
|
||||
|
||||
RAGFlow's file management allows you to *link* an uploaded file to multiple datasets, creating a file reference in each target dataset. Therefore, deleting a file in your file management will AUTOMATICALLY REMOVE all related file references across the datasets.
|
||||
|
||||

|
||||
|
||||
You can link your file to one dataset or multiple datasets at one time:
|
||||
|
||||

|
||||
|
||||
## Move file to a specific folder
|
||||
|
||||

|
||||
|
||||
## Search files or folders
|
||||
|
||||
**File Management** only supports file name and folder name filtering in the current directory (files or folders in the child directory will not be retrieved).
|
||||
|
||||

|
||||
|
||||
## Rename file or folder
|
||||
|
||||
RAGFlow's file management allows you to rename a file or folder:
|
||||
|
||||

|
||||
|
||||
|
||||
## Delete files or folders
|
||||
|
||||
RAGFlow's file management allows you to delete files or folders individually or in bulk.
|
||||
|
||||
To delete a file or folder:
|
||||
|
||||

|
||||
|
||||
To bulk delete files or folders:
|
||||
|
||||

|
||||
|
||||
> - You are not allowed to delete the **root/.knowledgebase** folder.
|
||||
> - Deleting files that have been linked to datasets will **AUTOMATICALLY REMOVE** all associated file references across the datasets.
|
||||
|
||||
## Download uploaded file
|
||||
|
||||
RAGFlow's file management allows you to download an uploaded file:
|
||||
|
||||

|
||||
|
||||
> As of RAGFlow v0.21.1, bulk download is not supported, nor can you download an entire folder.
|
||||
390
docs/guides/manage_users_and_services.md
Normal file
390
docs/guides/manage_users_and_services.md
Normal file
@@ -0,0 +1,390 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /manage_users_and_services
|
||||
---
|
||||
|
||||
|
||||
# Admin CLI and Admin Service
|
||||
|
||||
|
||||
|
||||
The Admin CLI and Admin Service form a client-server architectural suite for RAGflow system administration. The Admin CLI serves as an interactive command-line interface that receives instructions and displays execution results from the Admin Service in real-time. This duo enables real-time monitoring of system operational status, supporting visibility into RAGflow Server services and dependent components including MySQL, Elasticsearch, Redis, and MinIO. In administrator mode, they provide user management capabilities that allow viewing users and performing critical operations—such as user creation, password updates, activation status changes, and comprehensive user data deletion—even when corresponding web interface functionalities are disabled.
|
||||
|
||||
|
||||
|
||||
## Starting the Admin Service
|
||||
|
||||
### Launching from source code
|
||||
|
||||
1. Before start Admin Service, please make sure RAGFlow system is already started.
|
||||
|
||||
2. Launch from source code:
|
||||
|
||||
```bash
|
||||
python admin/server/admin_server.py
|
||||
```
|
||||
|
||||
The service will start and listen for incoming connections from the CLI on the configured port.
|
||||
|
||||
### Using docker image
|
||||
|
||||
1. Before startup, please configure the `docker_compose.yml` file to enable admin server:
|
||||
|
||||
```bash
|
||||
command:
|
||||
- --enable-adminserver
|
||||
```
|
||||
|
||||
2. Start the containers, the service will start and listen for incoming connections from the CLI on the configured port.
|
||||
|
||||
|
||||
|
||||
## Using the Admin CLI
|
||||
|
||||
1. Ensure the Admin Service is running.
|
||||
|
||||
2. Install ragflow-cli.
|
||||
|
||||
```bash
|
||||
pip install ragflow-cli==0.21.1
|
||||
```
|
||||
|
||||
3. Launch the CLI client:
|
||||
|
||||
```bash
|
||||
ragflow-cli -h 127.0.0.1 -p 9381
|
||||
```
|
||||
|
||||
You will be prompted to enter the superuser's password to log in.
|
||||
The default password is admin.
|
||||
|
||||
**Parameters:**
|
||||
|
||||
- -h: RAGFlow admin server host address
|
||||
|
||||
- -p: RAGFlow admin server port
|
||||
|
||||
|
||||
|
||||
## Supported Commands
|
||||
|
||||
Commands are case-insensitive and must be terminated with a semicolon(;).
|
||||
|
||||
### Service manage commands
|
||||
|
||||
`LIST SERVICES;`
|
||||
|
||||
- Lists all available services within the RAGFlow system.
|
||||
|
||||
- [Example](#example-list-services)
|
||||
|
||||
`SHOW SERVICE <id>;`
|
||||
|
||||
- Shows detailed status information for the service identified by **id**.
|
||||
- [Example](#example-show-service)
|
||||
|
||||
### User Management Commands
|
||||
|
||||
`LIST USERS;`
|
||||
|
||||
- Lists all users known to the system.
|
||||
- [Example](#example-list-users)
|
||||
|
||||
`SHOW USER <username>;`
|
||||
|
||||
- Shows details and permissions for the user specified by **email**. The username must be enclosed in single or double quotes.
|
||||
- [Example](#example-show-user)
|
||||
|
||||
`CREATE USER <username> <password>;`
|
||||
|
||||
- Create user by username and password. The username and password must be enclosed in single or double quotes.
|
||||
- [Example](#example-create-user)
|
||||
|
||||
`DROP USER <username>;`
|
||||
|
||||
- Removes the specified user from the system. Use with caution.
|
||||
- [Example](#example-drop-user)
|
||||
|
||||
`ALTER USER PASSWORD <username> <new_password>;`
|
||||
|
||||
- Changes the password for the specified user.
|
||||
- [Example](#example-alter-user-password)
|
||||
|
||||
`ALTER USER ACTIVE <username> <on/off>;`
|
||||
|
||||
- Changes the user to active or inactive.
|
||||
- [Example](#example-alter-user-active)
|
||||
|
||||
### Data and Agent Commands
|
||||
|
||||
`LIST DATASETS OF <username>;`
|
||||
|
||||
- Lists the datasets associated with the specified user.
|
||||
- [Example](#example-list-datasets-of-user)
|
||||
|
||||
`LIST AGENTS OF <username>;`
|
||||
|
||||
- Lists the agents associated with the specified user.
|
||||
- [Example](#example-list-agents-of-user)
|
||||
|
||||
### Meta-Commands
|
||||
|
||||
- \? or \help
|
||||
Shows help information for the available commands.
|
||||
- \q or \quit
|
||||
Exits the CLI application.
|
||||
- [Example](#example-meta-commands)
|
||||
|
||||
### Examples
|
||||
|
||||
<span id="example-list-services"></span>
|
||||
|
||||
- List all available services.
|
||||
|
||||
```
|
||||
admin> list services;
|
||||
command: list services;
|
||||
Listing all services
|
||||
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+---------+
|
||||
| extra | host | id | name | port | service_type | status |
|
||||
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+---------+
|
||||
| {} | 0.0.0.0 | 0 | ragflow_0 | 9380 | ragflow_server | Timeout |
|
||||
| {'meta_type': 'mysql', 'password': 'infini_rag_flow', 'username': 'root'} | localhost | 1 | mysql | 5455 | meta_data | Alive |
|
||||
| {'password': 'infini_rag_flow', 'store_type': 'minio', 'user': 'rag_flow'} | localhost | 2 | minio | 9000 | file_store | Alive |
|
||||
| {'password': 'infini_rag_flow', 'retrieval_type': 'elasticsearch', 'username': 'elastic'} | localhost | 3 | elasticsearch | 1200 | retrieval | Alive |
|
||||
| {'db_name': 'default_db', 'retrieval_type': 'infinity'} | localhost | 4 | infinity | 23817 | retrieval | Timeout |
|
||||
| {'database': 1, 'mq_type': 'redis', 'password': 'infini_rag_flow'} | localhost | 5 | redis | 6379 | message_queue | Alive |
|
||||
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+---------+
|
||||
|
||||
```
|
||||
|
||||
<span id="example-show-service"></span>
|
||||
|
||||
- Show ragflow_server.
|
||||
|
||||
```
|
||||
admin> show service 0;
|
||||
command: show service 0;
|
||||
Showing service: 0
|
||||
Service ragflow_0 is alive. Detail:
|
||||
Confirm elapsed: 26.0 ms.
|
||||
```
|
||||
|
||||
- Show mysql.
|
||||
|
||||
```
|
||||
admin> show service 1;
|
||||
command: show service 1;
|
||||
Showing service: 1
|
||||
Service mysql is alive. Detail:
|
||||
+---------+----------+------------------+------+------------------+------------------------+-------+-----------------+
|
||||
| command | db | host | id | info | state | time | user |
|
||||
+---------+----------+------------------+------+------------------+------------------------+-------+-----------------+
|
||||
| Daemon | None | localhost | 5 | None | Waiting on empty queue | 16111 | event_scheduler |
|
||||
| Sleep | rag_flow | 172.18.0.1:40046 | 1610 | None | | 2 | root |
|
||||
| Query | rag_flow | 172.18.0.1:35882 | 1629 | SHOW PROCESSLIST | init | 0 | root |
|
||||
+---------+----------+------------------+------+------------------+------------------------+-------+-----------------+
|
||||
```
|
||||
|
||||
- Show minio.
|
||||
|
||||
```
|
||||
admin> show service 2;
|
||||
command: show service 2;
|
||||
Showing service: 2
|
||||
Service minio is alive. Detail:
|
||||
Confirm elapsed: 2.1 ms.
|
||||
```
|
||||
|
||||
- Show elasticsearch.
|
||||
|
||||
```
|
||||
admin> show service 3;
|
||||
command: show service 3;
|
||||
Showing service: 3
|
||||
Service elasticsearch is alive. Detail:
|
||||
+----------------+------+--------------+---------+----------------+--------------+---------------+--------------+------------------------------+----------------------------+-----------------+-------+---------------+---------+-------------+---------------------+--------+------------+--------------------+
|
||||
| cluster_name | docs | docs_deleted | indices | indices_shards | jvm_heap_max | jvm_heap_used | jvm_versions | mappings_deduplicated_fields | mappings_deduplicated_size | mappings_fields | nodes | nodes_version | os_mem | os_mem_used | os_mem_used_percent | status | store_size | total_dataset_size |
|
||||
+----------------+------+--------------+---------+----------------+--------------+---------------+--------------+------------------------------+----------------------------+-----------------+-------+---------------+---------+-------------+---------------------+--------+------------+--------------------+
|
||||
| docker-cluster | 717 | 86 | 37 | 42 | 3.76 GB | 1.74 GB | 21.0.1+12-29 | 6575 | 48.0 KB | 8521 | 1 | ['8.11.3'] | 7.52 GB | 4.55 GB | 61 | green | 4.60 MB | 4.60 MB |
|
||||
+----------------+------+--------------+---------+----------------+--------------+---------------+--------------+------------------------------+----------------------------+-----------------+-------+---------------+---------+-------------+---------------------+--------+------------+--------------------+
|
||||
```
|
||||
|
||||
- Show infinity.
|
||||
|
||||
```
|
||||
admin> show service 4;
|
||||
command: show service 4;
|
||||
Showing service: 4
|
||||
Fail to show service, code: 500, message: Infinity is not in use.
|
||||
```
|
||||
|
||||
- Show redis.
|
||||
|
||||
```
|
||||
admin> show service 5;
|
||||
command: show service 5;
|
||||
Showing service: 5
|
||||
Service redis is alive. Detail:
|
||||
+-----------------+-------------------+---------------------------+-------------------------+---------------+-------------+--------------------------+---------------------+-------------+
|
||||
| blocked_clients | connected_clients | instantaneous_ops_per_sec | mem_fragmentation_ratio | redis_version | server_mode | total_commands_processed | total_system_memory | used_memory |
|
||||
+-----------------+-------------------+---------------------------+-------------------------+---------------+-------------+--------------------------+---------------------+-------------+
|
||||
| 0 | 2 | 1 | 10.41 | 7.2.4 | standalone | 10446 | 30.84G | 1.10M |
|
||||
+-----------------+-------------------+---------------------------+-------------------------+---------------+-------------+--------------------------+---------------------+-------------+
|
||||
```
|
||||
|
||||
<span id="example-list-users"></span>
|
||||
|
||||
- List all user.
|
||||
|
||||
```
|
||||
admin> list users;
|
||||
command: list users;
|
||||
Listing all users
|
||||
+-------------------------------+----------------------+-----------+----------+
|
||||
| create_date | email | is_active | nickname |
|
||||
+-------------------------------+----------------------+-----------+----------+
|
||||
| Mon, 22 Sep 2025 10:59:04 GMT | admin@ragflow.io | 1 | admin |
|
||||
| Sun, 14 Sep 2025 17:36:27 GMT | lynn_inf@hotmail.com | 1 | Lynn |
|
||||
+-------------------------------+----------------------+-----------+----------+
|
||||
```
|
||||
|
||||
<span id="example-show-user"></span>
|
||||
|
||||
- Show specified user.
|
||||
|
||||
```
|
||||
admin> show user "admin@ragflow.io";
|
||||
command: show user "admin@ragflow.io";
|
||||
Showing user: admin@ragflow.io
|
||||
+-------------------------------+------------------+-----------+--------------+------------------+--------------+----------+-----------------+---------------+--------+-------------------------------+
|
||||
| create_date | email | is_active | is_anonymous | is_authenticated | is_superuser | language | last_login_time | login_channel | status | update_date |
|
||||
+-------------------------------+------------------+-----------+--------------+------------------+--------------+----------+-----------------+---------------+--------+-------------------------------+
|
||||
| Mon, 22 Sep 2025 10:59:04 GMT | admin@ragflow.io | 1 | 0 | 1 | True | Chinese | None | None | 1 | Mon, 22 Sep 2025 10:59:04 GMT |
|
||||
+-------------------------------+------------------+-----------+--------------+------------------+--------------+----------+-----------------+---------------+--------+-------------------------------+
|
||||
```
|
||||
|
||||
<span id="example-create-user"></span>
|
||||
|
||||
- Create new user.
|
||||
|
||||
```
|
||||
admin> create user "example@ragflow.io" "psw";
|
||||
command: create user "example@ragflow.io" "psw";
|
||||
Create user: example@ragflow.io, password: psw, role: user
|
||||
+----------------------------------+--------------------+----------------------------------+--------------+---------------+----------+
|
||||
| access_token | email | id | is_superuser | login_channel | nickname |
|
||||
+----------------------------------+--------------------+----------------------------------+--------------+---------------+----------+
|
||||
| 5cdc6d1e9df111f099b543aee592c6bf | example@ragflow.io | 5cdc6ca69df111f099b543aee592c6bf | False | password | |
|
||||
+----------------------------------+--------------------+----------------------------------+--------------+---------------+----------+
|
||||
```
|
||||
|
||||
<span id="example-alter-user-password"></span>
|
||||
|
||||
- Alter user password.
|
||||
|
||||
```
|
||||
admin> alter user password "example@ragflow.io" "newpsw";
|
||||
command: alter user password "example@ragflow.io" "newpsw";
|
||||
Alter user: example@ragflow.io, password: newpsw
|
||||
Password updated successfully!
|
||||
```
|
||||
|
||||
<span id="example-alter-user-active"></span>
|
||||
|
||||
- Alter user active, turn off.
|
||||
|
||||
```
|
||||
admin> alter user active "example@ragflow.io" off;
|
||||
command: alter user active "example@ragflow.io" off;
|
||||
Alter user example@ragflow.io activate status, turn off.
|
||||
Turn off user activate status successfully!
|
||||
```
|
||||
|
||||
<span id="example-drop-user"></span>
|
||||
|
||||
- Drop user.
|
||||
|
||||
```
|
||||
admin> Drop user "example@ragflow.io";
|
||||
command: Drop user "example@ragflow.io";
|
||||
Drop user: example@ragflow.io
|
||||
Successfully deleted user. Details:
|
||||
Start to delete owned tenant.
|
||||
- Deleted 2 tenant-LLM records.
