Merge branch 'v0.21.1-fastapi' of https://code.deep-pilot.chat/AI_POC/TERES_fastapi_backend into v0.21.1-fastapi
This commit is contained in:
25
Dockerfile
25
Dockerfile
@@ -13,15 +13,30 @@ USER root
|
|||||||
|
|
||||||
WORKDIR /ragflow
|
WORKDIR /ragflow
|
||||||
|
|
||||||
# install dependencies from uv.lock file
|
# Ensure Node.js/npm available even if base image lacks it
|
||||||
COPY pyproject.toml uv.lock ./
|
RUN --mount=type=cache,id=ragflow_apt,target=/var/cache/apt,sharing=locked \
|
||||||
|
if ! command -v npm >/dev/null 2>&1; then \
|
||||||
|
apt-get update && \
|
||||||
|
curl -fsSL https://deb.nodesource.com/setup_20.x | bash - && \
|
||||||
|
apt-get install -y --no-install-recommends nodejs && \
|
||||||
|
rm -rf /var/lib/apt/lists/*; \
|
||||||
|
fi
|
||||||
|
|
||||||
|
# Set UV HTTP timeout to handle large package downloads (e.g., nvidia-cusolver-cu12)
|
||||||
|
# Default is 30s, increase to 600s (10 minutes) for large packages
|
||||||
|
ENV UV_HTTP_TIMEOUT=600
|
||||||
|
|
||||||
|
# install dependencies from pyproject.toml
|
||||||
|
COPY pyproject.toml ./
|
||||||
# https://github.com/astral-sh/uv/issues/10462
|
# https://github.com/astral-sh/uv/issues/10462
|
||||||
# uv records index url into uv.lock but doesn't failover among multiple indexes
|
# uv records index url into uv.lock but doesn't failover among multiple indexes
|
||||||
|
# Generate uv.lock from pyproject.toml and install dependencies with cache
|
||||||
RUN --mount=type=cache,id=ragflow_uv,target=/root/.cache/uv,sharing=locked \
|
RUN --mount=type=cache,id=ragflow_uv,target=/root/.cache/uv,sharing=locked \
|
||||||
if [ "$NEED_MIRROR" == "1" ]; then \
|
if [ "$NEED_MIRROR" == "1" ]; then \
|
||||||
|
uv lock --index-url https://mirrors.aliyun.com/pypi/simple; \
|
||||||
sed -i 's|pypi.org|mirrors.aliyun.com/pypi|g' uv.lock; \
|
sed -i 's|pypi.org|mirrors.aliyun.com/pypi|g' uv.lock; \
|
||||||
else \
|
else \
|
||||||
|
uv lock; \
|
||||||
sed -i 's|mirrors.aliyun.com/pypi|pypi.org|g' uv.lock; \
|
sed -i 's|mirrors.aliyun.com/pypi|pypi.org|g' uv.lock; \
|
||||||
fi; \
|
fi; \
|
||||||
if [ "$LIGHTEN" == "1" ]; then \
|
if [ "$LIGHTEN" == "1" ]; then \
|
||||||
@@ -68,13 +83,13 @@ COPY rag rag
|
|||||||
COPY agent agent
|
COPY agent agent
|
||||||
COPY graphrag graphrag
|
COPY graphrag graphrag
|
||||||
COPY agentic_reasoning agentic_reasoning
|
COPY agentic_reasoning agentic_reasoning
|
||||||
COPY pyproject.toml uv.lock ./
|
COPY pyproject.toml ./
|
||||||
COPY mcp mcp
|
COPY mcp mcp
|
||||||
COPY plugin plugin
|
COPY plugin plugin
|
||||||
|
|
||||||
COPY docker/service_conf.yaml.template ./conf/service_conf.yaml.template
|
COPY docker/service_conf.yaml.template ./conf/service_conf.yaml.template
|
||||||
COPY docker/entrypoint.sh ./
|
COPY --chmod=+x docker/entrypoint.sh ./entrypoint.sh
|
||||||
RUN chmod +x ./entrypoint*.sh
|
|
||||||
|
|
||||||
# Copy compiled web pages
|
# Copy compiled web pages
|
||||||
COPY --from=builder /ragflow/web/dist /ragflow/web/dist
|
COPY --from=builder /ragflow/web/dist /ragflow/web/dist
|
||||||
|
|||||||
@@ -162,14 +162,26 @@ def setup_routes(app: FastAPI):
|
|||||||
from api.apps.chunk_app import router as chunk_router
|
from api.apps.chunk_app import router as chunk_router
|
||||||
from api.apps.mcp_server_app import router as mcp_router
|
from api.apps.mcp_server_app import router as mcp_router
|
||||||
from api.apps.canvas_app import router as canvas_router
|
from api.apps.canvas_app import router as canvas_router
|
||||||
|
from api.apps.tenant_app import router as tenant_router
|
||||||
|
from api.apps.dialog_app import router as dialog_router
|
||||||
|
from api.apps.system_app import router as system_router
|
||||||
|
from api.apps.search_app import router as search_router
|
||||||
|
from api.apps.conversation_app import router as conversation_router
|
||||||
|
from api.apps.file_app import router as file_router
|
||||||
|
|
||||||
app.include_router(user_router, prefix=f"/{API_VERSION}/user", tags=["User"])
|
app.include_router(user_router, prefix=f"/{API_VERSION}/user", tags=["User"])
|
||||||
app.include_router(kb_router, prefix=f"/{API_VERSION}/kb", tags=["KnowledgeBase"])
|
app.include_router(kb_router, prefix=f"/{API_VERSION}/kb", tags=["KnowledgeBase"])
|
||||||
app.include_router(document_router, prefix=f"/{API_VERSION}/document", tags=["Document"])
|
app.include_router(document_router, prefix=f"/{API_VERSION}/document", tags=["Document"])
|
||||||
app.include_router(llm_router, prefix=f"/{API_VERSION}/llm", tags=["LLM"])
|
app.include_router(llm_router, prefix=f"/{API_VERSION}/llm", tags=["LLM"])
|
||||||
app.include_router(chunk_router, prefix=f"/{API_VERSION}/chunk", tags=["Chunk"])
|
app.include_router(chunk_router, prefix=f"/{API_VERSION}/chunk", tags=["Chunk"])
|
||||||
app.include_router(mcp_router, prefix=f"/{API_VERSION}/mcp", tags=["MCP"])
|
app.include_router(mcp_router, prefix=f"/{API_VERSION}/mcp_server", tags=["MCP"])
|
||||||
app.include_router(canvas_router, prefix=f"/{API_VERSION}/canvas", tags=["Canvas"])
|
app.include_router(canvas_router, prefix=f"/{API_VERSION}/canvas", tags=["Canvas"])
|
||||||
|
app.include_router(tenant_router, prefix=f"/{API_VERSION}/tenant", tags=["Tenant"])
|
||||||
|
app.include_router(dialog_router, prefix=f"/{API_VERSION}/dialog", tags=["Dialog"])
|
||||||
|
app.include_router(system_router, prefix=f"/{API_VERSION}/system", tags=["System"])
|
||||||
|
app.include_router(search_router, prefix=f"/{API_VERSION}/search", tags=["Search"])
|
||||||
|
app.include_router(conversation_router, prefix=f"/{API_VERSION}/conversation", tags=["Conversation"])
|
||||||
|
app.include_router(file_router, prefix=f"/{API_VERSION}/file", tags=["File"])
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@@ -17,8 +17,10 @@ import json
|
|||||||
import re
|
import re
|
||||||
import logging
|
import logging
|
||||||
from copy import deepcopy
|
from copy import deepcopy
|
||||||
from flask import Response, request
|
from typing import Optional
|
||||||
from flask_login import current_user, login_required
|
from fastapi import APIRouter, Depends, Query, Header, HTTPException, status
|
||||||
|
from fastapi.responses import StreamingResponse
|
||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.db import LLMType
|
from api.db import LLMType
|
||||||
from api.db.db_models import APIToken
|
from api.db.db_models import APIToken
|
||||||
@@ -28,15 +30,35 @@ from api.db.services.llm_service import LLMBundle
|
|||||||
from api.db.services.search_service import SearchService
|
from api.db.services.search_service import SearchService
|
||||||
from api.db.services.tenant_llm_service import TenantLLMService
|
from api.db.services.tenant_llm_service import TenantLLMService
|
||||||
from api.db.services.user_service import TenantService, UserTenantService
|
from api.db.services.user_service import TenantService, UserTenantService
|
||||||
from api.utils.api_utils import get_data_error_result, get_json_result, server_error_response, validate_request
|
from api.utils.api_utils import get_data_error_result, get_json_result, server_error_response
|
||||||
|
from api.utils import get_uuid
|
||||||
from rag.prompts.template import load_prompt
|
from rag.prompts.template import load_prompt
|
||||||
from rag.prompts.generator import chunks_format
|
from rag.prompts.generator import chunks_format
|
||||||
|
|
||||||
|
from api.apps.models.auth_dependencies import get_current_user
|
||||||
|
from api.apps.models.conversation_models import (
|
||||||
|
SetConversationRequest,
|
||||||
|
DeleteConversationsRequest,
|
||||||
|
CompletionRequest,
|
||||||
|
TTSRequest,
|
||||||
|
DeleteMessageRequest,
|
||||||
|
ThumbupRequest,
|
||||||
|
AskRequest,
|
||||||
|
MindmapRequest,
|
||||||
|
RelatedQuestionsRequest,
|
||||||
|
)
|
||||||
|
|
||||||
@manager.route("/set", methods=["POST"]) # noqa: F821
|
# 创建路由器
|
||||||
@login_required
|
router = APIRouter()
|
||||||
def set_conversation():
|
|
||||||
req = request.json
|
|
||||||
|
@router.post('/set')
|
||||||
|
async def set_conversation(
|
||||||
|
request: SetConversationRequest,
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""设置对话"""
|
||||||
|
req = request.model_dump(exclude_unset=True)
|
||||||
conv_id = req.get("conversation_id")
|
conv_id = req.get("conversation_id")
|
||||||
is_new = req.get("is_new")
|
is_new = req.get("is_new")
|
||||||
name = req.get("name", "New conversation")
|
name = req.get("name", "New conversation")
|
||||||
@@ -45,9 +67,9 @@ def set_conversation():
|
|||||||
if len(name) > 255:
|
if len(name) > 255:
|
||||||
name = name[0:255]
|
name = name[0:255]
|
||||||
|
|
||||||
del req["is_new"]
|
|
||||||
if not is_new:
|
if not is_new:
|
||||||
del req["conversation_id"]
|
if not conv_id:
|
||||||
|
return get_data_error_result(message="conversation_id is required when is_new is False!")
|
||||||
try:
|
try:
|
||||||
if not ConversationService.update_by_id(conv_id, req):
|
if not ConversationService.update_by_id(conv_id, req):
|
||||||
return get_data_error_result(message="Conversation not found!")
|
return get_data_error_result(message="Conversation not found!")
|
||||||
@@ -64,7 +86,7 @@ def set_conversation():
|
|||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="Dialog not found")
|
return get_data_error_result(message="Dialog not found")
|
||||||
conv = {
|
conv = {
|
||||||
"id": conv_id,
|
"id": conv_id or get_uuid(),
|
||||||
"dialog_id": req["dialog_id"],
|
"dialog_id": req["dialog_id"],
|
||||||
"name": name,
|
"name": name,
|
||||||
"message": [{"role": "assistant", "content": dia.prompt_config["prologue"]}],
|
"message": [{"role": "assistant", "content": dia.prompt_config["prologue"]}],
|
||||||
@@ -77,12 +99,14 @@ def set_conversation():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/get", methods=["GET"]) # noqa: F821
|
@router.get('/get')
|
||||||
@login_required
|
async def get(
|
||||||
def get():
|
conversation_id: str = Query(..., description="对话ID"),
|
||||||
conv_id = request.args["conversation_id"]
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取对话"""
|
||||||
try:
|
try:
|
||||||
e, conv = ConversationService.get_by_id(conv_id)
|
e, conv = ConversationService.get_by_id(conversation_id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="Conversation not found!")
|
return get_data_error_result(message="Conversation not found!")
|
||||||
tenants = UserTenantService.query(user_id=current_user.id)
|
tenants = UserTenantService.query(user_id=current_user.id)
|
||||||
@@ -107,15 +131,27 @@ def get():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/getsse/<dialog_id>", methods=["GET"]) # type: ignore # noqa: F821
|
@router.get('/getsse/{dialog_id}')
|
||||||
def getsse(dialog_id):
|
async def getsse(
|
||||||
token = request.headers.get("Authorization").split()
|
dialog_id: str,
|
||||||
if len(token) != 2:
|
authorization: Optional[str] = Header(None, alias="Authorization")
|
||||||
|
):
|
||||||
|
"""通过 SSE 获取对话(使用 API token 认证)"""
|
||||||
|
if not authorization:
|
||||||
|
raise HTTPException(
|
||||||
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
|
detail="Authorization header is required"
|
||||||
|
)
|
||||||
|
|
||||||
|
token_parts = authorization.split()
|
||||||
|
if len(token_parts) != 2:
|
||||||
return get_data_error_result(message='Authorization is not valid!"')
|
return get_data_error_result(message='Authorization is not valid!"')
|
||||||
token = token[1]
|
token = token_parts[1]
|
||||||
|
|
||||||
objs = APIToken.query(beta=token)
|
objs = APIToken.query(beta=token)
|
||||||
if not objs:
|
if not objs:
|
||||||
return get_data_error_result(message='Authentication error: API key is invalid!"')
|
return get_data_error_result(message='Authentication error: API key is invalid!"')
|
||||||
|
|
||||||
try:
|
try:
|
||||||
e, conv = DialogService.get_by_id(dialog_id)
|
e, conv = DialogService.get_by_id(dialog_id)
|
||||||
if not e:
|
if not e:
|
||||||
@@ -128,12 +164,14 @@ def getsse(dialog_id):
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/rm", methods=["POST"]) # noqa: F821
|
@router.post('/rm')
|
||||||
@login_required
|
async def rm(
|
||||||
def rm():
|
request: DeleteConversationsRequest,
|
||||||
conv_ids = request.json["conversation_ids"]
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""删除对话"""
|
||||||
try:
|
try:
|
||||||
for cid in conv_ids:
|
for cid in request.conversation_ids:
|
||||||
exist, conv = ConversationService.get_by_id(cid)
|
exist, conv = ConversationService.get_by_id(cid)
|
||||||
if not exist:
|
if not exist:
|
||||||
return get_data_error_result(message="Conversation not found!")
|
return get_data_error_result(message="Conversation not found!")
|
||||||
@@ -149,10 +187,12 @@ def rm():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/list", methods=["GET"]) # noqa: F821
|
@router.get('/list')
|
||||||
@login_required
|
async def list_conversation(
|
||||||
def list_conversation():
|
dialog_id: str = Query(..., description="对话ID"),
|
||||||
dialog_id = request.args["dialog_id"]
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""列出对话"""
|
||||||
try:
|
try:
|
||||||
if not DialogService.query(tenant_id=current_user.id, id=dialog_id):
|
if not DialogService.query(tenant_id=current_user.id, id=dialog_id):
|
||||||
return get_json_result(data=False, message="Only owner of dialog authorized for this operation.", code=settings.RetCode.OPERATING_ERROR)
|
return get_json_result(data=False, message="Only owner of dialog authorized for this operation.", code=settings.RetCode.OPERATING_ERROR)
|
||||||
@@ -164,11 +204,13 @@ def list_conversation():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/completion", methods=["POST"]) # noqa: F821
|
@router.post('/completion')
|
||||||
@login_required
|
async def completion(
|
||||||
@validate_request("conversation_id", "messages")
|
request: CompletionRequest,
|
||||||
def completion():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
|
"""完成请求(聊天完成)"""
|
||||||
|
req = request.model_dump(exclude_unset=True)
|
||||||
msg = []
|
msg = []
|
||||||
for m in req["messages"]:
|
for m in req["messages"]:
|
||||||
if m["role"] == "system":
|
if m["role"] == "system":
|
||||||
@@ -176,6 +218,10 @@ def completion():
|
|||||||
if m["role"] == "assistant" and not msg:
|
if m["role"] == "assistant" and not msg:
|
||||||
continue
|
continue
|
||||||
msg.append(m)
|
msg.append(m)
|
||||||
|
|
||||||
|
if not msg:
|
||||||
|
return get_data_error_result(message="No valid messages found!")
|
||||||
|
|
||||||
message_id = msg[-1].get("id")
|
message_id = msg[-1].get("id")
|
||||||
chat_model_id = req.get("llm_id", "")
|
chat_model_id = req.get("llm_id", "")
|
||||||
req.pop("llm_id", None)
|
req.pop("llm_id", None)
|
||||||
@@ -217,6 +263,7 @@ def completion():
|
|||||||
dia.llm_setting = chat_model_config
|
dia.llm_setting = chat_model_config
|
||||||
|
|
||||||
is_embedded = bool(chat_model_id)
|
is_embedded = bool(chat_model_id)
|
||||||
|
|
||||||
def stream():
|
def stream():
|
||||||
nonlocal dia, msg, req, conv
|
nonlocal dia, msg, req, conv
|
||||||
try:
|
try:
|
||||||
@@ -230,14 +277,18 @@ def completion():
|
|||||||
yield "data:" + json.dumps({"code": 500, "message": str(e), "data": {"answer": "**ERROR**: " + str(e), "reference": []}}, ensure_ascii=False) + "\n\n"
|
yield "data:" + json.dumps({"code": 500, "message": str(e), "data": {"answer": "**ERROR**: " + str(e), "reference": []}}, ensure_ascii=False) + "\n\n"
|
||||||
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
||||||
|
|
||||||
if req.get("stream", True):
|
stream_enabled = request.stream if request.stream is not None else True
|
||||||
resp = Response(stream(), mimetype="text/event-stream")
|
if stream_enabled:
|
||||||
resp.headers.add_header("Cache-control", "no-cache")
|
return StreamingResponse(
|
||||||
resp.headers.add_header("Connection", "keep-alive")
|
stream(),
|
||||||
resp.headers.add_header("X-Accel-Buffering", "no")
|
media_type="text/event-stream",
|
||||||
resp.headers.add_header("Content-Type", "text/event-stream; charset=utf-8")
|
headers={
|
||||||
return resp
|
"Cache-control": "no-cache",
|
||||||
|
"Connection": "keep-alive",
|
||||||
|
"X-Accel-Buffering": "no",
|
||||||
|
"Content-Type": "text/event-stream; charset=utf-8"
|
||||||
|
}
|
||||||
|
)
|
||||||
else:
|
else:
|
||||||
answer = None
|
answer = None
|
||||||
for ans in chat(dia, msg, **req):
|
for ans in chat(dia, msg, **req):
|
||||||
@@ -250,11 +301,13 @@ def completion():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/tts", methods=["POST"]) # noqa: F821
|
@router.post('/tts')
|
||||||
@login_required
|
async def tts(
|
||||||
def tts():
|
request: TTSRequest,
|
||||||
req = request.json
|
current_user = Depends(get_current_user)
|
||||||
text = req["text"]
|
):
|
||||||
|
"""文本转语音"""
|
||||||
|
text = request.text
|
||||||
|
|
||||||
tenants = TenantService.get_info_by(current_user.id)
|
tenants = TenantService.get_info_by(current_user.id)
|
||||||
if not tenants:
|
if not tenants:
|
||||||
@@ -274,28 +327,32 @@ def tts():
|
|||||||
except Exception as e:
|
except Exception as e:
|
||||||
yield ("data:" + json.dumps({"code": 500, "message": str(e), "data": {"answer": "**ERROR**: " + str(e)}}, ensure_ascii=False)).encode("utf-8")
|
yield ("data:" + json.dumps({"code": 500, "message": str(e), "data": {"answer": "**ERROR**: " + str(e)}}, ensure_ascii=False)).encode("utf-8")
|
||||||
|
|
||||||
resp = Response(stream_audio(), mimetype="audio/mpeg")
|
return StreamingResponse(
|
||||||
resp.headers.add_header("Cache-Control", "no-cache")
|
stream_audio(),
|
||||||
resp.headers.add_header("Connection", "keep-alive")
|
media_type="audio/mpeg",
|
||||||
resp.headers.add_header("X-Accel-Buffering", "no")
|
headers={
|
||||||
|
"Cache-Control": "no-cache",
|
||||||
return resp
|
"Connection": "keep-alive",
|
||||||
|
"X-Accel-Buffering": "no"
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/delete_msg", methods=["POST"]) # noqa: F821
|
@router.post('/delete_msg')
|
||||||
@login_required
|
async def delete_msg(
|
||||||
@validate_request("conversation_id", "message_id")
|
request: DeleteMessageRequest,
|
||||||
def delete_msg():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
e, conv = ConversationService.get_by_id(req["conversation_id"])
|
"""删除消息"""
|
||||||
|
e, conv = ConversationService.get_by_id(request.conversation_id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="Conversation not found!")
|
return get_data_error_result(message="Conversation not found!")
|
||||||
|
|
||||||
conv = conv.to_dict()
|
conv = conv.to_dict()
|
||||||
for i, msg in enumerate(conv["message"]):
|
for i, msg in enumerate(conv["message"]):
|
||||||
if req["message_id"] != msg.get("id", ""):
|
if request.message_id != msg.get("id", ""):
|
||||||
continue
|
continue
|
||||||
assert conv["message"][i + 1]["id"] == req["message_id"]
|
assert conv["message"][i + 1]["id"] == request.message_id
|
||||||
conv["message"].pop(i)
|
conv["message"].pop(i)
|
||||||
conv["message"].pop(i)
|
conv["message"].pop(i)
|
||||||
conv["reference"].pop(max(0, i // 2 - 1))
|
conv["reference"].pop(max(0, i // 2 - 1))
|
||||||
@@ -305,19 +362,21 @@ def delete_msg():
|
|||||||
return get_json_result(data=conv)
|
return get_json_result(data=conv)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/thumbup", methods=["POST"]) # noqa: F821
|
@router.post('/thumbup')
|
||||||
@login_required
|
async def thumbup(
|
||||||
@validate_request("conversation_id", "message_id")
|
request: ThumbupRequest,
|
||||||
def thumbup():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
e, conv = ConversationService.get_by_id(req["conversation_id"])
|
"""点赞/点踩"""
|
||||||
|
e, conv = ConversationService.get_by_id(request.conversation_id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result(message="Conversation not found!")
|
return get_data_error_result(message="Conversation not found!")
|
||||||
up_down = req.get("thumbup")
|
|
||||||
feedback = req.get("feedback", "")
|
up_down = request.thumbup
|
||||||
|
feedback = request.feedback or ""
|
||||||
conv = conv.to_dict()
|
conv = conv.to_dict()
|
||||||
for i, msg in enumerate(conv["message"]):
|
for i, msg in enumerate(conv["message"]):
|
||||||
if req["message_id"] == msg.get("id", "") and msg.get("role", "") == "assistant":
|
if request.message_id == msg.get("id", "") and msg.get("role", "") == "assistant":
|
||||||
if up_down:
|
if up_down:
|
||||||
msg["thumbup"] = True
|
msg["thumbup"] = True
|
||||||
if "feedback" in msg:
|
if "feedback" in msg:
|
||||||
@@ -332,14 +391,15 @@ def thumbup():
|
|||||||
return get_json_result(data=conv)
|
return get_json_result(data=conv)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/ask", methods=["POST"]) # noqa: F821
|
@router.post('/ask')
|
||||||
@login_required
|
async def ask_about(
|
||||||
@validate_request("question", "kb_ids")
|
request: AskRequest,
|
||||||
def ask_about():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
|
"""提问"""
|
||||||
uid = current_user.id
|
uid = current_user.id
|
||||||
|
|
||||||
search_id = req.get("search_id", "")
|
search_id = request.search_id or ""
|
||||||
search_app = None
|
search_app = None
|
||||||
search_config = {}
|
search_config = {}
|
||||||
if search_id:
|
if search_id:
|
||||||
@@ -348,53 +408,58 @@ def ask_about():
|
|||||||
search_config = search_app.get("search_config", {})
|
search_config = search_app.get("search_config", {})
|
||||||
|
|
||||||
def stream():
|
def stream():
|
||||||
nonlocal req, uid
|
nonlocal request, uid
|
||||||
try:
|
try:
|
||||||
for ans in ask(req["question"], req["kb_ids"], uid, search_config=search_config):
|
for ans in ask(request.question, request.kb_ids, uid, search_config=search_config):
|
||||||
yield "data:" + json.dumps({"code": 0, "message": "", "data": ans}, ensure_ascii=False) + "\n\n"
|
yield "data:" + json.dumps({"code": 0, "message": "", "data": ans}, ensure_ascii=False) + "\n\n"
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
yield "data:" + json.dumps({"code": 500, "message": str(e), "data": {"answer": "**ERROR**: " + str(e), "reference": []}}, ensure_ascii=False) + "\n\n"
|
yield "data:" + json.dumps({"code": 500, "message": str(e), "data": {"answer": "**ERROR**: " + str(e), "reference": []}}, ensure_ascii=False) + "\n\n"
|
||||||
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
yield "data:" + json.dumps({"code": 0, "message": "", "data": True}, ensure_ascii=False) + "\n\n"
|
||||||
|
|
||||||
resp = Response(stream(), mimetype="text/event-stream")
|
return StreamingResponse(
|
||||||
resp.headers.add_header("Cache-control", "no-cache")
|
stream(),
|
||||||
resp.headers.add_header("Connection", "keep-alive")
|
media_type="text/event-stream",
|
||||||
resp.headers.add_header("X-Accel-Buffering", "no")
|
headers={
|
||||||
resp.headers.add_header("Content-Type", "text/event-stream; charset=utf-8")
|
"Cache-control": "no-cache",
|
||||||
return resp
|
"Connection": "keep-alive",
|
||||||
|
"X-Accel-Buffering": "no",
|
||||||
|
"Content-Type": "text/event-stream; charset=utf-8"
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/mindmap", methods=["POST"]) # noqa: F821
|
@router.post('/mindmap')
|
||||||
@login_required
|
async def mindmap(
|
||||||
@validate_request("question", "kb_ids")
|
request: MindmapRequest,
|
||||||
def mindmap():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
search_id = req.get("search_id", "")
|
"""思维导图"""
|
||||||
|
search_id = request.search_id or ""
|
||||||
search_app = SearchService.get_detail(search_id) if search_id else {}
|
search_app = SearchService.get_detail(search_id) if search_id else {}
|
||||||
search_config = search_app.get("search_config", {}) if search_app else {}
|
search_config = search_app.get("search_config", {}) if search_app else {}
|
||||||
kb_ids = search_config.get("kb_ids", [])
|
kb_ids = search_config.get("kb_ids", [])
|
||||||
kb_ids.extend(req["kb_ids"])
|
kb_ids.extend(request.kb_ids)
|
||||||
kb_ids = list(set(kb_ids))
|
kb_ids = list(set(kb_ids))
|
||||||
|
|
||||||
mind_map = gen_mindmap(req["question"], kb_ids, search_app.get("tenant_id", current_user.id), search_config)
|
mind_map = gen_mindmap(request.question, kb_ids, search_app.get("tenant_id", current_user.id), search_config)
|
||||||
if "error" in mind_map:
|
if "error" in mind_map:
|
||||||
return server_error_response(Exception(mind_map["error"]))
|
return server_error_response(Exception(mind_map["error"]))
|
||||||
return get_json_result(data=mind_map)
|
return get_json_result(data=mind_map)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/related_questions", methods=["POST"]) # noqa: F821
|
@router.post('/related_questions')
|
||||||
@login_required
|
async def related_questions(
|
||||||
@validate_request("question")
|
request: RelatedQuestionsRequest,
|
||||||
def related_questions():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
|
"""相关问题"""
|
||||||
search_id = req.get("search_id", "")
|
search_id = request.search_id or ""
|
||||||
search_config = {}
|
search_config = {}
|
||||||
if search_id:
|
if search_id:
|
||||||
if search_app := SearchService.get_detail(search_id):
|
if search_app := SearchService.get_detail(search_id):
|
||||||
search_config = search_app.get("search_config", {})
|
search_config = search_app.get("search_config", {})
|
||||||
|
|
||||||
question = req["question"]
|
question = request.question
|
||||||
|
|
||||||
chat_id = search_config.get("chat_id", "")
|
chat_id = search_config.get("chat_id", "")
|
||||||
chat_mdl = LLMBundle(current_user.id, LLMType.CHAT, chat_id)
|
chat_mdl = LLMBundle(current_user.id, LLMType.CHAT, chat_id)
|
||||||
|
|||||||
@@ -14,8 +14,17 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
|
||||||
from flask import request
|
from typing import Optional
|
||||||
from flask_login import login_required, current_user
|
|
||||||
|
from fastapi import APIRouter, Depends, Query
|
||||||
|
|
||||||
|
from api.apps.models.auth_dependencies import get_current_user
|
||||||
|
from api.apps.models.dialog_models import (
|
||||||
|
SetDialogRequest,
|
||||||
|
ListDialogsNextQuery,
|
||||||
|
ListDialogsNextBody,
|
||||||
|
DeleteDialogRequest,
|
||||||
|
)
|
||||||
from api.db.services import duplicate_name
|
from api.db.services import duplicate_name
|
||||||
from api.db.services.dialog_service import DialogService
|
from api.db.services.dialog_service import DialogService
|
||||||
from api.db import StatusEnum
|
from api.db import StatusEnum
|
||||||
@@ -23,16 +32,21 @@ from api.db.services.tenant_llm_service import TenantLLMService
|
|||||||
from api.db.services.knowledgebase_service import KnowledgebaseService
|
from api.db.services.knowledgebase_service import KnowledgebaseService
|
||||||
from api.db.services.user_service import TenantService, UserTenantService
|
from api.db.services.user_service import TenantService, UserTenantService
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.utils.api_utils import server_error_response, get_data_error_result, validate_request
|
from api.utils.api_utils import server_error_response, get_data_error_result
|
||||||
from api.utils import get_uuid
|
from api.utils import get_uuid
|
||||||
from api.utils.api_utils import get_json_result
|
from api.utils.api_utils import get_json_result
|
||||||
|
|
||||||
|
# 创建路由器
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
@manager.route('/set', methods=['POST']) # noqa: F821
|
|
||||||
@validate_request("prompt_config")
|
@router.post('/set')
|
||||||
@login_required
|
async def set_dialog(
|
||||||
def set_dialog():
|
request: SetDialogRequest,
|
||||||
req = request.json
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""设置/创建对话框"""
|
||||||
|
req = request.model_dump(exclude_unset=True)
|
||||||
dialog_id = req.get("dialog_id", "")
|
dialog_id = req.get("dialog_id", "")
|
||||||
is_create = not dialog_id
|
is_create = not dialog_id
|
||||||
name = req.get("name", "New Dialog")
|
name = req.get("name", "New Dialog")
|
||||||
@@ -124,10 +138,12 @@ def set_dialog():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/get', methods=['GET']) # noqa: F821
|
@router.get('/get')
|
||||||
@login_required
|
async def get(
|
||||||
def get():
|
dialog_id: str = Query(..., description="对话框ID"),
|
||||||
dialog_id = request.args["dialog_id"]
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取对话框详情"""
|
||||||
try:
|
try:
|
||||||
e, dia = DialogService.get_by_id(dialog_id)
|
e, dia = DialogService.get_by_id(dialog_id)
|
||||||
if not e:
|
if not e:
|
||||||
@@ -150,9 +166,11 @@ def get_kb_names(kb_ids):
|
|||||||
return ids, nms
|
return ids, nms
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/list', methods=['GET']) # noqa: F821
|
@router.get('/list')
|
||||||
@login_required
|
async def list_dialogs(
|
||||||
def list_dialogs():
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""列出对话框"""
|
||||||
try:
|
try:
|
||||||
diags = DialogService.query(
|
diags = DialogService.query(
|
||||||
tenant_id=current_user.id,
|
tenant_id=current_user.id,
|
||||||
@@ -167,21 +185,24 @@ def list_dialogs():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/next', methods=['POST']) # noqa: F821
|
@router.post('/next')
|
||||||
@login_required
|
async def list_dialogs_next(
|
||||||
def list_dialogs_next():
|
query: ListDialogsNextQuery = Depends(),
|
||||||
keywords = request.args.get("keywords", "")
|
body: Optional[ListDialogsNextBody] = None,
|
||||||
page_number = int(request.args.get("page", 0))
|
current_user = Depends(get_current_user)
|
||||||
items_per_page = int(request.args.get("page_size", 0))
|
):
|
||||||
parser_id = request.args.get("parser_id")
|
"""列出对话框(分页)"""
|
||||||
orderby = request.args.get("orderby", "create_time")
|
if body is None:
|
||||||
if request.args.get("desc", "true").lower() == "false":
|
body = ListDialogsNextBody()
|
||||||
desc = False
|
|
||||||
else:
|
|
||||||
desc = True
|
|
||||||
|
|
||||||
req = request.get_json()
|
keywords = query.keywords or ""
|
||||||
owner_ids = req.get("owner_ids", [])
|
page_number = int(query.page or 0)
|
||||||
|
items_per_page = int(query.page_size or 0)
|
||||||
|
parser_id = query.parser_id
|
||||||
|
orderby = query.orderby or "create_time"
|
||||||
|
desc = query.desc.lower() == "true" if query.desc else True
|
||||||
|
|
||||||
|
owner_ids = body.owner_ids or []
|
||||||
try:
|
try:
|
||||||
if not owner_ids:
|
if not owner_ids:
|
||||||
# tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
# tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
||||||
@@ -204,15 +225,16 @@ def list_dialogs_next():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/rm', methods=['POST']) # noqa: F821
|
@router.post('/rm')
|
||||||
@login_required
|
async def rm(
|
||||||
@validate_request("dialog_ids")
|
request: DeleteDialogRequest,
|
||||||
def rm():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
dialog_list=[]
|
"""删除对话框"""
|
||||||
|
dialog_list = []
|
||||||
tenants = UserTenantService.query(user_id=current_user.id)
|
tenants = UserTenantService.query(user_id=current_user.id)
|
||||||
try:
|
try:
|
||||||
for id in req["dialog_ids"]:
|
for id in request.dialog_ids:
|
||||||
for tenant in tenants:
|
for tenant in tenants:
|
||||||
if DialogService.query(tenant_id=tenant.tenant_id, id=id):
|
if DialogService.query(tenant_id=tenant.tenant_id, id=id):
|
||||||
break
|
break
|
||||||
@@ -220,7 +242,7 @@ def rm():
|
|||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False, message='Only owner of dialog authorized for this operation.',
|
data=False, message='Only owner of dialog authorized for this operation.',
|
||||||
code=settings.RetCode.OPERATING_ERROR)
|
code=settings.RetCode.OPERATING_ERROR)
|
||||||
dialog_list.append({"id": id,"status":StatusEnum.INVALID.value})
|
dialog_list.append({"id": id, "status": StatusEnum.INVALID.value})
|
||||||
DialogService.update_many_by_id(dialog_list)
|
DialogService.update_many_by_id(dialog_list)
|
||||||
return get_json_result(data=True)
|
return get_json_result(data=True)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
|
|||||||
@@ -72,18 +72,24 @@ router = APIRouter()
|
|||||||
@router.post("/upload")
|
@router.post("/upload")
|
||||||
async def upload(
|
async def upload(
|
||||||
kb_id: str = Form(...),
|
kb_id: str = Form(...),
|
||||||
files: List[UploadFile] = File(...),
|
file: List[UploadFile] = File(...),
|
||||||
current_user = Depends(get_current_user)
|
current_user = Depends(get_current_user)
|
||||||
):
|
):
|
||||||
"""上传文档"""
|
"""上传文档"""
|
||||||
if not files:
|
if not file:
|
||||||
return get_json_result(data=False, message="No file part!", code=settings.RetCode.ARGUMENT_ERROR)
|
return get_json_result(data=False, message="No file part!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
|
||||||
for file_obj in files:
|
valid_files: List[UploadFile] = []
|
||||||
if not file_obj.filename or file_obj.filename == "":
|
for upload_file in file:
|
||||||
|
if not upload_file or not upload_file.filename:
|
||||||
return get_json_result(data=False, message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR)
|
return get_json_result(data=False, message="No file selected!", code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
if len(file_obj.filename.encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
if len(upload_file.filename.encode("utf-8")) > FILE_NAME_LEN_LIMIT:
|
||||||
return get_json_result(data=False, message=f"File name must be {FILE_NAME_LEN_LIMIT} bytes or less.", code=settings.RetCode.ARGUMENT_ERROR)
|
return get_json_result(
|
||||||
|
data=False,
|
||||||
|
message=f"File '{upload_file.filename}' name must be {FILE_NAME_LEN_LIMIT} bytes or less.",
|
||||||
|
code=settings.RetCode.ARGUMENT_ERROR
|
||||||
|
)
|
||||||
|
valid_files.append(upload_file)
|
||||||
|
|
||||||
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
e, kb = KnowledgebaseService.get_by_id(kb_id)
|
||||||
if not e:
|
if not e:
|
||||||
@@ -91,7 +97,7 @@ async def upload(
|
|||||||
if not check_kb_team_permission(kb, current_user.id):
|
if not check_kb_team_permission(kb, current_user.id):
|
||||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
|
|
||||||
err, uploaded_files = FileService.upload_document(kb, files, current_user.id)
|
err, uploaded_files = FileService.upload_document(kb, valid_files, current_user.id)
|
||||||
if err:
|
if err:
|
||||||
return get_json_result(data=uploaded_files, message="\n".join(err), code=settings.RetCode.SERVER_ERROR)
|
return get_json_result(data=uploaded_files, message="\n".join(err), code=settings.RetCode.SERVER_ERROR)
|
||||||
|
|
||||||
|
|||||||
@@ -17,15 +17,23 @@ import logging
|
|||||||
import os
|
import os
|
||||||
import pathlib
|
import pathlib
|
||||||
import re
|
import re
|
||||||
|
from typing import Optional, List
|
||||||
|
|
||||||
import flask
|
from fastapi import APIRouter, Depends, Query, UploadFile, File, Form
|
||||||
from flask import request
|
from fastapi.responses import Response
|
||||||
from flask_login import login_required, current_user
|
|
||||||
|
from api.apps.models.auth_dependencies import get_current_user
|
||||||
|
from api.apps.models.file_models import (
|
||||||
|
CreateFileRequest,
|
||||||
|
DeleteFilesRequest,
|
||||||
|
RenameFileRequest,
|
||||||
|
MoveFilesRequest,
|
||||||
|
)
|
||||||
|
|
||||||
from api.common.check_team_permission import check_file_team_permission
|
from api.common.check_team_permission import check_file_team_permission
|
||||||
from api.db.services.document_service import DocumentService
|
from api.db.services.document_service import DocumentService
|
||||||
from api.db.services.file2document_service import File2DocumentService
|
from api.db.services.file2document_service import File2DocumentService
|
||||||
from api.utils.api_utils import server_error_response, get_data_error_result, validate_request
|
from api.utils.api_utils import server_error_response, get_data_error_result
|
||||||
from api.utils import get_uuid
|
from api.utils import get_uuid
|
||||||
from api.db import FileType, FileSource
|
from api.db import FileType, FileSource
|
||||||
from api.db.services import duplicate_name
|
from api.db.services import duplicate_name
|
||||||
@@ -36,35 +44,41 @@ from api.utils.file_utils import filename_type
|
|||||||
from api.utils.web_utils import CONTENT_TYPE_MAP
|
from api.utils.web_utils import CONTENT_TYPE_MAP
|
||||||
from rag.utils.storage_factory import STORAGE_IMPL
|
from rag.utils.storage_factory import STORAGE_IMPL
|
||||||
|
|
||||||
|
# 创建路由器
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
@manager.route('/upload', methods=['POST']) # noqa: F821
|
|
||||||
@login_required
|
@router.post('/upload')
|
||||||
# @validate_request("parent_id")
|
async def upload(
|
||||||
def upload():
|
files: List[UploadFile] = File(...),
|
||||||
pf_id = request.form.get("parent_id")
|
parent_id: Optional[str] = Form(None),
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""上传文件"""
|
||||||
|
pf_id = parent_id
|
||||||
|
|
||||||
if not pf_id:
|
if not pf_id:
|
||||||
root_folder = FileService.get_root_folder(current_user.id)
|
root_folder = FileService.get_root_folder(current_user.id)
|
||||||
pf_id = root_folder["id"]
|
pf_id = root_folder["id"]
|
||||||
|
|
||||||
if 'file' not in request.files:
|
if not files:
|
||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False, message='No file part!', code=settings.RetCode.ARGUMENT_ERROR)
|
data=False, message='No file part!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
file_objs = request.files.getlist('file')
|
|
||||||
|
|
||||||
for file_obj in file_objs:
|
for file_obj in files:
|
||||||
if file_obj.filename == '':
|
if not file_obj.filename or file_obj.filename == '':
|
||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False, message='No file selected!', code=settings.RetCode.ARGUMENT_ERROR)
|
data=False, message='No file selected!', code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
|
|
||||||
file_res = []
|
file_res = []
|
||||||
try:
|
try:
|
||||||
e, pf_folder = FileService.get_by_id(pf_id)
|
e, pf_folder = FileService.get_by_id(pf_id)
|
||||||
if not e:
|
if not e:
|
||||||
return get_data_error_result( message="Can't find this folder!")
|
return get_data_error_result(message="Can't find this folder!")
|
||||||
for file_obj in file_objs:
|
for file_obj in files:
|
||||||
MAX_FILE_NUM_PER_USER = int(os.environ.get('MAX_FILE_NUM_PER_USER', 0))
|
MAX_FILE_NUM_PER_USER = int(os.environ.get('MAX_FILE_NUM_PER_USER', 0))
|
||||||
if MAX_FILE_NUM_PER_USER > 0 and DocumentService.get_doc_count(current_user.id) >= MAX_FILE_NUM_PER_USER:
|
if MAX_FILE_NUM_PER_USER > 0 and DocumentService.get_doc_count(current_user.id) >= MAX_FILE_NUM_PER_USER:
|
||||||
return get_data_error_result( message="Exceed the maximum file number of a free user!")
|
return get_data_error_result(message="Exceed the maximum file number of a free user!")
|
||||||
|
|
||||||
# split file name path
|
# split file name path
|
||||||
if not file_obj.filename:
|
if not file_obj.filename:
|
||||||
@@ -97,7 +111,7 @@ def upload():
|
|||||||
location = file_obj_names[file_len - 1]
|
location = file_obj_names[file_len - 1]
|
||||||
while STORAGE_IMPL.obj_exist(last_folder.id, location):
|
while STORAGE_IMPL.obj_exist(last_folder.id, location):
|
||||||
location += "_"
|
location += "_"
|
||||||
blob = file_obj.read()
|
blob = await file_obj.read()
|
||||||
filename = duplicate_name(
|
filename = duplicate_name(
|
||||||
FileService.query,
|
FileService.query,
|
||||||
name=file_obj_names[file_len - 1],
|
name=file_obj_names[file_len - 1],
|
||||||
@@ -120,13 +134,16 @@ def upload():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/create', methods=['POST']) # noqa: F821
|
@router.post('/create')
|
||||||
@login_required
|
async def create(
|
||||||
@validate_request("name")
|
request: CreateFileRequest,
|
||||||
def create():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
pf_id = request.json.get("parent_id")
|
"""创建文件/文件夹"""
|
||||||
input_file_type = request.json.get("type")
|
req = request.model_dump(exclude_unset=True)
|
||||||
|
pf_id = req.get("parent_id")
|
||||||
|
input_file_type = req.get("type")
|
||||||
|
|
||||||
if not pf_id:
|
if not pf_id:
|
||||||
root_folder = FileService.get_root_folder(current_user.id)
|
root_folder = FileService.get_root_folder(current_user.id)
|
||||||
pf_id = root_folder["id"]
|
pf_id = root_folder["id"]
|
||||||
@@ -160,17 +177,22 @@ def create():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/list', methods=['GET']) # noqa: F821
|
@router.get('/list')
|
||||||
@login_required
|
async def list_files(
|
||||||
def list_files():
|
parent_id: Optional[str] = Query(None, description="父文件夹ID"),
|
||||||
pf_id = request.args.get("parent_id")
|
keywords: Optional[str] = Query("", description="搜索关键词"),
|
||||||
|
page: Optional[int] = Query(1, description="页码"),
|
||||||
|
page_size: Optional[int] = Query(15, description="每页数量"),
|
||||||
|
orderby: Optional[str] = Query("create_time", description="排序字段"),
|
||||||
|
desc: Optional[bool] = Query(True, description="是否降序"),
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""列出文件"""
|
||||||
|
pf_id = parent_id
|
||||||
|
|
||||||
keywords = request.args.get("keywords", "")
|
page_number = int(page) if page else 1
|
||||||
|
items_per_page = int(page_size) if page_size else 15
|
||||||
|
|
||||||
page_number = int(request.args.get("page", 1))
|
|
||||||
items_per_page = int(request.args.get("page_size", 15))
|
|
||||||
orderby = request.args.get("orderby", "create_time")
|
|
||||||
desc = request.args.get("desc", True)
|
|
||||||
if not pf_id:
|
if not pf_id:
|
||||||
root_folder = FileService.get_root_folder(current_user.id)
|
root_folder = FileService.get_root_folder(current_user.id)
|
||||||
pf_id = root_folder["id"]
|
pf_id = root_folder["id"]
|
||||||
@@ -192,9 +214,11 @@ def list_files():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/root_folder', methods=['GET']) # noqa: F821
|
@router.get('/root_folder')
|
||||||
@login_required
|
async def get_root_folder(
|
||||||
def get_root_folder():
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取根文件夹"""
|
||||||
try:
|
try:
|
||||||
root_folder = FileService.get_root_folder(current_user.id)
|
root_folder = FileService.get_root_folder(current_user.id)
|
||||||
return get_json_result(data={"root_folder": root_folder})
|
return get_json_result(data={"root_folder": root_folder})
|
||||||
@@ -202,10 +226,12 @@ def get_root_folder():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/parent_folder', methods=['GET']) # noqa: F821
|
@router.get('/parent_folder')
|
||||||
@login_required
|
async def get_parent_folder(
|
||||||
def get_parent_folder():
|
file_id: str = Query(..., description="文件ID"),
|
||||||
file_id = request.args.get("file_id")
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取父文件夹"""
|
||||||
try:
|
try:
|
||||||
e, file = FileService.get_by_id(file_id)
|
e, file = FileService.get_by_id(file_id)
|
||||||
if not e:
|
if not e:
|
||||||
@@ -217,10 +243,12 @@ def get_parent_folder():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/all_parent_folder', methods=['GET']) # noqa: F821
|
@router.get('/all_parent_folder')
|
||||||
@login_required
|
async def get_all_parent_folders(
|
||||||
def get_all_parent_folders():
|
file_id: str = Query(..., description="文件ID"),
|
||||||
file_id = request.args.get("file_id")
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取所有父文件夹"""
|
||||||
try:
|
try:
|
||||||
e, file = FileService.get_by_id(file_id)
|
e, file = FileService.get_by_id(file_id)
|
||||||
if not e:
|
if not e:
|
||||||
@@ -235,12 +263,13 @@ def get_all_parent_folders():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/rm", methods=["POST"]) # noqa: F821
|
@router.post("/rm")
|
||||||
@login_required
|
async def rm(
|
||||||
@validate_request("file_ids")
|
request: DeleteFilesRequest,
|
||||||
def rm():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
file_ids = req["file_ids"]
|
"""删除文件"""
|
||||||
|
file_ids = request.file_ids
|
||||||
|
|
||||||
def _delete_single_file(file):
|
def _delete_single_file(file):
|
||||||
try:
|
try:
|
||||||
@@ -296,11 +325,13 @@ def rm():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/rename', methods=['POST']) # noqa: F821
|
@router.post('/rename')
|
||||||
@login_required
|
async def rename(
|
||||||
@validate_request("file_id", "name")
|
request: RenameFileRequest,
|
||||||
def rename():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
|
"""重命名文件"""
|
||||||
|
req = request.model_dump()
|
||||||
try:
|
try:
|
||||||
e, file = FileService.get_by_id(req["file_id"])
|
e, file = FileService.get_by_id(req["file_id"])
|
||||||
if not e:
|
if not e:
|
||||||
@@ -314,8 +345,8 @@ def rename():
|
|||||||
data=False,
|
data=False,
|
||||||
message="The extension of file can't be changed",
|
message="The extension of file can't be changed",
|
||||||
code=settings.RetCode.ARGUMENT_ERROR)
|
code=settings.RetCode.ARGUMENT_ERROR)
|
||||||
for file in FileService.query(name=req["name"], pf_id=file.parent_id):
|
for existing_file in FileService.query(name=req["name"], pf_id=file.parent_id):
|
||||||
if file.name == req["name"]:
|
if existing_file.name == req["name"]:
|
||||||
return get_data_error_result(
|
return get_data_error_result(
|
||||||
message="Duplicated file name in the same folder.")
|
message="Duplicated file name in the same folder.")
|
||||||
|
|
||||||
@@ -336,9 +367,12 @@ def rename():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/get/<file_id>', methods=['GET']) # noqa: F821
|
@router.get('/get/{file_id}')
|
||||||
@login_required
|
async def get(
|
||||||
def get(file_id):
|
file_id: str,
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取文件内容"""
|
||||||
try:
|
try:
|
||||||
e, file = FileService.get_by_id(file_id)
|
e, file = FileService.get_by_id(file_id)
|
||||||
if not e:
|
if not e:
|
||||||
@@ -351,25 +385,28 @@ def get(file_id):
|
|||||||
b, n = File2DocumentService.get_storage_address(file_id=file_id)
|
b, n = File2DocumentService.get_storage_address(file_id=file_id)
|
||||||
blob = STORAGE_IMPL.get(b, n)
|
blob = STORAGE_IMPL.get(b, n)
|
||||||
|
|
||||||
response = flask.make_response(blob)
|
|
||||||
ext = re.search(r"\.([^.]+)$", file.name.lower())
|
ext = re.search(r"\.([^.]+)$", file.name.lower())
|
||||||
ext = ext.group(1) if ext else None
|
ext = ext.group(1) if ext else None
|
||||||
|
|
||||||
|
content_type = "application/octet-stream"
|
||||||
if ext:
|
if ext:
|
||||||
if file.type == FileType.VISUAL.value:
|
if file.type == FileType.VISUAL.value:
|
||||||
content_type = CONTENT_TYPE_MAP.get(ext, f"image/{ext}")
|
content_type = CONTENT_TYPE_MAP.get(ext, f"image/{ext}")
|
||||||
else:
|
else:
|
||||||
content_type = CONTENT_TYPE_MAP.get(ext, f"application/{ext}")
|
content_type = CONTENT_TYPE_MAP.get(ext, f"application/{ext}")
|
||||||
response.headers.set("Content-Type", content_type)
|
|
||||||
return response
|
return Response(content=blob, media_type=content_type)
|
||||||
except Exception as e:
|
except Exception as e:
|
||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/mv", methods=["POST"]) # noqa: F821
|
@router.post("/mv")
|
||||||
@login_required
|
async def move(
|
||||||
@validate_request("src_file_ids", "dest_file_id")
|
request: MoveFilesRequest,
|
||||||
def move():
|
current_user = Depends(get_current_user)
|
||||||
req = request.json
|
):
|
||||||
|
"""移动文件"""
|
||||||
|
req = request.model_dump()
|
||||||
try:
|
try:
|
||||||
file_ids = req["src_file_ids"]
|
file_ids = req["src_file_ids"]
|
||||||
dest_parent_id = req["dest_file_id"]
|
dest_parent_id = req["dest_file_id"]
|
||||||
|
|||||||
@@ -169,6 +169,9 @@ async def update(
|
|||||||
):
|
):
|
||||||
"""更新知识库"""
|
"""更新知识库"""
|
||||||
req = request.model_dump(exclude_unset=True)
|
req = request.model_dump(exclude_unset=True)
|
||||||
|
|
||||||
|
# 验证 name 字段(如果提供)
|
||||||
|
if "name" in req:
|
||||||
if not isinstance(req["name"], str):
|
if not isinstance(req["name"], str):
|
||||||
return get_data_error_result(message="Dataset name must be string.")
|
return get_data_error_result(message="Dataset name must be string.")
|
||||||
if req["name"].strip() == "":
|
if req["name"].strip() == "":
|
||||||
@@ -202,7 +205,8 @@ async def update(
|
|||||||
return get_data_error_result(
|
return get_data_error_result(
|
||||||
message="Can't find this knowledgebase!")
|
message="Can't find this knowledgebase!")
|
||||||
|
|
||||||
if req["name"].lower() != kb.name.lower() \
|
# 检查名称重复(仅在提供新名称时)
|
||||||
|
if "name" in req and req["name"].lower() != kb.name.lower() \
|
||||||
and len(
|
and len(
|
||||||
KnowledgebaseService.query(name=req["name"], tenant_id=current_user.id, status=StatusEnum.VALID.value)) >= 1:
|
KnowledgebaseService.query(name=req["name"], tenant_id=current_user.id, status=StatusEnum.VALID.value)) >= 1:
|
||||||
return get_data_error_result(
|
return get_data_error_result(
|
||||||
|
|||||||
@@ -24,25 +24,43 @@ from api.utils.api_utils import get_json_result
|
|||||||
http_bearer = HTTPBearer(auto_error=False)
|
http_bearer = HTTPBearer(auto_error=False)
|
||||||
|
|
||||||
|
|
||||||
def get_current_user(credentials: Optional[HTTPAuthorizationCredentials] = Security(http_bearer)):
|
def get_current_user(
|
||||||
|
authorization: Optional[str] = Header(None, alias="Authorization"),
|
||||||
|
credentials: Optional[HTTPAuthorizationCredentials] = Security(http_bearer)
|
||||||
|
):
|
||||||
"""FastAPI 依赖注入:获取当前用户(替代 Flask 的 login_required 和 current_user)
|
"""FastAPI 依赖注入:获取当前用户(替代 Flask 的 login_required 和 current_user)
|
||||||
|
|
||||||
|
支持两种格式的 Authorization 头:
|
||||||
|
1. 标准格式:Bearer <token>
|
||||||
|
2. 简化格式:<token>(不带 Bearer 前缀)
|
||||||
|
|
||||||
使用 Security(http_bearer) 可以让 FastAPI 自动在 OpenAPI schema 中添加安全要求,
|
使用 Security(http_bearer) 可以让 FastAPI 自动在 OpenAPI schema 中添加安全要求,
|
||||||
这样 Swagger UI 就会显示授权输入框并自动在请求中添加 Authorization 头。
|
这样 Swagger UI 就会显示授权输入框并自动在请求中添加 Authorization 头。
|
||||||
"""
|
"""
|
||||||
# 延迟导入以避免循环导入
|
# 延迟导入以避免循环导入
|
||||||
from api.apps.__init___fastapi import get_current_user_from_token
|
from api.apps.__init___fastapi import get_current_user_from_token
|
||||||
|
|
||||||
if not credentials:
|
token = None
|
||||||
|
|
||||||
|
# 优先从 HTTPBearer 获取(标准格式:Bearer <token>)
|
||||||
|
if credentials:
|
||||||
|
token = credentials.credentials
|
||||||
|
# 如果 HTTPBearer 没有获取到,尝试直接从 Header 获取(可能是简化格式)
|
||||||
|
elif authorization:
|
||||||
|
# 如果包含 "Bearer " 前缀,则去除它
|
||||||
|
if authorization.startswith("Bearer "):
|
||||||
|
token = authorization[7:] # 去除 "Bearer " 前缀(7个字符)
|
||||||
|
else:
|
||||||
|
# 不带 Bearer 前缀,直接使用
|
||||||
|
token = authorization
|
||||||
|
|
||||||
|
if not token:
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
detail="Authorization header is required"
|
detail="Authorization header is required"
|
||||||
)
|
)
|
||||||
|
|
||||||
# HTTPBearer 已经提取了 Bearer token,credentials.credentials 就是 token 本身
|
user = get_current_user_from_token(token)
|
||||||
authorization = credentials.credentials
|
|
||||||
|
|
||||||
user = get_current_user_from_token(authorization)
|
|
||||||
if not user:
|
if not user:
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
|
|||||||
84
api/apps/models/conversation_models.py
Normal file
84
api/apps/models/conversation_models.py
Normal file
@@ -0,0 +1,84 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from typing import Optional, List, Dict, Any
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
|
||||||
|
|
||||||
|
class SetConversationRequest(BaseModel):
|
||||||
|
"""设置对话请求"""
|
||||||
|
conversation_id: Optional[str] = None
|
||||||
|
is_new: bool
|
||||||
|
name: Optional[str] = Field(default="New conversation", max_length=255)
|
||||||
|
dialog_id: str
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteConversationsRequest(BaseModel):
|
||||||
|
"""删除对话请求"""
|
||||||
|
conversation_ids: List[str]
|
||||||
|
|
||||||
|
|
||||||
|
class CompletionRequest(BaseModel):
|
||||||
|
"""完成请求(聊天完成)"""
|
||||||
|
conversation_id: str
|
||||||
|
messages: List[Dict[str, Any]]
|
||||||
|
llm_id: Optional[str] = None
|
||||||
|
stream: Optional[bool] = True
|
||||||
|
temperature: Optional[float] = None
|
||||||
|
top_p: Optional[float] = None
|
||||||
|
frequency_penalty: Optional[float] = None
|
||||||
|
presence_penalty: Optional[float] = None
|
||||||
|
max_tokens: Optional[int] = None
|
||||||
|
|
||||||
|
|
||||||
|
class TTSRequest(BaseModel):
|
||||||
|
"""文本转语音请求"""
|
||||||
|
text: str
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteMessageRequest(BaseModel):
|
||||||
|
"""删除消息请求"""
|
||||||
|
conversation_id: str
|
||||||
|
message_id: str
|
||||||
|
|
||||||
|
|
||||||
|
class ThumbupRequest(BaseModel):
|
||||||
|
"""点赞/点踩请求"""
|
||||||
|
conversation_id: str
|
||||||
|
message_id: str
|
||||||
|
thumbup: Optional[bool] = None
|
||||||
|
feedback: Optional[str] = ""
|
||||||
|
|
||||||
|
|
||||||
|
class AskRequest(BaseModel):
|
||||||
|
"""提问请求"""
|
||||||
|
question: str
|
||||||
|
kb_ids: List[str]
|
||||||
|
search_id: Optional[str] = ""
|
||||||
|
|
||||||
|
|
||||||
|
class MindmapRequest(BaseModel):
|
||||||
|
"""思维导图请求"""
|
||||||
|
question: str
|
||||||
|
kb_ids: List[str]
|
||||||
|
search_id: Optional[str] = ""
|
||||||
|
|
||||||
|
|
||||||
|
class RelatedQuestionsRequest(BaseModel):
|
||||||
|
"""相关问题请求"""
|
||||||
|
question: str
|
||||||
|
search_id: Optional[str] = ""
|
||||||
|
|
||||||
57
api/apps/models/dialog_models.py
Normal file
57
api/apps/models/dialog_models.py
Normal file
@@ -0,0 +1,57 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from typing import Optional, List, Dict, Any
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
|
||||||
|
|
||||||
|
class SetDialogRequest(BaseModel):
|
||||||
|
"""设置/创建对话框请求"""
|
||||||
|
dialog_id: Optional[str] = Field(default="", description="对话框ID,为空时创建新对话框")
|
||||||
|
name: Optional[str] = Field(default="New Dialog", description="对话框名称")
|
||||||
|
description: Optional[str] = Field(default="A helpful dialog", description="对话框描述")
|
||||||
|
icon: Optional[str] = Field(default="", description="图标")
|
||||||
|
top_n: Optional[int] = Field(default=6, description="Top N")
|
||||||
|
top_k: Optional[int] = Field(default=1024, description="Top K")
|
||||||
|
rerank_id: Optional[str] = Field(default="", description="重排序模型ID")
|
||||||
|
similarity_threshold: Optional[float] = Field(default=0.1, description="相似度阈值")
|
||||||
|
vector_similarity_weight: Optional[float] = Field(default=0.3, description="向量相似度权重")
|
||||||
|
llm_setting: Optional[Dict[str, Any]] = Field(default={}, description="LLM设置")
|
||||||
|
meta_data_filter: Optional[Dict[str, Any]] = Field(default={}, description="元数据过滤器")
|
||||||
|
prompt_config: Dict[str, Any] = Field(..., description="提示配置")
|
||||||
|
kb_ids: Optional[List[str]] = Field(default=[], description="知识库ID列表")
|
||||||
|
llm_id: Optional[str] = Field(default=None, description="LLM ID")
|
||||||
|
|
||||||
|
|
||||||
|
class ListDialogsNextQuery(BaseModel):
|
||||||
|
"""列出对话框查询参数"""
|
||||||
|
keywords: Optional[str] = ""
|
||||||
|
page: Optional[int] = 0
|
||||||
|
page_size: Optional[int] = 0
|
||||||
|
parser_id: Optional[str] = None
|
||||||
|
orderby: Optional[str] = "create_time"
|
||||||
|
desc: Optional[str] = "true"
|
||||||
|
|
||||||
|
|
||||||
|
class ListDialogsNextBody(BaseModel):
|
||||||
|
"""列出对话框请求体"""
|
||||||
|
owner_ids: Optional[List[str]] = []
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteDialogRequest(BaseModel):
|
||||||
|
"""删除对话框请求"""
|
||||||
|
dialog_ids: List[str] = Field(..., description="要删除的对话框ID列表")
|
||||||
|
|
||||||
@@ -138,11 +138,11 @@ class GetDocumentInfosRequest(BaseModel):
|
|||||||
class ChangeStatusRequest(BaseModel):
|
class ChangeStatusRequest(BaseModel):
|
||||||
"""修改文档状态请求"""
|
"""修改文档状态请求"""
|
||||||
doc_ids: List[str]
|
doc_ids: List[str]
|
||||||
status: str # "0" 或 "1"
|
status: int
|
||||||
|
|
||||||
@model_validator(mode='after')
|
@model_validator(mode='after')
|
||||||
def validate_status(self):
|
def validate_status(self):
|
||||||
if self.status not in ["0", "1"]:
|
if self.status not in [0, 1]:
|
||||||
raise ValueError('Status must be either 0 or 1!')
|
raise ValueError('Status must be either 0 or 1!')
|
||||||
return self
|
return self
|
||||||
|
|
||||||
@@ -155,7 +155,7 @@ class DeleteDocumentRequest(BaseModel):
|
|||||||
class RunDocumentRequest(BaseModel):
|
class RunDocumentRequest(BaseModel):
|
||||||
"""运行文档解析请求"""
|
"""运行文档解析请求"""
|
||||||
doc_ids: List[str]
|
doc_ids: List[str]
|
||||||
run: str # TaskStatus 值
|
run: int # TaskStatus 值
|
||||||
delete: Optional[bool] = False
|
delete: Optional[bool] = False
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
43
api/apps/models/file_models.py
Normal file
43
api/apps/models/file_models.py
Normal file
@@ -0,0 +1,43 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from typing import Optional, List
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
|
||||||
|
|
||||||
|
class CreateFileRequest(BaseModel):
|
||||||
|
"""创建文件/文件夹请求"""
|
||||||
|
name: str
|
||||||
|
parent_id: Optional[str] = None
|
||||||
|
type: Optional[str] = None
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteFilesRequest(BaseModel):
|
||||||
|
"""删除文件请求"""
|
||||||
|
file_ids: List[str]
|
||||||
|
|
||||||
|
|
||||||
|
class RenameFileRequest(BaseModel):
|
||||||
|
"""重命名文件请求"""
|
||||||
|
file_id: str
|
||||||
|
name: str
|
||||||
|
|
||||||
|
|
||||||
|
class MoveFilesRequest(BaseModel):
|
||||||
|
"""移动文件请求"""
|
||||||
|
src_file_ids: List[str]
|
||||||
|
dest_file_id: str
|
||||||
|
|
||||||
@@ -26,11 +26,12 @@ class CreateKnowledgeBaseRequest(BaseModel):
|
|||||||
- parse_type=2: 使用自定义 pipeline,需要 pipeline_id,parser_id 为空
|
- parse_type=2: 使用自定义 pipeline,需要 pipeline_id,parser_id 为空
|
||||||
"""
|
"""
|
||||||
name: str
|
name: str
|
||||||
parse_type: Literal[1, 2] = Field(..., description="解析类型:1=内置解析器,2=自定义pipeline")
|
parse_type: Literal[1, 2] = Field(default=1, description="解析类型:1=内置解析器,2=自定义pipeline")
|
||||||
embd_id: str = Field(..., description="嵌入模型ID")
|
embd_id: str = Field(..., description="嵌入模型ID")
|
||||||
parser_id: Optional[str] = Field(default="", description="解析器ID,parse_type=1时必需")
|
parser_id: Optional[str] = Field(default="", description="解析器ID,parse_type=1时必需")
|
||||||
pipeline_id: Optional[str] = Field(default="", description="流水线ID,parse_type=2时必需")
|
pipeline_id: Optional[str] = Field(default="", description="流水线ID,parse_type=2时必需")
|
||||||
description: Optional[str] = None
|
description: Optional[str] = None
|
||||||
|
permission: Optional[str] = Field(default="me", description="权限:me|team")
|
||||||
pagerank: Optional[int] = None
|
pagerank: Optional[int] = None
|
||||||
|
|
||||||
@model_validator(mode='after')
|
@model_validator(mode='after')
|
||||||
@@ -41,8 +42,9 @@ class CreateKnowledgeBaseRequest(BaseModel):
|
|||||||
parser_id_val = self.parser_id or ""
|
parser_id_val = self.parser_id or ""
|
||||||
pipeline_id_val = self.pipeline_id or ""
|
pipeline_id_val = self.pipeline_id or ""
|
||||||
|
|
||||||
|
# 如果 parser_id 为空,自动设置为 "naive"
|
||||||
if parser_id_val.strip() == "":
|
if parser_id_val.strip() == "":
|
||||||
raise ValueError("parse_type=1时,parser_id不能为空")
|
self.parser_id = "naive"
|
||||||
if pipeline_id_val.strip() != "":
|
if pipeline_id_val.strip() != "":
|
||||||
raise ValueError("parse_type=1时,pipeline_id必须为空")
|
raise ValueError("parse_type=1时,pipeline_id必须为空")
|
||||||
elif self.parse_type == 2:
|
elif self.parse_type == 2:
|
||||||
@@ -60,9 +62,16 @@ class CreateKnowledgeBaseRequest(BaseModel):
|
|||||||
class UpdateKnowledgeBaseRequest(BaseModel):
|
class UpdateKnowledgeBaseRequest(BaseModel):
|
||||||
"""更新知识库请求"""
|
"""更新知识库请求"""
|
||||||
kb_id: str
|
kb_id: str
|
||||||
name: str
|
name: Optional[str] = None
|
||||||
description: str
|
avatar: Optional[str] = None
|
||||||
parser_id: str
|
language: Optional[str] = None
|
||||||
|
description: Optional[str] = None
|
||||||
|
permission: Optional[str] = None
|
||||||
|
doc_num: Optional[int] = None
|
||||||
|
token_num: Optional[int] = None
|
||||||
|
chunk_num: Optional[int] = None
|
||||||
|
parser_id: Optional[str] = None
|
||||||
|
embd_id: Optional[str] = None
|
||||||
pagerank: Optional[int] = None
|
pagerank: Optional[int] = None
|
||||||
# 其他可选字段,但排除 id, tenant_id, created_by, create_time, update_time, create_date, update_date
|
# 其他可选字段,但排除 id, tenant_id, created_by, create_time, update_time, create_date, update_date
|
||||||
|
|
||||||
|
|||||||
53
api/apps/models/search_models.py
Normal file
53
api/apps/models/search_models.py
Normal file
@@ -0,0 +1,53 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from typing import Optional, List, Dict, Any
|
||||||
|
from pydantic import BaseModel, Field
|
||||||
|
|
||||||
|
|
||||||
|
class CreateSearchRequest(BaseModel):
|
||||||
|
"""创建搜索应用请求"""
|
||||||
|
name: str
|
||||||
|
description: Optional[str] = ""
|
||||||
|
|
||||||
|
|
||||||
|
class UpdateSearchRequest(BaseModel):
|
||||||
|
"""更新搜索应用请求"""
|
||||||
|
search_id: str
|
||||||
|
name: str
|
||||||
|
search_config: Dict[str, Any]
|
||||||
|
tenant_id: str
|
||||||
|
description: Optional[str] = None
|
||||||
|
|
||||||
|
|
||||||
|
class DeleteSearchRequest(BaseModel):
|
||||||
|
"""删除搜索应用请求"""
|
||||||
|
search_id: str
|
||||||
|
|
||||||
|
|
||||||
|
class ListSearchAppsQuery(BaseModel):
|
||||||
|
"""列出搜索应用查询参数"""
|
||||||
|
keywords: Optional[str] = ""
|
||||||
|
page: Optional[int] = 0
|
||||||
|
page_size: Optional[int] = 0
|
||||||
|
orderby: Optional[str] = "create_time"
|
||||||
|
desc: Optional[str] = "true"
|
||||||
|
|
||||||
|
|
||||||
|
class ListSearchAppsBody(BaseModel):
|
||||||
|
"""列出搜索应用请求体"""
|
||||||
|
owner_ids: Optional[List[str]] = []
|
||||||
|
|
||||||
23
api/apps/models/tenant_models.py
Normal file
23
api/apps/models/tenant_models.py
Normal file
@@ -0,0 +1,23 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from pydantic import BaseModel, Field, EmailStr
|
||||||
|
|
||||||
|
|
||||||
|
class InviteUserRequest(BaseModel):
|
||||||
|
"""邀请用户请求"""
|
||||||
|
email: EmailStr = Field(..., description="要邀请的用户邮箱")
|
||||||
|
|
||||||
@@ -14,8 +14,18 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
|
||||||
from flask import request
|
from typing import Optional
|
||||||
from flask_login import current_user, login_required
|
|
||||||
|
from fastapi import APIRouter, Depends, Query
|
||||||
|
|
||||||
|
from api.apps.models.auth_dependencies import get_current_user
|
||||||
|
from api.apps.models.search_models import (
|
||||||
|
CreateSearchRequest,
|
||||||
|
UpdateSearchRequest,
|
||||||
|
DeleteSearchRequest,
|
||||||
|
ListSearchAppsQuery,
|
||||||
|
ListSearchAppsBody,
|
||||||
|
)
|
||||||
|
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.constants import DATASET_NAME_LIMIT
|
from api.constants import DATASET_NAME_LIMIT
|
||||||
@@ -25,14 +35,23 @@ from api.db.services import duplicate_name
|
|||||||
from api.db.services.search_service import SearchService
|
from api.db.services.search_service import SearchService
|
||||||
from api.db.services.user_service import TenantService, UserTenantService
|
from api.db.services.user_service import TenantService, UserTenantService
|
||||||
from api.utils import get_uuid
|
from api.utils import get_uuid
|
||||||
from api.utils.api_utils import get_data_error_result, get_json_result, not_allowed_parameters, server_error_response, validate_request
|
from api.utils.api_utils import (
|
||||||
|
get_data_error_result,
|
||||||
|
get_json_result,
|
||||||
|
server_error_response,
|
||||||
|
)
|
||||||
|
|
||||||
|
# 创建路由器
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/create", methods=["post"]) # noqa: F821
|
@router.post('/create')
|
||||||
@login_required
|
async def create(
|
||||||
@validate_request("name")
|
request: CreateSearchRequest,
|
||||||
def create():
|
current_user = Depends(get_current_user)
|
||||||
req = request.get_json()
|
):
|
||||||
|
"""创建搜索应用"""
|
||||||
|
req = request.model_dump(exclude_unset=True)
|
||||||
search_name = req["name"]
|
search_name = req["name"]
|
||||||
description = req.get("description", "")
|
description = req.get("description", "")
|
||||||
if not isinstance(search_name, str):
|
if not isinstance(search_name, str):
|
||||||
@@ -62,12 +81,13 @@ def create():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/update", methods=["post"]) # noqa: F821
|
@router.post('/update')
|
||||||
@login_required
|
async def update(
|
||||||
@validate_request("search_id", "name", "search_config", "tenant_id")
|
request: UpdateSearchRequest,
|
||||||
@not_allowed_parameters("id", "created_by", "create_time", "update_time", "create_date", "update_date", "created_by")
|
current_user = Depends(get_current_user)
|
||||||
def update():
|
):
|
||||||
req = request.get_json()
|
"""更新搜索应用"""
|
||||||
|
req = request.model_dump(exclude_unset=True)
|
||||||
if not isinstance(req["name"], str):
|
if not isinstance(req["name"], str):
|
||||||
return get_data_error_result(message="Search name must be string.")
|
return get_data_error_result(message="Search name must be string.")
|
||||||
if req["name"].strip() == "":
|
if req["name"].strip() == "":
|
||||||
@@ -84,6 +104,12 @@ def update():
|
|||||||
if not SearchService.accessible4deletion(search_id, current_user.id):
|
if not SearchService.accessible4deletion(search_id, current_user.id):
|
||||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
|
|
||||||
|
# 验证不允许的参数
|
||||||
|
not_allowed = ["id", "created_by", "create_time", "update_time", "create_date", "update_date"]
|
||||||
|
for key in not_allowed:
|
||||||
|
if key in req:
|
||||||
|
del req[key]
|
||||||
|
|
||||||
try:
|
try:
|
||||||
search_app = SearchService.query(tenant_id=tenant_id, id=search_id)[0]
|
search_app = SearchService.query(tenant_id=tenant_id, id=search_id)[0]
|
||||||
if not search_app:
|
if not search_app:
|
||||||
@@ -119,10 +145,12 @@ def update():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/detail", methods=["GET"]) # noqa: F821
|
@router.get('/detail')
|
||||||
@login_required
|
async def detail(
|
||||||
def detail():
|
search_id: str = Query(..., description="搜索应用ID"),
|
||||||
search_id = request.args["search_id"]
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取搜索应用详情"""
|
||||||
try:
|
try:
|
||||||
tenants = UserTenantService.query(user_id=current_user.id)
|
tenants = UserTenantService.query(user_id=current_user.id)
|
||||||
for tenant in tenants:
|
for tenant in tenants:
|
||||||
@@ -139,20 +167,23 @@ def detail():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/list", methods=["POST"]) # noqa: F821
|
@router.post('/list')
|
||||||
@login_required
|
async def list_search_app(
|
||||||
def list_search_app():
|
query: ListSearchAppsQuery = Depends(),
|
||||||
keywords = request.args.get("keywords", "")
|
body: Optional[ListSearchAppsBody] = None,
|
||||||
page_number = int(request.args.get("page", 0))
|
current_user = Depends(get_current_user)
|
||||||
items_per_page = int(request.args.get("page_size", 0))
|
):
|
||||||
orderby = request.args.get("orderby", "create_time")
|
"""列出搜索应用"""
|
||||||
if request.args.get("desc", "true").lower() == "false":
|
if body is None:
|
||||||
desc = False
|
body = ListSearchAppsBody()
|
||||||
else:
|
|
||||||
desc = True
|
|
||||||
|
|
||||||
req = request.get_json()
|
keywords = query.keywords or ""
|
||||||
owner_ids = req.get("owner_ids", [])
|
page_number = int(query.page or 0)
|
||||||
|
items_per_page = int(query.page_size or 0)
|
||||||
|
orderby = query.orderby or "create_time"
|
||||||
|
desc = query.desc.lower() == "true" if query.desc else True
|
||||||
|
|
||||||
|
owner_ids = body.owner_ids or [] if body else []
|
||||||
try:
|
try:
|
||||||
if not owner_ids:
|
if not owner_ids:
|
||||||
# tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
# tenants = TenantService.get_joined_tenants_by_user_id(current_user.id)
|
||||||
@@ -171,12 +202,13 @@ def list_search_app():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/rm", methods=["post"]) # noqa: F821
|
@router.post('/rm')
|
||||||
@login_required
|
async def rm(
|
||||||
@validate_request("search_id")
|
request: DeleteSearchRequest,
|
||||||
def rm():
|
current_user = Depends(get_current_user)
|
||||||
req = request.get_json()
|
):
|
||||||
search_id = req["search_id"]
|
"""删除搜索应用"""
|
||||||
|
search_id = request.search_id
|
||||||
if not SearchService.accessible4deletion(search_id, current_user.id):
|
if not SearchService.accessible4deletion(search_id, current_user.id):
|
||||||
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
return get_json_result(data=False, message="No authorization.", code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
|
|
||||||
|
|||||||
@@ -17,7 +17,8 @@ import logging
|
|||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
import json
|
import json
|
||||||
|
|
||||||
from flask_login import login_required, current_user
|
from fastapi import APIRouter, Depends
|
||||||
|
from fastapi.responses import JSONResponse
|
||||||
|
|
||||||
from api.db.db_models import APIToken
|
from api.db.db_models import APIToken
|
||||||
from api.db.services.api_service import APITokenService
|
from api.db.services.api_service import APITokenService
|
||||||
@@ -36,67 +37,26 @@ from rag.utils.storage_factory import STORAGE_IMPL, STORAGE_IMPL_TYPE
|
|||||||
from timeit import default_timer as timer
|
from timeit import default_timer as timer
|
||||||
|
|
||||||
from rag.utils.redis_conn import REDIS_CONN
|
from rag.utils.redis_conn import REDIS_CONN
|
||||||
from flask import jsonify
|
|
||||||
from api.utils.health_utils import run_health_checks
|
from api.utils.health_utils import run_health_checks
|
||||||
|
from api.apps.models.auth_dependencies import get_current_user
|
||||||
|
|
||||||
|
# 创建路由器
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/version", methods=["GET"]) # noqa: F821
|
@router.get("/version")
|
||||||
@login_required
|
async def version(
|
||||||
def version():
|
current_user = Depends(get_current_user)
|
||||||
"""
|
):
|
||||||
Get the current version of the application.
|
"""获取应用程序当前版本"""
|
||||||
---
|
|
||||||
tags:
|
|
||||||
- System
|
|
||||||
security:
|
|
||||||
- ApiKeyAuth: []
|
|
||||||
responses:
|
|
||||||
200:
|
|
||||||
description: Version retrieved successfully.
|
|
||||||
schema:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
version:
|
|
||||||
type: string
|
|
||||||
description: Version number.
|
|
||||||
"""
|
|
||||||
return get_json_result(data=get_ragflow_version())
|
return get_json_result(data=get_ragflow_version())
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/status", methods=["GET"]) # noqa: F821
|
@router.get("/status")
|
||||||
@login_required
|
async def status(
|
||||||
def status():
|
current_user = Depends(get_current_user)
|
||||||
"""
|
):
|
||||||
Get the system status.
|
"""获取系统状态"""
|
||||||
---
|
|
||||||
tags:
|
|
||||||
- System
|
|
||||||
security:
|
|
||||||
- ApiKeyAuth: []
|
|
||||||
responses:
|
|
||||||
200:
|
|
||||||
description: System is operational.
|
|
||||||
schema:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
es:
|
|
||||||
type: object
|
|
||||||
description: Elasticsearch status.
|
|
||||||
storage:
|
|
||||||
type: object
|
|
||||||
description: Storage status.
|
|
||||||
database:
|
|
||||||
type: object
|
|
||||||
description: Database status.
|
|
||||||
503:
|
|
||||||
description: Service unavailable.
|
|
||||||
schema:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
error:
|
|
||||||
type: string
|
|
||||||
description: Error message.
|
|
||||||
"""
|
|
||||||
res = {}
|
res = {}
|
||||||
st = timer()
|
st = timer()
|
||||||
try:
|
try:
|
||||||
@@ -172,43 +132,24 @@ def status():
|
|||||||
return get_json_result(data=res)
|
return get_json_result(data=res)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/healthz", methods=["GET"]) # noqa: F821
|
@router.get("/healthz")
|
||||||
def healthz():
|
async def healthz():
|
||||||
|
"""健康检查"""
|
||||||
result, all_ok = run_health_checks()
|
result, all_ok = run_health_checks()
|
||||||
return jsonify(result), (200 if all_ok else 500)
|
return JSONResponse(content=result, status_code=200 if all_ok else 500)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/ping", methods=["GET"]) # noqa: F821
|
@router.get("/ping")
|
||||||
def ping():
|
async def ping():
|
||||||
return "pong", 200
|
"""心跳检测"""
|
||||||
|
return "pong"
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/new_token", methods=["POST"]) # noqa: F821
|
@router.post("/new_token")
|
||||||
@login_required
|
async def new_token(
|
||||||
def new_token():
|
current_user = Depends(get_current_user)
|
||||||
"""
|
):
|
||||||
Generate a new API token.
|
"""生成新的 API 令牌"""
|
||||||
---
|
|
||||||
tags:
|
|
||||||
- API Tokens
|
|
||||||
security:
|
|
||||||
- ApiKeyAuth: []
|
|
||||||
parameters:
|
|
||||||
- in: query
|
|
||||||
name: name
|
|
||||||
type: string
|
|
||||||
required: false
|
|
||||||
description: Name of the token.
|
|
||||||
responses:
|
|
||||||
200:
|
|
||||||
description: Token generated successfully.
|
|
||||||
schema:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
token:
|
|
||||||
type: string
|
|
||||||
description: The generated API token.
|
|
||||||
"""
|
|
||||||
try:
|
try:
|
||||||
tenants = UserTenantService.query(user_id=current_user.id)
|
tenants = UserTenantService.query(user_id=current_user.id)
|
||||||
if not tenants:
|
if not tenants:
|
||||||
@@ -233,37 +174,11 @@ def new_token():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/token_list", methods=["GET"]) # noqa: F821
|
@router.get("/token_list")
|
||||||
@login_required
|
async def token_list(
|
||||||
def token_list():
|
current_user = Depends(get_current_user)
|
||||||
"""
|
):
|
||||||
List all API tokens for the current user.
|
"""列出当前用户的所有 API 令牌"""
|
||||||
---
|
|
||||||
tags:
|
|
||||||
- API Tokens
|
|
||||||
security:
|
|
||||||
- ApiKeyAuth: []
|
|
||||||
responses:
|
|
||||||
200:
|
|
||||||
description: List of API tokens.
|
|
||||||
schema:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
tokens:
|
|
||||||
type: array
|
|
||||||
items:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
token:
|
|
||||||
type: string
|
|
||||||
description: The API token.
|
|
||||||
name:
|
|
||||||
type: string
|
|
||||||
description: Name of the token.
|
|
||||||
create_time:
|
|
||||||
type: string
|
|
||||||
description: Token creation time.
|
|
||||||
"""
|
|
||||||
try:
|
try:
|
||||||
tenants = UserTenantService.query(user_id=current_user.id)
|
tenants = UserTenantService.query(user_id=current_user.id)
|
||||||
if not tenants:
|
if not tenants:
|
||||||
@@ -282,55 +197,21 @@ def token_list():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/token/<token>", methods=["DELETE"]) # noqa: F821
|
@router.delete("/token/{token}")
|
||||||
@login_required
|
async def rm(
|
||||||
def rm(token):
|
token: str,
|
||||||
"""
|
current_user = Depends(get_current_user)
|
||||||
Remove an API token.
|
):
|
||||||
---
|
"""删除 API 令牌"""
|
||||||
tags:
|
|
||||||
- API Tokens
|
|
||||||
security:
|
|
||||||
- ApiKeyAuth: []
|
|
||||||
parameters:
|
|
||||||
- in: path
|
|
||||||
name: token
|
|
||||||
type: string
|
|
||||||
required: true
|
|
||||||
description: The API token to remove.
|
|
||||||
responses:
|
|
||||||
200:
|
|
||||||
description: Token removed successfully.
|
|
||||||
schema:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
success:
|
|
||||||
type: boolean
|
|
||||||
description: Deletion status.
|
|
||||||
"""
|
|
||||||
APITokenService.filter_delete(
|
APITokenService.filter_delete(
|
||||||
[APIToken.tenant_id == current_user.id, APIToken.token == token]
|
[APIToken.tenant_id == current_user.id, APIToken.token == token]
|
||||||
)
|
)
|
||||||
return get_json_result(data=True)
|
return get_json_result(data=True)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/config', methods=['GET']) # noqa: F821
|
@router.get('/config')
|
||||||
def get_config():
|
async def get_config():
|
||||||
"""
|
"""获取系统配置"""
|
||||||
Get system configuration.
|
|
||||||
---
|
|
||||||
tags:
|
|
||||||
- System
|
|
||||||
responses:
|
|
||||||
200:
|
|
||||||
description: Return system configuration
|
|
||||||
schema:
|
|
||||||
type: object
|
|
||||||
properties:
|
|
||||||
registerEnable:
|
|
||||||
type: integer 0 means disabled, 1 means enabled
|
|
||||||
description: Whether user registration is enabled
|
|
||||||
"""
|
|
||||||
return get_json_result(data={
|
return get_json_result(data={
|
||||||
"registerEnabled": settings.REGISTER_ENABLED
|
"registerEnabled": settings.REGISTER_ENABLED
|
||||||
})
|
})
|
||||||
|
|||||||
@@ -14,9 +14,10 @@
|
|||||||
# limitations under the License.
|
# limitations under the License.
|
||||||
#
|
#
|
||||||
|
|
||||||
from flask import request
|
from fastapi import APIRouter, Depends, Path
|
||||||
from flask_login import login_required, current_user
|
|
||||||
|
|
||||||
|
from api.apps.models.auth_dependencies import get_current_user
|
||||||
|
from api.apps.models.tenant_models import InviteUserRequest
|
||||||
from api import settings
|
from api import settings
|
||||||
from api.apps import smtp_mail_server
|
from api.apps import smtp_mail_server
|
||||||
from api.db import UserTenantRole, StatusEnum
|
from api.db import UserTenantRole, StatusEnum
|
||||||
@@ -24,13 +25,19 @@ from api.db.db_models import UserTenant
|
|||||||
from api.db.services.user_service import UserTenantService, UserService
|
from api.db.services.user_service import UserTenantService, UserService
|
||||||
|
|
||||||
from api.utils import get_uuid, delta_seconds
|
from api.utils import get_uuid, delta_seconds
|
||||||
from api.utils.api_utils import get_json_result, validate_request, server_error_response, get_data_error_result
|
from api.utils.api_utils import get_json_result, server_error_response, get_data_error_result
|
||||||
from api.utils.web_utils import send_invite_email
|
from api.utils.web_utils import send_invite_email
|
||||||
|
|
||||||
|
# 创建路由器
|
||||||
|
router = APIRouter()
|
||||||
|
|
||||||
@manager.route("/<tenant_id>/user/list", methods=["GET"]) # noqa: F821
|
|
||||||
@login_required
|
@router.get("/{tenant_id}/user/list")
|
||||||
def user_list(tenant_id):
|
async def user_list(
|
||||||
|
tenant_id: str = Path(..., description="租户ID"),
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取租户用户列表"""
|
||||||
if current_user.id != tenant_id:
|
if current_user.id != tenant_id:
|
||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False,
|
data=False,
|
||||||
@@ -46,18 +53,20 @@ def user_list(tenant_id):
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/<tenant_id>/user', methods=['POST']) # noqa: F821
|
@router.post('/{tenant_id}/user')
|
||||||
@login_required
|
async def create(
|
||||||
@validate_request("email")
|
tenant_id: str,
|
||||||
def create(tenant_id):
|
request: InviteUserRequest,
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""邀请用户加入租户"""
|
||||||
if current_user.id != tenant_id:
|
if current_user.id != tenant_id:
|
||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False,
|
data=False,
|
||||||
message='No authorization.',
|
message='No authorization.',
|
||||||
code=settings.RetCode.AUTHENTICATION_ERROR)
|
code=settings.RetCode.AUTHENTICATION_ERROR)
|
||||||
|
|
||||||
req = request.json
|
invite_user_email = request.email
|
||||||
invite_user_email = req["email"]
|
|
||||||
invite_users = UserService.query(email=invite_user_email)
|
invite_users = UserService.query(email=invite_user_email)
|
||||||
if not invite_users:
|
if not invite_users:
|
||||||
return get_data_error_result(message="User not found.")