|
||||
- Deleted 0 langfuse records.
|
||||
- Deleted 1 tenant.
|
||||
- Deleted 1 user-tenant records.
|
||||
- Deleted 1 user.
|
||||
Delete done!
|
||||
```
|
||||
|
||||
Delete user's data at the same time.
|
||||
|
||||
<span id="example-list-datasets-of-user"></span>
|
||||
|
||||
- List the specified user's dataset.
|
||||
|
||||
```
|
||||
admin> list datasets of "lynn_inf@hotmail.com";
|
||||
command: list datasets of "lynn_inf@hotmail.com";
|
||||
Listing all datasets of user: lynn_inf@hotmail.com
|
||||
+-----------+-------------------------------+---------+----------+---------------+------------+--------+-----------+-------------------------------+
|
||||
| chunk_num | create_date | doc_num | language | name | permission | status | token_num | update_date |
|
||||
+-----------+-------------------------------+---------+----------+---------------+------------+--------+-----------+-------------------------------+
|
||||
| 29 | Mon, 15 Sep 2025 11:56:59 GMT | 12 | Chinese | test_dataset | me | 1 | 12896 | Fri, 19 Sep 2025 17:50:58 GMT |
|
||||
| 4 | Sun, 28 Sep 2025 11:49:31 GMT | 6 | Chinese | dataset_share | team | 1 | 1121 | Sun, 28 Sep 2025 14:41:03 GMT |
|
||||
+-----------+-------------------------------+---------+----------+---------------+------------+--------+-----------+-------------------------------+
|
||||
```
|
||||
|
||||
<span id="example-list-agents-of-user"></span>
|
||||
|
||||
- List the specified user's agents.
|
||||
|
||||
```
|
||||
admin> list agents of "lynn_inf@hotmail.com";
|
||||
command: list agents of "lynn_inf@hotmail.com";
|
||||
Listing all agents of user: lynn_inf@hotmail.com
|
||||
+-----------------+-------------+------------+-----------------+
|
||||
| canvas_category | canvas_type | permission | title |
|
||||
+-----------------+-------------+------------+-----------------+
|
||||
| agent | None | team | research_helper |
|
||||
+-----------------+-------------+------------+-----------------+
|
||||
```
|
||||
|
||||
<span id="example-meta-commands"></span>
|
||||
|
||||
- Show help information.
|
||||
|
||||
```
|
||||
admin> \help
|
||||
command: \help
|
||||
|
||||
Commands:
|
||||
LIST SERVICES
|
||||
SHOW SERVICE <service>
|
||||
STARTUP SERVICE <service>
|
||||
SHUTDOWN SERVICE <service>
|
||||
RESTART SERVICE <service>
|
||||
LIST USERS
|
||||
SHOW USER <user>
|
||||
DROP USER <user>
|
||||
CREATE USER <user> <password>
|
||||
ALTER USER PASSWORD <user> <new_password>
|
||||
ALTER USER ACTIVE <user> <on/off>
|
||||
LIST DATASETS OF <user>
|
||||
LIST AGENTS OF <user>
|
||||
|
||||
Meta Commands:
|
||||
\?, \h, \help Show this help
|
||||
\q, \quit, \exit Quit the CLI
|
||||
```
|
||||
|
||||
- Exit
|
||||
|
||||
```
|
||||
admin> \q
|
||||
command: \q
|
||||
Goodbye!
|
||||
```
|
||||
|
||||
108
docs/guides/migration/migrate_from_docker_compose.md
Normal file
108
docs/guides/migration/migrate_from_docker_compose.md
Normal file
@@ -0,0 +1,108 @@
|
||||
# Data Migration Guide
|
||||
|
||||
A common scenario is processing large datasets on a powerful instance (e.g., with a GPU) and then migrating the entire RAGFlow service to a different production environment (e.g., a CPU-only server). This guide explains how to safely back up and restore your data using our provided migration script.
|
||||
|
||||
## Identifying Your Data
|
||||
|
||||
By default, RAGFlow uses Docker volumes to store all persistent data, including your database, uploaded files, and search indexes. You can see these volumes by running:
|
||||
|
||||
```bash
|
||||
docker volume ls
|
||||
```
|
||||
|
||||
The output will look similar to this:
|
||||
|
||||
```text
|
||||
DRIVER VOLUME NAME
|
||||
local docker_esdata01
|
||||
local docker_minio_data
|
||||
local docker_mysql_data
|
||||
local docker_redis_data
|
||||
```
|
||||
|
||||
These volumes contain all the data you need to migrate.
|
||||
|
||||
## Step 1: Stop RAGFlow Services
|
||||
|
||||
Before starting the migration, you must stop all running RAGFlow services on the **source machine**. Navigate to the project's root directory and run:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker/docker-compose.yml down
|
||||
```
|
||||
|
||||
**Important:** Do **not** use the `-v` flag (e.g., `docker-compose down -v`), as this will delete all your data volumes. The migration script includes a check and will prevent you from running it if services are active.
|
||||
|
||||
## Step 2: Back Up Your Data
|
||||
|
||||
We provide a convenient script to package all your data volumes into a single backup folder.
|
||||
|
||||
For a quick reference of the script's commands and options, you can run:
|
||||
```bash
|
||||
bash docker/migration.sh help
|
||||
```
|
||||
|
||||
To create a backup, run the following command from the project's root directory:
|
||||
|
||||
```bash
|
||||
bash docker/migration.sh backup
|
||||
```
|
||||
|
||||
This will create a `backup/` folder in your project root containing compressed archives of your data volumes.
|
||||
|
||||
You can also specify a custom name for your backup folder:
|
||||
|
||||
```bash
|
||||
bash docker/migration.sh backup my_ragflow_backup
|
||||
```
|
||||
|
||||
This will create a folder named `my_ragflow_backup/` instead.
|
||||
|
||||
## Step 3: Transfer the Backup Folder
|
||||
|
||||
Copy the entire backup folder (e.g., `backup/` or `my_ragflow_backup/`) from your source machine to the RAGFlow project directory on your **target machine**. You can use tools like `scp`, `rsync`, or a physical drive for the transfer.
|
||||
|
||||
## Step 4: Restore Your Data
|
||||
|
||||
On the **target machine**, ensure that RAGFlow services are not running. Then, use the migration script to restore your data from the backup folder.
|
||||
|
||||
If your backup folder is named `backup/`, run:
|
||||
|
||||
```bash
|
||||
bash docker/migration.sh restore
|
||||
```
|
||||
|
||||
If you used a custom name, specify it in the command:
|
||||
|
||||
```bash
|
||||
bash docker/migration.sh restore my_ragflow_backup
|
||||
```
|
||||
|
||||
The script will automatically create the necessary Docker volumes and unpack the data.
|
||||
|
||||
**Note:** If the script detects that Docker volumes with the same names already exist on the target machine, it will warn you that restoring will overwrite the existing data and ask for confirmation before proceeding.
|
||||
|
||||
## Step 5: Start RAGFlow Services
|
||||
|
||||
Once the restore process is complete, you can start the RAGFlow services on your new machine:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker/docker-compose.yml up -d
|
||||
```
|
||||
|
||||
**Note:** If you already have build an service by docker-compose before, you may need to backup your data for target machine like this guide above and run like:
|
||||
|
||||
```bash
|
||||
# Please backup by `sh docker/migration.sh backup backup_dir_name` before you do the following line.
|
||||
# !!! this line -v flag will delete the original docker volume
|
||||
docker-compose -f docker/docker-compose.yml down -v
|
||||
docker-compose -f docker/docker-compose.yml up -d
|
||||
```
|
||||
|
||||
Your RAGFlow instance is now running with all the data from your original machine.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
8
docs/guides/models/_category_.json
Normal file
8
docs/guides/models/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Models",
|
||||
"position": -1,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides on model settings."
|
||||
}
|
||||
}
|
||||
353
docs/guides/models/deploy_local_llm.mdx
Normal file
353
docs/guides/models/deploy_local_llm.mdx
Normal file
@@ -0,0 +1,353 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /deploy_local_llm
|
||||
---
|
||||
|
||||
# Deploy local models
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
Deploy and run local models using Ollama, Xinference, or other frameworks.
|
||||
|
||||
---
|
||||
|
||||
RAGFlow supports deploying models locally using Ollama, Xinference, IPEX-LLM, or jina. If you have locally deployed models to leverage or wish to enable GPU or CUDA for inference acceleration, you can bind Ollama or Xinference into RAGFlow and use either of them as a local "server" for interacting with your local models.
|
||||
|
||||
RAGFlow seamlessly integrates with Ollama and Xinference, without the need for further environment configurations. You can use them to deploy two types of local models in RAGFlow: chat models and embedding models.
|
||||
|
||||
:::tip NOTE
|
||||
This user guide does not intend to cover much of the installation or configuration details of Ollama or Xinference; its focus is on configurations inside RAGFlow. For the most current information, you may need to check out the official site of Ollama or Xinference.
|
||||
:::
|
||||
|
||||
## Deploy local models using Ollama
|
||||
|
||||
[Ollama](https://github.com/ollama/ollama) enables you to run open-source large language models that you deployed locally. It bundles model weights, configurations, and data into a single package, defined by a Modelfile, and optimizes setup and configurations, including GPU usage.
|
||||
|
||||
:::note
|
||||
- For information about downloading Ollama, see [here](https://github.com/ollama/ollama?tab=readme-ov-file#ollama).
|
||||
- For a complete list of supported models and variants, see the [Ollama model library](https://ollama.com/library).
|
||||
:::
|
||||
|
||||
### 1. Deploy Ollama using Docker
|
||||
|
||||
Ollama can be [installed from binaries](https://ollama.com/download) or [deployed with Docker](https://hub.docker.com/r/ollama/ollama). Here are the instructions to deploy with Docker:
|
||||
|
||||
```bash
|
||||
$ sudo docker run --name ollama -p 11434:11434 ollama/ollama
|
||||
> time=2024-12-02T02:20:21.360Z level=INFO source=routes.go:1248 msg="Listening on [::]:11434 (version 0.4.6)"
|
||||
> time=2024-12-02T02:20:21.360Z level=INFO source=common.go:49 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 cuda_v11 cuda_v12]"
|
||||
```
|
||||
|
||||
Ensure Ollama is listening on all IP address:
|
||||
```bash
|
||||
$ sudo ss -tunlp | grep 11434
|
||||
> tcp LISTEN 0 4096 0.0.0.0:11434 0.0.0.0:* users:(("docker-proxy",pid=794507,fd=4))
|
||||
> tcp LISTEN 0 4096 [::]:11434 [::]:* users:(("docker-proxy",pid=794513,fd=4))
|
||||
```
|
||||
|
||||
Pull models as you need. We recommend that you start with `llama3.2` (a 3B chat model) and `bge-m3` (a 567M embedding model):
|
||||
```bash
|
||||
$ sudo docker exec ollama ollama pull llama3.2
|
||||
> pulling dde5aa3fc5ff... 100% ▕████████████████▏ 2.0 GB
|
||||
> success
|
||||
```
|
||||
|
||||
```bash
|
||||
$ sudo docker exec ollama ollama pull bge-m3
|
||||
> pulling daec91ffb5dd... 100% ▕████████████████▏ 1.2 GB
|
||||
> success
|
||||
```
|
||||
|
||||
### 2. Find Ollama URL and ensure it is accessible
|
||||
|
||||
- If RAGFlow runs in Docker, the localhost is mapped within the RAGFlow Docker container as `host.docker.internal`. If Ollama runs on the same host machine, the right URL to use for Ollama would be `http://host.docker.internal:11434/' and you should check that Ollama is accessible from inside the RAGFlow container with:
|
||||
```bash
|
||||
$ sudo docker exec -it ragflow-server bash
|
||||
$ curl http://host.docker.internal:11434/
|
||||
> Ollama is running
|
||||
```
|
||||
|
||||
- If RAGFlow is launched from source code and Ollama runs on the same host machine as RAGFlow, check if Ollama is accessible from RAGFlow's host machine:
|
||||
```bash
|
||||
$ curl http://localhost:11434/
|
||||
> Ollama is running
|
||||
```
|
||||
|
||||
- If RAGFlow and Ollama run on different machines, check if Ollama is accessible from RAGFlow's host machine:
|
||||
```bash
|
||||
$ curl http://${IP_OF_OLLAMA_MACHINE}:11434/
|
||||
> Ollama is running
|
||||
```
|
||||
|
||||
### 3. Add Ollama
|
||||
|
||||
In RAGFlow, click on your logo on the top right of the page **>** **Model providers** and add Ollama to RAGFlow:
|
||||
|
||||

|
||||
|
||||
|
||||
### 4. Complete basic Ollama settings
|
||||
|
||||
In the popup window, complete basic settings for Ollama:
|
||||
|
||||
1. Ensure that your model name and type match those been pulled at step 1 (Deploy Ollama using Docker). For example, (`llama3.2` and `chat`) or (`bge-m3` and `embedding`).
|
||||
2. Put in the Ollama base URL, i.e. `http://host.docker.internal:11434`, `http://localhost:11434` or `http://${IP_OF_OLLAMA_MACHINE}:11434`.
|
||||
3. OPTIONAL: Switch on the toggle under **Does it support Vision?** if your model includes an image-to-text model.
|
||||
|
||||
|
||||
:::caution WARNING
|
||||
Improper base URL settings will trigger the following error:
|
||||
```bash
|
||||
Max retries exceeded with url: /api/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0xffff98b81ff0>: Failed to establish a new connection: [Errno 111] Connection refused'))
|
||||
```
|
||||
:::
|
||||
|
||||
### 5. Update System Model Settings
|
||||
|
||||
Click on your logo **>** **Model providers** **>** **System Model Settings** to update your model:
|
||||
|
||||
- *You should now be able to find **llama3.2** from the dropdown list under **Chat model**, and **bge-m3** from the dropdown list under **Embedding model**.*
|
||||
- _If your local model is an embedding model, you should find it under **Embedding model**._
|
||||
|
||||
### 6. Update Chat Configuration
|
||||
|
||||
Update your model(s) accordingly in **Chat Configuration**.
|
||||
|
||||
## Deploy a local model using Xinference
|
||||
|
||||
Xorbits Inference ([Xinference](https://github.com/xorbitsai/inference)) enables you to unleash the full potential of cutting-edge AI models.
|
||||
|
||||
:::note
|
||||
- For information about installing Xinference Ollama, see [here](https://inference.readthedocs.io/en/latest/getting_started/).
|
||||
- For a complete list of supported models, see the [Builtin Models](https://inference.readthedocs.io/en/latest/models/builtin/).
|
||||
:::
|
||||
|
||||
To deploy a local model, e.g., **Mistral**, using Xinference:
|
||||
|
||||
### 1. Check firewall settings
|
||||
|
||||
Ensure that your host machine's firewall allows inbound connections on port 9997.
|
||||
|
||||
### 2. Start an Xinference instance
|
||||
|
||||
```bash
|
||||
$ xinference-local --host 0.0.0.0 --port 9997
|
||||
```
|
||||
|
||||
### 3. Launch your local model
|
||||
|
||||
Launch your local model (**Mistral**), ensuring that you replace `${quantization}` with your chosen quantization method:
|
||||
|
||||
```bash
|
||||
$ xinference launch -u mistral --model-name mistral-v0.1 --size-in-billions 7 --model-format pytorch --quantization ${quantization}
|
||||
```
|
||||
### 4. Add Xinference
|
||||
|
||||
In RAGFlow, click on your logo on the top right of the page **>** **Model providers** and add Xinference to RAGFlow:
|
||||
|
||||

|
||||
|
||||
### 5. Complete basic Xinference settings
|
||||
|
||||
Enter an accessible base URL, such as `http://<your-xinference-endpoint-domain>:9997/v1`.
|
||||
> For rerank model, please use the `http://<your-xinference-endpoint-domain>:9997/v1/rerank` as the base URL.
|
||||
|
||||
### 6. Update System Model Settings
|
||||
|
||||
Click on your logo **>** **Model providers** **>** **System Model Settings** to update your model.
|
||||
|
||||
*You should now be able to find **mistral** from the dropdown list under **Chat model**.*
|
||||
|
||||
> If your local model is an embedding model, you should find your local model under **Embedding model**.
|
||||
|
||||
### 7. Update Chat Configuration
|
||||
|
||||
Update your chat model accordingly in **Chat Configuration**:
|
||||
|
||||
> If your local model is an embedding model, update it on the configuration page of your dataset.
|
||||
|
||||
## Deploy a local model using IPEX-LLM
|
||||
|
||||
[IPEX-LLM](https://github.com/intel-analytics/ipex-llm) is a PyTorch library for running LLMs on local Intel CPUs or GPUs (including iGPU or discrete GPUs like Arc, Flex, and Max) with low latency. It supports Ollama on Linux and Windows systems.
|
||||
|
||||
To deploy a local model, e.g., **Qwen2**, using IPEX-LLM-accelerated Ollama:
|
||||
|
||||
### 1. Check firewall settings
|
||||
|
||||
Ensure that your host machine's firewall allows inbound connections on port 11434. For example:
|
||||
|
||||
```bash
|
||||
sudo ufw allow 11434/tcp
|
||||
```
|
||||
|
||||
### 2. Launch Ollama service using IPEX-LLM
|
||||
|
||||
#### 2.1 Install IPEX-LLM for Ollama
|
||||
|
||||
:::tip NOTE
|
||||
IPEX-LLM's supports Ollama on Linux and Windows systems.
|
||||
:::
|
||||
|
||||
For detailed information about installing IPEX-LLM for Ollama, see [Run llama.cpp with IPEX-LLM on Intel GPU Guide](https://github.com/intel-analytics/ipex-llm/blob/main/docs/mddocs/Quickstart/llama_cpp_quickstart.md):
|
||||
- [Prerequisites](https://github.com/intel-analytics/ipex-llm/blob/main/docs/mddocs/Quickstart/llama_cpp_quickstart.md#0-prerequisites)
|
||||
- [Install IPEX-LLM cpp with Ollama binaries](https://github.com/intel-analytics/ipex-llm/blob/main/docs/mddocs/Quickstart/llama_cpp_quickstart.md#1-install-ipex-llm-for-llamacpp)
|
||||
|
||||
*After the installation, you should have created a Conda environment, e.g., `llm-cpp`, for running Ollama commands with IPEX-LLM.*
|
||||
|
||||
#### 2.2 Initialize Ollama
|
||||
|
||||
1. Activate the `llm-cpp` Conda environment and initialize Ollama:
|
||||
|
||||
<Tabs
|
||||
defaultValue="linux"
|
||||
values={[
|
||||
{label: 'Linux', value: 'linux'},
|
||||
{label: 'Windows', value: 'windows'},
|
||||
]}>
|
||||
<TabItem value="linux">
|
||||
|
||||
```bash
|
||||
conda activate llm-cpp
|
||||
init-ollama
|
||||
```
|
||||
</TabItem>
|
||||
<TabItem value="windows">
|
||||
|
||||
Run these commands with *administrator privileges in Miniforge Prompt*:
|
||||
|
||||
```cmd
|
||||
conda activate llm-cpp
|
||||
init-ollama.bat
|
||||
```
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
2. If the installed `ipex-llm[cpp]` requires an upgrade to the Ollama binary files, remove the old binary files and reinitialize Ollama using `init-ollama` (Linux) or `init-ollama.bat` (Windows).
|
||||
|
||||
*A symbolic link to Ollama appears in your current directory, and you can use this executable file following standard Ollama commands.*
|
||||
|
||||
#### 2.3 Launch Ollama service
|
||||
|
||||
1. Set the environment variable `OLLAMA_NUM_GPU` to `999` to ensure that all layers of your model run on the Intel GPU; otherwise, some layers may default to CPU.
|
||||
2. For optimal performance on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), set the following environment variable before launching the Ollama service:
|
||||
|
||||
```bash
|
||||
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
|
||||
```
|
||||
3. Launch the Ollama service:
|
||||
|
||||
<Tabs
|
||||
defaultValue="linux"
|
||||
values={[
|
||||
{label: 'Linux', value: 'linux'},
|
||||
{label: 'Windows', value: 'windows'},
|
||||
]}>
|
||||
<TabItem value="linux">
|
||||
|
||||
```bash
|
||||
export OLLAMA_NUM_GPU=999
|
||||
export no_proxy=localhost,127.0.0.1
|
||||
export ZES_ENABLE_SYSMAN=1
|
||||
source /opt/intel/oneapi/setvars.sh
|
||||
export SYCL_CACHE_PERSISTENT=1
|
||||
|
||||
./ollama serve
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="windows">
|
||||
|
||||
Run the following command *in Miniforge Prompt*:
|
||||
|
||||
```cmd
|
||||
set OLLAMA_NUM_GPU=999
|
||||
set no_proxy=localhost,127.0.0.1
|
||||
set ZES_ENABLE_SYSMAN=1
|
||||
set SYCL_CACHE_PERSISTENT=1
|
||||
|
||||
ollama serve
|
||||
```
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
|
||||
:::tip NOTE
|
||||
To enable the Ollama service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` rather than simply `./ollama serve`.
|
||||
:::
|
||||
|
||||
*The console displays messages similar to the following:*
|
||||
|
||||

|
||||
|
||||
### 3. Pull and Run Ollama model
|
||||
|
||||
#### 3.1 Pull Ollama model
|
||||
|
||||
With the Ollama service running, open a new terminal and run `./ollama pull <model_name>` (Linux) or `ollama.exe pull <model_name>` (Windows) to pull the desired model. e.g., `qwen2:latest`:
|
||||
|
||||

|
||||
|
||||
#### 3.2 Run Ollama model
|
||||
|
||||
<Tabs
|
||||
defaultValue="linux"
|
||||
values={[
|
||||
{label: 'Linux', value: 'linux'},
|
||||
{label: 'Windows', value: 'windows'},
|
||||
]}>
|
||||
<TabItem value="linux">
|
||||
|
||||
```bash
|
||||
./ollama run qwen2:latest
|
||||
```
|
||||
</TabItem>
|
||||
<TabItem value="windows">
|
||||
|
||||
```cmd
|
||||
ollama run qwen2:latest
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
### 4. Configure RAGflow
|
||||
|
||||
To enable IPEX-LLM accelerated Ollama in RAGFlow, you must also complete the configurations in RAGFlow. The steps are identical to those outlined in the *Deploy a local model using Ollama* section:
|
||||
|
||||
1. [Add Ollama](#4-add-ollama)
|
||||
2. [Complete basic Ollama settings](#5-complete-basic-ollama-settings)
|
||||
3. [Update System Model Settings](#6-update-system-model-settings)
|
||||
4. [Update Chat Configuration](#7-update-chat-configuration)
|
||||
|
||||
## Deploy a local model using jina
|
||||
|
||||
To deploy a local model, e.g., **gpt2**, using jina:
|
||||
|
||||
### 1. Check firewall settings
|
||||
|
||||
Ensure that your host machine's firewall allows inbound connections on port 12345.
|
||||
|
||||
```bash
|
||||
sudo ufw allow 12345/tcp
|
||||
```
|
||||
|
||||
### 2. Install jina package
|
||||
|
||||
```bash
|
||||
pip install jina
|
||||
```
|
||||
|
||||
### 3. Deploy a local model
|
||||
|
||||
Step 1: Navigate to the **rag/svr** directory.
|
||||
|
||||
```bash
|
||||
cd rag/svr
|
||||
```
|
||||
|
||||
Step 2: Run **jina_server.py**, specifying either the model's name or its local directory:
|
||||
|
||||
```bash
|
||||
python jina_server.py --model_name gpt2
|
||||
```
|
||||
> The script only supports models downloaded from Hugging Face.
|
||||
48
docs/guides/models/llm_api_key_setup.md
Normal file
48
docs/guides/models/llm_api_key_setup.md
Normal file
@@ -0,0 +1,48 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /llm_api_key_setup
|
||||
---
|
||||
|
||||
# Configure model API key
|
||||
|
||||
An API key is required for RAGFlow to interact with an online AI model. This guide provides information about setting your model API key in RAGFlow.
|
||||
|
||||
## Get model API key
|
||||
|
||||
RAGFlow supports most mainstream LLMs. Please refer to [Supported Models](../../references/supported_models.mdx) for a complete list of supported models. You will need to apply for your model API key online. Note that most LLM providers grant newly-created accounts trial credit, which will expire in a couple of months, or a promotional amount of free quota.
|
||||
|
||||
:::note
|
||||
If you find your online LLM is not on the list, don't feel disheartened. The list is expanding, and you can [file a feature request](https://github.com/infiniflow/ragflow/issues/new?assignees=&labels=feature+request&projects=&template=feature_request.yml&title=%5BFeature+Request%5D%3A+) with us! Alternatively, if you have customized or locally-deployed models, you can [bind them to RAGFlow using Ollama, Xinference, or LocalAI](./deploy_local_llm.mdx).
|
||||
:::
|
||||
|
||||
## Configure model API key
|
||||
|
||||
You have two options for configuring your model API key:
|
||||
|
||||
- Configure it in **service_conf.yaml.template** before starting RAGFlow.
|
||||
- Configure it on the **Model providers** page after logging into RAGFlow.
|
||||
|
||||
### Configure model API key before starting up RAGFlow
|
||||
|
||||
1. Navigate to **./docker/ragflow**.
|
||||
2. Find entry **user_default_llm**:
|
||||
- Update `factory` with your chosen LLM.
|
||||
- Update `api_key` with yours.
|
||||
- Update `base_url` if you use a proxy to connect to the remote service.
|
||||
3. Reboot your system for your changes to take effect.
|
||||
4. Log into RAGFlow.
|
||||
_After logging into RAGFlow, you will find your chosen model appears under **Added models** on the **Model providers** page._
|
||||
|
||||
### Configure model API key after logging into RAGFlow
|
||||
|
||||
:::caution WARNING
|
||||
After logging into RAGFlow, configuring your model API key through the **service_conf.yaml.template** file will no longer take effect.
|
||||
:::
|
||||
|
||||
After logging into RAGFlow, you can *only* configure API Key on the **Model providers** page:
|
||||
|
||||
1. Click on your logo on the top right of the page **>** **Model providers**.
|
||||
2. Find your model card under **Models to be added** and click **Add the model**.
|
||||
3. Paste your model API key.
|
||||
4. Fill in your base URL if you use a proxy to connect to the remote service.
|
||||
5. Click **OK** to confirm your changes.
|
||||
109
docs/guides/run_health_check.md
Normal file
109
docs/guides/run_health_check.md
Normal file
@@ -0,0 +1,109 @@
|
||||
---
|
||||
sidebar_position: 8
|
||||
slug: /run_health_check
|
||||
---
|
||||
|
||||
# Monitoring
|
||||
|
||||
Double-check the health status of RAGFlow's dependencies.
|
||||
|
||||
---
|
||||
|
||||
The operation of RAGFlow depends on four services:
|
||||
|
||||
- **Elasticsearch** (default) or [Infinity](https://github.com/infiniflow/infinity) as the document engine
|
||||
- **MySQL**
|
||||
- **Redis**
|
||||
- **MinIO** for object storage
|
||||
|
||||
If an exception or error occurs related to any of the above services, such as `Exception: Can't connect to ES cluster`, refer to this document to check their health status.
|
||||
|
||||
You can also click you avatar in the top right corner of the page **>** System to view the visualized health status of RAGFlow's core services. The following screenshot shows that all services are 'green' (running healthily). The task executor displays the *cumulative* number of completed and failed document parsing tasks from the past 30 minutes:
|
||||
|
||||
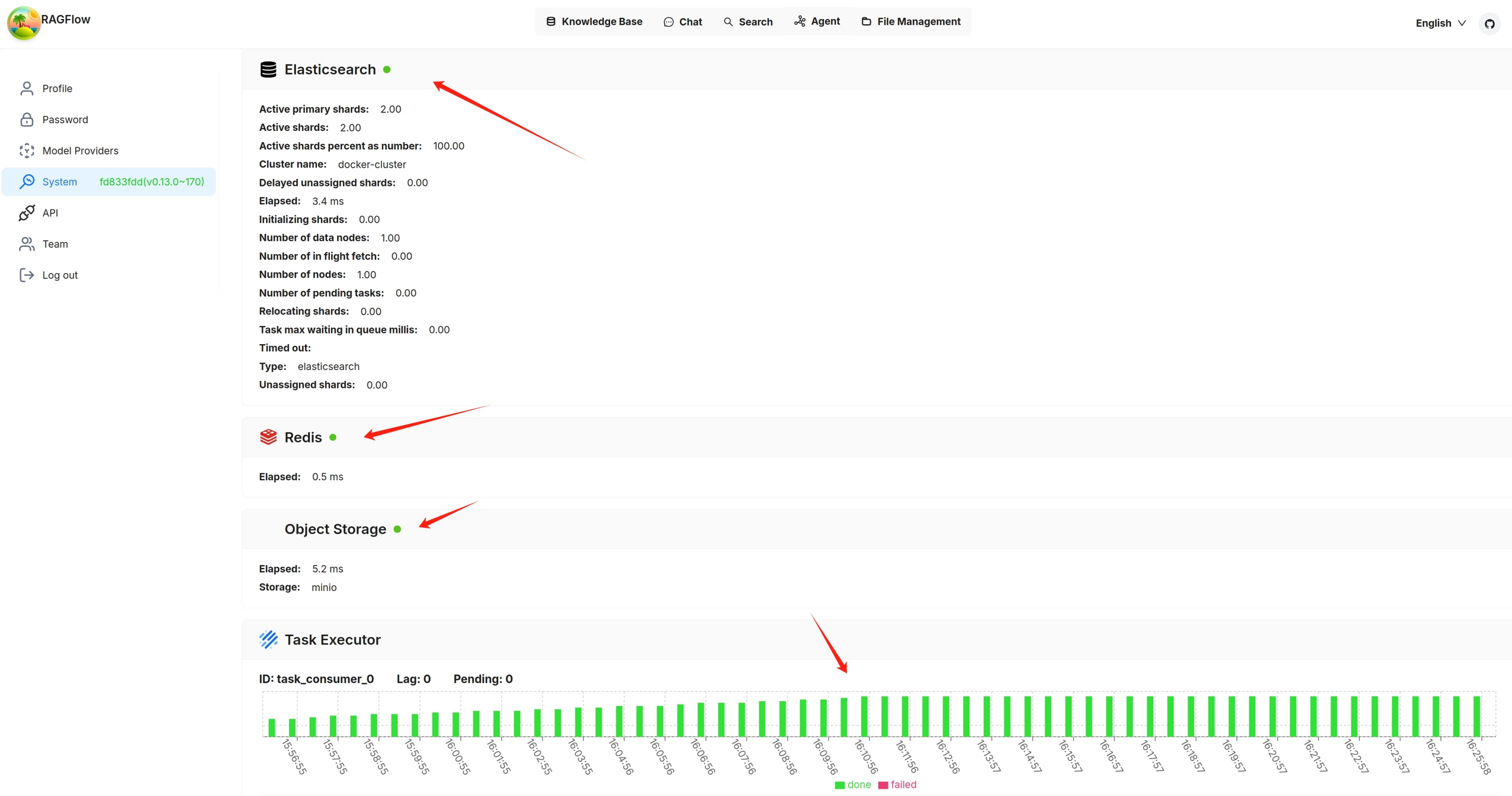
|
||||
|
||||
Services with a yellow or red light are not running properly. The following is a screenshot of the system page after running `docker stop ragflow-es-10`:
|
||||
|
||||

|
||||
|
||||
You can click on a specific 30-second time interval to view the details of completed and failed tasks:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## API Health Check
|
||||
|
||||
In addition to checking the system dependencies from the **avatar > System** page in the UI, you can directly query the backend health check endpoint:
|
||||
|
||||
```bash
|
||||
http://IP_OF_YOUR_MACHINE/v1/system/healthz
|
||||
```
|
||||
|
||||
Here `<port>` refers to the actual port of your backend service (e.g., `7897`, `9222`, etc.).