|
return get_data_error_result(message="User not found.")
|
||||||
@@ -101,9 +110,13 @@ def create(tenant_id):
|
|||||||
return get_json_result(data=usr)
|
return get_json_result(data=usr)
|
||||||
|
|
||||||
|
|
||||||
@manager.route('/<tenant_id>/user/<user_id>', methods=['DELETE']) # noqa: F821
|
@router.delete('/{tenant_id}/user/{user_id}')
|
||||||
@login_required
|
async def rm(
|
||||||
def rm(tenant_id, user_id):
|
tenant_id: str = Path(..., description="租户ID"),
|
||||||
|
user_id: str = Path(..., description="用户ID"),
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""从租户中删除用户"""
|
||||||
if current_user.id != tenant_id and current_user.id != user_id:
|
if current_user.id != tenant_id and current_user.id != user_id:
|
||||||
return get_json_result(
|
return get_json_result(
|
||||||
data=False,
|
data=False,
|
||||||
@@ -117,9 +130,11 @@ def rm(tenant_id, user_id):
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/list", methods=["GET"]) # noqa: F821
|
@router.get("/list")
|
||||||
@login_required
|
async def tenant_list(
|
||||||
def tenant_list():
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""获取租户列表"""
|
||||||
try:
|
try:
|
||||||
users = UserTenantService.get_tenants_by_user_id(current_user.id)
|
users = UserTenantService.get_tenants_by_user_id(current_user.id)
|
||||||
for u in users:
|
for u in users:
|
||||||
@@ -129,9 +144,12 @@ def tenant_list():
|
|||||||
return server_error_response(e)
|
return server_error_response(e)
|
||||||
|
|
||||||
|
|
||||||
@manager.route("/agree/<tenant_id>", methods=["PUT"]) # noqa: F821
|
@router.put("/agree/{tenant_id}")
|
||||||
@login_required
|
async def agree(
|
||||||
def agree(tenant_id):
|
tenant_id: str = Path(..., description="租户ID"),
|
||||||
|
current_user = Depends(get_current_user)
|
||||||
|
):
|
||||||
|
"""同意加入租户邀请"""
|
||||||
try:
|
try:
|
||||||
UserTenantService.filter_update([UserTenant.tenant_id == tenant_id, UserTenant.user_id == current_user.id],
|
UserTenantService.filter_update([UserTenant.tenant_id == tenant_id, UserTenant.user_id == current_user.id],
|
||||||
{"role": UserTenantRole.NORMAL})
|
{"role": UserTenantRole.NORMAL})
|
||||||
|
|||||||
@@ -15,12 +15,15 @@
|
|||||||
#
|
#
|
||||||
import json
|
import json
|
||||||
import logging
|
import logging
|
||||||
|
import os
|
||||||
import re
|
import re
|
||||||
import secrets
|
import secrets
|
||||||
|
import string
|
||||||
|
import time
|
||||||
from datetime import datetime
|
from datetime import datetime
|
||||||
from typing import Optional, Dict, Any
|
from typing import Optional, Dict, Any
|
||||||
|
|
||||||
from fastapi import APIRouter, Depends, HTTPException, Request, Response, status
|
from fastapi import APIRouter, Depends, HTTPException, Request, Response, Query, status
|
||||||
from api.apps.models.auth_dependencies import get_current_user
|
from api.apps.models.auth_dependencies import get_current_user
|
||||||
from fastapi.responses import RedirectResponse
|
from fastapi.responses import RedirectResponse
|
||||||
from pydantic import BaseModel, EmailStr
|
from pydantic import BaseModel, EmailStr
|
||||||
@@ -60,6 +63,19 @@ from api.utils.api_utils import (
|
|||||||
validate_request,
|
validate_request,
|
||||||
)
|
)
|
||||||
from api.utils.crypt import decrypt
|
from api.utils.crypt import decrypt
|
||||||
|
from rag.utils.redis_conn import REDIS_CONN
|
||||||
|
from api.apps import smtp_mail_server
|
||||||
|
from api.utils.web_utils import (
|
||||||
|
send_email_html,
|
||||||
|
OTP_LENGTH,
|
||||||
|
OTP_TTL_SECONDS,
|
||||||
|
ATTEMPT_LIMIT,
|
||||||
|
ATTEMPT_LOCK_SECONDS,
|
||||||
|
RESEND_COOLDOWN_SECONDS,
|
||||||
|
otp_keys,
|
||||||
|
hash_code,
|
||||||
|
captcha_key,
|
||||||
|
)
|
||||||
|
|
||||||
# 创建路由器
|
# 创建路由器
|
||||||
router = APIRouter()
|
router = APIRouter()
|
||||||
@@ -77,10 +93,14 @@ class RegisterRequest(BaseModel):
|
|||||||
password: str
|
password: str
|
||||||
|
|
||||||
class UserSettingRequest(BaseModel):
|
class UserSettingRequest(BaseModel):
|
||||||
|
language: Optional[str] = None
|
||||||
nickname: Optional[str] = None
|
nickname: Optional[str] = None
|
||||||
|
avatar: Optional[str] = None
|
||||||
|
timezone: Optional[str] = None
|
||||||
password: Optional[str] = None
|
password: Optional[str] = None
|
||||||
new_password: Optional[str] = None
|
new_password: Optional[str] = None
|
||||||
|
|
||||||
|
|
||||||
class TenantInfoRequest(BaseModel):
|
class TenantInfoRequest(BaseModel):
|
||||||
tenant_id: str
|
tenant_id: str
|
||||||
asr_id: str
|
asr_id: str
|
||||||
@@ -88,6 +108,16 @@ class TenantInfoRequest(BaseModel):
|
|||||||
img2txt_id: str
|
img2txt_id: str
|
||||||
llm_id: str
|
llm_id: str
|
||||||
|
|
||||||
|
class ForgetOtpRequest(BaseModel):
|
||||||
|
email: str
|
||||||
|
captcha: str
|
||||||
|
|
||||||
|
class ForgetPasswordRequest(BaseModel):
|
||||||
|
email: str
|
||||||
|
otp: str
|
||||||
|
new_password: str
|
||||||
|
confirm_new_password: str
|
||||||
|
|
||||||
# 依赖项:获取当前用户 - 从 auth_dependencies 导入
|
# 依赖项:获取当前用户 - 从 auth_dependencies 导入
|
||||||
|
|
||||||
@router.post("/login")
|
@router.post("/login")
|
||||||
@@ -95,12 +125,13 @@ async def login(request: LoginRequest):
|
|||||||
"""
|
"""
|
||||||
用户登录端点
|
用户登录端点
|
||||||
"""
|
"""
|
||||||
email = request.email
|
raw_email = (request.email or "").strip()
|
||||||
users = UserService.query(email=email)
|
email = raw_email.lower()
|
||||||
|
users = UserService.query_user_by_email_insensitive(raw_email)
|
||||||
if not users:
|
if not users:
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
detail=f"Email: {email} is not registered!"
|
detail=f"Email: {raw_email} is not registered!"
|
||||||
)
|
)
|
||||||
|
|
||||||
password = request.password
|
password = request.password
|
||||||
@@ -279,17 +310,22 @@ async def setting_user(request: UserSettingRequest, current_user = Depends(get_c
|
|||||||
更新用户设置
|
更新用户设置
|
||||||
"""
|
"""
|
||||||
update_dict = {}
|
update_dict = {}
|
||||||
request_data = request.dict()
|
request_data = request.dict(exclude_unset=True)
|
||||||
|
|
||||||
if request_data.get("password"):
|
password = request_data.get("password")
|
||||||
new_password = request_data.get("new_password")
|
new_password = request_data.get("new_password")
|
||||||
if not check_password_hash(current_user.password, decrypt(request_data["password"])):
|
if password is not None or new_password is not None:
|
||||||
|
if not password or not new_password:
|
||||||
|
raise HTTPException(
|
||||||
|
status_code=status.HTTP_400_BAD_REQUEST,
|
||||||
|
detail="Both password and new_password are required!"
|
||||||
|
)
|
||||||
|
if not check_password_hash(current_user.password, decrypt(password)):
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_401_UNAUTHORIZED,
|
status_code=status.HTTP_401_UNAUTHORIZED,
|
||||||
detail="Password error!"
|
detail="Password error!"
|
||||||
)
|
)
|
||||||
|
|
||||||
if new_password:
|
|
||||||
update_dict["password"] = generate_password_hash(decrypt(new_password))
|
update_dict["password"] = generate_password_hash(decrypt(new_password))
|
||||||
|
|
||||||
for k in request_data.keys():
|
for k in request_data.keys():
|
||||||
@@ -407,8 +443,9 @@ async def user_add(request: RegisterRequest):
|
|||||||
detail=f"Invalid email address: {email_address}!"
|
detail=f"Invalid email address: {email_address}!"
|
||||||
)
|
)
|
||||||
|
|
||||||
# 检查邮箱地址是否已被使用
|
# 检查邮箱地址是否已被使用(大小写不敏感)
|
||||||
if UserService.query(email=email_address):
|
existing_users = UserService.query_user_by_email_insensitive(email_address)
|
||||||
|
if existing_users:
|
||||||
raise HTTPException(
|
raise HTTPException(
|
||||||
status_code=status.HTTP_400_BAD_REQUEST,
|
status_code=status.HTTP_400_BAD_REQUEST,
|
||||||
detail=f"Email: {email_address} has already registered!"
|
detail=f"Email: {email_address} has already registered!"
|
||||||
@@ -481,3 +518,357 @@ async def set_tenant_info(request: TenantInfoRequest, current_user = Depends(get
|
|||||||
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
|
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
|
||||||
detail=str(e)
|
detail=str(e)
|
||||||
)
|
)
|
||||||
|
|
||||||
|
@router.get("/github_callback")
|
||||||
|
async def github_callback(code: Optional[str] = Query(None)):
|
||||||
|
"""
|
||||||
|
**Deprecated**, Use `/oauth/callback/<channel>` instead.
|
||||||
|
|
||||||
|
GitHub OAuth callback endpoint.
|
||||||
|
"""
|
||||||
|
import requests
|
||||||
|
|
||||||
|
if not code:
|
||||||
|
return RedirectResponse(url="/?error=missing_code")
|
||||||
|
|
||||||
|
res = requests.post(
|
||||||
|
settings.GITHUB_OAUTH.get("url"),
|
||||||
|
data={
|
||||||
|
"client_id": settings.GITHUB_OAUTH.get("client_id"),
|
||||||
|
"client_secret": settings.GITHUB_OAUTH.get("secret_key"),
|
||||||
|
"code": code,
|
||||||
|
},
|
||||||
|
headers={"Accept": "application/json"},
|
||||||
|
)
|
||||||
|
res = res.json()
|
||||||
|
if "error" in res:
|
||||||
|
return RedirectResponse(url=f"/?error={res.get('error_description', res.get('error'))}")
|
||||||
|
|
||||||
|
if "user:email" not in res.get("scope", "").split(","):
|
||||||
|
return RedirectResponse(url="/?error=user:email not in scope")
|
||||||
|
|
||||||
|
access_token = res["access_token"]
|
||||||
|
user_info = user_info_from_github(access_token)
|
||||||
|
email_address = user_info["email"]
|
||||||
|
users = UserService.query(email=email_address)
|
||||||
|
user_id = get_uuid()
|
||||||
|
|
||||||
|
if not users:
|
||||||
|
try:
|
||||||
|
try:
|
||||||
|
avatar = download_img(user_info["avatar_url"])
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception(e)
|
||||||
|
avatar = ""
|
||||||
|
|
||||||
|
users = user_register(
|
||||||
|
user_id,
|
||||||
|
{
|
||||||
|
"access_token": access_token,
|
||||||
|
"email": email_address,
|
||||||
|
"avatar": avatar,
|
||||||
|
"nickname": user_info["login"],
|
||||||
|
"login_channel": "github",
|
||||||
|
"last_login_time": get_format_time(),
|
||||||
|
"is_superuser": False,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
if not users:
|
||||||
|
raise Exception(f"Fail to register {email_address}.")
|
||||||
|
if len(users) > 1:
|
||||||
|
raise Exception(f"Same email: {email_address} exists!")
|
||||||
|
|
||||||
|
user = users[0]
|
||||||
|
return RedirectResponse(url=f"/?auth={user.get_id()}")
|
||||||
|
except Exception as e:
|
||||||
|
rollback_user_registration(user_id)
|
||||||
|
logging.exception(e)
|
||||||
|
return RedirectResponse(url=f"/?error={str(e)}")
|
||||||
|
|
||||||
|
# User has already registered, try to log in
|
||||||
|
user = users[0]
|
||||||
|
user.access_token = get_uuid()
|
||||||
|
if user and hasattr(user, 'is_active') and user.is_active == "0":
|
||||||
|
return RedirectResponse(url="/?error=user_inactive")
|
||||||
|
user.save()
|
||||||
|
return RedirectResponse(url=f"/?auth={user.get_id()}")
|
||||||
|
|
||||||
|
@router.get("/feishu_callback")
|
||||||
|
async def feishu_callback(code: Optional[str] = Query(None)):
|
||||||
|
"""
|
||||||
|
Feishu OAuth callback endpoint.
|
||||||
|
"""
|
||||||
|
import requests
|
||||||
|
|
||||||
|
if not code:
|
||||||
|
return RedirectResponse(url="/?error=missing_code")
|
||||||
|
|
||||||
|
app_access_token_res = requests.post(
|
||||||
|
settings.FEISHU_OAUTH.get("app_access_token_url"),
|
||||||
|
data=json.dumps(
|
||||||
|
{
|
||||||
|
"app_id": settings.FEISHU_OAUTH.get("app_id"),
|
||||||
|
"app_secret": settings.FEISHU_OAUTH.get("app_secret"),
|
||||||
|
}
|
||||||
|
),
|
||||||
|
headers={"Content-Type": "application/json; charset=utf-8"},
|
||||||
|
)
|
||||||
|
app_access_token_res = app_access_token_res.json()
|
||||||
|
if app_access_token_res.get("code") != 0:
|
||||||
|
return RedirectResponse(url=f"/?error={app_access_token_res}")
|
||||||
|
|
||||||
|
res = requests.post(
|
||||||
|
settings.FEISHU_OAUTH.get("user_access_token_url"),
|
||||||
|
data=json.dumps(
|
||||||
|
{
|
||||||
|
"grant_type": settings.FEISHU_OAUTH.get("grant_type"),
|
||||||
|
"code": code,
|
||||||
|
}
|
||||||
|
),
|
||||||
|
headers={
|
||||||
|
"Content-Type": "application/json; charset=utf-8",
|
||||||
|
"Authorization": f"Bearer {app_access_token_res['app_access_token']}",
|
||||||
|
},
|
||||||
|
)
|
||||||
|
res = res.json()
|
||||||
|
if res.get("code") != 0:
|
||||||
|
return RedirectResponse(url=f"/?error={res.get('message', 'unknown_error')}")
|
||||||
|
|
||||||
|
if "contact:user.email:readonly" not in res.get("data", {}).get("scope", "").split():
|
||||||
|
return RedirectResponse(url="/?error=contact:user.email:readonly not in scope")
|
||||||
|
|
||||||
|
access_token = res["data"]["access_token"]
|
||||||
|
user_info = user_info_from_feishu(access_token)
|
||||||
|
email_address = user_info["email"]
|
||||||
|
users = UserService.query(email=email_address)
|
||||||
|
user_id = get_uuid()
|
||||||
|
|
||||||
|
if not users:
|
||||||
|
try:
|
||||||
|
try:
|
||||||
|
avatar = download_img(user_info["avatar_url"])
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception(e)
|
||||||
|
avatar = ""
|
||||||
|
|
||||||
|
users = user_register(
|
||||||
|
user_id,
|
||||||
|
{
|
||||||
|
"access_token": access_token,
|
||||||
|
"email": email_address,
|
||||||
|
"avatar": avatar,
|
||||||
|
"nickname": user_info["en_name"],
|
||||||
|
"login_channel": "feishu",
|
||||||
|
"last_login_time": get_format_time(),
|
||||||
|
"is_superuser": False,
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
if not users:
|
||||||
|
raise Exception(f"Fail to register {email_address}.")
|
||||||
|
if len(users) > 1:
|
||||||
|
raise Exception(f"Same email: {email_address} exists!")
|
||||||
|
|
||||||
|
user = users[0]
|
||||||
|
return RedirectResponse(url=f"/?auth={user.get_id()}")
|
||||||
|
except Exception as e:
|
||||||
|
rollback_user_registration(user_id)
|
||||||
|
logging.exception(e)
|
||||||
|
return RedirectResponse(url=f"/?error={str(e)}")
|
||||||
|
|
||||||
|
# User has already registered, try to log in
|
||||||
|
user = users[0]
|
||||||
|
if user and hasattr(user, 'is_active') and user.is_active == "0":
|
||||||
|
return RedirectResponse(url="/?error=user_inactive")
|
||||||
|
user.access_token = get_uuid()
|
||||||
|
user.save()
|
||||||
|
return RedirectResponse(url=f"/?auth={user.get_id()}")
|
||||||
|
|
||||||
|
def user_info_from_feishu(access_token):
|
||||||
|
"""从飞书获取用户信息"""
|
||||||
|
import requests
|
||||||
|
|
||||||
|
headers = {
|
||||||
|
"Content-Type": "application/json; charset=utf-8",
|
||||||
|
"Authorization": f"Bearer {access_token}",
|
||||||
|
}
|
||||||
|
res = requests.get("https://open.feishu.cn/open-apis/authen/v1/user_info", headers=headers)
|
||||||
|
user_info = res.json()["data"]
|
||||||
|
user_info["email"] = None if user_info.get("email") == "" else user_info["email"]
|
||||||
|
return user_info
|
||||||
|
|
||||||
|
def user_info_from_github(access_token):
|
||||||
|
"""从GitHub获取用户信息"""
|
||||||
|
import requests
|
||||||
|
|
||||||
|
headers = {"Accept": "application/json", "Authorization": f"token {access_token}"}
|
||||||
|
res = requests.get(f"https://api.github.com/user?access_token={access_token}", headers=headers)
|
||||||
|
user_info = res.json()
|
||||||
|
email_info = requests.get(
|
||||||
|
f"https://api.github.com/user/emails?access_token={access_token}",
|
||||||
|
headers=headers,
|
||||||
|
).json()
|
||||||
|
user_info["email"] = next((email for email in email_info if email["primary"]), None)["email"]
|
||||||
|
return user_info
|
||||||
|
|
||||||
|
@router.get("/forget/captcha")
|
||||||
|
async def forget_get_captcha(email: str = Query(...)):
|
||||||
|
"""
|
||||||
|
GET /forget/captcha?email=<email>
|
||||||
|
- Generate an image captcha and cache it in Redis under key captcha:{email} with TTL = 60 seconds.
|
||||||
|
- Returns the captcha as a JPEG image.
|
||||||
|
"""
|
||||||
|
if not email:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.ARGUMENT_ERROR, message="email is required")
|
||||||
|
|
||||||
|
users = UserService.query(email=email)
|
||||||
|
if not users:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.DATA_ERROR, message="invalid email")
|
||||||
|
|
||||||
|
# Generate captcha text
|
||||||
|
allowed = string.ascii_uppercase + string.digits
|
||||||
|
captcha_text = "".join(secrets.choice(allowed) for _ in range(OTP_LENGTH))
|
||||||
|
REDIS_CONN.set(captcha_key(email), captcha_text, 60) # Valid for 60 seconds
|
||||||
|
|
||||||
|
from captcha.image import ImageCaptcha
|
||||||
|
image = ImageCaptcha(width=300, height=120, font_sizes=[50, 60, 70])
|
||||||
|
img_bytes = image.generate(captcha_text).read()
|
||||||
|
|
||||||
|
return Response(content=img_bytes, media_type="image/JPEG")
|
||||||
|
|
||||||
|
@router.post("/forget/otp")
|
||||||
|
async def forget_send_otp(request: ForgetOtpRequest):
|
||||||
|
"""
|
||||||
|
POST /forget/otp
|
||||||
|
- Verify the image captcha stored at captcha:{email} (case-insensitive).
|
||||||
|
- On success, generate an email OTP (A–Z with length = OTP_LENGTH), store hash + salt (and timestamp) in Redis with TTL, reset attempts and cooldown, and send the OTP via email.
|
||||||
|
"""
|
||||||
|
email = request.email or ""
|
||||||
|
captcha = (request.captcha or "").strip()
|
||||||
|
|
||||||
|
if not email or not captcha:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.ARGUMENT_ERROR, message="email and captcha required")
|
||||||
|
|
||||||
|
users = UserService.query(email=email)
|
||||||
|
if not users:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.DATA_ERROR, message="invalid email")
|
||||||
|
|
||||||
|
stored_captcha = REDIS_CONN.get(captcha_key(email))
|
||||||
|
if not stored_captcha:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.NOT_EFFECTIVE, message="invalid or expired captcha")
|
||||||
|
if (stored_captcha or "").strip().lower() != captcha.lower():
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.AUTHENTICATION_ERROR, message="invalid or expired captcha")
|
||||||
|
|
||||||
|
# Delete captcha to prevent reuse
|
||||||
|
REDIS_CONN.delete(captcha_key(email))
|
||||||
|
|
||||||
|
k_code, k_attempts, k_last, k_lock = otp_keys(email)
|
||||||
|
now = int(time.time())
|
||||||
|
last_ts = REDIS_CONN.get(k_last)
|
||||||
|
if last_ts:
|
||||||
|
try:
|
||||||
|
elapsed = now - int(last_ts)
|
||||||
|
except Exception:
|
||||||
|
elapsed = RESEND_COOLDOWN_SECONDS
|
||||||
|
remaining = RESEND_COOLDOWN_SECONDS - elapsed
|
||||||
|
if remaining > 0:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.NOT_EFFECTIVE, message=f"you still have to wait {remaining} seconds")
|
||||||
|
|
||||||
|
# Generate OTP (uppercase letters only) and store hashed
|
||||||
|
otp = "".join(secrets.choice(string.ascii_uppercase) for _ in range(OTP_LENGTH))
|
||||||
|
salt = os.urandom(16)
|
||||||
|
code_hash = hash_code(otp, salt)
|
||||||
|
REDIS_CONN.set(k_code, f"{code_hash}:{salt.hex()}", OTP_TTL_SECONDS)
|
||||||
|
REDIS_CONN.set(k_attempts, 0, OTP_TTL_SECONDS)
|
||||||
|
REDIS_CONN.set(k_last, now, OTP_TTL_SECONDS)
|
||||||
|
REDIS_CONN.delete(k_lock)
|
||||||
|
|
||||||
|
ttl_min = OTP_TTL_SECONDS // 60
|
||||||
|
|
||||||
|
if not smtp_mail_server:
|
||||||
|
logging.warning("SMTP mail server not initialized; skip sending email.")
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
send_email_html(
|
||||||
|
subject="Your Password Reset Code",
|
||||||
|
to_email=email,
|
||||||
|
template_key="reset_code",
|
||||||
|
code=otp,
|
||||||
|
ttl_min=ttl_min,
|
||||||
|
)
|
||||||
|
except Exception:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.SERVER_ERROR, message="failed to send email")
|
||||||
|
|
||||||
|
return get_json_result(data=True, code=settings.RetCode.SUCCESS, message="verification passed, email sent")
|
||||||
|
|
||||||
|
@router.post("/forget")
|
||||||
|
async def forget(request: ForgetPasswordRequest):
|
||||||
|
"""
|
||||||
|
POST: Verify email + OTP and reset password, then log the user in.
|
||||||
|
Request JSON: { email, otp, new_password, confirm_new_password }
|
||||||
|
"""
|
||||||
|
email = request.email or ""
|
||||||
|
otp = (request.otp or "").strip()
|
||||||
|
new_pwd = request.new_password
|
||||||
|
new_pwd2 = request.confirm_new_password
|
||||||
|
|
||||||
|
if not all([email, otp, new_pwd, new_pwd2]):
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.ARGUMENT_ERROR, message="email, otp and passwords are required")
|
||||||
|
|
||||||
|
# For reset, passwords are provided as-is (no decrypt needed)
|
||||||
|
if new_pwd != new_pwd2:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.ARGUMENT_ERROR, message="passwords do not match")
|
||||||
|
|
||||||
|
users = UserService.query(email=email)
|
||||||
|
if not users:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.DATA_ERROR, message="invalid email")
|
||||||
|
|
||||||
|
user = users[0]
|
||||||
|
# Verify OTP from Redis
|
||||||
|
k_code, k_attempts, k_last, k_lock = otp_keys(email)
|
||||||
|
if REDIS_CONN.get(k_lock):
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.NOT_EFFECTIVE, message="too many attempts, try later")
|
||||||
|
|
||||||
|
stored = REDIS_CONN.get(k_code)
|
||||||
|
if not stored:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.NOT_EFFECTIVE, message="expired otp")
|
||||||
|
|
||||||
|
try:
|
||||||
|
stored_hash, salt_hex = str(stored).split(":", 1)
|
||||||
|
salt = bytes.fromhex(salt_hex)
|
||||||
|
except Exception:
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.EXCEPTION_ERROR, message="otp storage corrupted")
|
||||||
|
|
||||||
|
# Case-insensitive verification: OTP generated uppercase
|
||||||
|
calc = hash_code(otp.upper(), salt)
|
||||||
|
if calc != stored_hash:
|
||||||
|
# bump attempts
|
||||||
|
try:
|
||||||
|
attempts = int(REDIS_CONN.get(k_attempts) or 0) + 1
|
||||||
|
except Exception:
|
||||||
|
attempts = 1
|
||||||
|
REDIS_CONN.set(k_attempts, attempts, OTP_TTL_SECONDS)
|
||||||
|
if attempts >= ATTEMPT_LIMIT:
|
||||||
|
REDIS_CONN.set(k_lock, int(time.time()), ATTEMPT_LOCK_SECONDS)
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.AUTHENTICATION_ERROR, message="expired otp")
|
||||||
|
|
||||||
|
# Success: consume OTP and reset password
|
||||||
|
REDIS_CONN.delete(k_code)
|
||||||
|
REDIS_CONN.delete(k_attempts)
|
||||||
|
REDIS_CONN.delete(k_last)
|
||||||
|
REDIS_CONN.delete(k_lock)
|
||||||
|
|
||||||
|
try:
|
||||||
|
UserService.update_user_password(user.id, new_pwd)
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception(e)
|
||||||
|
return get_json_result(data=False, code=settings.RetCode.EXCEPTION_ERROR, message="failed to reset password")
|
||||||
|
|
||||||
|
# Auto login (reuse login flow)
|
||||||
|
user.access_token = get_uuid()
|
||||||
|
user.update_time = (current_timestamp(),)
|
||||||
|
user.update_date = (datetime_format(datetime.now()),)
|
||||||
|
user.save()
|
||||||
|
msg = "Password reset successful. Logged in."
|
||||||
|
return construct_response(data=user.to_json(), auth=user.get_id(), message=msg)
|
||||||
|
|||||||
@@ -18,6 +18,7 @@ from datetime import datetime
|
|||||||
import logging
|
import logging
|
||||||
|
|
||||||
import peewee
|
import peewee
|
||||||
|
from peewee import fn
|
||||||
from werkzeug.security import generate_password_hash, check_password_hash
|
from werkzeug.security import generate_password_hash, check_password_hash
|
||||||
|
|
||||||
from api.db import UserTenantRole
|
from api.db import UserTenantRole
|
||||||
@@ -93,8 +94,15 @@ class UserService(CommonService):
|
|||||||
Returns:
|
Returns:
|
||||||
User object if authentication successful, None otherwise.
|
User object if authentication successful, None otherwise.
|
||||||
"""
|
"""
|
||||||
user = cls.model.select().where((cls.model.email == email),
|
normalized_email = (email or "").strip().lower()
|
||||||
(cls.model.status == StatusEnum.VALID.value)).first()
|
user = (
|
||||||
|
cls.model.select()
|
||||||
|
.where(
|
||||||
|
fn.Lower(cls.model.email) == normalized_email,
|
||||||
|
cls.model.status == StatusEnum.VALID.value
|
||||||
|
)
|
||||||
|
.first()
|
||||||
|
)
|
||||||
if user and check_password_hash(str(user.password), password):
|
if user and check_password_hash(str(user.password), password):
|
||||||
return user
|
return user
|
||||||
else:
|
else:
|
||||||
@@ -106,6 +114,16 @@ class UserService(CommonService):
|
|||||||
users = cls.model.select().where((cls.model.email == email))
|
users = cls.model.select().where((cls.model.email == email))
|
||||||
return list(users)
|
return list(users)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
@DB.connection_context()
|
||||||
|
def query_user_by_email_insensitive(cls, email):
|
||||||
|
normalized_email = (email or "").strip().lower()
|
||||||
|
users = (
|
||||||
|
cls.model.select()
|
||||||
|
.where(fn.Lower(cls.model.email) == normalized_email)
|
||||||
|
)
|
||||||
|
return list(users)
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
@DB.connection_context()
|
@DB.connection_context()
|
||||||
def save(cls, **kwargs):
|
def save(cls, **kwargs):
|
||||||
|
|||||||
@@ -8,6 +8,10 @@ minio:
|
|||||||
user: 'rag_flow'
|
user: 'rag_flow'
|
||||||
password: 'infini_rag_flow'
|
password: 'infini_rag_flow'
|
||||||
host: 'localhost:9000'
|
host: 'localhost:9000'
|
||||||
|
es:
|
||||||
|
hosts: 'http://localhost:1200'
|
||||||
|
username: 'elastic'
|
||||||
|
password: 'infini_rag_flow'
|
||||||
os:
|
os:
|
||||||
hosts: 'http://localhost:1201'
|
hosts: 'http://localhost:1201'
|
||||||
username: 'admin'
|
username: 'admin'
|
||||||
|
|||||||
122
deepdoc/README.md
Normal file
122
deepdoc/README.md
Normal file
@@ -0,0 +1,122 @@
|
|||||||
|
English | [简体中文](./README_zh.md)
|
||||||
|
|
||||||
|
# *Deep*Doc
|
||||||
|
|
||||||
|
- [1. Introduction](#1)
|
||||||
|
- [2. Vision](#2)
|
||||||
|
- [3. Parser](#3)
|
||||||
|
|
||||||
|
<a name="1"></a>
|
||||||
|
## 1. Introduction
|
||||||
|
|
||||||
|
With a bunch of documents from various domains with various formats and along with diverse retrieval requirements,
|
||||||
|
an accurate analysis becomes a very challenge task. *Deep*Doc is born for that purpose.
|
||||||
|
There are 2 parts in *Deep*Doc so far: vision and parser.
|
||||||
|
You can run the flowing test programs if you're interested in our results of OCR, layout recognition and TSR.
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_ocr.py -h
|
||||||
|
usage: t_ocr.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR]
|
||||||
|
|
||||||
|
options:
|
||||||
|
-h, --help show this help message and exit
|
||||||
|
--inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
|
||||||
|
--output_dir OUTPUT_DIR
|
||||||
|
Directory where to store the output images. Default: './ocr_outputs'
|
||||||
|
```
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_recognizer.py -h
|
||||||
|
usage: t_recognizer.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR] [--threshold THRESHOLD] [--mode {layout,tsr}]
|
||||||
|
|
||||||
|
options:
|
||||||
|
-h, --help show this help message and exit
|
||||||
|
--inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
|
||||||
|
--output_dir OUTPUT_DIR
|
||||||
|
Directory where to store the output images. Default: './layouts_outputs'
|
||||||
|
--threshold THRESHOLD
|
||||||
|
A threshold to filter out detections. Default: 0.5
|
||||||
|
--mode {layout,tsr} Task mode: layout recognition or table structure recognition
|
||||||
|
```
|
||||||
|
|
||||||
|
Our models are served on HuggingFace. If you have trouble downloading HuggingFace models, this might help!!
|
||||||
|
```bash
|
||||||
|
export HF_ENDPOINT=https://hf-mirror.com
|
||||||
|
```
|
||||||
|
|
||||||
|
<a name="2"></a>
|
||||||
|
## 2. Vision
|
||||||
|
|
||||||
|
We use vision information to resolve problems as human being.
|
||||||
|
- OCR. Since a lot of documents presented as images or at least be able to transform to image,
|
||||||
|
OCR is a very essential and fundamental or even universal solution for text extraction.
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_ocr.py --inputs=path_to_images_or_pdfs --output_dir=path_to_store_result
|
||||||
|
```
|
||||||
|
The inputs could be directory to images or PDF, or a image or PDF.
|
||||||
|
You can look into the folder 'path_to_store_result' where has images which demonstrate the positions of results,
|
||||||
|
txt files which contain the OCR text.
|
||||||
|
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||||
|
<img src="https://github.com/infiniflow/ragflow/assets/12318111/f25bee3d-aaf7-4102-baf5-d5208361d110" width="900"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
- Layout recognition. Documents from different domain may have various layouts,
|
||||||
|
like, newspaper, magazine, book and résumé are distinct in terms of layout.
|
||||||
|
Only when machine have an accurate layout analysis, it can decide if these text parts are successive or not,
|
||||||
|
or this part needs Table Structure Recognition(TSR) to process, or this part is a figure and described with this caption.
|
||||||
|
We have 10 basic layout components which covers most cases:
|
||||||
|
- Text
|
||||||
|
- Title
|
||||||
|
- Figure
|
||||||
|
- Figure caption
|
||||||
|
- Table
|
||||||
|
- Table caption
|
||||||
|
- Header
|
||||||
|
- Footer
|
||||||
|
- Reference
|
||||||
|
- Equation
|
||||||
|
|
||||||
|
Have a try on the following command to see the layout detection results.
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_recognizer.py --inputs=path_to_images_or_pdfs --threshold=0.2 --mode=layout --output_dir=path_to_store_result
|
||||||
|
```
|
||||||
|
The inputs could be directory to images or PDF, or a image or PDF.
|
||||||
|
You can look into the folder 'path_to_store_result' where has images which demonstrate the detection results as following:
|
||||||
|
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||||
|
<img src="https://github.com/infiniflow/ragflow/assets/12318111/07e0f625-9b28-43d0-9fbb-5bf586cd286f" width="1000"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
- Table Structure Recognition(TSR). Data table is a frequently used structure to present data including numbers or text.
|
||||||
|
And the structure of a table might be very complex, like hierarchy headers, spanning cells and projected row headers.
|
||||||
|
Along with TSR, we also reassemble the content into sentences which could be well comprehended by LLM.
|
||||||
|
We have five labels for TSR task:
|
||||||
|
- Column
|
||||||
|
- Row
|
||||||
|
- Column header
|
||||||
|
- Projected row header
|
||||||
|
- Spanning cell
|
||||||
|
|
||||||
|
Have a try on the following command to see the layout detection results.
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_recognizer.py --inputs=path_to_images_or_pdfs --threshold=0.2 --mode=tsr --output_dir=path_to_store_result
|
||||||
|
```
|
||||||
|
The inputs could be directory to images or PDF, or a image or PDF.
|
||||||
|
You can look into the folder 'path_to_store_result' where has both images and html pages which demonstrate the detection results as following:
|
||||||
|
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||||
|
<img src="https://github.com/infiniflow/ragflow/assets/12318111/cb24e81b-f2ba-49f3-ac09-883d75606f4c" width="1000"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<a name="3"></a>
|
||||||
|
## 3. Parser
|
||||||
|
|
||||||
|
Four kinds of document formats as PDF, DOCX, EXCEL and PPT have their corresponding parser.
|
||||||
|
The most complex one is PDF parser since PDF's flexibility. The output of PDF parser includes:
|
||||||
|
- Text chunks with their own positions in PDF(page number and rectangular positions).
|
||||||
|
- Tables with cropped image from the PDF, and contents which has already translated into natural language sentences.
|
||||||
|
- Figures with caption and text in the figures.
|
||||||
|
|
||||||
|
### Résumé
|
||||||
|
|
||||||
|
The résumé is a very complicated kind of document. A résumé which is composed of unstructured text
|
||||||
|
with various layouts could be resolved into structured data composed of nearly a hundred of fields.
|
||||||
|
We haven't opened the parser yet, as we open the processing method after parsing procedure.
|
||||||
|
|
||||||
|
|
||||||
116
deepdoc/README_zh.md
Normal file
116
deepdoc/README_zh.md
Normal file
@@ -0,0 +1,116 @@
|
|||||||
|
[English](./README.md) | 简体中文
|
||||||
|
|
||||||
|
# *Deep*Doc
|
||||||
|
|
||||||
|
- [*Deep*Doc](#deepdoc)
|
||||||
|
- [1. 介绍](#1-介绍)
|
||||||
|
- [2. 视觉处理](#2-视觉处理)
|
||||||
|
- [3. 解析器](#3-解析器)
|
||||||
|
- [简历](#简历)
|
||||||
|
|
||||||
|
<a name="1"></a>
|
||||||
|
## 1. 介绍
|
||||||
|
|
||||||
|
对于来自不同领域、具有不同格式和不同检索要求的大量文档,准确的分析成为一项极具挑战性的任务。*Deep*Doc 就是为了这个目的而诞生的。到目前为止,*Deep*Doc 中有两个组成部分:视觉处理和解析器。如果您对我们的OCR、布局识别和TSR结果感兴趣,您可以运行下面的测试程序。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_ocr.py -h
|
||||||
|
usage: t_ocr.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR]
|
||||||
|
|
||||||
|
options:
|
||||||
|
-h, --help show this help message and exit
|
||||||
|
--inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
|
||||||
|
--output_dir OUTPUT_DIR
|
||||||
|
Directory where to store the output images. Default: './ocr_outputs'
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_recognizer.py -h
|
||||||
|
usage: t_recognizer.py [-h] --inputs INPUTS [--output_dir OUTPUT_DIR] [--threshold THRESHOLD] [--mode {layout,tsr}]
|
||||||
|
|
||||||
|
options:
|
||||||
|
-h, --help show this help message and exit
|
||||||
|
--inputs INPUTS Directory where to store images or PDFs, or a file path to a single image or PDF
|
||||||
|
--output_dir OUTPUT_DIR
|
||||||
|
Directory where to store the output images. Default: './layouts_outputs'
|
||||||
|
--threshold THRESHOLD
|
||||||
|
A threshold to filter out detections. Default: 0.5
|
||||||
|
--mode {layout,tsr} Task mode: layout recognition or table structure recognition
|
||||||
|
```
|
||||||
|
|
||||||
|
HuggingFace为我们的模型提供服务。如果你在下载HuggingFace模型时遇到问题,这可能会有所帮助!!
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export HF_ENDPOINT=https://hf-mirror.com
|
||||||
|
```
|
||||||
|
|
||||||
|
<a name="2"></a>
|
||||||
|
## 2. 视觉处理
|
||||||
|
|
||||||
|
作为人类,我们使用视觉信息来解决问题。
|
||||||
|
|
||||||
|
- **OCR(Optical Character Recognition,光学字符识别)**。由于许多文档都是以图像形式呈现的,或者至少能够转换为图像,因此OCR是文本提取的一个非常重要、基本,甚至通用的解决方案。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_ocr.py --inputs=path_to_images_or_pdfs --output_dir=path_to_store_result
|
||||||
|
```
|
||||||
|
|
||||||
|
输入可以是图像或PDF的目录,或者单个图像、PDF文件。您可以查看文件夹 `path_to_store_result` ,其中有演示结果位置的图像,以及包含OCR文本的txt文件。
|
||||||
|
|
||||||
|
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||||
|
<img src="https://github.com/infiniflow/ragflow/assets/12318111/f25bee3d-aaf7-4102-baf5-d5208361d110" width="900"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
- 布局识别(Layout recognition)。来自不同领域的文件可能有不同的布局,如报纸、杂志、书籍和简历在布局方面是不同的。只有当机器有准确的布局分析时,它才能决定这些文本部分是连续的还是不连续的,或者这个部分需要表结构识别(Table Structure Recognition,TSR)来处理,或者这个部件是一个图形并用这个标题来描述。我们有10个基本布局组件,涵盖了大多数情况:
|
||||||
|
- 文本
|
||||||
|
- 标题
|
||||||
|
- 配图
|
||||||
|
- 配图标题
|
||||||
|
- 表格
|
||||||
|
- 表格标题
|
||||||
|
- 页头
|
||||||
|
- 页尾
|
||||||
|
- 参考引用
|
||||||
|
- 公式
|
||||||
|
|
||||||
|
请尝试以下命令以查看布局检测结果。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_recognizer.py --inputs=path_to_images_or_pdfs --threshold=0.2 --mode=layout --output_dir=path_to_store_result
|
||||||
|
```
|
||||||
|
|
||||||
|
输入可以是图像或PDF的目录,或者单个图像、PDF文件。您可以查看文件夹 `path_to_store_result` ,其中有显示检测结果的图像,如下所示:
|
||||||
|
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||||
|
<img src="https://github.com/infiniflow/ragflow/assets/12318111/07e0f625-9b28-43d0-9fbb-5bf586cd286f" width="1000"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
- **TSR(Table Structure Recognition,表结构识别)**。数据表是一种常用的结构,用于表示包括数字或文本在内的数据。表的结构可能非常复杂,比如层次结构标题、跨单元格和投影行标题。除了TSR,我们还将内容重新组合成LLM可以很好理解的句子。TSR任务有五个标签:
|
||||||
|
- 列
|
||||||
|
- 行
|
||||||
|
- 列标题
|
||||||
|
- 行标题
|
||||||
|
- 合并单元格
|
||||||
|
|
||||||
|
请尝试以下命令以查看布局检测结果。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python deepdoc/vision/t_recognizer.py --inputs=path_to_images_or_pdfs --threshold=0.2 --mode=tsr --output_dir=path_to_store_result
|
||||||
|
```
|
||||||
|
|
||||||
|
输入可以是图像或PDF的目录,或者单个图像、PDF文件。您可以查看文件夹 `path_to_store_result` ,其中包含图像和html页面,这些页面展示了以下检测结果:
|
||||||
|
|
||||||
|
<div align="center" style="margin-top:20px;margin-bottom:20px;">
|
||||||
|
<img src="https://github.com/infiniflow/ragflow/assets/12318111/cb24e81b-f2ba-49f3-ac09-883d75606f4c" width="1000"/>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<a name="3"></a>
|
||||||
|
## 3. 解析器
|
||||||
|
|
||||||
|
PDF、DOCX、EXCEL和PPT四种文档格式都有相应的解析器。最复杂的是PDF解析器,因为PDF具有灵活性。PDF解析器的输出包括:
|
||||||
|
- 在PDF中有自己位置的文本块(页码和矩形位置)。
|
||||||
|
- 带有PDF裁剪图像的表格,以及已经翻译成自然语言句子的内容。
|
||||||
|
- 图中带标题和文字的图。
|
||||||
|
|
||||||
|
### 简历
|
||||||
|
|
||||||
|
简历是一种非常复杂的文档。由各种格式的非结构化文本构成的简历可以被解析为包含近百个字段的结构化数据。我们还没有启用解析器,因为在解析过程之后才会启动处理方法。
|
||||||
18
deepdoc/__init__.py
Normal file
18
deepdoc/__init__.py
Normal file
@@ -0,0 +1,18 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from beartype.claw import beartype_this_package
|
||||||
|
beartype_this_package()
|
||||||
40
deepdoc/parser/__init__.py
Normal file
40
deepdoc/parser/__init__.py
Normal file
@@ -0,0 +1,40 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from .docx_parser import RAGFlowDocxParser as DocxParser
|
||||||
|
from .excel_parser import RAGFlowExcelParser as ExcelParser
|
||||||
|
from .html_parser import RAGFlowHtmlParser as HtmlParser
|
||||||
|
from .json_parser import RAGFlowJsonParser as JsonParser
|
||||||
|
from .markdown_parser import MarkdownElementExtractor
|
||||||
|
from .markdown_parser import RAGFlowMarkdownParser as MarkdownParser
|
||||||
|
from .pdf_parser import PlainParser
|
||||||
|
from .pdf_parser import RAGFlowPdfParser as PdfParser
|
||||||
|
from .ppt_parser import RAGFlowPptParser as PptParser
|
||||||
|
from .txt_parser import RAGFlowTxtParser as TxtParser
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"PdfParser",
|
||||||
|
"PlainParser",
|
||||||
|
"DocxParser",
|
||||||
|
"ExcelParser",
|
||||||
|
"PptParser",
|
||||||
|
"HtmlParser",
|
||||||
|
"JsonParser",
|
||||||
|
"MarkdownParser",
|
||||||
|
"TxtParser",
|
||||||
|
"MarkdownElementExtractor",
|
||||||
|
]
|
||||||
|
|
||||||
139
deepdoc/parser/docx_parser.py
Normal file
139
deepdoc/parser/docx_parser.py
Normal file
@@ -0,0 +1,139 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from docx import Document
|
||||||
|
import re
|
||||||
|
import pandas as pd
|
||||||
|
from collections import Counter
|
||||||
|
from rag.nlp import rag_tokenizer
|
||||||
|
from io import BytesIO
|
||||||
|
|
||||||
|
|
||||||
|
class RAGFlowDocxParser:
|
||||||
|
|
||||||
|
def __extract_table_content(self, tb):
|
||||||
|
df = []
|
||||||
|
for row in tb.rows:
|
||||||
|
df.append([c.text for c in row.cells])
|
||||||
|
return self.__compose_table_content(pd.DataFrame(df))
|
||||||
|
|
||||||
|
def __compose_table_content(self, df):
|
||||||
|
|
||||||
|
def blockType(b):
|
||||||
|
pattern = [
|
||||||
|
("^(20|19)[0-9]{2}[年/-][0-9]{1,2}[月/-][0-9]{1,2}日*$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}年$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}[年/-][0-9]{1,2}月*$", "Dt"),
|
||||||
|
("^[0-9]{1,2}[月/-][0-9]{1,2}日*$", "Dt"),
|
||||||
|
(r"^第*[一二三四1-4]季度$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}年*[一二三四1-4]季度$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}[ABCDE]$", "DT"),
|
||||||
|
("^[0-9.,+%/ -]+$", "Nu"),
|
||||||
|
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
||||||
|
(r"^[A-Z]*[a-z' -]+$", "En"),
|
||||||
|
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
||||||
|
(r"^.{1}$", "Sg")
|
||||||
|
]
|
||||||
|
for p, n in pattern:
|
||||||
|
if re.search(p, b):
|
||||||
|
return n
|
||||||
|
tks = [t for t in rag_tokenizer.tokenize(b).split() if len(t) > 1]
|
||||||
|
if len(tks) > 3:
|
||||||
|
if len(tks) < 12:
|
||||||
|
return "Tx"
|
||||||
|
else:
|
||||||
|
return "Lx"
|
||||||
|
|
||||||
|
if len(tks) == 1 and rag_tokenizer.tag(tks[0]) == "nr":
|
||||||
|
return "Nr"
|
||||||
|
|
||||||
|
return "Ot"
|
||||||
|
|
||||||
|
if len(df) < 2:
|
||||||
|
return []
|
||||||
|
max_type = Counter([blockType(str(df.iloc[i, j])) for i in range(
|
||||||
|
1, len(df)) for j in range(len(df.iloc[i, :]))])
|
||||||
|
max_type = max(max_type.items(), key=lambda x: x[1])[0]
|
||||||
|
|
||||||
|
colnm = len(df.iloc[0, :])
|
||||||
|
hdrows = [0] # header is not necessarily appear in the first line
|
||||||
|
if max_type == "Nu":
|
||||||
|
for r in range(1, len(df)):
|
||||||
|
tys = Counter([blockType(str(df.iloc[r, j]))
|
||||||
|
for j in range(len(df.iloc[r, :]))])
|
||||||
|
tys = max(tys.items(), key=lambda x: x[1])[0]
|
||||||
|
if tys != max_type:
|
||||||
|
hdrows.append(r)
|
||||||
|
|
||||||
|
lines = []
|
||||||
|
for i in range(1, len(df)):
|
||||||
|
if i in hdrows:
|
||||||
|
continue
|
||||||
|
hr = [r - i for r in hdrows]
|
||||||
|
hr = [r for r in hr if r < 0]
|
||||||
|
t = len(hr) - 1
|
||||||
|
while t > 0:
|
||||||
|
if hr[t] - hr[t - 1] > 1:
|
||||||
|
hr = hr[t:]
|
||||||
|
break
|
||||||
|
t -= 1
|
||||||
|
headers = []
|
||||||
|
for j in range(len(df.iloc[i, :])):
|
||||||
|
t = []
|
||||||
|
for h in hr:
|
||||||
|
x = str(df.iloc[i + h, j]).strip()
|
||||||
|
if x in t:
|
||||||
|
continue
|
||||||
|
t.append(x)
|
||||||
|
t = ",".join(t)
|
||||||
|
if t:
|
||||||
|
t += ": "
|
||||||
|
headers.append(t)
|
||||||
|
cells = []
|
||||||
|
for j in range(len(df.iloc[i, :])):
|
||||||
|
if not str(df.iloc[i, j]):
|
||||||
|
continue
|
||||||
|
cells.append(headers[j] + str(df.iloc[i, j]))
|
||||||
|
lines.append(";".join(cells))
|
||||||
|
|
||||||
|
if colnm > 3:
|
||||||
|
return lines
|
||||||
|
return ["\n".join(lines)]
|
||||||
|
|
||||||
|
def __call__(self, fnm, from_page=0, to_page=100000000):
|
||||||
|
self.doc = Document(fnm) if isinstance(
|
||||||
|
fnm, str) else Document(BytesIO(fnm))
|
||||||
|
pn = 0 # parsed page
|
||||||
|
secs = [] # parsed contents
|
||||||
|
for p in self.doc.paragraphs:
|
||||||
|
if pn > to_page:
|
||||||
|
break
|
||||||
|
|
||||||
|
runs_within_single_paragraph = [] # save runs within the range of pages
|
||||||
|
for run in p.runs:
|
||||||
|
if pn > to_page:
|
||||||
|
break
|
||||||
|
if from_page <= pn < to_page and p.text.strip():
|
||||||
|
runs_within_single_paragraph.append(run.text) # append run.text first
|
||||||
|
|
||||||
|
# wrap page break checker into a static method
|
||||||
|
if 'lastRenderedPageBreak' in run._element.xml:
|
||||||
|
pn += 1
|
||||||
|
|
||||||
|
secs.append(("".join(runs_within_single_paragraph), p.style.name if hasattr(p.style, 'name') else '')) # then concat run.text as part of the paragraph
|
||||||
|
|
||||||
|
tbls = [self.__extract_table_content(tb) for tb in self.doc.tables]
|
||||||
|
return secs, tbls
|
||||||
209
deepdoc/parser/excel_parser.py
Normal file
209
deepdoc/parser/excel_parser.py
Normal file
@@ -0,0 +1,209 @@
|
|||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import re
|
||||||
|
import sys
|
||||||
|
from io import BytesIO
|
||||||
|
|
||||||
|
import pandas as pd
|
||||||
|
from openpyxl import Workbook, load_workbook
|
||||||
|
|
||||||
|
from rag.nlp import find_codec
|
||||||
|
|
||||||
|
# copied from `/openpyxl/cell/cell.py`
|
||||||
|
ILLEGAL_CHARACTERS_RE = re.compile(r"[\000-\010]|[\013-\014]|[\016-\037]")
|
||||||
|
|
||||||
|
|
||||||
|
class RAGFlowExcelParser:
|
||||||
|
@staticmethod
|
||||||
|
def _load_excel_to_workbook(file_like_object):
|
||||||
|
if isinstance(file_like_object, bytes):
|
||||||
|
file_like_object = BytesIO(file_like_object)
|
||||||
|
|
||||||
|
# Read first 4 bytes to determine file type
|
||||||
|
file_like_object.seek(0)
|
||||||
|
file_head = file_like_object.read(4)
|
||||||
|
file_like_object.seek(0)
|
||||||
|
|
||||||
|
if not (file_head.startswith(b"PK\x03\x04") or file_head.startswith(b"\xd0\xcf\x11\xe0")):
|
||||||
|
logging.info("Not an Excel file, converting CSV to Excel Workbook")
|
||||||
|
|
||||||
|
try:
|
||||||
|
file_like_object.seek(0)
|
||||||
|
df = pd.read_csv(file_like_object)
|
||||||
|
return RAGFlowExcelParser._dataframe_to_workbook(df)
|
||||||
|
|
||||||
|
except Exception as e_csv:
|
||||||
|
raise Exception(f"Failed to parse CSV and convert to Excel Workbook: {e_csv}")
|
||||||
|
|
||||||
|
try:
|
||||||
|
return load_workbook(file_like_object, data_only=True)
|
||||||
|
except Exception as e:
|
||||||
|
logging.info(f"openpyxl load error: {e}, try pandas instead")
|
||||||
|
try:
|
||||||
|
file_like_object.seek(0)
|
||||||
|
try:
|
||||||
|
dfs = pd.read_excel(file_like_object, sheet_name=None)
|
||||||
|
return RAGFlowExcelParser._dataframe_to_workbook(dfs)
|
||||||
|
except Exception as ex:
|
||||||
|
logging.info(f"pandas with default engine load error: {ex}, try calamine instead")
|
||||||
|
file_like_object.seek(0)
|
||||||
|
df = pd.read_excel(file_like_object, engine="calamine")
|
||||||
|
return RAGFlowExcelParser._dataframe_to_workbook(df)
|
||||||
|
except Exception as e_pandas:
|
||||||
|
raise Exception(f"pandas.read_excel error: {e_pandas}, original openpyxl error: {e}")
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _clean_dataframe(df: pd.DataFrame):
|
||||||
|
def clean_string(s):
|
||||||
|
if isinstance(s, str):
|
||||||
|
return ILLEGAL_CHARACTERS_RE.sub(" ", s)
|
||||||
|
return s
|
||||||
|
|
||||||
|
return df.apply(lambda col: col.map(clean_string))
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _dataframe_to_workbook(df):
|
||||||
|
# if contains multiple sheets use _dataframes_to_workbook
|
||||||
|
if isinstance(df, dict) and len(df) > 1:
|
||||||
|
return RAGFlowExcelParser._dataframes_to_workbook(df)
|
||||||
|
|
||||||
|
df = RAGFlowExcelParser._clean_dataframe(df)
|
||||||
|
wb = Workbook()
|
||||||
|
ws = wb.active
|
||||||
|
ws.title = "Data"
|
||||||
|
|
||||||
|
for col_num, column_name in enumerate(df.columns, 1):
|
||||||
|
ws.cell(row=1, column=col_num, value=column_name)
|
||||||
|
|
||||||
|
for row_num, row in enumerate(df.values, 2):
|
||||||
|
for col_num, value in enumerate(row, 1):
|
||||||
|
ws.cell(row=row_num, column=col_num, value=value)
|
||||||
|
|
||||||
|
return wb
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _dataframes_to_workbook(dfs: dict):
|
||||||
|
wb = Workbook()
|
||||||
|
default_sheet = wb.active
|
||||||
|
wb.remove(default_sheet)
|
||||||
|
|
||||||
|
for sheet_name, df in dfs.items():
|
||||||
|
df = RAGFlowExcelParser._clean_dataframe(df)
|
||||||
|
ws = wb.create_sheet(title=sheet_name)
|
||||||
|
for col_num, column_name in enumerate(df.columns, 1):
|
||||||
|
ws.cell(row=1, column=col_num, value=column_name)
|
||||||
|
for row_num, row in enumerate(df.values, 2):
|
||||||
|
for col_num, value in enumerate(row, 1):
|
||||||
|
ws.cell(row=row_num, column=col_num, value=value)
|
||||||
|
return wb
|
||||||
|
|
||||||
|
def html(self, fnm, chunk_rows=256):
|
||||||
|
from html import escape
|
||||||
|
|
||||||
|
file_like_object = BytesIO(fnm) if not isinstance(fnm, str) else fnm
|
||||||
|
wb = RAGFlowExcelParser._load_excel_to_workbook(file_like_object)
|
||||||
|
tb_chunks = []
|
||||||
|
|
||||||
|
def _fmt(v):
|
||||||
|
if v is None:
|
||||||
|
return ""
|
||||||
|
return str(v).strip()
|
||||||
|
|
||||||
|
for sheetname in wb.sheetnames:
|
||||||
|
ws = wb[sheetname]
|
||||||
|
rows = list(ws.rows)
|
||||||
|
if not rows:
|
||||||
|
continue
|
||||||
|
|
||||||
|
tb_rows_0 = "<tr>"
|
||||||
|
for t in list(rows[0]):
|
||||||
|
tb_rows_0 += f"<th>{escape(_fmt(t.value))}</th>"
|
||||||
|
tb_rows_0 += "</tr>"
|
||||||
|
|
||||||
|
for chunk_i in range((len(rows) - 1) // chunk_rows + 1):
|
||||||
|
tb = ""
|
||||||
|
tb += f"<table><caption>{sheetname}</caption>"
|
||||||
|
tb += tb_rows_0
|
||||||
|
for r in list(rows[1 + chunk_i * chunk_rows : min(1 + (chunk_i + 1) * chunk_rows, len(rows))]):
|
||||||
|
tb += "<tr>"
|
||||||
|
for i, c in enumerate(r):
|
||||||
|
if c.value is None:
|
||||||
|
tb += "<td></td>"
|
||||||
|
else:
|
||||||
|
tb += f"<td>{escape(_fmt(c.value))}</td>"
|
||||||
|
tb += "</tr>"
|
||||||
|
tb += "</table>\n"
|
||||||
|
tb_chunks.append(tb)
|
||||||
|
|
||||||
|
return tb_chunks
|
||||||
|
|
||||||
|
def markdown(self, fnm):
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
file_like_object = BytesIO(fnm) if not isinstance(fnm, str) else fnm
|
||||||
|
try:
|
||||||
|
file_like_object.seek(0)
|
||||||
|
df = pd.read_excel(file_like_object)
|
||||||
|
except Exception as e:
|
||||||
|
logging.warning(f"Parse spreadsheet error: {e}, trying to interpret as CSV file")
|
||||||
|
file_like_object.seek(0)
|
||||||
|
df = pd.read_csv(file_like_object)
|
||||||
|
df = df.replace(r"^\s*$", "", regex=True)
|
||||||
|
return df.to_markdown(index=False)
|
||||||
|
|
||||||
|
def __call__(self, fnm):
|
||||||
|
file_like_object = BytesIO(fnm) if not isinstance(fnm, str) else fnm
|
||||||
|
wb = RAGFlowExcelParser._load_excel_to_workbook(file_like_object)
|
||||||
|
|
||||||
|
res = []
|
||||||
|
for sheetname in wb.sheetnames:
|
||||||
|
ws = wb[sheetname]
|
||||||
|
rows = list(ws.rows)
|
||||||
|
if not rows:
|
||||||
|
continue
|
||||||
|
ti = list(rows[0])
|
||||||
|
for r in list(rows[1:]):
|
||||||
|
fields = []
|
||||||
|
for i, c in enumerate(r):
|
||||||
|
if not c.value:
|
||||||
|
continue
|
||||||
|
t = str(ti[i].value) if i < len(ti) else ""
|
||||||
|
t += (":" if t else "") + str(c.value)
|
||||||
|
fields.append(t)
|
||||||
|
line = "; ".join(fields)
|
||||||
|
if sheetname.lower().find("sheet") < 0:
|
||||||
|
line += " ——" + sheetname
|
||||||
|
res.append(line)
|
||||||
|
return res
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def row_number(fnm, binary):
|
||||||
|
if fnm.split(".")[-1].lower().find("xls") >= 0:
|
||||||
|
wb = RAGFlowExcelParser._load_excel_to_workbook(BytesIO(binary))
|
||||||
|
total = 0
|
||||||
|
for sheetname in wb.sheetnames:
|
||||||
|
ws = wb[sheetname]
|
||||||
|
total += len(list(ws.rows))
|
||||||
|
return total
|
||||||
|
|
||||||
|
if fnm.split(".")[-1].lower() in ["csv", "txt"]:
|
||||||
|
encoding = find_codec(binary)
|
||||||
|
txt = binary.decode(encoding, errors="ignore")
|
||||||
|
return len(txt.split("\n"))
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
psr = RAGFlowExcelParser()
|
||||||
|
psr(sys.argv[1])
|
||||||
144
deepdoc/parser/figure_parser.py
Normal file
144
deepdoc/parser/figure_parser.py
Normal file
@@ -0,0 +1,144 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
from concurrent.futures import ThreadPoolExecutor, as_completed
|
||||||
|
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
from api.db import LLMType
|
||||||
|
from api.db.services.llm_service import LLMBundle
|
||||||
|
from api.utils.api_utils import timeout
|
||||||
|
from rag.app.picture import vision_llm_chunk as picture_vision_llm_chunk
|
||||||
|
from rag.prompts.generator import vision_llm_figure_describe_prompt
|
||||||
|
|
||||||
|
|
||||||
|
def vision_figure_parser_figure_data_wrapper(figures_data_without_positions):
|
||||||
|
return [
|
||||||
|
(
|
||||||
|
(figure_data[1], [figure_data[0]]),
|
||||||
|
[(0, 0, 0, 0, 0)],
|
||||||
|
)
|
||||||
|
for figure_data in figures_data_without_positions
|
||||||
|
if isinstance(figure_data[1], Image.Image)
|
||||||
|
]
|
||||||
|
|
||||||
|
def vision_figure_parser_docx_wrapper(sections,tbls,callback=None,**kwargs):
|
||||||
|
try:
|
||||||
|
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||||
|
callback(0.7, "Visual model detected. Attempting to enhance figure extraction...")
|
||||||
|
except Exception:
|
||||||
|
vision_model = None
|
||||||
|
if vision_model:
|
||||||
|
figures_data = vision_figure_parser_figure_data_wrapper(sections)
|
||||||
|
try:
|
||||||
|
docx_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data=figures_data, **kwargs)
|
||||||
|
boosted_figures = docx_vision_parser(callback=callback)
|
||||||
|
tbls.extend(boosted_figures)
|
||||||
|
except Exception as e:
|
||||||
|
callback(0.8, f"Visual model error: {e}. Skipping figure parsing enhancement.")
|
||||||
|
return tbls
|
||||||
|
|
||||||
|
def vision_figure_parser_pdf_wrapper(tbls,callback=None,**kwargs):
|
||||||
|
try:
|
||||||
|
vision_model = LLMBundle(kwargs["tenant_id"], LLMType.IMAGE2TEXT)
|
||||||
|
callback(0.7, "Visual model detected. Attempting to enhance figure extraction...")
|
||||||
|
except Exception:
|
||||||
|
vision_model = None
|
||||||
|
if vision_model:
|
||||||
|
def is_figure_item(item):
|
||||||
|
return (
|
||||||
|
isinstance(item[0][0], Image.Image) and
|
||||||
|
isinstance(item[0][1], list)
|
||||||
|
)
|
||||||
|
figures_data = [item for item in tbls if is_figure_item(item)]
|
||||||
|
try:
|
||||||
|
docx_vision_parser = VisionFigureParser(vision_model=vision_model, figures_data=figures_data, **kwargs)
|
||||||
|
boosted_figures = docx_vision_parser(callback=callback)
|
||||||
|
tbls = [item for item in tbls if not is_figure_item(item)]
|
||||||
|
tbls.extend(boosted_figures)
|
||||||
|
except Exception as e:
|
||||||
|
callback(0.8, f"Visual model error: {e}. Skipping figure parsing enhancement.")
|
||||||
|
return tbls
|
||||||
|
|
||||||
|
shared_executor = ThreadPoolExecutor(max_workers=10)
|
||||||
|
|
||||||
|
|
||||||
|
class VisionFigureParser:
|
||||||
|
def __init__(self, vision_model, figures_data, *args, **kwargs):
|
||||||
|
self.vision_model = vision_model
|
||||||
|
self._extract_figures_info(figures_data)
|
||||||
|
assert len(self.figures) == len(self.descriptions)
|
||||||
|
assert not self.positions or (len(self.figures) == len(self.positions))
|
||||||
|
|
||||||
|
def _extract_figures_info(self, figures_data):
|
||||||
|
self.figures = []
|
||||||
|
self.descriptions = []
|
||||||
|
self.positions = []
|
||||||
|
|
||||||
|
for item in figures_data:
|
||||||
|
# position
|
||||||
|
if len(item) == 2 and isinstance(item[0], tuple) and len(item[0]) == 2 and isinstance(item[1], list) and isinstance(item[1][0], tuple) and len(item[1][0]) == 5:
|
||||||
|
img_desc = item[0]
|
||||||
|
assert len(img_desc) == 2 and isinstance(img_desc[0], Image.Image) and isinstance(img_desc[1], list), "Should be (figure, [description])"
|
||||||
|
self.figures.append(img_desc[0])
|
||||||
|
self.descriptions.append(img_desc[1])
|
||||||
|
self.positions.append(item[1])
|
||||||
|
else:
|
||||||
|
assert len(item) == 2 and isinstance(item[0], Image.Image) and isinstance(item[1], list), f"Unexpected form of figure data: get {len(item)=}, {item=}"
|
||||||
|
self.figures.append(item[0])
|
||||||
|
self.descriptions.append(item[1])
|
||||||
|
|
||||||
|
def _assemble(self):
|
||||||
|
self.assembled = []
|
||||||
|
self.has_positions = len(self.positions) != 0
|
||||||
|
for i in range(len(self.figures)):
|
||||||
|
figure = self.figures[i]
|
||||||
|
desc = self.descriptions[i]
|
||||||
|
pos = self.positions[i] if self.has_positions else None
|
||||||
|
|
||||||
|
figure_desc = (figure, desc)
|
||||||
|
|
||||||
|
if pos is not None:
|
||||||
|
self.assembled.append((figure_desc, pos))
|
||||||
|
else:
|
||||||
|
self.assembled.append((figure_desc,))
|
||||||
|
|
||||||
|
return self.assembled
|
||||||
|
|
||||||
|
def __call__(self, **kwargs):
|
||||||
|
callback = kwargs.get("callback", lambda prog, msg: None)
|
||||||
|
|
||||||
|
@timeout(30, 3)
|
||||||
|
def process(figure_idx, figure_binary):
|
||||||
|
description_text = picture_vision_llm_chunk(
|
||||||
|
binary=figure_binary,
|
||||||
|
vision_model=self.vision_model,
|
||||||
|
prompt=vision_llm_figure_describe_prompt(),
|
||||||
|
callback=callback,
|
||||||
|
)
|
||||||
|
return figure_idx, description_text
|
||||||
|
|
||||||
|
futures = []
|
||||||
|
for idx, img_binary in enumerate(self.figures or []):
|
||||||
|
futures.append(shared_executor.submit(process, idx, img_binary))
|
||||||
|
|
||||||
|
for future in as_completed(futures):
|
||||||
|
figure_num, txt = future.result()
|
||||||
|
if txt:
|
||||||
|
self.descriptions[figure_num] = txt + "\n".join(self.descriptions[figure_num])
|
||||||
|
|
||||||
|
self._assemble()
|
||||||
|
|
||||||
|
return self.assembled
|
||||||
214
deepdoc/parser/html_parser.py
Normal file
214
deepdoc/parser/html_parser.py
Normal file
@@ -0,0 +1,214 @@
|
|||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from rag.nlp import find_codec, rag_tokenizer
|
||||||
|
import uuid
|
||||||
|
import chardet
|
||||||
|
from bs4 import BeautifulSoup, NavigableString, Tag, Comment
|
||||||
|
import html
|
||||||
|
|
||||||
|
def get_encoding(file):
|
||||||
|
with open(file,'rb') as f:
|
||||||
|
tmp = chardet.detect(f.read())
|
||||||
|
return tmp['encoding']
|
||||||
|
|
||||||
|
BLOCK_TAGS = [
|
||||||
|
"h1", "h2", "h3", "h4", "h5", "h6",
|
||||||
|
"p", "div", "article", "section", "aside",
|
||||||
|
"ul", "ol", "li",
|
||||||
|
"table", "pre", "code", "blockquote",
|
||||||
|
"figure", "figcaption"
|
||||||
|
]
|
||||||
|
TITLE_TAGS = {"h1": "#", "h2": "##", "h3": "###", "h4": "#####", "h5": "#####", "h6": "######"}
|
||||||
|
|
||||||
|
|
||||||
|
class RAGFlowHtmlParser:
|
||||||
|
def __call__(self, fnm, binary=None, chunk_token_num=512):
|
||||||
|
if binary:
|
||||||
|
encoding = find_codec(binary)
|
||||||
|
txt = binary.decode(encoding, errors="ignore")
|
||||||
|
else:
|
||||||
|
with open(fnm, "r",encoding=get_encoding(fnm)) as f:
|
||||||
|
txt = f.read()
|
||||||
|
return self.parser_txt(txt, chunk_token_num)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parser_txt(cls, txt, chunk_token_num):
|
||||||
|
if not isinstance(txt, str):
|
||||||
|
raise TypeError("txt type should be string!")
|
||||||
|
|
||||||
|
temp_sections = []
|
||||||
|
soup = BeautifulSoup(txt, "html5lib")
|
||||||
|
# delete <style> tag
|
||||||
|
for style_tag in soup.find_all(["style", "script"]):
|
||||||
|
style_tag.decompose()
|
||||||
|
# delete <script> tag in <div>
|
||||||
|
for div_tag in soup.find_all("div"):
|
||||||
|
for script_tag in div_tag.find_all("script"):
|
||||||
|
script_tag.decompose()
|
||||||
|
# delete inline style
|
||||||
|
for tag in soup.find_all(True):
|
||||||
|
if 'style' in tag.attrs:
|
||||||
|
del tag.attrs['style']
|
||||||
|
# delete HTML comment
|
||||||
|
for comment in soup.find_all(string=lambda text: isinstance(text, Comment)):
|
||||||
|
comment.extract()
|
||||||
|
|
||||||
|
cls.read_text_recursively(soup.body, temp_sections, chunk_token_num=chunk_token_num)
|
||||||
|
block_txt_list, table_list = cls.merge_block_text(temp_sections)
|
||||||
|
sections = cls.chunk_block(block_txt_list, chunk_token_num=chunk_token_num)
|
||||||
|
for table in table_list:
|
||||||
|
sections.append(table.get("content", ""))
|
||||||
|
return sections
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def split_table(cls, html_table, chunk_token_num=512):
|
||||||
|
soup = BeautifulSoup(html_table, "html.parser")
|
||||||
|
rows = soup.find_all("tr")
|
||||||
|
tables = []
|
||||||
|
current_table = []
|
||||||
|
current_count = 0
|
||||||
|
table_str_list = []
|
||||||
|
for row in rows:
|
||||||
|
tks_str = rag_tokenizer.tokenize(str(row))
|
||||||
|
token_count = len(tks_str.split(" ")) if tks_str else 0
|
||||||
|
if current_count + token_count > chunk_token_num:
|
||||||
|
tables.append(current_table)
|
||||||
|
current_table = []
|
||||||
|
current_count = 0
|
||||||
|
current_table.append(row)
|
||||||
|
current_count += token_count
|
||||||
|
if current_table:
|
||||||
|
tables.append(current_table)
|
||||||
|
|
||||||
|
for table_rows in tables:
|
||||||
|
new_table = soup.new_tag("table")
|
||||||
|
for row in table_rows:
|
||||||
|
new_table.append(row)
|
||||||
|
table_str_list.append(str(new_table))
|
||||||
|
|
||||||
|
return table_str_list
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def read_text_recursively(cls, element, parser_result, chunk_token_num=512, parent_name=None, block_id=None):
|
||||||
|
if isinstance(element, NavigableString):
|
||||||
|
content = element.strip()
|
||||||
|
|
||||||
|
def is_valid_html(content):
|
||||||
|
try:
|
||||||
|
soup = BeautifulSoup(content, "html.parser")
|
||||||
|
return bool(soup.find())
|
||||||
|
except Exception:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return_info = []
|
||||||
|
if content:
|
||||||
|
if is_valid_html(content):
|
||||||
|
soup = BeautifulSoup(content, "html.parser")
|
||||||
|
child_info = cls.read_text_recursively(soup, parser_result, chunk_token_num, element.name, block_id)
|
||||||
|
parser_result.extend(child_info)
|
||||||
|
else:
|
||||||
|
info = {"content": element.strip(), "tag_name": "inner_text", "metadata": {"block_id": block_id}}
|
||||||
|
if parent_name:
|
||||||
|
info["tag_name"] = parent_name
|
||||||
|
return_info.append(info)
|
||||||
|
return return_info
|
||||||
|
elif isinstance(element, Tag):
|
||||||
|
|
||||||
|
if str.lower(element.name) == "table":
|
||||||
|
table_info_list = []
|
||||||
|
table_id = str(uuid.uuid1())
|
||||||
|
table_list = [html.unescape(str(element))]
|
||||||
|
for t in table_list:
|
||||||
|
table_info_list.append({"content": t, "tag_name": "table",
|
||||||
|
"metadata": {"table_id": table_id, "index": table_list.index(t)}})
|
||||||
|
return table_info_list
|
||||||
|
else:
|
||||||
|
block_id = None
|
||||||
|
if str.lower(element.name) in BLOCK_TAGS:
|
||||||
|
block_id = str(uuid.uuid1())
|
||||||
|
for child in element.children:
|
||||||
|
child_info = cls.read_text_recursively(child, parser_result, chunk_token_num, element.name,
|
||||||
|
block_id)
|
||||||
|
parser_result.extend(child_info)
|
||||||
|
return []
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def merge_block_text(cls, parser_result):
|
||||||
|
block_content = []
|
||||||
|
current_content = ""
|
||||||
|
table_info_list = []
|
||||||
|
lask_block_id = None
|
||||||
|
for item in parser_result:
|
||||||
|
content = item.get("content")
|
||||||
|
tag_name = item.get("tag_name")
|
||||||
|
title_flag = tag_name in TITLE_TAGS
|
||||||
|
block_id = item.get("metadata", {}).get("block_id")
|
||||||
|
if block_id:
|
||||||
|
if title_flag:
|
||||||
|
content = f"{TITLE_TAGS[tag_name]} {content}"
|
||||||
|
if lask_block_id != block_id:
|
||||||
|
if lask_block_id is not None:
|
||||||
|
block_content.append(current_content)
|
||||||
|
current_content = content
|
||||||
|
lask_block_id = block_id
|
||||||
|
else:
|
||||||
|
current_content += (" " if current_content else "") + content
|
||||||
|
else:
|
||||||
|
if tag_name == "table":
|
||||||
|
table_info_list.append(item)
|
||||||
|
else:
|
||||||
|
current_content += (" " if current_content else "" + content)
|
||||||
|
if current_content:
|
||||||
|
block_content.append(current_content)
|
||||||
|
return block_content, table_info_list
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def chunk_block(cls, block_txt_list, chunk_token_num=512):
|
||||||
|
chunks = []
|
||||||
|
current_block = ""
|
||||||
|
current_token_count = 0
|
||||||
|
|
||||||
|
for block in block_txt_list:
|
||||||
|
tks_str = rag_tokenizer.tokenize(block)
|
||||||
|
block_token_count = len(tks_str.split(" ")) if tks_str else 0
|
||||||
|
if block_token_count > chunk_token_num:
|
||||||
|
if current_block:
|
||||||
|
chunks.append(current_block)
|
||||||
|
start = 0
|
||||||
|
tokens = tks_str.split(" ")
|
||||||
|
while start < len(tokens):
|
||||||
|
end = start + chunk_token_num
|
||||||
|
split_tokens = tokens[start:end]
|
||||||
|
chunks.append(" ".join(split_tokens))
|
||||||
|
start = end
|
||||||
|
current_block = ""
|
||||||
|
current_token_count = 0
|
||||||
|
else:
|
||||||
|
if current_token_count + block_token_count <= chunk_token_num:
|
||||||
|
current_block += ("\n" if current_block else "") + block
|
||||||
|
current_token_count += block_token_count
|
||||||
|
else:
|
||||||
|
chunks.append(current_block)
|
||||||
|
current_block = block
|
||||||
|
current_token_count = block_token_count
|
||||||
|
|
||||||
|
if current_block:
|
||||||
|
chunks.append(current_block)
|
||||||
|
|
||||||
|
return chunks
|
||||||
|
|
||||||
179
deepdoc/parser/json_parser.py
Normal file
179
deepdoc/parser/json_parser.py
Normal file
@@ -0,0 +1,179 @@
|
|||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
# The following documents are mainly referenced, and only adaptation modifications have been made
|
||||||
|
# from https://github.com/langchain-ai/langchain/blob/master/libs/text-splitters/langchain_text_splitters/json.py
|
||||||
|
|
||||||
|
import json
|
||||||
|
from typing import Any
|
||||||
|
|
||||||
|
from rag.nlp import find_codec
|
||||||
|
|
||||||
|
|
||||||
|
class RAGFlowJsonParser:
|
||||||
|
def __init__(self, max_chunk_size: int = 2000, min_chunk_size: int | None = None):
|
||||||
|
super().__init__()
|
||||||
|
self.max_chunk_size = max_chunk_size * 2
|
||||||
|
self.min_chunk_size = min_chunk_size if min_chunk_size is not None else max(max_chunk_size - 200, 50)
|
||||||
|
|
||||||
|
def __call__(self, binary):
|
||||||
|
encoding = find_codec(binary)
|
||||||
|
txt = binary.decode(encoding, errors="ignore")
|
||||||
|
|
||||||
|
if self.is_jsonl_format(txt):
|
||||||
|
sections = self._parse_jsonl(txt)
|
||||||
|
else:
|
||||||
|
sections = self._parse_json(txt)
|
||||||
|
return sections
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _json_size(data: dict) -> int:
|
||||||
|
"""Calculate the size of the serialized JSON object."""
|
||||||
|
return len(json.dumps(data, ensure_ascii=False))
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _set_nested_dict(d: dict, path: list[str], value: Any) -> None:
|
||||||
|
"""Set a value in a nested dictionary based on the given path."""
|
||||||
|
for key in path[:-1]:
|
||||||
|
d = d.setdefault(key, {})
|
||||||
|
d[path[-1]] = value
|
||||||
|
|
||||||
|
def _list_to_dict_preprocessing(self, data: Any) -> Any:
|
||||||
|
if isinstance(data, dict):
|
||||||
|
# Process each key-value pair in the dictionary
|
||||||
|
return {k: self._list_to_dict_preprocessing(v) for k, v in data.items()}
|
||||||
|
elif isinstance(data, list):
|
||||||
|
# Convert the list to a dictionary with index-based keys
|
||||||
|
return {str(i): self._list_to_dict_preprocessing(item) for i, item in enumerate(data)}
|
||||||
|
else:
|
||||||
|
# Base case: the item is neither a dict nor a list, so return it unchanged
|
||||||
|
return data
|
||||||
|
|
||||||
|
def _json_split(
|
||||||
|
self,
|
||||||
|
data,
|
||||||
|
current_path: list[str] | None,
|
||||||
|
chunks: list[dict] | None,
|
||||||
|
) -> list[dict]:
|
||||||
|
"""
|
||||||
|
Split json into maximum size dictionaries while preserving structure.
|
||||||
|
"""
|
||||||
|
current_path = current_path or []
|
||||||
|
chunks = chunks or [{}]
|
||||||
|
if isinstance(data, dict):
|
||||||
|
for key, value in data.items():
|
||||||
|
new_path = current_path + [key]
|
||||||
|
chunk_size = self._json_size(chunks[-1])
|
||||||
|
size = self._json_size({key: value})
|
||||||
|
remaining = self.max_chunk_size - chunk_size
|
||||||
|
|
||||||
|
if size < remaining:
|
||||||
|
# Add item to current chunk
|
||||||
|
self._set_nested_dict(chunks[-1], new_path, value)
|
||||||
|
else:
|
||||||
|
if chunk_size >= self.min_chunk_size:
|
||||||
|
# Chunk is big enough, start a new chunk
|
||||||
|
chunks.append({})
|
||||||
|
|
||||||
|
# Iterate
|
||||||
|
self._json_split(value, new_path, chunks)
|
||||||
|
else:
|
||||||
|
# handle single item
|
||||||
|
self._set_nested_dict(chunks[-1], current_path, data)
|
||||||
|
return chunks
|
||||||
|
|
||||||
|
def split_json(
|
||||||
|
self,
|
||||||
|
json_data,
|
||||||
|
convert_lists: bool = False,
|
||||||
|
) -> list[dict]:
|
||||||
|
"""Splits JSON into a list of JSON chunks"""
|
||||||
|
|
||||||
|
if convert_lists:
|
||||||
|
preprocessed_data = self._list_to_dict_preprocessing(json_data)
|
||||||
|
chunks = self._json_split(preprocessed_data, None, None)
|
||||||
|
else:
|
||||||
|
chunks = self._json_split(json_data, None, None)
|
||||||
|
|
||||||
|
# Remove the last chunk if it's empty
|
||||||
|
if not chunks[-1]:
|
||||||
|
chunks.pop()
|
||||||
|
return chunks
|
||||||
|
|
||||||
|
def split_text(
|
||||||
|
self,
|
||||||
|
json_data: dict[str, Any],
|
||||||
|
convert_lists: bool = False,
|
||||||
|
ensure_ascii: bool = True,
|
||||||
|
) -> list[str]:
|
||||||
|
"""Splits JSON into a list of JSON formatted strings"""
|
||||||
|
|
||||||
|
chunks = self.split_json(json_data=json_data, convert_lists=convert_lists)
|
||||||
|
|
||||||
|
# Convert to string
|
||||||
|
return [json.dumps(chunk, ensure_ascii=ensure_ascii) for chunk in chunks]
|
||||||
|
|
||||||
|
def _parse_json(self, content: str) -> list[str]:
|
||||||
|
sections = []
|
||||||
|
try:
|
||||||
|
json_data = json.loads(content)
|
||||||
|
chunks = self.split_json(json_data, True)
|
||||||
|
sections = [json.dumps(line, ensure_ascii=False) for line in chunks if line]
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
pass
|
||||||
|
return sections
|
||||||
|
|
||||||
|
def _parse_jsonl(self, content: str) -> list[str]:
|
||||||
|
lines = content.strip().splitlines()
|
||||||
|
all_chunks = []
|
||||||
|
for line in lines:
|
||||||
|
if not line.strip():
|
||||||
|
continue
|
||||||
|
try:
|
||||||
|
data = json.loads(line)
|
||||||
|
chunks = self.split_json(data, convert_lists=True)
|
||||||
|
all_chunks.extend(json.dumps(chunk, ensure_ascii=False) for chunk in chunks if chunk)
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
continue
|
||||||
|
return all_chunks
|
||||||
|
|
||||||
|
def is_jsonl_format(self, txt: str, sample_limit: int = 10, threshold: float = 0.8) -> bool:
|
||||||
|
lines = [line.strip() for line in txt.strip().splitlines() if line.strip()]
|
||||||
|
if not lines:
|
||||||
|
return False
|
||||||
|
|
||||||
|
try:
|
||||||
|
json.loads(txt)
|
||||||
|
return False
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
sample_limit = min(len(lines), sample_limit)
|
||||||
|
sample_lines = lines[:sample_limit]
|
||||||
|
valid_lines = sum(1 for line in sample_lines if self._is_valid_json(line))
|
||||||
|
|
||||||
|
if not valid_lines:
|
||||||
|
return False
|
||||||
|
|
||||||
|
return (valid_lines / len(sample_lines)) >= threshold
|
||||||
|
|
||||||
|
def _is_valid_json(self, line: str) -> bool:
|
||||||
|
try:
|
||||||
|
json.loads(line)
|
||||||
|
return True
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
return False
|
||||||
270
deepdoc/parser/markdown_parser.py
Normal file
270
deepdoc/parser/markdown_parser.py
Normal file
@@ -0,0 +1,270 @@
|
|||||||
|
# -*- coding: utf-8 -*-
|
||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import re
|
||||||
|
|
||||||
|
from markdown import markdown
|
||||||
|
|
||||||
|
|
||||||
|
class RAGFlowMarkdownParser:
|
||||||
|
def __init__(self, chunk_token_num=128):
|
||||||
|
self.chunk_token_num = int(chunk_token_num)
|
||||||
|
|
||||||
|
def extract_tables_and_remainder(self, markdown_text, separate_tables=True):
|
||||||
|
tables = []
|
||||||
|
working_text = markdown_text
|
||||||
|
|
||||||
|
def replace_tables_with_rendered_html(pattern, table_list, render=True):
|
||||||
|
new_text = ""
|
||||||
|
last_end = 0
|
||||||
|
for match in pattern.finditer(working_text):
|
||||||
|
raw_table = match.group()
|
||||||
|
table_list.append(raw_table)
|
||||||
|
if separate_tables:
|
||||||
|
# Skip this match (i.e., remove it)
|
||||||
|
new_text += working_text[last_end : match.start()] + "\n\n"
|
||||||
|
else:
|
||||||
|
# Replace with rendered HTML
|
||||||
|
html_table = markdown(raw_table, extensions=["markdown.extensions.tables"]) if render else raw_table
|
||||||
|
new_text += working_text[last_end : match.start()] + html_table + "\n\n"
|
||||||
|
last_end = match.end()
|
||||||
|
new_text += working_text[last_end:]
|
||||||
|
return new_text
|
||||||
|
|
||||||
|
if "|" in markdown_text: # for optimize performance
|
||||||
|
# Standard Markdown table
|
||||||
|
border_table_pattern = re.compile(
|
||||||
|
r"""
|
||||||
|
(?:\n|^)
|
||||||
|
(?:\|.*?\|.*?\|.*?\n)
|
||||||
|
(?:\|(?:\s*[:-]+[-| :]*\s*)\|.*?\n)
|
||||||
|
(?:\|.*?\|.*?\|.*?\n)+
|
||||||
|
""",
|
||||||
|
re.VERBOSE,
|
||||||
|
)
|
||||||
|
working_text = replace_tables_with_rendered_html(border_table_pattern, tables)
|
||||||
|
|
||||||
|
# Borderless Markdown table
|
||||||
|
no_border_table_pattern = re.compile(
|
||||||
|
r"""
|
||||||
|
(?:\n|^)
|
||||||
|
(?:\S.*?\|.*?\n)
|
||||||
|
(?:(?:\s*[:-]+[-| :]*\s*).*?\n)
|
||||||
|
(?:\S.*?\|.*?\n)+
|
||||||
|
""",
|
||||||
|
re.VERBOSE,
|
||||||
|
)
|
||||||
|
working_text = replace_tables_with_rendered_html(no_border_table_pattern, tables)
|
||||||
|
|
||||||
|
if "<table>" in working_text.lower(): # for optimize performance
|
||||||
|
# HTML table extraction - handle possible html/body wrapper tags
|
||||||
|
html_table_pattern = re.compile(
|
||||||
|
r"""
|
||||||
|
(?:\n|^)
|
||||||
|
\s*
|
||||||
|
(?:
|
||||||
|
# case1: <html><body><table>...</table></body></html>
|
||||||
|
(?:<html[^>]*>\s*<body[^>]*>\s*<table[^>]*>.*?</table>\s*</body>\s*</html>)
|
||||||
|
|
|
||||||
|
# case2: <body><table>...</table></body>
|
||||||
|
(?:<body[^>]*>\s*<table[^>]*>.*?</table>\s*</body>)
|
||||||
|
|
|
||||||
|
# case3: only<table>...</table>
|
||||||
|
(?:<table[^>]*>.*?</table>)
|
||||||
|
)
|
||||||
|
\s*
|
||||||
|
(?=\n|$)
|
||||||
|
""",
|
||||||
|
re.VERBOSE | re.DOTALL | re.IGNORECASE,
|
||||||
|
)
|
||||||
|
|
||||||
|
def replace_html_tables():
|
||||||
|
nonlocal working_text
|
||||||
|
new_text = ""
|
||||||
|
last_end = 0
|
||||||
|
for match in html_table_pattern.finditer(working_text):
|
||||||
|
raw_table = match.group()
|
||||||
|
tables.append(raw_table)
|
||||||
|
if separate_tables:
|
||||||
|
new_text += working_text[last_end : match.start()] + "\n\n"
|
||||||
|
else:
|
||||||
|
new_text += working_text[last_end : match.start()] + raw_table + "\n\n"
|
||||||
|
last_end = match.end()
|
||||||
|
new_text += working_text[last_end:]
|
||||||
|
working_text = new_text
|
||||||
|
|
||||||
|
replace_html_tables()
|
||||||
|
|
||||||
|
return working_text, tables
|
||||||
|
|
||||||
|
|
||||||
|
class MarkdownElementExtractor:
|
||||||
|
def __init__(self, markdown_content):
|
||||||
|
self.markdown_content = markdown_content
|
||||||
|
self.lines = markdown_content.split("\n")
|
||||||
|
|
||||||
|
def extract_elements(self):
|
||||||
|
"""Extract individual elements (headers, code blocks, lists, etc.)"""