|
||||
|
||||
Key points:
|
||||
- **No login required** (no `@login_required` decorator)
|
||||
- Returns results in JSON format
|
||||
- If all dependencies are healthy → HTTP **200 OK**
|
||||
- If any dependency fails → HTTP **500 Internal Server Error**
|
||||
|
||||
### Example 1: All services healthy (HTTP 200)
|
||||
|
||||
```bash
|
||||
http://127.0.0.1/v1/system/healthz
|
||||
```
|
||||
|
||||
Response:
|
||||
|
||||
```http
|
||||
HTTP/1.1 200 OK
|
||||
Content-Type: application/json
|
||||
Content-Length: 120
|
||||
|
||||
```
|
||||
|
||||
Explanation:
|
||||
- Database (MySQL/Postgres), Redis, document engine (Elasticsearch/Infinity), and object storage (MinIO) are all healthy.
|
||||
- The `status` field returns `"ok"`.
|
||||
|
||||
### Example 2: One service unhealthy (HTTP 500)
|
||||
|
||||
For example, if Redis is down:
|
||||
|
||||
Response:
|
||||
|
||||
```http
|
||||
HTTP/1.1 500 INTERNAL SERVER ERROR
|
||||
Content-Type: application/json
|
||||
Content-Length: 300
|
||||
|
||||
```
|
||||
|
||||
Explanation:
|
||||
- `redis` is marked as `"nok"`, with detailed error info under `_meta.redis.error`.
|
||||
- The overall `status` is `"nok"`, so the endpoint returns 500.
|
||||
|
||||
---
|
||||
|
||||
This endpoint allows you to monitor RAGFlow’s core dependencies programmatically in scripts or external monitoring systems, without relying on the frontend UI.
|
||||
"redis": "nok",
|
||||
"doc_engine": "ok",
|
||||
"storage": "ok",
|
||||
"status": "nok",
|
||||
"_meta": {
|
||||
"redis": {
|
||||
"elapsed": "5.2",
|
||||
"error": "Lost connection!"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Explanation:
|
||||
- `redis` is marked as `"nok"`, with detailed error info under `_meta.redis.error`.
|
||||
- The overall `status` is `"nok"`, so the endpoint returns 500.
|
||||
|
||||
---
|
||||
|
||||
This endpoint allows you to monitor RAGFlow’s core dependencies programmatically in scripts or external monitoring systems, without relying on the frontend UI.
|
||||
8
docs/guides/team/_category_.json
Normal file
8
docs/guides/team/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Team",
|
||||
"position": 4,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Team-specific guides."
|
||||
}
|
||||
}
|
||||
37
docs/guides/team/join_or_leave_team.md
Normal file
37
docs/guides/team/join_or_leave_team.md
Normal file
@@ -0,0 +1,37 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /join_or_leave_team
|
||||
---
|
||||
|
||||
# Join or leave a team
|
||||
|
||||
Accept an invite to join a team, decline an invite, or leave a team.
|
||||
|
||||
---
|
||||
|
||||
Once you join a team, you can do the following:
|
||||
|
||||
- Upload documents to the team owner's shared datasets.
|
||||
- Parse documents in the team owner's shared datasets.
|
||||
- Use the team owner's shared Agents.
|
||||
|
||||
:::tip NOTE
|
||||
You cannot invite users to a team unless you are its owner.
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure that your Email address that received the team invitation is associated with a RAGFlow user account.
|
||||
2. The team owner should share his datasets by setting their **Permission** to **Team**.
|
||||
|
||||
## Accept or decline team invite
|
||||
|
||||
1. You will be notified on the top right corner of your system page when you receive an invitation to join a team.
|
||||
|
||||
2. Click on your avatar in the top right corner of the page, then select **Team** in the left-hand panel to access the **Team** page.
|
||||
|
||||
_On the **Team** page, you can view the information about members of your team and the teams you have joined._
|
||||
|
||||
_After accepting the team invite, you should be able to view and update the team owner's datasets whose **Permissions** is set to **Team**._
|
||||
|
||||
## Leave a joined team
|
||||
42
docs/guides/team/manage_team_members.md
Normal file
42
docs/guides/team/manage_team_members.md
Normal file
@@ -0,0 +1,42 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /manage_team_members
|
||||
---
|
||||
|
||||
# Manage team members
|
||||
|
||||
Invite or remove team members.
|
||||
|
||||
---
|
||||
|
||||
By default, each RAGFlow user is assigned a single team named after their name. RAGFlow allows you to invite RAGFlow users to your team. Your team members can help you:
|
||||
|
||||
- Upload documents to your shared datasets.
|
||||
- Parse documents in your shared datasets.
|
||||
- Use your shared Agents.
|
||||
|
||||
:::tip NOTE
|
||||
- Your team members are currently *not* allowed to invite users to your team, and only you, the team owner, is permitted to do so.
|
||||
- Sharing added models with team members is only available in RAGFlow's Enterprise edition.
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure that the invited team member is a RAGFlow user and that the Email address used is associated with a RAGFlow user account.
|
||||
2. To allow your team members to view and update your dataset, ensure that you set **Permissions** on its **Configuration** page from **Only me** to **Team**.
|
||||
|
||||
## Invite team members
|
||||
|
||||
Click on your avatar in the top right corner of the page, then select **Team** in the left-hand panel to access the **Team** page.
|
||||
|
||||
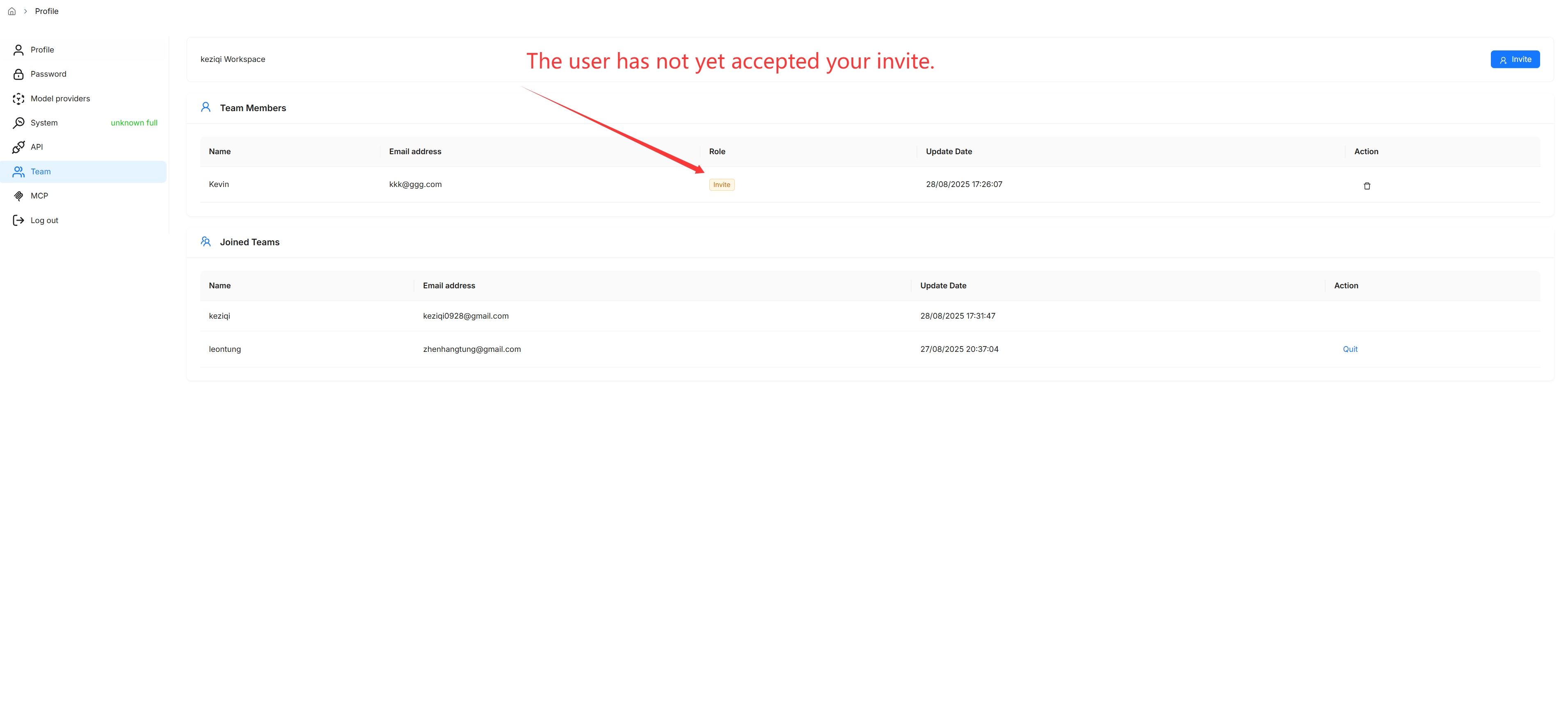
|
||||
|
||||
_On the **Team** page, you can view the information about members of your team and the teams you have joined._
|
||||
|
||||
You are, by default, the owner of your own team and the only person permitted to invite users to join your team or remove team members.
|
||||
|
||||
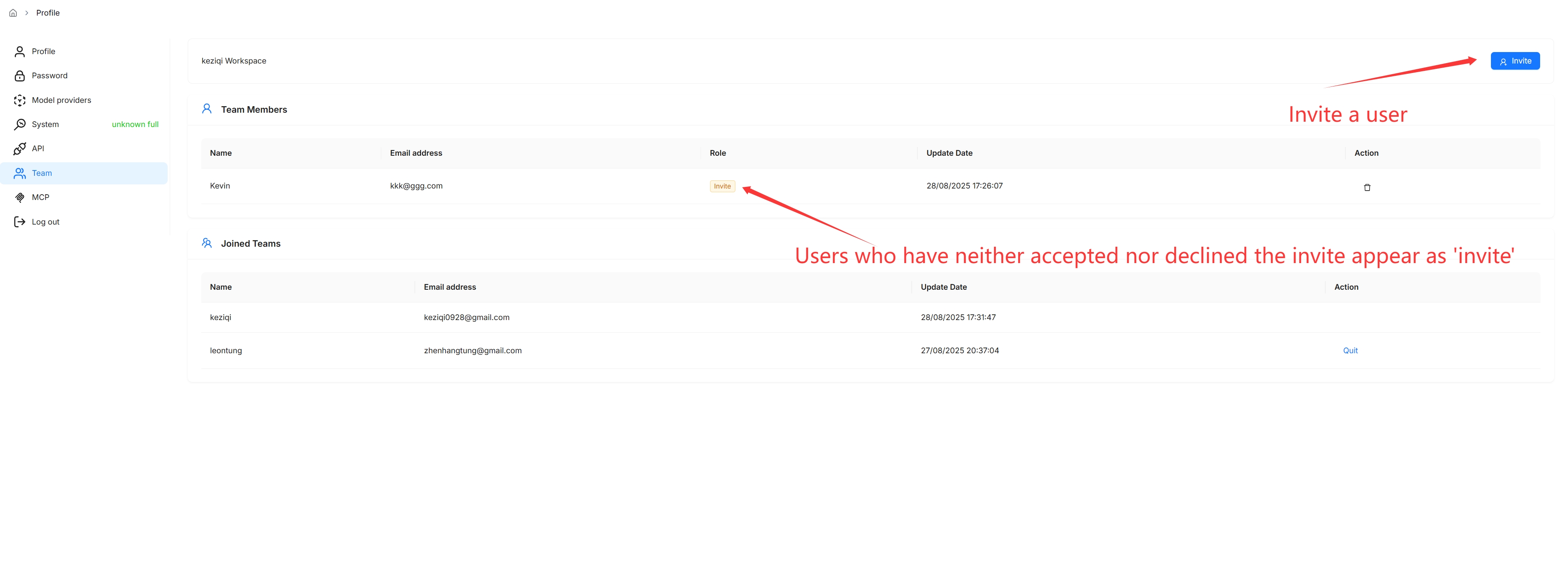
|
||||
|
||||
## Remove team members
|
||||
|
||||
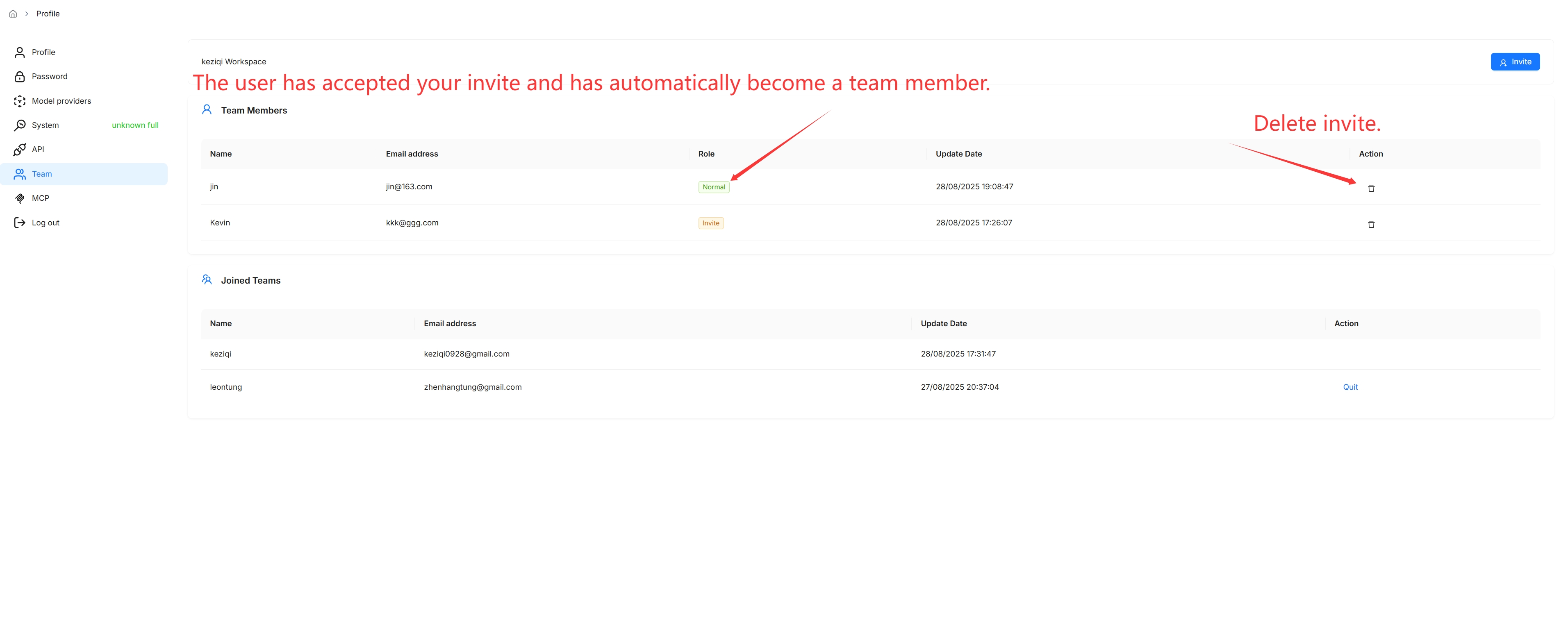
|
||||
19
docs/guides/team/share_agents.md
Normal file
19
docs/guides/team/share_agents.md
Normal file
@@ -0,0 +1,19 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /share_agent
|
||||
---
|
||||
|
||||
# Share Agent
|
||||
|
||||
Share an Agent with your team members.
|
||||
|
||||
---
|
||||
|
||||
When ready, you may share your Agents with your team members so that they can use them. Please note that your Agents are not shared automatically; you must manually enable sharing by selecting the corresponding **Permissions** radio button:
|
||||
|
||||
1. Click the intended Agent to open its editing canvas.
|
||||
2. Click **Management** > **Settings** to show the **Agent settings** dialogue.
|
||||
3. Change **Permissions** from **Only me** to **Team**.
|
||||
4. Click **Save** to apply your changes.
|
||||
|
||||
*When completed, your team members will see your shared Agents.*
|
||||
8
docs/guides/team/share_chat_assistant.md
Normal file
8
docs/guides/team/share_chat_assistant.md
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
sidebar_position: 5
|
||||
slug: /share_chat_assistant
|
||||
---
|
||||
|
||||
# Share chat assistant
|
||||
|
||||
Sharing chat assistant is currently exclusive to RAGFlow Enterprise, but will be made available in due course.
|
||||
18
docs/guides/team/share_knowledge_bases.md
Normal file
18
docs/guides/team/share_knowledge_bases.md
Normal file
@@ -0,0 +1,18 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /share_datasets
|
||||
---
|
||||
|
||||
# Share dataset
|
||||
|
||||
Share a dataset with team members.
|
||||
|
||||
---
|
||||
|
||||
When ready, you may share your datasets with your team members so that they can upload and parse files in them. Please note that your datasets are not shared automatically; you must manually enable sharing by selecting the appropriate **Permissions** radio button:
|
||||
|
||||
1. Navigate to the dataset's **Configuration** page.
|
||||
2. Change **Permissions** from **Only me** to **Team**.
|
||||
3. Click **Save** to apply your changes.
|
||||
|
||||
*Once completed, your team members will see your shared datasets.*
|
||||
8
docs/guides/team/share_model.md
Normal file
8
docs/guides/team/share_model.md
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /share_model
|
||||
---
|
||||
|
||||
# Share models
|
||||
|
||||
Sharing models is currently exclusive to RAGFlow Enterprise.
|
||||
72
docs/guides/tracing.mdx
Normal file
72
docs/guides/tracing.mdx
Normal file
@@ -0,0 +1,72 @@
|
||||
---
|
||||
sidebar_position: 9
|
||||
slug: /tracing
|
||||
---
|
||||
|
||||
# Tracing
|
||||
|
||||
Observability & Tracing with Langfuse.
|
||||
|
||||
---
|
||||
|
||||
:::info KUDOS
|
||||
This document is contributed by our community contributor [jannikmaierhoefer](https://github.com/jannikmaierhoefer). 👏
|
||||
:::
|
||||
|
||||
RAGFlow ships with a built-in [Langfuse](https://langfuse.com) integration so that you can **inspect and debug every retrieval and generation step** of your RAG pipelines in near real-time.
|
||||
|
||||
Langfuse stores traces, spans and prompt payloads in a purpose-built observability backend and offers filtering and visualisations on top.
|
||||
|
||||
:::info NOTE
|
||||
• RAGFlow **≥ 0.21.1** (contains the Langfuse connector)
|
||||
• A Langfuse workspace (cloud or self-hosted) with a _Project Public Key_ and _Secret Key_
|
||||
:::
|
||||
|
||||
---
|
||||
|
||||
## 1. Collect your Langfuse credentials
|
||||
|
||||
1. Sign in to your Langfuse dashboard.
|
||||
2. Open **Settings ▸ Projects** and either create a new project or select an existing one.
|
||||
3. Copy the **Public Key** and **Secret Key**.
|
||||
4. Note the Langfuse **host** (e.g. `https://cloud.langfuse.com`). Use the base URL of your own installation if you self-host.
|
||||
|
||||
> The keys are _project-scoped_: one pair of keys is enough for all environments that should write into the same project.
|
||||
|
||||
---
|
||||
|
||||
## 2. Add the keys to RAGFlow
|
||||
|
||||
RAGFlow stores the credentials _per tenant_. You can configure them either via the web UI or the HTTP API.
|
||||
|
||||
1. Log in to RAGFlow and click your avatar in the top-right corner.
|
||||
2. Select **API ▸ Scroll down to the bottom ▸ Langfuse Configuration**.
|
||||
3. Fill in you Langfuse **Host**, **Public Key** and **Secret Key**.
|
||||
4. Click **Save**.
|
||||
|
||||
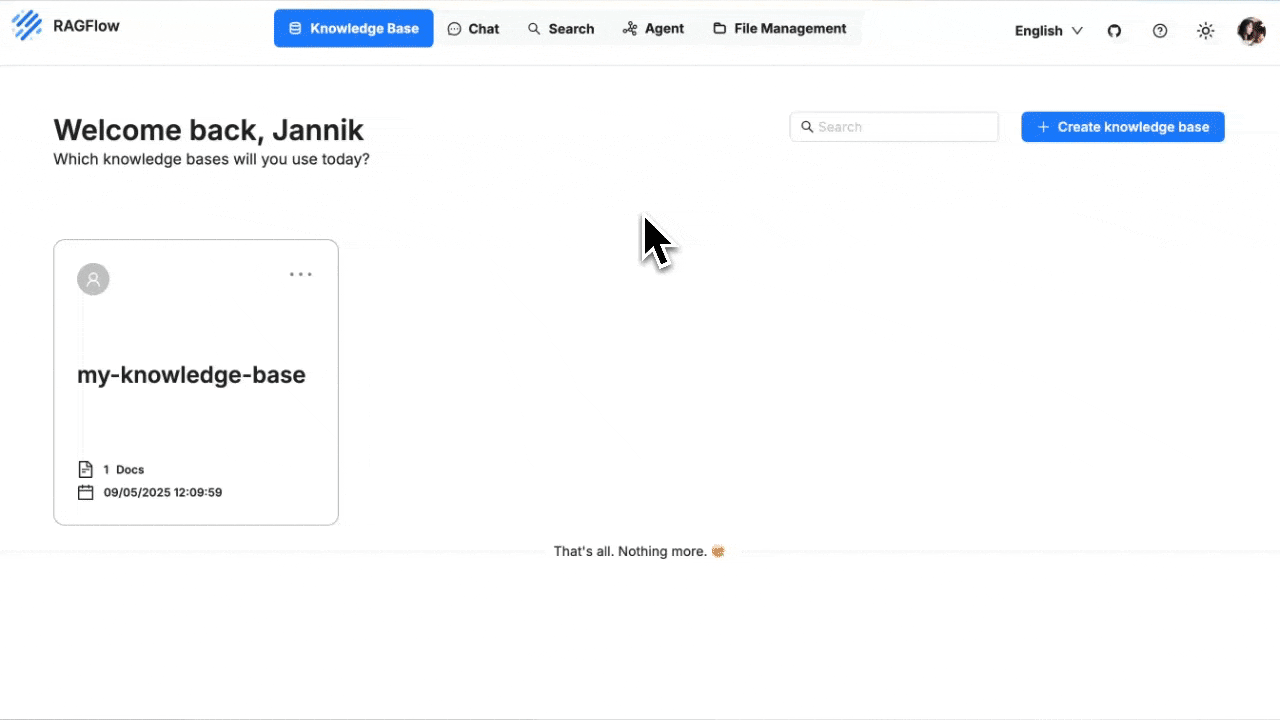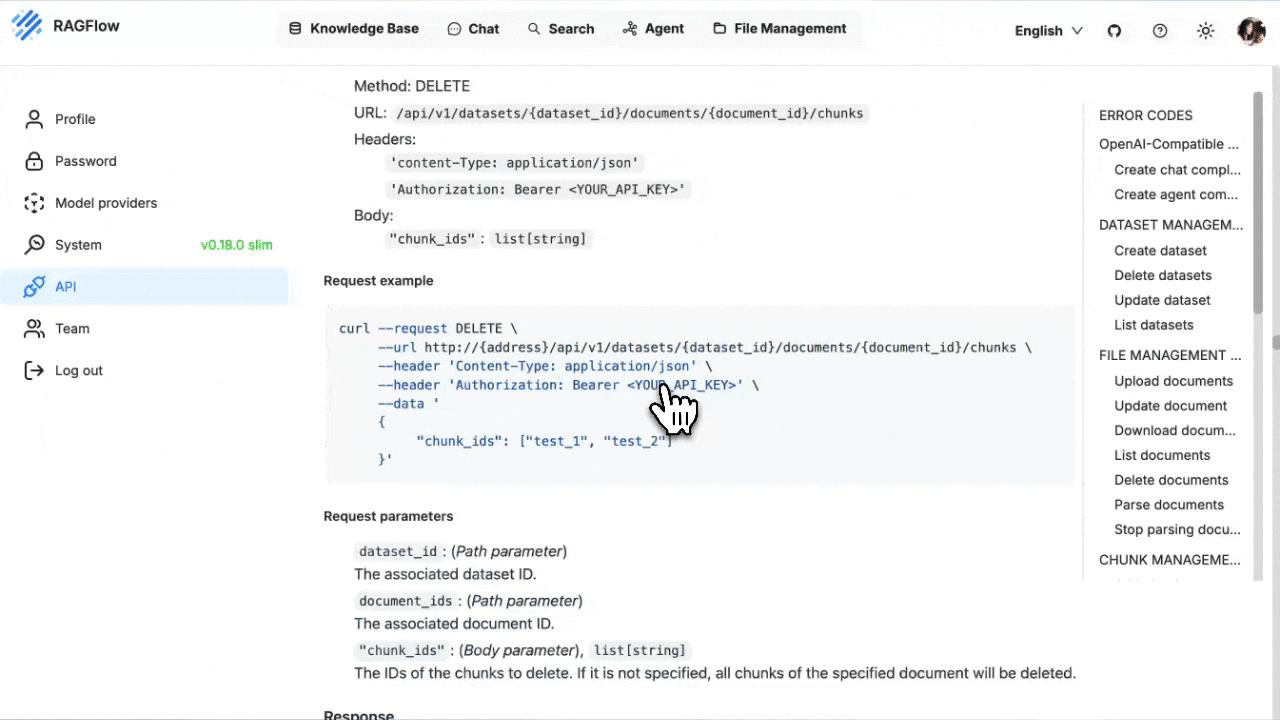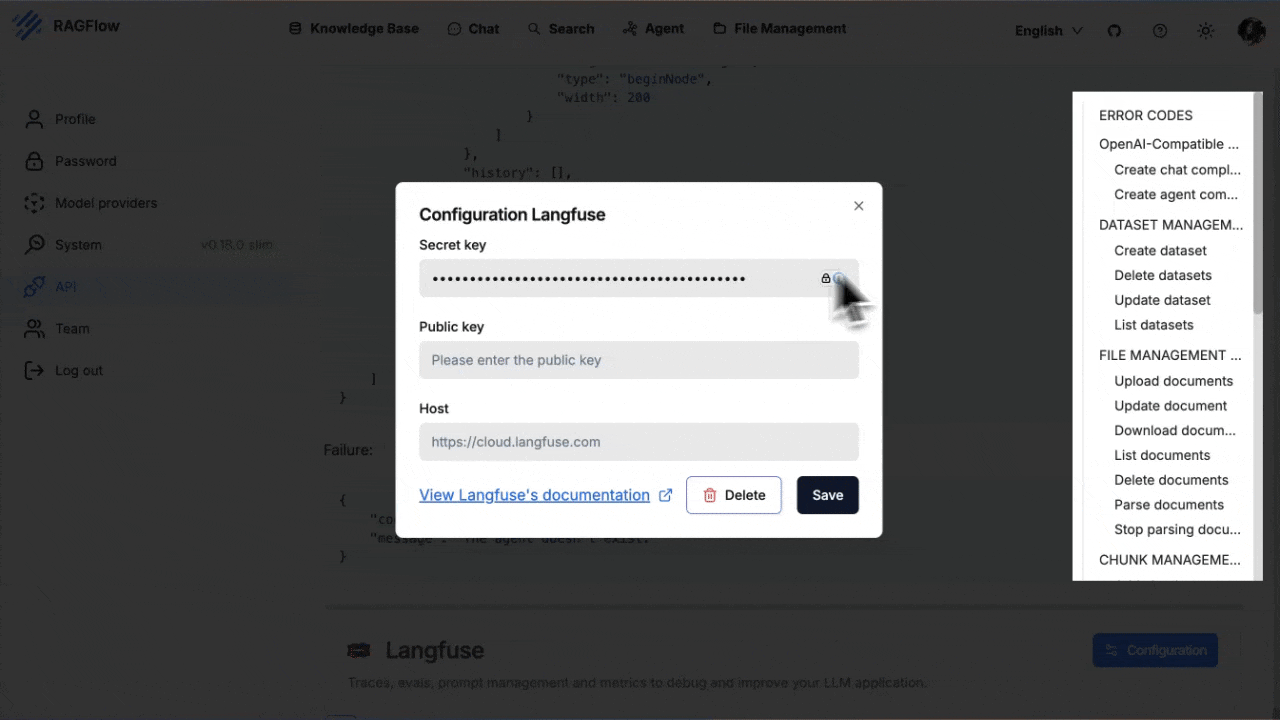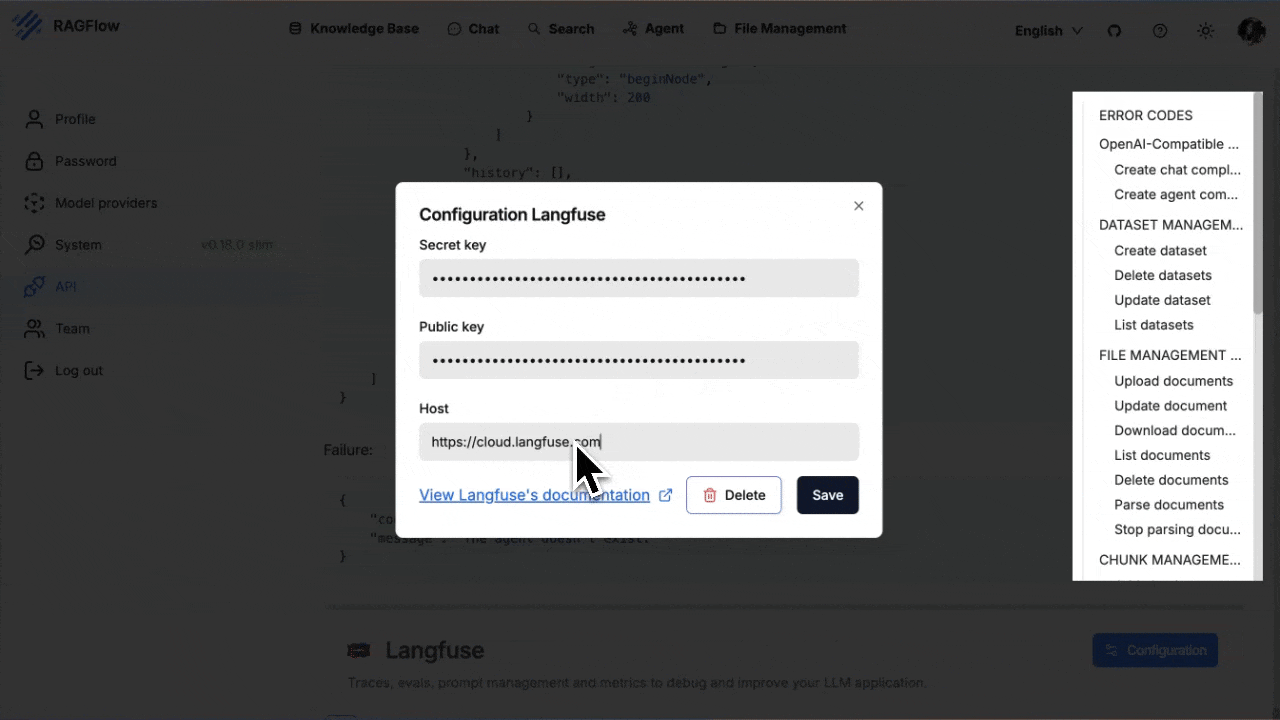
|
||||
|
||||
Once saved, RAGFlow starts emitting traces automatically – no code change required.