|
||||||
|
sections = []
|
||||||
|
|
||||||
|
i = 0
|
||||||
|
while i < len(self.lines):
|
||||||
|
line = self.lines[i]
|
||||||
|
|
||||||
|
if re.match(r"^#{1,6}\s+.*$", line):
|
||||||
|
# header
|
||||||
|
element = self._extract_header(i)
|
||||||
|
sections.append(element["content"])
|
||||||
|
i = element["end_line"] + 1
|
||||||
|
elif line.strip().startswith("```"):
|
||||||
|
# code block
|
||||||
|
element = self._extract_code_block(i)
|
||||||
|
sections.append(element["content"])
|
||||||
|
i = element["end_line"] + 1
|
||||||
|
elif re.match(r"^\s*[-*+]\s+.*$", line) or re.match(r"^\s*\d+\.\s+.*$", line):
|
||||||
|
# list block
|
||||||
|
element = self._extract_list_block(i)
|
||||||
|
sections.append(element["content"])
|
||||||
|
i = element["end_line"] + 1
|
||||||
|
elif line.strip().startswith(">"):
|
||||||
|
# blockquote
|
||||||
|
element = self._extract_blockquote(i)
|
||||||
|
sections.append(element["content"])
|
||||||
|
i = element["end_line"] + 1
|
||||||
|
elif line.strip():
|
||||||
|
# text block (paragraphs and inline elements until next block element)
|
||||||
|
element = self._extract_text_block(i)
|
||||||
|
sections.append(element["content"])
|
||||||
|
i = element["end_line"] + 1
|
||||||
|
else:
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
sections = [section for section in sections if section.strip()]
|
||||||
|
return sections
|
||||||
|
|
||||||
|
def _extract_header(self, start_pos):
|
||||||
|
return {
|
||||||
|
"type": "header",
|
||||||
|
"content": self.lines[start_pos],
|
||||||
|
"start_line": start_pos,
|
||||||
|
"end_line": start_pos,
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_code_block(self, start_pos):
|
||||||
|
end_pos = start_pos
|
||||||
|
content_lines = [self.lines[start_pos]]
|
||||||
|
|
||||||
|
# Find the end of the code block
|
||||||
|
for i in range(start_pos + 1, len(self.lines)):
|
||||||
|
content_lines.append(self.lines[i])
|
||||||
|
end_pos = i
|
||||||
|
if self.lines[i].strip().startswith("```"):
|
||||||
|
break
|
||||||
|
|
||||||
|
return {
|
||||||
|
"type": "code_block",
|
||||||
|
"content": "\n".join(content_lines),
|
||||||
|
"start_line": start_pos,
|
||||||
|
"end_line": end_pos,
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_list_block(self, start_pos):
|
||||||
|
end_pos = start_pos
|
||||||
|
content_lines = []
|
||||||
|
|
||||||
|
i = start_pos
|
||||||
|
while i < len(self.lines):
|
||||||
|
line = self.lines[i]
|
||||||
|
# check if this line is a list item or continuation of a list
|
||||||
|
if (
|
||||||
|
re.match(r"^\s*[-*+]\s+.*$", line)
|
||||||
|
or re.match(r"^\s*\d+\.\s+.*$", line)
|
||||||
|
or (i > start_pos and not line.strip())
|
||||||
|
or (i > start_pos and re.match(r"^\s{2,}[-*+]\s+.*$", line))
|
||||||
|
or (i > start_pos and re.match(r"^\s{2,}\d+\.\s+.*$", line))
|
||||||
|
or (i > start_pos and re.match(r"^\s+\w+.*$", line))
|
||||||
|
):
|
||||||
|
content_lines.append(line)
|
||||||
|
end_pos = i
|
||||||
|
i += 1
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
|
||||||
|
return {
|
||||||
|
"type": "list_block",
|
||||||
|
"content": "\n".join(content_lines),
|
||||||
|
"start_line": start_pos,
|
||||||
|
"end_line": end_pos,
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_blockquote(self, start_pos):
|
||||||
|
end_pos = start_pos
|
||||||
|
content_lines = []
|
||||||
|
|
||||||
|
i = start_pos
|
||||||
|
while i < len(self.lines):
|
||||||
|
line = self.lines[i]
|
||||||
|
if line.strip().startswith(">") or (i > start_pos and not line.strip()):
|
||||||
|
content_lines.append(line)
|
||||||
|
end_pos = i
|
||||||
|
i += 1
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
|
||||||
|
return {
|
||||||
|
"type": "blockquote",
|
||||||
|
"content": "\n".join(content_lines),
|
||||||
|
"start_line": start_pos,
|
||||||
|
"end_line": end_pos,
|
||||||
|
}
|
||||||
|
|
||||||
|
def _extract_text_block(self, start_pos):
|
||||||
|
"""Extract a text block (paragraphs, inline elements) until next block element"""
|
||||||
|
end_pos = start_pos
|
||||||
|
content_lines = [self.lines[start_pos]]
|
||||||
|
|
||||||
|
i = start_pos + 1
|
||||||
|
while i < len(self.lines):
|
||||||
|
line = self.lines[i]
|
||||||
|
# stop if we encounter a block element
|
||||||
|
if re.match(r"^#{1,6}\s+.*$", line) or line.strip().startswith("```") or re.match(r"^\s*[-*+]\s+.*$", line) or re.match(r"^\s*\d+\.\s+.*$", line) or line.strip().startswith(">"):
|
||||||
|
break
|
||||||
|
elif not line.strip():
|
||||||
|
# check if the next line is a block element
|
||||||
|
if i + 1 < len(self.lines) and (
|
||||||
|
re.match(r"^#{1,6}\s+.*$", self.lines[i + 1])
|
||||||
|
or self.lines[i + 1].strip().startswith("```")
|
||||||
|
or re.match(r"^\s*[-*+]\s+.*$", self.lines[i + 1])
|
||||||
|
or re.match(r"^\s*\d+\.\s+.*$", self.lines[i + 1])
|
||||||
|
or self.lines[i + 1].strip().startswith(">")
|
||||||
|
):
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
content_lines.append(line)
|
||||||
|
end_pos = i
|
||||||
|
i += 1
|
||||||
|
else:
|
||||||
|
content_lines.append(line)
|
||||||
|
end_pos = i
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
return {
|
||||||
|
"type": "text_block",
|
||||||
|
"content": "\n".join(content_lines),
|
||||||
|
"start_line": start_pos,
|
||||||
|
"end_line": end_pos,
|
||||||
|
}
|
||||||
344
deepdoc/parser/mineru_parser.py
Normal file
344
deepdoc/parser/mineru_parser.py
Normal file
@@ -0,0 +1,344 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
import json
|
||||||
|
import logging
|
||||||
|
import platform
|
||||||
|
import re
|
||||||
|
import subprocess
|
||||||
|
import sys
|
||||||
|
import tempfile
|
||||||
|
import threading
|
||||||
|
import time
|
||||||
|
from io import BytesIO
|
||||||
|
from os import PathLike
|
||||||
|
from pathlib import Path
|
||||||
|
from queue import Empty, Queue
|
||||||
|
from typing import Any, Callable, Optional
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import pdfplumber
|
||||||
|
from PIL import Image
|
||||||
|
from strenum import StrEnum
|
||||||
|
|
||||||
|
from deepdoc.parser.pdf_parser import RAGFlowPdfParser
|
||||||
|
|
||||||
|
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
||||||
|
if LOCK_KEY_pdfplumber not in sys.modules:
|
||||||
|
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
||||||
|
|
||||||
|
|
||||||
|
class MinerUContentType(StrEnum):
|
||||||
|
IMAGE = "image"
|
||||||
|
TABLE = "table"
|
||||||
|
TEXT = "text"
|
||||||
|
EQUATION = "equation"
|
||||||
|
|
||||||
|
|
||||||
|
class MinerUParser(RAGFlowPdfParser):
|
||||||
|
def __init__(self, mineru_path: str = "mineru"):
|
||||||
|
self.mineru_path = Path(mineru_path)
|
||||||
|
self.logger = logging.getLogger(self.__class__.__name__)
|
||||||
|
|
||||||
|
def check_installation(self) -> bool:
|
||||||
|
subprocess_kwargs = {
|
||||||
|
"capture_output": True,
|
||||||
|
"text": True,
|
||||||
|
"check": True,
|
||||||
|
"encoding": "utf-8",
|
||||||
|
"errors": "ignore",
|
||||||
|
}
|
||||||
|
|
||||||
|
if platform.system() == "Windows":
|
||||||
|
subprocess_kwargs["creationflags"] = getattr(subprocess, "CREATE_NO_WINDOW", 0)
|
||||||
|
|
||||||
|
try:
|
||||||
|
result = subprocess.run([str(self.mineru_path), "--version"], **subprocess_kwargs)
|
||||||
|
version_info = result.stdout.strip()
|
||||||
|
if version_info:
|
||||||
|
logging.info(f"[MinerU] Detected version: {version_info}")
|
||||||
|
else:
|
||||||
|
logging.info("[MinerU] Detected MinerU, but version info is empty.")
|
||||||
|
return True
|
||||||
|
except subprocess.CalledProcessError as e:
|
||||||
|
logging.warning(f"[MinerU] Execution failed (exit code {e.returncode}).")
|
||||||
|
except FileNotFoundError:
|
||||||
|
logging.warning("[MinerU] MinerU not found. Please install it via: pip install -U 'mineru[core]'")
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(f"[MinerU] Unexpected error during installation check: {e}")
|
||||||
|
return False
|
||||||
|
|
||||||
|
def _run_mineru(self, input_path: Path, output_dir: Path, method: str = "auto", lang: Optional[str] = None):
|
||||||
|
cmd = [str(self.mineru_path), "-p", str(input_path), "-o", str(output_dir), "-m", method]
|
||||||
|
if lang:
|
||||||
|
cmd.extend(["-l", lang])
|
||||||
|
|
||||||
|
self.logger.info(f"[MinerU] Running command: {' '.join(cmd)}")
|
||||||
|
|
||||||
|
subprocess_kwargs = {
|
||||||
|
"stdout": subprocess.PIPE,
|
||||||
|
"stderr": subprocess.PIPE,
|
||||||
|
"text": True,
|
||||||
|
"encoding": "utf-8",
|
||||||
|
"errors": "ignore",
|
||||||
|
"bufsize": 1,
|
||||||
|
}
|
||||||
|
|
||||||
|
if platform.system() == "Windows":
|
||||||
|
subprocess_kwargs["creationflags"] = getattr(subprocess, "CREATE_NO_WINDOW", 0)
|
||||||
|
|
||||||
|
process = subprocess.Popen(cmd, **subprocess_kwargs)
|
||||||
|
stdout_queue, stderr_queue = Queue(), Queue()
|
||||||
|
|
||||||
|
def enqueue_output(pipe, queue, prefix):
|
||||||
|
for line in iter(pipe.readline, ""):
|
||||||
|
if line.strip():
|
||||||
|
queue.put((prefix, line.strip()))
|
||||||
|
pipe.close()
|
||||||
|
|
||||||
|
threading.Thread(target=enqueue_output, args=(process.stdout, stdout_queue, "STDOUT"), daemon=True).start()
|
||||||
|
threading.Thread(target=enqueue_output, args=(process.stderr, stderr_queue, "STDERR"), daemon=True).start()
|
||||||
|
|
||||||
|
while process.poll() is None:
|
||||||
|
for q in (stdout_queue, stderr_queue):
|
||||||
|
try:
|
||||||
|
while True:
|
||||||
|
prefix, line = q.get_nowait()
|
||||||
|
if prefix == "STDOUT":
|
||||||
|
self.logger.info(f"[MinerU] {line}")
|
||||||
|
else:
|
||||||
|
self.logger.warning(f"[MinerU] {line}")
|
||||||
|
except Empty:
|
||||||
|
pass
|
||||||
|
time.sleep(0.1)
|
||||||
|
|
||||||
|
return_code = process.wait()
|
||||||
|
if return_code != 0:
|
||||||
|
raise RuntimeError(f"[MinerU] Process failed with exit code {return_code}")
|
||||||
|
self.logger.info("[MinerU] Command completed successfully.")
|
||||||
|
|
||||||
|
def __images__(self, fnm, zoomin: int = 1, page_from=0, page_to=600, callback=None):
|
||||||
|
self.page_from = page_from
|
||||||
|
self.page_to = page_to
|
||||||
|
try:
|
||||||
|
with pdfplumber.open(fnm) if isinstance(fnm, (str, PathLike)) else pdfplumber.open(BytesIO(fnm)) as pdf:
|
||||||
|
self.pdf = pdf
|
||||||
|
self.page_images = [p.to_image(resolution=72 * zoomin, antialias=True).original for _, p in enumerate(self.pdf.pages[page_from:page_to])]
|
||||||
|
except Exception as e:
|
||||||
|
self.page_images = None
|
||||||
|
self.total_page = 0
|
||||||
|
logging.exception(e)
|
||||||
|
|
||||||
|
def _line_tag(self, bx):
|
||||||
|
pn = [bx["page_idx"] + 1]
|
||||||
|
positions = bx["bbox"]
|
||||||
|
x0, top, x1, bott = positions
|
||||||
|
|
||||||
|
if hasattr(self, "page_images") and self.page_images and len(self.page_images) > bx["page_idx"]:
|
||||||
|
page_width, page_height = self.page_images[bx["page_idx"]].size
|
||||||
|
x0 = (x0 / 1000.0) * page_width
|
||||||
|
x1 = (x1 / 1000.0) * page_width
|
||||||
|
top = (top / 1000.0) * page_height
|
||||||
|
bott = (bott / 1000.0) * page_height
|
||||||
|
|
||||||
|
return "@@{}\t{:.1f}\t{:.1f}\t{:.1f}\t{:.1f}##".format("-".join([str(p) for p in pn]), x0, x1, top, bott)
|
||||||
|
|
||||||
|
def crop(self, text, ZM=1, need_position=False):
|
||||||
|
imgs = []
|
||||||
|
poss = self.extract_positions(text)
|
||||||
|
if not poss:
|
||||||
|
if need_position:
|
||||||
|
return None, None
|
||||||
|
return
|
||||||
|
|
||||||
|
max_width = max(np.max([right - left for (_, left, right, _, _) in poss]), 6)
|
||||||
|
GAP = 6
|
||||||
|
pos = poss[0]
|
||||||
|
poss.insert(0, ([pos[0][0]], pos[1], pos[2], max(0, pos[3] - 120), max(pos[3] - GAP, 0)))
|
||||||
|
pos = poss[-1]
|
||||||
|
poss.append(([pos[0][-1]], pos[1], pos[2], min(self.page_images[pos[0][-1]].size[1], pos[4] + GAP), min(self.page_images[pos[0][-1]].size[1], pos[4] + 120)))
|
||||||
|
|
||||||
|
positions = []
|
||||||
|
for ii, (pns, left, right, top, bottom) in enumerate(poss):
|
||||||
|
right = left + max_width
|
||||||
|
|
||||||
|
if bottom <= top:
|
||||||
|
bottom = top + 2
|
||||||
|
|
||||||
|
for pn in pns[1:]:
|
||||||
|
bottom += self.page_images[pn - 1].size[1]
|
||||||
|
|
||||||
|
img0 = self.page_images[pns[0]]
|
||||||
|
x0, y0, x1, y1 = int(left), int(top), int(right), int(min(bottom, img0.size[1]))
|
||||||
|
crop0 = img0.crop((x0, y0, x1, y1))
|
||||||
|
imgs.append(crop0)
|
||||||
|
if 0 < ii < len(poss) - 1:
|
||||||
|
positions.append((pns[0] + self.page_from, x0, x1, y0, y1))
|
||||||
|
|
||||||
|
bottom -= img0.size[1]
|
||||||
|
for pn in pns[1:]:
|
||||||
|
page = self.page_images[pn]
|
||||||
|
x0, y0, x1, y1 = int(left), 0, int(right), int(min(bottom, page.size[1]))
|
||||||
|
cimgp = page.crop((x0, y0, x1, y1))
|
||||||
|
imgs.append(cimgp)
|
||||||
|
if 0 < ii < len(poss) - 1:
|
||||||
|
positions.append((pn + self.page_from, x0, x1, y0, y1))
|
||||||
|
bottom -= page.size[1]
|
||||||
|
|
||||||
|
if not imgs:
|
||||||
|
if need_position:
|
||||||
|
return None, None
|
||||||
|
return
|
||||||
|
|
||||||
|
height = 0
|
||||||
|
for img in imgs:
|
||||||
|
height += img.size[1] + GAP
|
||||||
|
height = int(height)
|
||||||
|
width = int(np.max([i.size[0] for i in imgs]))
|
||||||
|
pic = Image.new("RGB", (width, height), (245, 245, 245))
|
||||||
|
height = 0
|
||||||
|
for ii, img in enumerate(imgs):
|
||||||
|
if ii == 0 or ii + 1 == len(imgs):
|
||||||
|
img = img.convert("RGBA")
|
||||||
|
overlay = Image.new("RGBA", img.size, (0, 0, 0, 0))
|
||||||
|
overlay.putalpha(128)
|
||||||
|
img = Image.alpha_composite(img, overlay).convert("RGB")
|
||||||
|
pic.paste(img, (0, int(height)))
|
||||||
|
height += img.size[1] + GAP
|
||||||
|
|
||||||
|
if need_position:
|
||||||
|
return pic, positions
|
||||||
|
return pic
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def extract_positions(txt: str):
|
||||||
|
poss = []
|
||||||
|
for tag in re.findall(r"@@[0-9-]+\t[0-9.\t]+##", txt):
|
||||||
|
pn, left, right, top, bottom = tag.strip("#").strip("@").split("\t")
|
||||||
|
left, right, top, bottom = float(left), float(right), float(top), float(bottom)
|
||||||
|
poss.append(([int(p) - 1 for p in pn.split("-")], left, right, top, bottom))
|
||||||
|
return poss
|
||||||
|
|
||||||
|
def _read_output(self, output_dir: Path, file_stem: str, method: str = "auto") -> list[dict[str, Any]]:
|
||||||
|
subdir = output_dir / file_stem / method
|
||||||
|
json_file = subdir / f"{file_stem}_content_list.json"
|
||||||
|
|
||||||
|
if not json_file.exists():
|
||||||
|
raise FileNotFoundError(f"[MinerU] Missing output file: {json_file}")
|
||||||
|
|
||||||
|
with open(json_file, "r", encoding="utf-8") as f:
|
||||||
|
data = json.load(f)
|
||||||
|
|
||||||
|
for item in data:
|
||||||
|
for key in ("img_path", "table_img_path", "equation_img_path"):
|
||||||
|
if key in item and item[key]:
|
||||||
|
item[key] = str((subdir / item[key]).resolve())
|
||||||
|
return data
|
||||||
|
|
||||||
|
def _transfer_to_sections(self, outputs: list[dict[str, Any]]):
|
||||||
|
sections = []
|
||||||
|
for output in outputs:
|
||||||
|
match output["type"]:
|
||||||
|
case MinerUContentType.TEXT:
|
||||||
|
section = output["text"]
|
||||||
|
case MinerUContentType.TABLE:
|
||||||
|
section = output["table_body"] + "\n".join(output["table_caption"]) + "\n".join(output["table_footnote"])
|
||||||
|
case MinerUContentType.IMAGE:
|
||||||
|
section = "".join(output["image_caption"]) + "\n" + "".join(output["image_footnote"])
|
||||||
|
case MinerUContentType.EQUATION:
|
||||||
|
section = output["text"]
|
||||||
|
|
||||||
|
if section:
|
||||||
|
sections.append((section, self._line_tag(output)))
|
||||||
|
return sections
|
||||||
|
|
||||||
|
def _transfer_to_tables(self, outputs: list[dict[str, Any]]):
|
||||||
|
return []
|
||||||
|
|
||||||
|
def parse_pdf(
|
||||||
|
self,
|
||||||
|
filepath: str | PathLike[str],
|
||||||
|
binary: BytesIO | bytes,
|
||||||
|
callback: Optional[Callable] = None,
|
||||||
|
*,
|
||||||
|
output_dir: Optional[str] = None,
|
||||||
|
lang: Optional[str] = None,
|
||||||
|
method: str = "auto",
|
||||||
|
delete_output: bool = True,
|
||||||
|
) -> tuple:
|
||||||
|
import shutil
|
||||||
|
|
||||||
|
temp_pdf = None
|
||||||
|
created_tmp_dir = False
|
||||||
|
|
||||||
|
if binary:
|
||||||
|
temp_dir = Path(tempfile.mkdtemp(prefix="mineru_bin_pdf_"))
|
||||||
|
temp_pdf = temp_dir / Path(filepath).name
|
||||||
|
with open(temp_pdf, "wb") as f:
|
||||||
|
f.write(binary)
|
||||||
|
pdf = temp_pdf
|
||||||
|
self.logger.info(f"[MinerU] Received binary PDF -> {temp_pdf}")
|
||||||
|
if callback:
|
||||||
|
callback(0.15, f"[MinerU] Received binary PDF -> {temp_pdf}")
|
||||||
|
else:
|
||||||
|
pdf = Path(filepath)
|
||||||
|
if not pdf.exists():
|
||||||
|
if callback:
|
||||||
|
callback(-1, f"[MinerU] PDF not found: {pdf}")
|
||||||
|
raise FileNotFoundError(f"[MinerU] PDF not found: {pdf}")
|
||||||
|
|
||||||
|
if output_dir:
|
||||||
|
out_dir = Path(output_dir)
|
||||||
|
out_dir.mkdir(parents=True, exist_ok=True)
|
||||||
|
else:
|
||||||
|
out_dir = Path(tempfile.mkdtemp(prefix="mineru_pdf_"))
|
||||||
|
created_tmp_dir = True
|
||||||
|
|
||||||
|
self.logger.info(f"[MinerU] Output directory: {out_dir}")
|
||||||
|
if callback:
|
||||||
|
callback(0.15, f"[MinerU] Output directory: {out_dir}")
|
||||||
|
|
||||||
|
self.__images__(pdf, zoomin=1)
|
||||||
|
|
||||||
|
try:
|
||||||
|
self._run_mineru(pdf, out_dir, method=method, lang=lang)
|
||||||
|
outputs = self._read_output(out_dir, pdf.stem, method=method)
|
||||||
|
self.logger.info(f"[MinerU] Parsed {len(outputs)} blocks from PDF.")
|
||||||
|
if callback:
|
||||||
|
callback(0.75, f"[MinerU] Parsed {len(outputs)} blocks from PDF.")
|
||||||
|
return self._transfer_to_sections(outputs), self._transfer_to_tables(outputs)
|
||||||
|
finally:
|
||||||
|
if temp_pdf and temp_pdf.exists():
|
||||||
|
try:
|
||||||
|
temp_pdf.unlink()
|
||||||
|
temp_pdf.parent.rmdir()
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
if delete_output and created_tmp_dir and out_dir.exists():
|
||||||
|
try:
|
||||||
|
shutil.rmtree(out_dir)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
parser = MinerUParser("mineru")
|
||||||
|
print("MinerU available:", parser.check_installation())
|
||||||
|
|
||||||
|
filepath = ""
|
||||||
|
with open(filepath, "rb") as file:
|
||||||
|
outputs = parser.parse_pdf(filepath=filepath, binary=file.read())
|
||||||
|
for output in outputs:
|
||||||
|
print(output)
|
||||||
1404
deepdoc/parser/pdf_parser.py
Normal file
1404
deepdoc/parser/pdf_parser.py
Normal file
File diff suppressed because it is too large
Load Diff
99
deepdoc/parser/ppt_parser.py
Normal file
99
deepdoc/parser/ppt_parser.py
Normal file
@@ -0,0 +1,99 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
from io import BytesIO
|
||||||
|
from pptx import Presentation
|
||||||
|
|
||||||
|
|
||||||
|
class RAGFlowPptParser:
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
def __get_bulleted_text(self, paragraph):
|
||||||
|
is_bulleted = bool(paragraph._p.xpath("./a:pPr/a:buChar")) or bool(paragraph._p.xpath("./a:pPr/a:buAutoNum")) or bool(paragraph._p.xpath("./a:pPr/a:buBlip"))
|
||||||
|
if is_bulleted:
|
||||||
|
return f"{' '* paragraph.level}.{paragraph.text}"
|
||||||
|
else:
|
||||||
|
return paragraph.text
|
||||||
|
|
||||||
|
def __extract(self, shape):
|
||||||
|
try:
|
||||||
|
# First try to get text content
|
||||||
|
if hasattr(shape, 'has_text_frame') and shape.has_text_frame:
|
||||||
|
text_frame = shape.text_frame
|
||||||
|
texts = []
|
||||||
|
for paragraph in text_frame.paragraphs:
|
||||||
|
if paragraph.text.strip():
|
||||||
|
texts.append(self.__get_bulleted_text(paragraph))
|
||||||
|
return "\n".join(texts)
|
||||||
|
|
||||||
|
# Safely get shape_type
|
||||||
|
try:
|
||||||
|
shape_type = shape.shape_type
|
||||||
|
except NotImplementedError:
|
||||||
|
# If shape_type is not available, try to get text content
|
||||||
|
if hasattr(shape, 'text'):
|
||||||
|
return shape.text.strip()
|
||||||
|
return ""
|
||||||
|
|
||||||
|
# Handle table
|
||||||
|
if shape_type == 19:
|
||||||
|
tb = shape.table
|
||||||
|
rows = []
|
||||||
|
for i in range(1, len(tb.rows)):
|
||||||
|
rows.append("; ".join([tb.cell(
|
||||||
|
0, j).text + ": " + tb.cell(i, j).text for j in range(len(tb.columns)) if tb.cell(i, j)]))
|
||||||
|
return "\n".join(rows)
|
||||||
|
|
||||||
|
# Handle group shape
|
||||||
|
if shape_type == 6:
|
||||||
|
texts = []
|
||||||
|
for p in sorted(shape.shapes, key=lambda x: (x.top // 10, x.left)):
|
||||||
|
t = self.__extract(p)
|
||||||
|
if t:
|
||||||
|
texts.append(t)
|
||||||
|
return "\n".join(texts)
|
||||||
|
|
||||||
|
return ""
|
||||||
|
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(f"Error processing shape: {str(e)}")
|
||||||
|
return ""
|
||||||
|
|
||||||
|
def __call__(self, fnm, from_page, to_page, callback=None):
|
||||||
|
ppt = Presentation(fnm) if isinstance(
|
||||||
|
fnm, str) else Presentation(
|
||||||
|
BytesIO(fnm))
|
||||||
|
txts = []
|
||||||
|
self.total_page = len(ppt.slides)
|
||||||
|
for i, slide in enumerate(ppt.slides):
|
||||||
|
if i < from_page:
|
||||||
|
continue
|
||||||
|
if i >= to_page:
|
||||||
|
break
|
||||||
|
texts = []
|
||||||
|
for shape in sorted(
|
||||||
|
slide.shapes, key=lambda x: ((x.top if x.top is not None else 0) // 10, x.left if x.left is not None else 0)):
|
||||||
|
try:
|
||||||
|
txt = self.__extract(shape)
|
||||||
|
if txt:
|
||||||
|
texts.append(txt)
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception(e)
|
||||||
|
txts.append("\n".join(texts))
|
||||||
|
|
||||||
|
return txts
|
||||||
109
deepdoc/parser/resume/__init__.py
Normal file
109
deepdoc/parser/resume/__init__.py
Normal file
@@ -0,0 +1,109 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import datetime
|
||||||
|
|
||||||
|
|
||||||
|
def refactor(cv):
|
||||||
|
for n in [
|
||||||
|
"raw_txt",
|
||||||
|
"parser_name",
|
||||||
|
"inference",
|
||||||
|
"ori_text",
|
||||||
|
"use_time",
|
||||||
|
"time_stat",
|
||||||
|
]:
|
||||||
|
if n in cv and cv[n] is not None:
|
||||||
|
del cv[n]
|
||||||
|
cv["is_deleted"] = 0
|
||||||
|
if "basic" not in cv:
|
||||||
|
cv["basic"] = {}
|
||||||
|
if cv["basic"].get("photo2"):
|
||||||
|
del cv["basic"]["photo2"]
|
||||||
|
|
||||||
|
for n in [
|
||||||
|
"education",
|
||||||
|
"work",
|
||||||
|
"certificate",
|
||||||
|
"project",
|
||||||
|
"language",
|
||||||
|
"skill",
|
||||||
|
"training",
|
||||||
|
]:
|
||||||
|
if n not in cv or cv[n] is None:
|
||||||
|
continue
|
||||||
|
if isinstance(cv[n], dict):
|
||||||
|
cv[n] = [v for _, v in cv[n].items()]
|
||||||
|
if not isinstance(cv[n], list):
|
||||||
|
del cv[n]
|
||||||
|
continue
|
||||||
|
vv = []
|
||||||
|
for v in cv[n]:
|
||||||
|
if "external" in v and v["external"] is not None:
|
||||||
|
del v["external"]
|
||||||
|
vv.append(v)
|
||||||
|
cv[n] = {str(i): vv[i] for i in range(len(vv))}
|
||||||
|
|
||||||
|
basics = [
|
||||||
|
("basic_salary_month", "salary_month"),
|
||||||
|
("expect_annual_salary_from", "expect_annual_salary"),
|
||||||
|
]
|
||||||
|
for n, t in basics:
|
||||||
|
if cv["basic"].get(n):
|
||||||
|
cv["basic"][t] = cv["basic"][n]
|
||||||
|
del cv["basic"][n]
|
||||||
|
|
||||||
|
work = sorted(
|
||||||
|
[v for _, v in cv.get("work", {}).items()],
|
||||||
|
key=lambda x: x.get("start_time", ""),
|
||||||
|
)
|
||||||
|
edu = sorted(
|
||||||
|
[v for _, v in cv.get("education", {}).items()],
|
||||||
|
key=lambda x: x.get("start_time", ""),
|
||||||
|
)
|
||||||
|
|
||||||
|
if work:
|
||||||
|
cv["basic"]["work_start_time"] = work[0].get("start_time", "")
|
||||||
|
cv["basic"]["management_experience"] = (
|
||||||
|
"Y"
|
||||||
|
if any([w.get("management_experience", "") == "Y" for w in work])
|
||||||
|
else "N"
|
||||||
|
)
|
||||||
|
cv["basic"]["annual_salary"] = work[-1].get("annual_salary_from", "0")
|
||||||
|
|
||||||
|
for n in [
|
||||||
|
"annual_salary_from",
|
||||||
|
"annual_salary_to",
|
||||||
|
"industry_name",
|
||||||
|
"position_name",
|
||||||
|
"responsibilities",
|
||||||
|
"corporation_type",
|
||||||
|
"scale",
|
||||||
|
"corporation_name",
|
||||||
|
]:
|
||||||
|
cv["basic"][n] = work[-1].get(n, "")
|
||||||
|
|
||||||
|
if edu:
|
||||||
|
for n in ["school_name", "discipline_name"]:
|
||||||
|
if n in edu[-1]:
|
||||||
|
cv["basic"][n] = edu[-1][n]
|
||||||
|
|
||||||
|
cv["basic"]["updated_at"] = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
||||||
|
if "contact" not in cv:
|
||||||
|
cv["contact"] = {}
|
||||||
|
if not cv["contact"].get("name"):
|
||||||
|
cv["contact"]["name"] = cv["basic"].get("name", "")
|
||||||
|
return cv
|
||||||
15
deepdoc/parser/resume/entities/__init__.py
Normal file
15
deepdoc/parser/resume/entities/__init__.py
Normal file
@@ -0,0 +1,15 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
128
deepdoc/parser/resume/entities/corporations.py
Normal file
128
deepdoc/parser/resume/entities/corporations.py
Normal file
@@ -0,0 +1,128 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import re
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import pandas as pd
|
||||||
|
from rag.nlp import rag_tokenizer
|
||||||
|
from . import regions
|
||||||
|
|
||||||
|
|
||||||
|
current_file_path = os.path.dirname(os.path.abspath(__file__))
|
||||||
|
GOODS = pd.read_csv(
|
||||||
|
os.path.join(current_file_path, "res/corp_baike_len.csv"), sep="\t", header=0
|
||||||
|
).fillna(0)
|
||||||
|
GOODS["cid"] = GOODS["cid"].astype(str)
|
||||||
|
GOODS = GOODS.set_index(["cid"])
|
||||||
|
CORP_TKS = json.load(
|
||||||
|
open(os.path.join(current_file_path, "res/corp.tks.freq.json"), "r",encoding="utf-8")
|
||||||
|
)
|
||||||
|
GOOD_CORP = json.load(open(os.path.join(current_file_path, "res/good_corp.json"), "r",encoding="utf-8"))
|
||||||
|
CORP_TAG = json.load(open(os.path.join(current_file_path, "res/corp_tag.json"), "r",encoding="utf-8"))
|
||||||
|
|
||||||
|
|
||||||
|
def baike(cid, default_v=0):
|
||||||
|
global GOODS
|
||||||
|
try:
|
||||||
|
return GOODS.loc[str(cid), "len"]
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
return default_v
|
||||||
|
|
||||||
|
|
||||||
|
def corpNorm(nm, add_region=True):
|
||||||
|
global CORP_TKS
|
||||||
|
if not nm or not isinstance(nm, str):
|
||||||
|
return ""
|
||||||
|
nm = rag_tokenizer.tradi2simp(rag_tokenizer.strQ2B(nm)).lower()
|
||||||
|
nm = re.sub(r"&", "&", nm)
|
||||||
|
nm = re.sub(r"[\(\)()\+'\"\t \*\\【】-]+", " ", nm)
|
||||||
|
nm = re.sub(
|
||||||
|
r"([—-]+.*| +co\..*|corp\..*| +inc\..*| +ltd.*)", "", nm, count=10000, flags=re.IGNORECASE
|
||||||
|
)
|
||||||
|
nm = re.sub(
|
||||||
|
r"(计算机|技术|(技术|科技|网络)*有限公司|公司|有限|研发中心|中国|总部)$",
|
||||||
|
"",
|
||||||
|
nm,
|
||||||
|
count=10000,
|
||||||
|
flags=re.IGNORECASE,
|
||||||
|
)
|
||||||
|
if not nm or (len(nm) < 5 and not regions.isName(nm[0:2])):
|
||||||
|
return nm
|
||||||
|
|
||||||
|
tks = rag_tokenizer.tokenize(nm).split()
|
||||||
|
reg = [t for i, t in enumerate(tks) if regions.isName(t) and (t != "中国" or i > 0)]
|
||||||
|
nm = ""
|
||||||
|
for t in tks:
|
||||||
|
if regions.isName(t) or t in CORP_TKS:
|
||||||
|
continue
|
||||||
|
if re.match(r"[0-9a-zA-Z\\,.]+", t) and re.match(r".*[0-9a-zA-Z\,.]+$", nm):
|
||||||
|
nm += " "
|
||||||
|
nm += t
|
||||||
|
|
||||||
|
r = re.search(r"^([^a-z0-9 \(\)&]{2,})[a-z ]{4,}$", nm.strip())
|
||||||
|
if r:
|
||||||
|
nm = r.group(1)
|
||||||
|
r = re.search(r"^([a-z ]{3,})[^a-z0-9 \(\)&]{2,}$", nm.strip())
|
||||||
|
if r:
|
||||||
|
nm = r.group(1)
|
||||||
|
return nm.strip() + (("" if not reg else "(%s)" % reg[0]) if add_region else "")
|
||||||
|
|
||||||
|
|
||||||
|
def rmNoise(n):
|
||||||
|
n = re.sub(r"[\((][^()()]+[))]", "", n)
|
||||||
|
n = re.sub(r"[,. &()()]+", "", n)
|
||||||
|
return n
|
||||||
|
|
||||||
|
|
||||||
|
GOOD_CORP = set([corpNorm(rmNoise(c), False) for c in GOOD_CORP])
|
||||||
|
for c, v in CORP_TAG.items():
|
||||||
|
cc = corpNorm(rmNoise(c), False)
|
||||||
|
if not cc:
|
||||||
|
logging.debug(c)
|
||||||
|
CORP_TAG = {corpNorm(rmNoise(c), False): v for c, v in CORP_TAG.items()}
|
||||||
|
|
||||||
|
|
||||||
|
def is_good(nm):
|
||||||
|
global GOOD_CORP
|
||||||
|
if nm.find("外派") >= 0:
|
||||||
|
return False
|
||||||
|
nm = rmNoise(nm)
|
||||||
|
nm = corpNorm(nm, False)
|
||||||
|
for n in GOOD_CORP:
|
||||||
|
if re.match(r"[0-9a-zA-Z]+$", n):
|
||||||
|
if n == nm:
|
||||||
|
return True
|
||||||
|
elif nm.find(n) >= 0:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def corp_tag(nm):
|
||||||
|
global CORP_TAG
|
||||||
|
nm = rmNoise(nm)
|
||||||
|
nm = corpNorm(nm, False)
|
||||||
|
for n in CORP_TAG.keys():
|
||||||
|
if re.match(r"[0-9a-zA-Z., ]+$", n):
|
||||||
|
if n == nm:
|
||||||
|
return CORP_TAG[n]
|
||||||
|
elif nm.find(n) >= 0:
|
||||||
|
if len(n) < 3 and len(nm) / len(n) >= 2:
|
||||||
|
continue
|
||||||
|
return CORP_TAG[n]
|
||||||
|
return []
|
||||||
44
deepdoc/parser/resume/entities/degrees.py
Normal file
44
deepdoc/parser/resume/entities/degrees.py
Normal file
@@ -0,0 +1,44 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
TBL = {
|
||||||
|
"94": "EMBA",
|
||||||
|
"6": "MBA",
|
||||||
|
"95": "MPA",
|
||||||
|
"92": "专升本",
|
||||||
|
"4": "专科",
|
||||||
|
"90": "中专",
|
||||||
|
"91": "中技",
|
||||||
|
"86": "初中",
|
||||||
|
"3": "博士",
|
||||||
|
"10": "博士后",
|
||||||
|
"1": "本科",
|
||||||
|
"2": "硕士",
|
||||||
|
"87": "职高",
|
||||||
|
"89": "高中",
|
||||||
|
}
|
||||||
|
|
||||||
|
TBL_ = {v: k for k, v in TBL.items()}
|
||||||
|
|
||||||
|
|
||||||
|
def get_name(id):
|
||||||
|
return TBL.get(str(id), "")
|
||||||
|
|
||||||
|
|
||||||
|
def get_id(nm):
|
||||||
|
if not nm:
|
||||||
|
return ""
|
||||||
|
return TBL_.get(nm.upper().strip(), "")
|
||||||
712
deepdoc/parser/resume/entities/industries.py
Normal file
712
deepdoc/parser/resume/entities/industries.py
Normal file
@@ -0,0 +1,712 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
TBL = {
|
||||||
|
"1": {"name": "IT/通信/电子", "parent": "0"},
|
||||||
|
"2": {"name": "互联网", "parent": "0"},
|
||||||
|
"3": {"name": "电子商务", "parent": "2"},
|
||||||
|
"4": {"name": "互联网金融", "parent": "2"},
|
||||||
|
"5": {"name": "网络游戏", "parent": "2"},
|
||||||
|
"6": {"name": "社交网络平台", "parent": "2"},
|
||||||
|
"7": {"name": "视频音乐", "parent": "2"},
|
||||||
|
"9": {"name": "安全", "parent": "2"},
|
||||||
|
"10": {"name": "云计算", "parent": "2"},
|
||||||
|
"12": {"name": "工具类客户端应用", "parent": "2"},
|
||||||
|
"13": {"name": "互联网广告", "parent": "2"},
|
||||||
|
"14": {"name": "企业互联网服务", "parent": "2"},
|
||||||
|
"16": {"name": "在线教育", "parent": "2"},
|
||||||
|
"17": {"name": "在线医疗", "parent": "2"},
|
||||||
|
"19": {"name": "B2B", "parent": "3"},
|
||||||
|
"20": {"name": "B2C", "parent": "3"},
|
||||||
|
"21": {"name": "C2C", "parent": "3"},
|
||||||
|
"22": {"name": "生活信息本地化", "parent": "3"},
|
||||||
|
"23": {"name": "在线旅游", "parent": "2"},
|
||||||
|
"24": {"name": "第三方支付", "parent": "4"},
|
||||||
|
"26": {"name": "客户端游戏", "parent": "5"},
|
||||||
|
"27": {"name": "网页游戏", "parent": "5"},
|
||||||
|
"28": {"name": "手机游戏", "parent": "5"},
|
||||||
|
"29": {"name": "微博", "parent": "6"},
|
||||||
|
"30": {"name": "社交网站", "parent": "6"},
|
||||||
|
"31": {"name": "在线视频", "parent": "7"},
|
||||||
|
"32": {"name": "在线音乐", "parent": "7"},
|
||||||
|
"35": {"name": "企业安全", "parent": "9"},
|
||||||
|
"36": {"name": "个人安全", "parent": "9"},
|
||||||
|
"37": {"name": "企业级云服务", "parent": "10"},
|
||||||
|
"38": {"name": "个人级云服务", "parent": "10"},
|
||||||
|
"43": {"name": "输入法", "parent": "12"},
|
||||||
|
"44": {"name": "浏览器", "parent": "12"},
|
||||||
|
"45": {"name": "词典", "parent": "12"},
|
||||||
|
"46": {"name": "播放器", "parent": "12"},
|
||||||
|
"47": {"name": "下载器", "parent": "12"},
|
||||||
|
"48": {"name": "IM", "parent": "12"},
|
||||||
|
"49": {"name": "广告服务", "parent": "13"},
|
||||||
|
"50": {"name": "第三方广告网络平台", "parent": "13"},
|
||||||
|
"51": {"name": "媒体代理", "parent": "13"},
|
||||||
|
"52": {"name": "创意代理", "parent": "13"},
|
||||||
|
"53": {"name": "IT-综合", "parent": "1"},
|
||||||
|
"71": {"name": "团购", "parent": "3"},
|
||||||
|
"72": {"name": "地图", "parent": "2"},
|
||||||
|
"73": {"name": "数据存储", "parent": "2"},
|
||||||
|
"414": {"name": "计算机软件", "parent": "1"},
|
||||||
|
"415": {"name": "计算机硬件", "parent": "1"},
|
||||||
|
"416": {"name": "计算机服务(系统、数据服务、维修)", "parent": "1"},
|
||||||
|
"417": {"name": "通信/电信/网络设备", "parent": "1"},
|
||||||
|
"418": {"name": "通信/电信运营、增值服务", "parent": "1"},
|
||||||
|
"419": {"name": "电子技术/半导体/集成电路", "parent": "1"},
|
||||||
|
"472": {"name": "P2P网贷", "parent": "4"},
|
||||||
|
"473": {"name": "互联网理财", "parent": "4"},
|
||||||
|
"474": {"name": "婚恋", "parent": "6"},
|
||||||
|
"476": {"name": "虚拟化", "parent": "10"},
|
||||||
|
"477": {"name": "邮箱", "parent": "12"},
|
||||||
|
"478": {"name": "商业智能", "parent": "14"},
|
||||||
|
"479": {"name": "企业建站", "parent": "14"},
|
||||||
|
"480": {"name": "安防", "parent": "14"},
|
||||||
|
"481": {"name": "网络营销", "parent": "2"},
|
||||||
|
"487": {"name": "智能终端", "parent": "2"},
|
||||||
|
"488": {"name": "移动互联网", "parent": "2"},
|
||||||
|
"489": {"name": "数字城市", "parent": "2"},
|
||||||
|
"490": {"name": "大数据", "parent": "2"},
|
||||||
|
"491": {"name": "互联网人力资源", "parent": "2"},
|
||||||
|
"492": {"name": "舆情监控", "parent": "2"},
|
||||||
|
"493": {"name": "移动营销", "parent": "481"},
|
||||||
|
"494": {"name": "微博营销", "parent": "481"},
|
||||||
|
"495": {"name": "精准营销", "parent": "481"},
|
||||||
|
"496": {"name": "海外营销", "parent": "481"},
|
||||||
|
"497": {"name": "微信营销", "parent": "481"},
|
||||||
|
"498": {"name": "智能手机", "parent": "487"},
|
||||||
|
"499": {"name": "可穿戴设备", "parent": "487"},
|
||||||
|
"500": {"name": "智能电视", "parent": "487"},
|
||||||
|
"501": {"name": "WAP", "parent": "488"},
|
||||||
|
"502": {"name": "物联网", "parent": "489"},
|
||||||
|
"503": {"name": "O2O", "parent": "489"},
|
||||||
|
"504": {"name": "数字出版", "parent": "489"},
|
||||||
|
"505": {"name": "搜索", "parent": "2"},
|
||||||
|
"506": {"name": "垂直搜索", "parent": "505"},
|
||||||
|
"507": {"name": "无线搜索", "parent": "505"},
|
||||||
|
"508": {"name": "网页搜索", "parent": "505"},
|
||||||
|
"509": {"name": "网址导航", "parent": "2"},
|
||||||
|
"510": {"name": "门户", "parent": "2"},
|
||||||
|
"511": {"name": "网络文学", "parent": "2"},
|
||||||
|
"512": {"name": "自媒体", "parent": "2"},
|
||||||
|
"513": {"name": "金融", "parent": "0"},
|
||||||
|
"514": {"name": "建筑与房地产", "parent": "0"},
|
||||||
|
"515": {"name": "专业服务", "parent": "0"},
|
||||||
|
"516": {"name": "教育培训", "parent": "0"},
|
||||||
|
"517": {"name": "文化传媒", "parent": "0"},
|
||||||
|
"518": {"name": "消费品", "parent": "0"},
|
||||||
|
"519": {"name": "工业", "parent": "0"},
|
||||||
|
"520": {"name": "交通物流", "parent": "0"},
|
||||||
|
"521": {"name": "贸易", "parent": "0"},
|
||||||
|
"522": {"name": "医药", "parent": "0"},
|
||||||
|
"523": {"name": "医疗器械", "parent": "522"},
|
||||||
|
"524": {"name": "保健品", "parent": "518"},
|
||||||
|
"525": {"name": "服务业", "parent": "0"},
|
||||||
|
"526": {"name": "能源/矿产/环保", "parent": "0"},
|
||||||
|
"527": {"name": "化工", "parent": "0"},
|
||||||
|
"528": {"name": "政府", "parent": "0"},
|
||||||
|
"529": {"name": "公共事业", "parent": "0"},
|
||||||
|
"530": {"name": "非盈利机构", "parent": "0"},
|
||||||
|
"531": {"name": "农业", "parent": "1131"},
|
||||||
|
"532": {"name": "林业", "parent": "1131"},
|
||||||
|
"533": {"name": "畜牧业", "parent": "1131"},
|
||||||
|
"534": {"name": "渔业", "parent": "1131"},
|
||||||
|
"535": {"name": "学术科研", "parent": "0"},
|
||||||
|
"536": {"name": "零售", "parent": "0"},
|
||||||
|
"537": {"name": "银行", "parent": "513"},
|
||||||
|
"538": {"name": "保险", "parent": "513"},
|
||||||
|
"539": {"name": "证券", "parent": "513"},
|
||||||
|
"540": {"name": "基金", "parent": "513"},
|
||||||
|
"541": {"name": "信托", "parent": "513"},
|
||||||
|
"542": {"name": "担保", "parent": "513"},
|
||||||
|
"543": {"name": "典当", "parent": "513"},
|
||||||
|
"544": {"name": "拍卖", "parent": "513"},
|
||||||
|
"545": {"name": "投资/融资", "parent": "513"},
|
||||||
|
"546": {"name": "期货", "parent": "513"},
|
||||||
|
"547": {"name": "房地产开发", "parent": "514"},
|
||||||
|
"548": {"name": "工程施工", "parent": "514"},
|
||||||
|
"549": {"name": "建筑设计", "parent": "514"},
|
||||||
|
"550": {"name": "房地产代理", "parent": "514"},
|
||||||
|
"551": {"name": "物业管理", "parent": "514"},
|
||||||
|
"552": {"name": "室内设计", "parent": "514"},
|
||||||
|
"553": {"name": "装修装潢", "parent": "514"},
|
||||||
|
"554": {"name": "市政工程", "parent": "514"},
|
||||||
|
"555": {"name": "工程造价", "parent": "514"},
|
||||||
|
"556": {"name": "工程监理", "parent": "514"},
|
||||||
|
"557": {"name": "环境工程", "parent": "514"},
|
||||||
|
"558": {"name": "园林景观", "parent": "514"},
|
||||||
|
"559": {"name": "法律", "parent": "515"},
|
||||||
|
"560": {"name": "人力资源", "parent": "515"},
|
||||||
|
"561": {"name": "会计", "parent": "1125"},
|
||||||
|
"562": {"name": "审计", "parent": "515"},
|
||||||
|
"563": {"name": "检测认证", "parent": "515"},
|
||||||
|
"565": {"name": "翻译", "parent": "515"},
|
||||||
|
"566": {"name": "中介", "parent": "515"},
|
||||||
|
"567": {"name": "咨询", "parent": "515"},
|
||||||
|
"568": {"name": "外包服务", "parent": "515"},
|
||||||
|
"569": {"name": "家教", "parent": "516"},
|
||||||
|
"570": {"name": "早教", "parent": "516"},
|
||||||
|
"571": {"name": "职业技能培训", "parent": "516"},
|
||||||
|
"572": {"name": "外语培训", "parent": "516"},
|
||||||
|
"573": {"name": "设计培训", "parent": "516"},
|
||||||
|
"574": {"name": "IT培训", "parent": "516"},
|
||||||
|
"575": {"name": "文艺体育培训", "parent": "516"},
|
||||||
|
"576": {"name": "学历教育", "parent": "516"},
|
||||||
|
"577": {"name": "管理培训", "parent": "516"},
|
||||||
|
"578": {"name": "民办基础教育", "parent": "516"},
|
||||||
|
"579": {"name": "广告", "parent": "517"},
|
||||||
|
"580": {"name": "媒体", "parent": "517"},
|
||||||
|
"581": {"name": "会展", "parent": "517"},
|
||||||
|
"582": {"name": "公关", "parent": "517"},
|
||||||
|
"583": {"name": "影视", "parent": "517"},
|
||||||
|
"584": {"name": "艺术", "parent": "517"},
|
||||||
|
"585": {"name": "文化传播", "parent": "517"},
|
||||||
|
"586": {"name": "娱乐", "parent": "517"},
|
||||||
|
"587": {"name": "体育", "parent": "517"},
|
||||||
|
"588": {"name": "出版", "parent": "517"},
|
||||||
|
"589": {"name": "休闲", "parent": "517"},
|
||||||
|
"590": {"name": "动漫", "parent": "517"},
|
||||||
|
"591": {"name": "市场推广", "parent": "517"},
|
||||||
|
"592": {"name": "市场研究", "parent": "517"},
|
||||||
|
"593": {"name": "食品", "parent": "1129"},
|
||||||
|
"594": {"name": "饮料", "parent": "1129"},
|
||||||
|
"595": {"name": "烟草", "parent": "1129"},
|
||||||
|
"596": {"name": "酒品", "parent": "518"},
|
||||||
|
"597": {"name": "服饰", "parent": "518"},
|
||||||
|
"598": {"name": "纺织", "parent": "518"},
|
||||||
|
"599": {"name": "化妆品", "parent": "1129"},
|
||||||
|
"600": {"name": "日用品", "parent": "1129"},
|
||||||
|
"601": {"name": "家电", "parent": "518"},
|
||||||
|
"602": {"name": "家具", "parent": "518"},
|
||||||
|
"603": {"name": "办公用品", "parent": "518"},
|
||||||
|
"604": {"name": "奢侈品", "parent": "518"},
|
||||||
|
"605": {"name": "珠宝", "parent": "518"},
|
||||||
|
"606": {"name": "数码产品", "parent": "518"},
|
||||||
|
"607": {"name": "玩具", "parent": "518"},
|
||||||
|
"608": {"name": "图书", "parent": "518"},
|
||||||
|
"609": {"name": "音像", "parent": "518"},
|
||||||
|
"610": {"name": "钟表", "parent": "518"},
|
||||||
|
"611": {"name": "箱包", "parent": "518"},
|
||||||
|
"612": {"name": "母婴", "parent": "518"},
|
||||||
|
"613": {"name": "营养保健", "parent": "518"},
|
||||||
|
"614": {"name": "户外用品", "parent": "518"},
|
||||||
|
"615": {"name": "健身器材", "parent": "518"},
|
||||||
|
"616": {"name": "乐器", "parent": "518"},
|
||||||
|
"617": {"name": "汽车用品", "parent": "518"},
|
||||||
|
"619": {"name": "厨具", "parent": "518"},
|
||||||
|
"620": {"name": "机械制造", "parent": "519"},
|
||||||
|
"621": {"name": "流体控制", "parent": "519"},
|
||||||
|
"622": {"name": "自动化控制", "parent": "519"},
|
||||||
|
"623": {"name": "仪器仪表", "parent": "519"},
|
||||||
|
"624": {"name": "航空/航天", "parent": "519"},
|
||||||
|
"625": {"name": "交通设施", "parent": "519"},
|
||||||
|
"626": {"name": "工业电子", "parent": "519"},
|
||||||
|
"627": {"name": "建材", "parent": "519"},
|
||||||
|
"628": {"name": "五金材料", "parent": "519"},
|
||||||
|
"629": {"name": "汽车", "parent": "519"},
|
||||||
|
"630": {"name": "印刷", "parent": "519"},
|
||||||
|
"631": {"name": "造纸", "parent": "519"},
|
||||||
|
"632": {"name": "包装", "parent": "519"},
|
||||||
|
"633": {"name": "原材料及加工", "parent": "519"},
|
||||||
|
"634": {"name": "物流", "parent": "520"},
|
||||||
|
"635": {"name": "仓储", "parent": "520"},
|
||||||
|
"636": {"name": "客运", "parent": "520"},
|
||||||
|
"637": {"name": "快递", "parent": "520"},
|
||||||
|
"638": {"name": "化学药", "parent": "522"},
|
||||||
|
"639": {"name": "中药", "parent": "522"},
|
||||||
|
"640": {"name": "生物制药", "parent": "522"},
|
||||||
|
"641": {"name": "兽药", "parent": "522"},
|
||||||
|
"642": {"name": "农药", "parent": "522"},
|
||||||
|
"643": {"name": "CRO", "parent": "522"},
|
||||||
|
"644": {"name": "消毒", "parent": "522"},
|
||||||
|
"645": {"name": "医药商业", "parent": "522"},
|
||||||
|
"646": {"name": "医疗服务", "parent": "522"},
|
||||||
|
"647": {"name": "医疗器械", "parent": "523"},
|
||||||
|
"648": {"name": "制药设备", "parent": "523"},
|
||||||
|
"649": {"name": "医用耗材", "parent": "523"},
|
||||||
|
"650": {"name": "手术器械", "parent": "523"},
|
||||||
|
"651": {"name": "保健器材", "parent": "524"},
|
||||||
|
"652": {"name": "性保健品", "parent": "524"},
|
||||||
|
"653": {"name": "医药保养", "parent": "524"},
|
||||||
|
"654": {"name": "医用保健", "parent": "524"},
|
||||||
|
"655": {"name": "酒店", "parent": "525"},
|
||||||
|
"656": {"name": "餐饮", "parent": "525"},
|
||||||
|
"657": {"name": "旅游", "parent": "525"},
|
||||||
|
"658": {"name": "生活服务", "parent": "525"},
|
||||||
|
"659": {"name": "保健服务", "parent": "525"},
|
||||||
|
"660": {"name": "运动健身", "parent": "525"},
|
||||||
|
"661": {"name": "家政服务", "parent": "525"},
|
||||||
|
"662": {"name": "婚庆服务", "parent": "525"},
|
||||||
|
"663": {"name": "租赁服务", "parent": "525"},
|
||||||
|
"664": {"name": "维修服务", "parent": "525"},
|
||||||
|
"665": {"name": "石油天然气", "parent": "526"},
|
||||||
|
"666": {"name": "电力", "parent": "526"},
|
||||||
|
"667": {"name": "新能源", "parent": "526"},
|
||||||
|
"668": {"name": "水利", "parent": "526"},
|
||||||
|
"669": {"name": "矿产", "parent": "526"},
|
||||||
|
"670": {"name": "采掘业", "parent": "526"},
|
||||||
|
"671": {"name": "冶炼", "parent": "526"},
|
||||||
|
"672": {"name": "环保", "parent": "526"},
|
||||||
|
"673": {"name": "无机化工原料", "parent": "527"},
|
||||||
|
"674": {"name": "有机化工原料", "parent": "527"},
|
||||||
|
"675": {"name": "精细化学品", "parent": "527"},
|
||||||
|
"676": {"name": "化工设备", "parent": "527"},
|
||||||
|
"677": {"name": "化工工程", "parent": "527"},
|
||||||
|
"678": {"name": "资产管理", "parent": "513"},
|
||||||
|
"679": {"name": "金融租赁", "parent": "513"},
|
||||||
|
"680": {"name": "征信及信评机构", "parent": "513"},
|
||||||
|
"681": {"name": "资产评估机构", "parent": "513"},
|
||||||
|
"683": {"name": "金融监管机构", "parent": "513"},
|
||||||
|
"684": {"name": "国际贸易", "parent": "521"},
|
||||||
|
"685": {"name": "海关", "parent": "521"},
|
||||||
|
"686": {"name": "购物中心", "parent": "536"},
|
||||||
|
"687": {"name": "超市", "parent": "536"},
|
||||||
|
"688": {"name": "便利店", "parent": "536"},
|
||||||
|
"689": {"name": "专卖店", "parent": "536"},
|
||||||
|
"690": {"name": "专业店", "parent": "536"},
|
||||||
|
"691": {"name": "百货店", "parent": "536"},
|
||||||
|
"692": {"name": "杂货店", "parent": "536"},
|
||||||
|
"693": {"name": "个人银行", "parent": "537"},
|
||||||
|
"695": {"name": "私人银行", "parent": "537"},
|
||||||
|
"696": {"name": "公司银行", "parent": "537"},
|
||||||
|
"697": {"name": "投资银行", "parent": "537"},
|
||||||
|
"698": {"name": "政策性银行", "parent": "537"},
|
||||||
|
"699": {"name": "中央银行", "parent": "537"},
|
||||||
|
"700": {"name": "人寿险", "parent": "538"},
|
||||||
|
"701": {"name": "财产险", "parent": "538"},
|
||||||
|
"702": {"name": "再保险", "parent": "538"},
|
||||||
|
"703": {"name": "养老险", "parent": "538"},
|
||||||
|
"704": {"name": "保险代理公司", "parent": "538"},
|
||||||
|
"705": {"name": "公募基金", "parent": "540"},
|
||||||
|
"707": {"name": "私募基金", "parent": "540"},
|
||||||
|
"708": {"name": "第三方理财", "parent": "679"},
|
||||||
|
"709": {"name": "资产管理公司", "parent": "679"},
|
||||||
|
"711": {"name": "房产中介", "parent": "566"},
|
||||||
|
"712": {"name": "职业中介", "parent": "566"},
|
||||||
|
"713": {"name": "婚姻中介", "parent": "566"},
|
||||||
|
"714": {"name": "战略咨询", "parent": "567"},
|
||||||
|
"715": {"name": "投资咨询", "parent": "567"},
|
||||||
|
"716": {"name": "心理咨询", "parent": "567"},
|
||||||
|
"717": {"name": "留学移民咨询", "parent": "567"},
|
||||||
|
"718": {"name": "工商注册代理", "parent": "568"},
|
||||||
|
"719": {"name": "商标专利代理", "parent": "568"},
|
||||||
|
"720": {"name": "财务代理", "parent": "568"},
|
||||||
|
"721": {"name": "工程机械", "parent": "620"},
|
||||||
|
"722": {"name": "农业机械", "parent": "620"},
|
||||||
|
"723": {"name": "海工设备", "parent": "620"},
|
||||||
|
"724": {"name": "包装机械", "parent": "620"},
|
||||||
|
"725": {"name": "印刷机械", "parent": "620"},
|
||||||
|
"726": {"name": "数控机床", "parent": "620"},
|
||||||
|
"727": {"name": "矿山机械", "parent": "620"},
|
||||||
|
"728": {"name": "水泵", "parent": "621"},
|
||||||
|
"729": {"name": "管道", "parent": "621"},
|
||||||
|
"730": {"name": "阀门", "parent": "621"},
|
||||||
|
"732": {"name": "压缩机", "parent": "621"},
|
||||||
|
"733": {"name": "集散控制系统", "parent": "622"},
|
||||||
|
"734": {"name": "远程控制", "parent": "622"},
|
||||||
|
"735": {"name": "液压系统", "parent": "622"},
|
||||||
|
"736": {"name": "楼宇智能化", "parent": "622"},
|
||||||
|
"737": {"name": "飞机制造", "parent": "624"},
|
||||||
|
"738": {"name": "航空公司", "parent": "624"},
|
||||||
|
"739": {"name": "发动机", "parent": "624"},
|
||||||
|
"740": {"name": "复合材料", "parent": "624"},
|
||||||
|
"741": {"name": "高铁", "parent": "625"},
|
||||||
|
"742": {"name": "地铁", "parent": "625"},
|
||||||
|
"743": {"name": "信号传输", "parent": "625"},
|
||||||
|
"745": {"name": "结构材料", "parent": "627"},
|
||||||
|
"746": {"name": "装饰材料", "parent": "627"},
|
||||||
|
"747": {"name": "专用材料", "parent": "627"},
|
||||||
|
"749": {"name": "经销商集团", "parent": "629"},
|
||||||
|
"750": {"name": "整车制造", "parent": "629"},
|
||||||
|
"751": {"name": "汽车零配件", "parent": "629"},
|
||||||
|
"752": {"name": "外型设计", "parent": "629"},
|
||||||
|
"753": {"name": "平版印刷", "parent": "630"},
|
||||||
|
"754": {"name": "凸版印刷", "parent": "630"},
|
||||||
|
"755": {"name": "凹版印刷", "parent": "630"},
|
||||||
|
"756": {"name": "孔版印刷", "parent": "630"},
|
||||||
|
"757": {"name": "印刷用纸", "parent": "631"},
|
||||||
|
"758": {"name": "书写、制图及复制用纸", "parent": "631"},
|
||||||
|
"759": {"name": "包装用纸", "parent": "631"},
|
||||||
|
"760": {"name": "生活、卫生及装饰用纸", "parent": "631"},
|
||||||
|
"761": {"name": "技术用纸", "parent": "631"},
|
||||||
|
"762": {"name": "加工纸原纸", "parent": "631"},
|
||||||
|
"763": {"name": "食品包装", "parent": "632"},
|
||||||
|
"764": {"name": "医药包装", "parent": "632"},
|
||||||
|
"765": {"name": "日化包装", "parent": "632"},
|
||||||
|
"766": {"name": "物流包装", "parent": "632"},
|
||||||
|
"767": {"name": "礼品包装", "parent": "632"},
|
||||||
|
"768": {"name": "电子五金包装", "parent": "632"},
|
||||||
|
"769": {"name": "汽车服务", "parent": "525"},
|
||||||
|
"770": {"name": "汽车保养", "parent": "769"},
|
||||||
|
"771": {"name": "租车", "parent": "769"},
|
||||||
|
"773": {"name": "出租车", "parent": "769"},
|
||||||
|
"774": {"name": "代驾", "parent": "769"},
|
||||||
|
"775": {"name": "发电", "parent": "666"},
|
||||||
|
"777": {"name": "输配电", "parent": "666"},
|
||||||
|
"779": {"name": "风电", "parent": "667"},
|
||||||
|
"780": {"name": "光伏/太阳能", "parent": "667"},
|
||||||
|
"781": {"name": "生物质发电", "parent": "667"},
|
||||||
|
"782": {"name": "煤化工", "parent": "667"},
|
||||||
|
"783": {"name": "垃圾发电", "parent": "667"},
|
||||||
|
"784": {"name": "核电", "parent": "667"},
|
||||||
|
"785": {"name": "能源矿产", "parent": "669"},
|
||||||
|
"786": {"name": "金属矿产", "parent": "669"},
|
||||||
|
"787": {"name": "非金属矿产", "parent": "669"},
|
||||||
|
"788": {"name": "水气矿产", "parent": "669"},
|
||||||
|
"789": {"name": "锅炉", "parent": "775"},
|
||||||
|
"790": {"name": "发电机", "parent": "775"},
|
||||||
|
"791": {"name": "汽轮机", "parent": "775"},
|
||||||
|
"792": {"name": "燃机", "parent": "775"},
|
||||||
|
"793": {"name": "冷却", "parent": "775"},
|
||||||
|
"794": {"name": "电力设计院", "parent": "775"},
|
||||||
|
"795": {"name": "高压输配电", "parent": "777"},
|
||||||
|
"796": {"name": "中压输配电", "parent": "777"},
|
||||||
|
"797": {"name": "低压输配电", "parent": "777"},
|
||||||
|
"798": {"name": "继电保护", "parent": "777"},
|
||||||
|
"799": {"name": "智能电网", "parent": "777"},
|
||||||
|
"800": {"name": "小学", "parent": "516"},
|
||||||
|
"801": {"name": "电动车", "parent": "519"},
|
||||||
|
"802": {"name": "皮具箱包", "parent": "518"},
|
||||||
|
"803": {"name": "医药制造", "parent": "522"},
|
||||||
|
"804": {"name": "电器销售", "parent": "536"},
|
||||||
|
"805": {"name": "塑料制品", "parent": "527"},
|
||||||
|
"806": {"name": "公益基金会", "parent": "530"},
|
||||||
|
"807": {"name": "美发服务", "parent": "525"},
|
||||||
|
"808": {"name": "农业养殖", "parent": "531"},
|
||||||
|
"809": {"name": "金融服务", "parent": "513"},
|
||||||
|
"810": {"name": "商业地产综合体", "parent": "514"},
|
||||||
|
"811": {"name": "美容服务", "parent": "525"},
|
||||||
|
"812": {"name": "灯饰", "parent": "518"},
|
||||||
|
"813": {"name": "油墨颜料产品", "parent": "527"},
|
||||||
|
"814": {"name": "眼镜制造", "parent": "518"},
|
||||||
|
"815": {"name": "农业生物技术", "parent": "531"},
|
||||||
|
"816": {"name": "体育用品", "parent": "518"},
|
||||||
|
"817": {"name": "保健用品", "parent": "524"},
|
||||||
|
"818": {"name": "化学化工产品", "parent": "527"},
|
||||||
|
"819": {"name": "饲料", "parent": "531"},
|
||||||
|
"821": {"name": "保安服务", "parent": "525"},
|
||||||
|
"822": {"name": "干细胞技术", "parent": "522"},
|
||||||
|
"824": {"name": "农药化肥", "parent": "527"},
|
||||||
|
"825": {"name": "卫生洁具", "parent": "518"},
|
||||||
|
"826": {"name": "体育器材、场馆", "parent": "518"},
|
||||||
|
"827": {"name": "饲料加工", "parent": "531"},
|
||||||
|
"828": {"name": "测绘服务", "parent": "529"},
|
||||||
|
"830": {"name": "金属船舶制造", "parent": "519"},
|
||||||
|
"831": {"name": "基因工程", "parent": "522"},
|
||||||
|
"832": {"name": "花卉服务", "parent": "536"},
|
||||||
|
"833": {"name": "农业种植", "parent": "531"},
|
||||||
|
"834": {"name": "皮革制品", "parent": "518"},
|
||||||
|
"835": {"name": "地理信息加工服务", "parent": "529"},
|
||||||
|
"836": {"name": "机器人", "parent": "519"},
|
||||||
|
"837": {"name": "礼品", "parent": "518"},
|
||||||
|
"838": {"name": "理发及美容服务", "parent": "525"},
|
||||||
|
"839": {"name": "其他清洁服务", "parent": "525"},
|
||||||
|
"840": {"name": "硅胶材料", "parent": "527"},
|
||||||
|
"841": {"name": "茶叶销售", "parent": "518"},
|
||||||
|
"842": {"name": "彩票活动", "parent": "529"},
|
||||||
|
"843": {"name": "化妆培训", "parent": "516"},
|
||||||
|
"844": {"name": "鞋业", "parent": "518"},
|
||||||
|
"845": {"name": "酒店用品", "parent": "518"},
|
||||||
|
"846": {"name": "复合材料", "parent": "527"},
|
||||||
|
"847": {"name": "房地产工程建设", "parent": "548"},
|
||||||
|
"848": {"name": "知识产权服务", "parent": "559"},
|
||||||
|
"849": {"name": "新型建材", "parent": "627"},
|
||||||
|
"850": {"name": "企业投资咨询", "parent": "567"},
|
||||||
|
"851": {"name": "含乳饮料和植物蛋白饮料制造", "parent": "594"},
|
||||||
|
"852": {"name": "汽车检测设备", "parent": "629"},
|
||||||
|
"853": {"name": "手机通讯器材", "parent": "417"},
|
||||||
|
"854": {"name": "环保材料", "parent": "672"},
|
||||||
|
"855": {"name": "交通设施", "parent": "554"},
|
||||||
|
"856": {"name": "电子器件", "parent": "419"},
|
||||||
|
"857": {"name": "啤酒", "parent": "594"},
|
||||||
|
"858": {"name": "生态旅游", "parent": "657"},
|
||||||
|
"859": {"name": "自动化设备", "parent": "626"},
|
||||||
|
"860": {"name": "软件开发", "parent": "414"},
|
||||||
|
"861": {"name": "葡萄酒销售", "parent": "594"},
|
||||||
|
"862": {"name": "钢材", "parent": "633"},
|
||||||
|
"863": {"name": "餐饮培训", "parent": "656"},
|
||||||
|
"864": {"name": "速冻食品", "parent": "593"},
|
||||||
|
"865": {"name": "空气环保", "parent": "672"},
|
||||||
|
"866": {"name": "互联网房地产经纪服务", "parent": "550"},
|
||||||
|
"867": {"name": "食品添加剂", "parent": "593"},
|
||||||
|
"868": {"name": "演艺传播", "parent": "585"},
|
||||||
|
"869": {"name": "信用卡", "parent": "537"},
|
||||||
|
"870": {"name": "报纸期刊广告", "parent": "579"},
|
||||||
|
"871": {"name": "摄影", "parent": "525"},
|
||||||
|
"872": {"name": "手机软件", "parent": "414"},
|
||||||
|
"873": {"name": "地坪建材", "parent": "627"},
|
||||||
|
"874": {"name": "企业管理咨询", "parent": "567"},
|
||||||
|
"875": {"name": "幼儿教育", "parent": "570"},
|
||||||
|
"876": {"name": "系统集成", "parent": "416"},
|
||||||
|
"877": {"name": "皮革服饰", "parent": "597"},
|
||||||
|
"878": {"name": "保健食品", "parent": "593"},
|
||||||
|
"879": {"name": "叉车", "parent": "620"},
|
||||||
|
"880": {"name": "厨卫电器", "parent": "601"},
|
||||||
|
"882": {"name": "地暖设备", "parent": "627"},
|
||||||
|
"883": {"name": "钢结构制造", "parent": "548"},
|
||||||
|
"884": {"name": "投影机", "parent": "606"},
|
||||||
|
"885": {"name": "啤酒销售", "parent": "594"},
|
||||||
|
"886": {"name": "度假村旅游", "parent": "657"},
|
||||||
|
"887": {"name": "电力元件设备", "parent": "626"},
|
||||||
|
"888": {"name": "管理软件", "parent": "414"},
|
||||||
|
"889": {"name": "轴承", "parent": "628"},
|
||||||
|
"890": {"name": "餐饮设备", "parent": "656"},
|
||||||
|
"891": {"name": "肉制品及副产品加工", "parent": "593"},
|
||||||
|
"892": {"name": "艺术收藏品投资交易", "parent": "584"},
|
||||||
|
"893": {"name": "净水器", "parent": "601"},
|
||||||
|
"894": {"name": "进口食品", "parent": "593"},
|
||||||
|
"895": {"name": "娱乐文化传播", "parent": "585"},
|
||||||
|
"896": {"name": "文化传播", "parent": "585"},
|
||||||
|
"897": {"name": "商旅传媒", "parent": "580"},
|
||||||
|
"898": {"name": "广告设计制作", "parent": "579"},
|
||||||
|
"899": {"name": "金属丝绳及其制品制造", "parent": "627"},
|
||||||
|
"900": {"name": "建筑涂料", "parent": "627"},
|
||||||
|
"901": {"name": "抵押贷款", "parent": "543"},
|
||||||
|
"902": {"name": "早教", "parent": "570"},
|
||||||
|
"903": {"name": "电影放映", "parent": "583"},
|
||||||
|
"904": {"name": "内衣服饰", "parent": "597"},
|
||||||
|
"905": {"name": "无线网络通信", "parent": "418"},
|
||||||
|
"906": {"name": "记忆卡", "parent": "415"},
|
||||||
|
"907": {"name": "女装服饰", "parent": "597"},
|
||||||
|
"908": {"name": "建筑机械", "parent": "620"},
|
||||||
|
"909": {"name": "制冷电器", "parent": "601"},
|
||||||
|
"910": {"name": "通信设备", "parent": "417"},
|
||||||
|
"911": {"name": "空调设备", "parent": "601"},
|
||||||
|
"912": {"name": "建筑装饰", "parent": "553"},
|
||||||
|
"913": {"name": "办公设备", "parent": "603"},
|
||||||
|
"916": {"name": "数据处理软件", "parent": "414"},
|
||||||
|
"917": {"name": "葡萄酒贸易", "parent": "594"},
|
||||||
|
"918": {"name": "通讯器材", "parent": "417"},
|
||||||
|
"919": {"name": "铜业", "parent": "633"},
|
||||||
|
"920": {"name": "食堂", "parent": "656"},
|
||||||
|
"921": {"name": "糖果零食", "parent": "593"},
|
||||||
|
"922": {"name": "文化艺术传播", "parent": "584"},
|
||||||
|
"923": {"name": "太阳能电器", "parent": "601"},
|
||||||
|
"924": {"name": "药品零售", "parent": "645"},
|
||||||
|
"925": {"name": "果蔬食品", "parent": "593"},
|
||||||
|
"926": {"name": "文化活动策划", "parent": "585"},
|
||||||
|
"928": {"name": "汽车广告", "parent": "657"},
|
||||||
|
"929": {"name": "条码设备", "parent": "630"},
|
||||||
|
"930": {"name": "建筑石材", "parent": "627"},
|
||||||
|
"931": {"name": "贵金属", "parent": "545"},
|
||||||
|
"932": {"name": "体育", "parent": "660"},
|
||||||
|
"933": {"name": "金融信息服务", "parent": "414"},
|
||||||
|
"934": {"name": "玻璃建材", "parent": "627"},
|
||||||
|
"935": {"name": "家教", "parent": "569"},
|
||||||
|
"936": {"name": "歌舞厅娱乐活动", "parent": "586"},
|
||||||
|
"937": {"name": "计算机服务器", "parent": "415"},
|
||||||
|
"938": {"name": "管道", "parent": "627"},
|
||||||
|
"939": {"name": "婴幼儿服饰", "parent": "597"},
|
||||||
|
"940": {"name": "热水器", "parent": "601"},
|
||||||
|
"941": {"name": "计算机及零部件制造", "parent": "415"},
|
||||||
|
"942": {"name": "钢铁贸易", "parent": "633"},
|
||||||
|
"944": {"name": "包装材料", "parent": "632"},
|
||||||
|
"945": {"name": "计算机办公设备", "parent": "603"},
|
||||||
|
"946": {"name": "白酒", "parent": "594"},
|
||||||
|
"948": {"name": "发动机", "parent": "620"},
|
||||||
|
"949": {"name": "快餐服务", "parent": "656"},
|
||||||
|
"950": {"name": "酒类销售", "parent": "594"},
|
||||||
|
"951": {"name": "电子产品、机电设备", "parent": "626"},
|
||||||
|
"952": {"name": "激光设备", "parent": "626"},
|
||||||
|
"953": {"name": "餐饮策划", "parent": "656"},
|
||||||
|
"954": {"name": "饮料、食品", "parent": "594"},
|
||||||
|
"955": {"name": "文化娱乐经纪", "parent": "585"},
|
||||||
|
"956": {"name": "天然气", "parent": "665"},
|
||||||
|
"957": {"name": "农副食品", "parent": "593"},
|
||||||
|
"958": {"name": "艺术表演", "parent": "585"},
|
||||||
|
"959": {"name": "石膏、水泥制品及类似制品制造", "parent": "627"},
|
||||||
|
"960": {"name": "橱柜", "parent": "602"},
|
||||||
|
"961": {"name": "管理培训", "parent": "577"},
|
||||||
|
"962": {"name": "男装服饰", "parent": "597"},
|
||||||
|
"963": {"name": "化肥制造", "parent": "675"},
|
||||||
|
"964": {"name": "童装服饰", "parent": "597"},
|
||||||
|
"965": {"name": "电源电池", "parent": "626"},
|
||||||
|
"966": {"name": "家电维修", "parent": "664"},
|
||||||
|
"967": {"name": "光电子器件", "parent": "419"},
|
||||||
|
"968": {"name": "旅行社服务", "parent": "657"},
|
||||||
|
"969": {"name": "电线、电缆制造", "parent": "626"},
|
||||||
|
"970": {"name": "软件开发、信息系统集成", "parent": "419"},
|
||||||
|
"971": {"name": "白酒制造", "parent": "594"},
|
||||||
|
"973": {"name": "甜品服务", "parent": "656"},
|
||||||
|
"974": {"name": "糕点、面包制造", "parent": "593"},
|
||||||
|
"975": {"name": "木工机械", "parent": "620"},
|
||||||
|
"976": {"name": "酒吧服务", "parent": "656"},
|
||||||
|
"977": {"name": "火腿肠", "parent": "593"},
|
||||||
|
"978": {"name": "广告策划推广", "parent": "579"},
|
||||||
|
"979": {"name": "新能源产品和生产装备制造", "parent": "667"},
|
||||||
|
"980": {"name": "调味品", "parent": "593"},
|
||||||
|
"981": {"name": "礼仪表演", "parent": "585"},
|
||||||
|
"982": {"name": "劳务派遣", "parent": "560"},
|
||||||
|
"983": {"name": "建材零售", "parent": "627"},
|
||||||
|
"984": {"name": "商品交易中心", "parent": "545"},
|
||||||
|
"985": {"name": "体育推广", "parent": "585"},
|
||||||
|
"986": {"name": "茶饮料及其他饮料制造", "parent": "594"},
|
||||||
|
"987": {"name": "金属建材", "parent": "627"},
|
||||||
|
"988": {"name": "职业技能培训", "parent": "571"},
|
||||||
|
"989": {"name": "网吧活动", "parent": "586"},
|
||||||
|
"990": {"name": "洗衣服务", "parent": "658"},
|
||||||
|
"991": {"name": "管道工程", "parent": "554"},
|
||||||
|
"992": {"name": "通信工程", "parent": "417"},
|
||||||
|
"993": {"name": "电子元器件", "parent": "626"},
|
||||||
|
"994": {"name": "电子设备", "parent": "419"},
|
||||||
|
"995": {"name": "茶馆服务", "parent": "656"},
|
||||||
|
"996": {"name": "旅游开发", "parent": "657"},
|
||||||
|
"997": {"name": "视频通讯", "parent": "417"},
|
||||||
|
"998": {"name": "白酒销售", "parent": "594"},
|
||||||
|
"1000": {"name": "咖啡馆服务", "parent": "656"},
|
||||||
|
"1001": {"name": "食品零售", "parent": "593"},
|
||||||
|
"1002": {"name": "健康疗养旅游", "parent": "655"},
|
||||||
|
"1003": {"name": "粮油食品", "parent": "593"},
|
||||||
|
"1004": {"name": "儿童教育影视", "parent": "583"},
|
||||||
|
"1005": {"name": "新能源发电", "parent": "667"},
|
||||||
|
"1006": {"name": "旅游策划", "parent": "657"},
|
||||||
|
"1007": {"name": "绘画", "parent": "575"},
|
||||||
|
"1008": {"name": "方便面及其他方便食品", "parent": "593"},
|
||||||
|
"1009": {"name": "房地产经纪", "parent": "550"},
|
||||||
|
"1010": {"name": "母婴家政", "parent": "661"},
|
||||||
|
"1011": {"name": "居家养老健康服务", "parent": "661"},
|
||||||
|
"1012": {"name": "文化艺术投资", "parent": "545"},
|
||||||
|
"1013": {"name": "运动健身", "parent": "660"},
|
||||||
|
"1014": {"name": "瓶(罐)装饮用水制造", "parent": "594"},
|
||||||
|
"1015": {"name": "金属门窗", "parent": "627"},