|
||||
|
||||
---
|
||||
|
||||
## 3. Run a pipeline and watch the traces
|
||||
|
||||
1. Execute any chat or retrieval pipeline in RAGFlow (e.g. the Quickstart demo).
|
||||
2. Open your Langfuse project ▸ **Traces**.
|
||||
3. Filter by **name ~ `ragflow-*`** (RAGFlow prefixes each trace with `ragflow-`).
|
||||
|
||||
For every user request you will see:
|
||||
|
||||
• a **trace** representing the overall request
|
||||
• **spans** for retrieval, ranking and generation steps
|
||||
• the complete **prompts**, **retrieved documents** and **LLM responses** as metadata
|
||||
|
||||
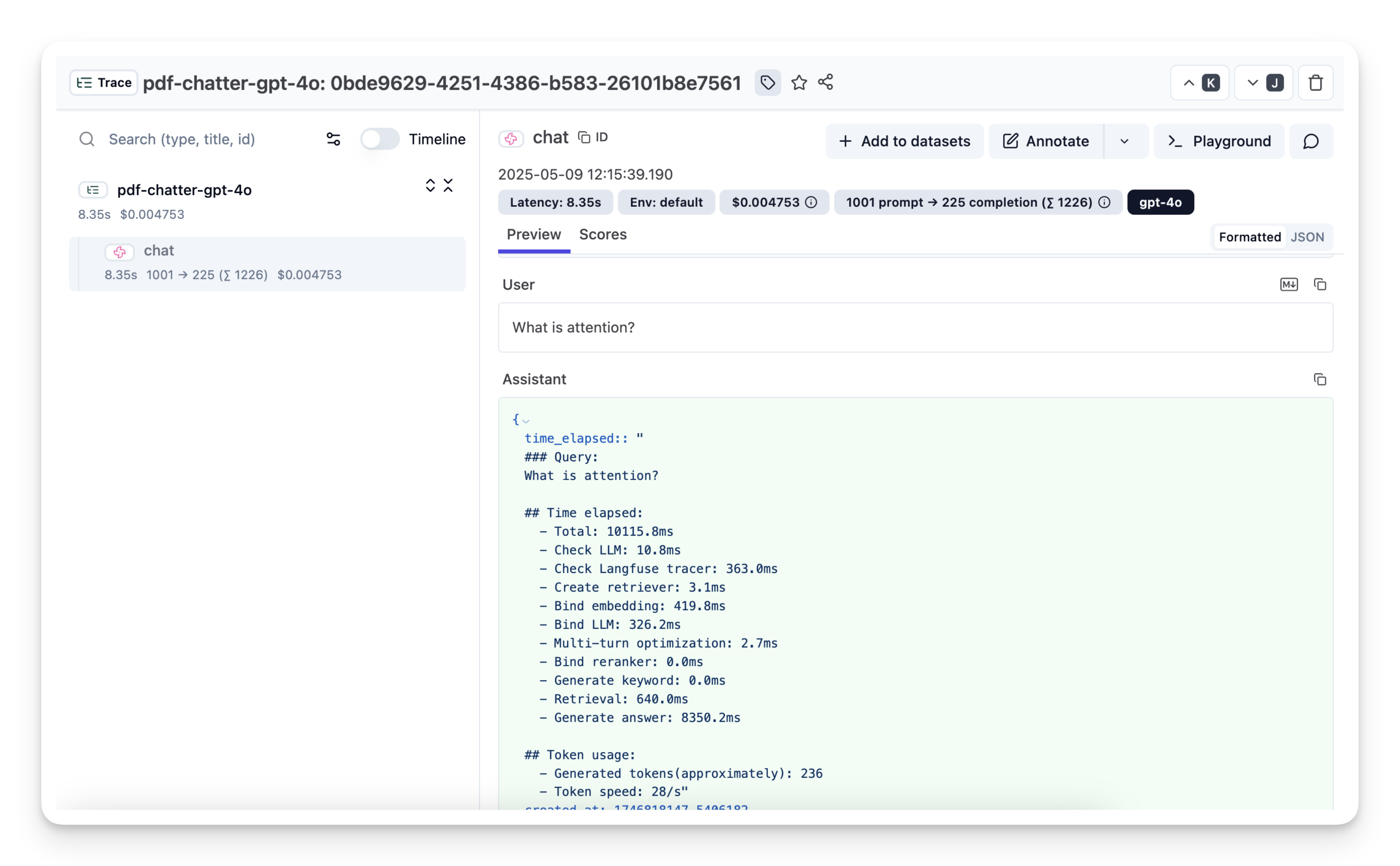
|
||||
|
||||
([Example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/0bde9629-4251-4386-b583-26101b8e7561?timestamp=2025-05-09T19%3A15%3A37.797Z&display=details&observation=823997d8-ac40-40f3-8e7b-8aa6753b499e))
|
||||
|
||||
:::tip NOTE
|
||||
Use Langfuse's diff view to compare prompt versions or drill down into long-running retrievals to identify bottlenecks.
|
||||
:::
|
||||
|
||||
123
docs/guides/upgrade_ragflow.mdx
Normal file
123
docs/guides/upgrade_ragflow.mdx
Normal file
@@ -0,0 +1,123 @@
|
||||
---
|
||||
sidebar_position: 11
|
||||
slug: /upgrade_ragflow
|
||||
---
|
||||
|
||||
# Upgrading
|
||||
import Tabs from '@theme/Tabs';
|
||||
import TabItem from '@theme/TabItem';
|
||||
|
||||
Upgrade RAGFlow to `nightly-slim`/`nightly` or the latest, published release.
|
||||
|
||||
:::info NOTE
|
||||
Upgrading RAGFlow in itself will *not* remove your uploaded/historical data. However, be aware that `docker compose -f docker/docker-compose.yml down -v` will remove Docker container volumes, resulting in data loss.
|
||||
:::
|
||||
|
||||
## Upgrade RAGFlow to `nightly-slim`/`nightly`, the most recent, tested Docker image
|
||||
|
||||
`nightly-slim` refers to the RAGFlow Docker image *without* embedding models, while `nightly` refers to the RAGFlow Docker image with embedding models. For details on their differences, see [ragflow/docker/.env](https://github.com/infiniflow/ragflow/blob/main/docker/.env).
|
||||
|
||||
To upgrade RAGFlow, you must upgrade **both** your code **and** your Docker image:
|
||||
|
||||
1. Clone the repo
|
||||
|
||||
```bash
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
```
|
||||
|
||||
2. Update **ragflow/docker/.env**:
|
||||
|
||||
<Tabs
|
||||
defaultValue="nightly-slim"
|
||||
values={[
|
||||
{label: 'nightly-slim', value: 'nightly-slim'},
|
||||
{label: 'nightly', value: 'nightly'},
|
||||
]}>
|
||||
<TabItem value="nightly-slim">
|
||||
|
||||
```bash
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:nightly-slim
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="nightly">
|
||||
|
||||
```bash
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:nightly
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
3. Update RAGFlow image and restart RAGFlow:
|
||||
|
||||
```bash
|
||||
docker compose -f docker/docker-compose.yml pull
|
||||
docker compose -f docker/docker-compose.yml up -d
|
||||
```
|
||||
|
||||
## Upgrade RAGFlow to the most recent, officially published release
|
||||
|
||||
To upgrade RAGFlow, you must upgrade **both** your code **and** your Docker image:
|
||||
|
||||
1. Clone the repo
|
||||
|
||||
```bash
|
||||
git clone https://github.com/infiniflow/ragflow.git
|
||||
```
|
||||
|
||||
2. Switch to the latest, officially published release, e.g., `v0.21.1`:
|
||||
|
||||
```bash
|
||||
git checkout -f v0.21.1
|
||||
```
|
||||
|
||||
3. Update **ragflow/docker/.env**:
|
||||
|
||||
<Tabs
|
||||
defaultValue="slim"
|
||||
values={[
|
||||
{label: 'slim', value: 'slim'},
|
||||
{label: 'full', value: 'full'},
|
||||
]}>
|
||||
<TabItem value="slim">
|
||||
|
||||
```bash
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.21.1-slim
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
<TabItem value="full">
|
||||
|
||||
```bash
|
||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.21.1
|
||||
```
|
||||
|
||||
</TabItem>
|
||||
</Tabs>
|
||||
|
||||
4. Update the RAGFlow image and restart RAGFlow:
|
||||
|
||||
```bash
|
||||
docker compose -f docker/docker-compose.yml pull
|
||||
docker compose -f docker/docker-compose.yml up -d
|
||||
```
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Do I need to back up my datasets before upgrading RAGFlow?
|
||||
|
||||
No, you do not need to. Upgrading RAGFlow in itself will *not* remove your uploaded data or dataset settings. However, be aware that `docker compose -f docker/docker-compose.yml down -v` will remove Docker container volumes, resulting in data loss.
|
||||
|
||||
### Upgrade RAGFlow in an offline environment (without Internet access)
|
||||
|
||||
1. From an environment with Internet access, pull the required Docker image.
|
||||
2. Save the Docker image to a **.tar** file.
|
||||
```bash
|
||||
docker save -o ragflow.v0.21.1.tar infiniflow/ragflow:v0.21.1
|
||||
```
|
||||
3. Copy the **.tar** file to the target server.
|
||||
4. Load the **.tar** file into Docker:
|
||||
```bash
|
||||
docker load -i ragflow.v0.21.1.tar
|
||||
```
|
||||
125
docs/ragflow-agent-overview.md
Normal file
125
docs/ragflow-agent-overview.md
Normal file
@@ -0,0 +1,125 @@
|
||||
# `agent` & `agents` 目录代码结构解析
|
||||
|
||||
本文档旨在详细解析 `ragflow_core_v0.21.1` 项目中 `src/pages/agent` 和 `src/pages/agents` 两个核心目录的结构、功能和关系。
|
||||
|
||||
- **`src/pages/agent`**: Agent/数据流的可视化编排器,是构建和调试单个 Agent 的工作区。
|
||||
- **`src/pages/agents`**: Agent 的管理中心,负责列表展示、创建、模板管理和日志查看。
|
||||
|
||||
---
|
||||
|
||||
## 1. `src/pages/agent` - Agent 可视化编排器
|
||||
|
||||
此目录是整个 RAGFlow 的核心功能所在,提供了一个基于 `@xyflow/react` 的可视化画布,用户可以通过拖拽节点和连接边的方式来构建复杂的数据处理流(DSL)。
|
||||
|
||||
### 1.1. 目录结构概览
|
||||
|
||||
```
|
||||
agent/
|
||||
├── canvas/ # 画布核心组件
|
||||
│ ├── node/ # 所有自定义节点的实现
|
||||
│ └── edge/ # 自定义边的实现
|
||||
├── form/ # 所有节点的配置表单
|
||||
│ ├── agent-form/
|
||||
│ └── ...
|
||||
├── hooks/ # 画布相关的 Hooks
|
||||
│ ├── use-build-dsl.ts
|
||||
│ └── use-save-graph.ts
|
||||
├── chat/ # 调试用的聊天面板
|
||||
├── constant/ # Agent 相关的常量
|
||||
├── index.tsx # Agent 页面主入口
|
||||
└── store.ts # Zustand store,管理画布状态
|
||||
```
|
||||
|
||||
### 1.2. 关键子目录解析
|
||||
|
||||
#### `canvas/` - 画布与节点
|
||||
|
||||
- **`canvas/index.tsx`**: 画布主组件,负责整合节点、边、背景、小地图等,并处理拖拽、连接、删除等基本交互。
|
||||
- **`canvas/node/`**: 定义了所有内置的节点类型。每个节点文件(如 `begin-node.tsx`, `retrieval-form/`) 负责节点的 UI 渲染、Handles(连接点)的定位和基本逻辑。
|
||||
- `node-wrapper.tsx`: 为所有节点提供统一的包裹层,处理选中、错误、运行状态等通用 UI 逻辑。
|
||||
- `card.tsx`: 节点内部内容的标准卡片布局。
|
||||
- **`canvas/edge/`**: 自定义边的实现,可能包含特殊的路径、箭头或交互。
|
||||
|
||||
#### `form/` - 节点配置表单
|
||||
|
||||
当用户在画布上选中一个节点时,会弹出一个表单用于配置该节点的参数。此目录存放了所有节点对应的表单组件。
|
||||
|
||||
- 目录结构与节点类型一一对应,例如 `retrieval-form/` 对应检索节点。
|
||||
- 每个表单组件负责:
|
||||
1. 渲染配置项(如输入框、下拉框、开关等)。
|
||||
2. 从节点数据中初始化表单。
|
||||
3. 将用户的输入实时或在保存时更新回节点的 `data` 属性中。
|
||||
- `form/components/` 包含了一些表单内复用的组件,如标准的输出配置 (`output.tsx`)。
|
||||
|
||||
#### `hooks/` - 核心逻辑 Hooks
|
||||
|
||||
此目录封装了画布的核心业务逻辑,使主页面 `index.tsx` 保持整洁。
|
||||
|
||||
- **`use-build-dsl.ts`**: 将画布上的节点和边(Graph a object)转换为后端可执行的领域特定语言(DSL JSON)。这是从前端图形表示到后端逻辑表示的关键转换。
|
||||
- **`use-save-graph.ts`**: 负责保存当前的图结构(节点和边的位置、数据等)到后端。通常在用户手动点击保存或自动保存时触发。
|
||||
- **`use-run-dataflow.ts`**: 触发当前 Agent 的运行,并处理返回的日志、结果等。
|
||||
- **`use-set-graph.ts`**: 从后端获取图数据并将其渲染到画布上,用于加载已保存的 Agent。
|
||||
|
||||
#### `chat/`, `debug-content/`, `log-sheet/` - 调试与运行
|
||||
|
||||
- **`chat/`**: Agent 调试时使用的聊天界面,用于发送输入并实时查看 Agent 的回复。
|
||||
- **`debug-content/`**: 调试抽屉的内容,可能包含更详细的输入/输出或日志信息。
|
||||
- **`log-sheet/`**: 展示 Agent 运行历史日志的面板。
|
||||
|
||||
#### `store.ts`
|
||||
|
||||
基于 Zustand 的状态管理,全局维护画布的状态,例如:
|
||||
- `nodes`, `edges`: 画布上的节点和边数组。
|
||||
- `onNodesChange`, `onEdgesChange`: `@xyflow/react` 需要的回调。
|
||||
- 当前选中的节点、画布的缩放/平移状态等。
|
||||
- 其他 UI 状态,如配置面板是否打开。
|
||||
|
||||
---
|
||||
|
||||
## 2. `src/pages/agents` - Agent 管理中心
|
||||
|
||||
此目录负责管理所有的 Agent 实例,是用户与 Agent 交互的入口页面。
|
||||
|
||||
### 2.1. 目录结构概览
|
||||
|
||||
```
|
||||
agents/
|
||||
├── hooks/
|
||||
│ ├── use-create-agent.ts
|
||||
│ └── use-selelct-filters.ts
|
||||
├── agent-card.tsx # 单个 Agent 的卡片展示
|
||||
├── agent-log-page.tsx # Agent 运行日志列表页
|
||||
├── agent-templates.tsx # Agent 模板页
|
||||
├── create-agent-dialog.tsx # 创建 Agent 的对话框
|
||||
├── index.tsx # Agent 列表页面主入口
|
||||
└── use-rename-agent.ts # 重命名 Agent 的 Hook
|
||||
```
|
||||
|
||||
### 2.2. 关键文件解析
|
||||
|
||||
- **`index.tsx`**: Agent 列表的主页面。通常会从后端获取所有 Agent 的列表,并使用 `agent-card.tsx` 将它们渲染出来。包含搜索、筛选和分页等功能。
|
||||
- **`agent-card.tsx`**: 以卡片形式展示单个 Agent 的摘要信息,如名称、描述、更新时间等。点击卡片通常会导航到 `src/pages/agent` 页面,并传入对应的 Agent ID。
|
||||
- **`create-agent-dialog.tsx` / `create-agent-form.tsx`**: 提供创建新 Agent 的表单和对话框。`use-create-agent.ts` Hook 封装了向后端发送创建请求的逻辑。
|
||||
- **`agent-templates.tsx`**: 展示可供用户选择的预置 Agent 模板,帮助用户快速启动。
|
||||
- **`agent-log-page.tsx`**: 展示所有 Agent 的历史运行日志,提供查询和筛选功能。点击某条日志可以查看详情。
|
||||
- **`hooks/`**: 存放与 Agent 列表管理相关的业务逻辑。
|
||||
- `use-create-agent.ts`: 封装创建 Agent 的 API 调用。
|
||||
- `use-selelct-filters.ts`: 管理列表页的筛选条件。
|
||||
|
||||
---
|
||||
|
||||
## 3. 关系与数据流
|
||||
|
||||
1. **从 `agents` 到 `agent`**:
|
||||
- 用户在 `agents` 列表页 (`/agents`) 点击一个 Agent 卡片。
|
||||
- 应用导航到 `agent` 编排页 (`/agent/{agent_id}`)。
|
||||
- `agent` 页面的 `use-set-graph.ts` Hook 被触发,使用 `agent_id` 从后端获取该 Agent 的图数据。
|
||||
- 获取到的图数据通过 `store.ts` 设置到全局状态,画布 (`canvas/index.tsx`) 监听到状态变化后,渲染出对应的节点和边。
|
||||
|
||||
2. **从 `agent` 保存与返回**:
|
||||
- 用户在 `agent` 页面修改了图结构。
|
||||
- `use-save-graph.ts` Hook 将新的图结构保存到后端。
|
||||
- `use-build-dsl.ts` 将图结构转换为 DSL 并一同保存。
|
||||
- 用户返回 `agents` 列表页,可以看到 Agent 的更新时间等信息已变化。
|
||||
|
||||
这两个目录共同构成了一个完整的 Agent 创建、管理、编排和调试的闭环。
|
||||
8
docs/references/_category_.json
Normal file
8
docs/references/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "References",
|
||||
"position": 6,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Miscellaneous References"
|
||||
}
|
||||
}
|
||||
26
docs/references/glossary.mdx
Normal file
26
docs/references/glossary.mdx
Normal file
@@ -0,0 +1,26 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
slug: /glossary
|
||||
---
|
||||
|
||||
# Glossary
|
||||
|
||||
Definitions of key terms and basic concepts related to RAGFlow.
|
||||
|
||||
---
|
||||
|
||||
import TOCInline from '@theme/TOCInline';
|
||||
|
||||
<TOCInline toc={toc} />
|
||||
|
||||
---
|
||||
|
||||
## C
|
||||
|
||||
### Cross-language search
|
||||
|
||||
Cross-language search (also known as cross-lingual retrieval) is a feature introduced in version 0.21.1. It enables users to submit queries in one language (for example, English) and retrieve relevant documents written in other languages such as Chinese or Spanish. This feature is enabled by the system’s default chat model, which translates queries to ensure accurate matching of semantic meaning across languages.
|
||||
|
||||
By enabling cross-language search, users can effortlessly access a broader range of information regardless of language barriers, significantly enhancing the system’s usability and inclusiveness.
|
||||
|
||||
This feature is available in the retrieval test and chat assistant settings. See [Run retrieval test](../guides/dataset/run_retrieval_test.md) and [Start AI chat](../guides/chat/start_chat.md) for further details.
|
||||
28
docs/references/http_api_reference.md
Normal file
28
docs/references/http_api_reference.md
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
title: HTTP API Reference
|
||||
---
|
||||
|
||||
# HTTP API Reference
|
||||
|
||||
本页为占位文档,用于满足应用在 `@parent/docs/references/http_api_reference.md` 的导入依赖。
|
||||
|
||||
> 说明:`@parent` 在 `ragflow_web/.umirc.ts` 中被设置为仓库根目录(`path.resolve(__dirname, '../')`)。
|
||||
> 因此此文件路径应位于仓库根的 `docs/references/http_api_reference.md`。
|
||||
|
||||
## Overview
|
||||
|
||||
这里将列出后端提供的 HTTP API 端点、请求参数、响应结构以及示例。
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
GET /api/v1/health
|
||||
|
||||
Response:
|
||||
{
|
||||
"status": "ok",
|
||||
"version": "0.21.1"
|
||||
}
|
||||
```
|
||||
|
||||
后续可将真实内容迁移或同步到此处,以便文档与前端导入路径保持一致。
|
||||
1962
docs/references/python_api_reference.md
Normal file
1962
docs/references/python_api_reference.md
Normal file
File diff suppressed because it is too large
Load Diff
81
docs/references/supported_models.mdx
Normal file
81
docs/references/supported_models.mdx
Normal file
@@ -0,0 +1,81 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /supported_models
|
||||
---
|
||||
|
||||
# Supported models
|
||||
|
||||
import APITable from '@site/src/components/APITable';
|
||||
|
||||
A complete list of models supported by RAGFlow, which will continue to expand.
|
||||
|
||||
```mdx-code-block
|
||||
<APITable>
|
||||
```
|
||||
|
||||
| Provider | Chat | Embedding | Rerank | Img2txt | Speech2txt | TTS |
|
||||
| --------------------- | ------------------ | ------------------ | ------------------ | ------------------ | ------------------ | ------------------ |
|
||||
| Anthropic | :heavy_check_mark: | | | | | |
|
||||
| Azure-OpenAI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: | |
|
||||
| BAAI | | :heavy_check_mark: | :heavy_check_mark: | | | |
|
||||
| BaiChuan | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| BaiduYiyan | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Bedrock | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| Cohere | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| DeepSeek | :heavy_check_mark: | | | | | |
|
||||
| FastEmbed | | :heavy_check_mark: | | | | |
|
||||
| Fish Audio | | | | | | :heavy_check_mark: |
|
||||
| Gemini | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| Google Cloud | :heavy_check_mark: | | | | | |
|
||||
| GPUStack | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Groq | :heavy_check_mark: | | | | | |
|
||||
| HuggingFace | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| Jina | | :heavy_check_mark: | :heavy_check_mark: | | | |
|
||||
| LeptonAI | :heavy_check_mark: | | | | | |
|
||||
| LocalAI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| LM-Studio | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| MiniMax | :heavy_check_mark: | | | | | |
|
||||
| Mistral | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| ModelScope | :heavy_check_mark: | | | | | |
|
||||
| Moonshot | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| Novita AI | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| NVIDIA | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Ollama | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| OpenAI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| OpenAI-API-Compatible | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| OpenRouter | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| PerfXCloud | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| Replicate | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| PPIO | :heavy_check_mark: | | | | | |
|
||||
| SILICONFLOW | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| StepFun | :heavy_check_mark: | | | | | |
|
||||
| Tencent Hunyuan | :heavy_check_mark: | | | | | |
|
||||
| Tencent Cloud | | | | | :heavy_check_mark: | |
|
||||
| TogetherAI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Tongyi-Qianwen | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| Upstage | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| VLLM | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| VolcEngine | :heavy_check_mark: | | | | | |
|
||||
| Voyage AI | | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| Xinference | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| XunFei Spark | :heavy_check_mark: | | | | | :heavy_check_mark: |
|
||||
| xAI | :heavy_check_mark: | | | :heavy_check_mark: | | |
|
||||
| Youdao | | :heavy_check_mark: | :heavy_check_mark: | | | |
|
||||
| ZHIPU-AI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | |
|
||||
| 01.AI | :heavy_check_mark: | | | | | |
|
||||
| DeepInfra | :heavy_check_mark: | :heavy_check_mark: | | | :heavy_check_mark: | :heavy_check_mark: |
|
||||
| 302.AI | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | |
|
||||
| CometAPI | :heavy_check_mark: | :heavy_check_mark: | | | | |
|
||||
| DeerAPI | :heavy_check_mark: | :heavy_check_mark: | | :heavy_check_mark: | | :heavy_check_mark: |
|
||||
|
||||
```mdx-code-block
|
||||
</APITable>
|
||||
```
|
||||
|
||||
:::danger IMPORTANT
|
||||
If your model is not listed here but has APIs compatible with those of OpenAI, click **OpenAI-API-Compatible** on the **Model providers** page to configure your model.
|
||||
:::
|
||||
|
||||
:::note
|
||||
The list of supported models is extracted from [this source](https://github.com/infiniflow/ragflow/blob/main/rag/llm/__init__.py) and may not be the most current. For the latest supported model list, please refer to the Python file.
|
||||
:::
|
||||
@@ -6,18 +6,28 @@ import tseslint from 'typescript-eslint'
|
||||
import { defineConfig, globalIgnores } from 'eslint/config'
|
||||
|
||||
export default defineConfig([
|
||||
globalIgnores(['dist', 'rag_web_core']),
|
||||
globalIgnores(['dist', 'ragflow_web']),
|
||||
{
|
||||
files: ['**/*.{ts,tsx}'],
|
||||
rules: {},
|
||||
extends: [
|
||||
js.configs.recommended,
|
||||
tseslint.configs.recommended,
|
||||
// tseslint.configs.recommended,
|
||||
reactHooks.configs['recommended-latest'],
|
||||
reactRefresh.configs.vite,
|
||||
],
|
||||
languageOptions: {
|
||||
ecmaVersion: 2020,
|
||||
globals: globals.browser,
|
||||
parser: tseslint.parser,
|
||||
parserOptions: {
|
||||
ecmaFeatures: { jsx: true },
|
||||
},
|
||||
},
|
||||
plugins: {
|
||||
'@typescript-eslint': tseslint.plugin,
|
||||
'react-hooks': reactHooks,
|
||||
'react-refresh': reactRefresh,
|
||||
},
|
||||
},
|
||||
])
|
||||
|
||||
@@ -2,9 +2,9 @@
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="UTF-8" />
|
||||
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
|
||||
<link rel="icon" type="image/svg+xml" href="/logo.svg" />
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
|
||||
<title>teres_web_frontend</title>
|
||||
<title>TERES AI</title>
|
||||
</head>
|
||||
<body>
|
||||
<div id="root"></div>
|
||||
|
||||
13
mcp/Filesystem.json
Normal file
13
mcp/Filesystem.json
Normal file
@@ -0,0 +1,13 @@
|
||||
{
|
||||
"mcpServers": {
|
||||
"Filesystem": {
|
||||
"command": "npx",
|
||||
"args": [
|
||||
"-y",
|
||||
"@modelcontextprotocol/server-filesystem",
|
||||
"/path/to/allowed/directory"
|
||||
],
|
||||
"env": {}
|
||||
}
|
||||
}
|
||||
}
|
||||
53
mcp/Mock.json
Normal file
53
mcp/Mock.json
Normal file
@@ -0,0 +1,53 @@
|
||||
{
|
||||
"mcpServers": {
|
||||
"Time": {
|
||||
"type": "mcp_server_time",
|
||||
"url": "http://localhost:8080",
|
||||
"name": "Time Server",
|
||||
"authorization_token": "",
|
||||
"tool_configuration": {}
|
||||
},
|
||||
"Mock": {
|
||||
"type": "mcp_server_mock",
|
||||
"url": "http://localhost:8080",
|
||||
"name": "Mock Server",
|
||||
"authorization_token": "",
|
||||
"tool_configuration": {}
|
||||
},
|
||||
"Filesystem": {
|
||||
"type": "mcp_server_filesystem",
|
||||
"url": "http://localhost:8080",
|
||||
"name": "Filesystem Server",
|
||||
"authorization_token": "",
|
||||
"tool_configuration": {}
|
||||
},
|
||||
"MockFilesystem": {
|
||||
"type": "mcp_server_mock_filesystem",
|
||||
"url": "http://localhost:8080",
|
||||
"name": "Mock Filesystem Server",
|
||||
"authorization_token": "",
|
||||
"tool_configuration": {}
|
||||
},
|
||||
"MockTime": {
|
||||
"type": "mcp_server_mock_time",
|
||||
"url": "http://localhost:8080",
|
||||
"name": "Mock Time Server",
|
||||
"authorization_token": "",
|
||||
"tool_configuration": {}
|
||||
},
|
||||
"MockMock": {
|
||||
"type": "mcp_server_mock_mock",
|
||||
"url": "http://localhost:8080",
|
||||
"name": "Mock Mock Server",
|
||||
"authorization_token": "",
|
||||
"tool_configuration": {}
|
||||
},
|
||||
"MockMockFilesystem": {
|
||||
"type": "mcp_server_mock_mock_filesystem",
|
||||
"url": "http://localhost:8080",
|
||||
"name": "Mock Mock Filesystem Server",
|
||||
"authorization_token": "",
|
||||
"tool_configuration": {}
|
||||
}
|
||||
}
|
||||
}
|
||||
16
package.json
16
package.json
@@ -5,9 +5,11 @@
|
||||
"type": "module",
|
||||
"scripts": {
|
||||
"dev": "vite",
|
||||
"dev:ragflow": "pnpm -r --filter ragflow_web run dev",
|
||||
"build": "tsc -b && vite build",
|
||||
"lint": "eslint .",
|
||||
"preview": "vite preview"
|
||||
"preview": "vite preview",
|
||||
"postinstall": "node scripts/copy-pdfjs-worker.mjs"
|
||||
},
|
||||
"dependencies": {
|
||||
"@emotion/react": "^11.14.0",
|
||||
@@ -16,6 +18,8 @@
|
||||
"@mui/material": "^7.3.4",
|
||||
"@mui/x-data-grid": "^8.14.0",
|
||||
"@mui/x-date-pickers": "^8.14.0",
|
||||
"@teres/iframe-bridge": "workspace:*",
|
||||
"@xyflow/react": "^12.8.6",
|
||||
"ahooks": "^3.9.5",
|
||||
"axios": "^1.12.2",
|
||||
"dayjs": "^1.11.18",
|
||||
@@ -24,6 +28,9 @@
|
||||
"js-base64": "^3.7.8",
|
||||
"jsencrypt": "^3.5.4",
|
||||
"lodash": "^4.17.21",
|
||||
"loglevel": "^1.9.2",
|
||||
"pdfjs-dist": "^5.4.394",
|
||||
"penpal": "^6.2.1",
|
||||
"react": "^18.3.1",
|
||||
"react-dom": "^18.3.1",
|
||||
"react-hook-form": "^7.64.0",
|
||||
@@ -31,7 +38,9 @@
|
||||
"react-is": "18.3.1",
|
||||
"react-router-dom": "^7.9.4",
|
||||
"uuid": "^13.0.0",
|
||||
"zustand": "^5.0.8"
|
||||
"zustand": "^5.0.8",
|
||||
"@monaco-editor/react": "^4.6.0",
|
||||
"monaco-editor": "^0.52.2"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@eslint/js": "^9.36.0",
|
||||
@@ -46,6 +55,7 @@
|
||||
"globals": "^16.4.0",
|
||||
"typescript": "~5.9.3",
|
||||
"typescript-eslint": "^8.45.0",
|
||||
"vite": "^7.1.7"
|
||||
"vite": "^7.1.7",
|
||||
"vite-plugin-svgr": "^4.5.0"
|
||||
}
|
||||
}
|
||||
|
||||
51
packages/auth-gateway/README.md
Normal file
51
packages/auth-gateway/README.md
Normal file
@@ -0,0 +1,51 @@
|
||||
# @teres/auth-gateway
|
||||
|
||||
Minimal Node session service to share auth token via Cookie or API.