|
||||||
|
"1016": {"name": "机动车检测", "parent": "563"},
|
||||||
|
"1017": {"name": "货物运输", "parent": "634"},
|
||||||
|
"1018": {"name": "服饰专卖", "parent": "690"},
|
||||||
|
"1019": {"name": "酒店服装", "parent": "597"},
|
||||||
|
"1020": {"name": "通讯软件", "parent": "417"},
|
||||||
|
"1021": {"name": "消防工程", "parent": "554"},
|
||||||
|
"1022": {"name": "嵌入式电子系统", "parent": "419"},
|
||||||
|
"1023": {"name": "航空票务", "parent": "636"},
|
||||||
|
"1024": {"name": "电气设备", "parent": "626"},
|
||||||
|
"1025": {"name": "酒业贸易", "parent": "594"},
|
||||||
|
"1027": {"name": "其他饮料及冷饮服务", "parent": "656"},
|
||||||
|
"1028": {"name": "乳制品", "parent": "593"},
|
||||||
|
"1029": {"name": "新闻期刊出版", "parent": "588"},
|
||||||
|
"1030": {"name": "水污染治理", "parent": "672"},
|
||||||
|
"1031": {"name": "谷物食品", "parent": "593"},
|
||||||
|
"1032": {"name": "数字动漫设计制造服务", "parent": "590"},
|
||||||
|
"1033": {"name": "医院", "parent": "646"},
|
||||||
|
"1034": {"name": "旅游广告", "parent": "657"},
|
||||||
|
"1035": {"name": "办公家具", "parent": "602"},
|
||||||
|
"1036": {"name": "房地产营销策划", "parent": "550"},
|
||||||
|
"1037": {"name": "保洁家政", "parent": "661"},
|
||||||
|
"1038": {"name": "水泥制造", "parent": "627"},
|
||||||
|
"1039": {"name": "市场研究咨询", "parent": "567"},
|
||||||
|
"1040": {"name": "驾校", "parent": "571"},
|
||||||
|
"1041": {"name": "正餐服务", "parent": "656"},
|
||||||
|
"1043": {"name": "机动车燃油", "parent": "665"},
|
||||||
|
"1044": {"name": "食品", "parent": "593"},
|
||||||
|
"1045": {"name": "新能源汽车", "parent": "629"},
|
||||||
|
"1046": {"name": "手机无线网络推广", "parent": "417"},
|
||||||
|
"1047": {"name": "环保设备", "parent": "672"},
|
||||||
|
"1048": {"name": "通讯工程", "parent": "418"},
|
||||||
|
"1049": {"name": "半导体集成电路", "parent": "419"},
|
||||||
|
"1050": {"name": "航空服务", "parent": "636"},
|
||||||
|
"1051": {"name": "电机设备", "parent": "626"},
|
||||||
|
"1052": {"name": "档案软件", "parent": "414"},
|
||||||
|
"1053": {"name": "冷链物流服务", "parent": "634"},
|
||||||
|
"1054": {"name": "小吃服务", "parent": "656"},
|
||||||
|
"1055": {"name": "水产品加工", "parent": "593"},
|
||||||
|
"1056": {"name": "图书出版", "parent": "588"},
|
||||||
|
"1057": {"name": "固体废物治理", "parent": "672"},
|
||||||
|
"1059": {"name": "坚果食品", "parent": "593"},
|
||||||
|
"1060": {"name": "广告传媒", "parent": "579"},
|
||||||
|
"1061": {"name": "电梯", "parent": "622"},
|
||||||
|
"1062": {"name": "社区医疗与卫生院", "parent": "646"},
|
||||||
|
"1063": {"name": "广告、印刷包装", "parent": "630"},
|
||||||
|
"1064": {"name": "婚纱礼服", "parent": "662"},
|
||||||
|
"1065": {"name": "地毯", "parent": "602"},
|
||||||
|
"1066": {"name": "互联网物业", "parent": "551"},
|
||||||
|
"1067": {"name": "跨境电商", "parent": "3"},
|
||||||
|
"1068": {"name": "信息安全、系统集成", "parent": "9"},
|
||||||
|
"1069": {"name": "专用汽车制造", "parent": "750"},
|
||||||
|
"1070": {"name": "商品贸易", "parent": "3"},
|
||||||
|
"1071": {"name": "墙壁装饰材料", "parent": "746"},
|
||||||
|
"1072": {"name": "窗帘装饰材料", "parent": "746"},
|
||||||
|
"1073": {"name": "电子商务、本地生活服务", "parent": "3"},
|
||||||
|
"1075": {"name": "白酒电子商务", "parent": "3"},
|
||||||
|
"1076": {"name": "商品贸易、电子商务", "parent": "3"},
|
||||||
|
"1077": {"name": "木质装饰材料", "parent": "746"},
|
||||||
|
"1078": {"name": "电子商务、汽车电商交易平台", "parent": "3"},
|
||||||
|
"1079": {"name": "汽车轮胎", "parent": "751"},
|
||||||
|
"1080": {"name": "气体压缩机械制造", "parent": "732"},
|
||||||
|
"1081": {"name": "家装家具电子商务", "parent": "3"},
|
||||||
|
"1082": {"name": "化妆品电子商务", "parent": "3"},
|
||||||
|
"1083": {"name": "汽车销售", "parent": "749"},
|
||||||
|
"1084": {"name": "新闻资讯网站", "parent": "510"},
|
||||||
|
"1085": {"name": "母婴电商", "parent": "3"},
|
||||||
|
"1086": {"name": "电商商务、收藏品交易", "parent": "3"},
|
||||||
|
"1088": {"name": "电子商务、数码产品", "parent": "3"},
|
||||||
|
"1089": {"name": "二手车交易", "parent": "749"},
|
||||||
|
"1090": {"name": "游戏制作服务", "parent": "5"},
|
||||||
|
"1091": {"name": "母婴服务", "parent": "510"},
|
||||||
|
"1092": {"name": "家具电子商务", "parent": "3"},
|
||||||
|
"1093": {"name": "汽车配件电子商务", "parent": "3"},
|
||||||
|
"1094": {"name": "输配电设备", "parent": "777"},
|
||||||
|
"1095": {"name": "矿山设备", "parent": "727"},
|
||||||
|
"1096": {"name": "机床机械", "parent": "726"},
|
||||||
|
"1097": {"name": "农产品电商", "parent": "3"},
|
||||||
|
"1098": {"name": "陶瓷装饰材料", "parent": "746"},
|
||||||
|
"1099": {"name": "车载联网设备", "parent": "487"},
|
||||||
|
"1100": {"name": "汽车销售电子商务", "parent": "3"},
|
||||||
|
"1101": {"name": "石油设备", "parent": "730"},
|
||||||
|
"1102": {"name": "智能家居", "parent": "487"},
|
||||||
|
"1103": {"name": "散热器", "parent": "751"},
|
||||||
|
"1104": {"name": "电力工程", "parent": "775"},
|
||||||
|
"1105": {"name": "生鲜电商", "parent": "3"},
|
||||||
|
"1106": {"name": "互联网数据服务", "parent": "490"},
|
||||||
|
"1107": {"name": "房车、商务车销售", "parent": "749"},
|
||||||
|
"1108": {"name": "茶叶电子商务", "parent": "3"},
|
||||||
|
"1109": {"name": "酒类电子商务", "parent": "3"},
|
||||||
|
"1110": {"name": "阀门", "parent": "730"},
|
||||||
|
"1111": {"name": "食品电商", "parent": "3"},
|
||||||
|
"1112": {"name": "儿童摄影", "parent": "871"},
|
||||||
|
"1113": {"name": "广告摄影", "parent": "871"},
|
||||||
|
"1114": {"name": "婚纱摄影", "parent": "871"},
|
||||||
|
"1115": {"name": "模具制造", "parent": "620"},
|
||||||
|
"1116": {"name": "汽车模具", "parent": "629"},
|
||||||
|
"1117": {"name": "认证咨询", "parent": "567"},
|
||||||
|
"1118": {"name": "数字视觉制作服务", "parent": "590"},
|
||||||
|
"1119": {"name": "牙科及医疗器械", "parent": "646"},
|
||||||
|
"1120": {"name": "猎头招聘", "parent": "560"},
|
||||||
|
"1121": {"name": "家居", "parent": "518"},
|
||||||
|
"1122": {"name": "收藏品", "parent": "518"},
|
||||||
|
"1123": {"name": "首饰", "parent": "518"},
|
||||||
|
"1124": {"name": "工艺品", "parent": "518"},
|
||||||
|
"1125": {"name": "财务", "parent": "515"},
|
||||||
|
"1126": {"name": "税务", "parent": "515"},
|
||||||
|
"1127": {"name": "分类信息", "parent": "2"},
|
||||||
|
"1128": {"name": "宠物", "parent": "0"},
|
||||||
|
"1129": {"name": "快消品", "parent": "518"},
|
||||||
|
"1130": {"name": "人工智能", "parent": "2"},
|
||||||
|
"1131": {"name": "农/林/牧/渔", "parent": "0"},
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def get_names(id):
|
||||||
|
id = str(id)
|
||||||
|
nms = []
|
||||||
|
d = TBL.get(id)
|
||||||
|
if not d:
|
||||||
|
return []
|
||||||
|
nms.append(d["name"])
|
||||||
|
p = get_names(d["parent"])
|
||||||
|
if p:
|
||||||
|
nms.extend(p)
|
||||||
|
return nms
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
print(get_names("1119"))
|
||||||
789
deepdoc/parser/resume/entities/regions.py
Normal file
789
deepdoc/parser/resume/entities/regions.py
Normal file
@@ -0,0 +1,789 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import re
|
||||||
|
|
||||||
|
TBL = {
|
||||||
|
"2": {"name": "北京", "parent": "1"},
|
||||||
|
"3": {"name": "天津", "parent": "1"},
|
||||||
|
"4": {"name": "河北", "parent": "1"},
|
||||||
|
"5": {"name": "山西", "parent": "1"},
|
||||||
|
"6": {"name": "内蒙古", "parent": "1"},
|
||||||
|
"7": {"name": "辽宁", "parent": "1"},
|
||||||
|
"8": {"name": "吉林", "parent": "1"},
|
||||||
|
"9": {"name": "黑龙江", "parent": "1"},
|
||||||
|
"10": {"name": "上海", "parent": "1"},
|
||||||
|
"11": {"name": "江苏", "parent": "1"},
|
||||||
|
"12": {"name": "浙江", "parent": "1"},
|
||||||
|
"13": {"name": "安徽", "parent": "1"},
|
||||||
|
"14": {"name": "福建", "parent": "1"},
|
||||||
|
"15": {"name": "江西", "parent": "1"},
|
||||||
|
"16": {"name": "山东", "parent": "1"},
|
||||||
|
"17": {"name": "河南", "parent": "1"},
|
||||||
|
"18": {"name": "湖北", "parent": "1"},
|
||||||
|
"19": {"name": "湖南", "parent": "1"},
|
||||||
|
"20": {"name": "广东", "parent": "1"},
|
||||||
|
"21": {"name": "广西", "parent": "1"},
|
||||||
|
"22": {"name": "海南", "parent": "1"},
|
||||||
|
"23": {"name": "重庆", "parent": "1"},
|
||||||
|
"24": {"name": "四川", "parent": "1"},
|
||||||
|
"25": {"name": "贵州", "parent": "1"},
|
||||||
|
"26": {"name": "云南", "parent": "1"},
|
||||||
|
"27": {"name": "西藏", "parent": "1"},
|
||||||
|
"28": {"name": "陕西", "parent": "1"},
|
||||||
|
"29": {"name": "甘肃", "parent": "1"},
|
||||||
|
"30": {"name": "青海", "parent": "1"},
|
||||||
|
"31": {"name": "宁夏", "parent": "1"},
|
||||||
|
"32": {"name": "新疆", "parent": "1"},
|
||||||
|
"33": {"name": "北京市", "parent": "2"},
|
||||||
|
"34": {"name": "天津市", "parent": "3"},
|
||||||
|
"35": {"name": "石家庄市", "parent": "4"},
|
||||||
|
"36": {"name": "唐山市", "parent": "4"},
|
||||||
|
"37": {"name": "秦皇岛市", "parent": "4"},
|
||||||
|
"38": {"name": "邯郸市", "parent": "4"},
|
||||||
|
"39": {"name": "邢台市", "parent": "4"},
|
||||||
|
"40": {"name": "保定市", "parent": "4"},
|
||||||
|
"41": {"name": "张家口市", "parent": "4"},
|
||||||
|
"42": {"name": "承德市", "parent": "4"},
|
||||||
|
"43": {"name": "沧州市", "parent": "4"},
|
||||||
|
"44": {"name": "廊坊市", "parent": "4"},
|
||||||
|
"45": {"name": "衡水市", "parent": "4"},
|
||||||
|
"46": {"name": "太原市", "parent": "5"},
|
||||||
|
"47": {"name": "大同市", "parent": "5"},
|
||||||
|
"48": {"name": "阳泉市", "parent": "5"},
|
||||||
|
"49": {"name": "长治市", "parent": "5"},
|
||||||
|
"50": {"name": "晋城市", "parent": "5"},
|
||||||
|
"51": {"name": "朔州市", "parent": "5"},
|
||||||
|
"52": {"name": "晋中市", "parent": "5"},
|
||||||
|
"53": {"name": "运城市", "parent": "5"},
|
||||||
|
"54": {"name": "忻州市", "parent": "5"},
|
||||||
|
"55": {"name": "临汾市", "parent": "5"},
|
||||||
|
"56": {"name": "吕梁市", "parent": "5"},
|
||||||
|
"57": {"name": "呼和浩特市", "parent": "6"},
|
||||||
|
"58": {"name": "包头市", "parent": "6"},
|
||||||
|
"59": {"name": "乌海市", "parent": "6"},
|
||||||
|
"60": {"name": "赤峰市", "parent": "6"},
|
||||||
|
"61": {"name": "通辽市", "parent": "6"},
|
||||||
|
"62": {"name": "鄂尔多斯市", "parent": "6"},
|
||||||
|
"63": {"name": "呼伦贝尔市", "parent": "6"},
|
||||||
|
"64": {"name": "巴彦淖尔市", "parent": "6"},
|
||||||
|
"65": {"name": "乌兰察布市", "parent": "6"},
|
||||||
|
"66": {"name": "兴安盟", "parent": "6"},
|
||||||
|
"67": {"name": "锡林郭勒盟", "parent": "6"},
|
||||||
|
"68": {"name": "阿拉善盟", "parent": "6"},
|
||||||
|
"69": {"name": "沈阳市", "parent": "7"},
|
||||||
|
"70": {"name": "大连市", "parent": "7"},
|
||||||
|
"71": {"name": "鞍山市", "parent": "7"},
|
||||||
|
"72": {"name": "抚顺市", "parent": "7"},
|
||||||
|
"73": {"name": "本溪市", "parent": "7"},
|
||||||
|
"74": {"name": "丹东市", "parent": "7"},
|
||||||
|
"75": {"name": "锦州市", "parent": "7"},
|
||||||
|
"76": {"name": "营口市", "parent": "7"},
|
||||||
|
"77": {"name": "阜新市", "parent": "7"},
|
||||||
|
"78": {"name": "辽阳市", "parent": "7"},
|
||||||
|
"79": {"name": "盘锦市", "parent": "7"},
|
||||||
|
"80": {"name": "铁岭市", "parent": "7"},
|
||||||
|
"81": {"name": "朝阳市", "parent": "7"},
|
||||||
|
"82": {"name": "葫芦岛市", "parent": "7"},
|
||||||
|
"83": {"name": "长春市", "parent": "8"},
|
||||||
|
"84": {"name": "吉林市", "parent": "8"},
|
||||||
|
"85": {"name": "四平市", "parent": "8"},
|
||||||
|
"86": {"name": "辽源市", "parent": "8"},
|
||||||
|
"87": {"name": "通化市", "parent": "8"},
|
||||||
|
"88": {"name": "白山市", "parent": "8"},
|
||||||
|
"89": {"name": "松原市", "parent": "8"},
|
||||||
|
"90": {"name": "白城市", "parent": "8"},
|
||||||
|
"91": {"name": "延边朝鲜族自治州", "parent": "8"},
|
||||||
|
"92": {"name": "哈尔滨市", "parent": "9"},
|
||||||
|
"93": {"name": "齐齐哈尔市", "parent": "9"},
|
||||||
|
"94": {"name": "鸡西市", "parent": "9"},
|
||||||
|
"95": {"name": "鹤岗市", "parent": "9"},
|
||||||
|
"96": {"name": "双鸭山市", "parent": "9"},
|
||||||
|
"97": {"name": "大庆市", "parent": "9"},
|
||||||
|
"98": {"name": "伊春市", "parent": "9"},
|
||||||
|
"99": {"name": "佳木斯市", "parent": "9"},
|
||||||
|
"100": {"name": "七台河市", "parent": "9"},
|
||||||
|
"101": {"name": "牡丹江市", "parent": "9"},
|
||||||
|
"102": {"name": "黑河市", "parent": "9"},
|
||||||
|
"103": {"name": "绥化市", "parent": "9"},
|
||||||
|
"104": {"name": "大兴安岭地区", "parent": "9"},
|
||||||
|
"105": {"name": "上海市", "parent": "10"},
|
||||||
|
"106": {"name": "南京市", "parent": "11"},
|
||||||
|
"107": {"name": "无锡市", "parent": "11"},
|
||||||
|
"108": {"name": "徐州市", "parent": "11"},
|
||||||
|
"109": {"name": "常州市", "parent": "11"},
|
||||||
|
"110": {"name": "苏州市", "parent": "11"},
|
||||||
|
"111": {"name": "南通市", "parent": "11"},
|
||||||
|
"112": {"name": "连云港市", "parent": "11"},
|
||||||
|
"113": {"name": "淮安市", "parent": "11"},
|
||||||
|
"114": {"name": "盐城市", "parent": "11"},
|
||||||
|
"115": {"name": "扬州市", "parent": "11"},
|
||||||
|
"116": {"name": "镇江市", "parent": "11"},
|
||||||
|
"117": {"name": "泰州市", "parent": "11"},
|
||||||
|
"118": {"name": "宿迁市", "parent": "11"},
|
||||||
|
"119": {"name": "杭州市", "parent": "12"},
|
||||||
|
"120": {"name": "宁波市", "parent": "12"},
|
||||||
|
"121": {"name": "温州市", "parent": "12"},
|
||||||
|
"122": {"name": "嘉兴市", "parent": "12"},
|
||||||
|
"123": {"name": "湖州市", "parent": "12"},
|
||||||
|
"124": {"name": "绍兴市", "parent": "12"},
|
||||||
|
"125": {"name": "金华市", "parent": "12"},
|
||||||
|
"126": {"name": "衢州市", "parent": "12"},
|
||||||
|
"127": {"name": "舟山市", "parent": "12"},
|
||||||
|
"128": {"name": "台州市", "parent": "12"},
|
||||||
|
"129": {"name": "丽水市", "parent": "12"},
|
||||||
|
"130": {"name": "合肥市", "parent": "13"},
|
||||||
|
"131": {"name": "芜湖市", "parent": "13"},
|
||||||
|
"132": {"name": "蚌埠市", "parent": "13"},
|
||||||
|
"133": {"name": "淮南市", "parent": "13"},
|
||||||
|
"134": {"name": "马鞍山市", "parent": "13"},
|
||||||
|
"135": {"name": "淮北市", "parent": "13"},
|
||||||
|
"136": {"name": "铜陵市", "parent": "13"},
|
||||||
|
"137": {"name": "安庆市", "parent": "13"},
|
||||||
|
"138": {"name": "黄山市", "parent": "13"},
|
||||||
|
"139": {"name": "滁州市", "parent": "13"},
|
||||||
|
"140": {"name": "阜阳市", "parent": "13"},
|
||||||
|
"141": {"name": "宿州市", "parent": "13"},
|
||||||
|
"143": {"name": "六安市", "parent": "13"},
|
||||||
|
"144": {"name": "亳州市", "parent": "13"},
|
||||||
|
"145": {"name": "池州市", "parent": "13"},
|
||||||
|
"146": {"name": "宣城市", "parent": "13"},
|
||||||
|
"147": {"name": "福州市", "parent": "14"},
|
||||||
|
"148": {"name": "厦门市", "parent": "14"},
|
||||||
|
"149": {"name": "莆田市", "parent": "14"},
|
||||||
|
"150": {"name": "三明市", "parent": "14"},
|
||||||
|
"151": {"name": "泉州市", "parent": "14"},
|
||||||
|
"152": {"name": "漳州市", "parent": "14"},
|
||||||
|
"153": {"name": "南平市", "parent": "14"},
|
||||||
|
"154": {"name": "龙岩市", "parent": "14"},
|
||||||
|
"155": {"name": "宁德市", "parent": "14"},
|
||||||
|
"156": {"name": "南昌市", "parent": "15"},
|
||||||
|
"157": {"name": "景德镇市", "parent": "15"},
|
||||||
|
"158": {"name": "萍乡市", "parent": "15"},
|
||||||
|
"159": {"name": "九江市", "parent": "15"},
|
||||||
|
"160": {"name": "新余市", "parent": "15"},
|
||||||
|
"161": {"name": "鹰潭市", "parent": "15"},
|
||||||
|
"162": {"name": "赣州市", "parent": "15"},
|
||||||
|
"163": {"name": "吉安市", "parent": "15"},
|
||||||
|
"164": {"name": "宜春市", "parent": "15"},
|
||||||
|
"165": {"name": "抚州市", "parent": "15"},
|
||||||
|
"166": {"name": "上饶市", "parent": "15"},
|
||||||
|
"167": {"name": "济南市", "parent": "16"},
|
||||||
|
"168": {"name": "青岛市", "parent": "16"},
|
||||||
|
"169": {"name": "淄博市", "parent": "16"},
|
||||||
|
"170": {"name": "枣庄市", "parent": "16"},
|
||||||
|
"171": {"name": "东营市", "parent": "16"},
|
||||||
|
"172": {"name": "烟台市", "parent": "16"},
|
||||||
|
"173": {"name": "潍坊市", "parent": "16"},
|
||||||
|
"174": {"name": "济宁市", "parent": "16"},
|
||||||
|
"175": {"name": "泰安市", "parent": "16"},
|
||||||
|
"176": {"name": "威海市", "parent": "16"},
|
||||||
|
"177": {"name": "日照市", "parent": "16"},
|
||||||
|
"179": {"name": "临沂市", "parent": "16"},
|
||||||
|
"180": {"name": "德州市", "parent": "16"},
|
||||||
|
"181": {"name": "聊城市", "parent": "16"},
|
||||||
|
"182": {"name": "滨州市", "parent": "16"},
|
||||||
|
"183": {"name": "菏泽市", "parent": "16"},
|
||||||
|
"184": {"name": "郑州市", "parent": "17"},
|
||||||
|
"185": {"name": "开封市", "parent": "17"},
|
||||||
|
"186": {"name": "洛阳市", "parent": "17"},
|
||||||
|
"187": {"name": "平顶山市", "parent": "17"},
|
||||||
|
"188": {"name": "安阳市", "parent": "17"},
|
||||||
|
"189": {"name": "鹤壁市", "parent": "17"},
|
||||||
|
"190": {"name": "新乡市", "parent": "17"},
|
||||||
|
"191": {"name": "焦作市", "parent": "17"},
|
||||||
|
"192": {"name": "濮阳市", "parent": "17"},
|
||||||
|
"193": {"name": "许昌市", "parent": "17"},
|
||||||
|
"194": {"name": "漯河市", "parent": "17"},
|
||||||
|
"195": {"name": "三门峡市", "parent": "17"},
|
||||||
|
"196": {"name": "南阳市", "parent": "17"},
|
||||||
|
"197": {"name": "商丘市", "parent": "17"},
|
||||||
|
"198": {"name": "信阳市", "parent": "17"},
|
||||||
|
"199": {"name": "周口市", "parent": "17"},
|
||||||
|
"200": {"name": "驻马店市", "parent": "17"},
|
||||||
|
"201": {"name": "武汉市", "parent": "18"},
|
||||||
|
"202": {"name": "黄石市", "parent": "18"},
|
||||||
|
"203": {"name": "十堰市", "parent": "18"},
|
||||||
|
"204": {"name": "宜昌市", "parent": "18"},
|
||||||
|
"205": {"name": "襄阳市", "parent": "18"},
|
||||||
|
"206": {"name": "鄂州市", "parent": "18"},
|
||||||
|
"207": {"name": "荆门市", "parent": "18"},
|
||||||
|
"208": {"name": "孝感市", "parent": "18"},
|
||||||
|
"209": {"name": "荆州市", "parent": "18"},
|
||||||
|
"210": {"name": "黄冈市", "parent": "18"},
|
||||||
|
"211": {"name": "咸宁市", "parent": "18"},
|
||||||
|
"212": {"name": "随州市", "parent": "18"},
|
||||||
|
"213": {"name": "恩施土家族苗族自治州", "parent": "18"},
|
||||||
|
"215": {"name": "长沙市", "parent": "19"},
|
||||||
|
"216": {"name": "株洲市", "parent": "19"},
|
||||||
|
"217": {"name": "湘潭市", "parent": "19"},
|
||||||
|
"218": {"name": "衡阳市", "parent": "19"},
|
||||||
|
"219": {"name": "邵阳市", "parent": "19"},
|
||||||
|
"220": {"name": "岳阳市", "parent": "19"},
|
||||||
|
"221": {"name": "常德市", "parent": "19"},
|
||||||
|
"222": {"name": "张家界市", "parent": "19"},
|
||||||
|
"223": {"name": "益阳市", "parent": "19"},
|
||||||
|
"224": {"name": "郴州市", "parent": "19"},
|
||||||
|
"225": {"name": "永州市", "parent": "19"},
|
||||||
|
"226": {"name": "怀化市", "parent": "19"},
|
||||||
|
"227": {"name": "娄底市", "parent": "19"},
|
||||||
|
"228": {"name": "湘西土家族苗族自治州", "parent": "19"},
|
||||||
|
"229": {"name": "广州市", "parent": "20"},
|
||||||
|
"230": {"name": "韶关市", "parent": "20"},
|
||||||
|
"231": {"name": "深圳市", "parent": "20"},
|
||||||
|
"232": {"name": "珠海市", "parent": "20"},
|
||||||
|
"233": {"name": "汕头市", "parent": "20"},
|
||||||
|
"234": {"name": "佛山市", "parent": "20"},
|
||||||
|
"235": {"name": "江门市", "parent": "20"},
|
||||||
|
"236": {"name": "湛江市", "parent": "20"},
|
||||||
|
"237": {"name": "茂名市", "parent": "20"},
|
||||||
|
"238": {"name": "肇庆市", "parent": "20"},
|
||||||
|
"239": {"name": "惠州市", "parent": "20"},
|
||||||
|
"240": {"name": "梅州市", "parent": "20"},
|
||||||
|
"241": {"name": "汕尾市", "parent": "20"},
|
||||||
|
"242": {"name": "河源市", "parent": "20"},
|
||||||
|
"243": {"name": "阳江市", "parent": "20"},
|
||||||
|
"244": {"name": "清远市", "parent": "20"},
|
||||||
|
"245": {"name": "东莞市", "parent": "20"},
|
||||||
|
"246": {"name": "中山市", "parent": "20"},
|
||||||
|
"247": {"name": "潮州市", "parent": "20"},
|
||||||
|
"248": {"name": "揭阳市", "parent": "20"},
|
||||||
|
"249": {"name": "云浮市", "parent": "20"},
|
||||||
|
"250": {"name": "南宁市", "parent": "21"},
|
||||||
|
"251": {"name": "柳州市", "parent": "21"},
|
||||||
|
"252": {"name": "桂林市", "parent": "21"},
|
||||||
|
"253": {"name": "梧州市", "parent": "21"},
|
||||||
|
"254": {"name": "北海市", "parent": "21"},
|
||||||
|
"255": {"name": "防城港市", "parent": "21"},
|
||||||
|
"256": {"name": "钦州市", "parent": "21"},
|
||||||
|
"257": {"name": "贵港市", "parent": "21"},
|
||||||
|
"258": {"name": "玉林市", "parent": "21"},
|
||||||
|
"259": {"name": "百色市", "parent": "21"},
|
||||||
|
"260": {"name": "贺州市", "parent": "21"},
|
||||||
|
"261": {"name": "河池市", "parent": "21"},
|
||||||
|
"262": {"name": "来宾市", "parent": "21"},
|
||||||
|
"263": {"name": "崇左市", "parent": "21"},
|
||||||
|
"264": {"name": "海口市", "parent": "22"},
|
||||||
|
"265": {"name": "三亚市", "parent": "22"},
|
||||||
|
"267": {"name": "重庆市", "parent": "23"},
|
||||||
|
"268": {"name": "成都市", "parent": "24"},
|
||||||
|
"269": {"name": "自贡市", "parent": "24"},
|
||||||
|
"270": {"name": "攀枝花市", "parent": "24"},
|
||||||
|
"271": {"name": "泸州市", "parent": "24"},
|
||||||
|
"272": {"name": "德阳市", "parent": "24"},
|
||||||
|
"273": {"name": "绵阳市", "parent": "24"},
|
||||||
|
"274": {"name": "广元市", "parent": "24"},
|
||||||
|
"275": {"name": "遂宁市", "parent": "24"},
|
||||||
|
"276": {"name": "内江市", "parent": "24"},
|
||||||
|
"277": {"name": "乐山市", "parent": "24"},
|
||||||
|
"278": {"name": "南充市", "parent": "24"},
|
||||||
|
"279": {"name": "眉山市", "parent": "24"},
|
||||||
|
"280": {"name": "宜宾市", "parent": "24"},
|
||||||
|
"281": {"name": "广安市", "parent": "24"},
|
||||||
|
"282": {"name": "达州市", "parent": "24"},
|
||||||
|
"283": {"name": "雅安市", "parent": "24"},
|
||||||
|
"284": {"name": "巴中市", "parent": "24"},
|
||||||
|
"285": {"name": "资阳市", "parent": "24"},
|
||||||
|
"286": {"name": "阿坝藏族羌族自治州", "parent": "24"},
|
||||||
|
"287": {"name": "甘孜藏族自治州", "parent": "24"},
|
||||||
|
"288": {"name": "凉山彝族自治州", "parent": "24"},
|
||||||
|
"289": {"name": "贵阳市", "parent": "25"},
|
||||||
|
"290": {"name": "六盘水市", "parent": "25"},
|
||||||
|
"291": {"name": "遵义市", "parent": "25"},
|
||||||
|
"292": {"name": "安顺市", "parent": "25"},
|
||||||
|
"293": {"name": "铜仁市", "parent": "25"},
|
||||||
|
"294": {"name": "黔西南布依族苗族自治州", "parent": "25"},
|
||||||
|
"295": {"name": "毕节市", "parent": "25"},
|
||||||
|
"296": {"name": "黔东南苗族侗族自治州", "parent": "25"},
|
||||||
|
"297": {"name": "黔南布依族苗族自治州", "parent": "25"},
|
||||||
|
"298": {"name": "昆明市", "parent": "26"},
|
||||||
|
"299": {"name": "曲靖市", "parent": "26"},
|
||||||
|
"300": {"name": "玉溪市", "parent": "26"},
|
||||||
|
"301": {"name": "保山市", "parent": "26"},
|
||||||
|
"302": {"name": "昭通市", "parent": "26"},
|
||||||
|
"303": {"name": "丽江市", "parent": "26"},
|
||||||
|
"304": {"name": "普洱市", "parent": "26"},
|
||||||
|
"305": {"name": "临沧市", "parent": "26"},
|
||||||
|
"306": {"name": "楚雄彝族自治州", "parent": "26"},
|
||||||
|
"307": {"name": "红河哈尼族彝族自治州", "parent": "26"},
|
||||||
|
"308": {"name": "文山壮族苗族自治州", "parent": "26"},
|
||||||
|
"309": {"name": "西双版纳傣族自治州", "parent": "26"},
|
||||||
|
"310": {"name": "大理白族自治州", "parent": "26"},
|
||||||
|
"311": {"name": "德宏傣族景颇族自治州", "parent": "26"},
|
||||||
|
"312": {"name": "怒江傈僳族自治州", "parent": "26"},
|
||||||
|
"313": {"name": "迪庆藏族自治州", "parent": "26"},
|
||||||
|
"314": {"name": "拉萨市", "parent": "27"},
|
||||||
|
"315": {"name": "昌都市", "parent": "27"},
|
||||||
|
"316": {"name": "山南市", "parent": "27"},
|
||||||
|
"317": {"name": "日喀则市", "parent": "27"},
|
||||||
|
"318": {"name": "那曲市", "parent": "27"},
|
||||||
|
"319": {"name": "阿里地区", "parent": "27"},
|
||||||
|
"320": {"name": "林芝市", "parent": "27"},
|
||||||
|
"321": {"name": "西安市", "parent": "28"},
|
||||||
|
"322": {"name": "铜川市", "parent": "28"},
|
||||||
|
"323": {"name": "宝鸡市", "parent": "28"},
|
||||||
|
"324": {"name": "咸阳市", "parent": "28"},
|
||||||
|
"325": {"name": "渭南市", "parent": "28"},
|
||||||
|
"326": {"name": "延安市", "parent": "28"},
|
||||||
|
"327": {"name": "汉中市", "parent": "28"},
|
||||||
|
"328": {"name": "榆林市", "parent": "28"},
|
||||||
|
"329": {"name": "安康市", "parent": "28"},
|
||||||
|
"330": {"name": "商洛市", "parent": "28"},
|
||||||
|
"331": {"name": "兰州市", "parent": "29"},
|
||||||
|
"332": {"name": "嘉峪关市", "parent": "29"},
|
||||||
|
"333": {"name": "金昌市", "parent": "29"},
|
||||||
|
"334": {"name": "白银市", "parent": "29"},
|
||||||
|
"335": {"name": "天水市", "parent": "29"},
|
||||||
|
"336": {"name": "武威市", "parent": "29"},
|
||||||
|
"337": {"name": "张掖市", "parent": "29"},
|
||||||
|
"338": {"name": "平凉市", "parent": "29"},
|
||||||
|
"339": {"name": "酒泉市", "parent": "29"},
|
||||||
|
"340": {"name": "庆阳市", "parent": "29"},
|
||||||
|
"341": {"name": "定西市", "parent": "29"},
|
||||||
|
"342": {"name": "陇南市", "parent": "29"},
|
||||||
|
"343": {"name": "临夏回族自治州", "parent": "29"},
|
||||||
|
"344": {"name": "甘南藏族自治州", "parent": "29"},
|
||||||
|
"345": {"name": "西宁市", "parent": "30"},
|
||||||
|
"346": {"name": "海东市", "parent": "30"},
|
||||||
|
"347": {"name": "海北藏族自治州", "parent": "30"},
|
||||||
|
"348": {"name": "黄南藏族自治州", "parent": "30"},
|
||||||
|
"349": {"name": "海南藏族自治州", "parent": "30"},
|
||||||
|
"350": {"name": "果洛藏族自治州", "parent": "30"},
|
||||||
|
"351": {"name": "玉树藏族自治州", "parent": "30"},
|
||||||
|
"352": {"name": "海西蒙古族藏族自治州", "parent": "30"},
|
||||||
|
"353": {"name": "银川市", "parent": "31"},
|
||||||
|
"354": {"name": "石嘴山市", "parent": "31"},
|
||||||
|
"355": {"name": "吴忠市", "parent": "31"},
|
||||||
|
"356": {"name": "固原市", "parent": "31"},
|
||||||
|
"357": {"name": "中卫市", "parent": "31"},
|
||||||
|
"358": {"name": "乌鲁木齐市", "parent": "32"},
|
||||||
|
"359": {"name": "克拉玛依市", "parent": "32"},
|
||||||
|
"360": {"name": "吐鲁番市", "parent": "32"},
|
||||||
|
"361": {"name": "哈密市", "parent": "32"},
|
||||||
|
"362": {"name": "昌吉回族自治州", "parent": "32"},
|
||||||
|
"363": {"name": "博尔塔拉蒙古自治州", "parent": "32"},
|
||||||
|
"364": {"name": "巴音郭楞蒙古自治州", "parent": "32"},
|
||||||
|
"365": {"name": "阿克苏地区", "parent": "32"},
|
||||||
|
"366": {"name": "克孜勒苏柯尔克孜自治州", "parent": "32"},
|
||||||
|
"367": {"name": "喀什地区", "parent": "32"},
|
||||||
|
"368": {"name": "和田地区", "parent": "32"},
|
||||||
|
"369": {"name": "伊犁哈萨克自治州", "parent": "32"},
|
||||||
|
"370": {"name": "塔城地区", "parent": "32"},
|
||||||
|
"371": {"name": "阿勒泰地区", "parent": "32"},
|
||||||
|
"372": {"name": "新疆省直辖行政单位", "parent": "32"},
|
||||||
|
"373": {"name": "可克达拉市", "parent": "32"},
|
||||||
|
"374": {"name": "昆玉市", "parent": "32"},
|
||||||
|
"375": {"name": "胡杨河市", "parent": "32"},
|
||||||
|
"376": {"name": "双河市", "parent": "32"},
|
||||||
|
"3560": {"name": "北票市", "parent": "7"},
|
||||||
|
"3615": {"name": "高州市", "parent": "20"},
|
||||||
|
"3651": {"name": "济源市", "parent": "17"},
|
||||||
|
"3662": {"name": "胶南市", "parent": "16"},
|
||||||
|
"3683": {"name": "老河口市", "parent": "18"},
|
||||||
|
"3758": {"name": "沙河市", "parent": "4"},
|
||||||
|
"3822": {"name": "宜城市", "parent": "18"},
|
||||||
|
"3842": {"name": "枣阳市", "parent": "18"},
|
||||||
|
"3850": {"name": "肇东市", "parent": "9"},
|
||||||
|
"3905": {"name": "澳门", "parent": "1"},
|
||||||
|
"3906": {"name": "澳门", "parent": "3905"},
|
||||||
|
"3907": {"name": "香港", "parent": "1"},
|
||||||
|
"3908": {"name": "香港", "parent": "3907"},
|
||||||
|
"3947": {"name": "仙桃市", "parent": "18"},
|
||||||
|
"3954": {"name": "台湾", "parent": "1"},
|
||||||
|
"3955": {"name": "台湾", "parent": "3954"},
|
||||||
|
"3956": {"name": "海外", "parent": "1"},
|
||||||
|
"3957": {"name": "海外", "parent": "3956"},
|
||||||
|
"3958": {"name": "美国", "parent": "3956"},
|
||||||
|
"3959": {"name": "加拿大", "parent": "3956"},
|
||||||
|
"3961": {"name": "日本", "parent": "3956"},
|
||||||
|
"3962": {"name": "韩国", "parent": "3956"},
|
||||||
|
"3963": {"name": "德国", "parent": "3956"},
|
||||||
|
"3964": {"name": "英国", "parent": "3956"},
|
||||||
|
"3965": {"name": "意大利", "parent": "3956"},
|
||||||
|
"3966": {"name": "西班牙", "parent": "3956"},
|
||||||
|
"3967": {"name": "法国", "parent": "3956"},
|
||||||
|
"3968": {"name": "澳大利亚", "parent": "3956"},
|
||||||
|
"3969": {"name": "东城区", "parent": "2"},
|
||||||
|
"3970": {"name": "西城区", "parent": "2"},
|
||||||
|
"3971": {"name": "崇文区", "parent": "2"},
|
||||||
|
"3972": {"name": "宣武区", "parent": "2"},
|
||||||
|
"3973": {"name": "朝阳区", "parent": "2"},
|
||||||
|
"3974": {"name": "海淀区", "parent": "2"},
|
||||||
|
"3975": {"name": "丰台区", "parent": "2"},
|
||||||
|
"3976": {"name": "石景山区", "parent": "2"},
|
||||||
|
"3977": {"name": "门头沟区", "parent": "2"},
|
||||||
|
"3978": {"name": "房山区", "parent": "2"},
|
||||||
|
"3979": {"name": "通州区", "parent": "2"},
|
||||||
|
"3980": {"name": "顺义区", "parent": "2"},
|
||||||
|
"3981": {"name": "昌平区", "parent": "2"},
|
||||||
|
"3982": {"name": "大兴区", "parent": "2"},
|
||||||
|
"3983": {"name": "平谷区", "parent": "2"},
|
||||||
|
"3984": {"name": "怀柔区", "parent": "2"},
|
||||||
|
"3985": {"name": "密云区", "parent": "2"},
|
||||||
|
"3986": {"name": "延庆区", "parent": "2"},
|
||||||
|
"3987": {"name": "黄浦区", "parent": "10"},
|
||||||
|
"3988": {"name": "徐汇区", "parent": "10"},
|
||||||
|
"3989": {"name": "长宁区", "parent": "10"},
|
||||||
|
"3990": {"name": "静安区", "parent": "10"},
|
||||||
|
"3991": {"name": "普陀区", "parent": "10"},
|
||||||
|
"3992": {"name": "闸北区", "parent": "10"},
|
||||||
|
"3993": {"name": "虹口区", "parent": "10"},
|
||||||
|
"3994": {"name": "杨浦区", "parent": "10"},
|
||||||
|
"3995": {"name": "宝山区", "parent": "10"},
|
||||||
|
"3996": {"name": "闵行区", "parent": "10"},
|
||||||
|
"3997": {"name": "嘉定区", "parent": "10"},
|
||||||
|
"3998": {"name": "浦东新区", "parent": "10"},
|
||||||
|
"3999": {"name": "松江区", "parent": "10"},
|
||||||
|
"4000": {"name": "金山区", "parent": "10"},
|
||||||
|
"4001": {"name": "青浦区", "parent": "10"},
|
||||||
|
"4002": {"name": "奉贤区", "parent": "10"},
|
||||||
|
"4003": {"name": "崇明区", "parent": "10"},
|
||||||
|
"4004": {"name": "和平区", "parent": "3"},
|
||||||
|
"4005": {"name": "河东区", "parent": "3"},
|
||||||
|
"4006": {"name": "河西区", "parent": "3"},
|
||||||
|
"4007": {"name": "南开区", "parent": "3"},
|
||||||
|
"4008": {"name": "红桥区", "parent": "3"},
|
||||||
|
"4009": {"name": "河北区", "parent": "3"},
|
||||||
|
"4010": {"name": "滨海新区", "parent": "3"},
|
||||||
|
"4011": {"name": "东丽区", "parent": "3"},
|
||||||
|
"4012": {"name": "西青区", "parent": "3"},
|
||||||
|
"4013": {"name": "北辰区", "parent": "3"},
|
||||||
|
"4014": {"name": "津南区", "parent": "3"},
|
||||||
|
"4015": {"name": "武清区", "parent": "3"},
|
||||||
|
"4016": {"name": "宝坻区", "parent": "3"},
|
||||||
|
"4017": {"name": "静海区", "parent": "3"},
|
||||||
|
"4018": {"name": "宁河区", "parent": "3"},
|
||||||
|
"4019": {"name": "蓟州区", "parent": "3"},
|
||||||
|
"4020": {"name": "渝中区", "parent": "23"},
|
||||||
|
"4021": {"name": "江北区", "parent": "23"},
|
||||||
|
"4022": {"name": "南岸区", "parent": "23"},
|
||||||
|
"4023": {"name": "沙坪坝区", "parent": "23"},
|
||||||
|
"4024": {"name": "九龙坡区", "parent": "23"},
|
||||||
|
"4025": {"name": "大渡口区", "parent": "23"},
|
||||||
|
"4026": {"name": "渝北区", "parent": "23"},
|
||||||
|
"4027": {"name": "巴南区", "parent": "23"},
|
||||||
|
"4028": {"name": "北碚区", "parent": "23"},
|
||||||
|
"4029": {"name": "万州区", "parent": "23"},
|
||||||
|
"4030": {"name": "黔江区", "parent": "23"},
|
||||||
|
"4031": {"name": "永川区", "parent": "23"},
|
||||||
|
"4032": {"name": "涪陵区", "parent": "23"},
|
||||||
|
"4033": {"name": "江津区", "parent": "23"},
|
||||||
|
"4034": {"name": "合川区", "parent": "23"},
|
||||||
|
"4035": {"name": "双桥区", "parent": "23"},
|
||||||
|
"4036": {"name": "万盛区", "parent": "23"},
|
||||||
|
"4037": {"name": "荣昌区", "parent": "23"},
|
||||||
|
"4038": {"name": "大足区", "parent": "23"},
|
||||||
|
"4039": {"name": "璧山区", "parent": "23"},
|
||||||
|
"4040": {"name": "铜梁区", "parent": "23"},
|
||||||
|
"4041": {"name": "潼南区", "parent": "23"},
|
||||||
|
"4042": {"name": "綦江区", "parent": "23"},
|
||||||
|
"4043": {"name": "忠县", "parent": "23"},
|
||||||
|
"4044": {"name": "开州区", "parent": "23"},
|
||||||
|
"4045": {"name": "云阳县", "parent": "23"},
|
||||||
|
"4046": {"name": "梁平区", "parent": "23"},
|
||||||
|
"4047": {"name": "垫江县", "parent": "23"},
|
||||||
|
"4048": {"name": "丰都县", "parent": "23"},
|
||||||
|
"4049": {"name": "奉节县", "parent": "23"},
|
||||||
|
"4050": {"name": "巫山县", "parent": "23"},
|
||||||
|
"4051": {"name": "巫溪县", "parent": "23"},
|
||||||
|
"4052": {"name": "城口县", "parent": "23"},
|
||||||
|
"4053": {"name": "武隆区", "parent": "23"},
|
||||||
|
"4054": {"name": "石柱土家族自治县", "parent": "23"},
|
||||||
|
"4055": {"name": "秀山土家族苗族自治县", "parent": "23"},
|
||||||
|
"4056": {"name": "酉阳土家族苗族自治县", "parent": "23"},
|
||||||
|
"4057": {"name": "彭水苗族土家族自治县", "parent": "23"},
|
||||||
|
"4058": {"name": "潜江市", "parent": "18"},
|
||||||
|
"4059": {"name": "三沙市", "parent": "22"},
|
||||||
|
"4060": {"name": "石河子市", "parent": "32"},
|
||||||
|
"4061": {"name": "阿拉尔市", "parent": "32"},
|
||||||
|
"4062": {"name": "图木舒克市", "parent": "32"},
|
||||||
|
"4063": {"name": "五家渠市", "parent": "32"},
|
||||||
|
"4064": {"name": "北屯市", "parent": "32"},
|
||||||
|
"4065": {"name": "铁门关市", "parent": "32"},
|
||||||
|
"4066": {"name": "儋州市", "parent": "22"},
|
||||||
|
"4067": {"name": "五指山市", "parent": "22"},
|
||||||
|
"4068": {"name": "文昌市", "parent": "22"},
|
||||||
|
"4069": {"name": "琼海市", "parent": "22"},
|
||||||
|
"4070": {"name": "万宁市", "parent": "22"},
|
||||||
|
"4072": {"name": "定安县", "parent": "22"},
|
||||||
|
"4073": {"name": "屯昌县", "parent": "22"},
|
||||||
|
"4074": {"name": "澄迈县", "parent": "22"},
|
||||||
|
"4075": {"name": "临高县", "parent": "22"},
|
||||||
|
"4076": {"name": "琼中黎族苗族自治县", "parent": "22"},
|
||||||
|
"4077": {"name": "保亭黎族苗族自治县", "parent": "22"},
|
||||||
|
"4078": {"name": "白沙黎族自治县", "parent": "22"},
|
||||||
|
"4079": {"name": "昌江黎族自治县", "parent": "22"},
|
||||||
|
"4080": {"name": "乐东黎族自治县", "parent": "22"},
|
||||||
|
"4081": {"name": "陵水黎族自治县", "parent": "22"},
|
||||||
|
"4082": {"name": "马来西亚", "parent": "3956"},
|
||||||
|
"6047": {"name": "长寿区", "parent": "23"},
|
||||||
|
"6857": {"name": "阿富汗", "parent": "3956"},
|
||||||
|
"6858": {"name": "阿尔巴尼亚", "parent": "3956"},
|
||||||
|
"6859": {"name": "阿尔及利亚", "parent": "3956"},
|
||||||
|
"6860": {"name": "美属萨摩亚", "parent": "3956"},
|
||||||
|
"6861": {"name": "安道尔", "parent": "3956"},
|
||||||
|
"6862": {"name": "安哥拉", "parent": "3956"},
|
||||||
|
"6863": {"name": "安圭拉", "parent": "3956"},
|
||||||
|
"6864": {"name": "南极洲", "parent": "3956"},
|
||||||
|
"6865": {"name": "安提瓜和巴布达", "parent": "3956"},
|
||||||
|
"6866": {"name": "阿根廷", "parent": "3956"},
|
||||||
|
"6867": {"name": "亚美尼亚", "parent": "3956"},
|
||||||
|
"6869": {"name": "奥地利", "parent": "3956"},
|
||||||
|
"6870": {"name": "阿塞拜疆", "parent": "3956"},
|
||||||
|
"6871": {"name": "巴哈马", "parent": "3956"},
|
||||||
|
"6872": {"name": "巴林", "parent": "3956"},
|
||||||
|
"6873": {"name": "孟加拉国", "parent": "3956"},
|
||||||
|
"6874": {"name": "巴巴多斯", "parent": "3956"},
|
||||||
|
"6875": {"name": "白俄罗斯", "parent": "3956"},
|
||||||
|
"6876": {"name": "比利时", "parent": "3956"},
|
||||||
|
"6877": {"name": "伯利兹", "parent": "3956"},
|
||||||
|
"6878": {"name": "贝宁", "parent": "3956"},
|
||||||
|
"6879": {"name": "百慕大", "parent": "3956"},
|
||||||
|
"6880": {"name": "不丹", "parent": "3956"},
|
||||||
|
"6881": {"name": "玻利维亚", "parent": "3956"},
|
||||||
|
"6882": {"name": "波黑", "parent": "3956"},
|
||||||
|
"6883": {"name": "博茨瓦纳", "parent": "3956"},
|
||||||
|
"6884": {"name": "布维岛", "parent": "3956"},
|
||||||
|
"6885": {"name": "巴西", "parent": "3956"},
|
||||||
|
"6886": {"name": "英属印度洋领土", "parent": "3956"},
|
||||||
|
"6887": {"name": "文莱", "parent": "3956"},
|
||||||
|
"6888": {"name": "保加利亚", "parent": "3956"},
|
||||||
|
"6889": {"name": "布基纳法索", "parent": "3956"},
|
||||||
|
"6890": {"name": "布隆迪", "parent": "3956"},
|
||||||
|
"6891": {"name": "柬埔寨", "parent": "3956"},
|
||||||
|
"6892": {"name": "喀麦隆", "parent": "3956"},
|
||||||
|
"6893": {"name": "佛得角", "parent": "3956"},
|
||||||
|
"6894": {"name": "开曼群岛", "parent": "3956"},
|
||||||
|
"6895": {"name": "中非", "parent": "3956"},
|
||||||
|
"6896": {"name": "乍得", "parent": "3956"},
|
||||||
|
"6897": {"name": "智利", "parent": "3956"},
|
||||||
|
"6898": {"name": "圣诞岛", "parent": "3956"},
|
||||||
|
"6899": {"name": "科科斯(基林)群岛", "parent": "3956"},
|
||||||
|
"6900": {"name": "哥伦比亚", "parent": "3956"},
|
||||||
|
"6901": {"name": "科摩罗", "parent": "3956"},
|
||||||
|
"6902": {"name": "刚果(布)", "parent": "3956"},
|
||||||
|
"6903": {"name": "刚果(金)", "parent": "3956"},
|
||||||
|
"6904": {"name": "库克群岛", "parent": "3956"},
|
||||||
|
"6905": {"name": "哥斯达黎加", "parent": "3956"},
|
||||||
|
"6906": {"name": "科特迪瓦", "parent": "3956"},
|
||||||
|
"6907": {"name": "克罗地亚", "parent": "3956"},
|
||||||
|
"6908": {"name": "古巴", "parent": "3956"},
|
||||||
|
"6909": {"name": "塞浦路斯", "parent": "3956"},
|
||||||
|
"6910": {"name": "捷克", "parent": "3956"},
|
||||||
|
"6911": {"name": "丹麦", "parent": "3956"},
|
||||||
|
"6912": {"name": "吉布提", "parent": "3956"},
|
||||||
|
"6913": {"name": "多米尼克", "parent": "3956"},
|
||||||
|
"6914": {"name": "多米尼加共和国", "parent": "3956"},
|
||||||
|
"6915": {"name": "东帝汶", "parent": "3956"},
|
||||||
|
"6916": {"name": "厄瓜多尔", "parent": "3956"},
|
||||||
|
"6917": {"name": "埃及", "parent": "3956"},
|
||||||
|
"6918": {"name": "萨尔瓦多", "parent": "3956"},
|
||||||
|
"6919": {"name": "赤道几内亚", "parent": "3956"},
|
||||||
|
"6920": {"name": "厄立特里亚", "parent": "3956"},
|
||||||
|
"6921": {"name": "爱沙尼亚", "parent": "3956"},
|
||||||
|
"6922": {"name": "埃塞俄比亚", "parent": "3956"},
|
||||||
|
"6923": {"name": "福克兰群岛(马尔维纳斯)", "parent": "3956"},
|
||||||
|
"6924": {"name": "法罗群岛", "parent": "3956"},
|
||||||
|
"6925": {"name": "斐济", "parent": "3956"},
|
||||||
|
"6926": {"name": "芬兰", "parent": "3956"},
|
||||||
|
"6927": {"name": "法属圭亚那", "parent": "3956"},
|
||||||
|
"6928": {"name": "法属波利尼西亚", "parent": "3956"},
|
||||||
|
"6929": {"name": "法属南部领土", "parent": "3956"},
|
||||||
|
"6930": {"name": "加蓬", "parent": "3956"},
|
||||||
|
"6931": {"name": "冈比亚", "parent": "3956"},
|
||||||
|
"6932": {"name": "格鲁吉亚", "parent": "3956"},
|
||||||
|
"6933": {"name": "加纳", "parent": "3956"},
|
||||||
|
"6934": {"name": "直布罗陀", "parent": "3956"},
|
||||||
|
"6935": {"name": "希腊", "parent": "3956"},
|
||||||
|
"6936": {"name": "格陵兰", "parent": "3956"},
|
||||||
|
"6937": {"name": "格林纳达", "parent": "3956"},
|
||||||
|
"6938": {"name": "瓜德罗普", "parent": "3956"},
|
||||||
|
"6939": {"name": "关岛", "parent": "3956"},
|
||||||
|
"6940": {"name": "危地马拉", "parent": "3956"},
|
||||||
|
"6941": {"name": "几内亚", "parent": "3956"},
|
||||||
|
"6942": {"name": "几内亚比绍", "parent": "3956"},
|
||||||
|
"6943": {"name": "圭亚那", "parent": "3956"},
|
||||||
|
"6944": {"name": "海地", "parent": "3956"},
|
||||||
|
"6945": {"name": "赫德岛和麦克唐纳岛", "parent": "3956"},
|
||||||
|
"6946": {"name": "洪都拉斯", "parent": "3956"},
|
||||||
|
"6947": {"name": "匈牙利", "parent": "3956"},
|
||||||
|
"6948": {"name": "冰岛", "parent": "3956"},
|
||||||
|
"6949": {"name": "印度", "parent": "3956"},
|
||||||
|
"6950": {"name": "印度尼西亚", "parent": "3956"},
|
||||||
|
"6951": {"name": "伊朗", "parent": "3956"},
|
||||||
|
"6952": {"name": "伊拉克", "parent": "3956"},
|
||||||
|
"6953": {"name": "爱尔兰", "parent": "3956"},
|
||||||
|
"6954": {"name": "以色列", "parent": "3956"},
|
||||||
|
"6955": {"name": "牙买加", "parent": "3956"},
|
||||||
|
"6956": {"name": "约旦", "parent": "3956"},
|
||||||
|
"6957": {"name": "哈萨克斯坦", "parent": "3956"},
|
||||||
|
"6958": {"name": "肯尼亚", "parent": "3956"},
|
||||||
|
"6959": {"name": "基里巴斯", "parent": "3956"},
|
||||||
|
"6960": {"name": "朝鲜", "parent": "3956"},
|
||||||
|
"6961": {"name": "科威特", "parent": "3956"},
|
||||||
|
"6962": {"name": "吉尔吉斯斯坦", "parent": "3956"},
|
||||||
|
"6963": {"name": "老挝", "parent": "3956"},
|
||||||
|
"6964": {"name": "拉脱维亚", "parent": "3956"},
|
||||||
|
"6965": {"name": "黎巴嫩", "parent": "3956"},
|
||||||
|
"6966": {"name": "莱索托", "parent": "3956"},
|
||||||
|
"6967": {"name": "利比里亚", "parent": "3956"},
|
||||||
|
"6968": {"name": "利比亚", "parent": "3956"},
|
||||||
|
"6969": {"name": "列支敦士登", "parent": "3956"},
|
||||||
|
"6970": {"name": "立陶宛", "parent": "3956"},
|
||||||
|
"6971": {"name": "卢森堡", "parent": "3956"},
|
||||||
|
"6972": {"name": "前南马其顿", "parent": "3956"},
|
||||||
|
"6973": {"name": "马达加斯加", "parent": "3956"},
|
||||||
|
"6974": {"name": "马拉维", "parent": "3956"},
|
||||||
|
"6975": {"name": "马尔代夫", "parent": "3956"},
|
||||||
|
"6976": {"name": "马里", "parent": "3956"},
|
||||||
|
"6977": {"name": "马耳他", "parent": "3956"},
|
||||||
|
"6978": {"name": "马绍尔群岛", "parent": "3956"},
|
||||||
|
"6979": {"name": "马提尼克", "parent": "3956"},
|
||||||
|
"6980": {"name": "毛里塔尼亚", "parent": "3956"},
|
||||||
|
"6981": {"name": "毛里求斯", "parent": "3956"},
|
||||||
|
"6982": {"name": "马约特", "parent": "3956"},
|
||||||
|
"6983": {"name": "墨西哥", "parent": "3956"},
|
||||||
|
"6984": {"name": "密克罗尼西亚联邦", "parent": "3956"},
|
||||||
|
"6985": {"name": "摩尔多瓦", "parent": "3956"},
|
||||||
|
"6986": {"name": "摩纳哥", "parent": "3956"},
|
||||||
|
"6987": {"name": "蒙古", "parent": "3956"},
|
||||||
|
"6988": {"name": "蒙特塞拉特", "parent": "3956"},
|
||||||
|
"6989": {"name": "摩洛哥", "parent": "3956"},
|
||||||
|
"6990": {"name": "莫桑比克", "parent": "3956"},
|
||||||
|
"6991": {"name": "缅甸", "parent": "3956"},
|
||||||
|
"6992": {"name": "纳米比亚", "parent": "3956"},
|
||||||
|
"6993": {"name": "瑙鲁", "parent": "3956"},
|
||||||
|
"6994": {"name": "尼泊尔", "parent": "3956"},
|
||||||
|
"6995": {"name": "荷兰", "parent": "3956"},
|
||||||
|
"6996": {"name": "荷属安的列斯", "parent": "3956"},
|
||||||
|
"6997": {"name": "新喀里多尼亚", "parent": "3956"},
|
||||||
|
"6998": {"name": "新西兰", "parent": "3956"},
|
||||||
|
"6999": {"name": "尼加拉瓜", "parent": "3956"},
|
||||||
|
"7000": {"name": "尼日尔", "parent": "3956"},
|
||||||
|
"7001": {"name": "尼日利亚", "parent": "3956"},
|
||||||
|
"7002": {"name": "纽埃", "parent": "3956"},
|
||||||
|
"7003": {"name": "诺福克岛", "parent": "3956"},
|
||||||
|
"7004": {"name": "北马里亚纳", "parent": "3956"},
|
||||||
|
"7005": {"name": "挪威", "parent": "3956"},
|
||||||
|
"7006": {"name": "阿曼", "parent": "3956"},
|
||||||
|
"7007": {"name": "巴基斯坦", "parent": "3956"},
|
||||||
|
"7008": {"name": "帕劳", "parent": "3956"},
|
||||||
|
"7009": {"name": "巴勒斯坦", "parent": "3956"},
|
||||||
|
"7010": {"name": "巴拿马", "parent": "3956"},
|
||||||
|
"7011": {"name": "巴布亚新几内亚", "parent": "3956"},
|
||||||
|
"7012": {"name": "巴拉圭", "parent": "3956"},
|
||||||
|
"7013": {"name": "秘鲁", "parent": "3956"},
|
||||||
|
"7014": {"name": "菲律宾", "parent": "3956"},
|
||||||
|
"7015": {"name": "皮特凯恩群岛", "parent": "3956"},
|
||||||
|
"7016": {"name": "波兰", "parent": "3956"},
|
||||||
|
"7017": {"name": "葡萄牙", "parent": "3956"},
|
||||||
|
"7018": {"name": "波多黎各", "parent": "3956"},
|
||||||
|
"7019": {"name": "卡塔尔", "parent": "3956"},
|
||||||
|
"7020": {"name": "留尼汪", "parent": "3956"},
|
||||||
|
"7021": {"name": "罗马尼亚", "parent": "3956"},
|
||||||
|
"7022": {"name": "俄罗斯联邦", "parent": "3956"},
|
||||||
|
"7023": {"name": "卢旺达", "parent": "3956"},
|
||||||
|
"7024": {"name": "圣赫勒拿", "parent": "3956"},
|
||||||
|
"7025": {"name": "圣基茨和尼维斯", "parent": "3956"},
|
||||||
|
"7026": {"name": "圣卢西亚", "parent": "3956"},
|
||||||
|
"7027": {"name": "圣皮埃尔和密克隆", "parent": "3956"},
|
||||||
|
"7028": {"name": "圣文森特和格林纳丁斯", "parent": "3956"},
|
||||||
|
"7029": {"name": "萨摩亚", "parent": "3956"},
|
||||||
|
"7030": {"name": "圣马力诺", "parent": "3956"},
|
||||||
|
"7031": {"name": "圣多美和普林西比", "parent": "3956"},
|
||||||
|
"7032": {"name": "沙特阿拉伯", "parent": "3956"},
|
||||||
|
"7033": {"name": "塞内加尔", "parent": "3956"},
|
||||||
|
"7034": {"name": "塞舌尔", "parent": "3956"},
|
||||||
|
"7035": {"name": "塞拉利昂", "parent": "3956"},
|
||||||
|
"7036": {"name": "新加坡", "parent": "3956"},
|
||||||
|
"7037": {"name": "斯洛伐克", "parent": "3956"},
|
||||||
|
"7038": {"name": "斯洛文尼亚", "parent": "3956"},
|
||||||
|
"7039": {"name": "所罗门群岛", "parent": "3956"},
|
||||||
|
"7040": {"name": "索马里", "parent": "3956"},
|
||||||
|
"7041": {"name": "南非", "parent": "3956"},
|
||||||
|
"7042": {"name": "南乔治亚岛和南桑德韦奇岛", "parent": "3956"},
|
||||||
|
"7043": {"name": "斯里兰卡", "parent": "3956"},
|
||||||
|
"7044": {"name": "苏丹", "parent": "3956"},
|
||||||
|
"7045": {"name": "苏里南", "parent": "3956"},
|
||||||
|
"7046": {"name": "斯瓦尔巴群岛", "parent": "3956"},
|
||||||
|
"7047": {"name": "斯威士兰", "parent": "3956"},
|
||||||
|
"7048": {"name": "瑞典", "parent": "3956"},
|
||||||
|
"7049": {"name": "瑞士", "parent": "3956"},
|
||||||
|
"7050": {"name": "叙利亚", "parent": "3956"},
|
||||||
|
"7051": {"name": "塔吉克斯坦", "parent": "3956"},
|
||||||
|
"7052": {"name": "坦桑尼亚", "parent": "3956"},
|
||||||
|
"7053": {"name": "泰国", "parent": "3956"},
|
||||||
|
"7054": {"name": "多哥", "parent": "3956"},
|
||||||
|
"7055": {"name": "托克劳", "parent": "3956"},
|
||||||
|
"7056": {"name": "汤加", "parent": "3956"},
|
||||||
|
"7057": {"name": "特立尼达和多巴哥", "parent": "3956"},
|
||||||
|
"7058": {"name": "突尼斯", "parent": "3956"},
|
||||||
|
"7059": {"name": "土耳其", "parent": "3956"},
|
||||||
|
"7060": {"name": "土库曼斯坦", "parent": "3956"},
|
||||||
|
"7061": {"name": "特克斯科斯群岛", "parent": "3956"},
|
||||||
|
"7062": {"name": "图瓦卢", "parent": "3956"},
|
||||||
|
"7063": {"name": "乌干达", "parent": "3956"},
|
||||||
|
"7064": {"name": "乌克兰", "parent": "3956"},
|
||||||
|
"7065": {"name": "阿联酋", "parent": "3956"},
|
||||||
|
"7066": {"name": "美国本土外小岛屿", "parent": "3956"},
|
||||||
|
"7067": {"name": "乌拉圭", "parent": "3956"},
|
||||||
|
"7068": {"name": "乌兹别克斯坦", "parent": "3956"},
|
||||||
|
"7069": {"name": "瓦努阿图", "parent": "3956"},
|
||||||
|
"7070": {"name": "梵蒂冈", "parent": "3956"},
|
||||||
|
"7071": {"name": "委内瑞拉", "parent": "3956"},
|
||||||
|
"7072": {"name": "越南", "parent": "3956"},
|
||||||
|
"7073": {"name": "英属维尔京群岛", "parent": "3956"},
|
||||||
|
"7074": {"name": "美属维尔京群岛", "parent": "3956"},
|
||||||
|
"7075": {"name": "瓦利斯和富图纳", "parent": "3956"},
|
||||||
|
"7076": {"name": "西撒哈拉", "parent": "3956"},
|
||||||
|
"7077": {"name": "也门", "parent": "3956"},
|
||||||
|
"7078": {"name": "南斯拉夫", "parent": "3956"},
|
||||||
|
"7079": {"name": "赞比亚", "parent": "3956"},
|
||||||
|
"7080": {"name": "津巴布韦", "parent": "3956"},
|
||||||
|
"7081": {"name": "塞尔维亚", "parent": "3956"},
|
||||||
|
"7082": {"name": "雄安新区", "parent": "4"},
|
||||||
|
"7084": {"name": "天门市", "parent": "18"},
|
||||||
|
}
|
||||||
|
|
||||||
|
NM_SET = set([v["name"] for _, v in TBL.items()])
|
||||||
|
|
||||||
|
|
||||||
|
def get_names(id):
|
||||||
|
if not id or str(id).lower() == "none":
|
||||||
|
return []
|
||||||
|
id = str(id)
|
||||||
|
if not re.match("[0-9]+$", id.strip()):
|
||||||
|
return [id]
|
||||||
|
nms = []
|
||||||
|
d = TBL.get(id)
|
||||||
|
if not d:
|
||||||
|
return []
|
||||||
|
nms.append(d["name"])
|
||||||
|
p = get_names(d["parent"])
|
||||||
|
if p:
|
||||||
|
nms.extend(p)
|
||||||
|
return nms
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
def isName(nm):
|
||||||
|
if nm in NM_SET:
|
||||||
|
return True
|
||||||
|
if nm + "市" in NM_SET:
|
||||||
|
return True
|
||||||
|
if re.sub(r"(省|(回族|壮族|维吾尔)*自治区)$", "", nm) in NM_SET:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
65
deepdoc/parser/resume/entities/res/corp.tks.freq.json
Normal file
65
deepdoc/parser/resume/entities/res/corp.tks.freq.json
Normal file
@@ -0,0 +1,65 @@
|
|||||||
|
[
|
||||||
|
"科技",
|
||||||
|
"集团",
|
||||||
|
"网络科技",
|
||||||
|
"技术",
|
||||||
|
"信息",
|
||||||
|
"分公司",
|
||||||
|
"信息技术",
|
||||||
|
"发展",
|
||||||
|
"科技股份",
|
||||||
|
"网络",
|
||||||
|
"贸易",
|
||||||
|
"商贸",
|
||||||
|
"工程",
|
||||||
|
"企业",
|
||||||
|
"集团股份",
|
||||||
|
"商务",
|
||||||
|
"工业",
|
||||||
|
"控股集团",
|
||||||
|
"国际贸易",
|
||||||
|
"软件技术",
|
||||||
|
"数码科技",
|
||||||
|
"软件开发",
|
||||||
|
"有限",
|
||||||
|
"经营",
|
||||||
|
"科技开发",
|
||||||
|
"股份公司",
|
||||||
|
"电子技术",
|
||||||
|
"实业集团",
|
||||||
|
"责任",
|
||||||
|
"无限",
|
||||||
|
"工程技术",
|
||||||
|
"上市公司",
|
||||||
|
"技术开发",
|
||||||
|
"软件系统",
|
||||||
|
"总公司",
|
||||||
|
"网络服务",
|
||||||
|
"ltd.",
|
||||||
|
"technology",
|
||||||
|
"company",
|
||||||
|
"服务公司",
|
||||||
|
"计算机技术",
|
||||||
|
"计算机软件",
|
||||||
|
"电子信息",
|
||||||
|
"corporation",
|
||||||
|
"计算机服务",
|
||||||
|
"计算机系统",
|
||||||
|
"有限公司",
|
||||||
|
"事业部",
|
||||||
|
"公司",
|
||||||
|
"股份",
|
||||||
|
"有限责任",
|
||||||
|
"软件",
|
||||||
|
"控股",
|
||||||
|
"高科技",
|
||||||
|
"房地产",
|
||||||
|
"事业群",
|
||||||
|
"部门",
|
||||||
|
"电子商务",
|
||||||
|
"人力资源顾问",
|
||||||
|
"人力资源",
|
||||||
|
"株式会社",
|
||||||
|
"网络营销"
|
||||||
|
]
|
||||||
|
|
||||||
31480
deepdoc/parser/resume/entities/res/corp_baike_len.csv
Normal file
31480
deepdoc/parser/resume/entities/res/corp_baike_len.csv
Normal file
File diff suppressed because it is too large
Load Diff
14939
deepdoc/parser/resume/entities/res/corp_tag.json
Normal file
14939
deepdoc/parser/resume/entities/res/corp_tag.json
Normal file
File diff suppressed because it is too large
Load Diff
911
deepdoc/parser/resume/entities/res/good_corp.json
Normal file
911
deepdoc/parser/resume/entities/res/good_corp.json
Normal file
@@ -0,0 +1,911 @@
|
|||||||
|
[
|
||||||
|
"google assistant investments",
|
||||||
|
"amazon",
|
||||||
|
"dingtalk china information",
|
||||||
|
"zhejiang alibaba communication",
|
||||||
|
"yunos",
|
||||||
|
"腾讯云",
|
||||||
|
"新浪新闻",
|
||||||
|
"网邻通",
|
||||||
|
"蚂蚁集团",
|
||||||
|
"大疆",
|
||||||
|
"恒生股份",
|
||||||
|
"sf express",
|
||||||
|
"智者天下",
|
||||||
|
"shanghai hema network",
|
||||||
|
"papayamobile",
|
||||||
|
"lexinfintech",
|
||||||
|
"industrial consumer finance",
|
||||||
|
"360搜索",
|
||||||
|
"世纪光速",
|
||||||
|
"迅雷区块链",
|
||||||
|
"赛盒科技",
|
||||||
|
"齐力电子商务",
|
||||||
|
"平安养老险",
|
||||||
|
"平安证券",
|
||||||
|
"平安好贷",
|
||||||
|
"五八新服",
|
||||||
|
"呯嘭智能",
|
||||||
|
"阿里妈妈",
|
||||||
|
"mdt",
|
||||||
|
"tencent",
|
||||||
|
"weibo",
|
||||||
|
"浪潮软件",
|
||||||
|
"阿里巴巴广告",
|
||||||
|
"mashang consumer finance",
|
||||||
|
"维沃",
|
||||||
|
"hqg , limited",
|
||||||
|
"moodys",
|
||||||
|
"搜狐支付",
|
||||||
|
"百度秀",
|
||||||
|
"新浪服务",
|
||||||
|
"零售通",
|
||||||
|
"同城艺龙",
|
||||||
|
"虾米音乐",
|
||||||
|
"贝壳集团",
|
||||||
|
"小米有品",
|
||||||
|
"滴滴自动驾驶",
|
||||||
|
"图记",
|
||||||
|
"阿里影业",
|
||||||
|
"卓联软件",
|
||||||
|
"zhejiang tmall",
|
||||||
|
"谷歌中国",
|
||||||
|
"hithink flush",
|
||||||
|
"时装科技",
|
||||||
|
"程会玩国际旅行社",
|
||||||
|
"amazon china holding limited",
|
||||||
|
"中信消金",
|
||||||
|
"当当比特物流",
|
||||||
|
"新浪新媒体咨询",
|
||||||
|
"tongcheng network",
|
||||||
|
"金山在线",
|
||||||
|
"shopping cart",
|
||||||
|
"犀互动",
|
||||||
|
"五八",
|
||||||
|
"bilibili",
|
||||||
|
"阿里星球",
|
||||||
|
"滴滴金科服务",
|
||||||
|
"美团",
|
||||||
|
"哈啰出行",
|
||||||
|
"face",
|
||||||
|
"平安健康",
|
||||||
|
"招商银行",
|
||||||
|
"连亚",
|
||||||
|
"盒马网络",
|
||||||
|
"b站",
|
||||||
|
"华为机器",
|
||||||
|
"shanghai mdt infotech",
|
||||||
|
"ping an healthkonnect",
|
||||||
|
"beijing home link real estate broker",
|
||||||
|
"花海仓",
|
||||||
|
"beijing jingdong shangke information",
|
||||||
|
"微影智能",
|
||||||
|
"酷狗游戏",
|
||||||
|
"health.pingan.com",
|
||||||
|
"众安",
|
||||||
|
"陌陌",
|
||||||
|
"海康威视数字",
|
||||||
|
"同程网",
|
||||||
|
"艾丁金融",
|
||||||
|
"知乎",
|
||||||
|
" lu",
|
||||||
|
"国际商业机器公司",
|
||||||
|
"捷信消费金融",
|
||||||
|
"恒生利融",
|
||||||
|
"china merchants bank",
|
||||||
|
"企鹅电竞",
|
||||||
|
"捷信信驰",
|
||||||
|
"360智能家居",
|
||||||
|
"小桔车服",
|
||||||
|
"homecredit",
|
||||||
|
"皮皮虾",
|
||||||
|
"畅游",
|
||||||
|
"聚爱聊",
|
||||||
|
"suning.com",
|
||||||
|
"途牛旅游网",
|
||||||
|
"花呗",
|
||||||
|
"盈店通",
|
||||||
|
"sina",
|
||||||
|
"阿里巴巴音乐",
|
||||||
|
"华为技术有限公司",
|
||||||
|
"国付宝",
|
||||||
|
"shanghai lianshang network",
|
||||||
|
"oppo",
|
||||||
|
"华为投资控股",
|
||||||
|
"beijing sohu new media information",
|
||||||
|
"times square",
|
||||||
|
"菜鸟物流",
|
||||||
|
"lingxing",
|
||||||
|
"jd digits",
|
||||||
|
"同程旅游",
|
||||||
|
"分期乐",
|
||||||
|
"火锅视频",
|
||||||
|
"天天快报",
|
||||||
|
"猎豹移动",
|
||||||
|
"五八人力资源",
|
||||||
|
"宝宝树",
|
||||||
|
"顺丰科技",
|
||||||
|
"上海西翠",
|
||||||
|
"诗程文化传播",
|
||||||
|
"dewu",
|
||||||
|
"领星网络",
|
||||||
|
"aliexpress",
|
||||||
|
"贝塔通科技",
|
||||||
|
"链家",
|
||||||
|
"花小猪",
|
||||||
|
"趣输入",
|
||||||
|
"搜狐新媒体",
|
||||||
|
"一淘",
|
||||||
|
"56",
|
||||||
|
"qq阅读",
|
||||||
|
"青桔单车",
|
||||||
|
"iflytek",
|
||||||
|
"每日优鲜电子商务",
|
||||||
|
"腾讯觅影",
|
||||||
|
"微医",
|
||||||
|
"松果网",
|
||||||
|
"paypal",
|
||||||
|
"递瑞供应链管理",
|
||||||
|
"领星",
|
||||||
|
"qunar",
|
||||||
|
"三快",
|
||||||
|
"lu.com",
|
||||||
|
"携程旅行网",
|
||||||
|
"新潮传媒",
|
||||||
|
"链家经纪",
|
||||||
|
"景域文化",
|
||||||
|
"阿里健康",
|
||||||
|
"pingpeng",
|
||||||
|
"聚划算",
|
||||||
|
"零机科技",
|
||||||
|
"街兔电单车",
|
||||||
|
"快乐购",
|
||||||
|
"华为数字能源",
|
||||||
|
"搜狐",
|
||||||
|
"陆家嘴国际金融资产交易市场",
|
||||||
|
"nanjing tuniu",
|
||||||
|
"亚马逊",
|
||||||
|
"苏宁易购",
|
||||||
|
"携程旅游",
|
||||||
|
"苏宁金服",
|
||||||
|
"babytree",
|
||||||
|
"悟空问答",
|
||||||
|
"同花顺",
|
||||||
|
"eastmoney",
|
||||||
|
"浪潮信息",
|
||||||
|
"滴滴智慧交通",
|
||||||
|
"beijing ruixun lingtong",
|
||||||
|
"平安综合金融服务",
|
||||||
|
"爱奇艺",
|
||||||
|
"小米集团",
|
||||||
|
"华为云",
|
||||||
|
"微店",
|
||||||
|
"恒生集团",
|
||||||
|
"网易有道",
|
||||||
|
"boccfc",
|
||||||
|
"世纪思速科技",
|
||||||
|
"海康消防",
|
||||||
|
"beijing xiaomi",
|
||||||
|
"众安科技",
|
||||||
|
"五八同城",
|
||||||
|
"霆程汽车租赁",
|
||||||
|
"云卖分销",
|
||||||
|
"乐信集团",
|
||||||
|
"蚂蚁",
|
||||||
|
"舶乐蜜电子商务",
|
||||||
|
"支付宝中国",
|
||||||
|
"砖块消消消",
|
||||||
|
"vivo",
|
||||||
|
"阿里互娱",
|
||||||
|
"中国平安",
|
||||||
|
"lingxihudong",
|
||||||
|
"百度网盘",
|
||||||
|
"1号店",
|
||||||
|
"字节跳动",
|
||||||
|
"京东科技",
|
||||||
|
"驴妈妈兴旅国际旅行社",
|
||||||
|
"hangzhou alibaba music",
|
||||||
|
"xunlei",
|
||||||
|
"灵犀互动娱乐",
|
||||||
|
"快手",
|
||||||
|
"youtube",
|
||||||
|
"连尚慧眼",
|
||||||
|
"腾讯体育",
|
||||||
|
"爱商在线",
|
||||||
|
"酷我音乐",
|
||||||
|
"金融壹账通",
|
||||||
|
"搜狗服务",
|
||||||
|
"banma information",
|
||||||
|
"a站",
|
||||||
|
"罗汉堂",
|
||||||
|
"薇仕网络",
|
||||||
|
"搜狐新闻",
|
||||||
|
"贝宝",
|
||||||
|
"薇仕",
|
||||||
|
"口袋时尚科技",
|
||||||
|
"穆迪咨询",
|
||||||
|
"新狐投资管理",
|
||||||
|
"hikvision",
|
||||||
|
"alimama china holding limited",
|
||||||
|
"超聚变数字",
|
||||||
|
"腾讯视频",
|
||||||
|
"恒生电子",
|
||||||
|
"百度游戏",
|
||||||
|
"绿洲",
|
||||||
|
"木瓜移动",
|
||||||
|
"红袖添香",
|
||||||
|
"店匠科技",
|
||||||
|
"易贝",
|
||||||
|
"一淘网",
|
||||||
|
"博览群书",
|
||||||
|
"唯品会",
|
||||||
|
"lazglobal",
|
||||||
|
"amap",
|
||||||
|
"芒果网",
|
||||||
|
"口碑",
|
||||||
|
"海康慧影",
|
||||||
|
"腾讯音乐娱乐",
|
||||||
|
"网易严选",
|
||||||
|
"微信",
|
||||||
|
"shenzhen lexin holding",
|
||||||
|
"hangzhou pingpeng intelligent",
|
||||||
|
"连尚网络",
|
||||||
|
"海思",
|
||||||
|
"isunor",
|
||||||
|
"蝉翼",
|
||||||
|
"阿里游戏",
|
||||||
|
"广州优视",
|
||||||
|
"优视",
|
||||||
|
"腾讯征信",
|
||||||
|
"识装",
|
||||||
|
"finserve.pingan.com",
|
||||||
|
"papaya",
|
||||||
|
"阅文",
|
||||||
|
"平安健康保险",
|
||||||
|
"考拉海购",
|
||||||
|
"网易印象",
|
||||||
|
"wifi万能钥匙",
|
||||||
|
"新浪互联服务",
|
||||||
|
"亚马逊云科技",
|
||||||
|
"迅雷看看",
|
||||||
|
"华为朗新科技",
|
||||||
|
"adyen hong kong limited",
|
||||||
|
"谷歌",
|
||||||
|
"得物",
|
||||||
|
"网心",
|
||||||
|
"cainiao network",
|
||||||
|
"沐瞳",
|
||||||
|
"linkedln",
|
||||||
|
"hundsun",
|
||||||
|
"阿里旅行",
|
||||||
|
"珍爱网",
|
||||||
|
"阿里巴巴通信",
|
||||||
|
"金山奇剑",
|
||||||
|
"tongtool",
|
||||||
|
"华为安捷信电气",
|
||||||
|
"快乐时代",
|
||||||
|
"平安寿险",
|
||||||
|
"微博",
|
||||||
|
"微跳蚤",
|
||||||
|
"oppo移动通信",
|
||||||
|
"毒",
|
||||||
|
"alimama",
|
||||||
|
"shoplazza",
|
||||||
|
"shenzhen dianjiang science and",
|
||||||
|
"众鸣世科",
|
||||||
|
"平安金融",
|
||||||
|
"狐友",
|
||||||
|
"维沃移动通信",
|
||||||
|
"tobosoft",
|
||||||
|
"齐力电商",
|
||||||
|
"ali",
|
||||||
|
"诚信通",
|
||||||
|
"行吟",
|
||||||
|
"跳舞的线",
|
||||||
|
"橙心优选",
|
||||||
|
"众安健康",
|
||||||
|
"亚马逊中国投资",
|
||||||
|
"德絮投资管理中心合伙",
|
||||||
|
"招联消费金融",
|
||||||
|
"百度文学",
|
||||||
|
"芝麻信用",
|
||||||
|
"阿里零售通",
|
||||||
|
"时装",
|
||||||
|
"花样直播",
|
||||||
|
"sogou",
|
||||||
|
"uc",
|
||||||
|
"海思半导体",
|
||||||
|
"zhongan online p&c insurance",
|
||||||
|
"新浪数字",
|
||||||
|
"驴妈妈旅游网",
|
||||||
|
"华为数字能源技术",
|
||||||
|
"京东数科",
|
||||||
|
"oracle",
|
||||||
|
"xiaomi",
|
||||||
|
"nyse",
|
||||||
|
"阳光消费金融",
|
||||||
|
"天天动听",
|
||||||
|
"大众点评",
|
||||||
|
"上海瑞家",
|
||||||
|
"trustpass",
|
||||||
|
"hundsun technologies",
|
||||||
|
"美团小贷",
|
||||||
|
"ebay",
|
||||||
|
"通途",
|
||||||
|
"tcl",
|
||||||
|
"鸿蒙",
|
||||||
|
"酷狗计算机",
|
||||||
|
"品诺保险",
|
||||||
|
"capitalg",
|
||||||
|
"康盛创想",
|
||||||
|
"58同城",
|
||||||
|
"闲鱼",
|
||||||
|
"微软",
|
||||||
|
"吉易付科技",
|
||||||
|
"理财通",
|
||||||
|
"ctrip",
|
||||||
|
"yy",
|
||||||
|
"华为数字",
|
||||||
|
"kingsoft",
|
||||||
|
"孙宁金融",
|
||||||
|
"房江湖经纪",
|
||||||
|
"youku",
|
||||||
|
"ant financial services group",
|
||||||
|
"盒马",
|
||||||
|
"sensetime",
|
||||||
|
"伊千网络",
|
||||||
|
"小豹ai翻译棒",
|
||||||
|
"shopify",
|
||||||
|
"前海微众银行",
|
||||||
|
"qd",
|
||||||
|
"gmail",
|
||||||
|
"pingpong",
|
||||||
|
"alibaba group holding limited",
|
||||||
|
"捷信时空电子商务",
|
||||||
|
"orientsec",
|
||||||
|
"乔戈里管理咨询",
|
||||||
|
"ant",
|
||||||
|
"锐讯灵通",
|
||||||
|
"兴业消费金融",
|
||||||
|
"京东叁佰陆拾度电子商务",
|
||||||
|
"新浪",
|
||||||
|
"优酷土豆",
|
||||||
|
"海康机器人",
|
||||||
|
"美团单车",
|
||||||
|
"海康存储",
|
||||||
|
"领英",
|
||||||
|
"阿里全球速卖通",
|
||||||
|
"美菜网",
|
||||||
|
"京邦达",
|
||||||
|
"安居客",
|
||||||
|
"阿里体育",
|
||||||
|
"相互宝",
|
||||||
|
"cloudwalk",
|
||||||
|
"百度智能云",
|
||||||
|
"贝壳",
|
||||||
|
"酷狗",
|
||||||
|
"sunshine consumer finance",
|
||||||
|
"掌宜",
|
||||||
|
"奇酷网",
|
||||||
|
"核新同花顺",
|
||||||
|
"阿里巴巴影业",
|
||||||
|
"节创",
|
||||||
|
"学而思网校",
|
||||||
|
"速途",
|
||||||
|
"途牛",
|
||||||
|
"阿里云计算",
|
||||||
|
"beijing sensetime",
|
||||||
|
"alibaba cloud",
|
||||||
|
"西瓜视频",
|
||||||
|
"美团优选",
|
||||||
|
"orient securities limited",
|
||||||
|
"华为朗新",
|
||||||
|
"店匠",
|
||||||
|
"shanghai weishi network",
|
||||||
|
"友盟",
|
||||||
|
"飞猪旅行",
|
||||||
|
"滴滴出行",
|
||||||
|
"alipay",
|
||||||
|
"mogu",
|
||||||
|
"dangdang",
|
||||||
|
"大麦网",
|
||||||
|
"汉军智能系统",
|
||||||
|
"百度地图",
|
||||||
|
"货车帮",
|
||||||
|
"狐狸金服",
|
||||||
|
"众安在线保险经纪",
|
||||||
|
"华为通信",
|
||||||
|
"新浪支付",
|
||||||
|
"zhihu",
|
||||||
|
"alibaba cloud computing",
|
||||||
|
"沙发视频",
|
||||||
|
"金山软件",
|
||||||
|
"ping an good doctor",
|
||||||
|
"携程",
|
||||||
|
"脉脉",
|
||||||
|
"youku information beijing",
|
||||||
|
"zhongan",
|
||||||
|
"艾丁软件",
|
||||||
|
"乒乓智能",
|
||||||
|
"蘑菇街",
|
||||||
|
"taobao",
|
||||||
|
"华为技术服务",
|
||||||
|
"仕承文化传播",
|
||||||
|
"安捷信",
|
||||||
|
"狐狸互联网小额贷款",
|
||||||
|
"节点迅捷",
|
||||||
|
"中国银行",
|
||||||
|
"搜镇",
|
||||||
|
"众安在线",
|
||||||
|
"dingtalk",
|
||||||
|
"云从科技",
|
||||||
|
"beijing jingbangda trade",
|
||||||
|
"moody s",
|
||||||
|
"滚动的天空",
|
||||||
|
"yl.pingan.com",
|
||||||
|
"奇虎",
|
||||||
|
"alihealth",
|
||||||
|
"芒果tv",
|
||||||
|
"lufax",
|
||||||
|
"美团打车",
|
||||||
|
"小桔",
|
||||||
|
"贝壳找房网",
|
||||||
|
"小米科技",
|
||||||
|
"vips",
|
||||||
|
"kindle",
|
||||||
|
"亚马逊服务",
|
||||||
|
"citic consumer finance",
|
||||||
|
"微众",
|
||||||
|
"搜狗智慧互联网医院",
|
||||||
|
"盒马鲜生",
|
||||||
|
"life.pinan.com",
|
||||||
|
"ph.com.cn",
|
||||||
|
"银联",
|
||||||
|
"cmbchina",
|
||||||
|
"平安金融科技咨询",
|
||||||
|
"微保",
|
||||||
|
"甲骨文中国",
|
||||||
|
"飞书",
|
||||||
|
"koubei shanghai information",
|
||||||
|
"企鹅辅导",
|
||||||
|
"斑马",
|
||||||
|
"平安租赁",
|
||||||
|
"云从",
|
||||||
|
"马上消费",
|
||||||
|
"hangzhou ali baba advertising",
|
||||||
|
"金山",
|
||||||
|
"赛盒",
|
||||||
|
"科大讯飞",
|
||||||
|
"金星创业投资",
|
||||||
|
"平安国际融资租赁",
|
||||||
|
"360你财富",
|
||||||
|
"西山居",
|
||||||
|
"shenzhen qianhai fourth paradigm data",
|
||||||
|
"海思光电子",
|
||||||
|
"猎户星空",
|
||||||
|
"网易公司",
|
||||||
|
"浪潮",
|
||||||
|
"粒粒橙传媒",
|
||||||
|
"招联金融",
|
||||||
|
"100. me",
|
||||||
|
"捷信信驰咨询",
|
||||||
|
"唯品仓",
|
||||||
|
"orient",
|
||||||
|
"趣拿",
|
||||||
|
"摩拜单车",
|
||||||
|
"天猫精灵",
|
||||||
|
"菜鸟",
|
||||||
|
"豹小贩",
|
||||||
|
"去哪儿",
|
||||||
|
"米家",
|
||||||
|
"哈啰单车",
|
||||||
|
"搜狐体育",
|
||||||
|
"shopify payments usa",
|
||||||
|
"高德软件",
|
||||||
|
"讯联智付",
|
||||||
|
"乐信",
|
||||||
|
"唯你搭",
|
||||||
|
"第四范式",
|
||||||
|
"菜鸟网络",
|
||||||
|
"同程",
|
||||||
|
"yy语音",
|
||||||
|
"浪潮云",
|
||||||
|
"东财",
|
||||||
|
"淘宝",
|
||||||
|
"寻梦",
|
||||||
|
"citic securities limited",
|
||||||
|
"青橙之旅",
|
||||||
|
"阿里巴巴",
|
||||||
|
"番茄小说",
|
||||||
|
"上海亿贝",
|
||||||
|
"inspur",
|
||||||
|
"babytree inc",
|
||||||
|
"海康智慧产业股权投资基金合伙合伙",
|
||||||
|
"adyen",
|
||||||
|
"艺龙",
|
||||||
|
"蚂蚁金服",
|
||||||
|
"平安金服",
|
||||||
|
"百度百科",
|
||||||
|
"unionpay",
|
||||||
|
"当当",
|
||||||
|
"阅文集团",
|
||||||
|
"东方财富",
|
||||||
|
"东方证券",
|
||||||
|
"哈罗单车",
|
||||||
|
"优酷",
|
||||||
|
"海康",
|
||||||
|
"alipay china network",
|
||||||
|
"网商银行",
|
||||||
|
"钧正",
|
||||||
|
"property.pingan.com",
|
||||||
|
"豹咖啡",
|
||||||
|
"网易",
|
||||||
|
"我爱cba",
|
||||||
|
"theduapp",
|
||||||
|
"360",
|
||||||
|
"金山数字娱乐",
|
||||||
|
"新浪阅读",
|
||||||
|
"alibabagames",
|
||||||
|
"顺丰",
|
||||||
|
"支点商贸",
|
||||||
|
"同程旅行",
|
||||||
|
"citic securities",
|
||||||
|
"ele.com",
|
||||||
|
"tal",
|
||||||
|
"fresh hema",
|
||||||
|
"运满满",
|
||||||
|
"贝壳网",
|
||||||
|
"酷狗音乐",
|
||||||
|
"鲜城",
|
||||||
|
"360健康",
|
||||||
|
"浪潮世科",
|
||||||
|
"迅雷网络",
|
||||||
|
"哔哩哔哩",
|
||||||
|
"华为电动",
|
||||||
|
"淘友天下",
|
||||||
|
"华多网络",
|
||||||
|
"xunlei networking technologies",
|
||||||
|
"云杉",
|
||||||
|
"当当网电子商务",
|
||||||
|
"津虹网络",
|
||||||
|
"wedoc cloud hangzhou holdings",
|
||||||
|
"alisports shanghai",
|
||||||
|
"旷视金智",
|
||||||
|
"钉钉中国",
|
||||||
|
"微影",
|
||||||
|
"金山快快",
|
||||||
|
"亿贝",
|
||||||
|
"wedoc",
|
||||||
|
"autonavi",
|
||||||
|
"哈啰助力车",
|
||||||
|
"google cloud",
|
||||||
|
"新浪乐居",
|
||||||
|
"京东股票",
|
||||||
|
"搜狗智慧远程医疗中心",
|
||||||
|
"中银消金",
|
||||||
|
"merchants union consumer finance",
|
||||||
|
"王者荣耀",
|
||||||
|
"百度手机",
|
||||||
|
"美团民宿",
|
||||||
|
"kaola",
|
||||||
|
"小屋",
|
||||||
|
"金山网络",
|
||||||
|
"来往",
|
||||||
|
"顺丰速运",
|
||||||
|
"腾讯课堂",
|
||||||
|
"百度在线网络",
|
||||||
|
"美团买菜",
|
||||||
|
"威视汽车",
|
||||||
|
"uc mobile",
|
||||||
|
"来赞达",
|
||||||
|
"平安健康医疗",
|
||||||
|
"豹小秘",
|
||||||
|
"尚网",
|
||||||
|
"哈勃投资",
|
||||||
|
" ping an insurance group of china ,",
|
||||||
|
"小米",
|
||||||
|
"360好药",
|
||||||
|
"qq音乐",
|
||||||
|
"lingxigames",
|
||||||
|
"faceu激萌",
|
||||||
|
"搜狗",
|
||||||
|
"sohu",
|
||||||
|
"满帮",
|
||||||
|
"vipshop",
|
||||||
|
"wishpost",
|
||||||
|
"金山世游",
|
||||||
|
"shanghai yibaimi network",
|
||||||
|
"1688",
|
||||||
|
"海康汽车",
|
||||||
|
"顺丰控股",
|
||||||
|
"华为",
|
||||||
|
"妙镜vr",
|
||||||
|
"paybkj.com",
|
||||||
|
"hellobike",
|
||||||
|
"豹来电",
|
||||||
|
"京东",
|
||||||
|
"驴妈妈",
|
||||||
|
"momo",
|
||||||
|
"平安健康险",
|
||||||
|
"哈勃科技",
|
||||||
|
"美菜",
|
||||||
|
"众安在线财产保险",
|
||||||
|
"海康威视",
|
||||||
|
"east money information",
|
||||||
|
"阿里云",
|
||||||
|
"蝉游记",
|
||||||
|
"余额宝",
|
||||||
|
"屋客",
|
||||||
|
"滴滴",
|
||||||
|
"shopify international limited",
|
||||||
|
"百度",
|
||||||
|
"阿里健康中国",
|
||||||
|
"阿里通信",
|
||||||
|
"微梦创科",
|
||||||
|
"微医云",
|
||||||
|
"轻颜相机",
|
||||||
|
"搜易居",
|
||||||
|
"趣店集团",
|
||||||
|
"美团云",
|
||||||
|
"ant group",
|
||||||
|
"金山云",
|
||||||
|
"beijing express hand",
|
||||||
|
"觅觅",
|
||||||
|
"支付宝",
|
||||||
|
"滴滴承信科技咨询服务",
|
||||||
|
"拼多多",
|
||||||
|
"众安运动",
|
||||||
|
"乞力电商",
|
||||||
|
"youcash",
|
||||||
|
"唯品金融",
|
||||||
|
"陆金所",
|
||||||
|
"本地生活",
|
||||||
|
"sz dji",
|
||||||
|
"海康智能",
|
||||||
|
"魔方网聘",
|
||||||
|
"青藤大学",
|
||||||
|
"international business machines",
|
||||||
|
"学而思",
|
||||||
|
"beijing zhongming century science and",
|
||||||
|
"猎豹清理大师",
|
||||||
|
"asinking",
|
||||||
|
"高德",
|
||||||
|
"苏宁",
|
||||||
|
"优酷网",
|
||||||
|
"艾丁",
|
||||||
|
"中银消费金融",
|
||||||
|
"京东健康",
|
||||||
|
"五八教育",
|
||||||
|
"pingpongx",
|
||||||
|
"搜狐时尚",
|
||||||
|
"阿里广告",
|
||||||
|
"平安财险",
|
||||||
|
"中邮消金",
|
||||||
|
"etao",
|
||||||
|
"怕怕",
|
||||||
|
"nyse:cmcm",
|
||||||
|
"华为培训中心",
|
||||||
|
"高德地图",
|
||||||
|
"云狐天下征信",
|
||||||
|
"大疆创新",
|
||||||
|
"连尚",
|
||||||
|
"壹佰米",
|
||||||
|
"康健公司",
|
||||||
|
"iqiyi.com",
|
||||||
|
"360安全云盘",
|
||||||
|
"馒头直播",
|
||||||
|
"淘友网",
|
||||||
|
"东方赢家",
|
||||||
|
"bank of china",
|
||||||
|
"微众银行",
|
||||||
|
"阿里巴巴国际站",
|
||||||
|
"虾米",
|
||||||
|
"去哪儿网",
|
||||||
|
"ctrip travel network shanghai",
|
||||||
|
"潇湘书院",
|
||||||
|
"腾讯",
|
||||||
|
"快乐阳光互动娱乐传媒",
|
||||||
|
"迅雷",
|
||||||
|
"weidian",
|
||||||
|
"滴滴货运",
|
||||||
|
"ping an puhui enterprise management",
|
||||||
|
"新浪仓石基金销售",
|
||||||
|
"搜狐焦点",
|
||||||
|
"alibaba pictures",
|
||||||
|
"wps",
|
||||||
|
"平安",
|
||||||
|
"lazmall",
|
||||||
|
"百度开放平台",
|
||||||
|
"兴业消金",
|
||||||
|
" 珍爱网",
|
||||||
|
"京东云",
|
||||||
|
"小红书",
|
||||||
|
"1688. com",
|
||||||
|
"如视智数",
|
||||||
|
"missfresh",
|
||||||
|
"pazl.pingan.cn",
|
||||||
|
"平安集团",
|
||||||
|
"kugou",
|
||||||
|
"懂车帝",
|
||||||
|
"斑马智行",
|
||||||
|
"浪潮集团",
|
||||||
|
"netease hangzhou network",
|
||||||
|
"pagd.net",
|
||||||
|
"探探",
|
||||||
|
"chinaliterature",
|
||||||
|
"amazon亚马逊",
|
||||||
|
"alphabet",
|
||||||
|
"当当文创手工艺品电子商务",
|
||||||
|
"五八邦",
|
||||||
|
"shenzhen zhenai network information",
|
||||||
|
"lingshoutong",
|
||||||
|
"字节",
|
||||||
|
"lvmama",
|
||||||
|
"金山办公",
|
||||||
|
"众安保险",
|
||||||
|
"时装信息",
|
||||||
|
"优视科技",
|
||||||
|
"guangzhou kugou",
|
||||||
|
"ibm",
|
||||||
|
"滴滴打车",
|
||||||
|
"beijing sogou information service",
|
||||||
|
"megvii",
|
||||||
|
"健谈哥",
|
||||||
|
"cloudwalk group",
|
||||||
|
"蜂联科技",
|
||||||
|
"冬云",
|
||||||
|
"京东尚科",
|
||||||
|
"钢琴块2",
|
||||||
|
"京东世纪",
|
||||||
|
"商汤",
|
||||||
|
"众鸣世纪",
|
||||||
|
"腾讯音乐",
|
||||||
|
"迅雷网文化",
|
||||||
|
"华为云计算技术",
|
||||||
|
"live.me",
|
||||||
|
"全球速卖通",
|
||||||
|
"快的打车",
|
||||||
|
"hello group inc",
|
||||||
|
"美丽说",
|
||||||
|
"suning",
|
||||||
|
"opengauss",
|
||||||
|
"lazada",
|
||||||
|
"tmall",
|
||||||
|
"acfun",
|
||||||
|
"当当网",
|
||||||
|
"中银",
|
||||||
|
"旷视科技",
|
||||||
|
"百度钱包",
|
||||||
|
"淘宝网",
|
||||||
|
"新浪微博",
|
||||||
|
"迅雷集团",
|
||||||
|
"中信消费金融",
|
||||||
|
"学而思教育",
|
||||||
|
"平安普惠",
|
||||||
|
"悟空跨境",
|
||||||
|
"irobotbox",
|
||||||
|
"平安产险",
|
||||||
|
"inspur group",
|
||||||
|
"世纪卓越快递服务",
|
||||||
|
"奇虎360",
|
||||||
|
"webank",
|
||||||
|
"偶藻",
|
||||||
|
"唯品支付",
|
||||||
|
"腾讯云计算",
|
||||||
|
"众安服务",
|
||||||
|
"亿之唐",
|
||||||
|
"beijing 58 information ttechnology",
|
||||||
|
"平安好医生",
|
||||||
|
"迅雷之锤",
|
||||||
|
"旅行小账本",
|
||||||
|
"芒果游戏",
|
||||||
|
"新浪传媒",
|
||||||
|
"旷镜博煊",
|
||||||
|
"全民k歌",
|
||||||
|
"滴滴支付",
|
||||||
|
"北京网心科技",
|
||||||
|
"挂号网",
|
||||||
|
"萤石",
|
||||||
|
"chinavision media group limited",
|
||||||
|
"猎豹安全大师",
|
||||||
|
"cmcm",
|
||||||
|
"趣店",
|
||||||
|
"蚂蚁财富",
|
||||||
|
"商汤科技",
|
||||||
|
"甲骨文",
|
||||||
|
"百度云",
|
||||||
|
"百度apollo",
|
||||||
|
"19 pay",
|
||||||
|
"stock.pingan.com",
|
||||||
|
"tiktok",
|
||||||
|
"alibaba pictures group limited",
|
||||||
|
"ele",
|
||||||
|
"考拉",
|
||||||
|
"天猫",
|
||||||
|
"腾讯优图",
|
||||||
|
"起点中文网",
|
||||||
|
"百度视频",
|
||||||
|
"shanghai bili bili",
|
||||||
|
"京东物流",
|
||||||
|
"ebay marketplaces gmbh",
|
||||||
|
"alibaba sport",
|
||||||
|
"wish",
|
||||||
|
"阿里巴巴中国",
|
||||||
|
"中国银联",
|
||||||
|
"alibaba china network",
|
||||||
|
"china ping an property insurance",
|
||||||
|
"百度糯米网",
|
||||||
|
"微软中国",
|
||||||
|
"一九付",
|
||||||
|
"4 paradigm",
|
||||||
|
"叮咚买菜",
|
||||||
|
"umeng",
|
||||||
|
"众鸣科技",
|
||||||
|
"平安财富通",
|
||||||
|
"google",
|
||||||
|
"巨量引擎",
|
||||||
|
"百度贴吧",
|
||||||
|
"beijing jingdong century information",
|
||||||
|
"讯飞",
|
||||||
|
"beijing yunshan information",
|
||||||
|
"满运软件",
|
||||||
|
"中邮消费金融",
|
||||||
|
"饿了么",
|
||||||
|
"alios",
|
||||||
|
"腾讯ai实验室",
|
||||||
|
"第四范式智能",
|
||||||
|
"瀚星创业投资",
|
||||||
|
"gradient ventures",
|
||||||
|
"microsoft",
|
||||||
|
"哈啰共享汽车",
|
||||||
|
"乞力电子商务",
|
||||||
|
"mscf",
|
||||||
|
"网易影业文化",
|
||||||
|
"铁友旅游咨询",
|
||||||
|
"kilimall",
|
||||||
|
"云企互联投资",
|
||||||
|
"ping an financial consulting",
|
||||||
|
"beijng jingdong century commerce",
|
||||||
|
"高德威智能交通系统",
|
||||||
|
"中友信息",
|
||||||
|
"平安医疗健康管理",
|
||||||
|
"eciticcfc",
|
||||||
|
"中信证券",
|
||||||
|
"fliggy",
|
||||||
|
"电子湾",
|
||||||
|
"旷云金智",
|
||||||
|
"微粒贷",
|
||||||
|
"rsi",
|
||||||
|
"滴滴云计算",
|
||||||
|
"google ventures",
|
||||||
|
"箐程",
|
||||||
|
"每日优鲜",
|
||||||
|
"音兔",
|
||||||
|
"拉扎斯",
|
||||||
|
"今日头条",
|
||||||
|
"乐信控股",
|
||||||
|
"猎豹浏览器",
|
||||||
|
"细微咨询",
|
||||||
|
"好未来",
|
||||||
|
"我乐",
|
||||||
|
"绘声绘色",
|
||||||
|
"抖音",
|
||||||
|
"搜狐新时代",
|
||||||
|
"飞猪",
|
||||||
|
"鹅厂",
|
||||||
|
"贝壳找房",
|
||||||
|
"tuniu",
|
||||||
|
"红马传媒文化",
|
||||||
|
"钉钉",
|
||||||
|
"马上消费金融",
|
||||||
|
"360手机",
|
||||||
|
"平安医保",
|
||||||
|
"快途",
|
||||||
|
"alibaba",
|
||||||
|
"小哈换电",
|
||||||
|
"大麦",
|
||||||
|
"恒睿人工智能研究院",
|
||||||
|
"谷歌资本",
|
||||||
|
"猎豹",
|
||||||
|
"穆迪信息"
|
||||||
|
]
|
||||||
595
deepdoc/parser/resume/entities/res/good_sch.json
Normal file
595
deepdoc/parser/resume/entities/res/good_sch.json
Normal file
@@ -0,0 +1,595 @@
|
|||||||
|
[
|
||||||
|
"中国科技大学",
|
||||||
|
"国防科学技术大学",
|
||||||
|
"清华大学",
|
||||||
|
"清华",
|
||||||
|
"tsinghua university",
|
||||||
|
"thu",
|
||||||
|
"北京大学",
|
||||||
|
"北大",
|
||||||
|
"beijing university",
|
||||||
|
"pku",
|
||||||
|
"中国科学技术大学",
|
||||||
|
"中国科大",
|
||||||
|
"中科大",
|
||||||
|
"china science & technology university",
|
||||||
|
"ustc",
|
||||||
|
"复旦大学",
|
||||||
|
"复旦",
|
||||||
|
"fudan university",
|
||||||
|
"fdu",
|
||||||
|
"中国人民大学",
|
||||||
|
"人大",
|
||||||
|
"人民大学",
|
||||||
|
"renmin university of china",
|
||||||
|
"ruc",
|
||||||
|
"上海交通大学",
|
||||||
|
"上海交大",
|
||||||
|
"shanghai jiao tong university",
|
||||||
|
"sjtu",
|
||||||
|
"南京大学",
|
||||||
|
"南大",
|
||||||
|
"nanjing university",
|
||||||
|
"nju",
|
||||||
|
"同济大学",
|
||||||
|
"同济",
|
||||||
|
"tongji university",
|
||||||
|
"tongji",
|
||||||
|
"浙江大学",
|
||||||
|
"浙大",
|
||||||
|
"zhejiang university",
|
||||||
|
"zju",
|
||||||
|
"南开大学",
|
||||||
|
"南开",
|
||||||
|
"nankai university",
|
||||||
|
"nku",
|
||||||
|
"北京航空航天大学",
|
||||||
|
"北航",
|
||||||
|
"beihang university",
|
||||||
|
"buaa",
|
||||||
|
"北京师范大学",
|
||||||
|
"北师",
|
||||||
|
"北师大",
|
||||||
|
"beijing normal university",
|
||||||
|
"bnu",
|
||||||
|
"武汉大学",
|
||||||
|
"武大",
|
||||||
|
"wuhan university",
|
||||||
|
"whu",
|
||||||
|
"西安交通大学",
|
||||||
|
"西安交大",
|
||||||
|
"xi’an jiaotong university",
|
||||||
|
"xjtu",
|
||||||
|
"天津大学",
|
||||||
|
"天大",
|
||||||
|
"university of tianjin",
|
||||||
|
"tju",
|
||||||
|
"华中科技大学",
|
||||||
|
"华中大",
|
||||||
|
"central china university science and technology",
|
||||||
|
"hust",
|
||||||
|
"北京理工大学",
|
||||||
|
"北理",
|
||||||
|
"beijing institute of technology",
|
||||||
|
"bit",
|
||||||
|
"东南大学",
|
||||||
|
"东大",
|
||||||
|
"southeast china university",
|
||||||
|
"seu",
|
||||||
|
"中山大学",
|
||||||
|
"中大",
|
||||||
|
"zhongshan university",
|
||||||
|
"sysu",
|
||||||
|
"华东师范大学",
|
||||||
|
"华师大",
|
||||||
|
"east china normal university",
|
||||||
|
"ecnu",
|
||||||
|
"哈尔滨工业大学",
|
||||||
|
"哈工大",
|
||||||
|
"harbin institute of technology",
|
||||||
|
"hit",
|
||||||
|
"厦门大学",
|
||||||
|
"厦大",
|
||||||
|
"xiamen university",
|
||||||
|
"xmu",
|
||||||
|
"西北工业大学",
|
||||||
|
"西工大",
|
||||||
|
"西北工大",
|
||||||
|
"northwestern polytechnical university",
|
||||||
|
"npu",
|
||||||
|
"中南大学",
|
||||||
|
"中南",
|
||||||
|
"middle and southern university",
|
||||||
|
"csu",
|
||||||
|
"大连理工大学",
|
||||||
|
"大工",
|
||||||
|
"institute of technology of dalian",
|
||||||
|
"dut",
|
||||||
|
"四川大学",
|
||||||
|
"川大",
|
||||||
|
"sichuan university",
|
||||||
|
"scu",
|
||||||
|
"电子科技大学",
|
||||||
|
"电子科大",
|
||||||
|
"university of electronic science and technology of china",
|
||||||
|
"uestc",
|
||||||
|
"华南理工大学",
|
||||||
|
"华南理工",
|
||||||
|
"institutes of technology of south china",
|
||||||
|
"scut",
|
||||||
|
"吉林大学",
|
||||||
|
"吉大",
|
||||||
|
"jilin university",
|
||||||
|
"jlu",
|
||||||
|
"湖南大学",
|
||||||
|
"湖大",
|
||||||
|
"hunan university",
|
||||||
|
"hnu",
|
||||||
|
"重庆大学",
|
||||||
|
"重大",
|
||||||
|
"university of chongqing",
|
||||||
|
"cqu",
|
||||||
|
"山东大学",
|
||||||
|
"山大",
|
||||||
|
"shandong university",
|
||||||
|
"sdu",
|
||||||
|
"中国农业大学",
|
||||||
|
"中国农大",
|
||||||
|
"china agricultural university",
|
||||||
|
"cau",
|
||||||
|
"中国海洋大学",
|
||||||
|
"中国海大",
|
||||||
|
"chinese marine university",
|
||||||
|
"ouc",
|
||||||
|
"中央民族大学",
|
||||||
|
"中央民大",
|
||||||
|
"central university for nationalities",
|
||||||
|
"muc",
|
||||||
|
"东北大学",
|
||||||
|
"东北工学院",
|
||||||
|
"northeastern university",
|
||||||
|
"neu 或 nu",
|
||||||
|
"兰州大学",
|
||||||
|
"兰大",
|
||||||
|
"lanzhou university",
|
||||||
|
"lzu",
|
||||||
|
"西北农林科技大学",
|
||||||
|
"西农","西北农大",
|
||||||
|
"northwest a&f university",
|
||||||
|
"nwafu",
|
||||||
|
"中国人民解放军国防科技大学",
|
||||||
|
"国防科技大学","国防科大",
|
||||||
|
"national university of defense technology",
|
||||||
|
"nudt",
|
||||||
|
"郑州大学",
|
||||||
|
"郑大",
|
||||||
|
"zhengzhou university",
|
||||||
|
"zzu",
|
||||||
|
"云南大学",
|
||||||
|
"云大",
|
||||||
|
"yunnan university",
|
||||||
|
"ynu",
|
||||||
|
"新疆大学",
|
||||||
|
"新大",
|
||||||
|
"xinjiang university",
|
||||||
|
"xju",
|
||||||
|
"北京交通大学",
|
||||||
|
"北京交大",
|
||||||
|
"beijing jiaotong university",
|
||||||
|
"bjtu",
|
||||||
|
"北京工业大学",
|
||||||
|
"北工大",
|
||||||
|
"beijing university of technology",
|
||||||
|
"bjut",
|
||||||
|
"北京科技大学",
|
||||||
|
"北科大","北京科大",
|
||||||
|
"university of science and technology beijing",
|
||||||
|
"ustb",
|
||||||
|
"北京化工大学",
|
||||||
|
"北化",
|
||||||
|
"beijing university of chemical technology",
|
||||||
|
"buct",
|
||||||
|
"北京邮电大学",
|
||||||
|
"北邮",
|
||||||
|
"beijing university of posts and telecommunications",
|
||||||
|
"beijing university of post and telecommunications",
|
||||||
|
"beijing university of post and telecommunication",
|
||||||
|
"beijing university of posts and telecommunication",
|
||||||
|
"bupt",
|
||||||
|
"北京林业大学",
|
||||||
|
"北林",
|
||||||
|
"beijing forestry university",
|
||||||
|
"bfu",
|
||||||
|
"北京协和医学院",
|
||||||
|
"协和医学院",
|
||||||
|
"peking union medical college",
|
||||||
|
"pumc",
|
||||||
|
"北京中医药大学",
|
||||||
|
"北中医",
|
||||||
|
"beijing university of chinese medicine",
|
||||||
|
"bucm",
|
||||||
|
"首都师范大学",
|
||||||
|
"首师大",
|
||||||
|
"capital normal university",
|
||||||
|
"cnu",
|
||||||
|
"北京外国语大学",
|
||||||
|
"北外",
|
||||||
|
"beijing foreign studies university",
|
||||||
|
"bfsu",
|
||||||
|
"中国传媒大学",
|
||||||
|
"中媒",
|
||||||
|
"中传",
|
||||||
|
"北京广播学院",
|
||||||
|
"communication university of china",
|
||||||
|
"cuc",
|
||||||
|
"中央财经大学",
|
||||||
|
"中央财大",
|
||||||
|
"中财大",
|
||||||
|
"the central university of finance and economics",
|
||||||
|
"cufe",
|
||||||
|
"对外经济贸易大学",
|
||||||
|
"对外经贸大学",
|
||||||
|
"贸大",
|
||||||
|
"university of international business and economics",
|
||||||
|
"uibe",
|
||||||
|
"外交学院",
|
||||||
|
"外院",
|
||||||
|
"china foreign affairs university",
|
||||||
|
"cfau",
|
||||||
|
"中国人民公安大学",
|
||||||
|
"公安大学",
|
||||||
|
"people's public security university of china",
|
||||||
|
"ppsuc",
|
||||||
|
"北京体育大学",
|
||||||
|
"北体大",
|
||||||
|
"beijing sport university",
|
||||||
|
"bsu",
|
||||||
|
"中央音乐学院",
|
||||||
|
"央音",
|
||||||
|
"中央院",
|
||||||
|
"central conservatory of music",
|
||||||
|
"ccom",
|
||||||
|
"中国音乐学院",
|
||||||
|
"国音",
|
||||||
|
"中国院",
|
||||||
|
"china conservatory of music",
|
||||||
|
"ccmusic",
|
||||||
|
"中央美术学院",
|
||||||
|
"央美",
|
||||||
|
"central academy of fine art",
|
||||||
|
"cafa",
|
||||||
|
"中央戏剧学院",
|
||||||
|
"中戏",
|
||||||
|
"the central academy of drama",
|
||||||
|
"tcad",
|
||||||
|
"中国政法大学",
|
||||||
|
"法大",
|
||||||
|
"china university of political science and law",
|
||||||
|
"zuc",
|
||||||
|
"cupl",
|
||||||
|
"中国科学院大学",
|
||||||
|
"国科大",
|
||||||
|
"科院大",
|
||||||
|
"university of chinese academy of sciences",
|
||||||
|
"ucas",
|
||||||
|
"福州大学",
|
||||||
|
"福大",
|
||||||
|
"university of fuzhou",
|
||||||
|
"fzu",
|
||||||
|
"暨南大学",
|
||||||
|
"暨大",
|
||||||
|
"ji'nan university",
|
||||||
|
"jnu",
|
||||||
|
"广州中医药大学",
|
||||||
|
"广中医",
|
||||||
|
"traditional chinese medicine university of guangzhou",
|
||||||
|
"gucm",
|
||||||
|
"华南师范大学",
|
||||||
|
"华南师大",
|
||||||
|
"south china normal university",
|
||||||
|
"scnu",
|
||||||
|
"广西大学",
|
||||||
|
"西大",
|
||||||
|
"guangxi university",
|
||||||
|
"gxu",
|
||||||
|
"贵州大学",
|
||||||
|
"贵大",
|
||||||
|
"guizhou university",
|
||||||
|
"gzu",
|
||||||
|
"海南大学",
|
||||||
|
"海大",
|
||||||
|
"university of hainan",
|
||||||
|
"hainu",
|
||||||
|
"河南大学",
|
||||||
|
"河大",
|
||||||
|
"he'nan university",
|
||||||
|
"henu",
|
||||||
|
"哈尔滨工程大学",
|
||||||
|
"哈工程",
|
||||||
|
"harbin engineering university",
|
||||||
|
"heu",
|
||||||
|
"东北农业大学",
|
||||||
|
"东北农大",
|
||||||
|
"northeast agricultural university",
|
||||||
|
"neau",
|
||||||
|
"东北林业大学",
|
||||||
|
"东北林大",
|
||||||
|
"northeast forestry university",
|
||||||
|
"nefu",
|
||||||
|
"中国地质大学",
|
||||||
|
"地大",
|
||||||
|
"china university of geosciences",
|
||||||
|
"cug",
|
||||||
|
"武汉理工大学",
|
||||||
|
"武汉理工",
|
||||||
|
"wuhan university of technology",
|
||||||
|
"wut",
|
||||||
|
"华中农业大学",
|
||||||
|
"华中农大",
|
||||||
|
"华农",
|
||||||
|
"central china agricultural university",
|
||||||
|
"hzau",
|
||||||
|
"华中师范大学",
|
||||||
|
"华中师大",
|
||||||
|
"华大",
|
||||||
|
"central china normal university",
|
||||||
|
"ccnu",
|
||||||
|
"中南财经政法大学",
|
||||||
|
"中南大",
|
||||||
|
"zhongnan university of economics & law",
|
||||||
|
"zuel",
|
||||||
|
"湖南师范大学",
|
||||||
|
"湖南师大",
|
||||||
|
"hunan normal university",
|
||||||
|
"hunnu",
|
||||||
|
"延边大学",
|
||||||
|
"延大",
|
||||||
|
"yanbian university",
|
||||||
|
"ybu",
|
||||||
|
"东北师范大学",
|
||||||
|
"东北师大",
|
||||||
|
"northeast normal university",
|
||||||
|
"nenu",
|
||||||
|
"苏州大学",
|
||||||
|
"苏大",
|
||||||
|
"soochow university",
|
||||||
|
"suda",
|
||||||
|
"南京航空航天大学",
|
||||||
|
"南航",
|
||||||
|
"nanjing aero-space university",
|
||||||
|
"nuaa",
|
||||||
|
"南京理工大学",
|
||||||
|
"南理工",
|
||||||
|
"institutes of technology of nanjing",
|
||||||
|
"njust",
|
||||||
|
"中国矿业大学",
|
||||||
|
"中国矿大",
|
||||||
|
"china mining university",
|
||||||
|
"cumt",
|
||||||
|
"南京邮电大学",
|
||||||
|
"南邮",
|
||||||
|
"nanjing university of posts and telecommunications",
|
||||||
|
"njupt",
|
||||||
|
"河海大学",
|
||||||
|
"河海",
|
||||||
|
"river sea university",
|
||||||
|
"hhu",
|
||||||
|
"江南大学",
|
||||||
|
"江南大",
|
||||||
|
"jiangnan university",
|
||||||
|
"jiangnan",
|
||||||
|
"南京林业大学",
|
||||||
|
"南林",
|
||||||
|
"nanjing forestry university",
|
||||||
|
"njfu",
|
||||||
|
"南京信息工程大学",
|
||||||
|
"南信大",
|
||||||
|
"nanjing university of information science and technology",
|
||||||
|
"nuist",
|
||||||
|
"南京农业大学",
|
||||||
|
"南农",
|
||||||
|
"南农大",
|
||||||
|
"南京农大",
|
||||||
|
"agricultural university of nanjing",
|
||||||
|
"njau",
|
||||||
|
"nau",
|
||||||
|
"南京中医药大学",
|
||||||
|
"南中医",
|
||||||
|
"nanjing university of chinese medicine",
|
||||||
|
"njucm",
|
||||||
|
"中国药科大学",
|
||||||
|
"中国药大",
|
||||||
|
"china medicine university",
|
||||||
|
"cpu",
|
||||||
|
"南京师范大学",
|
||||||
|
"南京师大",
|
||||||
|
"南师大",
|
||||||
|
"南师",
|
||||||
|
"nanjing normal university",
|
||||||
|
"nnu",
|
||||||
|
"南昌大学",
|
||||||
|
"昌大",
|
||||||
|
"university of nanchang","nanchang university",
|
||||||
|
"ncu",
|
||||||
|
"辽宁大学",
|
||||||
|
"辽大",
|
||||||
|
"liaoning university",
|
||||||
|
"lnu",
|
||||||
|
"大连海事大学",
|
||||||
|
"大连海大",
|
||||||
|
"海大",
|
||||||
|
"maritime affairs university of dalian",
|
||||||
|
"dmu",
|
||||||
|
"内蒙古大学",
|
||||||
|
"内大",
|
||||||
|
"university of the inner mongol","inner mongolia university",
|
||||||
|
"imu",
|
||||||
|
"宁夏大学",
|
||||||
|
"宁大",
|
||||||
|
"ningxia university",
|
||||||
|
"nxu",
|
||||||
|
"青海大学",
|
||||||
|
"清大",
|
||||||
|
"qinghai university",
|
||||||
|
"qhu",
|
||||||
|
"中国石油大学",
|
||||||
|
"中石大",
|
||||||
|
"china university of petroleum beijing",
|
||||||
|
"upc",
|
||||||
|
"太原理工大学",
|
||||||
|
"太原理工",
|
||||||
|
"institutes of technology of taiyuan","taiyuan university of technology",
|
||||||
|
"tyut",
|
||||||
|
"西北大学",
|
||||||
|
"西大",
|
||||||
|
"northwest university",
|
||||||
|
"nwu",
|
||||||
|
"西安电子科技大学",
|
||||||
|
"西电",
|
||||||
|
"xidian university",
|
||||||
|
"xdu",
|
||||||
|
"长安大学",
|
||||||
|
"长大",
|
||||||
|
"chang`an university",
|
||||||
|
"chu",
|
||||||
|
"陕西师范大学",
|
||||||
|
"陕西师大",
|
||||||
|
"陕师大",
|
||||||
|
"shaanxi normal university",
|
||||||
|
"snnu",
|
||||||
|
"第四军医大学",
|
||||||
|
"空军军医大学","四医大",
|
||||||
|
"air force medical university",
|
||||||
|
"fmmu",
|
||||||
|
"华东理工大学",
|
||||||
|
"华理",
|
||||||
|
"east china university of science",
|
||||||
|
"ecust",
|
||||||
|
"东华大学",
|
||||||
|
"东华",
|
||||||
|
"donghua university",
|
||||||
|
"dhu",
|
||||||
|
"上海海洋大学",
|
||||||
|
"上海海大",
|
||||||
|
"shanghai ocean university",
|
||||||
|
"shou",
|
||||||
|
"上海中医药大学",
|
||||||
|
"上中医",
|
||||||
|
"shanghai university of traditional chinese medicine",
|
||||||
|
"shutcm",
|
||||||
|
"上海外国语大学",
|
||||||
|
"上外",
|
||||||
|
"shanghai international studies university",
|
||||||
|
"sisu",
|
||||||
|
"上海财经大学",
|
||||||
|
"上海财大",
|
||||||
|
"上财",
|
||||||
|
"shanghai university of finance",
|
||||||
|
"sufe",
|
||||||
|
"上海体育学院",
|
||||||
|
"shanghai university of sport",
|
||||||
|
"上海音乐学院",
|
||||||
|
"上音",
|
||||||
|
"shanghai conservatory of music",
|
||||||
|
"shcm",
|
||||||
|
"上海大学",
|
||||||
|
"上大",
|
||||||
|
"shanghai university",
|
||||||
|
"第二军医大学",
|
||||||
|
"海军军医大学",
|
||||||
|
"naval medical university",
|
||||||
|
"西南交通大学",
|
||||||
|
"西南交大",
|
||||||
|
"southwest jiaotong university",
|
||||||
|
"swjtu",
|
||||||
|
"西南石油大学",
|
||||||
|
"西南石大",
|
||||||
|
"southwest petroleum university",
|
||||||
|
"swpu",
|
||||||
|
"成都理工大学",
|
||||||
|
"成都理工",
|
||||||
|
"chengdu university of technology",
|
||||||
|
"cdut ",
|
||||||
|
"四川农业大学",
|
||||||
|
"川农",
|
||||||
|
"川农大",
|
||||||
|
"sichuan agricultural university",
|
||||||
|
"sicau",
|
||||||
|
"成都中医药大学",
|
||||||
|
"成中医",
|
||||||
|
"chengdu university of tcm",
|
||||||
|
"cdutcm",
|
||||||
|
"西南财经大学",
|
||||||
|
"西南财大",
|
||||||
|
"西财",
|
||||||
|
"southwestern university of finance and economics",
|
||||||
|
"swufe",
|
||||||
|
"天津工业大学",
|
||||||
|
"天工大",
|
||||||
|
"tianjin university of technology",
|
||||||
|
"tgu",
|
||||||
|
"天津医科大学",
|
||||||
|
"天津医大",
|
||||||
|
"medical university of tianjin",
|
||||||
|
"tmu",
|
||||||
|
"天津中医药大学",
|
||||||
|
"天中",
|
||||||
|
"tianjin university of traditional chinese medicine",
|
||||||
|
"tutcm",
|
||||||
|
"华北电力大学",
|
||||||
|
"华电",
|
||||||
|
"north china electric power university",
|
||||||
|
"ncepu",
|
||||||
|
"河北工业大学",
|
||||||
|
"河工大",
|
||||||
|
"hebei university of technology",
|
||||||
|
"hebut",
|
||||||
|
"西藏大学",
|
||||||
|
"藏大",
|
||||||
|
"tibet university",
|
||||||
|
"tu",
|
||||||
|
"石河子大学",
|
||||||
|
"石大",
|
||||||
|
"shihezi university",
|
||||||
|
"中国美术学院",
|
||||||
|
"中国美院",
|
||||||
|
"国美",
|
||||||
|
"china academy of art",
|
||||||
|
"caa",
|
||||||
|
"宁波大学",
|
||||||
|
"宁大",
|
||||||
|
"ningbo university",
|
||||||
|
"nbu",
|
||||||
|
"西南大学",
|
||||||
|
"西大",
|
||||||
|
"southwest university",
|
||||||
|
"swu",
|
||||||
|
"安徽大学",
|
||||||
|
"安大",
|
||||||
|
"university of anhui",
|
||||||
|
"ahu",
|
||||||
|
"合肥工业大学",
|
||||||
|
"合肥工大",
|
||||||
|
"合工大",
|
||||||
|
"hefei university of technology",
|
||||||
|
"hfut",
|
||||||
|
"中国地质大学",
|
||||||
|
"地大",
|
||||||
|
"china university of geosciences",
|
||||||
|
"cug",
|
||||||
|
"中国地质大学",
|
||||||
|
"地大",
|
||||||
|
"北京地大",
|
||||||
|
"cugb",
|
||||||
|
"中国矿业大学",
|
||||||
|
"中国矿大",
|
||||||
|
"china university of mining & technology",
|
||||||
|
"cumtb",
|
||||||
|
"中国石油大学",
|
||||||
|
"中石大",
|
||||||
|
"石大",
|
||||||
|
"china university of petroleum",
|
||||||
|
"cup",
|
||||||
|
"中国石油大学",
|
||||||
|
"中石大",
|
||||||
|
"cup"]
|
||||||
1627
deepdoc/parser/resume/entities/res/school.rank.csv
Normal file
1627
deepdoc/parser/resume/entities/res/school.rank.csv
Normal file
File diff suppressed because it is too large
Load Diff
5713
deepdoc/parser/resume/entities/res/schools.csv
Normal file
5713
deepdoc/parser/resume/entities/res/schools.csv
Normal file
File diff suppressed because it is too large
Load Diff
91
deepdoc/parser/resume/entities/schools.py
Normal file
91
deepdoc/parser/resume/entities/schools.py
Normal file
@@ -0,0 +1,91 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import os
|
||||||
|
import json
|
||||||
|
import re
|
||||||
|
import copy
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
current_file_path = os.path.dirname(os.path.abspath(__file__))
|
||||||
|
TBL = pd.read_csv(
|
||||||
|
os.path.join(current_file_path, "res/schools.csv"), sep="\t", header=0
|
||||||
|
).fillna("")
|
||||||
|
TBL["name_en"] = TBL["name_en"].map(lambda x: x.lower().strip())
|
||||||
|
GOOD_SCH = json.load(open(os.path.join(current_file_path, "res/good_sch.json"), "r",encoding="utf-8"))
|
||||||
|
GOOD_SCH = set([re.sub(r"[,. &()()]+", "", c) for c in GOOD_SCH])
|
||||||
|
|
||||||
|
|
||||||
|
def loadRank(fnm):
|
||||||
|
global TBL
|
||||||
|
TBL["rank"] = 1000000
|
||||||
|
with open(fnm, "r", encoding="utf-8") as f:
|
||||||
|
while True:
|
||||||
|
line = f.readline()
|
||||||
|
if not line:
|
||||||
|
break
|
||||||
|
line = line.strip("\n").split(",")
|
||||||
|
try:
|
||||||
|
nm, rk = line[0].strip(), int(line[1])
|
||||||
|
# assert len(TBL[((TBL.name_cn == nm) | (TBL.name_en == nm))]),f"<{nm}>"
|
||||||
|
TBL.loc[((TBL.name_cn == nm) | (TBL.name_en == nm)), "rank"] = rk
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
loadRank(os.path.join(current_file_path, "res/school.rank.csv"))
|
||||||
|
|
||||||
|
|
||||||
|
def split(txt):
|
||||||
|
tks = []
|
||||||
|
for t in re.sub(r"[ \t]+", " ", txt).split():
|
||||||
|
if (
|
||||||
|
tks
|
||||||
|
and re.match(r".*[a-zA-Z]$", tks[-1])
|
||||||
|
and re.match(r"[a-zA-Z]", t)
|
||||||
|
and tks
|
||||||
|
):
|
||||||
|
tks[-1] = tks[-1] + " " + t
|
||||||
|
else:
|
||||||
|
tks.append(t)
|
||||||
|
return tks
|
||||||
|
|
||||||
|
|
||||||
|
def select(nm):
|
||||||
|
global TBL
|
||||||
|
if not nm:
|
||||||
|
return
|
||||||
|
if isinstance(nm, list):
|
||||||
|
nm = str(nm[0])
|
||||||
|
nm = split(nm)[0]
|
||||||
|
nm = str(nm).lower().strip()
|
||||||
|
nm = re.sub(r"[((][^()()]+[))]", "", nm.lower())
|
||||||
|
nm = re.sub(r"(^the |[,.&()();;·]+|^(英国|美国|瑞士))", "", nm)
|
||||||
|
nm = re.sub(r"大学.*学院", "大学", nm)
|
||||||
|
tbl = copy.deepcopy(TBL)
|
||||||
|
tbl["hit_alias"] = tbl["alias"].map(lambda x: nm in set(x.split("+")))
|
||||||
|
res = tbl[((tbl.name_cn == nm) | (tbl.name_en == nm) | tbl.hit_alias)]
|
||||||
|
if res.empty:
|
||||||
|
return
|
||||||
|
|
||||||
|
return json.loads(res.to_json(orient="records"))[0]
|
||||||
|
|
||||||
|
|
||||||
|
def is_good(nm):
|
||||||
|
global GOOD_SCH
|
||||||
|
nm = re.sub(r"[((][^()()]+[))]", "", nm.lower())
|
||||||
|
nm = re.sub(r"[''`‘’“”,. &()();;]+", "", nm)
|
||||||
|
return nm in GOOD_SCH
|
||||||
189
deepdoc/parser/resume/step_one.py
Normal file
189
deepdoc/parser/resume/step_one.py
Normal file
@@ -0,0 +1,189 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import json
|
||||||
|
from deepdoc.parser.resume.entities import degrees, regions, industries
|
||||||
|
|
||||||
|
FIELDS = [
|
||||||
|
"address STRING",
|
||||||
|
"annual_salary int",
|
||||||
|
"annual_salary_from int",
|
||||||
|
"annual_salary_to int",
|
||||||
|
"birth STRING",
|
||||||
|
"card STRING",
|
||||||
|
"certificate_obj string",
|
||||||
|
"city STRING",
|
||||||
|
"corporation_id int",
|
||||||
|
"corporation_name STRING",
|
||||||
|
"corporation_type STRING",
|
||||||
|
"degree STRING",
|
||||||
|
"discipline_name STRING",
|
||||||
|
"education_obj string",
|
||||||
|
"email STRING",
|
||||||
|
"expect_annual_salary int",
|
||||||
|
"expect_city_names string",
|
||||||
|
"expect_industry_name STRING",
|
||||||
|
"expect_position_name STRING",
|
||||||
|
"expect_salary_from int",
|
||||||
|
"expect_salary_to int",
|
||||||
|
"expect_type STRING",
|
||||||
|
"gender STRING",
|
||||||
|
"industry_name STRING",
|
||||||
|
"industry_names STRING",
|
||||||
|
"is_deleted STRING",
|
||||||
|
"is_fertility STRING",
|
||||||
|
"is_house STRING",
|
||||||
|
"is_management_experience STRING",
|
||||||
|
"is_marital STRING",
|
||||||
|
"is_oversea STRING",
|
||||||
|
"language_obj string",
|
||||||
|
"name STRING",
|
||||||
|
"nation STRING",
|
||||||
|
"phone STRING",
|
||||||
|
"political_status STRING",
|
||||||
|
"position_name STRING",
|
||||||
|
"project_obj string",
|
||||||
|
"responsibilities string",
|
||||||
|
"salary_month int",
|
||||||
|
"scale STRING",
|
||||||
|
"school_name STRING",
|
||||||
|
"self_remark string",
|
||||||
|
"skill_obj string",
|
||||||
|
"title_name STRING",
|
||||||
|
"tob_resume_id STRING",
|
||||||
|
"updated_at Timestamp",
|
||||||
|
"wechat STRING",
|
||||||
|
"work_obj string",
|
||||||
|
"work_experience int",
|
||||||
|
"work_start_time BIGINT"
|
||||||
|
]
|
||||||
|
|
||||||
|
def refactor(df):
|
||||||
|
def deal_obj(obj, k, kk):
|
||||||
|
if not isinstance(obj, type({})):
|
||||||
|
return ""
|
||||||
|
obj = obj.get(k, {})
|
||||||
|
if not isinstance(obj, type({})):
|
||||||
|
return ""
|
||||||
|
return obj.get(kk, "")
|
||||||
|
|
||||||
|
def loadjson(line):
|
||||||
|
try:
|
||||||
|
return json.loads(line)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
return {}
|
||||||
|
|
||||||
|
df["obj"] = df["resume_content"].map(lambda x: loadjson(x))
|
||||||
|
df.fillna("", inplace=True)
|
||||||
|
|
||||||
|
clms = ["tob_resume_id", "updated_at"]
|
||||||
|
|
||||||
|
def extract(nms, cc=None):
|
||||||
|
nonlocal clms
|
||||||
|
clms.extend(nms)
|
||||||
|
for c in nms:
|
||||||
|
if cc:
|
||||||
|
df[c] = df["obj"].map(lambda x: deal_obj(x, cc, c))
|
||||||
|
else:
|
||||||
|
df[c] = df["obj"].map(
|
||||||
|
lambda x: json.dumps(
|
||||||
|
x.get(
|
||||||
|
c,
|
||||||
|
{}),
|
||||||
|
ensure_ascii=False) if isinstance(
|
||||||
|
x,
|
||||||
|
type(
|
||||||
|
{})) and (
|
||||||
|
isinstance(
|
||||||
|
x.get(c),
|
||||||
|
type(
|
||||||
|
{})) or not x.get(c)) else str(x).replace(
|
||||||
|
"None",
|
||||||
|
""))
|
||||||
|
|
||||||
|
extract(["education", "work", "certificate", "project", "language",
|
||||||
|
"skill"])
|
||||||
|
extract(["wechat", "phone", "is_deleted",
|
||||||
|
"name", "tel", "email"], "contact")
|
||||||
|
extract(["nation", "expect_industry_name", "salary_month",
|
||||||
|
"industry_ids", "is_house", "birth", "annual_salary_from",
|
||||||
|
"annual_salary_to", "card",
|
||||||
|
"expect_salary_to", "expect_salary_from",
|
||||||
|
"expect_position_name", "gender", "city",
|
||||||
|
"is_fertility", "expect_city_names",
|
||||||
|
"political_status", "title_name", "expect_annual_salary",
|
||||||
|
"industry_name", "address", "position_name", "school_name",
|
||||||
|
"corporation_id",
|
||||||
|
"is_oversea", "responsibilities",
|
||||||
|
"work_start_time", "degree", "management_experience",
|
||||||
|
"expect_type", "corporation_type", "scale", "corporation_name",
|
||||||
|
"self_remark", "annual_salary", "work_experience",
|
||||||
|
"discipline_name", "marital", "updated_at"], "basic")
|
||||||
|
|
||||||
|
df["degree"] = df["degree"].map(lambda x: degrees.get_name(x))
|
||||||
|
df["address"] = df["address"].map(lambda x: " ".join(regions.get_names(x)))
|
||||||
|
df["industry_names"] = df["industry_ids"].map(lambda x: " ".join([" ".join(industries.get_names(i)) for i in
|
||||||
|
str(x).split(",")]))
|
||||||
|
clms.append("industry_names")
|
||||||
|
|
||||||
|
def arr2str(a):
|
||||||
|
if not a:
|
||||||
|
return ""
|
||||||
|
if isinstance(a, list):
|
||||||
|
a = " ".join([str(i) for i in a])
|
||||||
|
return str(a).replace(",", " ")
|
||||||
|
|
||||||
|
df["expect_industry_name"] = df["expect_industry_name"].map(
|
||||||
|
lambda x: arr2str(x))
|
||||||
|
df["gender"] = df["gender"].map(
|
||||||
|
lambda x: "男" if x == 'M' else (
|
||||||
|
"女" if x == 'F' else ""))
|
||||||
|
for c in ["is_fertility", "is_oversea", "is_house",
|
||||||
|
"management_experience", "marital"]:
|
||||||
|
df[c] = df[c].map(
|
||||||
|
lambda x: '是' if x == 'Y' else (
|
||||||
|
'否' if x == 'N' else ""))
|
||||||
|
df["is_management_experience"] = df["management_experience"]
|
||||||
|
df["is_marital"] = df["marital"]
|
||||||
|
clms.extend(["is_management_experience", "is_marital"])
|
||||||
|
|
||||||
|
df.fillna("", inplace=True)
|
||||||
|
for i in range(len(df)):
|
||||||
|
if not df.loc[i, "phone"].strip() and df.loc[i, "tel"].strip():
|
||||||
|
df.loc[i, "phone"] = df.loc[i, "tel"].strip()
|
||||||
|
|
||||||
|
for n in ["industry_ids", "management_experience", "marital", "tel"]:
|
||||||
|
for i in range(len(clms)):
|
||||||
|
if clms[i] == n:
|
||||||
|
del clms[i]
|
||||||
|
break
|
||||||
|
|
||||||
|
clms = list(set(clms))
|
||||||
|
|
||||||
|
df = df.reindex(sorted(clms), axis=1)
|
||||||
|
#print(json.dumps(list(df.columns.values)), "LLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLL")
|
||||||
|
for c in clms:
|
||||||
|
df[c] = df[c].map(
|
||||||
|
lambda s: str(s).replace(
|
||||||
|
"\t",
|
||||||
|
" ").replace(
|
||||||
|
"\n",
|
||||||
|
"\\n").replace(
|
||||||
|
"\r",
|
||||||
|
"\\n"))
|
||||||
|
# print(df.values.tolist())
|
||||||
|
return dict(zip([n.split()[0] for n in FIELDS], df.values.tolist()[0]))
|
||||||
696
deepdoc/parser/resume/step_two.py
Normal file
696
deepdoc/parser/resume/step_two.py
Normal file
@@ -0,0 +1,696 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import re
|
||||||
|
import copy
|
||||||
|
import time
|
||||||
|
import datetime
|
||||||
|
import demjson3
|
||||||
|
import traceback
|
||||||
|
import signal
|
||||||
|
import numpy as np
|
||||||
|
from deepdoc.parser.resume.entities import degrees, schools, corporations
|
||||||
|
from rag.nlp import rag_tokenizer, surname
|
||||||
|
from xpinyin import Pinyin
|
||||||
|
from contextlib import contextmanager
|
||||||
|
|
||||||
|
|
||||||
|
class TimeoutException(Exception):
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
@contextmanager
|
||||||
|
def time_limit(seconds):
|
||||||
|
def signal_handler(signum, frame):
|
||||||
|
raise TimeoutException("Timed out!")
|
||||||
|
|
||||||
|
signal.signal(signal.SIGALRM, signal_handler)
|
||||||
|
signal.alarm(seconds)
|
||||||
|
try:
|
||||||
|
yield
|
||||||
|
finally:
|
||||||
|
signal.alarm(0)
|
||||||
|
|
||||||
|
|
||||||
|
ENV = None
|
||||||
|
PY = Pinyin()
|
||||||
|
|
||||||
|
|
||||||
|
def rmHtmlTag(line):
|
||||||
|
return re.sub(r"<[a-z0-9.\"=';,:\+_/ -]+>", " ", line, count=100000, flags=re.IGNORECASE)
|
||||||
|
|
||||||
|
|
||||||
|
def highest_degree(dg):
|
||||||
|
if not dg:
|
||||||
|
return ""
|
||||||
|
if isinstance(dg, str):
|
||||||
|
dg = [dg]
|
||||||
|
m = {"初中": 0, "高中": 1, "中专": 2, "大专": 3, "专升本": 4, "本科": 5, "硕士": 6, "博士": 7, "博士后": 8}
|
||||||
|
return sorted([(d, m.get(d, -1)) for d in dg], key=lambda x: x[1] * -1)[0][0]
|
||||||
|
|
||||||
|
|
||||||
|
def forEdu(cv):
|
||||||
|
if not cv.get("education_obj"):
|
||||||
|
cv["integerity_flt"] *= 0.8
|
||||||
|
return cv
|
||||||
|
|
||||||
|
first_fea, fea, maj, fmaj, deg, fdeg, sch, fsch, st_dt, ed_dt = [], [], [], [], [], [], [], [], [], []
|
||||||
|
edu_nst = []
|
||||||
|
edu_end_dt = ""
|
||||||
|
cv["school_rank_int"] = 1000000
|
||||||
|
for ii, n in enumerate(sorted(cv["education_obj"], key=lambda x: x.get("start_time", "3"))):
|
||||||
|
e = {}
|
||||||
|
if n.get("end_time"):
|
||||||
|
if n["end_time"] > edu_end_dt:
|
||||||
|
edu_end_dt = n["end_time"]
|
||||||
|
try:
|
||||||
|
dt = n["end_time"]
|
||||||
|
if re.match(r"[0-9]{9,}", dt):
|
||||||
|
dt = turnTm2Dt(dt)
|
||||||
|
y, m, d = getYMD(dt)
|
||||||
|
ed_dt.append(str(y))
|
||||||
|
e["end_dt_kwd"] = str(y)
|
||||||
|
except Exception as e:
|
||||||
|
pass
|
||||||
|
if n.get("start_time"):
|
||||||
|
try:
|
||||||
|
dt = n["start_time"]
|
||||||
|
if re.match(r"[0-9]{9,}", dt):
|
||||||
|
dt = turnTm2Dt(dt)
|
||||||
|
y, m, d = getYMD(dt)
|
||||||
|
st_dt.append(str(y))
|
||||||
|
e["start_dt_kwd"] = str(y)
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
|
||||||
|
r = schools.select(n.get("school_name", ""))
|
||||||
|
if r:
|
||||||
|
if str(r.get("type", "")) == "1":
|
||||||
|
fea.append("211")
|
||||||
|
if str(r.get("type", "")) == "2":
|
||||||
|
fea.append("211")
|
||||||
|
if str(r.get("is_abroad", "")) == "1":
|
||||||
|
fea.append("留学")
|
||||||
|
if str(r.get("is_double_first", "")) == "1":
|
||||||
|
fea.append("双一流")
|
||||||
|
if str(r.get("is_985", "")) == "1":
|
||||||
|
fea.append("985")
|
||||||
|
if str(r.get("is_world_known", "")) == "1":
|
||||||
|
fea.append("海外知名")
|
||||||
|
if r.get("rank") and cv["school_rank_int"] > r["rank"]:
|
||||||
|
cv["school_rank_int"] = r["rank"]
|
||||||
|
|
||||||
|
if n.get("school_name") and isinstance(n["school_name"], str):
|
||||||
|
sch.append(re.sub(r"(211|985|重点大学|[,&;;-])", "", n["school_name"]))
|
||||||
|
e["sch_nm_kwd"] = sch[-1]
|
||||||
|
fea.append(rag_tokenizer.fine_grained_tokenize(rag_tokenizer.tokenize(n.get("school_name", ""))).split()[-1])
|
||||||
|
|
||||||
|
if n.get("discipline_name") and isinstance(n["discipline_name"], str):
|
||||||
|
maj.append(n["discipline_name"])
|
||||||
|
e["major_kwd"] = n["discipline_name"]
|
||||||
|
|
||||||
|
if not n.get("degree") and "985" in fea and not first_fea:
|
||||||
|
n["degree"] = "1"
|
||||||
|
|
||||||
|
if n.get("degree"):
|
||||||
|
d = degrees.get_name(n["degree"])
|
||||||
|
if d:
|
||||||
|
e["degree_kwd"] = d
|
||||||
|
if d == "本科" and ("专科" in deg or "专升本" in deg or "中专" in deg or "大专" in deg or re.search(r"(成人|自考|自学考试)", n.get("school_name",""))):
|
||||||
|
d = "专升本"
|
||||||
|
if d:
|
||||||
|
deg.append(d)
|
||||||
|
|
||||||
|
# for first degree
|
||||||
|
if not fdeg and d in ["中专", "专升本", "专科", "本科", "大专"]:
|
||||||
|
fdeg = [d]
|
||||||
|
if n.get("school_name"):
|
||||||
|
fsch = [n["school_name"]]
|
||||||
|
if n.get("discipline_name"):
|
||||||
|
fmaj = [n["discipline_name"]]
|
||||||
|
first_fea = copy.deepcopy(fea)
|
||||||
|
|
||||||
|
edu_nst.append(e)
|
||||||
|
|
||||||
|
cv["sch_rank_kwd"] = []
|
||||||
|
if cv["school_rank_int"] <= 20 \
|
||||||
|
or ("海外名校" in fea and cv["school_rank_int"] <= 200):
|
||||||
|
cv["sch_rank_kwd"].append("顶尖学校")
|
||||||
|
elif cv["school_rank_int"] <= 50 and cv["school_rank_int"] > 20 \
|
||||||
|
or ("海外名校" in fea and cv["school_rank_int"] <= 500 and \
|
||||||
|
cv["school_rank_int"] > 200):
|
||||||
|
cv["sch_rank_kwd"].append("精英学校")
|
||||||
|
elif cv["school_rank_int"] > 50 and ("985" in fea or "211" in fea) \
|
||||||
|
or ("海外名校" in fea and cv["school_rank_int"] > 500):
|
||||||
|
cv["sch_rank_kwd"].append("优质学校")
|
||||||
|
else:
|
||||||
|
cv["sch_rank_kwd"].append("一般学校")
|
||||||
|
|
||||||
|
if edu_nst:
|
||||||
|
cv["edu_nst"] = edu_nst
|
||||||
|
if fea:
|
||||||
|
cv["edu_fea_kwd"] = list(set(fea))
|
||||||
|
if first_fea:
|
||||||
|
cv["edu_first_fea_kwd"] = list(set(first_fea))
|
||||||
|
if maj:
|
||||||
|
cv["major_kwd"] = maj
|
||||||
|
if fsch:
|
||||||
|
cv["first_school_name_kwd"] = fsch
|
||||||
|
if fdeg:
|
||||||
|
cv["first_degree_kwd"] = fdeg
|
||||||
|
if fmaj:
|
||||||
|
cv["first_major_kwd"] = fmaj
|
||||||
|
if st_dt:
|
||||||
|
cv["edu_start_kwd"] = st_dt
|
||||||
|
if ed_dt:
|
||||||
|
cv["edu_end_kwd"] = ed_dt
|
||||||
|
if ed_dt:
|
||||||
|
cv["edu_end_int"] = max([int(t) for t in ed_dt])
|
||||||
|
if deg:
|
||||||
|
if "本科" in deg and "专科" in deg:
|
||||||
|
deg.append("专升本")
|
||||||
|
deg = [d for d in deg if d != '本科']
|
||||||
|
cv["degree_kwd"] = deg
|
||||||
|
cv["highest_degree_kwd"] = highest_degree(deg)
|
||||||
|
if edu_end_dt:
|
||||||
|
try:
|
||||||
|
if re.match(r"[0-9]{9,}", edu_end_dt):
|
||||||
|
edu_end_dt = turnTm2Dt(edu_end_dt)
|
||||||
|
if edu_end_dt.strip("\n") == "至今":
|
||||||
|
edu_end_dt = cv.get("updated_at_dt", str(datetime.date.today()))
|
||||||
|
y, m, d = getYMD(edu_end_dt)
|
||||||
|
cv["work_exp_flt"] = min(int(str(datetime.date.today())[0:4]) - int(y), cv.get("work_exp_flt", 1000))
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception("forEdu {} {} {}".format(e, edu_end_dt, cv.get("work_exp_flt")))
|
||||||
|
if sch:
|
||||||
|
cv["school_name_kwd"] = sch
|
||||||
|
if (len(cv.get("degree_kwd", [])) >= 1 and "本科" in cv["degree_kwd"]) \
|
||||||
|
or all([c.lower() in ["硕士", "博士", "mba", "博士后"] for c in cv.get("degree_kwd", [])]) \
|
||||||
|
or not cv.get("degree_kwd"):
|
||||||
|
for c in sch:
|
||||||
|
if schools.is_good(c):
|
||||||
|
if "tag_kwd" not in cv:
|
||||||
|
cv["tag_kwd"] = []
|
||||||
|
cv["tag_kwd"].append("好学校")
|
||||||
|
cv["tag_kwd"].append("好学历")
|
||||||
|
break
|
||||||
|
if (len(cv.get("degree_kwd", [])) >= 1 and \
|
||||||
|
"本科" in cv["degree_kwd"] and \
|
||||||
|
any([d.lower() in ["硕士", "博士", "mba", "博士"] for d in cv.get("degree_kwd", [])])) \
|
||||||
|
or all([d.lower() in ["硕士", "博士", "mba", "博士后"] for d in cv.get("degree_kwd", [])]) \
|
||||||
|
or any([d in ["mba", "emba", "博士后"] for d in cv.get("degree_kwd", [])]):
|
||||||
|
if "tag_kwd" not in cv:
|
||||||
|
cv["tag_kwd"] = []
|
||||||
|
if "好学历" not in cv["tag_kwd"]:
|
||||||
|
cv["tag_kwd"].append("好学历")
|
||||||
|
|
||||||
|
if cv.get("major_kwd"):
|
||||||
|
cv["major_tks"] = rag_tokenizer.tokenize(" ".join(maj))
|
||||||
|
if cv.get("school_name_kwd"):
|
||||||
|
cv["school_name_tks"] = rag_tokenizer.tokenize(" ".join(sch))
|
||||||
|
if cv.get("first_school_name_kwd"):
|
||||||
|
cv["first_school_name_tks"] = rag_tokenizer.tokenize(" ".join(fsch))
|
||||||
|
if cv.get("first_major_kwd"):
|
||||||
|
cv["first_major_tks"] = rag_tokenizer.tokenize(" ".join(fmaj))
|
||||||
|
|
||||||
|
return cv
|
||||||
|
|
||||||
|
|
||||||
|
def forProj(cv):
|
||||||
|
if not cv.get("project_obj"):
|
||||||
|
return cv
|
||||||
|
|
||||||
|
pro_nms, desc = [], []
|
||||||
|
for i, n in enumerate(
|
||||||
|
sorted(cv.get("project_obj", []), key=lambda x: str(x.get("updated_at", "")) if isinstance(x, dict) else "",
|
||||||
|
reverse=True)):
|
||||||
|
if n.get("name"):
|
||||||
|
pro_nms.append(n["name"])
|
||||||
|
if n.get("describe"):
|
||||||
|
desc.append(str(n["describe"]))
|
||||||
|
if n.get("responsibilities"):
|
||||||
|
desc.append(str(n["responsibilities"]))
|
||||||
|
if n.get("achivement"):
|
||||||
|
desc.append(str(n["achivement"]))
|
||||||
|
|
||||||
|
if pro_nms:
|
||||||
|
# cv["pro_nms_tks"] = rag_tokenizer.tokenize(" ".join(pro_nms))
|
||||||
|
cv["project_name_tks"] = rag_tokenizer.tokenize(pro_nms[0])
|
||||||
|
if desc:
|
||||||
|
cv["pro_desc_ltks"] = rag_tokenizer.tokenize(rmHtmlTag(" ".join(desc)))
|
||||||
|
cv["project_desc_ltks"] = rag_tokenizer.tokenize(rmHtmlTag(desc[0]))
|
||||||
|
|
||||||
|
return cv
|
||||||
|
|
||||||
|
|
||||||
|
def json_loads(line):
|
||||||
|
return demjson3.decode(re.sub(r": *(True|False)", r": '\1'", line))
|
||||||
|
|
||||||
|
|
||||||
|
def forWork(cv):
|
||||||
|
if not cv.get("work_obj"):
|
||||||
|
cv["integerity_flt"] *= 0.7
|
||||||
|
return cv
|
||||||
|
|
||||||
|
flds = ["position_name", "corporation_name", "corporation_id", "responsibilities",
|
||||||
|
"industry_name", "subordinates_count"]
|
||||||
|
duas = []
|
||||||
|
scales = []
|
||||||
|
fea = {c: [] for c in flds}
|
||||||
|
latest_job_tm = ""
|
||||||
|
goodcorp = False
|
||||||
|
goodcorp_ = False
|
||||||
|
work_st_tm = ""
|
||||||
|
corp_tags = []
|
||||||
|
for i, n in enumerate(
|
||||||
|
sorted(cv.get("work_obj", []), key=lambda x: str(x.get("start_time", "")) if isinstance(x, dict) else "",
|
||||||
|
reverse=True)):
|
||||||
|
if isinstance(n, str):
|
||||||
|
try:
|
||||||
|
n = json_loads(n)
|
||||||
|
except Exception:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if n.get("start_time") and (not work_st_tm or n["start_time"] < work_st_tm):
|
||||||
|
work_st_tm = n["start_time"]
|
||||||
|
for c in flds:
|
||||||
|
if not n.get(c) or str(n[c]) == '0':
|
||||||
|
fea[c].append("")
|
||||||
|
continue
|
||||||
|
if c == "corporation_name":
|
||||||
|
n[c] = corporations.corpNorm(n[c], False)
|
||||||
|
if corporations.is_good(n[c]):
|
||||||
|
if i == 0:
|
||||||
|
goodcorp = True
|
||||||
|
else:
|
||||||
|
goodcorp_ = True
|
||||||
|
ct = corporations.corp_tag(n[c])
|
||||||
|
if i == 0:
|
||||||
|
corp_tags.extend(ct)
|
||||||
|
elif ct and ct[0] != "软外":
|
||||||
|
corp_tags.extend([f"{t}(曾)" for t in ct])
|
||||||
|
|
||||||
|
fea[c].append(rmHtmlTag(str(n[c]).lower()))
|
||||||
|
|
||||||
|
y, m, d = getYMD(n.get("start_time"))
|
||||||
|
if not y or not m:
|
||||||
|
continue
|
||||||
|
st = "%s-%02d-%02d" % (y, int(m), int(d))
|
||||||
|
latest_job_tm = st
|
||||||
|
|
||||||
|
y, m, d = getYMD(n.get("end_time"))
|
||||||
|
if (not y or not m) and i > 0:
|
||||||
|
continue
|
||||||
|
if not y or not m or int(y) > 2022:
|
||||||
|
y, m, d = getYMD(str(n.get("updated_at", "")))
|
||||||
|
if not y or not m:
|
||||||
|
continue
|
||||||
|
ed = "%s-%02d-%02d" % (y, int(m), int(d))
|
||||||
|
|
||||||
|
try:
|
||||||
|
duas.append((datetime.datetime.strptime(ed, "%Y-%m-%d") - datetime.datetime.strptime(st, "%Y-%m-%d")).days)
|
||||||
|
except Exception:
|
||||||
|
logging.exception("forWork {} {}".format(n.get("start_time"), n.get("end_time")))
|
||||||
|
|
||||||
|
if n.get("scale"):
|
||||||
|
r = re.search(r"^([0-9]+)", str(n["scale"]))
|
||||||
|
if r:
|
||||||
|
scales.append(int(r.group(1)))
|
||||||
|
|
||||||
|
if goodcorp:
|
||||||
|
if "tag_kwd" not in cv:
|
||||||
|
cv["tag_kwd"] = []
|
||||||
|
cv["tag_kwd"].append("好公司")
|
||||||
|
if goodcorp_:
|
||||||
|
if "tag_kwd" not in cv:
|
||||||
|
cv["tag_kwd"] = []
|
||||||
|
cv["tag_kwd"].append("好公司(曾)")
|
||||||
|
|
||||||
|
if corp_tags:
|
||||||
|
if "tag_kwd" not in cv:
|
||||||
|
cv["tag_kwd"] = []
|
||||||
|
cv["tag_kwd"].extend(corp_tags)
|
||||||
|
cv["corp_tag_kwd"] = [c for c in corp_tags if re.match(r"(综合|行业)", c)]
|
||||||
|
|
||||||
|
if latest_job_tm:
|
||||||
|
cv["latest_job_dt"] = latest_job_tm
|
||||||
|
if fea["corporation_id"]:
|
||||||
|
cv["corporation_id"] = fea["corporation_id"]
|
||||||
|
|
||||||
|
if fea["position_name"]:
|
||||||
|
cv["position_name_tks"] = rag_tokenizer.tokenize(fea["position_name"][0])
|
||||||
|
cv["position_name_sm_tks"] = rag_tokenizer.fine_grained_tokenize(cv["position_name_tks"])
|
||||||
|
cv["pos_nm_tks"] = rag_tokenizer.tokenize(" ".join(fea["position_name"][1:]))
|
||||||
|
|
||||||
|
if fea["industry_name"]:
|
||||||
|
cv["industry_name_tks"] = rag_tokenizer.tokenize(fea["industry_name"][0])
|
||||||
|
cv["industry_name_sm_tks"] = rag_tokenizer.fine_grained_tokenize(cv["industry_name_tks"])
|
||||||
|
cv["indu_nm_tks"] = rag_tokenizer.tokenize(" ".join(fea["industry_name"][1:]))
|
||||||
|
|
||||||
|
if fea["corporation_name"]:
|
||||||
|
cv["corporation_name_kwd"] = fea["corporation_name"][0]
|
||||||
|
cv["corp_nm_kwd"] = fea["corporation_name"]
|
||||||
|
cv["corporation_name_tks"] = rag_tokenizer.tokenize(fea["corporation_name"][0])
|
||||||
|
cv["corporation_name_sm_tks"] = rag_tokenizer.fine_grained_tokenize(cv["corporation_name_tks"])
|
||||||
|
cv["corp_nm_tks"] = rag_tokenizer.tokenize(" ".join(fea["corporation_name"][1:]))
|
||||||
|
|
||||||
|
if fea["responsibilities"]:
|
||||||
|
cv["responsibilities_ltks"] = rag_tokenizer.tokenize(fea["responsibilities"][0])
|
||||||
|
cv["resp_ltks"] = rag_tokenizer.tokenize(" ".join(fea["responsibilities"][1:]))
|
||||||
|
|
||||||
|
if fea["subordinates_count"]:
|
||||||
|
fea["subordinates_count"] = [int(i) for i in fea["subordinates_count"] if
|
||||||
|
re.match(r"[^0-9]+$", str(i))]
|
||||||
|
if fea["subordinates_count"]:
|
||||||
|
cv["max_sub_cnt_int"] = np.max(fea["subordinates_count"])
|
||||||
|
|
||||||
|
if isinstance(cv.get("corporation_id"), int):
|
||||||
|
cv["corporation_id"] = [str(cv["corporation_id"])]
|
||||||
|
if not cv.get("corporation_id"):
|
||||||
|
cv["corporation_id"] = []
|
||||||
|
for i in cv.get("corporation_id", []):
|
||||||
|
cv["baike_flt"] = max(corporations.baike(i), cv["baike_flt"] if "baike_flt" in cv else 0)
|
||||||
|
|
||||||
|
if work_st_tm:
|
||||||
|
try:
|
||||||
|
if re.match(r"[0-9]{9,}", work_st_tm):
|
||||||
|
work_st_tm = turnTm2Dt(work_st_tm)
|
||||||
|
y, m, d = getYMD(work_st_tm)
|
||||||
|
cv["work_exp_flt"] = min(int(str(datetime.date.today())[0:4]) - int(y), cv.get("work_exp_flt", 1000))
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception("forWork {} {} {}".format(e, work_st_tm, cv.get("work_exp_flt")))
|
||||||
|
|
||||||
|
cv["job_num_int"] = 0
|
||||||
|
if duas:
|
||||||
|
cv["dua_flt"] = np.mean(duas)
|
||||||
|
cv["cur_dua_int"] = duas[0]
|
||||||
|
cv["job_num_int"] = len(duas)
|
||||||
|
if scales:
|
||||||
|
cv["scale_flt"] = np.max(scales)
|
||||||
|
return cv
|
||||||
|
|
||||||
|
|
||||||
|
def turnTm2Dt(b):
|
||||||
|
if not b:
|
||||||
|
return
|
||||||
|
b = str(b).strip()
|
||||||
|
if re.match(r"[0-9]{10,}", b):
|
||||||
|
b = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(b[:10])))
|
||||||
|
return b
|
||||||
|
|
||||||
|
|
||||||
|
def getYMD(b):
|
||||||
|
y, m, d = "", "", "01"
|
||||||
|
if not b:
|
||||||
|
return (y, m, d)
|
||||||
|
b = turnTm2Dt(b)
|
||||||
|
if re.match(r"[0-9]{4}", b):
|
||||||
|
y = int(b[:4])
|
||||||
|
r = re.search(r"[0-9]{4}.?([0-9]{1,2})", b)
|
||||||
|
if r:
|
||||||
|
m = r.group(1)
|
||||||
|
r = re.search(r"[0-9]{4}.?[0-9]{,2}.?([0-9]{1,2})", b)
|
||||||
|
if r:
|
||||||
|
d = r.group(1)
|
||||||
|
if not d or int(d) == 0 or int(d) > 31:
|
||||||
|
d = "1"
|
||||||
|
if not m or int(m) > 12 or int(m) < 1:
|
||||||
|
m = "1"
|
||||||
|
return (y, m, d)
|
||||||
|
|
||||||
|
|
||||||
|
def birth(cv):
|
||||||
|
if not cv.get("birth"):
|
||||||
|
cv["integerity_flt"] *= 0.9
|
||||||
|
return cv
|
||||||
|
y, m, d = getYMD(cv["birth"])
|
||||||
|
if not m or not y:
|
||||||
|
return cv
|
||||||
|
b = "%s-%02d-%02d" % (y, int(m), int(d))
|
||||||
|
cv["birth_dt"] = b
|
||||||
|
cv["birthday_kwd"] = "%02d%02d" % (int(m), int(d))
|
||||||
|
|
||||||
|
cv["age_int"] = datetime.datetime.now().year - int(y)
|
||||||
|
return cv
|
||||||
|
|
||||||
|
|
||||||
|
def parse(cv):
|
||||||
|
for k in cv.keys():
|
||||||
|
if cv[k] == '\\N':
|
||||||
|
cv[k] = ''
|
||||||
|
# cv = cv.asDict()
|
||||||
|
tks_fld = ["address", "corporation_name", "discipline_name", "email", "expect_city_names",
|
||||||
|
"expect_industry_name", "expect_position_name", "industry_name", "industry_names", "name",
|
||||||
|
"position_name", "school_name", "self_remark", "title_name"]
|
||||||
|
small_tks_fld = ["corporation_name", "expect_position_name", "position_name", "school_name", "title_name"]
|
||||||
|
kwd_fld = ["address", "city", "corporation_type", "degree", "discipline_name", "expect_city_names", "email",
|
||||||
|
"expect_industry_name", "expect_position_name", "expect_type", "gender", "industry_name",
|
||||||
|
"industry_names", "political_status", "position_name", "scale", "school_name", "phone", "tel"]
|
||||||
|
num_fld = ["annual_salary", "annual_salary_from", "annual_salary_to", "expect_annual_salary", "expect_salary_from",
|
||||||
|
"expect_salary_to", "salary_month"]
|
||||||
|
|
||||||
|
is_fld = [
|
||||||
|
("is_fertility", "已育", "未育"),
|
||||||
|
("is_house", "有房", "没房"),
|
||||||
|
("is_management_experience", "有管理经验", "无管理经验"),
|
||||||
|
("is_marital", "已婚", "未婚"),
|
||||||
|
("is_oversea", "有海外经验", "无海外经验")
|
||||||
|
]
|
||||||
|
|
||||||
|
rmkeys = []
|
||||||
|
for k in cv.keys():
|
||||||
|
if cv[k] is None:
|
||||||
|
rmkeys.append(k)
|
||||||
|
if (isinstance(cv[k], list) or isinstance(cv[k], str)) and len(cv[k]) == 0:
|
||||||
|
rmkeys.append(k)
|
||||||
|
for k in rmkeys:
|
||||||
|
del cv[k]
|
||||||
|
|
||||||
|
integerity = 0.
|
||||||
|
flds_num = 0.
|
||||||
|
|
||||||
|
def hasValues(flds):
|
||||||
|
nonlocal integerity, flds_num
|
||||||
|
flds_num += len(flds)
|
||||||
|
for f in flds:
|
||||||
|
v = str(cv.get(f, ""))
|
||||||
|
if len(v) > 0 and v != '0' and v != '[]':
|
||||||
|
integerity += 1
|
||||||
|
|
||||||
|
hasValues(tks_fld)
|
||||||
|
hasValues(small_tks_fld)
|
||||||
|
hasValues(kwd_fld)
|
||||||
|
hasValues(num_fld)
|
||||||
|
cv["integerity_flt"] = integerity / flds_num
|
||||||
|
|
||||||
|
if cv.get("corporation_type"):
|
||||||
|
for p, r in [(r"(公司|企业|其它|其他|Others*|\n|未填写|Enterprises|Company|companies)", ""),
|
||||||
|
(r"[//.· <\((]+.*", ""),
|
||||||
|
(r".*(合资|民企|股份制|中外|私营|个体|Private|创业|Owned|投资).*", "民营"),
|
||||||
|
(r".*(机关|事业).*", "机关"),
|
||||||
|
(r".*(非盈利|Non-profit).*", "非盈利"),
|
||||||
|
(r".*(外企|外商|欧美|foreign|Institution|Australia|港资).*", "外企"),
|
||||||
|
(r".*国有.*", "国企"),
|
||||||
|
(r"[ ()\(\)人/·0-9-]+", ""),
|
||||||
|
(r".*(元|规模|于|=|北京|上海|至今|中国|工资|州|shanghai|强|餐饮|融资|职).*", "")]:
|
||||||
|
cv["corporation_type"] = re.sub(p, r, cv["corporation_type"], count=1000, flags=re.IGNORECASE)
|
||||||
|
if len(cv["corporation_type"]) < 2:
|
||||||
|
del cv["corporation_type"]
|
||||||
|
|
||||||
|
if cv.get("political_status"):
|
||||||
|
for p, r in [
|
||||||
|
(r".*党员.*", "党员"),
|
||||||
|
(r".*(无党派|公民).*", "群众"),
|
||||||
|
(r".*团员.*", "团员")]:
|
||||||
|
cv["political_status"] = re.sub(p, r, cv["political_status"])
|
||||||
|
if not re.search(r"[党团群]", cv["political_status"]):
|
||||||
|
del cv["political_status"]
|
||||||
|
|
||||||
|
if cv.get("phone"):
|
||||||
|
cv["phone"] = re.sub(r"^0*86([0-9]{11})", r"\1", re.sub(r"[^0-9]+", "", cv["phone"]))
|
||||||
|
|
||||||
|
keys = list(cv.keys())
|
||||||
|
for k in keys:
|
||||||
|
# deal with json objects
|
||||||
|
if k.find("_obj") > 0:
|
||||||
|
try:
|
||||||
|
cv[k] = json_loads(cv[k])
|
||||||
|
cv[k] = [a for _, a in cv[k].items()]
|
||||||
|
nms = []
|
||||||
|
for n in cv[k]:
|
||||||
|
if not isinstance(n, dict) or "name" not in n or not n.get("name"):
|
||||||
|
continue
|
||||||
|
n["name"] = re.sub(r"((442)|\t )", "", n["name"]).strip().lower()
|
||||||
|
if not n["name"]:
|
||||||
|
continue
|
||||||
|
nms.append(n["name"])
|
||||||
|
if nms:
|
||||||
|
t = k[:-4]
|
||||||
|
cv[f"{t}_kwd"] = nms
|
||||||
|
cv[f"{t}_tks"] = rag_tokenizer.tokenize(" ".join(nms))
|
||||||
|
except Exception:
|
||||||
|
logging.exception("parse {} {}".format(str(traceback.format_exc()), cv[k]))
|
||||||
|
cv[k] = []
|
||||||
|
|
||||||
|
# tokenize fields
|
||||||
|
if k in tks_fld:
|
||||||
|
cv[f"{k}_tks"] = rag_tokenizer.tokenize(cv[k])
|
||||||
|
if k in small_tks_fld:
|
||||||
|
cv[f"{k}_sm_tks"] = rag_tokenizer.tokenize(cv[f"{k}_tks"])
|
||||||
|
|
||||||
|
# keyword fields
|
||||||
|
if k in kwd_fld:
|
||||||
|
cv[f"{k}_kwd"] = [n.lower()
|
||||||
|
for n in re.split(r"[\t,,;;. ]",
|
||||||
|
re.sub(r"([^a-zA-Z])[ ]+([^a-zA-Z ])", r"\1,\2", cv[k])
|
||||||
|
) if n]
|
||||||
|
|
||||||
|
if k in num_fld and cv.get(k):
|
||||||
|
cv[f"{k}_int"] = cv[k]
|
||||||
|
|
||||||
|
cv["email_kwd"] = cv.get("email_tks", "").replace(" ", "")
|
||||||
|
# for name field
|
||||||
|
if cv.get("name"):
|
||||||
|
nm = re.sub(r"[\n——\-\((\+].*", "", cv["name"].strip())
|
||||||
|
nm = re.sub(r"[ \t ]+", " ", nm)
|
||||||
|
if re.match(r"[a-zA-Z ]+$", nm):
|
||||||
|
if len(nm.split()) > 1:
|
||||||
|
cv["name"] = nm
|
||||||
|
else:
|
||||||
|
nm = ""
|
||||||
|
elif nm and (surname.isit(nm[0]) or surname.isit(nm[:2])):
|
||||||
|
nm = re.sub(r"[a-zA-Z]+.*", "", nm[:5])
|
||||||
|
else:
|
||||||
|
nm = ""
|
||||||
|
cv["name"] = nm.strip()
|
||||||
|
name = cv["name"]
|
||||||
|
|
||||||
|
# name pingyin and its prefix
|
||||||
|
cv["name_py_tks"] = " ".join(PY.get_pinyins(nm[:20], '')) + " " + " ".join(PY.get_pinyins(nm[:20], ' '))
|
||||||
|
cv["name_py_pref0_tks"] = ""
|
||||||
|
cv["name_py_pref_tks"] = ""
|
||||||
|
for py in PY.get_pinyins(nm[:20], ''):
|
||||||
|
for i in range(2, len(py) + 1):
|
||||||
|
cv["name_py_pref_tks"] += " " + py[:i]
|
||||||
|
for py in PY.get_pinyins(nm[:20], ' '):
|
||||||
|
py = py.split()
|
||||||
|
for i in range(1, len(py) + 1):
|
||||||
|
cv["name_py_pref0_tks"] += " " + "".join(py[:i])
|
||||||
|
|
||||||
|
cv["name_kwd"] = name
|
||||||
|
cv["name_pinyin_kwd"] = PY.get_pinyins(nm[:20], ' ')[:3]
|
||||||
|
cv["name_tks"] = (
|
||||||
|
rag_tokenizer.tokenize(name) + " " + (" ".join(list(name)) if not re.match(r"[a-zA-Z ]+$", name) else "")
|
||||||
|
) if name else ""
|
||||||
|
else:
|
||||||
|
cv["integerity_flt"] /= 2.
|
||||||
|
|
||||||
|
if cv.get("phone"):
|
||||||
|
r = re.search(r"(1[3456789][0-9]{9})", cv["phone"])
|
||||||
|
if not r:
|
||||||
|
cv["phone"] = ""
|
||||||
|
else:
|
||||||
|
cv["phone"] = r.group(1)
|
||||||
|
|
||||||
|
# deal with date fields
|
||||||
|
if cv.get("updated_at") and isinstance(cv["updated_at"], datetime.datetime):
|
||||||
|
cv["updated_at_dt"] = cv["updated_at"].strftime('%Y-%m-%d %H:%M:%S')
|
||||||
|
else:
|
||||||
|
y, m, d = getYMD(str(cv.get("updated_at", "")))
|
||||||
|
if not y:
|
||||||
|
y = "2012"
|
||||||
|
if not m:
|
||||||
|
m = "01"
|
||||||
|
if not d:
|
||||||
|
d = "01"
|
||||||
|
cv["updated_at_dt"] = "%s-%02d-%02d 00:00:00" % (y, int(m), int(d))
|
||||||
|
# long text tokenize
|
||||||
|
|
||||||
|
if cv.get("responsibilities"):
|
||||||
|
cv["responsibilities_ltks"] = rag_tokenizer.tokenize(rmHtmlTag(cv["responsibilities"]))
|
||||||
|
|
||||||
|
# for yes or no field
|
||||||
|
fea = []
|
||||||
|
for f, y, n in is_fld:
|
||||||
|
if f not in cv:
|
||||||
|
continue
|
||||||
|
if cv[f] == '是':
|
||||||
|
fea.append(y)
|
||||||
|
if cv[f] == '否':
|
||||||
|
fea.append(n)
|
||||||
|
|
||||||
|
if fea:
|
||||||
|
cv["tag_kwd"] = fea
|
||||||
|
|
||||||
|
cv = forEdu(cv)
|
||||||
|
cv = forProj(cv)
|
||||||
|
cv = forWork(cv)
|
||||||
|
cv = birth(cv)
|
||||||
|
|
||||||
|
cv["corp_proj_sch_deg_kwd"] = [c for c in cv.get("corp_tag_kwd", [])]
|
||||||
|
for i in range(len(cv["corp_proj_sch_deg_kwd"])):
|
||||||
|
for j in cv.get("sch_rank_kwd", []):
|
||||||
|
cv["corp_proj_sch_deg_kwd"][i] += "+" + j
|
||||||
|
for i in range(len(cv["corp_proj_sch_deg_kwd"])):
|
||||||
|
if cv.get("highest_degree_kwd"):
|
||||||
|
cv["corp_proj_sch_deg_kwd"][i] += "+" + cv["highest_degree_kwd"]
|
||||||
|
|
||||||
|
try:
|
||||||
|
if not cv.get("work_exp_flt") and cv.get("work_start_time"):
|
||||||
|
if re.match(r"[0-9]{9,}", str(cv["work_start_time"])):
|
||||||
|
cv["work_start_dt"] = turnTm2Dt(cv["work_start_time"])
|
||||||
|
cv["work_exp_flt"] = (time.time() - int(int(cv["work_start_time"]) / 1000)) / 3600. / 24. / 365.
|
||||||
|
elif re.match(r"[0-9]{4}[^0-9]", str(cv["work_start_time"])):
|
||||||
|
y, m, d = getYMD(str(cv["work_start_time"]))
|
||||||
|
cv["work_start_dt"] = "%s-%02d-%02d 00:00:00" % (y, int(m), int(d))
|
||||||
|
cv["work_exp_flt"] = int(str(datetime.date.today())[0:4]) - int(y)
|
||||||
|
except Exception as e:
|
||||||
|
logging.exception("parse {} ==> {}".format(e, cv.get("work_start_time")))
|
||||||
|
if "work_exp_flt" not in cv and cv.get("work_experience", 0):
|
||||||
|
cv["work_exp_flt"] = int(cv["work_experience"]) / 12.
|
||||||
|
|
||||||
|
keys = list(cv.keys())
|
||||||
|
for k in keys:
|
||||||
|
if not re.search(r"_(fea|tks|nst|dt|int|flt|ltks|kwd|id)$", k):
|
||||||
|
del cv[k]
|
||||||
|
for k in cv.keys():
|
||||||
|
if not re.search("_(kwd|id)$", k) or not isinstance(cv[k], list):
|
||||||
|
continue
|
||||||
|
cv[k] = list(set([re.sub("(市)$", "", str(n)) for n in cv[k] if n not in ['中国', '0']]))
|
||||||
|
keys = [k for k in cv.keys() if re.search(r"_feas*$", k)]
|
||||||
|
for k in keys:
|
||||||
|
if cv[k] <= 0:
|
||||||
|
del cv[k]
|
||||||
|
|
||||||
|
cv["tob_resume_id"] = str(cv["tob_resume_id"])
|
||||||
|
cv["id"] = cv["tob_resume_id"]
|
||||||
|
logging.debug("CCCCCCCCCCCCCCC")
|
||||||
|
|
||||||
|
return dealWithInt64(cv)
|
||||||
|
|
||||||
|
|
||||||
|
def dealWithInt64(d):
|
||||||
|
if isinstance(d, dict):
|
||||||
|
for n, v in d.items():
|
||||||
|
d[n] = dealWithInt64(v)
|
||||||
|
|
||||||
|
if isinstance(d, list):
|
||||||
|
d = [dealWithInt64(t) for t in d]
|
||||||
|
|
||||||
|
if isinstance(d, np.integer):
|
||||||
|
d = int(d)
|
||||||
|
return d
|
||||||
64
deepdoc/parser/txt_parser.py
Normal file
64
deepdoc/parser/txt_parser.py
Normal file
@@ -0,0 +1,64 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import re
|
||||||
|
|
||||||
|
from deepdoc.parser.utils import get_text
|
||||||
|
from rag.nlp import num_tokens_from_string
|
||||||
|
|
||||||
|
|
||||||
|
class RAGFlowTxtParser:
|
||||||
|
def __call__(self, fnm, binary=None, chunk_token_num=128, delimiter="\n!?;。;!?"):
|
||||||
|
txt = get_text(fnm, binary)
|
||||||
|
return self.parser_txt(txt, chunk_token_num, delimiter)
|
||||||
|
|
||||||
|
@classmethod
|
||||||
|
def parser_txt(cls, txt, chunk_token_num=128, delimiter="\n!?;。;!?"):
|
||||||
|
if not isinstance(txt, str):
|
||||||
|
raise TypeError("txt type should be str!")