|
||||
|
||||
## Run
|
||||
|
||||
```sh
|
||||
pnpm -F @teres/auth-gateway dev
|
||||
```
|
||||
|
||||
Default port: `7000`. Configure via env:
|
||||
|
||||
- `PORT=7000`
|
||||
- `ALLOWED_ORIGINS=http://localhost:5173,http://localhost:6006`
|
||||
- `COOKIE_NAME=sid`
|
||||
- `COOKIE_DOMAIN=` (optional)
|
||||
- `COOKIE_SECURE=false` (set `true` in HTTPS)
|
||||
- `COOKIE_SAMESITE=lax` (`lax|strict|none`)
|
||||
- `EXPOSE_TOKEN=true` (set `false` to hide token in GET response)
|
||||
|
||||
## Endpoints
|
||||
|
||||
- `GET /health` → `{ ok: true }`
|
||||
- `POST /auth/session` → set token; accepts JSON `{ token }` or `Authorization: Bearer <token>`
|
||||
- `GET /auth/session` → read session; returns `{ exists, updatedAt, token? }`
|
||||
- `DELETE /auth/session` → clear session and cookie
|
||||
|
||||
## Frontend usage
|
||||
|
||||
After login in host app:
|
||||
|
||||
```ts
|
||||
await fetch("http://localhost:7000/auth/session", {
|
||||
method: "POST",
|
||||
headers: { "Content-Type": "application/json" },
|
||||
body: JSON.stringify({ token }),
|
||||
credentials: "include",
|
||||
});
|
||||
```
|
||||
|
||||
In iframe app (ragflow) to read the token (if `EXPOSE_TOKEN=true`):
|
||||
|
||||
```ts
|
||||
const res = await fetch("http://localhost:7000/auth/session", {
|
||||
credentials: "include",
|
||||
});
|
||||
const data = await res.json();
|
||||
const token = data.token; // may be undefined if EXPOSE_TOKEN=false
|
||||
```
|
||||
|
||||
Alternatively, keep `EXPOSE_TOKEN=false` and use a backend that reads the cookie server-side. Or pass the token via your `iframe-bridge`/Penpal channel.
|
||||
28
packages/auth-gateway/package.json
Normal file
28
packages/auth-gateway/package.json
Normal file
@@ -0,0 +1,28 @@
|
||||
{
|
||||
"name": "@teres/auth-gateway",
|
||||
"version": "0.1.0",
|
||||
"private": true,
|
||||
"type": "module",
|
||||
"description": "Minimal Node session service to share auth token via Cookie or API.",
|
||||
"scripts": {
|
||||
"dev": "tsx watch src/index.ts",
|
||||
"build": "tsc -b",
|
||||
"start": "node dist/index.js"
|
||||
},
|
||||
"dependencies": {
|
||||
"cors": "^2.8.5",
|
||||
"cookie-parser": "^1.4.6",
|
||||
"dotenv": "^16.4.5",
|
||||
"express": "^4.19.2"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/cookie-parser": "^1.4.7",
|
||||
"@types/cors": "^2.8.17",
|
||||
"@types/express": "^4.17.21",
|
||||
"tsx": "^4.7.0",
|
||||
"typescript": "~5.9.3"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=18"
|
||||
}
|
||||
}
|
||||
107
packages/auth-gateway/src/index.ts
Normal file
107
packages/auth-gateway/src/index.ts
Normal file
@@ -0,0 +1,107 @@
|
||||
import express from "express";
|
||||
import cors from "cors";
|
||||
import cookieParser from "cookie-parser";
|
||||
import dotenv from "dotenv";
|
||||
import { randomUUID } from "node:crypto";
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const PORT = Number(process.env.PORT || 7000);
|
||||
const COOKIE_NAME = process.env.COOKIE_NAME || "sid";
|
||||
const COOKIE_DOMAIN = process.env.COOKIE_DOMAIN || undefined; // e.g. your.dev.local
|
||||
const COOKIE_SECURE = String(process.env.COOKIE_SECURE || "false") === "true"; // true for https
|
||||
const COOKIE_SAMESITE = (process.env.COOKIE_SAMESITE || "lax") as
|
||||
| "lax"
|
||||
| "strict"
|
||||
| "none";
|
||||
const ALLOWED_ORIGINS = (process.env.ALLOWED_ORIGINS || "http://localhost:5173,http://localhost:6006")
|
||||
.split(",")
|
||||
.map((s) => s.trim())
|
||||
.filter(Boolean);
|
||||
const EXPOSE_TOKEN = String(process.env.EXPOSE_TOKEN || "true") !== "false"; // if false, GET won't return raw token
|
||||
|
||||
// In-memory store: sid -> token
|
||||
const store = new Map<string, { token: string; updatedAt: number }>();
|
||||
|
||||
const app = express();
|
||||
|
||||
app.use(
|
||||
cors({
|
||||
origin(origin, cb) {
|
||||
if (!origin) return cb(null, true); // allow same-origin or curl
|
||||
if (ALLOWED_ORIGINS.includes(origin)) return cb(null, true);
|
||||
return cb(new Error("Not allowed by CORS"));
|
||||
},
|
||||
credentials: true,
|
||||
})
|
||||
);
|
||||
app.use(cookieParser());
|
||||
app.use(express.json());
|
||||
|
||||
// Ensure a session cookie exists
|
||||
app.use((req, res, next) => {
|
||||
let sid = req.cookies[COOKIE_NAME];
|
||||
if (!sid) {
|
||||
sid = randomUUID();
|
||||
res.cookie(COOKIE_NAME, sid, {
|
||||
httpOnly: true,
|
||||
sameSite: COOKIE_SAMESITE,
|
||||
secure: COOKIE_SECURE,
|
||||
domain: COOKIE_DOMAIN,
|
||||
path: "/",
|
||||
maxAge: 1000 * 60 * 60 * 24, // 1 day
|
||||
});
|
||||
}
|
||||
(req as any).sid = sid;
|
||||
next();
|
||||
});
|
||||
|
||||
app.get("/health", (_req, res) => {
|
||||
res.json({ ok: true, service: "auth-gateway", port: PORT });
|
||||
});
|
||||
|
||||
// Set token: accept JSON body { token } or Authorization: Bearer <token>
|
||||
app.post("/auth/session", (req, res) => {
|
||||
const sid: string = (req as any).sid;
|
||||
const bearer = req.header("authorization") || req.header("Authorization");
|
||||
let token = req.body?.token as string | undefined;
|
||||
if (!token && bearer && bearer.toLowerCase().startsWith("bearer ")) {
|
||||
token = bearer.slice(7);
|
||||
}
|
||||
if (!token) {
|
||||
return res.status(400).json({ ok: false, error: "Missing token" });
|
||||
}
|
||||
store.set(sid, { token, updatedAt: Date.now() });
|
||||
res.json({ ok: true });
|
||||
});
|
||||
|
||||
// Get token (if EXPOSE_TOKEN=true). Always returns session status.
|
||||
app.get("/auth/session", (req, res) => {
|
||||
const sid: string = (req as any).sid;
|
||||
const item = store.get(sid);
|
||||
const data: any = { ok: true, exists: Boolean(item), updatedAt: item?.updatedAt ?? null };
|
||||
if (EXPOSE_TOKEN && item) data.token = item.token;
|
||||
res.json(data);
|
||||
});
|
||||
|
||||
// Logout / clear token
|
||||
app.delete("/auth/session", (req, res) => {
|
||||
const sid: string = (req as any).sid;
|
||||
store.delete(sid);
|
||||
// Optionally clear cookie
|
||||
res.clearCookie(COOKIE_NAME, {
|
||||
httpOnly: true,
|
||||
sameSite: COOKIE_SAMESITE,
|
||||
secure: COOKIE_SECURE,
|
||||
domain: COOKIE_DOMAIN,
|
||||
path: "/",
|
||||
});
|
||||
res.json({ ok: true });
|
||||
});
|
||||
|
||||
app.listen(PORT, () => {
|
||||
// eslint-disable-next-line no-console
|
||||
console.log(`Auth gateway running on http://localhost:${PORT}`);
|
||||
// eslint-disable-next-line no-console
|
||||
console.log(`Allowed origins: ${ALLOWED_ORIGINS.join(", ")}`);
|
||||
});
|
||||
9
packages/auth-gateway/tsconfig.json
Normal file
9
packages/auth-gateway/tsconfig.json
Normal file
@@ -0,0 +1,9 @@
|
||||
{
|
||||
"extends": "../../tsconfig.node.json",
|
||||
"compilerOptions": {
|
||||
"outDir": "dist",
|
||||
"rootDir": "src",
|
||||
"tsBuildInfoFile": "./dist/.tsbuildinfo"
|
||||
},
|
||||
"include": ["src"]
|
||||
}
|
||||
141
packages/iframe-bridge/README.md
Normal file
141
packages/iframe-bridge/README.md
Normal file
@@ -0,0 +1,141 @@
|
||||
# @teres/iframe-bridge
|
||||
|
||||
一个基于 [Penpal](https://github.com/Aaronius/penpal) 的轻量 iframe 通信桥,帮助宿主页面与子应用(iframe)安全、稳定地进行双向方法调用与状态同步。
|
||||
|
||||
## 为什么需要它
|
||||
- 将跨项目的交互(如语言切换、导航、关闭、就绪通知)抽象为清晰的 API。
|
||||
- 在 Monorepo 或多项目场景下,提供“宿主 ↔ 子应用”的统一通信约定。
|
||||
- 屏蔽 Penpal 细节,专注业务方法与类型定义。
|
||||
|
||||
## 安装与版本
|
||||
- 已在工作空间内作为包使用(`packages/iframe-bridge`)。
|
||||
- 依赖:`penpal@^6.2.1`。
|
||||
|
||||
## 目录结构
|
||||
```
|
||||
packages/iframe-bridge/
|
||||
├── package.json
|
||||
├── README.md
|
||||
└── src/
|
||||
├── index.ts # 入口聚合与导出(不含业务逻辑)
|
||||
├── types.ts # 对外类型:HostApi、ChildApi
|
||||
├── path.ts # 路径转换与是否嵌入判断
|
||||
├── client.ts # 子端到父端的连接与客户端方法
|
||||
├── host.ts # 宿主侧创建与管理与子端的连接
|
||||
└── logger.ts # 统一日志工具
|
||||
```
|
||||
|
||||
## 核心概念
|
||||
- Host(宿主):包含 `iframe` 的父页面。
|
||||
- Child(子端):被嵌入在 `iframe` 中的子应用。子端暴露方法给宿主调用。
|
||||
- Penpal:在宿主与子端之间建立安全的双向 RPC(方法调用)连接。
|
||||
|
||||
## 快速上手
|
||||
|
||||
### 宿主侧(Host)示例:创建连接并缓存子端引用
|
||||
```ts
|
||||
import { createPenpalHostBridge } from '@teres/iframe-bridge';
|
||||
|
||||
// iframeRef 指向你页面中的 <iframe>
|
||||
const { child, destroy } = await createPenpalHostBridge({
|
||||
iframe: iframeRef.current!,
|
||||
methods: {
|
||||
// 暴露给“子端”可调用的宿主方法
|
||||
navigate: (path: string) => {
|
||||
// 宿主导航逻辑
|
||||
},
|
||||
close: () => {
|
||||
// 关闭或返回逻辑
|
||||
},
|
||||
agentReady: (agentId?: string) => {
|
||||
// 子端就绪通知处理
|
||||
},
|
||||
},
|
||||
});
|
||||
|
||||
// child 是一个 Promise,解析后可拿到子端暴露的方法(例如 changeLanguage)
|
||||
await child; // 也可以缓存后续使用
|
||||
|
||||
// 组件卸载或需要重建连接时
|
||||
await destroy();
|
||||
```
|
||||
|
||||
在你的项目中(如 `src/pages/ragflow/iframe.tsx`)通常会把 `child` 引用存到一个管理器,供语言切换等场景调用。
|
||||
|
||||
### 子端侧(Child)示例:暴露方法并与宿主交互
|
||||
```ts
|
||||
import Bridge from '@teres/iframe-bridge';
|
||||
|
||||
// 在子应用初始化时调用(例如根组件 useEffect 中)
|
||||
Bridge.initChildBridge({
|
||||
// 暴露给“宿主”可调用的子端方法
|
||||
methods: {
|
||||
changeLanguage: async (lang: string) => {
|
||||
// 你的 i18n 切换逻辑,例如:
|
||||
// await i18n.changeLanguage(lang);
|
||||
},
|
||||
},
|
||||
});
|
||||
|
||||
// 主动与宿主交互(可选)
|
||||
Bridge.clientReady();
|
||||
Bridge.clientNavigate('/some/path');
|
||||
Bridge.clientClose();
|
||||
```
|
||||
|
||||
## API 参考
|
||||
|
||||
### 类型(types.ts)
|
||||
- `HostApi`
|
||||
- `navigate(path: string): void`
|
||||
- `close(): void`
|
||||
- `agentReady(agentId?: string): void`
|
||||
- `ChildApi`
|
||||
- `changeLanguage(lang: string): Promise<void>`
|
||||
|
||||
### 路径与嵌入(path.ts)
|
||||
- `isEmbedded(): boolean` 判断当前窗口是否运行在 iframe 中(且需要通信)。
|
||||
- `toHostPath(childPath: string): string` 将子端路径转换为宿主侧路由前缀路径。
|
||||
- `toChildPath(hostPath: string): string` 将宿主路径映射回子端路径。
|
||||
|
||||
### 子端客户端方法(client.ts)
|
||||
- `getClientHostApi(): Promise<HostApi>` 建立并缓存与宿主的连接。
|
||||
- `clientNavigate(path: string): Promise<void>` 请求宿主导航。
|
||||
- `clientClose(): Promise<void>` 请求宿主关闭或返回。
|
||||
- `clientReady(agentId?: string): Promise<void>` 通知宿主子端就绪。
|
||||
- `initChildBridge(options: { methods: Partial<ChildApi> }): Promise<void>` 在子端暴露方法供宿主调用(如 `changeLanguage`)。
|
||||
|
||||
### 宿主桥接(host.ts)
|
||||
- `createPenpalHostBridge({ iframe, methods })`
|
||||
- `iframe: HTMLIFrameElement`
|
||||
- `methods: Partial<HostApi>` 暴露给子端可调用的宿主方法。
|
||||
- 返回:`{ child: Promise<ChildExposed>, destroy: () => Promise<void> }`
|
||||
- `child`:解析后可获得子端暴露的方法(如 `changeLanguage`)。
|
||||
- `destroy`:销毁连接与事件监听。
|
||||
|
||||
## 语言联动最佳实践
|
||||
1. 子端在初始化中通过 `initChildBridge` 暴露 `changeLanguage`。
|
||||
2. 宿主在创建连接后缓存 `child` 引用。
|
||||
3. 宿主语言切换组件在变更时调用:
|
||||
```ts
|
||||
const child = await childPromise; // 取到缓存的子端引用
|
||||
await child.changeLanguage(nextLang);
|
||||
```
|
||||
|
||||
## 调试与排错
|
||||
- 确保 iframe 与宿主同源或允许跨源通信(Penpal 支持跨源,但需正确 URL)。
|
||||
- 连接建立需要子端加载完成;在子端 `initChildBridge` 之前调用子端方法会报错或超时。
|
||||
- 若需要观察连接过程,可在 `logger.ts` 中启用调试日志或在业务代码中打点。
|
||||
- 组件卸载时务必调用 `destroy()`,避免内存泄漏或事件残留。
|
||||
|
||||
## 设计说明
|
||||
- 入口 `index.ts` 仅做导出聚合,具体逻辑按职责拆分到 `types/logger/path/client/host`。
|
||||
- 子端侧会缓存一次宿主连接,避免重复握手,提高性能与稳定性。
|
||||
|
||||
## 常见问题
|
||||
- 调用时机过早:请在子端完成初始化(`initChildBridge`)后再由宿主调用子端方法。
|
||||
- 路径映射:`toHostPath`/`toChildPath` 默认适配当前项目前缀,如需自定义可扩展配置模块。
|
||||
- 异步方法:所有跨端调用均为异步,注意 `await` 与错误处理。
|
||||
|
||||
---
|
||||
若你需要把路径前缀改为可配置项或扩展更多方法(如主题切换、会话同步),欢迎提 issue 或继续迭代。
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user