|
||||||
|
cks = [""]
|
||||||
|
tk_nums = [0]
|
||||||
|
delimiter = delimiter.encode('utf-8').decode('unicode_escape').encode('latin1').decode('utf-8')
|
||||||
|
|
||||||
|
def add_chunk(t):
|
||||||
|
nonlocal cks, tk_nums, delimiter
|
||||||
|
tnum = num_tokens_from_string(t)
|
||||||
|
if tk_nums[-1] > chunk_token_num:
|
||||||
|
cks.append(t)
|
||||||
|
tk_nums.append(tnum)
|
||||||
|
else:
|
||||||
|
cks[-1] += t
|
||||||
|
tk_nums[-1] += tnum
|
||||||
|
|
||||||
|
dels = []
|
||||||
|
s = 0
|
||||||
|
for m in re.finditer(r"`([^`]+)`", delimiter, re.I):
|
||||||
|
f, t = m.span()
|
||||||
|
dels.append(m.group(1))
|
||||||
|
dels.extend(list(delimiter[s: f]))
|
||||||
|
s = t
|
||||||
|
if s < len(delimiter):
|
||||||
|
dels.extend(list(delimiter[s:]))
|
||||||
|
dels = [re.escape(d) for d in dels if d]
|
||||||
|
dels = [d for d in dels if d]
|
||||||
|
dels = "|".join(dels)
|
||||||
|
secs = re.split(r"(%s)" % dels, txt)
|
||||||
|
for sec in secs:
|
||||||
|
if re.match(f"^{dels}$", sec):
|
||||||
|
continue
|
||||||
|
add_chunk(sec)
|
||||||
|
|
||||||
|
return [[c, ""] for c in cks]
|
||||||
32
deepdoc/parser/utils.py
Normal file
32
deepdoc/parser/utils.py
Normal file
@@ -0,0 +1,32 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
from rag.nlp import find_codec
|
||||||
|
|
||||||
|
|
||||||
|
def get_text(fnm: str, binary=None) -> str:
|
||||||
|
txt = ""
|
||||||
|
if binary:
|
||||||
|
encoding = find_codec(binary)
|
||||||
|
txt = binary.decode(encoding, errors="ignore")
|
||||||
|
else:
|
||||||
|
with open(fnm, "r") as f:
|
||||||
|
while True:
|
||||||
|
line = f.readline()
|
||||||
|
if not line:
|
||||||
|
break
|
||||||
|
txt += line
|
||||||
|
return txt
|
||||||
90
deepdoc/vision/__init__.py
Normal file
90
deepdoc/vision/__init__.py
Normal file
@@ -0,0 +1,90 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
import io
|
||||||
|
import sys
|
||||||
|
import threading
|
||||||
|
|
||||||
|
import pdfplumber
|
||||||
|
|
||||||
|
from .ocr import OCR
|
||||||
|
from .recognizer import Recognizer
|
||||||
|
from .layout_recognizer import AscendLayoutRecognizer
|
||||||
|
from .layout_recognizer import LayoutRecognizer4YOLOv10 as LayoutRecognizer
|
||||||
|
from .table_structure_recognizer import TableStructureRecognizer
|
||||||
|
|
||||||
|
LOCK_KEY_pdfplumber = "global_shared_lock_pdfplumber"
|
||||||
|
if LOCK_KEY_pdfplumber not in sys.modules:
|
||||||
|
sys.modules[LOCK_KEY_pdfplumber] = threading.Lock()
|
||||||
|
|
||||||
|
|
||||||
|
def init_in_out(args):
|
||||||
|
import os
|
||||||
|
import traceback
|
||||||
|
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
from api.utils.file_utils import traversal_files
|
||||||
|
|
||||||
|
images = []
|
||||||
|
outputs = []
|
||||||
|
|
||||||
|
if not os.path.exists(args.output_dir):
|
||||||
|
os.mkdir(args.output_dir)
|
||||||
|
|
||||||
|
def pdf_pages(fnm, zoomin=3):
|
||||||
|
nonlocal outputs, images
|
||||||
|
with sys.modules[LOCK_KEY_pdfplumber]:
|
||||||
|
pdf = pdfplumber.open(fnm)
|
||||||
|
images = [p.to_image(resolution=72 * zoomin).annotated for i, p in enumerate(pdf.pages)]
|
||||||
|
|
||||||
|
for i, page in enumerate(images):
|
||||||
|
outputs.append(os.path.split(fnm)[-1] + f"_{i}.jpg")
|
||||||
|
pdf.close()
|
||||||
|
|
||||||
|
def images_and_outputs(fnm):
|
||||||
|
nonlocal outputs, images
|
||||||
|
if fnm.split(".")[-1].lower() == "pdf":
|
||||||
|
pdf_pages(fnm)
|
||||||
|
return
|
||||||
|
try:
|
||||||
|
fp = open(fnm, "rb")
|
||||||
|
binary = fp.read()
|
||||||
|
fp.close()
|
||||||
|
images.append(Image.open(io.BytesIO(binary)).convert("RGB"))
|
||||||
|
outputs.append(os.path.split(fnm)[-1])
|
||||||
|
except Exception:
|
||||||
|
traceback.print_exc()
|
||||||
|
|
||||||
|
if os.path.isdir(args.inputs):
|
||||||
|
for fnm in traversal_files(args.inputs):
|
||||||
|
images_and_outputs(fnm)
|
||||||
|
else:
|
||||||
|
images_and_outputs(args.inputs)
|
||||||
|
|
||||||
|
for i in range(len(outputs)):
|
||||||
|
outputs[i] = os.path.join(args.output_dir, outputs[i])
|
||||||
|
|
||||||
|
return images, outputs
|
||||||
|
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"OCR",
|
||||||
|
"Recognizer",
|
||||||
|
"LayoutRecognizer",
|
||||||
|
"AscendLayoutRecognizer",
|
||||||
|
"TableStructureRecognizer",
|
||||||
|
"init_in_out",
|
||||||
|
]
|
||||||
456
deepdoc/vision/layout_recognizer.py
Normal file
456
deepdoc/vision/layout_recognizer.py
Normal file
@@ -0,0 +1,456 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import math
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
from collections import Counter
|
||||||
|
from copy import deepcopy
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
from huggingface_hub import snapshot_download
|
||||||
|
|
||||||
|
from api.utils.file_utils import get_project_base_directory
|
||||||
|
from deepdoc.vision import Recognizer
|
||||||
|
from deepdoc.vision.operators import nms
|
||||||
|
|
||||||
|
|
||||||
|
class LayoutRecognizer(Recognizer):
|
||||||
|
labels = [
|
||||||
|
"_background_",
|
||||||
|
"Text",
|
||||||
|
"Title",
|
||||||
|
"Figure",
|
||||||
|
"Figure caption",
|
||||||
|
"Table",
|
||||||
|
"Table caption",
|
||||||
|
"Header",
|
||||||
|
"Footer",
|
||||||
|
"Reference",
|
||||||
|
"Equation",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self, domain):
|
||||||
|
try:
|
||||||
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
|
super().__init__(self.labels, domain, model_dir)
|
||||||
|
except Exception:
|
||||||
|
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc", local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"), local_dir_use_symlinks=False)
|
||||||
|
super().__init__(self.labels, domain, model_dir)
|
||||||
|
|
||||||
|
self.garbage_layouts = ["footer", "header", "reference"]
|
||||||
|
self.client = None
|
||||||
|
if os.environ.get("TENSORRT_DLA_SVR"):
|
||||||
|
from deepdoc.vision.dla_cli import DLAClient
|
||||||
|
|
||||||
|
self.client = DLAClient(os.environ["TENSORRT_DLA_SVR"])
|
||||||
|
|
||||||
|
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||||
|
def __is_garbage(b):
|
||||||
|
patt = [r"^•+$", "^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", "^http://[^ ]{12,}", "\\(cid *: *[0-9]+ *\\)"]
|
||||||
|
return any([re.search(p, b["text"]) for p in patt])
|
||||||
|
|
||||||
|
if self.client:
|
||||||
|
layouts = self.client.predict(image_list)
|
||||||
|
else:
|
||||||
|
layouts = super().__call__(image_list, thr, batch_size)
|
||||||
|
# save_results(image_list, layouts, self.labels, output_dir='output/', threshold=0.7)
|
||||||
|
assert len(image_list) == len(ocr_res)
|
||||||
|
# Tag layout type
|
||||||
|
boxes = []
|
||||||
|
assert len(image_list) == len(layouts)
|
||||||
|
garbages = {}
|
||||||
|
page_layout = []
|
||||||
|
for pn, lts in enumerate(layouts):
|
||||||
|
bxs = ocr_res[pn]
|
||||||
|
lts = [
|
||||||
|
{
|
||||||
|
"type": b["type"],
|
||||||
|
"score": float(b["score"]),
|
||||||
|
"x0": b["bbox"][0] / scale_factor,
|
||||||
|
"x1": b["bbox"][2] / scale_factor,
|
||||||
|
"top": b["bbox"][1] / scale_factor,
|
||||||
|
"bottom": b["bbox"][-1] / scale_factor,
|
||||||
|
"page_number": pn,
|
||||||
|
}
|
||||||
|
for b in lts
|
||||||
|
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts
|
||||||
|
]
|
||||||
|
lts = self.sort_Y_firstly(lts, np.mean([lt["bottom"] - lt["top"] for lt in lts]) / 2)
|
||||||
|
lts = self.layouts_cleanup(bxs, lts)
|
||||||
|
page_layout.append(lts)
|
||||||
|
|
||||||
|
def findLayout(ty):
|
||||||
|
nonlocal bxs, lts, self
|
||||||
|
lts_ = [lt for lt in lts if lt["type"] == ty]
|
||||||
|
i = 0
|
||||||
|
while i < len(bxs):
|
||||||
|
if bxs[i].get("layout_type"):
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
if __is_garbage(bxs[i]):
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
ii = self.find_overlapped_with_threshold(bxs[i], lts_, thr=0.4)
|
||||||
|
if ii is None:
|
||||||
|
bxs[i]["layout_type"] = ""
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
lts_[ii]["visited"] = True
|
||||||
|
keep_feats = [
|
||||||
|
lts_[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].size[1] * 0.9 / scale_factor,
|
||||||
|
lts_[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].size[1] * 0.1 / scale_factor,
|
||||||
|
]
|
||||||
|
if drop and lts_[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||||
|
if lts_[ii]["type"] not in garbages:
|
||||||
|
garbages[lts_[ii]["type"]] = []
|
||||||
|
garbages[lts_[ii]["type"]].append(bxs[i]["text"])
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||||
|
bxs[i]["layout_type"] = lts_[ii]["type"] if lts_[ii]["type"] != "equation" else "figure"
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
for lt in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||||
|
findLayout(lt)
|
||||||
|
|
||||||
|
# add box to figure layouts which has not text box
|
||||||
|
for i, lt in enumerate([lt for lt in lts if lt["type"] in ["figure", "equation"]]):
|
||||||
|
if lt.get("visited"):
|
||||||
|
continue
|
||||||
|
lt = deepcopy(lt)
|
||||||
|
del lt["type"]
|
||||||
|
lt["text"] = ""
|
||||||
|
lt["layout_type"] = "figure"
|
||||||
|
lt["layoutno"] = f"figure-{i}"
|
||||||
|
bxs.append(lt)
|
||||||
|
|
||||||
|
boxes.extend(bxs)
|
||||||
|
|
||||||
|
ocr_res = boxes
|
||||||
|
|
||||||
|
garbag_set = set()
|
||||||
|
for k in garbages.keys():
|
||||||
|
garbages[k] = Counter(garbages[k])
|
||||||
|
for g, c in garbages[k].items():
|
||||||
|
if c > 1:
|
||||||
|
garbag_set.add(g)
|
||||||
|
|
||||||
|
ocr_res = [b for b in ocr_res if b["text"].strip() not in garbag_set]
|
||||||
|
return ocr_res, page_layout
|
||||||
|
|
||||||
|
def forward(self, image_list, thr=0.7, batch_size=16):
|
||||||
|
return super().__call__(image_list, thr, batch_size)
|
||||||
|
|
||||||
|
|
||||||
|
class LayoutRecognizer4YOLOv10(LayoutRecognizer):
|
||||||
|
labels = [
|
||||||
|
"title",
|
||||||
|
"Text",
|
||||||
|
"Reference",
|
||||||
|
"Figure",
|
||||||
|
"Figure caption",
|
||||||
|
"Table",
|
||||||
|
"Table caption",
|
||||||
|
"Table caption",
|
||||||
|
"Equation",
|
||||||
|
"Figure caption",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self, domain):
|
||||||
|
domain = "layout"
|
||||||
|
super().__init__(domain)
|
||||||
|
self.auto = False
|
||||||
|
self.scaleFill = False
|
||||||
|
self.scaleup = True
|
||||||
|
self.stride = 32
|
||||||
|
self.center = True
|
||||||
|
|
||||||
|
def preprocess(self, image_list):
|
||||||
|
inputs = []
|
||||||
|
new_shape = self.input_shape # height, width
|
||||||
|
for img in image_list:
|
||||||
|
shape = img.shape[:2] # current shape [height, width]
|
||||||
|
# Scale ratio (new / old)
|
||||||
|
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
|
||||||
|
# Compute padding
|
||||||
|
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
|
||||||
|
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
|
||||||
|
dw /= 2 # divide padding into 2 sides
|
||||||
|
dh /= 2
|
||||||
|
ww, hh = new_unpad
|
||||||
|
img = np.array(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)).astype(np.float32)
|
||||||
|
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||||
|
top, bottom = int(round(dh - 0.1)) if self.center else 0, int(round(dh + 0.1))
|
||||||
|
left, right = int(round(dw - 0.1)) if self.center else 0, int(round(dw + 0.1))
|
||||||
|
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # add border
|
||||||
|
img /= 255.0
|
||||||
|
img = img.transpose(2, 0, 1)
|
||||||
|
img = img[np.newaxis, :, :, :].astype(np.float32)
|
||||||
|
inputs.append({self.input_names[0]: img, "scale_factor": [shape[1] / ww, shape[0] / hh, dw, dh]})
|
||||||
|
|
||||||
|
return inputs
|
||||||
|
|
||||||
|
def postprocess(self, boxes, inputs, thr):
|
||||||
|
thr = 0.08
|
||||||
|
boxes = np.squeeze(boxes)
|
||||||
|
scores = boxes[:, 4]
|
||||||
|
boxes = boxes[scores > thr, :]
|
||||||
|
scores = scores[scores > thr]
|
||||||
|
if len(boxes) == 0:
|
||||||
|
return []
|
||||||
|
class_ids = boxes[:, -1].astype(int)
|
||||||
|
boxes = boxes[:, :4]
|
||||||
|
boxes[:, 0] -= inputs["scale_factor"][2]
|
||||||
|
boxes[:, 2] -= inputs["scale_factor"][2]
|
||||||
|
boxes[:, 1] -= inputs["scale_factor"][3]
|
||||||
|
boxes[:, 3] -= inputs["scale_factor"][3]
|
||||||
|
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0], inputs["scale_factor"][1]])
|
||||||
|
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
||||||
|
|
||||||
|
unique_class_ids = np.unique(class_ids)
|
||||||
|
indices = []
|
||||||
|
for class_id in unique_class_ids:
|
||||||
|
class_indices = np.where(class_ids == class_id)[0]
|
||||||
|
class_boxes = boxes[class_indices, :]
|
||||||
|
class_scores = scores[class_indices]
|
||||||
|
class_keep_boxes = nms(class_boxes, class_scores, 0.45)
|
||||||
|
indices.extend(class_indices[class_keep_boxes])
|
||||||
|
|
||||||
|
return [{"type": self.label_list[class_ids[i]].lower(), "bbox": [float(t) for t in boxes[i].tolist()], "score": float(scores[i])} for i in indices]
|
||||||
|
|
||||||
|
|
||||||
|
class AscendLayoutRecognizer(Recognizer):
|
||||||
|
labels = [
|
||||||
|
"title",
|
||||||
|
"Text",
|
||||||
|
"Reference",
|
||||||
|
"Figure",
|
||||||
|
"Figure caption",
|
||||||
|
"Table",
|
||||||
|
"Table caption",
|
||||||
|
"Table caption",
|
||||||
|
"Equation",
|
||||||
|
"Figure caption",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self, domain):
|
||||||
|
from ais_bench.infer.interface import InferSession
|
||||||
|
|
||||||
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
|
model_file_path = os.path.join(model_dir, domain + ".om")
|
||||||
|
|
||||||
|
if not os.path.exists(model_file_path):
|
||||||
|
raise ValueError(f"Model file not found: {model_file_path}")
|
||||||
|
|
||||||
|
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||||
|
self.session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||||
|
self.input_shape = self.session.get_inputs()[0].shape[2:4] # H,W
|
||||||
|
self.garbage_layouts = ["footer", "header", "reference"]
|
||||||
|
|
||||||
|
def preprocess(self, image_list):
|
||||||
|
inputs = []
|
||||||
|
H, W = self.input_shape
|
||||||
|
for img in image_list:
|
||||||
|
h, w = img.shape[:2]
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)
|
||||||
|
|
||||||
|
r = min(H / h, W / w)
|
||||||
|
new_unpad = (int(round(w * r)), int(round(h * r)))
|
||||||
|
dw, dh = (W - new_unpad[0]) / 2.0, (H - new_unpad[1]) / 2.0
|
||||||
|
|
||||||
|
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||||
|
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
||||||
|
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
||||||
|
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114))
|
||||||
|
|
||||||
|
img /= 255.0
|
||||||
|
img = img.transpose(2, 0, 1)[np.newaxis, :, :, :].astype(np.float32)
|
||||||
|
|
||||||
|
inputs.append(
|
||||||
|
{
|
||||||
|
"image": img,
|
||||||
|
"scale_factor": [w / new_unpad[0], h / new_unpad[1]],
|
||||||
|
"pad": [dw, dh],
|
||||||
|
"orig_shape": [h, w],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
return inputs
|
||||||
|
|
||||||
|
def postprocess(self, boxes, inputs, thr=0.25):
|
||||||
|
arr = np.squeeze(boxes)
|
||||||
|
if arr.ndim == 1:
|
||||||
|
arr = arr.reshape(1, -1)
|
||||||
|
|
||||||
|
results = []
|
||||||
|
if arr.shape[1] == 6:
|
||||||
|
# [x1,y1,x2,y2,score,cls]
|
||||||
|
m = arr[:, 4] >= thr
|
||||||
|
arr = arr[m]
|
||||||
|
if arr.size == 0:
|
||||||
|
return []
|
||||||
|
xyxy = arr[:, :4].astype(np.float32)
|
||||||
|
scores = arr[:, 4].astype(np.float32)
|
||||||
|
cls_ids = arr[:, 5].astype(np.int32)
|
||||||
|
|
||||||
|
if "pad" in inputs:
|
||||||
|
dw, dh = inputs["pad"]
|
||||||
|
sx, sy = inputs["scale_factor"]
|
||||||
|
xyxy[:, [0, 2]] -= dw
|
||||||
|
xyxy[:, [1, 3]] -= dh
|
||||||
|
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||||
|
else:
|
||||||
|
# backup
|
||||||
|
sx, sy = inputs["scale_factor"]
|
||||||
|
xyxy *= np.array([sx, sy, sx, sy], dtype=np.float32)
|
||||||
|
|
||||||
|
keep_indices = []
|
||||||
|
for c in np.unique(cls_ids):
|
||||||
|
idx = np.where(cls_ids == c)[0]
|
||||||
|
k = nms(xyxy[idx], scores[idx], 0.45)
|
||||||
|
keep_indices.extend(idx[k])
|
||||||
|
|
||||||
|
for i in keep_indices:
|
||||||
|
cid = int(cls_ids[i])
|
||||||
|
if 0 <= cid < len(self.labels):
|
||||||
|
results.append({"type": self.labels[cid].lower(), "bbox": [float(t) for t in xyxy[i].tolist()], "score": float(scores[i])})
|
||||||
|
return results
|
||||||
|
|
||||||
|
raise ValueError(f"Unexpected output shape: {arr.shape}")
|
||||||
|
|
||||||
|
def __call__(self, image_list, ocr_res, scale_factor=3, thr=0.2, batch_size=16, drop=True):
|
||||||
|
import re
|
||||||
|
from collections import Counter
|
||||||
|
|
||||||
|
assert len(image_list) == len(ocr_res)
|
||||||
|
|
||||||
|
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||||
|
layouts_all_pages = [] # list of list[{"type","score","bbox":[x1,y1,x2,y2]}]
|
||||||
|
|
||||||
|
conf_thr = max(thr, 0.08)
|
||||||
|
|
||||||
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
|
for bi in range(batch_loop_cnt):
|
||||||
|
s = bi * batch_size
|
||||||
|
e = min((bi + 1) * batch_size, len(images))
|
||||||
|
batch_images = images[s:e]
|
||||||
|
|
||||||
|
inputs_list = self.preprocess(batch_images)
|
||||||
|
logging.debug("preprocess done")
|
||||||
|
|
||||||
|
for ins in inputs_list:
|
||||||
|
feeds = [ins["image"]]
|
||||||
|
out_list = self.session.infer(feeds=feeds, mode="static")
|
||||||
|
|
||||||
|
for out in out_list:
|
||||||
|
lts = self.postprocess(out, ins, conf_thr)
|
||||||
|
|
||||||
|
page_lts = []
|
||||||
|
for b in lts:
|
||||||
|
if float(b["score"]) >= 0.4 or b["type"] not in self.garbage_layouts:
|
||||||
|
x0, y0, x1, y1 = b["bbox"]
|
||||||
|
page_lts.append(
|
||||||
|
{
|
||||||
|
"type": b["type"],
|
||||||
|
"score": float(b["score"]),
|
||||||
|
"x0": float(x0) / scale_factor,
|
||||||
|
"x1": float(x1) / scale_factor,
|
||||||
|
"top": float(y0) / scale_factor,
|
||||||
|
"bottom": float(y1) / scale_factor,
|
||||||
|
"page_number": len(layouts_all_pages),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
layouts_all_pages.append(page_lts)
|
||||||
|
|
||||||
|
def _is_garbage_text(box):
|
||||||
|
patt = [r"^•+$", r"^[0-9]{1,2} / ?[0-9]{1,2}$", r"^[0-9]{1,2} of [0-9]{1,2}$", r"^http://[^ ]{12,}", r"\(cid *: *[0-9]+ *\)"]
|
||||||
|
return any(re.search(p, box.get("text", "")) for p in patt)
|
||||||
|
|
||||||
|
boxes_out = []
|
||||||
|
page_layout = []
|
||||||
|
garbages = {}
|
||||||
|
|
||||||
|
for pn, lts in enumerate(layouts_all_pages):
|
||||||
|
if lts:
|
||||||
|
avg_h = np.mean([lt["bottom"] - lt["top"] for lt in lts])
|
||||||
|
lts = self.sort_Y_firstly(lts, avg_h / 2 if avg_h > 0 else 0)
|
||||||
|
|
||||||
|
bxs = ocr_res[pn]
|
||||||
|
lts = self.layouts_cleanup(bxs, lts)
|
||||||
|
page_layout.append(lts)
|
||||||
|
|
||||||
|
def _tag_layout(ty):
|
||||||
|
nonlocal bxs, lts
|
||||||
|
lts_of_ty = [lt for lt in lts if lt["type"] == ty]
|
||||||
|
i = 0
|
||||||
|
while i < len(bxs):
|
||||||
|
if bxs[i].get("layout_type"):
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
if _is_garbage_text(bxs[i]):
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
ii = self.find_overlapped_with_threshold(bxs[i], lts_of_ty, thr=0.4)
|
||||||
|
if ii is None:
|
||||||
|
bxs[i]["layout_type"] = ""
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
lts_of_ty[ii]["visited"] = True
|
||||||
|
|
||||||
|
keep_feats = [
|
||||||
|
lts_of_ty[ii]["type"] == "footer" and bxs[i]["bottom"] < image_list[pn].shape[0] * 0.9 / scale_factor,
|
||||||
|
lts_of_ty[ii]["type"] == "header" and bxs[i]["top"] > image_list[pn].shape[0] * 0.1 / scale_factor,
|
||||||
|
]
|
||||||
|
if drop and lts_of_ty[ii]["type"] in self.garbage_layouts and not any(keep_feats):
|
||||||
|
garbages.setdefault(lts_of_ty[ii]["type"], []).append(bxs[i].get("text", ""))
|
||||||
|
bxs.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
bxs[i]["layoutno"] = f"{ty}-{ii}"
|
||||||
|
bxs[i]["layout_type"] = lts_of_ty[ii]["type"] if lts_of_ty[ii]["type"] != "equation" else "figure"
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
for ty in ["footer", "header", "reference", "figure caption", "table caption", "title", "table", "text", "figure", "equation"]:
|
||||||
|
_tag_layout(ty)
|
||||||
|
|
||||||
|
figs = [lt for lt in lts if lt["type"] in ["figure", "equation"]]
|
||||||
|
for i, lt in enumerate(figs):
|
||||||
|
if lt.get("visited"):
|
||||||
|
continue
|
||||||
|
lt = deepcopy(lt)
|
||||||
|
lt.pop("type", None)
|
||||||
|
lt["text"] = ""
|
||||||
|
lt["layout_type"] = "figure"
|
||||||
|
lt["layoutno"] = f"figure-{i}"
|
||||||
|
bxs.append(lt)
|
||||||
|
|
||||||
|
boxes_out.extend(bxs)
|
||||||
|
|
||||||
|
garbag_set = set()
|
||||||
|
for k, lst in garbages.items():
|
||||||
|
cnt = Counter(lst)
|
||||||
|
for g, c in cnt.items():
|
||||||
|
if c > 1:
|
||||||
|
garbag_set.add(g)
|
||||||
|
|
||||||
|
ocr_res_new = [b for b in boxes_out if b["text"].strip() not in garbag_set]
|
||||||
|
return ocr_res_new, page_layout
|
||||||
750
deepdoc/vision/ocr.py
Normal file
750
deepdoc/vision/ocr.py
Normal file
@@ -0,0 +1,750 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
import gc
|
||||||
|
import logging
|
||||||
|
import copy
|
||||||
|
import time
|
||||||
|
import os
|
||||||
|
|
||||||
|
from huggingface_hub import snapshot_download
|
||||||
|
|
||||||
|
from api.utils.file_utils import get_project_base_directory
|
||||||
|
from rag.settings import PARALLEL_DEVICES
|
||||||
|
from .operators import * # noqa: F403
|
||||||
|
from . import operators
|
||||||
|
import math
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
import onnxruntime as ort
|
||||||
|
|
||||||
|
from .postprocess import build_post_process
|
||||||
|
|
||||||
|
loaded_models = {}
|
||||||
|
|
||||||
|
def transform(data, ops=None):
|
||||||
|
""" transform """
|
||||||
|
if ops is None:
|
||||||
|
ops = []
|
||||||
|
for op in ops:
|
||||||
|
data = op(data)
|
||||||
|
if data is None:
|
||||||
|
return None
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
def create_operators(op_param_list, global_config=None):
|
||||||
|
"""
|
||||||
|
create operators based on the config
|
||||||
|
|
||||||
|
Args:
|
||||||
|
params(list): a dict list, used to create some operators
|
||||||
|
"""
|
||||||
|
assert isinstance(
|
||||||
|
op_param_list, list), ('operator config should be a list')
|
||||||
|
ops = []
|
||||||
|
for operator in op_param_list:
|
||||||
|
assert isinstance(operator,
|
||||||
|
dict) and len(operator) == 1, "yaml format error"
|
||||||
|
op_name = list(operator)[0]
|
||||||
|
param = {} if operator[op_name] is None else operator[op_name]
|
||||||
|
if global_config is not None:
|
||||||
|
param.update(global_config)
|
||||||
|
op = getattr(operators, op_name)(**param)
|
||||||
|
ops.append(op)
|
||||||
|
return ops
|
||||||
|
|
||||||
|
|
||||||
|
def load_model(model_dir, nm, device_id: int | None = None):
|
||||||
|
model_file_path = os.path.join(model_dir, nm + ".onnx")
|
||||||
|
model_cached_tag = model_file_path + str(device_id) if device_id is not None else model_file_path
|
||||||
|
|
||||||
|
global loaded_models
|
||||||
|
loaded_model = loaded_models.get(model_cached_tag)
|
||||||
|
if loaded_model:
|
||||||
|
logging.info(f"load_model {model_file_path} reuses cached model")
|
||||||
|
return loaded_model
|
||||||
|
|
||||||
|
if not os.path.exists(model_file_path):
|
||||||
|
raise ValueError("not find model file path {}".format(
|
||||||
|
model_file_path))
|
||||||
|
|
||||||
|
def cuda_is_available():
|
||||||
|
try:
|
||||||
|
import torch
|
||||||
|
target_id = 0 if device_id is None else device_id
|
||||||
|
if torch.cuda.is_available() and torch.cuda.device_count() > target_id:
|
||||||
|
return True
|
||||||
|
except Exception:
|
||||||
|
return False
|
||||||
|
return False
|
||||||
|
|
||||||
|
options = ort.SessionOptions()
|
||||||
|
options.enable_cpu_mem_arena = False
|
||||||
|
options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
|
||||||
|
options.intra_op_num_threads = 2
|
||||||
|
options.inter_op_num_threads = 2
|
||||||
|
|
||||||
|
# https://github.com/microsoft/onnxruntime/issues/9509#issuecomment-951546580
|
||||||
|
# Shrink GPU memory after execution
|
||||||
|
run_options = ort.RunOptions()
|
||||||
|
if cuda_is_available():
|
||||||
|
gpu_mem_limit_mb = int(os.environ.get("OCR_GPU_MEM_LIMIT_MB", "2048"))
|
||||||
|
arena_strategy = os.environ.get("OCR_ARENA_EXTEND_STRATEGY", "kNextPowerOfTwo")
|
||||||
|
provider_device_id = 0 if device_id is None else device_id
|
||||||
|
cuda_provider_options = {
|
||||||
|
"device_id": provider_device_id, # Use specific GPU
|
||||||
|
"gpu_mem_limit": max(gpu_mem_limit_mb, 0) * 1024 * 1024,
|
||||||
|
"arena_extend_strategy": arena_strategy, # gpu memory allocation strategy
|
||||||
|
}
|
||||||
|
sess = ort.InferenceSession(
|
||||||
|
model_file_path,
|
||||||
|
options=options,
|
||||||
|
providers=['CUDAExecutionProvider'],
|
||||||
|
provider_options=[cuda_provider_options]
|
||||||
|
)
|
||||||
|
run_options.add_run_config_entry("memory.enable_memory_arena_shrinkage", "gpu:" + str(provider_device_id))
|
||||||
|
logging.info(f"load_model {model_file_path} uses GPU (device {provider_device_id}, gpu_mem_limit={cuda_provider_options['gpu_mem_limit']}, arena_strategy={arena_strategy})")
|
||||||
|
else:
|
||||||
|
sess = ort.InferenceSession(
|
||||||
|
model_file_path,
|
||||||
|
options=options,
|
||||||
|
providers=['CPUExecutionProvider'])
|
||||||
|
run_options.add_run_config_entry("memory.enable_memory_arena_shrinkage", "cpu")
|
||||||
|
logging.info(f"load_model {model_file_path} uses CPU")
|
||||||
|
loaded_model = (sess, run_options)
|
||||||
|
loaded_models[model_cached_tag] = loaded_model
|
||||||
|
return loaded_model
|
||||||
|
|
||||||
|
|
||||||
|
class TextRecognizer:
|
||||||
|
def __init__(self, model_dir, device_id: int | None = None):
|
||||||
|
self.rec_image_shape = [int(v) for v in "3, 48, 320".split(",")]
|
||||||
|
self.rec_batch_num = 16
|
||||||
|
postprocess_params = {
|
||||||
|
'name': 'CTCLabelDecode',
|
||||||
|
"character_dict_path": os.path.join(model_dir, "ocr.res"),
|
||||||
|
"use_space_char": True
|
||||||
|
}
|
||||||
|
self.postprocess_op = build_post_process(postprocess_params)
|
||||||
|
self.predictor, self.run_options = load_model(model_dir, 'rec', device_id)
|
||||||
|
self.input_tensor = self.predictor.get_inputs()[0]
|
||||||
|
|
||||||
|
def resize_norm_img(self, img, max_wh_ratio):
|
||||||
|
imgC, imgH, imgW = self.rec_image_shape
|
||||||
|
|
||||||
|
assert imgC == img.shape[2]
|
||||||
|
imgW = int((imgH * max_wh_ratio))
|
||||||
|
w = self.input_tensor.shape[3:][0]
|
||||||
|
if isinstance(w, str):
|
||||||
|
pass
|
||||||
|
elif w is not None and w > 0:
|
||||||
|
imgW = w
|
||||||
|
h, w = img.shape[:2]
|
||||||
|
ratio = w / float(h)
|
||||||
|
if math.ceil(imgH * ratio) > imgW:
|
||||||
|
resized_w = imgW
|
||||||
|
else:
|
||||||
|
resized_w = int(math.ceil(imgH * ratio))
|
||||||
|
|
||||||
|
resized_image = cv2.resize(img, (resized_w, imgH))
|
||||||
|
resized_image = resized_image.astype('float32')
|
||||||
|
resized_image = resized_image.transpose((2, 0, 1)) / 255
|
||||||
|
resized_image -= 0.5
|
||||||
|
resized_image /= 0.5
|
||||||
|
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
|
||||||
|
padding_im[:, :, 0:resized_w] = resized_image
|
||||||
|
return padding_im
|
||||||
|
|
||||||
|
def resize_norm_img_vl(self, img, image_shape):
|
||||||
|
|
||||||
|
imgC, imgH, imgW = image_shape
|
||||||
|
img = img[:, :, ::-1] # bgr2rgb
|
||||||
|
resized_image = cv2.resize(
|
||||||
|
img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
|
||||||
|
resized_image = resized_image.astype('float32')
|
||||||
|
resized_image = resized_image.transpose((2, 0, 1)) / 255
|
||||||
|
return resized_image
|
||||||
|
|
||||||
|
def resize_norm_img_srn(self, img, image_shape):
|
||||||
|
imgC, imgH, imgW = image_shape
|
||||||
|
|
||||||
|
img_black = np.zeros((imgH, imgW))
|
||||||
|
im_hei = img.shape[0]
|
||||||
|
im_wid = img.shape[1]
|
||||||
|
|
||||||
|
if im_wid <= im_hei * 1:
|
||||||
|
img_new = cv2.resize(img, (imgH * 1, imgH))
|
||||||
|
elif im_wid <= im_hei * 2:
|
||||||
|
img_new = cv2.resize(img, (imgH * 2, imgH))
|
||||||
|
elif im_wid <= im_hei * 3:
|
||||||
|
img_new = cv2.resize(img, (imgH * 3, imgH))
|
||||||
|
else:
|
||||||
|
img_new = cv2.resize(img, (imgW, imgH))
|
||||||
|
|
||||||
|
img_np = np.asarray(img_new)
|
||||||
|
img_np = cv2.cvtColor(img_np, cv2.COLOR_BGR2GRAY)
|
||||||
|
img_black[:, 0:img_np.shape[1]] = img_np
|
||||||
|
img_black = img_black[:, :, np.newaxis]
|
||||||
|
|
||||||
|
row, col, c = img_black.shape
|
||||||
|
c = 1
|
||||||
|
|
||||||
|
return np.reshape(img_black, (c, row, col)).astype(np.float32)
|
||||||
|
|
||||||
|
def srn_other_inputs(self, image_shape, num_heads, max_text_length):
|
||||||
|
|
||||||
|
imgC, imgH, imgW = image_shape
|
||||||
|
feature_dim = int((imgH / 8) * (imgW / 8))
|
||||||
|
|
||||||
|
encoder_word_pos = np.array(range(0, feature_dim)).reshape(
|
||||||
|
(feature_dim, 1)).astype('int64')
|
||||||
|
gsrm_word_pos = np.array(range(0, max_text_length)).reshape(
|
||||||
|
(max_text_length, 1)).astype('int64')
|
||||||
|
|
||||||
|
gsrm_attn_bias_data = np.ones((1, max_text_length, max_text_length))
|
||||||
|
gsrm_slf_attn_bias1 = np.triu(gsrm_attn_bias_data, 1).reshape(
|
||||||
|
[-1, 1, max_text_length, max_text_length])
|
||||||
|
gsrm_slf_attn_bias1 = np.tile(
|
||||||
|
gsrm_slf_attn_bias1,
|
||||||
|
[1, num_heads, 1, 1]).astype('float32') * [-1e9]
|
||||||
|
|
||||||
|
gsrm_slf_attn_bias2 = np.tril(gsrm_attn_bias_data, -1).reshape(
|
||||||
|
[-1, 1, max_text_length, max_text_length])
|
||||||
|
gsrm_slf_attn_bias2 = np.tile(
|
||||||
|
gsrm_slf_attn_bias2,
|
||||||
|
[1, num_heads, 1, 1]).astype('float32') * [-1e9]
|
||||||
|
|
||||||
|
encoder_word_pos = encoder_word_pos[np.newaxis, :]
|
||||||
|
gsrm_word_pos = gsrm_word_pos[np.newaxis, :]
|
||||||
|
|
||||||
|
return [
|
||||||
|
encoder_word_pos, gsrm_word_pos, gsrm_slf_attn_bias1,
|
||||||
|
gsrm_slf_attn_bias2
|
||||||
|
]
|
||||||
|
|
||||||
|
def process_image_srn(self, img, image_shape, num_heads, max_text_length):
|
||||||
|
norm_img = self.resize_norm_img_srn(img, image_shape)
|
||||||
|
norm_img = norm_img[np.newaxis, :]
|
||||||
|
|
||||||
|
[encoder_word_pos, gsrm_word_pos, gsrm_slf_attn_bias1, gsrm_slf_attn_bias2] = \
|
||||||
|
self.srn_other_inputs(image_shape, num_heads, max_text_length)
|
||||||
|
|
||||||
|
gsrm_slf_attn_bias1 = gsrm_slf_attn_bias1.astype(np.float32)
|
||||||
|
gsrm_slf_attn_bias2 = gsrm_slf_attn_bias2.astype(np.float32)
|
||||||
|
encoder_word_pos = encoder_word_pos.astype(np.int64)
|
||||||
|
gsrm_word_pos = gsrm_word_pos.astype(np.int64)
|
||||||
|
|
||||||
|
return (norm_img, encoder_word_pos, gsrm_word_pos, gsrm_slf_attn_bias1,
|
||||||
|
gsrm_slf_attn_bias2)
|
||||||
|
|
||||||
|
def resize_norm_img_sar(self, img, image_shape,
|
||||||
|
width_downsample_ratio=0.25):
|
||||||
|
imgC, imgH, imgW_min, imgW_max = image_shape
|
||||||
|
h = img.shape[0]
|
||||||
|
w = img.shape[1]
|
||||||
|
valid_ratio = 1.0
|
||||||
|
# make sure new_width is an integral multiple of width_divisor.
|
||||||
|
width_divisor = int(1 / width_downsample_ratio)
|
||||||
|
# resize
|
||||||
|
ratio = w / float(h)
|
||||||
|
resize_w = math.ceil(imgH * ratio)
|
||||||
|
if resize_w % width_divisor != 0:
|
||||||
|
resize_w = round(resize_w / width_divisor) * width_divisor
|
||||||
|
if imgW_min is not None:
|
||||||
|
resize_w = max(imgW_min, resize_w)
|
||||||
|
if imgW_max is not None:
|
||||||
|
valid_ratio = min(1.0, 1.0 * resize_w / imgW_max)
|
||||||
|
resize_w = min(imgW_max, resize_w)
|
||||||
|
resized_image = cv2.resize(img, (resize_w, imgH))
|
||||||
|
resized_image = resized_image.astype('float32')
|
||||||
|
# norm
|
||||||
|
if image_shape[0] == 1:
|
||||||
|
resized_image = resized_image / 255
|
||||||
|
resized_image = resized_image[np.newaxis, :]
|
||||||
|
else:
|
||||||
|
resized_image = resized_image.transpose((2, 0, 1)) / 255
|
||||||
|
resized_image -= 0.5
|
||||||
|
resized_image /= 0.5
|
||||||
|
resize_shape = resized_image.shape
|
||||||
|
padding_im = -1.0 * np.ones((imgC, imgH, imgW_max), dtype=np.float32)
|
||||||
|
padding_im[:, :, 0:resize_w] = resized_image
|
||||||
|
pad_shape = padding_im.shape
|
||||||
|
|
||||||
|
return padding_im, resize_shape, pad_shape, valid_ratio
|
||||||
|
|
||||||
|
def resize_norm_img_spin(self, img):
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
|
||||||
|
# return padding_im
|
||||||
|
img = cv2.resize(img, tuple([100, 32]), cv2.INTER_CUBIC)
|
||||||
|
img = np.array(img, np.float32)
|
||||||
|
img = np.expand_dims(img, -1)
|
||||||
|
img = img.transpose((2, 0, 1))
|
||||||
|
mean = [127.5]
|
||||||
|
std = [127.5]
|
||||||
|
mean = np.array(mean, dtype=np.float32)
|
||||||
|
std = np.array(std, dtype=np.float32)
|
||||||
|
mean = np.float32(mean.reshape(1, -1))
|
||||||
|
stdinv = 1 / np.float32(std.reshape(1, -1))
|
||||||
|
img -= mean
|
||||||
|
img *= stdinv
|
||||||
|
return img
|
||||||
|
|
||||||
|
def resize_norm_img_svtr(self, img, image_shape):
|
||||||
|
|
||||||
|
imgC, imgH, imgW = image_shape
|
||||||
|
resized_image = cv2.resize(
|
||||||
|
img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
|
||||||
|
resized_image = resized_image.astype('float32')
|
||||||
|
resized_image = resized_image.transpose((2, 0, 1)) / 255
|
||||||
|
resized_image -= 0.5
|
||||||
|
resized_image /= 0.5
|
||||||
|
return resized_image
|
||||||
|
|
||||||
|
def resize_norm_img_abinet(self, img, image_shape):
|
||||||
|
|
||||||
|
imgC, imgH, imgW = image_shape
|
||||||
|
|
||||||
|
resized_image = cv2.resize(
|
||||||
|
img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
|
||||||
|
resized_image = resized_image.astype('float32')
|
||||||
|
resized_image = resized_image / 255.
|
||||||
|
|
||||||
|
mean = np.array([0.485, 0.456, 0.406])
|
||||||
|
std = np.array([0.229, 0.224, 0.225])
|
||||||
|
resized_image = (
|
||||||
|
resized_image - mean[None, None, ...]) / std[None, None, ...]
|
||||||
|
resized_image = resized_image.transpose((2, 0, 1))
|
||||||
|
resized_image = resized_image.astype('float32')
|
||||||
|
|
||||||
|
return resized_image
|
||||||
|
|
||||||
|
def norm_img_can(self, img, image_shape):
|
||||||
|
|
||||||
|
img = cv2.cvtColor(
|
||||||
|
img, cv2.COLOR_BGR2GRAY) # CAN only predict gray scale image
|
||||||
|
|
||||||
|
if self.rec_image_shape[0] == 1:
|
||||||
|
h, w = img.shape
|
||||||
|
_, imgH, imgW = self.rec_image_shape
|
||||||
|
if h < imgH or w < imgW:
|
||||||
|
padding_h = max(imgH - h, 0)
|
||||||
|
padding_w = max(imgW - w, 0)
|
||||||
|
img_padded = np.pad(img, ((0, padding_h), (0, padding_w)),
|
||||||
|
'constant',
|
||||||
|
constant_values=(255))
|
||||||
|
img = img_padded
|
||||||
|
|
||||||
|
img = np.expand_dims(img, 0) / 255.0 # h,w,c -> c,h,w
|
||||||
|
img = img.astype('float32')
|
||||||
|
|
||||||
|
return img
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
# close session and release manually
|
||||||
|
logging.info('Close text recognizer.')
|
||||||
|
if hasattr(self, "predictor"):
|
||||||
|
del self.predictor
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
|
def __call__(self, img_list):
|
||||||
|
img_num = len(img_list)
|
||||||
|
# Calculate the aspect ratio of all text bars
|
||||||
|
width_list = []
|
||||||
|
for img in img_list:
|
||||||
|
width_list.append(img.shape[1] / float(img.shape[0]))
|
||||||
|
# Sorting can speed up the recognition process
|
||||||
|
indices = np.argsort(np.array(width_list))
|
||||||
|
rec_res = [['', 0.0]] * img_num
|
||||||
|
batch_num = self.rec_batch_num
|
||||||
|
st = time.time()
|
||||||
|
|
||||||
|
for beg_img_no in range(0, img_num, batch_num):
|
||||||
|
end_img_no = min(img_num, beg_img_no + batch_num)
|
||||||
|
norm_img_batch = []
|
||||||
|
imgC, imgH, imgW = self.rec_image_shape[:3]
|
||||||
|
max_wh_ratio = imgW / imgH
|
||||||
|
# max_wh_ratio = 0
|
||||||
|
for ino in range(beg_img_no, end_img_no):
|
||||||
|
h, w = img_list[indices[ino]].shape[0:2]
|
||||||
|
wh_ratio = w * 1.0 / h
|
||||||
|
max_wh_ratio = max(max_wh_ratio, wh_ratio)
|
||||||
|
for ino in range(beg_img_no, end_img_no):
|
||||||
|
norm_img = self.resize_norm_img(img_list[indices[ino]],
|
||||||
|
max_wh_ratio)
|
||||||
|
norm_img = norm_img[np.newaxis, :]
|
||||||
|
norm_img_batch.append(norm_img)
|
||||||
|
norm_img_batch = np.concatenate(norm_img_batch)
|
||||||
|
norm_img_batch = norm_img_batch.copy()
|
||||||
|
|
||||||
|
input_dict = {}
|
||||||
|
input_dict[self.input_tensor.name] = norm_img_batch
|
||||||
|
for i in range(100000):
|
||||||
|
try:
|
||||||
|
outputs = self.predictor.run(None, input_dict, self.run_options)
|
||||||
|
break
|
||||||
|
except Exception as e:
|
||||||
|
if i >= 3:
|
||||||
|
raise e
|
||||||
|
time.sleep(5)
|
||||||
|
preds = outputs[0]
|
||||||
|
rec_result = self.postprocess_op(preds)
|
||||||
|
for rno in range(len(rec_result)):
|
||||||
|
rec_res[indices[beg_img_no + rno]] = rec_result[rno]
|
||||||
|
|
||||||
|
return rec_res, time.time() - st
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
|
class TextDetector:
|
||||||
|
def __init__(self, model_dir, device_id: int | None = None):
|
||||||
|
pre_process_list = [{
|
||||||
|
'DetResizeForTest': {
|
||||||
|
'limit_side_len': 960,
|
||||||
|
'limit_type': "max",
|
||||||
|
}
|
||||||
|
}, {
|
||||||
|
'NormalizeImage': {
|
||||||
|
'std': [0.229, 0.224, 0.225],
|
||||||
|
'mean': [0.485, 0.456, 0.406],
|
||||||
|
'scale': '1./255.',
|
||||||
|
'order': 'hwc'
|
||||||
|
}
|
||||||
|
}, {
|
||||||
|
'ToCHWImage': None
|
||||||
|
}, {
|
||||||
|
'KeepKeys': {
|
||||||
|
'keep_keys': ['image', 'shape']
|
||||||
|
}
|
||||||
|
}]
|
||||||
|
postprocess_params = {"name": "DBPostProcess", "thresh": 0.3, "box_thresh": 0.5, "max_candidates": 1000,
|
||||||
|
"unclip_ratio": 1.5, "use_dilation": False, "score_mode": "fast", "box_type": "quad"}
|
||||||
|
|
||||||
|
self.postprocess_op = build_post_process(postprocess_params)
|
||||||
|
self.predictor, self.run_options = load_model(model_dir, 'det', device_id)
|
||||||
|
self.input_tensor = self.predictor.get_inputs()[0]
|
||||||
|
|
||||||
|
img_h, img_w = self.input_tensor.shape[2:]
|
||||||
|
if isinstance(img_h, str) or isinstance(img_w, str):
|
||||||
|
pass
|
||||||
|
elif img_h is not None and img_w is not None and img_h > 0 and img_w > 0:
|
||||||
|
pre_process_list[0] = {
|
||||||
|
'DetResizeForTest': {
|
||||||
|
'image_shape': [img_h, img_w]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
self.preprocess_op = create_operators(pre_process_list)
|
||||||
|
|
||||||
|
def order_points_clockwise(self, pts):
|
||||||
|
rect = np.zeros((4, 2), dtype="float32")
|
||||||
|
s = pts.sum(axis=1)
|
||||||
|
rect[0] = pts[np.argmin(s)]
|
||||||
|
rect[2] = pts[np.argmax(s)]
|
||||||
|
tmp = np.delete(pts, (np.argmin(s), np.argmax(s)), axis=0)
|
||||||
|
diff = np.diff(np.array(tmp), axis=1)
|
||||||
|
rect[1] = tmp[np.argmin(diff)]
|
||||||
|
rect[3] = tmp[np.argmax(diff)]
|
||||||
|
return rect
|
||||||
|
|
||||||
|
def clip_det_res(self, points, img_height, img_width):
|
||||||
|
for pno in range(points.shape[0]):
|
||||||
|
points[pno, 0] = int(min(max(points[pno, 0], 0), img_width - 1))
|
||||||
|
points[pno, 1] = int(min(max(points[pno, 1], 0), img_height - 1))
|
||||||
|
return points
|
||||||
|
|
||||||
|
def filter_tag_det_res(self, dt_boxes, image_shape):
|
||||||
|
img_height, img_width = image_shape[0:2]
|
||||||
|
dt_boxes_new = []
|
||||||
|
for box in dt_boxes:
|
||||||
|
if isinstance(box, list):
|
||||||
|
box = np.array(box)
|
||||||
|
box = self.order_points_clockwise(box)
|
||||||
|
box = self.clip_det_res(box, img_height, img_width)
|
||||||
|
rect_width = int(np.linalg.norm(box[0] - box[1]))
|
||||||
|
rect_height = int(np.linalg.norm(box[0] - box[3]))
|
||||||
|
if rect_width <= 3 or rect_height <= 3:
|
||||||
|
continue
|
||||||
|
dt_boxes_new.append(box)
|
||||||
|
dt_boxes = np.array(dt_boxes_new)
|
||||||
|
return dt_boxes
|
||||||
|
|
||||||
|
def filter_tag_det_res_only_clip(self, dt_boxes, image_shape):
|
||||||
|
img_height, img_width = image_shape[0:2]
|
||||||
|
dt_boxes_new = []
|
||||||
|
for box in dt_boxes:
|
||||||
|
if isinstance(box, list):
|
||||||
|
box = np.array(box)
|
||||||
|
box = self.clip_det_res(box, img_height, img_width)
|
||||||
|
dt_boxes_new.append(box)
|
||||||
|
dt_boxes = np.array(dt_boxes_new)
|
||||||
|
return dt_boxes
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
logging.info("Close text detector.")
|
||||||
|
if hasattr(self, "predictor"):
|
||||||
|
del self.predictor
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
|
def __call__(self, img):
|
||||||
|
ori_im = img.copy()
|
||||||
|
data = {'image': img}
|
||||||
|
|
||||||
|
st = time.time()
|
||||||
|
data = transform(data, self.preprocess_op)
|
||||||
|
img, shape_list = data
|
||||||
|
if img is None:
|
||||||
|
return None, 0
|
||||||
|
img = np.expand_dims(img, axis=0)
|
||||||
|
shape_list = np.expand_dims(shape_list, axis=0)
|
||||||
|
img = img.copy()
|
||||||
|
input_dict = {}
|
||||||
|
input_dict[self.input_tensor.name] = img
|
||||||
|
for i in range(100000):
|
||||||
|
try:
|
||||||
|
outputs = self.predictor.run(None, input_dict, self.run_options)
|
||||||
|
break
|
||||||
|
except Exception as e:
|
||||||
|
if i >= 3:
|
||||||
|
raise e
|
||||||
|
time.sleep(5)
|
||||||
|
|
||||||
|
post_result = self.postprocess_op({"maps": outputs[0]}, shape_list)
|
||||||
|
dt_boxes = post_result[0]['points']
|
||||||
|
dt_boxes = self.filter_tag_det_res(dt_boxes, ori_im.shape)
|
||||||
|
|
||||||
|
return dt_boxes, time.time() - st
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
|
class OCR:
|
||||||
|
def __init__(self, model_dir=None):
|
||||||
|
"""
|
||||||
|
If you have trouble downloading HuggingFace models, -_^ this might help!!
|
||||||
|
|
||||||
|
For Linux:
|
||||||
|
export HF_ENDPOINT=https://hf-mirror.com
|
||||||
|
|
||||||
|
For Windows:
|
||||||
|
Good luck
|
||||||
|
^_-
|
||||||
|
|
||||||
|
"""
|
||||||
|
if not model_dir:
|
||||||
|
try:
|
||||||
|
model_dir = os.path.join(
|
||||||
|
get_project_base_directory(),
|
||||||
|
"rag/res/deepdoc")
|
||||||
|
|
||||||
|
# Append muti-gpus task to the list
|
||||||
|
if PARALLEL_DEVICES > 0:
|
||||||
|
self.text_detector = []
|
||||||
|
self.text_recognizer = []
|
||||||
|
for device_id in range(PARALLEL_DEVICES):
|
||||||
|
self.text_detector.append(TextDetector(model_dir, device_id))
|
||||||
|
self.text_recognizer.append(TextRecognizer(model_dir, device_id))
|
||||||
|
else:
|
||||||
|
self.text_detector = [TextDetector(model_dir)]
|
||||||
|
self.text_recognizer = [TextRecognizer(model_dir)]
|
||||||
|
|
||||||
|
except Exception:
|
||||||
|
model_dir = snapshot_download(repo_id="InfiniFlow/deepdoc",
|
||||||
|
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||||
|
local_dir_use_symlinks=False)
|
||||||
|
|
||||||
|
if PARALLEL_DEVICES > 0:
|
||||||
|
self.text_detector = []
|
||||||
|
self.text_recognizer = []
|
||||||
|
for device_id in range(PARALLEL_DEVICES):
|
||||||
|
self.text_detector.append(TextDetector(model_dir, device_id))
|
||||||
|
self.text_recognizer.append(TextRecognizer(model_dir, device_id))
|
||||||
|
else:
|
||||||
|
self.text_detector = [TextDetector(model_dir)]
|
||||||
|
self.text_recognizer = [TextRecognizer(model_dir)]
|
||||||
|
|
||||||
|
self.drop_score = 0.5
|
||||||
|
self.crop_image_res_index = 0
|
||||||
|
|
||||||
|
def get_rotate_crop_image(self, img, points):
|
||||||
|
'''
|
||||||
|
img_height, img_width = img.shape[0:2]
|
||||||
|
left = int(np.min(points[:, 0]))
|
||||||
|
right = int(np.max(points[:, 0]))
|
||||||
|
top = int(np.min(points[:, 1]))
|
||||||
|
bottom = int(np.max(points[:, 1]))
|
||||||
|
img_crop = img[top:bottom, left:right, :].copy()
|
||||||
|
points[:, 0] = points[:, 0] - left
|
||||||
|
points[:, 1] = points[:, 1] - top
|
||||||
|
'''
|
||||||
|
assert len(points) == 4, "shape of points must be 4*2"
|
||||||
|
img_crop_width = int(
|
||||||
|
max(
|
||||||
|
np.linalg.norm(points[0] - points[1]),
|
||||||
|
np.linalg.norm(points[2] - points[3])))
|
||||||
|
img_crop_height = int(
|
||||||
|
max(
|
||||||
|
np.linalg.norm(points[0] - points[3]),
|
||||||
|
np.linalg.norm(points[1] - points[2])))
|
||||||
|
pts_std = np.float32([[0, 0], [img_crop_width, 0],
|
||||||
|
[img_crop_width, img_crop_height],
|
||||||
|
[0, img_crop_height]])
|
||||||
|
M = cv2.getPerspectiveTransform(points, pts_std)
|
||||||
|
dst_img = cv2.warpPerspective(
|
||||||
|
img,
|
||||||
|
M, (img_crop_width, img_crop_height),
|
||||||
|
borderMode=cv2.BORDER_REPLICATE,
|
||||||
|
flags=cv2.INTER_CUBIC)
|
||||||
|
dst_img_height, dst_img_width = dst_img.shape[0:2]
|
||||||
|
if dst_img_height * 1.0 / dst_img_width >= 1.5:
|
||||||
|
# Try original orientation
|
||||||
|
rec_result = self.text_recognizer[0]([dst_img])
|
||||||
|
text, score = rec_result[0][0]
|
||||||
|
best_score = score
|
||||||
|
best_img = dst_img
|
||||||
|
|
||||||
|
# Try clockwise 90° rotation
|
||||||
|
rotated_cw = np.rot90(dst_img, k=3)
|
||||||
|
rec_result = self.text_recognizer[0]([rotated_cw])
|
||||||
|
rotated_cw_text, rotated_cw_score = rec_result[0][0]
|
||||||
|
if rotated_cw_score > best_score:
|
||||||
|
best_score = rotated_cw_score
|
||||||
|
best_img = rotated_cw
|
||||||
|
|
||||||
|
# Try counter-clockwise 90° rotation
|
||||||
|
rotated_ccw = np.rot90(dst_img, k=1)
|
||||||
|
rec_result = self.text_recognizer[0]([rotated_ccw])
|
||||||
|
rotated_ccw_text, rotated_ccw_score = rec_result[0][0]
|
||||||
|
if rotated_ccw_score > best_score:
|
||||||
|
best_img = rotated_ccw
|
||||||
|
|
||||||
|
# Use the best image
|
||||||
|
dst_img = best_img
|
||||||
|
return dst_img
|
||||||
|
|
||||||
|
def sorted_boxes(self, dt_boxes):
|
||||||
|
"""
|
||||||
|
Sort text boxes in order from top to bottom, left to right
|
||||||
|
args:
|
||||||
|
dt_boxes(array):detected text boxes with shape [4, 2]
|
||||||
|
return:
|
||||||
|
sorted boxes(array) with shape [4, 2]
|
||||||
|
"""
|
||||||
|
num_boxes = dt_boxes.shape[0]
|
||||||
|
sorted_boxes = sorted(dt_boxes, key=lambda x: (x[0][1], x[0][0]))
|
||||||
|
_boxes = list(sorted_boxes)
|
||||||
|
|
||||||
|
for i in range(num_boxes - 1):
|
||||||
|
for j in range(i, -1, -1):
|
||||||
|
if abs(_boxes[j + 1][0][1] - _boxes[j][0][1]) < 10 and \
|
||||||
|
(_boxes[j + 1][0][0] < _boxes[j][0][0]):
|
||||||
|
tmp = _boxes[j]
|
||||||
|
_boxes[j] = _boxes[j + 1]
|
||||||
|
_boxes[j + 1] = tmp
|
||||||
|
else:
|
||||||
|
break
|
||||||
|
return _boxes
|
||||||
|
|
||||||
|
def detect(self, img, device_id: int | None = None):
|
||||||
|
if device_id is None:
|
||||||
|
device_id = 0
|
||||||
|
|
||||||
|
time_dict = {'det': 0, 'rec': 0, 'cls': 0, 'all': 0}
|
||||||
|
|
||||||
|
if img is None:
|
||||||
|
return None, None, time_dict
|
||||||
|
|
||||||
|
start = time.time()
|
||||||
|
dt_boxes, elapse = self.text_detector[device_id](img)
|
||||||
|
time_dict['det'] = elapse
|
||||||
|
|
||||||
|
if dt_boxes is None:
|
||||||
|
end = time.time()
|
||||||
|
time_dict['all'] = end - start
|
||||||
|
return None, None, time_dict
|
||||||
|
|
||||||
|
return zip(self.sorted_boxes(dt_boxes), [
|
||||||
|
("", 0) for _ in range(len(dt_boxes))])
|
||||||
|
|
||||||
|
def recognize(self, ori_im, box, device_id: int | None = None):
|
||||||
|
if device_id is None:
|
||||||
|
device_id = 0
|
||||||
|
|
||||||
|
img_crop = self.get_rotate_crop_image(ori_im, box)
|
||||||
|
|
||||||
|
rec_res, elapse = self.text_recognizer[device_id]([img_crop])
|
||||||
|
text, score = rec_res[0]
|
||||||
|
if score < self.drop_score:
|
||||||
|
return ""
|
||||||
|
return text
|
||||||
|
|
||||||
|
def recognize_batch(self, img_list, device_id: int | None = None):
|
||||||
|
if device_id is None:
|
||||||
|
device_id = 0
|
||||||
|
rec_res, elapse = self.text_recognizer[device_id](img_list)
|
||||||
|
texts = []
|
||||||
|
for i in range(len(rec_res)):
|
||||||
|
text, score = rec_res[i]
|
||||||
|
if score < self.drop_score:
|
||||||
|
text = ""
|
||||||
|
texts.append(text)
|
||||||
|
return texts
|
||||||
|
|
||||||
|
def __call__(self, img, device_id = 0, cls=True):
|
||||||
|
time_dict = {'det': 0, 'rec': 0, 'cls': 0, 'all': 0}
|
||||||
|
if device_id is None:
|
||||||
|
device_id = 0
|
||||||
|
|
||||||
|
if img is None:
|
||||||
|
return None, None, time_dict
|
||||||
|
|
||||||
|
start = time.time()
|
||||||
|
ori_im = img.copy()
|
||||||
|
dt_boxes, elapse = self.text_detector[device_id](img)
|
||||||
|
time_dict['det'] = elapse
|
||||||
|
|
||||||
|
if dt_boxes is None:
|
||||||
|
end = time.time()
|
||||||
|
time_dict['all'] = end - start
|
||||||
|
return None, None, time_dict
|
||||||
|
|
||||||
|
img_crop_list = []
|
||||||
|
|
||||||
|
dt_boxes = self.sorted_boxes(dt_boxes)
|
||||||
|
|
||||||
|
for bno in range(len(dt_boxes)):
|
||||||
|
tmp_box = copy.deepcopy(dt_boxes[bno])
|
||||||
|
img_crop = self.get_rotate_crop_image(ori_im, tmp_box)
|
||||||
|
img_crop_list.append(img_crop)
|
||||||
|
|
||||||
|
rec_res, elapse = self.text_recognizer[device_id](img_crop_list)
|
||||||
|
|
||||||
|
time_dict['rec'] = elapse
|
||||||
|
|
||||||
|
filter_boxes, filter_rec_res = [], []
|
||||||
|
for box, rec_result in zip(dt_boxes, rec_res):
|
||||||
|
text, score = rec_result
|
||||||
|
if score >= self.drop_score:
|
||||||
|
filter_boxes.append(box)
|
||||||
|
filter_rec_res.append(rec_result)
|
||||||
|
end = time.time()
|
||||||
|
time_dict['all'] = end - start
|
||||||
|
|
||||||
|
# for bno in range(len(img_crop_list)):
|
||||||
|
# print(f"{bno}, {rec_res[bno]}")
|
||||||
|
|
||||||
|
return list(zip([a.tolist() for a in filter_boxes], filter_rec_res))
|
||||||
725
deepdoc/vision/operators.py
Normal file
725
deepdoc/vision/operators.py
Normal file
@@ -0,0 +1,725 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2024 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import sys
|
||||||
|
import six
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
import math
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
|
|
||||||
|
class DecodeImage:
|
||||||
|
""" decode image """
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
img_mode='RGB',
|
||||||
|
channel_first=False,
|
||||||
|
ignore_orientation=False,
|
||||||
|
**kwargs):
|
||||||
|
self.img_mode = img_mode
|
||||||
|
self.channel_first = channel_first
|
||||||
|
self.ignore_orientation = ignore_orientation
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
if six.PY2:
|
||||||
|
assert isinstance(img, str) and len(
|
||||||
|
img) > 0, "invalid input 'img' in DecodeImage"
|
||||||
|
else:
|
||||||
|
assert isinstance(img, bytes) and len(
|
||||||
|
img) > 0, "invalid input 'img' in DecodeImage"
|
||||||
|
img = np.frombuffer(img, dtype='uint8')
|
||||||
|
if self.ignore_orientation:
|
||||||
|
img = cv2.imdecode(img, cv2.IMREAD_IGNORE_ORIENTATION |
|
||||||
|
cv2.IMREAD_COLOR)
|
||||||
|
else:
|
||||||
|
img = cv2.imdecode(img, 1)
|
||||||
|
if img is None:
|
||||||
|
return None
|
||||||
|
if self.img_mode == 'GRAY':
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
|
||||||
|
elif self.img_mode == 'RGB':
|
||||||
|
assert img.shape[2] == 3, 'invalid shape of image[%s]' % (
|
||||||
|
img.shape)
|
||||||
|
img = img[:, :, ::-1]
|
||||||
|
|
||||||
|
if self.channel_first:
|
||||||
|
img = img.transpose((2, 0, 1))
|
||||||
|
|
||||||
|
data['image'] = img
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
class StandardizeImag:
|
||||||
|
"""normalize image
|
||||||
|
Args:
|
||||||
|
mean (list): im - mean
|
||||||
|
std (list): im / std
|
||||||
|
is_scale (bool): whether need im / 255
|
||||||
|
norm_type (str): type in ['mean_std', 'none']
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, mean, std, is_scale=True, norm_type='mean_std'):
|
||||||
|
self.mean = mean
|
||||||
|
self.std = std
|
||||||
|
self.is_scale = is_scale
|
||||||
|
self.norm_type = norm_type
|
||||||
|
|
||||||
|
def __call__(self, im, im_info):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
im (np.ndarray): image (np.ndarray)
|
||||||
|
im_info (dict): info of image
|
||||||
|
Returns:
|
||||||
|
im (np.ndarray): processed image (np.ndarray)
|
||||||
|
im_info (dict): info of processed image
|
||||||
|
"""
|
||||||
|
im = im.astype(np.float32, copy=False)
|
||||||
|
if self.is_scale:
|
||||||
|
scale = 1.0 / 255.0
|
||||||
|
im *= scale
|
||||||
|
|
||||||
|
if self.norm_type == 'mean_std':
|
||||||
|
mean = np.array(self.mean)[np.newaxis, np.newaxis, :]
|
||||||
|
std = np.array(self.std)[np.newaxis, np.newaxis, :]
|
||||||
|
im -= mean
|
||||||
|
im /= std
|
||||||
|
return im, im_info
|
||||||
|
|
||||||
|
|
||||||
|
class NormalizeImage:
|
||||||
|
""" normalize image such as subtract mean, divide std
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, scale=None, mean=None, std=None, order='chw', **kwargs):
|
||||||
|
if isinstance(scale, str):
|
||||||
|
scale = eval(scale)
|
||||||
|
self.scale = np.float32(scale if scale is not None else 1.0 / 255.0)
|
||||||
|
mean = mean if mean is not None else [0.485, 0.456, 0.406]
|
||||||
|
std = std if std is not None else [0.229, 0.224, 0.225]
|
||||||
|
|
||||||
|
shape = (3, 1, 1) if order == 'chw' else (1, 1, 3)
|
||||||
|
self.mean = np.array(mean).reshape(shape).astype('float32')
|
||||||
|
self.std = np.array(std).reshape(shape).astype('float32')
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
from PIL import Image
|
||||||
|
if isinstance(img, Image.Image):
|
||||||
|
img = np.array(img)
|
||||||
|
assert isinstance(img,
|
||||||
|
np.ndarray), "invalid input 'img' in NormalizeImage"
|
||||||
|
data['image'] = (
|
||||||
|
img.astype('float32') * self.scale - self.mean) / self.std
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
class ToCHWImage:
|
||||||
|
""" convert hwc image to chw image
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
pass
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
from PIL import Image
|
||||||
|
if isinstance(img, Image.Image):
|
||||||
|
img = np.array(img)
|
||||||
|
data['image'] = img.transpose((2, 0, 1))
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
class KeepKeys:
|
||||||
|
def __init__(self, keep_keys, **kwargs):
|
||||||
|
self.keep_keys = keep_keys
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
data_list = []
|
||||||
|
for key in self.keep_keys:
|
||||||
|
data_list.append(data[key])
|
||||||
|
return data_list
|
||||||
|
|
||||||
|
|
||||||
|
class Pad:
|
||||||
|
def __init__(self, size=None, size_div=32, **kwargs):
|
||||||
|
if size is not None and not isinstance(size, (int, list, tuple)):
|
||||||
|
raise TypeError("Type of target_size is invalid. Now is {}".format(
|
||||||
|
type(size)))
|
||||||
|
if isinstance(size, int):
|
||||||
|
size = [size, size]
|
||||||
|
self.size = size
|
||||||
|
self.size_div = size_div
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
|
||||||
|
img = data['image']
|
||||||
|
img_h, img_w = img.shape[0], img.shape[1]
|
||||||
|
if self.size:
|
||||||
|
resize_h2, resize_w2 = self.size
|
||||||
|
assert (
|
||||||
|
img_h < resize_h2 and img_w < resize_w2
|
||||||
|
), '(h, w) of target size should be greater than (img_h, img_w)'
|
||||||
|
else:
|
||||||
|
resize_h2 = max(
|
||||||
|
int(math.ceil(img.shape[0] / self.size_div) * self.size_div),
|
||||||
|
self.size_div)
|
||||||
|
resize_w2 = max(
|
||||||
|
int(math.ceil(img.shape[1] / self.size_div) * self.size_div),
|
||||||
|
self.size_div)
|
||||||
|
img = cv2.copyMakeBorder(
|
||||||
|
img,
|
||||||
|
0,
|
||||||
|
resize_h2 - img_h,
|
||||||
|
0,
|
||||||
|
resize_w2 - img_w,
|
||||||
|
cv2.BORDER_CONSTANT,
|
||||||
|
value=0)
|
||||||
|
data['image'] = img
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
class LinearResize:
|
||||||
|
"""resize image by target_size and max_size
|
||||||
|
Args:
|
||||||
|
target_size (int): the target size of image
|
||||||
|
keep_ratio (bool): whether keep_ratio or not, default true
|
||||||
|
interp (int): method of resize
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, target_size, keep_ratio=True, interp=cv2.INTER_LINEAR):
|
||||||
|
if isinstance(target_size, int):
|
||||||
|
target_size = [target_size, target_size]
|
||||||
|
self.target_size = target_size
|
||||||
|
self.keep_ratio = keep_ratio
|
||||||
|
self.interp = interp
|
||||||
|
|
||||||
|
def __call__(self, im, im_info):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
im (np.ndarray): image (np.ndarray)
|
||||||
|
im_info (dict): info of image
|
||||||
|
Returns:
|
||||||
|
im (np.ndarray): processed image (np.ndarray)
|
||||||
|
im_info (dict): info of processed image
|
||||||
|
"""
|
||||||
|
assert len(self.target_size) == 2
|
||||||
|
assert self.target_size[0] > 0 and self.target_size[1] > 0
|
||||||
|
_im_channel = im.shape[2]
|
||||||
|
im_scale_y, im_scale_x = self.generate_scale(im)
|
||||||
|
im = cv2.resize(
|
||||||
|
im,
|
||||||
|
None,
|
||||||
|
None,
|
||||||
|
fx=im_scale_x,
|
||||||
|
fy=im_scale_y,
|
||||||
|
interpolation=self.interp)
|
||||||
|
im_info['im_shape'] = np.array(im.shape[:2]).astype('float32')
|
||||||
|
im_info['scale_factor'] = np.array(
|
||||||
|
[im_scale_y, im_scale_x]).astype('float32')
|
||||||
|
return im, im_info
|
||||||
|
|
||||||
|
def generate_scale(self, im):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
im (np.ndarray): image (np.ndarray)
|
||||||
|
Returns:
|
||||||
|
im_scale_x: the resize ratio of X
|
||||||
|
im_scale_y: the resize ratio of Y
|
||||||
|
"""
|
||||||
|
origin_shape = im.shape[:2]
|
||||||
|
_im_c = im.shape[2]
|
||||||
|
if self.keep_ratio:
|
||||||
|
im_size_min = np.min(origin_shape)
|
||||||
|
im_size_max = np.max(origin_shape)
|
||||||
|
target_size_min = np.min(self.target_size)
|
||||||
|
target_size_max = np.max(self.target_size)
|
||||||
|
im_scale = float(target_size_min) / float(im_size_min)
|
||||||
|
if np.round(im_scale * im_size_max) > target_size_max:
|
||||||
|
im_scale = float(target_size_max) / float(im_size_max)
|
||||||
|
im_scale_x = im_scale
|
||||||
|
im_scale_y = im_scale
|
||||||
|
else:
|
||||||
|
resize_h, resize_w = self.target_size
|
||||||
|
im_scale_y = resize_h / float(origin_shape[0])
|
||||||
|
im_scale_x = resize_w / float(origin_shape[1])
|
||||||
|
return im_scale_y, im_scale_x
|
||||||
|
|
||||||
|
|
||||||
|
class Resize:
|
||||||
|
def __init__(self, size=(640, 640), **kwargs):
|
||||||
|
self.size = size
|
||||||
|
|
||||||
|
def resize_image(self, img):
|
||||||
|
resize_h, resize_w = self.size
|
||||||
|
ori_h, ori_w = img.shape[:2] # (h, w, c)
|
||||||
|
ratio_h = float(resize_h) / ori_h
|
||||||
|
ratio_w = float(resize_w) / ori_w
|
||||||
|
img = cv2.resize(img, (int(resize_w), int(resize_h)))
|
||||||
|
return img, [ratio_h, ratio_w]
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
if 'polys' in data:
|
||||||
|
text_polys = data['polys']
|
||||||
|
|
||||||
|
img_resize, [ratio_h, ratio_w] = self.resize_image(img)
|
||||||
|
if 'polys' in data:
|
||||||
|
new_boxes = []
|
||||||
|
for box in text_polys:
|
||||||
|
new_box = []
|
||||||
|
for cord in box:
|
||||||
|
new_box.append([cord[0] * ratio_w, cord[1] * ratio_h])
|
||||||
|
new_boxes.append(new_box)
|
||||||
|
data['polys'] = np.array(new_boxes, dtype=np.float32)
|
||||||
|
data['image'] = img_resize
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
class DetResizeForTest:
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super(DetResizeForTest, self).__init__()
|
||||||
|
self.resize_type = 0
|
||||||
|
self.keep_ratio = False
|
||||||
|
if 'image_shape' in kwargs:
|
||||||
|
self.image_shape = kwargs['image_shape']
|
||||||
|
self.resize_type = 1
|
||||||
|
if 'keep_ratio' in kwargs:
|
||||||
|
self.keep_ratio = kwargs['keep_ratio']
|
||||||
|
elif 'limit_side_len' in kwargs:
|
||||||
|
self.limit_side_len = kwargs['limit_side_len']
|
||||||
|
self.limit_type = kwargs.get('limit_type', 'min')
|
||||||
|
elif 'resize_long' in kwargs:
|
||||||
|
self.resize_type = 2
|
||||||
|
self.resize_long = kwargs.get('resize_long', 960)
|
||||||
|
else:
|
||||||
|
self.limit_side_len = 736
|
||||||
|
self.limit_type = 'min'
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
src_h, src_w, _ = img.shape
|
||||||
|
if sum([src_h, src_w]) < 64:
|
||||||
|
img = self.image_padding(img)
|
||||||
|
|
||||||
|
if self.resize_type == 0:
|
||||||
|
# img, shape = self.resize_image_type0(img)
|
||||||
|
img, [ratio_h, ratio_w] = self.resize_image_type0(img)
|
||||||
|
elif self.resize_type == 2:
|
||||||
|
img, [ratio_h, ratio_w] = self.resize_image_type2(img)
|
||||||
|
else:
|
||||||
|
# img, shape = self.resize_image_type1(img)
|
||||||
|
img, [ratio_h, ratio_w] = self.resize_image_type1(img)
|
||||||
|
data['image'] = img
|
||||||
|
data['shape'] = np.array([src_h, src_w, ratio_h, ratio_w])
|
||||||
|
return data
|
||||||
|
|
||||||
|
def image_padding(self, im, value=0):
|
||||||
|
h, w, c = im.shape
|
||||||
|
im_pad = np.zeros((max(32, h), max(32, w), c), np.uint8) + value
|
||||||
|
im_pad[:h, :w, :] = im
|
||||||
|
return im_pad
|
||||||
|
|
||||||
|
def resize_image_type1(self, img):
|
||||||
|
resize_h, resize_w = self.image_shape
|
||||||
|
ori_h, ori_w = img.shape[:2] # (h, w, c)
|
||||||
|
if self.keep_ratio is True:
|
||||||
|
resize_w = ori_w * resize_h / ori_h
|
||||||
|
N = math.ceil(resize_w / 32)
|
||||||
|
resize_w = N * 32
|
||||||
|
ratio_h = float(resize_h) / ori_h
|
||||||
|
ratio_w = float(resize_w) / ori_w
|
||||||
|
img = cv2.resize(img, (int(resize_w), int(resize_h)))
|
||||||
|
# return img, np.array([ori_h, ori_w])
|
||||||
|
return img, [ratio_h, ratio_w]
|
||||||
|
|
||||||
|
def resize_image_type0(self, img):
|
||||||
|
"""
|
||||||
|
resize image to a size multiple of 32 which is required by the network
|
||||||
|
args:
|
||||||
|
img(array): array with shape [h, w, c]
|
||||||
|
return(tuple):
|
||||||
|
img, (ratio_h, ratio_w)
|
||||||
|
"""
|
||||||
|
limit_side_len = self.limit_side_len
|
||||||
|
h, w, c = img.shape
|
||||||
|
|
||||||
|
# limit the max side
|
||||||
|
if self.limit_type == 'max':
|
||||||
|
if max(h, w) > limit_side_len:
|
||||||
|
if h > w:
|
||||||
|
ratio = float(limit_side_len) / h
|
||||||
|
else:
|
||||||
|
ratio = float(limit_side_len) / w
|
||||||
|
else:
|
||||||
|
ratio = 1.
|
||||||
|
elif self.limit_type == 'min':
|
||||||
|
if min(h, w) < limit_side_len:
|
||||||
|
if h < w:
|
||||||
|
ratio = float(limit_side_len) / h
|
||||||
|
else:
|
||||||
|
ratio = float(limit_side_len) / w
|
||||||
|
else:
|
||||||
|
ratio = 1.
|
||||||
|
elif self.limit_type == 'resize_long':
|
||||||
|
ratio = float(limit_side_len) / max(h, w)
|
||||||
|
else:
|
||||||
|
raise Exception('not support limit type, image ')
|
||||||
|
resize_h = int(h * ratio)
|
||||||
|
resize_w = int(w * ratio)
|
||||||
|
|
||||||
|
resize_h = max(int(round(resize_h / 32) * 32), 32)
|
||||||
|
resize_w = max(int(round(resize_w / 32) * 32), 32)
|
||||||
|
|
||||||
|
try:
|
||||||
|
if int(resize_w) <= 0 or int(resize_h) <= 0:
|
||||||
|
return None, (None, None)
|
||||||
|
img = cv2.resize(img, (int(resize_w), int(resize_h)))
|
||||||
|
except BaseException:
|
||||||
|
logging.exception("{} {} {}".format(img.shape, resize_w, resize_h))
|
||||||
|
sys.exit(0)
|
||||||
|
ratio_h = resize_h / float(h)
|
||||||
|
ratio_w = resize_w / float(w)
|
||||||
|
return img, [ratio_h, ratio_w]
|
||||||
|
|
||||||
|
def resize_image_type2(self, img):
|
||||||
|
h, w, _ = img.shape
|
||||||
|
|
||||||
|
resize_w = w
|
||||||
|
resize_h = h
|
||||||
|
|
||||||
|
if resize_h > resize_w:
|
||||||
|
ratio = float(self.resize_long) / resize_h
|
||||||
|
else:
|
||||||
|
ratio = float(self.resize_long) / resize_w
|
||||||
|
|
||||||
|
resize_h = int(resize_h * ratio)
|
||||||
|
resize_w = int(resize_w * ratio)
|
||||||
|
|
||||||
|
max_stride = 128
|
||||||
|
resize_h = (resize_h + max_stride - 1) // max_stride * max_stride
|
||||||
|
resize_w = (resize_w + max_stride - 1) // max_stride * max_stride
|
||||||
|
img = cv2.resize(img, (int(resize_w), int(resize_h)))
|
||||||
|
ratio_h = resize_h / float(h)
|
||||||
|
ratio_w = resize_w / float(w)
|
||||||
|
|
||||||
|
return img, [ratio_h, ratio_w]
|
||||||
|
|
||||||
|
|
||||||
|
class E2EResizeForTest:
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super(E2EResizeForTest, self).__init__()
|
||||||
|
self.max_side_len = kwargs['max_side_len']
|
||||||
|
self.valid_set = kwargs['valid_set']
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
src_h, src_w, _ = img.shape
|
||||||
|
if self.valid_set == 'totaltext':
|
||||||
|
im_resized, [ratio_h, ratio_w] = self.resize_image_for_totaltext(
|
||||||
|
img, max_side_len=self.max_side_len)
|
||||||
|
else:
|
||||||
|
im_resized, (ratio_h, ratio_w) = self.resize_image(
|
||||||
|
img, max_side_len=self.max_side_len)
|
||||||
|
data['image'] = im_resized
|
||||||
|
data['shape'] = np.array([src_h, src_w, ratio_h, ratio_w])
|
||||||
|
return data
|
||||||
|
|
||||||
|
def resize_image_for_totaltext(self, im, max_side_len=512):
|
||||||
|
h, w, _ = im.shape
|
||||||
|
resize_w = w
|
||||||
|
resize_h = h
|
||||||
|
ratio = 1.25
|
||||||
|
if h * ratio > max_side_len:
|
||||||
|
ratio = float(max_side_len) / resize_h
|
||||||
|
resize_h = int(resize_h * ratio)
|
||||||
|
resize_w = int(resize_w * ratio)
|
||||||
|
|
||||||
|
max_stride = 128
|
||||||
|
resize_h = (resize_h + max_stride - 1) // max_stride * max_stride
|
||||||
|
resize_w = (resize_w + max_stride - 1) // max_stride * max_stride
|
||||||
|
im = cv2.resize(im, (int(resize_w), int(resize_h)))
|
||||||
|
ratio_h = resize_h / float(h)
|
||||||
|
ratio_w = resize_w / float(w)
|
||||||
|
return im, (ratio_h, ratio_w)
|
||||||
|
|
||||||
|
def resize_image(self, im, max_side_len=512):
|
||||||
|
"""
|
||||||
|
resize image to a size multiple of max_stride which is required by the network
|
||||||
|
:param im: the resized image
|
||||||
|
:param max_side_len: limit of max image size to avoid out of memory in gpu
|
||||||
|
:return: the resized image and the resize ratio
|
||||||
|
"""
|
||||||
|
h, w, _ = im.shape
|
||||||
|
|
||||||
|
resize_w = w
|
||||||
|
resize_h = h
|
||||||
|
|
||||||
|
# Fix the longer side
|
||||||
|
if resize_h > resize_w:
|
||||||
|
ratio = float(max_side_len) / resize_h
|
||||||
|
else:
|
||||||
|
ratio = float(max_side_len) / resize_w
|
||||||
|
|
||||||
|
resize_h = int(resize_h * ratio)
|
||||||
|
resize_w = int(resize_w * ratio)
|
||||||
|
|
||||||
|
max_stride = 128
|
||||||
|
resize_h = (resize_h + max_stride - 1) // max_stride * max_stride
|
||||||
|
resize_w = (resize_w + max_stride - 1) // max_stride * max_stride
|
||||||
|
im = cv2.resize(im, (int(resize_w), int(resize_h)))
|
||||||
|
ratio_h = resize_h / float(h)
|
||||||
|
ratio_w = resize_w / float(w)
|
||||||
|
|
||||||
|
return im, (ratio_h, ratio_w)
|
||||||
|
|
||||||
|
|
||||||
|
class KieResize:
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super(KieResize, self).__init__()
|
||||||
|
self.max_side, self.min_side = kwargs['img_scale'][0], kwargs[
|
||||||
|
'img_scale'][1]
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
points = data['points']
|
||||||
|
src_h, src_w, _ = img.shape
|
||||||
|
im_resized, scale_factor, [ratio_h, ratio_w
|
||||||
|
], [new_h, new_w] = self.resize_image(img)
|
||||||
|
resize_points = self.resize_boxes(img, points, scale_factor)
|
||||||
|
data['ori_image'] = img
|
||||||
|
data['ori_boxes'] = points
|
||||||
|
data['points'] = resize_points
|
||||||
|
data['image'] = im_resized
|
||||||
|
data['shape'] = np.array([new_h, new_w])
|
||||||
|
return data
|
||||||
|
|
||||||
|
def resize_image(self, img):
|
||||||
|
norm_img = np.zeros([1024, 1024, 3], dtype='float32')
|
||||||
|
scale = [512, 1024]
|
||||||
|
h, w = img.shape[:2]
|
||||||
|
max_long_edge = max(scale)
|
||||||
|
max_short_edge = min(scale)
|
||||||
|
scale_factor = min(max_long_edge / max(h, w),
|
||||||
|
max_short_edge / min(h, w))
|
||||||
|
resize_w, resize_h = int(w * float(scale_factor) + 0.5), int(h * float(
|
||||||
|
scale_factor) + 0.5)
|
||||||
|
max_stride = 32
|
||||||
|
resize_h = (resize_h + max_stride - 1) // max_stride * max_stride
|
||||||
|
resize_w = (resize_w + max_stride - 1) // max_stride * max_stride
|
||||||
|
im = cv2.resize(img, (resize_w, resize_h))
|
||||||
|
new_h, new_w = im.shape[:2]
|
||||||
|
w_scale = new_w / w
|
||||||
|
h_scale = new_h / h
|
||||||
|
scale_factor = np.array(
|
||||||
|
[w_scale, h_scale, w_scale, h_scale], dtype=np.float32)
|
||||||
|
norm_img[:new_h, :new_w, :] = im
|
||||||
|
return norm_img, scale_factor, [h_scale, w_scale], [new_h, new_w]
|
||||||
|
|
||||||
|
def resize_boxes(self, im, points, scale_factor):
|
||||||
|
points = points * scale_factor
|
||||||
|
img_shape = im.shape[:2]
|
||||||
|
points[:, 0::2] = np.clip(points[:, 0::2], 0, img_shape[1])
|
||||||
|
points[:, 1::2] = np.clip(points[:, 1::2], 0, img_shape[0])
|
||||||
|
return points
|
||||||
|
|
||||||
|
|
||||||
|
class SRResize:
|
||||||
|
def __init__(self,
|
||||||
|
imgH=32,
|
||||||
|
imgW=128,
|
||||||
|
down_sample_scale=4,
|
||||||
|
keep_ratio=False,
|
||||||
|
min_ratio=1,
|
||||||
|
mask=False,
|
||||||
|
infer_mode=False,
|
||||||
|
**kwargs):
|
||||||
|
self.imgH = imgH
|
||||||
|
self.imgW = imgW
|
||||||
|
self.keep_ratio = keep_ratio
|
||||||
|
self.min_ratio = min_ratio
|
||||||
|
self.down_sample_scale = down_sample_scale
|
||||||
|
self.mask = mask
|
||||||
|
self.infer_mode = infer_mode
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
imgH = self.imgH
|
||||||
|
imgW = self.imgW
|
||||||
|
images_lr = data["image_lr"]
|
||||||
|
transform2 = ResizeNormalize(
|
||||||
|
(imgW // self.down_sample_scale, imgH // self.down_sample_scale))
|
||||||
|
images_lr = transform2(images_lr)
|
||||||
|
data["img_lr"] = images_lr
|
||||||
|
if self.infer_mode:
|
||||||
|
return data
|
||||||
|
|
||||||
|
images_HR = data["image_hr"]
|
||||||
|
_label_strs = data["label"]
|
||||||
|
transform = ResizeNormalize((imgW, imgH))
|
||||||
|
images_HR = transform(images_HR)
|
||||||
|
data["img_hr"] = images_HR
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
class ResizeNormalize:
|
||||||
|
def __init__(self, size, interpolation=Image.BICUBIC):
|
||||||
|
self.size = size
|
||||||
|
self.interpolation = interpolation
|
||||||
|
|
||||||
|
def __call__(self, img):
|
||||||
|
img = img.resize(self.size, self.interpolation)
|
||||||
|
img_numpy = np.array(img).astype("float32")
|
||||||
|
img_numpy = img_numpy.transpose((2, 0, 1)) / 255
|
||||||
|
return img_numpy
|
||||||
|
|
||||||
|
|
||||||
|
class GrayImageChannelFormat:
|
||||||
|
"""
|
||||||
|
format gray scale image's channel: (3,h,w) -> (1,h,w)
|
||||||
|
Args:
|
||||||
|
inverse: inverse gray image
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, inverse=False, **kwargs):
|
||||||
|
self.inverse = inverse
|
||||||
|
|
||||||
|
def __call__(self, data):
|
||||||
|
img = data['image']
|
||||||
|
img_single_channel = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
|
||||||
|
img_expanded = np.expand_dims(img_single_channel, 0)
|
||||||
|
|
||||||
|
if self.inverse:
|
||||||
|
data['image'] = np.abs(img_expanded - 1)
|
||||||
|
else:
|
||||||
|
data['image'] = img_expanded
|
||||||
|
|
||||||
|
data['src_image'] = img
|
||||||
|
return data
|
||||||
|
|
||||||
|
|
||||||
|
class Permute:
|
||||||
|
"""permute image
|
||||||
|
Args:
|
||||||
|
to_bgr (bool): whether convert RGB to BGR
|
||||||
|
channel_first (bool): whether convert HWC to CHW
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, ):
|
||||||
|
super(Permute, self).__init__()
|
||||||
|
|
||||||
|
def __call__(self, im, im_info):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
im (np.ndarray): image (np.ndarray)
|
||||||
|
im_info (dict): info of image
|
||||||
|
Returns:
|
||||||
|
im (np.ndarray): processed image (np.ndarray)
|
||||||
|
im_info (dict): info of processed image
|
||||||
|
"""
|
||||||
|
im = im.transpose((2, 0, 1)).copy()
|
||||||
|
return im, im_info
|
||||||
|
|
||||||
|
|
||||||
|
class PadStride:
|
||||||
|
""" padding image for model with FPN, instead PadBatch(pad_to_stride) in original config
|
||||||
|
Args:
|
||||||
|
stride (bool): model with FPN need image shape % stride == 0
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, stride=0):
|
||||||
|
self.coarsest_stride = stride
|
||||||
|
|
||||||
|
def __call__(self, im, im_info):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
im (np.ndarray): image (np.ndarray)
|
||||||
|
im_info (dict): info of image
|
||||||
|
Returns:
|
||||||
|
im (np.ndarray): processed image (np.ndarray)
|
||||||
|
im_info (dict): info of processed image
|
||||||
|
"""
|
||||||
|
coarsest_stride = self.coarsest_stride
|
||||||
|
if coarsest_stride <= 0:
|
||||||
|
return im, im_info
|
||||||
|
im_c, im_h, im_w = im.shape
|
||||||
|
pad_h = int(np.ceil(float(im_h) / coarsest_stride) * coarsest_stride)
|
||||||
|
pad_w = int(np.ceil(float(im_w) / coarsest_stride) * coarsest_stride)
|
||||||
|
padding_im = np.zeros((im_c, pad_h, pad_w), dtype=np.float32)
|
||||||
|
padding_im[:, :im_h, :im_w] = im
|
||||||
|
return padding_im, im_info
|
||||||
|
|
||||||
|
|
||||||
|
def decode_image(im_file, im_info):
|
||||||
|
"""read rgb image
|
||||||
|
Args:
|
||||||
|
im_file (str|np.ndarray): input can be image path or np.ndarray
|
||||||
|
im_info (dict): info of image
|
||||||
|
Returns:
|
||||||
|
im (np.ndarray): processed image (np.ndarray)
|
||||||
|
im_info (dict): info of processed image
|
||||||
|
"""
|
||||||
|
if isinstance(im_file, str):
|
||||||
|
with open(im_file, 'rb') as f:
|
||||||
|
im_read = f.read()
|
||||||
|
data = np.frombuffer(im_read, dtype='uint8')
|
||||||
|
im = cv2.imdecode(data, 1) # BGR mode, but need RGB mode
|
||||||
|
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
|
||||||
|
else:
|
||||||
|
im = im_file
|
||||||
|
im_info['im_shape'] = np.array(im.shape[:2], dtype=np.float32)
|
||||||
|
im_info['scale_factor'] = np.array([1., 1.], dtype=np.float32)
|
||||||
|
return im, im_info
|
||||||
|
|
||||||
|
|
||||||
|
def preprocess(im, preprocess_ops):
|
||||||
|
# process image by preprocess_ops
|
||||||
|
im_info = {
|
||||||
|
'scale_factor': np.array(
|
||||||
|
[1., 1.], dtype=np.float32),
|
||||||
|
'im_shape': None,
|
||||||
|
}
|
||||||
|
im, im_info = decode_image(im, im_info)
|
||||||
|
for operator in preprocess_ops:
|
||||||
|
im, im_info = operator(im, im_info)
|
||||||
|
return im, im_info
|
||||||
|
|
||||||
|
|
||||||
|
def nms(bboxes, scores, iou_thresh):
|
||||||
|
import numpy as np
|
||||||
|
x1 = bboxes[:, 0]
|
||||||
|
y1 = bboxes[:, 1]
|
||||||
|
x2 = bboxes[:, 2]
|
||||||
|
y2 = bboxes[:, 3]
|
||||||
|
areas = (y2 - y1) * (x2 - x1)
|
||||||
|
|
||||||
|
indices = []
|
||||||
|
index = scores.argsort()[::-1]
|
||||||
|
while index.size > 0:
|
||||||
|
i = index[0]
|
||||||
|
indices.append(i)
|
||||||
|
x11 = np.maximum(x1[i], x1[index[1:]])
|
||||||
|
y11 = np.maximum(y1[i], y1[index[1:]])
|
||||||
|
x22 = np.minimum(x2[i], x2[index[1:]])
|
||||||
|
y22 = np.minimum(y2[i], y2[index[1:]])
|
||||||
|
w = np.maximum(0, x22 - x11 + 1)
|
||||||
|
h = np.maximum(0, y22 - y11 + 1)
|
||||||
|
overlaps = w * h
|
||||||
|
ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)
|
||||||
|
idx = np.where(ious <= iou_thresh)[0]
|
||||||
|
index = index[idx + 1]
|
||||||
|
return indices
|
||||||
370
deepdoc/vision/postprocess.py
Normal file
370
deepdoc/vision/postprocess.py
Normal file
@@ -0,0 +1,370 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import copy
|
||||||
|
import re
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
from shapely.geometry import Polygon
|
||||||
|
import pyclipper
|
||||||
|
|
||||||
|
|
||||||
|
def build_post_process(config, global_config=None):
|
||||||
|
support_dict = {'DBPostProcess': DBPostProcess, 'CTCLabelDecode': CTCLabelDecode}
|
||||||
|
|
||||||
|
config = copy.deepcopy(config)
|
||||||
|
module_name = config.pop('name')
|
||||||
|
if module_name == "None":
|
||||||
|
return
|
||||||
|
if global_config is not None:
|
||||||
|
config.update(global_config)
|
||||||
|
module_class = support_dict.get(module_name)
|
||||||
|
if module_class is None:
|
||||||
|
raise ValueError(
|
||||||
|
'post process only support {}'.format(list(support_dict)))
|
||||||
|
return module_class(**config)
|
||||||
|
|
||||||
|
|
||||||
|
class DBPostProcess:
|
||||||
|
"""
|
||||||
|
The post process for Differentiable Binarization (DB).
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
thresh=0.3,
|
||||||
|
box_thresh=0.7,
|
||||||
|
max_candidates=1000,
|
||||||
|
unclip_ratio=2.0,
|
||||||
|
use_dilation=False,
|
||||||
|
score_mode="fast",
|
||||||
|
box_type='quad',
|
||||||
|
**kwargs):
|
||||||
|
self.thresh = thresh
|
||||||
|
self.box_thresh = box_thresh
|
||||||
|
self.max_candidates = max_candidates
|
||||||
|
self.unclip_ratio = unclip_ratio
|
||||||
|
self.min_size = 3
|
||||||
|
self.score_mode = score_mode
|
||||||
|
self.box_type = box_type
|
||||||
|
assert score_mode in [
|
||||||
|
"slow", "fast"
|
||||||
|
], "Score mode must be in [slow, fast] but got: {}".format(score_mode)
|
||||||
|
|
||||||
|
self.dilation_kernel = None if not use_dilation else np.array(
|
||||||
|
[[1, 1], [1, 1]])
|
||||||
|
|
||||||
|
def polygons_from_bitmap(self, pred, _bitmap, dest_width, dest_height):
|
||||||
|
'''
|
||||||
|
_bitmap: single map with shape (1, H, W),
|
||||||
|
whose values are binarized as {0, 1}
|
||||||
|
'''
|
||||||
|
|
||||||
|
bitmap = _bitmap
|
||||||
|
height, width = bitmap.shape
|
||||||
|
|
||||||
|
boxes = []
|
||||||
|
scores = []
|
||||||
|
|
||||||
|
contours, _ = cv2.findContours((bitmap * 255).astype(np.uint8),
|
||||||
|
cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
|
||||||
|
|
||||||
|
for contour in contours[:self.max_candidates]:
|
||||||
|
epsilon = 0.002 * cv2.arcLength(contour, True)
|
||||||
|
approx = cv2.approxPolyDP(contour, epsilon, True)
|
||||||
|
points = approx.reshape((-1, 2))
|
||||||
|
if points.shape[0] < 4:
|
||||||
|
continue
|
||||||
|
|
||||||
|
score = self.box_score_fast(pred, points.reshape(-1, 2))
|
||||||
|
if self.box_thresh > score:
|
||||||
|
continue
|
||||||
|
|
||||||
|
if points.shape[0] > 2:
|
||||||
|
box = self.unclip(points, self.unclip_ratio)
|
||||||
|
if len(box) > 1:
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
continue
|
||||||
|
box = box.reshape(-1, 2)
|
||||||
|
|
||||||
|
_, sside = self.get_mini_boxes(box.reshape((-1, 1, 2)))
|
||||||
|
if sside < self.min_size + 2:
|
||||||
|
continue
|
||||||
|
|
||||||
|
box = np.array(box)
|
||||||
|
box[:, 0] = np.clip(
|
||||||
|
np.round(box[:, 0] / width * dest_width), 0, dest_width)
|
||||||
|
box[:, 1] = np.clip(
|
||||||
|
np.round(box[:, 1] / height * dest_height), 0, dest_height)
|
||||||
|
boxes.append(box.tolist())
|
||||||
|
scores.append(score)
|
||||||
|
return boxes, scores
|
||||||
|
|
||||||
|
def boxes_from_bitmap(self, pred, _bitmap, dest_width, dest_height):
|
||||||
|
'''
|
||||||
|
_bitmap: single map with shape (1, H, W),
|
||||||
|
whose values are binarized as {0, 1}
|
||||||
|
'''
|
||||||
|
|
||||||
|
bitmap = _bitmap
|
||||||
|
height, width = bitmap.shape
|
||||||
|
|
||||||
|
outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST,
|
||||||
|
cv2.CHAIN_APPROX_SIMPLE)
|
||||||
|
if len(outs) == 3:
|
||||||
|
_img, contours, _ = outs[0], outs[1], outs[2]
|
||||||
|
elif len(outs) == 2:
|
||||||
|
contours, _ = outs[0], outs[1]
|
||||||
|
|
||||||
|
num_contours = min(len(contours), self.max_candidates)
|
||||||
|
|
||||||
|
boxes = []
|
||||||
|
scores = []
|
||||||
|
for index in range(num_contours):
|
||||||
|
contour = contours[index]
|
||||||
|
points, sside = self.get_mini_boxes(contour)
|
||||||
|
if sside < self.min_size:
|
||||||
|
continue
|
||||||
|
points = np.array(points)
|
||||||
|
if self.score_mode == "fast":
|
||||||
|
score = self.box_score_fast(pred, points.reshape(-1, 2))
|
||||||
|
else:
|
||||||
|
score = self.box_score_slow(pred, contour)
|
||||||
|
if self.box_thresh > score:
|
||||||
|
continue
|
||||||
|
|
||||||
|
box = self.unclip(points, self.unclip_ratio).reshape(-1, 1, 2)
|
||||||
|
box, sside = self.get_mini_boxes(box)
|
||||||
|
if sside < self.min_size + 2:
|
||||||
|
continue
|
||||||
|
box = np.array(box)
|
||||||
|
|
||||||
|
box[:, 0] = np.clip(
|
||||||
|
np.round(box[:, 0] / width * dest_width), 0, dest_width)
|
||||||
|
box[:, 1] = np.clip(
|
||||||
|
np.round(box[:, 1] / height * dest_height), 0, dest_height)
|
||||||
|
boxes.append(box.astype("int32"))
|
||||||
|
scores.append(score)
|
||||||
|
return np.array(boxes, dtype="int32"), scores
|
||||||
|
|
||||||
|
def unclip(self, box, unclip_ratio):
|
||||||
|
poly = Polygon(box)
|
||||||
|
distance = poly.area * unclip_ratio / poly.length
|
||||||
|
offset = pyclipper.PyclipperOffset()
|
||||||
|
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
|
||||||
|
expanded = np.array(offset.Execute(distance))
|
||||||
|
return expanded
|
||||||
|
|
||||||
|
def get_mini_boxes(self, contour):
|
||||||
|
bounding_box = cv2.minAreaRect(contour)
|
||||||
|
points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
|
||||||
|
|
||||||
|
index_1, index_2, index_3, index_4 = 0, 1, 2, 3
|
||||||
|
if points[1][1] > points[0][1]:
|
||||||
|
index_1 = 0
|
||||||
|
index_4 = 1
|
||||||
|
else:
|
||||||
|
index_1 = 1
|
||||||
|
index_4 = 0
|
||||||
|
if points[3][1] > points[2][1]:
|
||||||
|
index_2 = 2
|
||||||
|
index_3 = 3
|
||||||
|
else:
|
||||||
|
index_2 = 3
|
||||||
|
index_3 = 2
|
||||||
|
|
||||||
|
box = [
|
||||||
|
points[index_1], points[index_2], points[index_3], points[index_4]
|
||||||
|
]
|
||||||
|
return box, min(bounding_box[1])
|
||||||
|
|
||||||
|
def box_score_fast(self, bitmap, _box):
|
||||||
|
'''
|
||||||
|
box_score_fast: use bbox mean score as the mean score
|
||||||
|
'''
|
||||||
|
h, w = bitmap.shape[:2]
|
||||||
|
box = _box.copy()
|
||||||
|
xmin = np.clip(np.floor(box[:, 0].min()).astype("int32"), 0, w - 1)
|
||||||
|
xmax = np.clip(np.ceil(box[:, 0].max()).astype("int32"), 0, w - 1)
|
||||||
|
ymin = np.clip(np.floor(box[:, 1].min()).astype("int32"), 0, h - 1)
|
||||||
|
ymax = np.clip(np.ceil(box[:, 1].max()).astype("int32"), 0, h - 1)
|
||||||
|
|
||||||
|
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
|
||||||
|
box[:, 0] = box[:, 0] - xmin
|
||||||
|
box[:, 1] = box[:, 1] - ymin
|
||||||
|
cv2.fillPoly(mask, box.reshape(1, -1, 2).astype("int32"), 1)
|
||||||
|
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
|
||||||
|
|
||||||
|
def box_score_slow(self, bitmap, contour):
|
||||||
|
'''
|
||||||
|
box_score_slow: use polyon mean score as the mean score
|
||||||
|
'''
|
||||||
|
h, w = bitmap.shape[:2]
|
||||||
|
contour = contour.copy()
|
||||||
|
contour = np.reshape(contour, (-1, 2))
|
||||||
|
|
||||||
|
xmin = np.clip(np.min(contour[:, 0]), 0, w - 1)
|
||||||
|
xmax = np.clip(np.max(contour[:, 0]), 0, w - 1)
|
||||||
|
ymin = np.clip(np.min(contour[:, 1]), 0, h - 1)
|
||||||
|
ymax = np.clip(np.max(contour[:, 1]), 0, h - 1)
|
||||||
|
|
||||||
|
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
|
||||||
|
|
||||||
|
contour[:, 0] = contour[:, 0] - xmin
|
||||||
|
contour[:, 1] = contour[:, 1] - ymin
|
||||||
|
|
||||||
|
cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype("int32"), 1)
|
||||||
|
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
|
||||||
|
|
||||||
|
def __call__(self, outs_dict, shape_list):
|
||||||
|
pred = outs_dict['maps']
|
||||||
|
if not isinstance(pred, np.ndarray):
|
||||||
|
pred = pred.numpy()
|
||||||
|
pred = pred[:, 0, :, :]
|
||||||
|
segmentation = pred > self.thresh
|
||||||
|
|
||||||
|
boxes_batch = []
|
||||||
|
for batch_index in range(pred.shape[0]):
|
||||||
|
src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
|
||||||
|
if self.dilation_kernel is not None:
|
||||||
|
mask = cv2.dilate(
|
||||||
|
np.array(segmentation[batch_index]).astype(np.uint8),
|
||||||
|
self.dilation_kernel)
|
||||||
|
else:
|
||||||
|
mask = segmentation[batch_index]
|
||||||
|
if self.box_type == 'poly':
|
||||||
|
boxes, scores = self.polygons_from_bitmap(pred[batch_index],
|
||||||
|
mask, src_w, src_h)
|
||||||
|
elif self.box_type == 'quad':
|
||||||
|
boxes, scores = self.boxes_from_bitmap(pred[batch_index], mask,
|
||||||
|
src_w, src_h)
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
"box_type can only be one of ['quad', 'poly']")
|
||||||
|
|
||||||
|
boxes_batch.append({'points': boxes})
|
||||||
|
return boxes_batch
|
||||||
|
|
||||||
|
|
||||||
|
class BaseRecLabelDecode:
|
||||||
|
""" Convert between text-label and text-index """
|
||||||
|
|
||||||
|
def __init__(self, character_dict_path=None, use_space_char=False):
|
||||||
|
self.beg_str = "sos"
|
||||||
|
self.end_str = "eos"
|
||||||
|
self.reverse = False
|
||||||
|
self.character_str = []
|
||||||
|
|
||||||
|
if character_dict_path is None:
|
||||||
|
self.character_str = "0123456789abcdefghijklmnopqrstuvwxyz"
|
||||||
|
dict_character = list(self.character_str)
|
||||||
|
else:
|
||||||
|
with open(character_dict_path, "rb") as fin:
|
||||||
|
lines = fin.readlines()
|
||||||
|
for line in lines:
|
||||||
|
line = line.decode('utf-8').strip("\n").strip("\r\n")
|
||||||
|
self.character_str.append(line)
|
||||||
|
if use_space_char:
|
||||||
|
self.character_str.append(" ")
|
||||||
|
dict_character = list(self.character_str)
|
||||||
|
if 'arabic' in character_dict_path:
|
||||||
|
self.reverse = True
|
||||||
|
|
||||||
|
dict_character = self.add_special_char(dict_character)
|
||||||
|
self.dict = {}
|
||||||
|
for i, char in enumerate(dict_character):
|
||||||
|
self.dict[char] = i
|
||||||
|
self.character = dict_character
|
||||||
|
|
||||||
|
def pred_reverse(self, pred):
|
||||||
|
pred_re = []
|
||||||
|
c_current = ''
|
||||||
|
for c in pred:
|
||||||
|
if not bool(re.search('[a-zA-Z0-9 :*./%+-]', c)):
|
||||||
|
if c_current != '':
|
||||||
|
pred_re.append(c_current)
|
||||||
|
pred_re.append(c)
|
||||||
|
c_current = ''
|
||||||
|
else:
|
||||||
|
c_current += c
|
||||||
|
if c_current != '':
|
||||||
|
pred_re.append(c_current)
|
||||||
|
|
||||||
|
return ''.join(pred_re[::-1])
|
||||||
|
|
||||||
|
def add_special_char(self, dict_character):
|
||||||
|
return dict_character
|
||||||
|
|
||||||
|
def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
|
||||||
|
""" convert text-index into text-label. """
|
||||||
|
result_list = []
|
||||||
|
ignored_tokens = self.get_ignored_tokens()
|
||||||
|
batch_size = len(text_index)
|
||||||
|
for batch_idx in range(batch_size):
|
||||||
|
selection = np.ones(len(text_index[batch_idx]), dtype=bool)
|
||||||
|
if is_remove_duplicate:
|
||||||
|
selection[1:] = text_index[batch_idx][1:] != text_index[
|
||||||
|
batch_idx][:-1]
|
||||||
|
for ignored_token in ignored_tokens:
|
||||||
|
selection &= text_index[batch_idx] != ignored_token
|
||||||
|
|
||||||
|
char_list = [
|
||||||
|
self.character[text_id]
|
||||||
|
for text_id in text_index[batch_idx][selection]
|
||||||
|
]
|
||||||
|
if text_prob is not None:
|
||||||
|
conf_list = text_prob[batch_idx][selection]
|
||||||
|
else:
|
||||||
|
conf_list = [1] * len(selection)
|
||||||
|
if len(conf_list) == 0:
|
||||||
|
conf_list = [0]
|
||||||
|
|
||||||
|
text = ''.join(char_list)
|
||||||
|
|
||||||
|
if self.reverse: # for arabic rec
|
||||||
|
text = self.pred_reverse(text)
|
||||||
|
|
||||||
|
result_list.append((text, np.mean(conf_list).tolist()))
|
||||||
|
return result_list
|
||||||
|
|
||||||
|
def get_ignored_tokens(self):
|
||||||
|
return [0] # for ctc blank
|
||||||
|
|
||||||
|
|
||||||
|
class CTCLabelDecode(BaseRecLabelDecode):
|
||||||
|
""" Convert between text-label and text-index """
|
||||||
|
|
||||||
|
def __init__(self, character_dict_path=None, use_space_char=False,
|
||||||
|
**kwargs):
|
||||||
|
super(CTCLabelDecode, self).__init__(character_dict_path,
|
||||||
|
use_space_char)
|
||||||
|
|
||||||
|
def __call__(self, preds, label=None, *args, **kwargs):
|
||||||
|
if isinstance(preds, tuple) or isinstance(preds, list):
|
||||||
|
preds = preds[-1]
|
||||||
|
if not isinstance(preds, np.ndarray):
|
||||||
|
preds = preds.numpy()
|
||||||
|
preds_idx = preds.argmax(axis=2)
|
||||||
|
preds_prob = preds.max(axis=2)
|
||||||
|
text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
|
||||||
|
if label is None:
|
||||||
|
return text
|
||||||
|
label = self.decode(label)
|
||||||
|
return text, label
|
||||||
|
|
||||||
|
def add_special_char(self, dict_character):
|
||||||
|
dict_character = ['blank'] + dict_character
|
||||||
|
return dict_character
|
||||||
442
deepdoc/vision/recognizer.py
Normal file
442
deepdoc/vision/recognizer.py
Normal file
@@ -0,0 +1,442 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
import gc
|
||||||
|
import logging
|
||||||
|
import os
|
||||||
|
import math
|
||||||
|
import numpy as np
|
||||||
|
import cv2
|
||||||
|
from functools import cmp_to_key
|
||||||
|
|
||||||
|
|
||||||
|
from api.utils.file_utils import get_project_base_directory
|
||||||
|
from .operators import * # noqa: F403
|
||||||
|
from .operators import preprocess
|
||||||
|
from . import operators
|
||||||
|
from .ocr import load_model
|
||||||
|
|
||||||
|
class Recognizer:
|
||||||
|
def __init__(self, label_list, task_name, model_dir=None):
|
||||||
|
"""
|
||||||
|
If you have trouble downloading HuggingFace models, -_^ this might help!!
|
||||||
|
|
||||||
|
For Linux:
|
||||||
|
export HF_ENDPOINT=https://hf-mirror.com
|
||||||
|
|
||||||
|
For Windows:
|
||||||
|
Good luck
|
||||||
|
^_-
|
||||||
|
|
||||||
|
"""
|
||||||
|
if not model_dir:
|
||||||
|
model_dir = os.path.join(
|
||||||
|
get_project_base_directory(),
|
||||||
|
"rag/res/deepdoc")
|
||||||
|
self.ort_sess, self.run_options = load_model(model_dir, task_name)
|
||||||
|
self.input_names = [node.name for node in self.ort_sess.get_inputs()]
|
||||||
|
self.output_names = [node.name for node in self.ort_sess.get_outputs()]
|
||||||
|
self.input_shape = self.ort_sess.get_inputs()[0].shape[2:4]
|
||||||
|
self.label_list = label_list
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def sort_Y_firstly(arr, threshold):
|
||||||
|
def cmp(c1, c2):
|
||||||
|
diff = c1["top"] - c2["top"]
|
||||||
|
if abs(diff) < threshold:
|
||||||
|
diff = c1["x0"] - c2["x0"]
|
||||||
|
return diff
|
||||||
|
arr = sorted(arr, key=cmp_to_key(cmp))
|
||||||
|
return arr
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def sort_X_firstly(arr, threshold):
|
||||||
|
def cmp(c1, c2):
|
||||||
|
diff = c1["x0"] - c2["x0"]
|
||||||
|
if abs(diff) < threshold:
|
||||||
|
diff = c1["top"] - c2["top"]
|
||||||
|
return diff
|
||||||
|
arr = sorted(arr, key=cmp_to_key(cmp))
|
||||||
|
return arr
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def sort_C_firstly(arr, thr=0):
|
||||||
|
# sort using y1 first and then x1
|
||||||
|
# sorted(arr, key=lambda r: (r["x0"], r["top"]))
|
||||||
|
arr = Recognizer.sort_X_firstly(arr, thr)
|
||||||
|
for i in range(len(arr) - 1):
|
||||||
|
for j in range(i, -1, -1):
|
||||||
|
# restore the order using th
|
||||||
|
if "C" not in arr[j] or "C" not in arr[j + 1]:
|
||||||
|
continue
|
||||||
|
if arr[j + 1]["C"] < arr[j]["C"] \
|
||||||
|
or (
|
||||||
|
arr[j + 1]["C"] == arr[j]["C"]
|
||||||
|
and arr[j + 1]["top"] < arr[j]["top"]
|
||||||
|
):
|
||||||
|
tmp = arr[j]
|
||||||
|
arr[j] = arr[j + 1]
|
||||||
|
arr[j + 1] = tmp
|
||||||
|
return arr
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def sort_R_firstly(arr, thr=0):
|
||||||
|
# sort using y1 first and then x1
|
||||||
|
# sorted(arr, key=lambda r: (r["top"], r["x0"]))
|
||||||
|
arr = Recognizer.sort_Y_firstly(arr, thr)
|
||||||
|
for i in range(len(arr) - 1):
|
||||||
|
for j in range(i, -1, -1):
|
||||||
|
if "R" not in arr[j] or "R" not in arr[j + 1]:
|
||||||
|
continue
|
||||||
|
if arr[j + 1]["R"] < arr[j]["R"] \
|
||||||
|
or (
|
||||||
|
arr[j + 1]["R"] == arr[j]["R"]
|
||||||
|
and arr[j + 1]["x0"] < arr[j]["x0"]
|
||||||
|
):
|
||||||
|
tmp = arr[j]
|
||||||
|
arr[j] = arr[j + 1]
|
||||||
|
arr[j + 1] = tmp
|
||||||
|
return arr
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def overlapped_area(a, b, ratio=True):
|
||||||
|
tp, btm, x0, x1 = a["top"], a["bottom"], a["x0"], a["x1"]
|
||||||
|
if b["x0"] > x1 or b["x1"] < x0:
|
||||||
|
return 0
|
||||||
|
if b["bottom"] < tp or b["top"] > btm:
|
||||||
|
return 0
|
||||||
|
x0_ = max(b["x0"], x0)
|
||||||
|
x1_ = min(b["x1"], x1)
|
||||||
|
assert x0_ <= x1_, "Bbox mismatch! T:{},B:{},X0:{},X1:{} ==> {}".format(
|
||||||
|
tp, btm, x0, x1, b)
|
||||||
|
tp_ = max(b["top"], tp)
|
||||||
|
btm_ = min(b["bottom"], btm)
|
||||||
|
assert tp_ <= btm_, "Bbox mismatch! T:{},B:{},X0:{},X1:{} => {}".format(
|
||||||
|
tp, btm, x0, x1, b)
|
||||||
|
ov = (btm_ - tp_) * (x1_ - x0_) if x1 - \
|
||||||
|
x0 != 0 and btm - tp != 0 else 0
|
||||||
|
if ov > 0 and ratio:
|
||||||
|
ov /= (x1 - x0) * (btm - tp)
|
||||||
|
return ov
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def layouts_cleanup(boxes, layouts, far=2, thr=0.7):
|
||||||
|
def not_overlapped(a, b):
|
||||||
|
return any([a["x1"] < b["x0"],
|
||||||
|
a["x0"] > b["x1"],
|
||||||
|
a["bottom"] < b["top"],
|
||||||
|
a["top"] > b["bottom"]])
|
||||||
|
|
||||||
|
i = 0
|
||||||
|
while i + 1 < len(layouts):
|
||||||
|
j = i + 1
|
||||||
|
while j < min(i + far, len(layouts)) \
|
||||||
|
and (layouts[i].get("type", "") != layouts[j].get("type", "")
|
||||||
|
or not_overlapped(layouts[i], layouts[j])):
|
||||||
|
j += 1
|
||||||
|
if j >= min(i + far, len(layouts)):
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
if Recognizer.overlapped_area(layouts[i], layouts[j]) < thr \
|
||||||
|
and Recognizer.overlapped_area(layouts[j], layouts[i]) < thr:
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
if layouts[i].get("score") and layouts[j].get("score"):
|
||||||
|
if layouts[i]["score"] > layouts[j]["score"]:
|
||||||
|
layouts.pop(j)
|
||||||
|
else:
|
||||||
|
layouts.pop(i)
|
||||||
|
continue
|
||||||
|
|
||||||
|
area_i, area_i_1 = 0, 0
|
||||||
|
for b in boxes:
|
||||||
|
if not not_overlapped(b, layouts[i]):
|
||||||
|
area_i += Recognizer.overlapped_area(b, layouts[i], False)
|
||||||
|
if not not_overlapped(b, layouts[j]):
|
||||||
|
area_i_1 += Recognizer.overlapped_area(b, layouts[j], False)
|
||||||
|
|
||||||
|
if area_i > area_i_1:
|
||||||
|
layouts.pop(j)
|
||||||
|
else:
|
||||||
|
layouts.pop(i)
|
||||||
|
|
||||||
|
return layouts
|
||||||
|
|
||||||
|
def create_inputs(self, imgs, im_info):
|
||||||
|
"""generate input for different model type
|
||||||
|
Args:
|
||||||
|
imgs (list(numpy)): list of images (np.ndarray)
|
||||||
|
im_info (list(dict)): list of image info
|
||||||
|
Returns:
|
||||||
|
inputs (dict): input of model
|
||||||
|
"""
|
||||||
|
inputs = {}
|
||||||
|
|
||||||
|
im_shape = []
|
||||||
|
scale_factor = []
|
||||||
|
if len(imgs) == 1:
|
||||||
|
inputs['image'] = np.array((imgs[0],)).astype('float32')
|
||||||
|
inputs['im_shape'] = np.array(
|
||||||
|
(im_info[0]['im_shape'],)).astype('float32')
|
||||||
|
inputs['scale_factor'] = np.array(
|
||||||
|
(im_info[0]['scale_factor'],)).astype('float32')
|
||||||
|
return inputs
|
||||||
|
|
||||||
|
im_shape = np.array([info['im_shape'] for info in im_info], dtype='float32')
|
||||||
|
scale_factor = np.array([info['scale_factor'] for info in im_info], dtype='float32')
|
||||||
|
|
||||||
|
inputs['im_shape'] = np.concatenate(im_shape, axis=0)
|
||||||
|
inputs['scale_factor'] = np.concatenate(scale_factor, axis=0)
|
||||||
|
|
||||||
|
imgs_shape = [[e.shape[1], e.shape[2]] for e in imgs]
|
||||||
|
max_shape_h = max([e[0] for e in imgs_shape])
|
||||||
|
max_shape_w = max([e[1] for e in imgs_shape])
|
||||||
|
padding_imgs = []
|
||||||
|
for img in imgs:
|
||||||
|
im_c, im_h, im_w = img.shape[:]
|
||||||
|
padding_im = np.zeros(
|
||||||
|
(im_c, max_shape_h, max_shape_w), dtype=np.float32)
|
||||||
|
padding_im[:, :im_h, :im_w] = img
|
||||||
|
padding_imgs.append(padding_im)
|
||||||
|
inputs['image'] = np.stack(padding_imgs, axis=0)
|
||||||
|
return inputs
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def find_overlapped(box, boxes_sorted_by_y, naive=False):
|
||||||
|
if not boxes_sorted_by_y:
|
||||||
|
return
|
||||||
|
bxs = boxes_sorted_by_y
|
||||||
|
s, e, ii = 0, len(bxs), 0
|
||||||
|
while s < e and not naive:
|
||||||
|
ii = (e + s) // 2
|
||||||
|
pv = bxs[ii]
|
||||||
|
if box["bottom"] < pv["top"]:
|
||||||
|
e = ii
|
||||||
|
continue
|
||||||
|
if box["top"] > pv["bottom"]:
|
||||||
|
s = ii + 1
|
||||||
|
continue
|
||||||
|
break
|
||||||
|
while s < ii:
|
||||||
|
if box["top"] > bxs[s]["bottom"]:
|
||||||
|
s += 1
|
||||||
|
break
|
||||||
|
while e - 1 > ii:
|
||||||
|
if box["bottom"] < bxs[e - 1]["top"]:
|
||||||
|
e -= 1
|
||||||
|
break
|
||||||
|
|
||||||
|
max_overlapped_i, max_overlapped = None, 0
|
||||||
|
for i in range(s, e):
|
||||||
|
ov = Recognizer.overlapped_area(bxs[i], box)
|
||||||
|
if ov <= max_overlapped:
|
||||||
|
continue
|
||||||
|
max_overlapped_i = i
|
||||||
|
max_overlapped = ov
|
||||||
|
|
||||||
|
return max_overlapped_i
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def find_horizontally_tightest_fit(box, boxes):
|
||||||
|
if not boxes:
|
||||||
|
return
|
||||||
|
min_dis, min_i = 1000000, None
|
||||||
|
for i,b in enumerate(boxes):
|
||||||
|
if box.get("layoutno", "0") != b.get("layoutno", "0"):
|
||||||
|
continue
|
||||||
|
dis = min(abs(box["x0"] - b["x0"]), abs(box["x1"] - b["x1"]), abs(box["x0"]+box["x1"] - b["x1"] - b["x0"])/2)
|
||||||
|
if dis < min_dis:
|
||||||
|
min_i = i
|
||||||
|
min_dis = dis
|
||||||
|
return min_i
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def find_overlapped_with_threshold(box, boxes, thr=0.3):
|
||||||
|
if not boxes:
|
||||||
|
return
|
||||||
|
max_overlapped_i, max_overlapped, _max_overlapped = None, thr, 0
|
||||||
|
s, e = 0, len(boxes)
|
||||||
|
for i in range(s, e):
|
||||||
|
ov = Recognizer.overlapped_area(box, boxes[i])
|
||||||
|
_ov = Recognizer.overlapped_area(boxes[i], box)
|
||||||
|
if (ov, _ov) < (max_overlapped, _max_overlapped):
|
||||||
|
continue
|
||||||
|
max_overlapped_i = i
|
||||||
|
max_overlapped = ov
|
||||||
|
_max_overlapped = _ov
|
||||||
|
|
||||||
|
return max_overlapped_i
|
||||||
|
|
||||||
|
def preprocess(self, image_list):
|
||||||
|
inputs = []
|
||||||
|
if "scale_factor" in self.input_names:
|
||||||
|
preprocess_ops = []
|
||||||
|
for op_info in [
|
||||||
|
{'interp': 2, 'keep_ratio': False, 'target_size': [800, 608], 'type': 'LinearResize'},
|
||||||
|
{'is_scale': True, 'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225], 'type': 'StandardizeImage'},
|
||||||
|
{'type': 'Permute'},
|
||||||
|
{'stride': 32, 'type': 'PadStride'}
|
||||||
|
]:
|
||||||
|
new_op_info = op_info.copy()
|
||||||
|
op_type = new_op_info.pop('type')
|
||||||
|
preprocess_ops.append(getattr(operators, op_type)(**new_op_info))
|
||||||
|
|
||||||
|
for im_path in image_list:
|
||||||
|
im, im_info = preprocess(im_path, preprocess_ops)
|
||||||
|
inputs.append({"image": np.array((im,)).astype('float32'),
|
||||||
|
"scale_factor": np.array((im_info["scale_factor"],)).astype('float32')})
|
||||||
|
else:
|
||||||
|
hh, ww = self.input_shape
|
||||||
|
for img in image_list:
|
||||||
|
h, w = img.shape[:2]
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
||||||
|
img = cv2.resize(np.array(img).astype('float32'), (ww, hh))
|
||||||
|
# Scale input pixel values to 0 to 1
|
||||||
|
img /= 255.0
|
||||||
|
img = img.transpose(2, 0, 1)
|
||||||
|
img = img[np.newaxis, :, :, :].astype(np.float32)
|
||||||
|
inputs.append({self.input_names[0]: img, "scale_factor": [w/ww, h/hh]})
|
||||||
|
return inputs
|
||||||
|
|
||||||
|
def postprocess(self, boxes, inputs, thr):
|
||||||
|
if "scale_factor" in self.input_names:
|
||||||
|
bb = []
|
||||||
|
for b in boxes:
|
||||||
|
clsid, bbox, score = int(b[0]), b[2:], b[1]
|
||||||
|
if score < thr:
|
||||||
|
continue
|
||||||
|
if clsid >= len(self.label_list):
|
||||||
|
continue
|
||||||
|
bb.append({
|
||||||
|
"type": self.label_list[clsid].lower(),
|
||||||
|
"bbox": [float(t) for t in bbox.tolist()],
|
||||||
|
"score": float(score)
|
||||||
|
})
|
||||||
|
return bb
|
||||||
|
|
||||||
|
def xywh2xyxy(x):
|
||||||
|
# [x, y, w, h] to [x1, y1, x2, y2]
|
||||||
|
y = np.copy(x)
|
||||||
|
y[:, 0] = x[:, 0] - x[:, 2] / 2
|
||||||
|
y[:, 1] = x[:, 1] - x[:, 3] / 2
|
||||||
|
y[:, 2] = x[:, 0] + x[:, 2] / 2
|
||||||
|
y[:, 3] = x[:, 1] + x[:, 3] / 2
|
||||||
|
return y
|
||||||
|
|
||||||
|
def compute_iou(box, boxes):
|
||||||
|
# Compute xmin, ymin, xmax, ymax for both boxes
|
||||||
|
xmin = np.maximum(box[0], boxes[:, 0])
|
||||||
|
ymin = np.maximum(box[1], boxes[:, 1])
|
||||||
|
xmax = np.minimum(box[2], boxes[:, 2])
|
||||||
|
ymax = np.minimum(box[3], boxes[:, 3])
|
||||||
|
|
||||||
|
# Compute intersection area
|
||||||
|
intersection_area = np.maximum(0, xmax - xmin) * np.maximum(0, ymax - ymin)
|
||||||
|
|
||||||
|
# Compute union area
|
||||||
|
box_area = (box[2] - box[0]) * (box[3] - box[1])
|
||||||
|
boxes_area = (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
|
||||||
|
union_area = box_area + boxes_area - intersection_area
|
||||||
|
|
||||||
|
# Compute IoU
|
||||||
|
iou = intersection_area / union_area
|
||||||
|
|
||||||
|
return iou
|
||||||
|
|
||||||
|
def iou_filter(boxes, scores, iou_threshold):
|
||||||
|
sorted_indices = np.argsort(scores)[::-1]
|
||||||
|
|
||||||
|
keep_boxes = []
|
||||||
|
while sorted_indices.size > 0:
|
||||||
|
# Pick the last box
|
||||||
|
box_id = sorted_indices[0]
|
||||||
|
keep_boxes.append(box_id)
|
||||||
|
|
||||||
|
# Compute IoU of the picked box with the rest
|
||||||
|
ious = compute_iou(boxes[box_id, :], boxes[sorted_indices[1:], :])
|
||||||
|
|
||||||
|
# Remove boxes with IoU over the threshold
|
||||||
|
keep_indices = np.where(ious < iou_threshold)[0]
|
||||||
|
|
||||||
|
# print(keep_indices.shape, sorted_indices.shape)
|
||||||
|
sorted_indices = sorted_indices[keep_indices + 1]
|
||||||
|
|
||||||
|
return keep_boxes
|
||||||
|
|
||||||
|
boxes = np.squeeze(boxes).T
|
||||||
|
# Filter out object confidence scores below threshold
|
||||||
|
scores = np.max(boxes[:, 4:], axis=1)
|
||||||
|
boxes = boxes[scores > thr, :]
|
||||||
|
scores = scores[scores > thr]
|
||||||
|
if len(boxes) == 0:
|
||||||
|
return []
|
||||||
|
|
||||||
|
# Get the class with the highest confidence
|
||||||
|
class_ids = np.argmax(boxes[:, 4:], axis=1)
|
||||||
|
boxes = boxes[:, :4]
|
||||||
|
input_shape = np.array([inputs["scale_factor"][0], inputs["scale_factor"][1], inputs["scale_factor"][0], inputs["scale_factor"][1]])
|
||||||
|
boxes = np.multiply(boxes, input_shape, dtype=np.float32)
|
||||||
|
boxes = xywh2xyxy(boxes)
|
||||||
|
|
||||||
|
unique_class_ids = np.unique(class_ids)
|
||||||
|
indices = []
|
||||||
|
for class_id in unique_class_ids:
|
||||||
|
class_indices = np.where(class_ids == class_id)[0]
|
||||||
|
class_boxes = boxes[class_indices, :]
|
||||||
|
class_scores = scores[class_indices]
|
||||||
|
class_keep_boxes = iou_filter(class_boxes, class_scores, 0.2)
|
||||||
|
indices.extend(class_indices[class_keep_boxes])
|
||||||
|
|
||||||
|
return [{
|
||||||
|
"type": self.label_list[class_ids[i]].lower(),
|
||||||
|
"bbox": [float(t) for t in boxes[i].tolist()],
|
||||||
|
"score": float(scores[i])
|
||||||
|
} for i in indices]
|
||||||
|
|
||||||
|
def close(self):
|
||||||
|
logging.info("Close recognizer.")
|
||||||
|
if hasattr(self, "ort_sess"):
|
||||||
|
del self.ort_sess
|
||||||
|
gc.collect()
|
||||||
|
|
||||||
|
def __call__(self, image_list, thr=0.7, batch_size=16):
|
||||||
|
res = []
|
||||||
|
images = []
|
||||||
|
for i in range(len(image_list)):
|
||||||
|
if not isinstance(image_list[i], np.ndarray):
|
||||||
|
images.append(np.array(image_list[i]))
|
||||||
|
else:
|
||||||
|
images.append(image_list[i])
|
||||||
|
|
||||||
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
|
for i in range(batch_loop_cnt):
|
||||||
|
start_index = i * batch_size
|
||||||
|
end_index = min((i + 1) * batch_size, len(images))
|
||||||
|
batch_image_list = images[start_index:end_index]
|
||||||
|
inputs = self.preprocess(batch_image_list)
|
||||||
|
logging.debug("preprocess")
|
||||||
|
for ins in inputs:
|
||||||
|
bb = self.postprocess(self.ort_sess.run(None, {k:v for k,v in ins.items() if k in self.input_names}, self.run_options)[0], ins, thr)
|
||||||
|
res.append(bb)
|
||||||
|
|
||||||
|
#seeit.save_results(image_list, res, self.label_list, threshold=thr)
|
||||||
|
|
||||||
|
return res
|
||||||
|
|
||||||
|
def __del__(self):
|
||||||
|
self.close()
|
||||||
|
|
||||||
|
|
||||||
87
deepdoc/vision/seeit.py
Normal file
87
deepdoc/vision/seeit.py
Normal file
@@ -0,0 +1,87 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import os
|
||||||
|
import PIL
|
||||||
|
from PIL import ImageDraw
|
||||||
|
|
||||||
|
|
||||||
|
def save_results(image_list, results, labels, output_dir='output/', threshold=0.5):
|
||||||
|
if not os.path.exists(output_dir):
|
||||||
|
os.makedirs(output_dir)
|
||||||
|
for idx, im in enumerate(image_list):
|
||||||
|
im = draw_box(im, results[idx], labels, threshold=threshold)
|
||||||
|
|
||||||
|
out_path = os.path.join(output_dir, f"{idx}.jpg")
|
||||||
|
im.save(out_path, quality=95)
|
||||||
|
logging.debug("save result to: " + out_path)
|
||||||
|
|
||||||
|
|
||||||
|
def draw_box(im, result, labels, threshold=0.5):
|
||||||
|
draw_thickness = min(im.size) // 320
|
||||||
|
draw = ImageDraw.Draw(im)
|
||||||
|
color_list = get_color_map_list(len(labels))
|
||||||
|
clsid2color = {n.lower():color_list[i] for i,n in enumerate(labels)}
|
||||||
|
result = [r for r in result if r["score"] >= threshold]
|
||||||
|
|
||||||
|
for dt in result:
|
||||||
|
color = tuple(clsid2color[dt["type"]])
|
||||||
|
xmin, ymin, xmax, ymax = dt["bbox"]
|
||||||
|
draw.line(
|
||||||
|
[(xmin, ymin), (xmin, ymax), (xmax, ymax), (xmax, ymin),
|
||||||
|
(xmin, ymin)],
|
||||||
|
width=draw_thickness,
|
||||||
|
fill=color)
|
||||||
|
|
||||||
|
# draw label
|
||||||
|
text = "{} {:.4f}".format(dt["type"], dt["score"])
|
||||||
|
tw, th = imagedraw_textsize_c(draw, text)
|
||||||
|
draw.rectangle(
|
||||||
|
[(xmin + 1, ymin - th), (xmin + tw + 1, ymin)], fill=color)
|
||||||
|
draw.text((xmin + 1, ymin - th), text, fill=(255, 255, 255))
|
||||||
|
return im
|
||||||
|
|
||||||
|
|
||||||
|
def get_color_map_list(num_classes):
|
||||||
|
"""
|
||||||
|
Args:
|
||||||
|
num_classes (int): number of class
|
||||||
|
Returns:
|
||||||
|
color_map (list): RGB color list
|
||||||
|
"""
|
||||||
|
color_map = num_classes * [0, 0, 0]
|
||||||
|
for i in range(0, num_classes):
|
||||||
|
j = 0
|
||||||
|
lab = i
|
||||||
|
while lab:
|
||||||
|
color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
|
||||||
|
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
|
||||||
|
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
|
||||||
|
j += 1
|
||||||
|
lab >>= 3
|
||||||
|
color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
|
||||||
|
return color_map
|
||||||
|
|
||||||
|
|
||||||
|
def imagedraw_textsize_c(draw, text):
|
||||||
|
if int(PIL.__version__.split('.')[0]) < 10:
|
||||||
|
tw, th = draw.textsize(text)
|
||||||
|
else:
|
||||||
|
left, top, right, bottom = draw.textbbox((0, 0), text)
|
||||||
|
tw, th = right - left, bottom - top
|
||||||
|
|
||||||
|
return tw, th
|
||||||
93
deepdoc/vision/t_ocr.py
Normal file
93
deepdoc/vision/t_ocr.py
Normal file
@@ -0,0 +1,93 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
sys.path.insert(
|
||||||
|
0,
|
||||||
|
os.path.abspath(
|
||||||
|
os.path.join(
|
||||||
|
os.path.dirname(
|
||||||
|
os.path.abspath(__file__)),
|
||||||
|
'../../')))
|
||||||
|
|
||||||
|
from deepdoc.vision.seeit import draw_box
|
||||||
|
from deepdoc.vision import OCR, init_in_out
|
||||||
|
import argparse
|
||||||
|
import numpy as np
|
||||||
|
import trio
|
||||||
|
|
||||||
|
# os.environ['CUDA_VISIBLE_DEVICES'] = '0,2' #2 gpus, uncontinuous
|
||||||
|
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #1 gpu
|
||||||
|
# os.environ['CUDA_VISIBLE_DEVICES'] = '' #cpu
|
||||||
|
|
||||||
|
|
||||||
|
def main(args):
|
||||||
|
import torch.cuda
|
||||||
|
|
||||||
|
cuda_devices = torch.cuda.device_count()
|
||||||
|
limiter = [trio.CapacityLimiter(1) for _ in range(cuda_devices)] if cuda_devices > 1 else None
|
||||||
|
ocr = OCR()
|
||||||
|
images, outputs = init_in_out(args)
|
||||||
|
|
||||||
|
def __ocr(i, id, img):
|
||||||
|
print("Task {} start".format(i))
|
||||||
|
bxs = ocr(np.array(img), id)
|
||||||
|
bxs = [(line[0], line[1][0]) for line in bxs]
|
||||||
|
bxs = [{
|
||||||
|
"text": t,
|
||||||
|
"bbox": [b[0][0], b[0][1], b[1][0], b[-1][1]],
|
||||||
|
"type": "ocr",
|
||||||
|
"score": 1} for b, t in bxs if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]]
|
||||||
|
img = draw_box(images[i], bxs, ["ocr"], 1.)
|
||||||
|
img.save(outputs[i], quality=95)
|
||||||
|
with open(outputs[i] + ".txt", "w+", encoding='utf-8') as f:
|
||||||
|
f.write("\n".join([o["text"] for o in bxs]))
|
||||||
|
|
||||||
|
print("Task {} done".format(i))
|
||||||
|
|
||||||
|
async def __ocr_thread(i, id, img, limiter = None):
|
||||||
|
if limiter:
|
||||||
|
async with limiter:
|
||||||
|
print("Task {} use device {}".format(i, id))
|
||||||
|
await trio.to_thread.run_sync(lambda: __ocr(i, id, img))
|
||||||
|
else:
|
||||||
|
__ocr(i, id, img)
|
||||||
|
|
||||||
|
async def __ocr_launcher():
|
||||||
|
if cuda_devices > 1:
|
||||||
|
async with trio.open_nursery() as nursery:
|
||||||
|
for i, img in enumerate(images):
|
||||||
|
nursery.start_soon(__ocr_thread, i, i % cuda_devices, img, limiter[i % cuda_devices])
|
||||||
|
await trio.sleep(0.1)
|
||||||
|
else:
|
||||||
|
for i, img in enumerate(images):
|
||||||
|
await __ocr_thread(i, 0, img)
|
||||||
|
|
||||||
|
trio.run(__ocr_launcher)
|
||||||
|
|
||||||
|
print("OCR tasks are all done")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--inputs',
|
||||||
|
help="Directory where to store images or PDFs, or a file path to a single image or PDF",
|
||||||
|
required=True)
|
||||||
|
parser.add_argument('--output_dir', help="Directory where to store the output images. Default: './ocr_outputs'",
|
||||||
|
default="./ocr_outputs")
|
||||||
|
args = parser.parse_args()
|
||||||
|
main(args)
|
||||||
186
deepdoc/vision/t_recognizer.py
Normal file
186
deepdoc/vision/t_recognizer.py
Normal file
@@ -0,0 +1,186 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
|
||||||
|
import logging
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
|
||||||
|
sys.path.insert(
|
||||||
|
0,
|
||||||
|
os.path.abspath(
|
||||||
|
os.path.join(
|
||||||
|
os.path.dirname(
|
||||||
|
os.path.abspath(__file__)),
|
||||||
|
'../../')))
|
||||||
|
|
||||||
|
from deepdoc.vision.seeit import draw_box
|
||||||
|
from deepdoc.vision import LayoutRecognizer, TableStructureRecognizer, OCR, init_in_out
|
||||||
|
import argparse
|
||||||
|
import re
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
|
||||||
|
def main(args):
|
||||||
|
images, outputs = init_in_out(args)
|
||||||
|
if args.mode.lower() == "layout":
|
||||||
|
detr = LayoutRecognizer("layout")
|
||||||
|
layouts = detr.forward(images, thr=float(args.threshold))
|
||||||
|
if args.mode.lower() == "tsr":
|
||||||
|
detr = TableStructureRecognizer()
|
||||||
|
ocr = OCR()
|
||||||
|
layouts = detr(images, thr=float(args.threshold))
|
||||||
|
for i, lyt in enumerate(layouts):
|
||||||
|
if args.mode.lower() == "tsr":
|
||||||
|
#lyt = [t for t in lyt if t["type"] == "table column"]
|
||||||
|
html = get_table_html(images[i], lyt, ocr)
|
||||||
|
with open(outputs[i] + ".html", "w+", encoding='utf-8') as f:
|
||||||
|
f.write(html)
|
||||||
|
lyt = [{
|
||||||
|
"type": t["label"],
|
||||||
|
"bbox": [t["x0"], t["top"], t["x1"], t["bottom"]],
|
||||||
|
"score": t["score"]
|
||||||
|
} for t in lyt]
|
||||||
|
img = draw_box(images[i], lyt, detr.labels, float(args.threshold))
|
||||||
|
img.save(outputs[i], quality=95)
|
||||||
|
logging.info("save result to: " + outputs[i])
|
||||||
|
|
||||||
|
|
||||||
|
def get_table_html(img, tb_cpns, ocr):
|
||||||
|
boxes = ocr(np.array(img))
|
||||||
|
boxes = LayoutRecognizer.sort_Y_firstly(
|
||||||
|
[{"x0": b[0][0], "x1": b[1][0],
|
||||||
|
"top": b[0][1], "text": t[0],
|
||||||
|
"bottom": b[-1][1],
|
||||||
|
"layout_type": "table",
|
||||||
|
"page_number": 0} for b, t in boxes if b[0][0] <= b[1][0] and b[0][1] <= b[-1][1]],
|
||||||
|
np.mean([b[-1][1] - b[0][1] for b, _ in boxes]) / 3
|
||||||
|
)
|
||||||
|
|
||||||
|
def gather(kwd, fzy=10, ption=0.6):
|
||||||
|
nonlocal boxes
|
||||||
|
eles = LayoutRecognizer.sort_Y_firstly(
|
||||||
|
[r for r in tb_cpns if re.match(kwd, r["label"])], fzy)
|
||||||
|
eles = LayoutRecognizer.layouts_cleanup(boxes, eles, 5, ption)
|
||||||
|
return LayoutRecognizer.sort_Y_firstly(eles, 0)
|
||||||
|
|
||||||
|
headers = gather(r".*header$")
|
||||||
|
rows = gather(r".* (row|header)")
|
||||||
|
spans = gather(r".*spanning")
|
||||||
|
clmns = sorted([r for r in tb_cpns if re.match(
|
||||||
|
r"table column$", r["label"])], key=lambda x: x["x0"])
|
||||||
|
clmns = LayoutRecognizer.layouts_cleanup(boxes, clmns, 5, 0.5)
|
||||||
|
|
||||||
|
for b in boxes:
|
||||||
|
ii = LayoutRecognizer.find_overlapped_with_threshold(b, rows, thr=0.3)
|
||||||
|
if ii is not None:
|
||||||
|
b["R"] = ii
|
||||||
|
b["R_top"] = rows[ii]["top"]
|
||||||
|
b["R_bott"] = rows[ii]["bottom"]
|
||||||
|
|
||||||
|
ii = LayoutRecognizer.find_overlapped_with_threshold(b, headers, thr=0.3)
|
||||||
|
if ii is not None:
|
||||||
|
b["H_top"] = headers[ii]["top"]
|
||||||
|
b["H_bott"] = headers[ii]["bottom"]
|
||||||
|
b["H_left"] = headers[ii]["x0"]
|
||||||
|
b["H_right"] = headers[ii]["x1"]
|
||||||
|
b["H"] = ii
|
||||||
|
|
||||||
|
ii = LayoutRecognizer.find_horizontally_tightest_fit(b, clmns)
|
||||||
|
if ii is not None:
|
||||||
|
b["C"] = ii
|
||||||
|
b["C_left"] = clmns[ii]["x0"]
|
||||||
|
b["C_right"] = clmns[ii]["x1"]
|
||||||
|
|
||||||
|
ii = LayoutRecognizer.find_overlapped_with_threshold(b, spans, thr=0.3)
|
||||||
|
if ii is not None:
|
||||||
|
b["H_top"] = spans[ii]["top"]
|
||||||
|
b["H_bott"] = spans[ii]["bottom"]
|
||||||
|
b["H_left"] = spans[ii]["x0"]
|
||||||
|
b["H_right"] = spans[ii]["x1"]
|
||||||
|
b["SP"] = ii
|
||||||
|
|
||||||
|
html = """
|
||||||
|
<html>
|
||||||
|
<head>
|
||||||
|
<style>
|
||||||
|
._table_1nkzy_11 {
|
||||||
|
margin: auto;
|
||||||
|
width: 70%%;
|
||||||
|
padding: 10px;
|
||||||
|
}
|
||||||
|
._table_1nkzy_11 p {
|
||||||
|
margin-bottom: 50px;
|
||||||
|
border: 1px solid #e1e1e1;
|
||||||
|
}
|
||||||
|
|
||||||
|
caption {
|
||||||
|
color: #6ac1ca;
|
||||||
|
font-size: 20px;
|
||||||
|
height: 50px;
|
||||||
|
line-height: 50px;
|
||||||
|
font-weight: 600;
|
||||||
|
margin-bottom: 10px;
|
||||||
|
}
|
||||||
|
|
||||||
|
._table_1nkzy_11 table {
|
||||||
|
width: 100%%;
|
||||||
|
border-collapse: collapse;
|
||||||
|
}
|
||||||
|
|
||||||
|
th {
|
||||||
|
color: #fff;
|
||||||
|
background-color: #6ac1ca;
|
||||||
|
}
|
||||||
|
|
||||||
|
td:hover {
|
||||||
|
background: #c1e8e8;
|
||||||
|
}
|
||||||
|
|
||||||
|
tr:nth-child(even) {
|
||||||
|
background-color: #f2f2f2;
|
||||||
|
}
|
||||||
|
|
||||||
|
._table_1nkzy_11 th,
|
||||||
|
._table_1nkzy_11 td {
|
||||||
|
text-align: center;
|
||||||
|
border: 1px solid #ddd;
|
||||||
|
padding: 8px;
|
||||||
|
}
|
||||||
|
</style>
|
||||||
|
</head>
|
||||||
|
<body>
|
||||||
|
%s
|
||||||
|
</body>
|
||||||
|
</html>
|
||||||
|
""" % TableStructureRecognizer.construct_table(boxes, html=True)
|
||||||
|
return html
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--inputs',
|
||||||
|
help="Directory where to store images or PDFs, or a file path to a single image or PDF",
|
||||||
|
required=True)
|
||||||
|
parser.add_argument('--output_dir', help="Directory where to store the output images. Default: './layouts_outputs'",
|
||||||
|
default="./layouts_outputs")
|
||||||
|
parser.add_argument(
|
||||||
|
'--threshold',
|
||||||
|
help="A threshold to filter out detections. Default: 0.5",
|
||||||
|
default=0.5)
|
||||||
|
parser.add_argument('--mode', help="Task mode: layout recognition or table structure recognition", choices=["layout", "tsr"],
|
||||||
|
default="layout")
|
||||||
|
args = parser.parse_args()
|
||||||
|
main(args)
|
||||||
612
deepdoc/vision/table_structure_recognizer.py
Normal file
612
deepdoc/vision/table_structure_recognizer.py
Normal file
@@ -0,0 +1,612 @@
|
|||||||
|
#
|
||||||
|
# Copyright 2025 The InfiniFlow Authors. All Rights Reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
#
|
||||||
|
import logging
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
from collections import Counter
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
from huggingface_hub import snapshot_download
|
||||||
|
|
||||||
|
from api.utils.file_utils import get_project_base_directory
|
||||||
|
from rag.nlp import rag_tokenizer
|
||||||
|
|
||||||
|
from .recognizer import Recognizer
|
||||||
|
|
||||||
|
|
||||||
|
class TableStructureRecognizer(Recognizer):
|
||||||
|
labels = [
|
||||||
|
"table",
|
||||||
|
"table column",
|
||||||
|
"table row",
|
||||||
|
"table column header",
|
||||||
|
"table projected row header",
|
||||||
|
"table spanning cell",
|
||||||
|
]
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
try:
|
||||||
|
super().__init__(self.labels, "tsr", os.path.join(get_project_base_directory(), "rag/res/deepdoc"))
|
||||||
|
except Exception:
|
||||||
|
super().__init__(
|
||||||
|
self.labels,
|
||||||
|
"tsr",
|
||||||
|
snapshot_download(
|
||||||
|
repo_id="InfiniFlow/deepdoc",
|
||||||
|
local_dir=os.path.join(get_project_base_directory(), "rag/res/deepdoc"),
|
||||||
|
local_dir_use_symlinks=False,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
|
||||||
|
def __call__(self, images, thr=0.2):
|
||||||
|
table_structure_recognizer_type = os.getenv("TABLE_STRUCTURE_RECOGNIZER_TYPE", "onnx").lower()
|
||||||
|
if table_structure_recognizer_type not in ["onnx", "ascend"]:
|
||||||
|
raise RuntimeError("Unsupported table structure recognizer type.")
|
||||||
|
|
||||||
|
if table_structure_recognizer_type == "onnx":
|
||||||
|
logging.debug("Using Onnx table structure recognizer", flush=True)
|
||||||
|
tbls = super().__call__(images, thr)
|
||||||
|
else: # ascend
|
||||||
|
logging.debug("Using Ascend table structure recognizer", flush=True)
|
||||||
|
tbls = self._run_ascend_tsr(images, thr)
|
||||||
|
|
||||||
|
res = []
|
||||||
|
# align left&right for rows, align top&bottom for columns
|
||||||
|
for tbl in tbls:
|
||||||
|
lts = [
|
||||||
|
{
|
||||||
|
"label": b["type"],
|
||||||
|
"score": b["score"],
|
||||||
|
"x0": b["bbox"][0],
|
||||||
|
"x1": b["bbox"][2],
|
||||||
|
"top": b["bbox"][1],
|
||||||
|
"bottom": b["bbox"][-1],
|
||||||
|
}
|
||||||
|
for b in tbl
|
||||||
|
]
|
||||||
|
if not lts:
|
||||||
|
continue
|
||||||
|
|
||||||
|
left = [b["x0"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||||
|
right = [b["x1"] for b in lts if b["label"].find("row") > 0 or b["label"].find("header") > 0]
|
||||||
|
if not left:
|
||||||
|
continue
|
||||||
|
left = np.mean(left) if len(left) > 4 else np.min(left)
|
||||||
|
right = np.mean(right) if len(right) > 4 else np.max(right)
|
||||||
|
for b in lts:
|
||||||
|
if b["label"].find("row") > 0 or b["label"].find("header") > 0:
|
||||||
|
if b["x0"] > left:
|
||||||
|
b["x0"] = left
|
||||||
|
if b["x1"] < right:
|
||||||
|
b["x1"] = right
|
||||||
|
|
||||||
|
top = [b["top"] for b in lts if b["label"] == "table column"]
|
||||||
|
bottom = [b["bottom"] for b in lts if b["label"] == "table column"]
|
||||||
|
if not top:
|
||||||
|
res.append(lts)
|
||||||
|
continue
|
||||||
|
top = np.median(top) if len(top) > 4 else np.min(top)
|
||||||
|
bottom = np.median(bottom) if len(bottom) > 4 else np.max(bottom)
|
||||||
|
for b in lts:
|
||||||
|
if b["label"] == "table column":
|
||||||
|
if b["top"] > top:
|
||||||
|
b["top"] = top
|
||||||
|
if b["bottom"] < bottom:
|
||||||
|
b["bottom"] = bottom
|
||||||
|
|
||||||
|
res.append(lts)
|
||||||
|
return res
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def is_caption(bx):
|
||||||
|
patt = [r"[图表]+[ 0-9::]{2,}"]
|
||||||
|
if any([re.match(p, bx["text"].strip()) for p in patt]) or bx.get("layout_type", "").find("caption") >= 0:
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def blockType(b):
|
||||||
|
patt = [
|
||||||
|
("^(20|19)[0-9]{2}[年/-][0-9]{1,2}[月/-][0-9]{1,2}日*$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}年$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}[年-][0-9]{1,2}月*$", "Dt"),
|
||||||
|
("^[0-9]{1,2}[月-][0-9]{1,2}日*$", "Dt"),
|
||||||
|
(r"^第*[一二三四1-4]季度$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}年*[一二三四1-4]季度$", "Dt"),
|
||||||
|
(r"^(20|19)[0-9]{2}[ABCDE]$", "Dt"),
|
||||||
|
("^[0-9.,+%/ -]+$", "Nu"),
|
||||||
|
(r"^[0-9A-Z/\._~-]+$", "Ca"),
|
||||||
|
(r"^[A-Z]*[a-z' -]+$", "En"),
|
||||||
|
(r"^[0-9.,+-]+[0-9A-Za-z/$¥%<>()()' -]+$", "NE"),
|
||||||
|
(r"^.{1}$", "Sg"),
|
||||||
|
]
|
||||||
|
for p, n in patt:
|
||||||
|
if re.search(p, b["text"].strip()):
|
||||||
|
return n
|
||||||
|
tks = [t for t in rag_tokenizer.tokenize(b["text"]).split() if len(t) > 1]
|
||||||
|
if len(tks) > 3:
|
||||||
|
if len(tks) < 12:
|
||||||
|
return "Tx"
|
||||||
|
else:
|
||||||
|
return "Lx"
|
||||||
|
|
||||||
|
if len(tks) == 1 and rag_tokenizer.tag(tks[0]) == "nr":
|
||||||
|
return "Nr"
|
||||||
|
|
||||||
|
return "Ot"
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def construct_table(boxes, is_english=False, html=True, **kwargs):
|
||||||
|
cap = ""
|
||||||
|
i = 0
|
||||||
|
while i < len(boxes):
|
||||||
|
if TableStructureRecognizer.is_caption(boxes[i]):
|
||||||
|
if is_english:
|
||||||
|
cap + " "
|
||||||
|
cap += boxes[i]["text"]
|
||||||
|
boxes.pop(i)
|
||||||
|
i -= 1
|
||||||
|
i += 1
|
||||||
|
|
||||||
|
if not boxes:
|
||||||
|
return []
|
||||||
|
for b in boxes:
|
||||||
|
b["btype"] = TableStructureRecognizer.blockType(b)
|
||||||
|
max_type = Counter([b["btype"] for b in boxes]).items()
|
||||||
|
max_type = max(max_type, key=lambda x: x[1])[0] if max_type else ""
|
||||||
|
logging.debug("MAXTYPE: " + max_type)
|
||||||
|
|
||||||
|
rowh = [b["R_bott"] - b["R_top"] for b in boxes if "R" in b]
|
||||||
|
rowh = np.min(rowh) if rowh else 0
|
||||||
|
boxes = Recognizer.sort_R_firstly(boxes, rowh / 2)
|
||||||
|
# for b in boxes:print(b)
|
||||||
|
boxes[0]["rn"] = 0
|
||||||
|
rows = [[boxes[0]]]
|
||||||
|
btm = boxes[0]["bottom"]
|
||||||
|
for b in boxes[1:]:
|
||||||
|
b["rn"] = len(rows) - 1
|
||||||
|
lst_r = rows[-1]
|
||||||
|
if lst_r[-1].get("R", "") != b.get("R", "") or (b["top"] >= btm - 3 and lst_r[-1].get("R", "-1") != b.get("R", "-2")): # new row
|
||||||
|
btm = b["bottom"]
|
||||||
|
b["rn"] += 1
|
||||||
|
rows.append([b])
|
||||||
|
continue
|
||||||
|
btm = (btm + b["bottom"]) / 2.0
|
||||||
|
rows[-1].append(b)
|
||||||
|
|
||||||
|
colwm = [b["C_right"] - b["C_left"] for b in boxes if "C" in b]
|
||||||
|
colwm = np.min(colwm) if colwm else 0
|
||||||
|
crosspage = len(set([b["page_number"] for b in boxes])) > 1
|
||||||
|
if crosspage:
|
||||||
|
boxes = Recognizer.sort_X_firstly(boxes, colwm / 2)
|
||||||
|
else:
|
||||||
|
boxes = Recognizer.sort_C_firstly(boxes, colwm / 2)
|
||||||
|
boxes[0]["cn"] = 0
|
||||||
|
cols = [[boxes[0]]]
|
||||||
|
right = boxes[0]["x1"]
|
||||||
|
for b in boxes[1:]:
|
||||||
|
b["cn"] = len(cols) - 1
|
||||||
|
lst_c = cols[-1]
|
||||||
|
if (int(b.get("C", "1")) - int(lst_c[-1].get("C", "1")) == 1 and b["page_number"] == lst_c[-1]["page_number"]) or (
|
||||||
|
b["x0"] >= right and lst_c[-1].get("C", "-1") != b.get("C", "-2")
|
||||||
|
): # new col
|
||||||
|
right = b["x1"]
|
||||||
|
b["cn"] += 1
|
||||||
|
cols.append([b])
|
||||||
|
continue
|
||||||
|
right = (right + b["x1"]) / 2.0
|
||||||
|
cols[-1].append(b)
|
||||||
|
|
||||||
|
tbl = [[[] for _ in range(len(cols))] for _ in range(len(rows))]
|
||||||
|
for b in boxes:
|
||||||
|
tbl[b["rn"]][b["cn"]].append(b)
|
||||||
|
|
||||||
|
if len(rows) >= 4:
|
||||||
|
# remove single in column
|
||||||
|
j = 0
|
||||||
|
while j < len(tbl[0]):
|
||||||
|
e, ii = 0, 0
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
if tbl[i][j]:
|
||||||
|
e += 1
|
||||||
|
ii = i
|
||||||
|
if e > 1:
|
||||||
|
break
|
||||||
|
if e > 1:
|
||||||
|
j += 1
|
||||||
|
continue
|
||||||
|
f = (j > 0 and tbl[ii][j - 1] and tbl[ii][j - 1][0].get("text")) or j == 0
|
||||||
|
ff = (j + 1 < len(tbl[ii]) and tbl[ii][j + 1] and tbl[ii][j + 1][0].get("text")) or j + 1 >= len(tbl[ii])
|
||||||
|
if f and ff:
|
||||||
|
j += 1
|
||||||
|
continue
|
||||||
|
bx = tbl[ii][j][0]
|
||||||
|
logging.debug("Relocate column single: " + bx["text"])
|
||||||
|
# j column only has one value
|
||||||
|
left, right = 100000, 100000
|
||||||
|
if j > 0 and not f:
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
if tbl[i][j - 1]:
|
||||||
|
left = min(left, np.min([bx["x0"] - a["x1"] for a in tbl[i][j - 1]]))
|
||||||
|
if j + 1 < len(tbl[0]) and not ff:
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
if tbl[i][j + 1]:
|
||||||
|
right = min(right, np.min([a["x0"] - bx["x1"] for a in tbl[i][j + 1]]))
|
||||||
|
assert left < 100000 or right < 100000
|
||||||
|
if left < right:
|
||||||
|
for jj in range(j, len(tbl[0])):
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
for a in tbl[i][jj]:
|
||||||
|
a["cn"] -= 1
|
||||||
|
if tbl[ii][j - 1]:
|
||||||
|
tbl[ii][j - 1].extend(tbl[ii][j])
|
||||||
|
else:
|
||||||
|
tbl[ii][j - 1] = tbl[ii][j]
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
tbl[i].pop(j)
|
||||||
|
|
||||||
|
else:
|
||||||
|
for jj in range(j + 1, len(tbl[0])):
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
for a in tbl[i][jj]:
|
||||||
|
a["cn"] -= 1
|
||||||
|
if tbl[ii][j + 1]:
|
||||||
|
tbl[ii][j + 1].extend(tbl[ii][j])
|
||||||
|
else:
|
||||||
|
tbl[ii][j + 1] = tbl[ii][j]
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
tbl[i].pop(j)
|
||||||
|
cols.pop(j)
|
||||||
|
assert len(cols) == len(tbl[0]), "Column NO. miss matched: %d vs %d" % (len(cols), len(tbl[0]))
|
||||||
|
|
||||||
|
if len(cols) >= 4:
|
||||||
|
# remove single in row
|
||||||
|
i = 0
|
||||||
|
while i < len(tbl):
|
||||||
|
e, jj = 0, 0
|
||||||
|
for j in range(len(tbl[i])):
|
||||||
|
if tbl[i][j]:
|
||||||
|
e += 1
|
||||||
|
jj = j
|
||||||
|
if e > 1:
|
||||||
|
break
|
||||||
|
if e > 1:
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
f = (i > 0 and tbl[i - 1][jj] and tbl[i - 1][jj][0].get("text")) or i == 0
|
||||||
|
ff = (i + 1 < len(tbl) and tbl[i + 1][jj] and tbl[i + 1][jj][0].get("text")) or i + 1 >= len(tbl)
|
||||||
|
if f and ff:
|
||||||
|
i += 1
|
||||||
|
continue
|
||||||
|
|
||||||
|
bx = tbl[i][jj][0]
|
||||||
|
logging.debug("Relocate row single: " + bx["text"])
|
||||||
|
# i row only has one value
|
||||||
|
up, down = 100000, 100000
|
||||||
|
if i > 0 and not f:
|
||||||
|
for j in range(len(tbl[i - 1])):
|
||||||
|
if tbl[i - 1][j]:
|
||||||
|
up = min(up, np.min([bx["top"] - a["bottom"] for a in tbl[i - 1][j]]))
|
||||||
|
if i + 1 < len(tbl) and not ff:
|
||||||
|
for j in range(len(tbl[i + 1])):
|
||||||
|
if tbl[i + 1][j]:
|
||||||
|
down = min(down, np.min([a["top"] - bx["bottom"] for a in tbl[i + 1][j]]))
|
||||||
|
assert up < 100000 or down < 100000
|
||||||
|
if up < down:
|
||||||
|
for ii in range(i, len(tbl)):
|
||||||
|
for j in range(len(tbl[ii])):
|
||||||
|
for a in tbl[ii][j]:
|
||||||
|
a["rn"] -= 1
|
||||||
|
if tbl[i - 1][jj]:
|
||||||
|
tbl[i - 1][jj].extend(tbl[i][jj])
|
||||||
|
else:
|
||||||
|
tbl[i - 1][jj] = tbl[i][jj]
|
||||||
|
tbl.pop(i)
|
||||||
|
|
||||||
|
else:
|
||||||
|
for ii in range(i + 1, len(tbl)):
|
||||||
|
for j in range(len(tbl[ii])):
|
||||||
|
for a in tbl[ii][j]:
|
||||||
|
a["rn"] -= 1
|
||||||
|
if tbl[i + 1][jj]:
|
||||||
|
tbl[i + 1][jj].extend(tbl[i][jj])
|
||||||
|
else:
|
||||||
|
tbl[i + 1][jj] = tbl[i][jj]
|
||||||
|
tbl.pop(i)
|
||||||
|
rows.pop(i)
|
||||||
|
|
||||||
|
# which rows are headers
|
||||||
|
hdset = set([])
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
cnt, h = 0, 0
|
||||||
|
for j, arr in enumerate(tbl[i]):
|
||||||
|
if not arr:
|
||||||
|
continue
|
||||||
|
cnt += 1
|
||||||
|
if max_type == "Nu" and arr[0]["btype"] == "Nu":
|
||||||
|
continue
|
||||||
|
if any([a.get("H") for a in arr]) or (max_type == "Nu" and arr[0]["btype"] != "Nu"):
|
||||||
|
h += 1
|
||||||
|
if h / cnt > 0.5:
|
||||||
|
hdset.add(i)
|
||||||
|
|
||||||
|
if html:
|
||||||
|
return TableStructureRecognizer.__html_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, True))
|
||||||
|
|
||||||
|
return TableStructureRecognizer.__desc_table(cap, hdset, TableStructureRecognizer.__cal_spans(boxes, rows, cols, tbl, False), is_english)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def __html_table(cap, hdset, tbl):
|
||||||
|
# constrcut HTML
|
||||||
|
html = "<table>"
|
||||||
|
if cap:
|
||||||
|
html += f"<caption>{cap}</caption>"
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
row = "<tr>"
|
||||||
|
txts = []
|
||||||
|
for j, arr in enumerate(tbl[i]):
|
||||||
|
if arr is None:
|
||||||
|
continue
|
||||||
|
if not arr:
|
||||||
|
row += "<td></td>" if i not in hdset else "<th></th>"
|
||||||
|
continue
|
||||||
|
txt = ""
|
||||||
|
if arr:
|
||||||
|
h = min(np.min([c["bottom"] - c["top"] for c in arr]) / 2, 10)
|
||||||
|
txt = " ".join([c["text"] for c in Recognizer.sort_Y_firstly(arr, h)])
|
||||||
|
txts.append(txt)
|
||||||
|
sp = ""
|
||||||
|
if arr[0].get("colspan"):
|
||||||
|
sp = "colspan={}".format(arr[0]["colspan"])
|
||||||
|
if arr[0].get("rowspan"):
|
||||||
|
sp += " rowspan={}".format(arr[0]["rowspan"])
|
||||||
|
if i in hdset:
|
||||||
|
row += f"<th {sp} >" + txt + "</th>"
|
||||||
|
else:
|
||||||
|
row += f"<td {sp} >" + txt + "</td>"
|
||||||
|
|
||||||
|
if i in hdset:
|
||||||
|
if all([t in hdset for t in txts]):
|
||||||
|
continue
|
||||||
|
for t in txts:
|
||||||
|
hdset.add(t)
|
||||||
|
|
||||||
|
if row != "<tr>":
|
||||||
|
row += "</tr>"
|
||||||
|
else:
|
||||||
|
row = ""
|
||||||
|
html += "\n" + row
|
||||||
|
html += "\n</table>"
|
||||||
|
return html
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def __desc_table(cap, hdr_rowno, tbl, is_english):
|
||||||
|
# get text of every colomn in header row to become header text
|
||||||
|
clmno = len(tbl[0])
|
||||||
|
rowno = len(tbl)
|
||||||
|
headers = {}
|
||||||
|
hdrset = set()
|
||||||
|
lst_hdr = []
|
||||||
|
de = "的" if not is_english else " for "
|
||||||
|
for r in sorted(list(hdr_rowno)):
|
||||||
|
headers[r] = ["" for _ in range(clmno)]
|
||||||
|
for i in range(clmno):
|
||||||
|
if not tbl[r][i]:
|
||||||
|
continue
|
||||||
|
txt = " ".join([a["text"].strip() for a in tbl[r][i]])
|
||||||
|
headers[r][i] = txt
|
||||||
|
hdrset.add(txt)
|
||||||
|
if all([not t for t in headers[r]]):
|
||||||
|
del headers[r]
|
||||||
|
hdr_rowno.remove(r)
|
||||||
|
continue
|
||||||
|
for j in range(clmno):
|
||||||
|
if headers[r][j]:
|
||||||
|
continue
|
||||||
|
if j >= len(lst_hdr):
|
||||||
|
break
|
||||||
|
headers[r][j] = lst_hdr[j]
|
||||||
|
lst_hdr = headers[r]
|
||||||
|
for i in range(rowno):
|
||||||
|
if i not in hdr_rowno:
|
||||||
|
continue
|
||||||
|
for j in range(i + 1, rowno):
|
||||||
|
if j not in hdr_rowno:
|
||||||
|
break
|
||||||
|
for k in range(clmno):
|
||||||
|
if not headers[j - 1][k]:
|
||||||
|
continue
|
||||||
|
if headers[j][k].find(headers[j - 1][k]) >= 0:
|
||||||
|
continue
|
||||||
|
if len(headers[j][k]) > len(headers[j - 1][k]):
|
||||||
|
headers[j][k] += (de if headers[j][k] else "") + headers[j - 1][k]
|
||||||
|
else:
|
||||||
|
headers[j][k] = headers[j - 1][k] + (de if headers[j - 1][k] else "") + headers[j][k]
|
||||||
|
|
||||||
|
logging.debug(f">>>>>>>>>>>>>>>>>{cap}:SIZE:{rowno}X{clmno} Header: {hdr_rowno}")
|
||||||
|
row_txt = []
|
||||||
|
for i in range(rowno):
|
||||||
|
if i in hdr_rowno:
|
||||||
|
continue
|
||||||
|
rtxt = []
|
||||||
|
|
||||||
|
def append(delimer):
|
||||||
|
nonlocal rtxt, row_txt
|
||||||
|
rtxt = delimer.join(rtxt)
|
||||||
|
if row_txt and len(row_txt[-1]) + len(rtxt) < 64:
|
||||||
|
row_txt[-1] += "\n" + rtxt
|
||||||
|
else:
|
||||||
|
row_txt.append(rtxt)
|
||||||
|
|
||||||
|
r = 0
|
||||||
|
if len(headers.items()):
|
||||||
|
_arr = [(i - r, r) for r, _ in headers.items() if r < i]
|
||||||
|
if _arr:
|
||||||
|
_, r = min(_arr, key=lambda x: x[0])
|
||||||
|
|
||||||
|
if r not in headers and clmno <= 2:
|
||||||
|
for j in range(clmno):
|
||||||
|
if not tbl[i][j]:
|
||||||
|
continue
|
||||||
|
txt = "".join([a["text"].strip() for a in tbl[i][j]])
|
||||||
|
if txt:
|
||||||
|
rtxt.append(txt)
|
||||||
|
if rtxt:
|
||||||
|
append(":")
|
||||||
|
continue
|
||||||
|
|
||||||
|
for j in range(clmno):
|
||||||
|
if not tbl[i][j]:
|
||||||
|
continue
|
||||||
|
txt = "".join([a["text"].strip() for a in tbl[i][j]])
|
||||||
|
if not txt:
|
||||||
|
continue
|
||||||
|
ctt = headers[r][j] if r in headers else ""
|
||||||
|
if ctt:
|
||||||
|
ctt += ":"
|
||||||
|
ctt += txt
|
||||||
|
if ctt:
|
||||||
|
rtxt.append(ctt)
|
||||||
|
|
||||||
|
if rtxt:
|
||||||
|
row_txt.append("; ".join(rtxt))
|
||||||
|
|
||||||
|
if cap:
|
||||||
|
if is_english:
|
||||||
|
from_ = " in "
|
||||||
|
else:
|
||||||
|
from_ = "来自"
|
||||||
|
row_txt = [t + f"\t——{from_}“{cap}”" for t in row_txt]
|
||||||
|
return row_txt
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def __cal_spans(boxes, rows, cols, tbl, html=True):
|
||||||
|
# caculate span
|
||||||
|
clft = [np.mean([c.get("C_left", c["x0"]) for c in cln]) for cln in cols]
|
||||||
|
crgt = [np.mean([c.get("C_right", c["x1"]) for c in cln]) for cln in cols]
|
||||||
|
rtop = [np.mean([c.get("R_top", c["top"]) for c in row]) for row in rows]
|
||||||
|
rbtm = [np.mean([c.get("R_btm", c["bottom"]) for c in row]) for row in rows]
|
||||||
|
for b in boxes:
|
||||||
|
if "SP" not in b:
|
||||||
|
continue
|
||||||
|
b["colspan"] = [b["cn"]]
|
||||||
|
b["rowspan"] = [b["rn"]]
|
||||||
|
# col span
|
||||||
|
for j in range(0, len(clft)):
|
||||||
|
if j == b["cn"]:
|
||||||
|
continue
|
||||||
|
if clft[j] + (crgt[j] - clft[j]) / 2 < b["H_left"]:
|
||||||
|
continue
|
||||||
|
if crgt[j] - (crgt[j] - clft[j]) / 2 > b["H_right"]:
|
||||||
|
continue
|
||||||
|
b["colspan"].append(j)
|
||||||
|
# row span
|
||||||
|
for j in range(0, len(rtop)):
|
||||||
|
if j == b["rn"]:
|
||||||
|
continue
|
||||||
|
if rtop[j] + (rbtm[j] - rtop[j]) / 2 < b["H_top"]:
|
||||||
|
continue
|
||||||
|
if rbtm[j] - (rbtm[j] - rtop[j]) / 2 > b["H_bott"]:
|
||||||
|
continue
|
||||||
|
b["rowspan"].append(j)
|
||||||
|
|
||||||
|
def join(arr):
|
||||||
|
if not arr:
|
||||||
|
return ""
|
||||||
|
return "".join([t["text"] for t in arr])
|
||||||
|
|
||||||
|
# rm the spaning cells
|
||||||
|
for i in range(len(tbl)):
|
||||||
|
for j, arr in enumerate(tbl[i]):
|
||||||
|
if not arr:
|
||||||
|
continue
|
||||||
|
if all(["rowspan" not in a and "colspan" not in a for a in arr]):
|
||||||
|
continue
|
||||||
|
rowspan, colspan = [], []
|
||||||
|
for a in arr:
|
||||||
|
if isinstance(a.get("rowspan", 0), list):
|
||||||
|
rowspan.extend(a["rowspan"])
|
||||||
|
if isinstance(a.get("colspan", 0), list):
|
||||||
|
colspan.extend(a["colspan"])
|
||||||
|
rowspan, colspan = set(rowspan), set(colspan)
|
||||||
|
if len(rowspan) < 2 and len(colspan) < 2:
|
||||||
|
for a in arr:
|
||||||
|
if "rowspan" in a:
|
||||||
|
del a["rowspan"]
|
||||||
|
if "colspan" in a:
|
||||||
|
del a["colspan"]
|
||||||
|
continue
|
||||||
|
rowspan, colspan = sorted(rowspan), sorted(colspan)
|
||||||
|
rowspan = list(range(rowspan[0], rowspan[-1] + 1))
|
||||||
|
colspan = list(range(colspan[0], colspan[-1] + 1))
|
||||||
|
assert i in rowspan, rowspan
|
||||||
|
assert j in colspan, colspan
|
||||||
|
arr = []
|
||||||
|
for r in rowspan:
|
||||||
|
for c in colspan:
|
||||||
|
arr_txt = join(arr)
|
||||||
|
if tbl[r][c] and join(tbl[r][c]) != arr_txt:
|
||||||
|
arr.extend(tbl[r][c])
|
||||||
|
tbl[r][c] = None if html else arr
|
||||||
|
for a in arr:
|
||||||
|
if len(rowspan) > 1:
|
||||||
|
a["rowspan"] = len(rowspan)
|
||||||
|
elif "rowspan" in a:
|
||||||
|
del a["rowspan"]
|
||||||
|
if len(colspan) > 1:
|
||||||
|
a["colspan"] = len(colspan)
|
||||||
|
elif "colspan" in a:
|
||||||
|
del a["colspan"]
|
||||||
|
tbl[rowspan[0]][colspan[0]] = arr
|
||||||
|
|
||||||
|
return tbl
|
||||||
|
|
||||||
|
def _run_ascend_tsr(self, image_list, thr=0.2, batch_size=16):
|
||||||
|
import math
|
||||||
|
|
||||||
|
from ais_bench.infer.interface import InferSession
|
||||||
|
|
||||||
|
model_dir = os.path.join(get_project_base_directory(), "rag/res/deepdoc")
|
||||||
|
model_file_path = os.path.join(model_dir, "tsr.om")
|
||||||
|
|
||||||
|
if not os.path.exists(model_file_path):
|
||||||
|
raise ValueError(f"Model file not found: {model_file_path}")
|
||||||
|
|
||||||
|
device_id = int(os.getenv("ASCEND_LAYOUT_RECOGNIZER_DEVICE_ID", 0))
|
||||||
|
session = InferSession(device_id=device_id, model_path=model_file_path)
|
||||||
|
|
||||||
|
images = [np.array(im) if not isinstance(im, np.ndarray) else im for im in image_list]
|
||||||
|
results = []
|
||||||
|
|
||||||
|
conf_thr = max(thr, 0.08)
|
||||||
|
|
||||||
|
batch_loop_cnt = math.ceil(float(len(images)) / batch_size)
|
||||||
|
for bi in range(batch_loop_cnt):
|
||||||
|
s = bi * batch_size
|
||||||
|
e = min((bi + 1) * batch_size, len(images))
|
||||||
|
batch_images = images[s:e]
|
||||||
|
|
||||||
|
inputs_list = self.preprocess(batch_images)
|
||||||
|
for ins in inputs_list:
|
||||||
|
feeds = []
|
||||||
|
if "image" in ins:
|
||||||
|
feeds.append(ins["image"])
|
||||||
|
else:
|
||||||
|
feeds.append(ins[self.input_names[0]])
|
||||||
|
output_list = session.infer(feeds=feeds, mode="static")
|
||||||
|
bb = self.postprocess(output_list, ins, conf_thr)
|
||||||
|
results.append(bb)
|
||||||
|
return results
|
||||||
@@ -3,7 +3,7 @@
|
|||||||
# - `elasticsearch` (default)
|
# - `elasticsearch` (default)
|
||||||
# - `infinity` (https://github.com/infiniflow/infinity)
|
# - `infinity` (https://github.com/infiniflow/infinity)
|
||||||
# - `opensearch` (https://github.com/opensearch-project/OpenSearch)
|
# - `opensearch` (https://github.com/opensearch-project/OpenSearch)
|
||||||
DOC_ENGINE=opensearch
|
DOC_ENGINE=elasticsearch
|
||||||
|
|
||||||
# ------------------------------
|
# ------------------------------
|
||||||
# docker env var for specifying vector db type at startup
|
# docker env var for specifying vector db type at startup
|
||||||
@@ -98,7 +98,7 @@ ADMIN_SVR_HTTP_PORT=9381
|
|||||||
|
|
||||||
# The RAGFlow Docker image to download.
|
# The RAGFlow Docker image to download.
|
||||||
# Defaults to the v0.21.1-slim edition, which is the RAGFlow Docker image without embedding models.
|
# Defaults to the v0.21.1-slim edition, which is the RAGFlow Docker image without embedding models.
|
||||||
RAGFLOW_IMAGE=infiniflow/ragflow:v0.21.1-slim
|
RAGFLOW_IMAGE=infiniflow/ragflow:v0.21.1-fastapi-web
|
||||||
#
|
#
|
||||||
# To download the RAGFlow Docker image with embedding models, uncomment the following line instead:
|
# To download the RAGFlow Docker image with embedding models, uncomment the following line instead:
|
||||||
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.21.1
|
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.21.1
|
||||||
|
|||||||
@@ -4,7 +4,7 @@ services:
|
|||||||
container_name: ragflow-opensearch-01
|
container_name: ragflow-opensearch-01
|
||||||
profiles:
|
profiles:
|
||||||
- opensearch
|
- opensearch
|
||||||
image: hub.icert.top/opensearchproject/opensearch:2.19.1
|
image: hub.icert.top/opensearchproject/opensearch:3.3.2
|
||||||
volumes:
|
volumes:
|
||||||
- osdata01:/usr/share/opensearch/data
|
- osdata01:/usr/share/opensearch/data
|
||||||
ports:
|
ports:
|
||||||
@@ -38,6 +38,61 @@ services:
|
|||||||
- ragflow
|
- ragflow
|
||||||
restart: on-failure
|
restart: on-failure
|
||||||
|
|
||||||
|
opensearch-dashboards:
|
||||||
|
container_name: ragflow-opensearch-dashboards
|
||||||
|
profiles:
|
||||||
|
- opensearch
|
||||||
|
image: opensearchproject/opensearch-dashboards:3.3.0
|
||||||
|
env_file: .env
|
||||||
|
environment:
|
||||||
|
- OPENSEARCH_HOSTS=["http://opensearch01:9201"]
|
||||||
|
- OPENSEARCH_USERNAME=admin
|
||||||
|
- OPENSEARCH_PASSWORD=${OPENSEARCH_PASSWORD}
|
||||||
|
- TZ=${TIMEZONE}
|
||||||
|
ports:
|
||||||
|
- 5601:5601
|
||||||
|
depends_on:
|
||||||
|
- opensearch01
|
||||||
|
networks:
|
||||||
|
- ragflow
|
||||||
|
restart: on-failure
|
||||||
|
|
||||||
|
es01:
|
||||||
|
container_name: ragflow-es-01
|
||||||
|
profiles:
|
||||||
|
- elasticsearch
|
||||||
|
image: elasticsearch:${STACK_VERSION}
|
||||||
|
volumes:
|
||||||
|
- esdata01:/usr/share/elasticsearch/data
|
||||||
|
ports:
|
||||||
|
- ${ES_PORT}:9200
|
||||||
|
env_file: .env
|
||||||
|
environment:
|
||||||
|
- node.name=es01
|
||||||
|
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
|
||||||
|
- bootstrap.memory_lock=false
|
||||||
|
- discovery.type=single-node
|
||||||
|
- xpack.security.enabled=true
|
||||||
|
- xpack.security.http.ssl.enabled=false
|
||||||
|
- xpack.security.transport.ssl.enabled=false
|
||||||
|
- cluster.routing.allocation.disk.watermark.low=5gb
|
||||||
|
- cluster.routing.allocation.disk.watermark.high=3gb
|
||||||
|
- cluster.routing.allocation.disk.watermark.flood_stage=2gb
|
||||||
|
- TZ=${TIMEZONE}
|
||||||
|
mem_limit: ${MEM_LIMIT}
|
||||||
|
ulimits:
|
||||||
|
memlock:
|
||||||
|
soft: -1
|
||||||
|
hard: -1
|
||||||
|
healthcheck:
|
||||||
|
test: ["CMD-SHELL", "curl http://localhost:9200"]
|
||||||
|
interval: 10s
|
||||||
|
timeout: 10s
|
||||||
|
retries: 120
|
||||||
|
networks:
|
||||||
|
- ragflow
|
||||||
|
restart: on-failure
|
||||||
|
|
||||||
|
|
||||||
postgres:
|
postgres:
|
||||||
image: postgres:15
|
image: postgres:15
|
||||||
@@ -54,6 +109,7 @@ services:
|
|||||||
- postgres_data:/var/lib/postgresql/data
|
- postgres_data:/var/lib/postgresql/data
|
||||||
networks:
|
networks:
|
||||||
- ragflow
|
- ragflow
|
||||||
|
mem_limit: ${MEM_LIMIT}
|
||||||
healthcheck:
|
healthcheck:
|
||||||
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DBNAME}"]
|
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DBNAME}"]
|
||||||
interval: 10s
|
interval: 10s
|
||||||
@@ -84,6 +140,7 @@ services:
|
|||||||
- SANDBOX_ENABLE_SECCOMP=${SANDBOX_ENABLE_SECCOMP:-false}
|
- SANDBOX_ENABLE_SECCOMP=${SANDBOX_ENABLE_SECCOMP:-false}
|
||||||
- SANDBOX_MAX_MEMORY=${SANDBOX_MAX_MEMORY:-256m}
|
- SANDBOX_MAX_MEMORY=${SANDBOX_MAX_MEMORY:-256m}
|
||||||
- SANDBOX_TIMEOUT=${SANDBOX_TIMEOUT:-10s}
|
- SANDBOX_TIMEOUT=${SANDBOX_TIMEOUT:-10s}
|
||||||
|
mem_limit: ${MEM_LIMIT}
|
||||||
healthcheck:
|
healthcheck:
|
||||||
test: ["CMD", "curl", "http://localhost:9385/healthz"]
|
test: ["CMD", "curl", "http://localhost:9385/healthz"]
|
||||||
interval: 10s
|
interval: 10s
|
||||||
@@ -108,6 +165,7 @@ services:
|
|||||||
networks:
|
networks:
|
||||||
- ragflow
|
- ragflow
|
||||||
restart: on-failure
|
restart: on-failure
|
||||||
|
mem_limit: ${MEM_LIMIT}
|
||||||
healthcheck:
|
healthcheck:
|
||||||
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
|
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
|
||||||
interval: 30s
|
interval: 30s
|
||||||
@@ -127,6 +185,7 @@ services:
|
|||||||
networks:
|
networks:
|
||||||
- ragflow
|
- ragflow
|
||||||
restart: on-failure
|
restart: on-failure
|
||||||
|
mem_limit: ${MEM_LIMIT}
|
||||||
healthcheck:
|
healthcheck:
|
||||||
test: ["CMD", "redis-cli", "-a", "${REDIS_PASSWORD}", "ping"]
|
test: ["CMD", "redis-cli", "-a", "${REDIS_PASSWORD}", "ping"]
|
||||||
interval: 5s
|
interval: 5s
|
||||||
|
|||||||
@@ -30,8 +30,8 @@ services:
|
|||||||
ports:
|
ports:
|
||||||
- ${SVR_HTTP_PORT}:9380
|
- ${SVR_HTTP_PORT}:9380
|
||||||
- ${ADMIN_SVR_HTTP_PORT}:9381
|
- ${ADMIN_SVR_HTTP_PORT}:9381
|
||||||
- 80:80
|
- 8000:80
|
||||||
- 443:443
|
- 8443:443
|
||||||
- 5678:5678
|
- 5678:5678
|
||||||
- 5679:5679
|
- 5679:5679
|
||||||
- 9382:9382 # entry for MCP (host_port:docker_port). The docker_port must match the value you set for `mcp-port` above.
|
- 9382:9382 # entry for MCP (host_port:docker_port). The docker_port must match the value you set for `mcp-port` above.
|
||||||
|
|||||||
4
docker/entrypoint.sh
Normal file → Executable file
4
docker/entrypoint.sh
Normal file → Executable file
@@ -161,7 +161,7 @@ function task_exe() {
|
|||||||
JEMALLOC_PATH="$(pkg-config --variable=libdir jemalloc)/libjemalloc.so"
|
JEMALLOC_PATH="$(pkg-config --variable=libdir jemalloc)/libjemalloc.so"
|
||||||
while true; do
|
while true; do
|
||||||
LD_PRELOAD="$JEMALLOC_PATH" \
|
LD_PRELOAD="$JEMALLOC_PATH" \
|
||||||
"$PY" rag/svr/task_executor.py "${host_id}_${consumer_id}"
|
"$PY" rag/svr/task_executor.py "${host_id}_${consumer_id}" || true
|
||||||
done
|
done
|
||||||
}
|
}
|
||||||
|
|
||||||
@@ -188,7 +188,7 @@ if [[ "${ENABLE_WEBSERVER}" -eq 1 ]]; then
|
|||||||
|
|
||||||
echo "Starting ragflow_server..."
|
echo "Starting ragflow_server..."
|
||||||
while true; do
|
while true; do
|
||||||
"$PY" api/ragflow_server.py
|
"$PY" api/ragflow_server_fastapi.py
|
||||||
done &
|
done &
|
||||||
fi
|
fi
|
||||||
|
|
||||||
|
|||||||
8
docs/_category_.json
Normal file
8
docs/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"label": "Get Started",
|
||||||
|
"position": 1,
|
||||||
|
"link": {
|
||||||
|
"type": "generated-index",
|
||||||
|
"description": "RAGFlow Quick Start"
|
||||||
|
}
|
||||||
|
}
|
||||||
229
docs/configurations.md
Normal file
229
docs/configurations.md
Normal file
@@ -0,0 +1,229 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
slug: /configurations
|
||||||
|
---
|
||||||
|
|
||||||
|
# Configuration
|
||||||
|
|
||||||
|
Configurations for deploying RAGFlow via Docker.
|
||||||
|
|
||||||
|
## Guidelines
|
||||||
|
|
||||||
|
When it comes to system configurations, you will need to manage the following files:
|
||||||
|
|
||||||
|
- [.env](https://github.com/infiniflow/ragflow/blob/main/docker/.env): Contains important environment variables for Docker.
|
||||||
|
- [service_conf.yaml.template](https://github.com/infiniflow/ragflow/blob/main/docker/service_conf.yaml.template): Configures the back-end services. It specifies the system-level configuration for RAGFlow and is used by its API server and task executor. Upon container startup, the `service_conf.yaml` file will be generated based on this template file. This process replaces any environment variables within the template, allowing for dynamic configuration tailored to the container's environment.
|
||||||
|
- [docker-compose.yml](https://github.com/infiniflow/ragflow/blob/main/docker/docker-compose.yml): The Docker Compose file for starting up the RAGFlow service.
|
||||||
|
|
||||||
|
To update the default HTTP serving port (80), go to [docker-compose.yml](https://github.com/infiniflow/ragflow/blob/main/docker/docker-compose.yml) and change `80:80`
|
||||||
|
to `<YOUR_SERVING_PORT>:80`.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
Updates to the above configurations require a reboot of all containers to take effect:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose -f docker/docker-compose.yml up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Docker Compose
|
||||||
|
|
||||||
|
- **docker-compose.yml**
|
||||||
|
Sets up environment for RAGFlow and its dependencies.
|
||||||
|
- **docker-compose-base.yml**
|
||||||
|
Sets up environment for RAGFlow's dependencies: Elasticsearch/[Infinity](https://github.com/infiniflow/infinity), MySQL, MinIO, and Redis.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
We do not actively maintain **docker-compose-CN-oc9.yml**, **docker-compose-gpu-CN-oc9.yml**, or **docker-compose-gpu.yml**, so use them at your own risk. However, you are welcome to file a pull request to improve any of them.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Docker environment variables
|
||||||
|
|
||||||
|
The [.env](https://github.com/infiniflow/ragflow/blob/main/docker/.env) file contains important environment variables for Docker.
|
||||||
|
|
||||||
|
### Elasticsearch
|
||||||
|
|
||||||
|
- `STACK_VERSION`
|
||||||
|
The version of Elasticsearch. Defaults to `8.11.3`
|
||||||
|
- `ES_PORT`
|
||||||
|
The port used to expose the Elasticsearch service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `1200`.
|
||||||
|
- `ELASTIC_PASSWORD`
|
||||||
|
The password for Elasticsearch.
|
||||||
|
|
||||||
|
### Kibana
|
||||||
|
|
||||||
|
- `KIBANA_PORT`
|
||||||
|
The port used to expose the Kibana service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `6601`.
|
||||||
|
- `KIBANA_USER`
|
||||||
|
The username for Kibana. Defaults to `rag_flow`.
|
||||||
|
- `KIBANA_PASSWORD`
|
||||||
|
The password for Kibana. Defaults to `infini_rag_flow`.
|
||||||
|
|
||||||
|
### Resource management
|
||||||
|
|
||||||
|
- `MEM_LIMIT`
|
||||||
|
The maximum amount of the memory, in bytes, that *a specific* Docker container can use while running. Defaults to `8073741824`.
|
||||||
|
|
||||||
|
### MySQL
|
||||||
|
|
||||||
|
- `MYSQL_PASSWORD`
|
||||||
|
The password for MySQL.
|
||||||
|
- `MYSQL_PORT`
|
||||||
|
The port used to expose the MySQL service to the host machine, allowing **external** access to the MySQL database running inside the Docker container. Defaults to `5455`.
|
||||||
|
|
||||||
|
### MinIO
|
||||||
|
|
||||||
|
RAGFlow utilizes MinIO as its object storage solution, leveraging its scalability to store and manage all uploaded files.
|
||||||
|
|
||||||
|
- `MINIO_CONSOLE_PORT`
|
||||||
|
The port used to expose the MinIO console interface to the host machine, allowing **external** access to the web-based console running inside the Docker container. Defaults to `9001`
|
||||||
|
- `MINIO_PORT`
|
||||||
|
The port used to expose the MinIO API service to the host machine, allowing **external** access to the MinIO object storage service running inside the Docker container. Defaults to `9000`.
|
||||||
|
- `MINIO_USER`
|
||||||
|
The username for MinIO.
|
||||||
|
- `MINIO_PASSWORD`
|
||||||
|
The password for MinIO.
|
||||||
|
|
||||||
|
### Redis
|
||||||
|
|
||||||
|
- `REDIS_PORT`
|
||||||
|
The port used to expose the Redis service to the host machine, allowing **external** access to the Redis service running inside the Docker container. Defaults to `6379`.
|
||||||
|
- `REDIS_PASSWORD`
|
||||||
|
The password for Redis.
|
||||||
|
|
||||||
|
### RAGFlow
|
||||||
|
|
||||||
|
- `SVR_HTTP_PORT`
|
||||||
|
The port used to expose RAGFlow's HTTP API service to the host machine, allowing **external** access to the service running inside the Docker container. Defaults to `9380`.
|
||||||
|
- `RAGFLOW-IMAGE`
|
||||||
|
The Docker image edition. Available editions:
|
||||||
|
|
||||||
|
- `infiniflow/ragflow:v0.21.1-slim` (default): The RAGFlow Docker image without embedding models.
|
||||||
|
- `infiniflow/ragflow:v0.21.1`: The RAGFlow Docker image with embedding models including:
|
||||||
|
- Built-in embedding models:
|
||||||
|
- `BAAI/bge-large-zh-v1.5`
|
||||||
|
- `maidalun1020/bce-embedding-base_v1`
|
||||||
|
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
If you cannot download the RAGFlow Docker image, try the following mirrors.
|
||||||
|
|
||||||
|
- For the `nightly-slim` edition:
|
||||||
|
- `RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly-slim` or,
|
||||||
|
- `RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:nightly-slim`.
|
||||||
|
- For the `nightly` edition:
|
||||||
|
- `RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:nightly` or,
|
||||||
|
- `RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:nightly`.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Timezone
|
||||||
|
|
||||||
|
- `TIMEZONE`
|
||||||
|
The local time zone. Defaults to `'Asia/Shanghai'`.
|
||||||
|
|
||||||
|
### Hugging Face mirror site
|
||||||
|
|
||||||
|
- `HF_ENDPOINT`
|
||||||
|
The mirror site for huggingface.co. It is disabled by default. You can uncomment this line if you have limited access to the primary Hugging Face domain.
|
||||||
|
|
||||||
|
### MacOS
|
||||||
|
|
||||||
|
- `MACOS`
|
||||||
|
Optimizations for macOS. It is disabled by default. You can uncomment this line if your OS is macOS.
|
||||||
|
|
||||||
|
### User registration
|
||||||
|
|
||||||
|
- `REGISTER_ENABLED`
|
||||||
|
- `1`: (Default) Enable user registration.
|
||||||
|
- `0`: Disable user registration.
|
||||||
|
|
||||||
|
## Service configuration
|
||||||
|
|
||||||
|
[service_conf.yaml.template](https://github.com/infiniflow/ragflow/blob/main/docker/service_conf.yaml.template) specifies the system-level configuration for RAGFlow and is used by its API server and task executor.
|
||||||
|
|
||||||
|
### `ragflow`
|
||||||
|
|
||||||
|
- `host`: The API server's IP address inside the Docker container. Defaults to `0.0.0.0`.
|
||||||
|
- `port`: The API server's serving port inside the Docker container. Defaults to `9380`.
|
||||||
|
|
||||||
|
### `mysql`
|
||||||
|
|
||||||
|
- `name`: The MySQL database name. Defaults to `rag_flow`.
|
||||||
|
- `user`: The username for MySQL.
|
||||||
|
- `password`: The password for MySQL.
|
||||||
|
- `port`: The MySQL serving port inside the Docker container. Defaults to `3306`.
|
||||||
|
- `max_connections`: The maximum number of concurrent connections to the MySQL database. Defaults to `100`.
|
||||||
|
- `stale_timeout`: Timeout in seconds.
|
||||||
|
|
||||||
|
### `minio`
|
||||||
|
|
||||||
|
- `user`: The username for MinIO.
|
||||||
|
- `password`: The password for MinIO.
|
||||||
|
- `host`: The MinIO serving IP *and* port inside the Docker container. Defaults to `minio:9000`.
|
||||||
|
|
||||||
|
### `oauth`
|
||||||
|
|
||||||
|
The OAuth configuration for signing up or signing in to RAGFlow using a third-party account.
|
||||||
|
|
||||||
|
- `<channel>`: Custom channel ID.
|
||||||
|
- `type`: Authentication type, options include `oauth2`, `oidc`, `github`. Default is `oauth2`, when `issuer` parameter is provided, defaults to `oidc`.
|
||||||
|
- `icon`: Icon ID, options include `github`, `sso`, default is `sso`.
|
||||||
|
- `display_name`: Channel name, defaults to the Title Case format of the channel ID.
|
||||||
|
- `client_id`: Required, unique identifier assigned to the client application.
|
||||||
|
- `client_secret`: Required, secret key for the client application, used for communication with the authentication server.
|
||||||
|
- `authorization_url`: Base URL for obtaining user authorization.
|
||||||
|
- `token_url`: URL for exchanging authorization code and obtaining access token.
|
||||||
|
- `userinfo_url`: URL for obtaining user information (username, email, etc.).
|
||||||
|
- `issuer`: Base URL of the identity provider. OIDC clients can dynamically obtain the identity provider's metadata (`authorization_url`, `token_url`, `userinfo_url`) through `issuer`.
|
||||||
|
- `scope`: Requested permission scope, a space-separated string. For example, `openid profile email`.
|
||||||
|
- `redirect_uri`: Required, URI to which the authorization server redirects during the authentication flow to return results. Must match the callback URI registered with the authentication server. Format: `https://your-app.com/v1/user/oauth/callback/<channel>`. For local configuration, you can directly use `http://127.0.0.1:80/v1/user/oauth/callback/<channel>`.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
The following are best practices for configuring various third-party authentication methods. You can configure one or multiple third-party authentication methods for Ragflow:
|
||||||
|
```yaml
|
||||||
|
oauth:
|
||||||
|
oauth2:
|
||||||
|
display_name: "OAuth2"
|
||||||
|
client_id: "your_client_id"
|
||||||
|
client_secret: "your_client_secret"
|
||||||
|
authorization_url: "https://your-oauth-provider.com/oauth/authorize"
|
||||||
|
token_url: "https://your-oauth-provider.com/oauth/token"
|
||||||
|
userinfo_url: "https://your-oauth-provider.com/oauth/userinfo"
|
||||||
|
redirect_uri: "https://your-app.com/v1/user/oauth/callback/oauth2"
|
||||||
|
|
||||||
|
oidc:
|
||||||
|
display_name: "OIDC"
|
||||||
|
client_id: "your_client_id"
|
||||||
|
client_secret: "your_client_secret"
|
||||||
|
issuer: "https://your-oauth-provider.com/oidc"
|
||||||
|
scope: "openid email profile"
|
||||||
|
redirect_uri: "https://your-app.com/v1/user/oauth/callback/oidc"
|
||||||
|
|
||||||
|
github:
|
||||||
|
# https://docs.github.com/en/apps/oauth-apps/building-oauth-apps/creating-an-oauth-app
|
||||||
|
type: "github"
|
||||||
|
icon: "github"
|
||||||
|
display_name: "Github"
|
||||||
|
client_id: "your_client_id"
|
||||||
|
client_secret: "your_client_secret"
|
||||||
|
redirect_uri: "https://your-app.com/v1/user/oauth/callback/github"
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
### `user_default_llm`
|
||||||
|
|
||||||
|
The default LLM to use for a new RAGFlow user. It is disabled by default. To enable this feature, uncomment the corresponding lines in **service_conf.yaml.template**.
|
||||||
|
|
||||||
|
- `factory`: The LLM supplier. Available options:
|
||||||
|
- `"OpenAI"`
|
||||||
|
- `"DeepSeek"`
|
||||||
|
- `"Moonshot"`
|
||||||
|
- `"Tongyi-Qianwen"`
|
||||||
|
- `"VolcEngine"`
|
||||||
|
- `"ZHIPU-AI"`
|
||||||
|
- `api_key`: The API key for the specified LLM. You will need to apply for your model API key online.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
If you do not set the default LLM here, configure the default LLM on the **Settings** page in the RAGFlow UI.
|
||||||
|
:::
|
||||||
8
docs/contribution/_category_.json
Normal file
8
docs/contribution/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"label": "Contribution",
|
||||||
|
"position": 8,
|
||||||
|
"link": {
|
||||||
|
"type": "generated-index",
|
||||||
|
"description": "Miscellaneous contribution guides."
|
||||||
|
}
|
||||||
|
}
|
||||||
57
docs/contribution/contributing.md
Normal file
57
docs/contribution/contributing.md
Normal file
@@ -0,0 +1,57 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
slug: /contributing
|
||||||
|
---
|
||||||
|
|
||||||
|
# Contribution guidelines
|
||||||
|
|
||||||
|
General guidelines for RAGFlow's community contributors.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
This document offers guidelines and major considerations for submitting your contributions to RAGFlow.
|
||||||
|
|
||||||
|
- To report a bug, file a [GitHub issue](https://github.com/infiniflow/ragflow/issues/new/choose) with us.
|
||||||
|
- For further questions, you can explore existing discussions or initiate a new one in [Discussions](https://github.com/orgs/infiniflow/discussions).
|
||||||
|
|
||||||
|
## What you can contribute
|
||||||
|
|
||||||
|
The list below mentions some contributions you can make, but it is not a complete list.
|
||||||
|
|
||||||
|
- Proposing or implementing new features
|
||||||
|
- Fixing a bug
|
||||||
|
- Adding test cases or demos
|
||||||
|
- Posting a blog or tutorial
|
||||||
|
- Updates to existing documents, codes, or annotations.
|
||||||
|
- Suggesting more user-friendly error codes
|
||||||
|
|
||||||
|
## File a pull request (PR)
|
||||||
|
|
||||||
|
### General workflow
|
||||||
|
|
||||||
|
1. Fork our GitHub repository.
|
||||||
|
2. Clone your fork to your local machine:
|
||||||
|
`git clone git@github.com:<yourname>/ragflow.git`
|
||||||
|
3. Create a local branch:
|
||||||
|
`git checkout -b my-branch`
|
||||||
|
4. Provide sufficient information in your commit message
|
||||||
|
`git commit -m 'Provide sufficient info in your commit message'`
|
||||||
|
5. Commit changes to your local branch, and push to GitHub: (include necessary commit message)
|
||||||
|
`git push origin my-branch.`
|
||||||
|
6. Submit a pull request for review.
|
||||||
|
|
||||||
|
### Before filing a PR
|
||||||
|
|
||||||
|
- Consider splitting a large PR into multiple smaller, standalone PRs to keep a traceable development history.
|
||||||
|
- Ensure that your PR addresses just one issue, or keep any unrelated changes small.
|
||||||
|
- Add test cases when contributing new features. They demonstrate that your code functions correctly and protect against potential issues from future changes.
|
||||||
|
|
||||||
|
### Describing your PR
|
||||||
|
|
||||||
|
- Ensure that your PR title is concise and clear, providing all the required information.
|
||||||
|
- Refer to a corresponding GitHub issue in your PR description if applicable.
|
||||||
|
- Include sufficient design details for *breaking changes* or *API changes* in your description.
|
||||||
|
|
||||||
|
### Reviewing & merging a PR
|
||||||
|
|
||||||
|
Ensure that your PR passes all Continuous Integration (CI) tests before merging it.
|
||||||
8
docs/develop/_category_.json
Normal file
8
docs/develop/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"label": "Developers",
|
||||||
|
"position": 4,
|
||||||
|
"link": {
|
||||||
|
"type": "generated-index",
|
||||||
|
"description": "Guides for hardcore developers"
|
||||||
|
}
|
||||||
|
}
|
||||||
18
docs/develop/acquire_ragflow_api_key.md
Normal file
18
docs/develop/acquire_ragflow_api_key.md
Normal file
@@ -0,0 +1,18 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 4
|
||||||
|
slug: /acquire_ragflow_api_key
|
||||||
|
---
|
||||||
|
|
||||||
|
# Acquire RAGFlow API key
|
||||||
|
|
||||||
|
An API key is required for the RAGFlow server to authenticate your HTTP/Python or MCP requests. This documents provides instructions on obtaining a RAGFlow API key.
|
||||||
|
|
||||||
|
1. Click your avatar in the top right corner of the RAGFlow UI to access the configuration page.
|
||||||
|
2. Click **API** to switch to the **API** page.
|
||||||
|
3. Obtain a RAGFlow API key:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
See the [RAGFlow HTTP API reference](../references/http_api_reference.md) or the [RAGFlow Python API reference](../references/python_api_reference.md) for a complete reference of RAGFlow's HTTP or Python APIs.
|
||||||
|
:::
|
||||||
92
docs/develop/build_docker_image.mdx
Normal file
92
docs/develop/build_docker_image.mdx
Normal file
@@ -0,0 +1,92 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
slug: /build_docker_image
|
||||||
|
---
|
||||||
|
|
||||||
|
# Build RAGFlow Docker image
|
||||||
|
import Tabs from '@theme/Tabs';
|
||||||
|
import TabItem from '@theme/TabItem';
|
||||||
|
|
||||||
|
A guide explaining how to build a RAGFlow Docker image from its source code. By following this guide, you'll be able to create a local Docker image that can be used for development, debugging, or testing purposes.
|
||||||
|
|
||||||
|
## Target Audience
|
||||||
|
|
||||||
|
- Developers who have added new features or modified the existing code and require a Docker image to view and debug their changes.
|
||||||
|
- Developers seeking to build a RAGFlow Docker image for an ARM64 platform.
|
||||||
|
- Testers aiming to explore the latest features of RAGFlow in a Docker image.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- CPU ≥ 4 cores
|
||||||
|
- RAM ≥ 16 GB
|
||||||
|
- Disk ≥ 50 GB
|
||||||
|
- Docker ≥ 24.0.0 & Docker Compose ≥ v2.26.1
|
||||||
|
|
||||||
|
## Build a Docker image
|
||||||
|
|
||||||
|
<Tabs
|
||||||
|
defaultValue="without"
|
||||||
|
values={[
|
||||||
|
{label: 'Build a Docker image without embedding models', value: 'without'},
|
||||||
|
{label: 'Build a Docker image including embedding models', value: 'including'}
|
||||||
|
]}>
|
||||||
|
<TabItem value="without">
|
||||||
|
|
||||||
|
This image is approximately 2 GB in size and relies on external LLM and embedding services.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
- While we also test RAGFlow on ARM64 platforms, we do not maintain RAGFlow Docker images for ARM. However, you can build an image yourself on a `linux/arm64` or `darwin/arm64` host machine as well.
|
||||||
|
- For ARM64 platforms, please upgrade the `xgboost` version in **pyproject.toml** to `1.6.0` and ensure **unixODBC** is properly installed.
|
||||||
|
:::
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/infiniflow/ragflow.git
|
||||||
|
cd ragflow/
|
||||||
|
uv run download_deps.py
|
||||||
|
docker build -f Dockerfile.deps -t infiniflow/ragflow_deps .
|
||||||
|
docker build --build-arg LIGHTEN=1 -f Dockerfile -t infiniflow/ragflow:nightly-slim .
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
</TabItem>
|
||||||
|
<TabItem value="including">
|
||||||
|
|
||||||
|
This image is approximately 9 GB in size. As it includes embedding models, it relies on external LLM services only.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
- While we also test RAGFlow on ARM64 platforms, we do not maintain RAGFlow Docker images for ARM. However, you can build an image yourself on a `linux/arm64` or `darwin/arm64` host machine as well.
|
||||||
|
- For ARM64 platforms, please upgrade the `xgboost` version in **pyproject.toml** to `1.6.0` and ensure **unixODBC** is properly installed.
|
||||||
|
:::
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/infiniflow/ragflow.git
|
||||||
|
cd ragflow/
|
||||||
|
uv run download_deps.py
|
||||||
|
docker build -f Dockerfile.deps -t infiniflow/ragflow_deps .
|
||||||
|
docker build -f Dockerfile -t infiniflow/ragflow:nightly .
|
||||||
|
```
|
||||||
|
|
||||||
|
</TabItem>
|
||||||
|
</Tabs>
|
||||||
|
|
||||||
|
## Launch a RAGFlow Service from Docker for MacOS
|
||||||
|
|
||||||
|
After building the infiniflow/ragflow:nightly-slim image, you are ready to launch a fully-functional RAGFlow service with all the required components, such as Elasticsearch, MySQL, MinIO, Redis, and more.
|
||||||
|
|
||||||
|
## Example: Apple M2 Pro (Sequoia)
|
||||||
|
|
||||||
|
1. Edit Docker Compose Configuration
|
||||||
|
|
||||||
|
Open the `docker/.env` file. Find the `RAGFLOW_IMAGE` setting and change the image reference from `infiniflow/ragflow:v0.21.1-slim` to `infiniflow/ragflow:nightly-slim` to use the pre-built image.
|
||||||
|
|
||||||
|
|
||||||
|
2. Launch the Service
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd docker
|
||||||
|
$ docker compose -f docker-compose-macos.yml up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Access the RAGFlow Service
|
||||||
|
|
||||||
|
Once the setup is complete, open your web browser and navigate to http://127.0.0.1 or your server's \<IP_ADDRESS\>; (the default port is \<PORT\> = 80). You will be directed to the RAGFlow welcome page. Enjoy!🍻
|
||||||
145
docs/develop/launch_ragflow_from_source.md
Normal file
145
docs/develop/launch_ragflow_from_source.md
Normal file
@@ -0,0 +1,145 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 2
|
||||||
|
slug: /launch_ragflow_from_source
|
||||||
|
---
|
||||||
|
|
||||||
|
# Launch service from source
|
||||||
|
|
||||||
|
A guide explaining how to set up a RAGFlow service from its source code. By following this guide, you'll be able to debug using the source code.
|
||||||
|
|
||||||
|
## Target audience
|
||||||
|
|
||||||
|
Developers who have added new features or modified existing code and wish to debug using the source code, *provided that* their machine has the target deployment environment set up.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- CPU ≥ 4 cores
|
||||||
|
- RAM ≥ 16 GB
|
||||||
|
- Disk ≥ 50 GB
|
||||||
|
- Docker ≥ 24.0.0 & Docker Compose ≥ v2.26.1
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
If you have not installed Docker on your local machine (Windows, Mac, or Linux), see the [Install Docker Engine](https://docs.docker.com/engine/install/) guide.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Launch a service from source
|
||||||
|
|
||||||
|
To launch a RAGFlow service from source code:
|
||||||
|
|
||||||
|
### Clone the RAGFlow repository
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/infiniflow/ragflow.git
|
||||||
|
cd ragflow/
|
||||||
|
```
|
||||||
|
|
||||||
|
### Install Python dependencies
|
||||||
|
|
||||||
|
1. Install uv:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pipx install uv
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install Python dependencies:
|
||||||
|
- slim:
|
||||||
|
```bash
|
||||||
|
uv sync --python 3.10 # install RAGFlow dependent python modules
|
||||||
|
```
|
||||||
|
- full:
|
||||||
|
```bash
|
||||||
|
uv sync --python 3.10 --all-extras # install RAGFlow dependent python modules
|
||||||
|
```
|
||||||
|
*A virtual environment named `.venv` is created, and all Python dependencies are installed into the new environment.*
|
||||||
|
|
||||||
|
### Launch third-party services
|
||||||
|
|
||||||
|
The following command launches the 'base' services (MinIO, Elasticsearch, Redis, and MySQL) using Docker Compose:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose -f docker/docker-compose-base.yml up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
### Update `host` and `port` Settings for Third-party Services
|
||||||
|
|
||||||
|
1. Add the following line to `/etc/hosts` to resolve all hosts specified in **docker/service_conf.yaml.template** to `127.0.0.1`:
|
||||||
|
|
||||||
|
```
|
||||||
|
127.0.0.1 es01 infinity mysql minio redis
|
||||||
|
```
|
||||||
|
|
||||||
|
2. In **docker/service_conf.yaml.template**, update mysql port to `5455` and es port to `1200`, as specified in **docker/.env**.
|
||||||
|
|
||||||
|
### Launch the RAGFlow backend service
|
||||||
|
|
||||||
|
1. Comment out the `nginx` line in **docker/entrypoint.sh**.
|
||||||
|
|
||||||
|
```
|
||||||
|
# /usr/sbin/nginx
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Activate the Python virtual environment:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
source .venv/bin/activate
|
||||||
|
export PYTHONPATH=$(pwd)
|
||||||
|
```
|
||||||
|
|
||||||
|
3. **Optional:** If you cannot access HuggingFace, set the HF_ENDPOINT environment variable to use a mirror site:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export HF_ENDPOINT=https://hf-mirror.com
|
||||||
|
```
|
||||||
|
|
||||||
|
4. Check the configuration in **conf/service_conf.yaml**, ensuring all hosts and ports are correctly set.
|
||||||
|
|
||||||
|
5. Run the **entrypoint.sh** script to launch the backend service:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
JEMALLOC_PATH=$(pkg-config --variable=libdir jemalloc)/libjemalloc.so;
|
||||||
|
LD_PRELOAD=$JEMALLOC_PATH python rag/svr/task_executor.py 1;
|
||||||
|
```
|
||||||
|
```shell
|
||||||
|
python api/ragflow_server.py;
|
||||||
|
```
|
||||||
|
|
||||||
|
### Launch the RAGFlow frontend service
|
||||||
|
|
||||||
|
1. Navigate to the `web` directory and install the frontend dependencies:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd web
|
||||||
|
npm install
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Update `proxy.target` in **.umirc.ts** to `http://127.0.0.1:9380`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
vim .umirc.ts
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Start up the RAGFlow frontend service:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
npm run dev
|
||||||
|
```
|
||||||
|
|
||||||
|
*The following message appears, showing the IP address and port number of your frontend service:*
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Access the RAGFlow service
|
||||||
|
|
||||||
|
In your web browser, enter `http://127.0.0.1:<PORT>/`, ensuring the port number matches that shown in the screenshot above.
|
||||||
|
|
||||||
|
### Stop the RAGFlow service when the development is done
|
||||||
|
|
||||||
|
1. Stop the RAGFlow frontend service:
|
||||||
|
```bash
|
||||||
|
pkill npm
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Stop the RAGFlow backend service:
|
||||||
|
```bash
|
||||||
|
pkill -f "docker/entrypoint.sh"
|
||||||
|
```
|
||||||
8
docs/develop/mcp/_category_.json
Normal file
8
docs/develop/mcp/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"label": "MCP",
|
||||||
|
"position": 40,
|
||||||
|
"link": {
|
||||||
|
"type": "generated-index",
|
||||||
|
"description": "Guides and references on accessing RAGFlow's datasets via MCP."
|
||||||
|
}
|
||||||
|
}
|
||||||
212
docs/develop/mcp/launch_mcp_server.md
Normal file
212
docs/develop/mcp/launch_mcp_server.md
Normal file
@@ -0,0 +1,212 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
slug: /launch_mcp_server
|
||||||
|
---
|
||||||
|
|
||||||
|
# Launch RAGFlow MCP server
|
||||||
|
|
||||||
|
Launch an MCP server from source or via Docker.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A RAGFlow Model Context Protocol (MCP) server is designed as an independent component to complement the RAGFlow server. Note that an MCP server must operate alongside a properly functioning RAGFlow server.
|
||||||
|
|
||||||
|
An MCP server can start up in either self-host mode (default) or host mode:
|
||||||
|
|
||||||
|
- **Self-host mode**:
|
||||||
|
When launching an MCP server in self-host mode, you must provide an API key to authenticate the MCP server with the RAGFlow server. In this mode, the MCP server can access *only* the datasets of a specified tenant on the RAGFlow server.
|
||||||
|
- **Host mode**:
|
||||||
|
In host mode, each MCP client can access their own datasets on the RAGFlow server. However, each client request must include a valid API key to authenticate the client with the RAGFlow server.
|
||||||
|
|
||||||
|
Once a connection is established, an MCP server communicates with its client in MCP HTTP+SSE (Server-Sent Events) mode, unidirectionally pushing responses from the RAGFlow server to its client in real time.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
1. Ensure RAGFlow is upgraded to v0.18.0 or later.
|
||||||
|
2. Have your RAGFlow API key ready. See [Acquire a RAGFlow API key](../acquire_ragflow_api_key.md).
|
||||||
|
|
||||||
|
:::tip INFO
|
||||||
|
If you wish to try out our MCP server without upgrading RAGFlow, community contributor [yiminghub2024](https://github.com/yiminghub2024) 👏 shares their recommended steps [here](#launch-an-mcp-server-without-upgrading-ragflow).
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Launch an MCP server
|
||||||
|
|
||||||
|
You can start an MCP server either from source code or via Docker.
|
||||||
|
|
||||||
|
### Launch from source code
|
||||||
|
|
||||||
|
1. Ensure that a RAGFlow server v0.18.0+ is properly running.
|
||||||
|
2. Launch the MCP server:
|
||||||
|
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Launch the MCP server to work in self-host mode, run either of the following
|
||||||
|
uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base-url=http://127.0.0.1:9380 --api-key=ragflow-xxxxx
|
||||||
|
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base-url=http://127.0.0.1:9380 --mode=self-host --api-key=ragflow-xxxxx
|
||||||
|
|
||||||
|
# To launch the MCP server to work in host mode, run the following instead:
|
||||||
|
# uv run mcp/server/server.py --host=127.0.0.1 --port=9382 --base-url=http://127.0.0.1:9380 --mode=host
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
|
||||||
|
- `host`: The MCP server's host address.
|
||||||
|
- `port`: The MCP server's listening port.
|
||||||
|
- `base_url`: The address of the running RAGFlow server.
|
||||||
|
- `mode`: The launch mode.
|
||||||
|
- `self-host`: (default) self-host mode.
|
||||||
|
- `host`: host mode.
|
||||||
|
- `api_key`: Required in self-host mode to authenticate the MCP server with the RAGFlow server. See [here](../acquire_ragflow_api_key.md) for instructions on acquiring an API key.
|
||||||
|
|
||||||
|
### Transports
|
||||||
|
|
||||||
|
The RAGFlow MCP server supports two transports: the legacy SSE transport (served at `/sse`), introduced on November 5, 2024 and deprecated on March 26, 2025, and the streamable-HTTP transport (served at `/mcp`). The legacy SSE transport and the streamable HTTP transport with JSON responses are enabled by default. To disable either transport, use the flags `--no-transport-sse-enabled` or `--no-transport-streamable-http-enabled`. To disable JSON responses for the streamable HTTP transport, use the `--no-json-response` flag.
|
||||||
|
|
||||||
|
### Launch from Docker
|
||||||
|
|
||||||
|
#### 1. Enable MCP server
|
||||||
|
|
||||||
|
The MCP server is designed as an optional component that complements the RAGFlow server and disabled by default. To enable MCP server:
|
||||||
|
|
||||||
|
1. Navigate to **docker/docker-compose.yml**.
|
||||||
|
2. Uncomment the `services.ragflow.command` section as shown below:
|
||||||
|
|
||||||
|
```yaml {6-13}
|
||||||
|
services:
|
||||||
|
ragflow:
|
||||||
|
...
|
||||||
|
image: ${RAGFLOW_IMAGE}
|
||||||
|
# Example configuration to set up an MCP server:
|
||||||
|
command:
|
||||||
|
- --enable-mcpserver
|
||||||
|
- --mcp-host=0.0.0.0
|
||||||
|
- --mcp-port=9382
|
||||||
|
- --mcp-base-url=http://127.0.0.1:9380
|
||||||
|
- --mcp-script-path=/ragflow/mcp/server/server.py
|
||||||
|
- --mcp-mode=self-host
|
||||||
|
- --mcp-host-api-key=ragflow-xxxxxxx
|
||||||
|
# Optional transport flags for the RAGFlow MCP server.
|
||||||
|
# If you set `mcp-mode` to `host`, you must add the --no-transport-streamable-http-enabled flag, because the streamable-HTTP transport is not yet supported in host mode.
|
||||||
|
# The legacy SSE transport and the streamable-HTTP transport with JSON responses are enabled by default.
|
||||||
|
# To disable a specific transport or JSON responses for the streamable-HTTP transport, use the corresponding flag(s):
|
||||||
|
# - --no-transport-sse-enabled # Disables the legacy SSE endpoint (/sse)
|
||||||
|
# - --no-transport-streamable-http-enabled # Disables the streamable-HTTP transport (served at the /mcp endpoint)
|
||||||
|
# - --no-json-response # Disables JSON responses for the streamable-HTTP transport
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
|
||||||
|
- `mcp-host`: The MCP server's host address.
|
||||||
|
- `mcp-port`: The MCP server's listening port.
|
||||||
|
- `mcp-base-url`: The address of the running RAGFlow server.
|
||||||
|
- `mcp-script-path`: The file path to the MCP server’s main script.
|
||||||
|
- `mcp-mode`: The launch mode.
|
||||||
|
- `self-host`: (default) self-host mode.
|
||||||
|
- `host`: host mode.
|
||||||
|
- `mcp-host-api_key`: Required in self-host mode to authenticate the MCP server with the RAGFlow server. See [here](../acquire_ragflow_api_key.md) for instructions on acquiring an API key.
|
||||||
|
|
||||||
|
:::tip INFO
|
||||||
|
If you set `mcp-mode` to `host`, you must add the `--no-transport-streamable-http-enabled` flag, because the streamable-HTTP transport is not yet supported in host mode.
|
||||||
|
:::
|
||||||
|
|
||||||
|
#### 2. Launch a RAGFlow server with an MCP server
|
||||||
|
|
||||||
|
Run `docker compose -f docker-compose.yml up` to launch the RAGFlow server together with the MCP server.
|
||||||
|
|
||||||
|
*The following ASCII art confirms a successful launch:*
|
||||||
|
|
||||||
|
```bash
|
||||||
|
ragflow-server | Starting MCP Server on 0.0.0.0:9382 with base URL http://127.0.0.1:9380...
|
||||||
|
ragflow-server | Starting 1 task executor(s) on host 'dd0b5e07e76f'...
|
||||||
|
ragflow-server | 2025-04-18 15:41:18,816 INFO 27 ragflow_server log path: /ragflow/logs/ragflow_server.log, log levels: {'peewee': 'WARNING', 'pdfminer': 'WARNING', 'root': 'INFO'}
|
||||||
|
ragflow-server |
|
||||||
|
ragflow-server | __ __ ____ ____ ____ _____ ______ _______ ____
|
||||||
|
ragflow-server | | \/ |/ ___| _ \ / ___|| ____| _ \ \ / / ____| _ \
|
||||||
|
ragflow-server | | |\/| | | | |_) | \___ \| _| | |_) \ \ / /| _| | |_) |
|
||||||
|
ragflow-server | | | | | |___| __/ ___) | |___| _ < \ V / | |___| _ <
|
||||||
|
ragflow-server | |_| |_|\____|_| |____/|_____|_| \_\ \_/ |_____|_| \_\
|
||||||
|
ragflow-server |
|
||||||
|
ragflow-server | MCP launch mode: self-host
|
||||||
|
ragflow-server | MCP host: 0.0.0.0
|
||||||
|
ragflow-server | MCP port: 9382
|
||||||
|
ragflow-server | MCP base_url: http://127.0.0.1:9380
|
||||||
|
ragflow-server | INFO: Started server process [26]
|
||||||
|
ragflow-server | INFO: Waiting for application startup.
|
||||||
|
ragflow-server | INFO: Application startup complete.
|
||||||
|
ragflow-server | INFO: Uvicorn running on http://0.0.0.0:9382 (Press CTRL+C to quit)
|
||||||
|
ragflow-server | 2025-04-18 15:41:20,469 INFO 27 found 0 gpus
|
||||||
|
ragflow-server | 2025-04-18 15:41:23,263 INFO 27 init database on cluster mode successfully
|
||||||
|
ragflow-server | 2025-04-18 15:41:25,318 INFO 27 load_model /ragflow/rag/res/deepdoc/det.onnx uses CPU
|
||||||
|
ragflow-server | 2025-04-18 15:41:25,367 INFO 27 load_model /ragflow/rag/res/deepdoc/rec.onnx uses CPU
|
||||||
|
ragflow-server | ____ ___ ______ ______ __
|
||||||
|
ragflow-server | / __ \ / | / ____// ____// /____ _ __
|
||||||
|
ragflow-server | / /_/ // /| | / / __ / /_ / // __ \| | /| / /
|
||||||
|
ragflow-server | / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
|
||||||
|
ragflow-server | /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
|
||||||
|
ragflow-server |
|
||||||
|
ragflow-server |
|
||||||
|
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||||
|
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 project base: /ragflow
|
||||||
|
ragflow-server | 2025-04-18 15:41:29,088 INFO 27 Current configs, from /ragflow/conf/service_conf.yaml:
|
||||||
|
ragflow-server | ragflow: {'host': '0.0.0.0', 'http_port': 9380}
|
||||||
|
...
|
||||||
|
ragflow-server | * Running on all addresses (0.0.0.0)
|
||||||
|
ragflow-server | * Running on http://127.0.0.1:9380
|
||||||
|
ragflow-server | * Running on http://172.19.0.6:9380
|
||||||
|
ragflow-server | ______ __ ______ __
|
||||||
|
ragflow-server | /_ __/___ ______/ /__ / ____/ _____ _______ __/ /_____ _____
|
||||||
|
ragflow-server | / / / __ `/ ___/ //_/ / __/ | |/_/ _ \/ ___/ / / / __/ __ \/ ___/
|
||||||
|
ragflow-server | / / / /_/ (__ ) ,< / /____> </ __/ /__/ /_/ / /_/ /_/ / /
|
||||||
|
ragflow-server | /_/ \__,_/____/_/|_| /_____/_/|_|\___/\___/\__,_/\__/\____/_/
|
||||||
|
ragflow-server |
|
||||||
|
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 TaskExecutor: RAGFlow version: v0.18.0-285-gb2c299fa full
|
||||||
|
ragflow-server | 2025-04-18 15:41:34,501 INFO 32 Use Elasticsearch http://es01:9200 as the doc engine.
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Launch an MCP server without upgrading RAGFlow
|
||||||
|
|
||||||
|
:::info KUDOS
|
||||||
|
This section is contributed by our community contributor [yiminghub2024](https://github.com/yiminghub2024). 👏
|
||||||
|
:::
|
||||||
|
|
||||||
|
1. Prepare all MCP-specific files and directories.
|
||||||
|
i. Copy the [mcp/](https://github.com/infiniflow/ragflow/tree/main/mcp) directory to your local working directory.
|
||||||
|
ii. Copy [docker/docker-compose.yml](https://github.com/infiniflow/ragflow/blob/main/docker/docker-compose.yml) locally.
|
||||||
|
iii. Copy [docker/entrypoint.sh](https://github.com/infiniflow/ragflow/blob/main/docker/entrypoint.sh) locally.
|
||||||
|
iv. Install the required dependencies using `uv`:
|
||||||
|
- Run `uv add mcp` or
|
||||||
|
- Copy [pyproject.toml](https://github.com/infiniflow/ragflow/blob/main/pyproject.toml) locally and run `uv sync --python 3.10 --all-extras`.
|
||||||
|
2. Edit **docker-compose.yml** to enable MCP (disabled by default).
|
||||||
|
3. Launch the MCP server:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose -f docker-compose.yml up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
### Check MCP server status
|
||||||
|
|
||||||
|
Run the following to check the logs the RAGFlow server and the MCP server:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker logs ragflow-server
|
||||||
|
```
|
||||||
|
|
||||||
|
## Security considerations
|
||||||
|
|
||||||
|
As MCP technology is still at early stage and no official best practices for authentication or authorization have been established, RAGFlow currently uses [API key](./acquire_ragflow_api_key.md) to validate identity for the operations described earlier. However, in public environments, this makeshift solution could expose your MCP server to potential network attacks. Therefore, when running a local SSE server, it is recommended to bind only to localhost (`127.0.0.1`) rather than to all interfaces (`0.0.0.0`).
|
||||||
|
|
||||||
|
For further guidance, see the [official MCP documentation](https://modelcontextprotocol.io/docs/concepts/transports#security-considerations).
|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### When to use an API key for authentication?
|
||||||
|
|
||||||
|
The use of an API key depends on the operating mode of your MCP server.
|
||||||
|
|
||||||
|
- **Self-host mode** (default):
|
||||||
|
When starting the MCP server in self-host mode, you should provide an API key when launching it to authenticate it with the RAGFlow server:
|
||||||
|
- If launching from source, include the API key in the command.
|
||||||
|
- If launching from Docker, update the API key in **docker/docker-compose.yml**.
|
||||||
|
- **Host mode**:
|
||||||
|
If your RAGFlow MCP server is working in host mode, include the API key in the `headers` of your client requests to authenticate your client with the RAGFlow server. An example is available [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
||||||
241
docs/develop/mcp/mcp_client_example.md
Normal file
241
docs/develop/mcp/mcp_client_example.md
Normal file
@@ -0,0 +1,241 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 3
|
||||||
|
slug: /mcp_client
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
# RAGFlow MCP client examples
|
||||||
|
|
||||||
|
Python and curl MCP client examples.
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
## Example MCP Python client
|
||||||
|
|
||||||
|
We provide a *prototype* MCP client example for testing [here](https://github.com/infiniflow/ragflow/blob/main/mcp/client/client.py).
|
||||||
|
|
||||||
|
:::info IMPORTANT
|
||||||
|
If your MCP server is running in host mode, include your acquired API key in your client's `headers` when connecting asynchronously to it:
|
||||||
|
|
||||||
|
```python
|
||||||
|
async with sse_client("http://localhost:9382/sse", headers={"api_key": "YOUR_KEY_HERE"}) as streams:
|
||||||
|
# Rest of your code...
|
||||||
|
```
|
||||||
|
|
||||||
|
Alternatively, to comply with [OAuth 2.1 Section 5](https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-12#section-5), you can run the following code *instead* to connect to your MCP server:
|
||||||
|
|
||||||
|
```python
|
||||||
|
async with sse_client("http://localhost:9382/sse", headers={"Authorization": "YOUR_KEY_HERE"}) as streams:
|
||||||
|
# Rest of your code...
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Use curl to interact with the RAGFlow MCP server
|
||||||
|
|
||||||
|
When interacting with the MCP server via HTTP requests, follow this initialization sequence:
|
||||||
|
|
||||||
|
1. **The client sends an `initialize` request** with protocol version and capabilities.
|
||||||
|
2. **The server replies with an `initialize` response**, including the supported protocol and capabilities.
|
||||||
|
3. **The client confirms readiness with an `initialized` notification**.
|
||||||
|
_The connection is established between the client and the server, and further operations (such as tool listing) may proceed._
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
For more information about this initialization process, see [here](https://modelcontextprotocol.io/docs/concepts/architecture#1-initialization).
|
||||||
|
:::
|
||||||
|
|
||||||
|
In the following sections, we will walk you through a complete tool calling process.
|
||||||
|
|
||||||
|
### 1. Obtain a session ID
|
||||||
|
|
||||||
|
Each curl request with the MCP server must include a session ID:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ curl -N -H "api_key: YOUR_API_KEY" http://127.0.0.1:9382/sse
|
||||||
|
```
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
See [here](../acquire_ragflow_api_key.md) for information about acquiring an API key.
|
||||||
|
:::
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
The transport will stream messages such as tool results, server responses, and keep-alive pings.
|
||||||
|
|
||||||
|
_The server returns the session ID:_
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: endpoint
|
||||||
|
data: /messages/?session_id=5c6600ef61b845a788ddf30dceb25c54
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. Send an `Initialize` request
|
||||||
|
|
||||||
|
The client sends an `initialize` request with protocol version and capabilities:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
session_id="5c6600ef61b845a788ddf30dceb25c54" && \
|
||||||
|
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 1,
|
||||||
|
"method": "initialize",
|
||||||
|
"params": {
|
||||||
|
"protocolVersion": "1.0",
|
||||||
|
"capabilities": {},
|
||||||
|
"clientInfo": {
|
||||||
|
"name": "ragflow-mcp-client",
|
||||||
|
"version": "0.1"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}' && \
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
_The server replies with an `initialize` response, including the supported protocol and capabilities:_
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: message
|
||||||
|
data: {"jsonrpc":"2.0","id":1,"result":{"protocolVersion":"2025-03-26","capabilities":{"experimental":{"headers":{"host":"127.0.0.1:9382","user-agent":"curl/8.7.1","accept":"*/*","api_key":"ragflow-xxxxxxxxxxxx","accept-encoding":"gzip"}},"tools":{"listChanged":false}},"serverInfo":{"name":"ragflow-server","version":"1.9.4"}}}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3. Acknowledge readiness
|
||||||
|
|
||||||
|
The client confirms readiness with an `initialized` notification:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"method": "notifications/initialized",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
```
|
||||||
|
|
||||||
|
_The connection is established between the client and the server, and further operations (such as tool listing) may proceed._
|
||||||
|
|
||||||
|
### 4. Tool listing
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 3,
|
||||||
|
"method": "tools/list",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: message
|
||||||
|
data: {"jsonrpc":"2.0","id":3,"result":{"tools":[{"name":"ragflow_retrieval","description":"Retrieve relevant chunks from the RAGFlow retrieve interface based on the question, using the specified dataset_ids and optionally document_ids. Below is the list of all available datasets, including their descriptions and IDs. If you're unsure which datasets are relevant to the question, simply pass all dataset IDs to the function.","inputSchema":{"type":"object","properties":{"dataset_ids":{"type":"array","items":{"type":"string"}},"document_ids":{"type":"array","items":{"type":"string"}},"question":{"type":"string"}},"required":["dataset_ids","question"]}}]}}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
### 5. Tool calling
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 4,
|
||||||
|
"method": "tools/call",
|
||||||
|
"params": {
|
||||||
|
"name": "ragflow_retrieval",
|
||||||
|
"arguments": {
|
||||||
|
"question": "How to install neovim?",
|
||||||
|
"dataset_ids": ["DATASET_ID_HERE"],
|
||||||
|
"document_ids": []
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Transport
|
||||||
|
|
||||||
|
```bash
|
||||||
|
event: message
|
||||||
|
data: {"jsonrpc":"2.0","id":4,"result":{...}}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
### A complete curl example
|
||||||
|
|
||||||
|
```bash
|
||||||
|
session_id="YOUR_SESSION_ID" && \
|
||||||
|
|
||||||
|
# Step 1: Initialize request
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 1,
|
||||||
|
"method": "initialize",
|
||||||
|
"params": {
|
||||||
|
"protocolVersion": "1.0",
|
||||||
|
"capabilities": {},
|
||||||
|
"clientInfo": {
|
||||||
|
"name": "ragflow-mcp-client",
|
||||||
|
"version": "0.1"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}' && \
|
||||||
|
|
||||||
|
sleep 2 && \
|
||||||
|
|
||||||
|
# Step 2: Initialized notification
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"method": "notifications/initialized",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
|
||||||
|
sleep 2 && \
|
||||||
|
|
||||||
|
# Step 3: Tool listing
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 3,
|
||||||
|
"method": "tools/list",
|
||||||
|
"params": {}
|
||||||
|
}' && \
|
||||||
|
|
||||||
|
sleep 2 && \
|
||||||
|
|
||||||
|
# Step 4: Tool call
|
||||||
|
curl -X POST "http://127.0.0.1:9382/messages/?session_id=$session_id" \
|
||||||
|
-H "api_key: YOUR_API_KEY" \
|
||||||
|
-H "Content-Type: application/json" \
|
||||||
|
-d '{
|
||||||
|
"jsonrpc": "2.0",
|
||||||
|
"id": 4,
|
||||||
|
"method": "tools/call",
|
||||||
|
"params": {
|
||||||
|
"name": "ragflow_retrieval",
|
||||||
|
"arguments": {
|
||||||
|
"question": "How to install neovim?",
|
||||||
|
"dataset_ids": ["DATASET_ID_HERE"],
|
||||||
|
"document_ids": []
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}'
|
||||||
|
|
||||||
|
```
|
||||||
12
docs/develop/mcp/mcp_tools.md
Normal file
12
docs/develop/mcp/mcp_tools.md
Normal file
@@ -0,0 +1,12 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 2
|
||||||
|
slug: /mcp_tools
|
||||||
|
---
|
||||||
|
|
||||||
|
# RAGFlow MCP tools
|
||||||
|
|
||||||
|
The MCP server currently offers a specialized tool to assist users in searching for relevant information powered by RAGFlow DeepDoc technology:
|
||||||
|
|
||||||
|
- **retrieve**: Fetches relevant chunks from specified `dataset_ids` and optional `document_ids` using the RAGFlow retrieve interface, based on a given question. Details of all available datasets, namely, `id` and `description`, are provided within the tool description for each individual dataset.
|
||||||
|
|
||||||
|
For more information, see our Python implementation of the [MCP server](https://github.com/infiniflow/ragflow/blob/main/mcp/server/server.py).
|
||||||
34
docs/develop/switch_doc_engine.md
Normal file
34
docs/develop/switch_doc_engine.md
Normal file
@@ -0,0 +1,34 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 3
|
||||||
|
slug: /switch_doc_engine
|
||||||
|
---
|
||||||
|
|
||||||
|
# Switch document engine
|
||||||
|
|
||||||
|
Switch your doc engine from Elasticsearch to Infinity.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
RAGFlow uses Elasticsearch by default for storing full text and vectors. To switch to [Infinity](https://github.com/infiniflow/infinity/), follow these steps:
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
Switching to Infinity on a Linux/arm64 machine is not yet officially supported.
|
||||||
|
:::
|
||||||
|
|
||||||
|
1. Stop all running containers:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker compose -f docker/docker-compose.yml down -v
|
||||||
|
```
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
`-v` will delete the docker container volumes, and the existing data will be cleared.
|
||||||
|
:::
|
||||||
|
|
||||||
|
2. Set `DOC_ENGINE` in **docker/.env** to `infinity`.
|
||||||
|
|
||||||
|
3. Start the containers:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker compose -f docker-compose.yml up -d
|
||||||
|
```
|
||||||
536
docs/faq.mdx
Normal file
536
docs/faq.mdx
Normal file
@@ -0,0 +1,536 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 10
|
||||||
|
slug: /faq
|
||||||
|
---
|
||||||
|
|
||||||
|
# FAQs
|
||||||
|
|
||||||
|
Answers to questions about general features, troubleshooting, usage, and more.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
import TOCInline from '@theme/TOCInline';
|
||||||
|
|
||||||
|
<TOCInline toc={toc} />
|
||||||
|
|
||||||
|
## General features
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### What sets RAGFlow apart from other RAG products?
|
||||||
|
|
||||||
|
The "garbage in garbage out" status quo remains unchanged despite the fact that LLMs have advanced Natural Language Processing (NLP) significantly. In its response, RAGFlow introduces two unique features compared to other Retrieval-Augmented Generation (RAG) products.
|
||||||
|
|
||||||
|
- Fine-grained document parsing: Document parsing involves images and tables, with the flexibility for you to intervene as needed.
|
||||||
|
- Traceable answers with reduced hallucinations: You can trust RAGFlow's responses as you can view the citations and references supporting them.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Differences between RAGFlow full edition and RAGFlow slim edition?
|
||||||
|
|
||||||
|
Each RAGFlow release is available in two editions:
|
||||||
|
|
||||||
|
- **Slim edition**: excludes built-in embedding models and is identified by a **-slim** suffix added to the version name. Example: `infiniflow/ragflow:v0.21.1-slim`
|
||||||
|
- **Full edition**: includes built-in embedding models and has no suffix added to the version name. Example: `infiniflow/ragflow:v0.21.1`
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Which embedding models can be deployed locally?
|
||||||
|
|
||||||
|
RAGFlow offers two Docker image editions, `v0.21.1-slim` and `v0.21.1`:
|
||||||
|
|
||||||
|
- `infiniflow/ragflow:v0.21.1-slim` (default): The RAGFlow Docker image without embedding models.
|
||||||
|
- `infiniflow/ragflow:v0.21.1`: The RAGFlow Docker image with the following built-in embedding models:
|
||||||
|
- `BAAI/bge-large-zh-v1.5`
|
||||||
|
- `maidalun1020/bce-embedding-base_v1`
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Where to find the version of RAGFlow? How to interpret it?
|
||||||
|
|
||||||
|
You can find the RAGFlow version number on the **System** page of the UI:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
If you build RAGFlow from source, the version number is also in the system log:
|
||||||
|
|
||||||
|
```
|
||||||
|
____ ___ ______ ______ __
|
||||||
|
/ __ \ / | / ____// ____// /____ _ __
|
||||||
|
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
|
||||||
|
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
|
||||||
|
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
|
||||||
|
|
||||||
|
2025-02-18 10:10:43,835 INFO 1445658 RAGFlow version: v0.15.0-50-g6daae7f2 full
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
|
||||||
|
- `v0.15.0`: The officially published release.
|
||||||
|
- `50`: The number of git commits since the official release.
|
||||||
|
- `g6daae7f2`: `g` is the prefix, and `6daae7f2` is the first seven characters of the current commit ID.
|
||||||
|
- `full`/`slim`: The RAGFlow edition.
|
||||||
|
- `full`: The full RAGFlow edition.
|
||||||
|
- `slim`: The RAGFlow edition without embedding models and Python packages.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Why not use other open-source vector databases as the document engine?
|
||||||
|
|
||||||
|
Currently, only Elasticsearch and [Infinity](https://github.com/infiniflow/infinity) meet the hybrid search requirements of RAGFlow. Most open-source vector databases have limited support for full-text search, and sparse embedding is not an alternative to full-text search. Additionally, these vector databases lack critical features essential to RAGFlow, such as phrase search and advanced ranking capabilities.
|
||||||
|
|
||||||
|
These limitations led us to develop [Infinity](https://github.com/infiniflow/infinity), the AI-native database, from the ground up.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Differences between demo.ragflow.io and a locally deployed open-source RAGFlow service?
|
||||||
|
|
||||||
|
demo.ragflow.io demonstrates the capabilities of RAGFlow Enterprise. Its DeepDoc models are pre-trained using proprietary data and it offers much more sophisticated team permission controls. Essentially, demo.ragflow.io serves as a preview of RAGFlow's forthcoming SaaS (Software as a Service) offering.
|
||||||
|
|
||||||
|
You can deploy an open-source RAGFlow service and call it from a Python client or through RESTful APIs. However, this is not supported on demo.ragflow.io.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Why does it take longer for RAGFlow to parse a document than LangChain?
|
||||||
|
|
||||||
|
We put painstaking effort into document pre-processing tasks like layout analysis, table structure recognition, and OCR (Optical Character Recognition) using our vision models. This contributes to the additional time required.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Why does RAGFlow require more resources than other projects?
|
||||||
|
|
||||||
|
RAGFlow has a number of built-in models for document structure parsing, which account for the additional computational resources.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Which architectures or devices does RAGFlow support?
|
||||||
|
|
||||||
|
We officially support x86 CPU and nvidia GPU. While we also test RAGFlow on ARM64 platforms, we do not maintain RAGFlow Docker images for ARM. If you are on an ARM platform, follow [this guide](./develop/build_docker_image.mdx) to build a RAGFlow Docker image.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Do you offer an API for integration with third-party applications?
|
||||||
|
|
||||||
|
The corresponding APIs are now available. See the [RAGFlow HTTP API Reference](./references/http_api_reference.md) or the [RAGFlow Python API Reference](./references/python_api_reference.md) for more information.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Do you support stream output?
|
||||||
|
|
||||||
|
Yes, we do. Stream output is enabled by default in the chat assistant and agent. Note that you cannot disable stream output via RAGFlow's UI. To disable stream output in responses, use RAGFlow's Python or RESTful APIs:
|
||||||
|
|
||||||
|
Python:
|
||||||
|
|
||||||
|
- [Create chat completion](./references/python_api_reference.md#create-chat-completion)
|
||||||
|
- [Converse with chat assistant](./references/python_api_reference.md#converse-with-chat-assistant)
|
||||||
|
- [Converse with agent](./references/python_api_reference.md#converse-with-agent)
|
||||||
|
|
||||||
|
RESTful:
|
||||||
|
|
||||||
|
- [Create chat completion](./references/http_api_reference.md#create-chat-completion)
|
||||||
|
- [Converse with chat assistant](./references/http_api_reference.md#converse-with-chat-assistant)
|
||||||
|
- [Converse with agent](./references/http_api_reference.md#converse-with-agent)
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Do you support sharing dialogue through URL?
|
||||||
|
|
||||||
|
No, this feature is not supported.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Do you support multiple rounds of dialogues, referencing previous dialogues as context for the current query?
|
||||||
|
|
||||||
|
Yes, we support enhancing user queries based on existing context of an ongoing conversation:
|
||||||
|
|
||||||
|
1. On the **Chat** page, hover over the desired assistant and select **Edit**.
|
||||||
|
2. In the **Chat Configuration** popup, click the **Prompt engine** tab.
|
||||||
|
3. Switch on **Multi-turn optimization** to enable this feature.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Key differences between AI search and chat?
|
||||||
|
|
||||||
|
- **AI search**: This is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. Retrieved chunks will be listed below the chat model's response.
|
||||||
|
- **AI chat**: This is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
|
||||||
|
|
||||||
|
When debugging your chat assistant, you can use AI search as a reference to verify your model settings and retrieval strategy.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Troubleshooting
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to build the RAGFlow image from scratch?
|
||||||
|
|
||||||
|
See [Build a RAGFlow Docker image](./develop/build_docker_image.mdx).
|
||||||
|
|
||||||
|
### Cannot access https://huggingface.co
|
||||||
|
|
||||||
|
A locally deployed RAGflow downloads OCR and embedding modules from [Huggingface website](https://huggingface.co) by default. If your machine is unable to access this site, the following error occurs and PDF parsing fails:
|
||||||
|
|
||||||
|
```
|
||||||
|
FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/hub/models--InfiniFlow--deepdoc/snapshots/be0c1e50eef6047b412d1800aa89aba4d275f997/ocr.res'
|
||||||
|
```
|
||||||
|
|
||||||
|
To fix this issue, use https://hf-mirror.com instead:
|
||||||
|
|
||||||
|
1. Stop all containers and remove all related resources:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd ragflow/docker/
|
||||||
|
docker compose down
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Uncomment the following line in **ragflow/docker/.env**:
|
||||||
|
|
||||||
|
```
|
||||||
|
# HF_ENDPOINT=https://hf-mirror.com
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Start up the server:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)`
|
||||||
|
|
||||||
|
This error suggests that you do not have Internet access or are unable to connect to hf-mirror.com. Try the following:
|
||||||
|
|
||||||
|
1. Manually download the resource files from [huggingface.co/InfiniFlow/deepdoc](https://huggingface.co/InfiniFlow/deepdoc) to your local folder **~/deepdoc**.
|
||||||
|
2. Add a volumes to **docker-compose.yml**, for example:
|
||||||
|
|
||||||
|
```
|
||||||
|
- ~/deepdoc:/ragflow/rag/res/deepdoc
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `WARNING: can't find /raglof/rag/res/borker.tm`
|
||||||
|
|
||||||
|
Ignore this warning and continue. All system warnings can be ignored.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `network anomaly There is an abnormality in your network and you cannot connect to the server.`
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
You will not log in to RAGFlow unless the server is fully initialized. Run `docker logs -f ragflow-server`.
|
||||||
|
|
||||||
|
*The server is successfully initialized, if your system displays the following:*
|
||||||
|
|
||||||
|
```
|
||||||
|
____ ___ ______ ______ __
|
||||||
|
/ __ \ / | / ____// ____// /____ _ __
|
||||||
|
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
|
||||||
|
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
|
||||||
|
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
|
||||||
|
|
||||||
|
* Running on all addresses (0.0.0.0)
|
||||||
|
* Running on http://127.0.0.1:9380
|
||||||
|
* Running on http://x.x.x.x:9380
|
||||||
|
INFO:werkzeug:Press CTRL+C to quit
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `Realtime synonym is disabled, since no redis connection`
|
||||||
|
|
||||||
|
Ignore this warning and continue. All system warnings can be ignored.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Why does my document parsing stall at under one percent?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click the red cross beside the 'parsing status' bar, then restart the parsing process to see if the issue remains. If the issue persists and your RAGFlow is deployed locally, try the following:
|
||||||
|
|
||||||
|
1. Check the log of your RAGFlow server to see if it is running properly:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker logs -f ragflow-server
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Check if the **task_executor.py** process exists.
|
||||||
|
3. Check if your RAGFlow server can access hf-mirror.com or huggingface.com.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Why does my pdf parsing stall near completion, while the log does not show any error?
|
||||||
|
|
||||||
|
Click the red cross beside the 'parsing status' bar, then restart the parsing process to see if the issue remains. If the issue persists and your RAGFlow is deployed locally, the parsing process is likely killed due to insufficient RAM. Try increasing your memory allocation by increasing the `MEM_LIMIT` value in **docker/.env**.
|
||||||
|
|
||||||
|
:::note
|
||||||
|
Ensure that you restart up your RAGFlow server for your changes to take effect!
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose stop
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `Index failure`
|
||||||
|
|
||||||
|
An index failure usually indicates an unavailable Elasticsearch service.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to check the log of RAGFlow?
|
||||||
|
|
||||||
|
```bash
|
||||||
|
tail -f ragflow/docker/ragflow-logs/*.log
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to check the status of each component in RAGFlow?
|
||||||
|
|
||||||
|
1. Check the status of the Elasticsearch Docker container:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker ps
|
||||||
|
```
|
||||||
|
|
||||||
|
*The following is an example result:*
|
||||||
|
|
||||||
|
```bash
|
||||||
|
5bc45806b680 infiniflow/ragflow:latest "./entrypoint.sh" 11 hours ago Up 11 hours 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp, 0.0.0.0:9380->9380/tcp, :::9380->9380/tcp ragflow-server
|
||||||
|
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01
|
||||||
|
d8c86f06c56b mysql:5.7.18 "docker-entrypoint.s…" 7 days ago Up 16 seconds (healthy) 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp ragflow-mysql
|
||||||
|
cd29bcb254bc quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" 2 weeks ago Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Follow [this document](./guides/run_health_check.md) to check the health status of the Elasticsearch service.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||||
|
:::
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `Exception: Can't connect to ES cluster`
|
||||||
|
|
||||||
|
1. Check the status of the Elasticsearch Docker container:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker ps
|
||||||
|
```
|
||||||
|
|
||||||
|
*The status of a healthy Elasticsearch component should look as follows:*
|
||||||
|
|
||||||
|
```
|
||||||
|
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Follow [this document](./guides/run_health_check.md) to check the health status of the Elasticsearch service.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||||
|
:::
|
||||||
|
|
||||||
|
3. If your container keeps restarting, ensure `vm.max_map_count` >= 262144 as per [this README](https://github.com/infiniflow/ragflow?tab=readme-ov-file#-start-up-the-server). Updating the `vm.max_map_count` value in **/etc/sysctl.conf** is required, if you wish to keep your change permanent. Note that this configuration works only for Linux.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Can't start ES container and get `Elasticsearch did not exit normally`
|
||||||
|
|
||||||
|
This is because you forgot to update the `vm.max_map_count` value in **/etc/sysctl.conf** and your change to this value was reset after a system reboot.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `{"data":null,"code":100,"message":"<NotFound '404: Not Found'>"}`
|
||||||
|
|
||||||
|
Your IP address or port number may be incorrect. If you are using the default configurations, enter `http://<IP_OF_YOUR_MACHINE>` (**NOT 9380, AND NO PORT NUMBER REQUIRED!**) in your browser. This should work.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `Ollama - Mistral instance running at 127.0.0.1:11434 but cannot add Ollama as model in RagFlow`
|
||||||
|
|
||||||
|
A correct Ollama IP address and port is crucial to adding models to Ollama:
|
||||||
|
|
||||||
|
- If you are on demo.ragflow.io, ensure that the server hosting Ollama has a publicly accessible IP address. Note that 127.0.0.1 is not a publicly accessible IP address.
|
||||||
|
- If you deploy RAGFlow locally, ensure that Ollama and RAGFlow are in the same LAN and can communicate with each other.
|
||||||
|
|
||||||
|
See [Deploy a local LLM](./guides/models/deploy_local_llm.mdx) for more information.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Do you offer examples of using DeepDoc to parse PDF or other files?
|
||||||
|
|
||||||
|
Yes, we do. See the Python files under the **rag/app** folder.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `FileNotFoundError: [Errno 2] No such file or directory`
|
||||||
|
|
||||||
|
1. Check the status of the MinIO Docker container:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker ps
|
||||||
|
```
|
||||||
|
|
||||||
|
*The status of a healthy Elasticsearch component should look as follows:*
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd29bcb254bc quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" 2 weeks ago Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Follow [this document](./guides/run_health_check.md) to check the health status of the Elasticsearch service.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
|
||||||
|
:::
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Usage
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to run RAGFlow with a locally deployed LLM?
|
||||||
|
|
||||||
|
You can use Ollama or Xinference to deploy local LLM. See [here](./guides/models/deploy_local_llm.mdx) for more information.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to add an LLM that is not supported?
|
||||||
|
|
||||||
|
If your model is not currently supported but has APIs compatible with those of OpenAI, click **OpenAI-API-Compatible** on the **Model providers** page to configure your model:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to integrate RAGFlow with Ollama?
|
||||||
|
|
||||||
|
- If RAGFlow is locally deployed, ensure that your RAGFlow and Ollama are in the same LAN.
|
||||||
|
- If you are using our online demo, ensure that the IP address of your Ollama server is public and accessible.
|
||||||
|
|
||||||
|
See [here](./guides/models/deploy_local_llm.mdx) for more information.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to change the file size limit?
|
||||||
|
|
||||||
|
For a locally deployed RAGFlow: the total file size limit per upload is 1GB, with a batch upload limit of 32 files. There is no cap on the total number of files per account. To update this 1GB file size limit:
|
||||||
|
|
||||||
|
- In **docker/.env**, upcomment `# MAX_CONTENT_LENGTH=1073741824`, adjust the value as needed, and note that `1073741824` represents 1GB in bytes.
|
||||||
|
- If you update the value of `MAX_CONTENT_LENGTH` in **docker/.env**, ensure that you update `client_max_body_size` in **nginx/nginx.conf** accordingly.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
It is not recommended to manually change the 32-file batch upload limit. However, if you use RAGFlow's HTTP API or Python SDK to upload files, the 32-file batch upload limit is automatically removed.
|
||||||
|
:::
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### `Error: Range of input length should be [1, 30000]`
|
||||||
|
|
||||||
|
This error occurs because there are too many chunks matching your search criteria. Try reducing the **TopN** and increasing **Similarity threshold** to fix this issue:
|
||||||
|
|
||||||
|
1. Click **Chat** in the middle top of the page.
|
||||||
|
2. Right-click the desired conversation > **Edit** > **Prompt engine**
|
||||||
|
3. Reduce the **TopN** and/or raise **Similarity threshold**.
|
||||||
|
4. Click **OK** to confirm your changes.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to get an API key for integration with third-party applications?
|
||||||
|
|
||||||
|
See [Acquire a RAGFlow API key](./develop/acquire_ragflow_api_key.md).
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to upgrade RAGFlow?
|
||||||
|
|
||||||
|
See [Upgrade RAGFlow](./guides/upgrade_ragflow.mdx) for more information.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to switch the document engine to Infinity?
|
||||||
|
|
||||||
|
To switch your document engine from Elasticsearch to [Infinity](https://github.com/infiniflow/infinity):
|
||||||
|
|
||||||
|
1. Stop all running containers:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker compose -f docker/docker-compose.yml down -v
|
||||||
|
```
|
||||||
|
:::caution WARNING
|
||||||
|
`-v` will delete all Docker container volumes, and the existing data will be cleared.
|
||||||
|
:::
|
||||||
|
|
||||||
|
2. In **docker/.env**, set `DOC_ENGINE=${DOC_ENGINE:-infinity}`
|
||||||
|
3. Restart your Docker image:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
$ docker compose -f docker-compose.yml up -d
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### Where are my uploaded files stored in RAGFlow's image?
|
||||||
|
|
||||||
|
All uploaded files are stored in Minio, RAGFlow's object storage solution. For instance, if you upload your file directly to a dataset, it is located at `<knowledgebase_id>/filename`.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to tune batch size for document parsing and embedding?
|
||||||
|
|
||||||
|
You can control the batch size for document parsing and embedding by setting the environment variables `DOC_BULK_SIZE` and `EMBEDDING_BATCH_SIZE`. Increasing these values may improve throughput for large-scale data processing, but will also increase memory usage. Adjust them according to your hardware resources.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to accelerate the question-answering speed of my chat assistant?
|
||||||
|
|
||||||
|
See [here](./guides/chat/best_practices/accelerate_question_answering.mdx).
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to accelerate the question-answering speed of my Agent?
|
||||||
|
|
||||||
|
See [here](./guides/agent/best_practices/accelerate_agent_question_answering.md).
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### How to use MinerU to parse PDF documents?
|
||||||
|
|
||||||
|
MinerU PDF document parsing is available starting from v0.21.1. To use this feature, follow these steps:
|
||||||
|
|
||||||
|
1. Before deploying ragflow-server, update your **docker/.env** file:
|
||||||
|
- Enable `HF_ENDPOINT=https://hf-mirror.com`
|
||||||
|
- Add a MinerU entry: `MINERU_EXECUTABLE=/ragflow/uv_tools/.venv/bin/mineru`
|
||||||
|
|
||||||
|
2. Start the ragflow-server and run the following commands inside the container:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
mkdir uv_tools
|
||||||
|
cd uv_tools
|
||||||
|
uv venv .venv
|
||||||
|
source .venv/bin/activate
|
||||||
|
uv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Restart the ragflow-server.
|
||||||
|
4. In the web UI, navigate to the **Configuration** page of your dataset. Click **Built-in** in the **Ingestion pipeline** section, select a chunking method from the **Built-in** dropdown, which supports PDF parsing, and slect **MinerU** in **PDF parser**.
|
||||||
|
5. If you use a custom ingestion pipeline instead, you must also complete the first three steps before selecting **MinerU** in the **Parsing method** section of the **Parser** component.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
8
docs/guides/_category_.json
Normal file
8
docs/guides/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"label": "Guides",
|
||||||
|
"position": 3,
|
||||||
|
"link": {
|
||||||
|
"type": "generated-index",
|
||||||
|
"description": "Guides for RAGFlow users and developers."
|
||||||
|
}
|
||||||
|
}
|
||||||
8
docs/guides/agent/_category_.json
Normal file
8
docs/guides/agent/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"label": "Agents",
|
||||||
|
"position": 3,
|
||||||
|
"link": {
|
||||||
|
"type": "generated-index",
|
||||||
|
"description": "RAGFlow v0.8.0 introduces an agent mechanism, featuring a no-code workflow editor on the front end and a comprehensive graph-based task orchestration framework on the backend."
|
||||||
|
}
|
||||||
|
}
|
||||||
@@ -0,0 +1,8 @@
|
|||||||
|
{
|
||||||
|
"label": "Agent Components",
|
||||||
|
"position": 20,
|
||||||
|
"link": {
|
||||||
|
"type": "generated-index",
|
||||||
|
"description": "A complete reference for RAGFlow's agent components."
|
||||||
|
}
|
||||||
|
}
|
||||||
233
docs/guides/agent/agent_component_reference/agent.mdx
Normal file
233
docs/guides/agent/agent_component_reference/agent.mdx
Normal file
@@ -0,0 +1,233 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 2
|
||||||
|
slug: /agent_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Agent component
|
||||||
|
|
||||||
|
The component equipped with reasoning, tool usage, and multi-agent collaboration capabilities.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.5 onwards, an **Agent** component is able to work independently and with the following capabilities:
|
||||||
|
|
||||||
|
- Autonomous reasoning with reflection and adjustment based on environmental feedback.
|
||||||
|
- Use of tools or subagents to complete tasks.
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
An **Agent** component is essential when you need the LLM to assist with summarizing, translating, or controlling various tasks.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
1. Ensure you have a chat model properly configured:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||||
|
|
||||||
|
## Quickstart
|
||||||
|
|
||||||
|
### 1. Click on an **Agent** component to show its configuration panel
|
||||||
|
|
||||||
|
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||||
|
|
||||||
|
### 2. Select your model
|
||||||
|
|
||||||
|
Click **Model**, and select a chat model from the dropdown menu.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 3. Update system prompt (Optional)
|
||||||
|
|
||||||
|
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||||
|
|
||||||
|
|
||||||
|
### 4. Update user prompt
|
||||||
|
|
||||||
|
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||||
|
|
||||||
|
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 5. Skip Tools and Agent
|
||||||
|
|
||||||
|
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||||
|
|
||||||
|
### 6. Choose the next component
|
||||||
|
|
||||||
|
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||||
|
|
||||||
|
## Connect to an MCP server as a client
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 1. Navigate to the MCP configuration page
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 2. Configure your Tavily MCP server
|
||||||
|
|
||||||
|
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 3. Navigate to your Agent's editing page
|
||||||
|
|
||||||
|
### 4. Connect to your MCP server
|
||||||
|
|
||||||
|
1. Click **+ Add tools**:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
2. Click **MCP** to show the available MCP servers.
|
||||||
|
|
||||||
|
3. Select your MCP server:
|
||||||
|
|
||||||
|
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||||
|
|
||||||
|
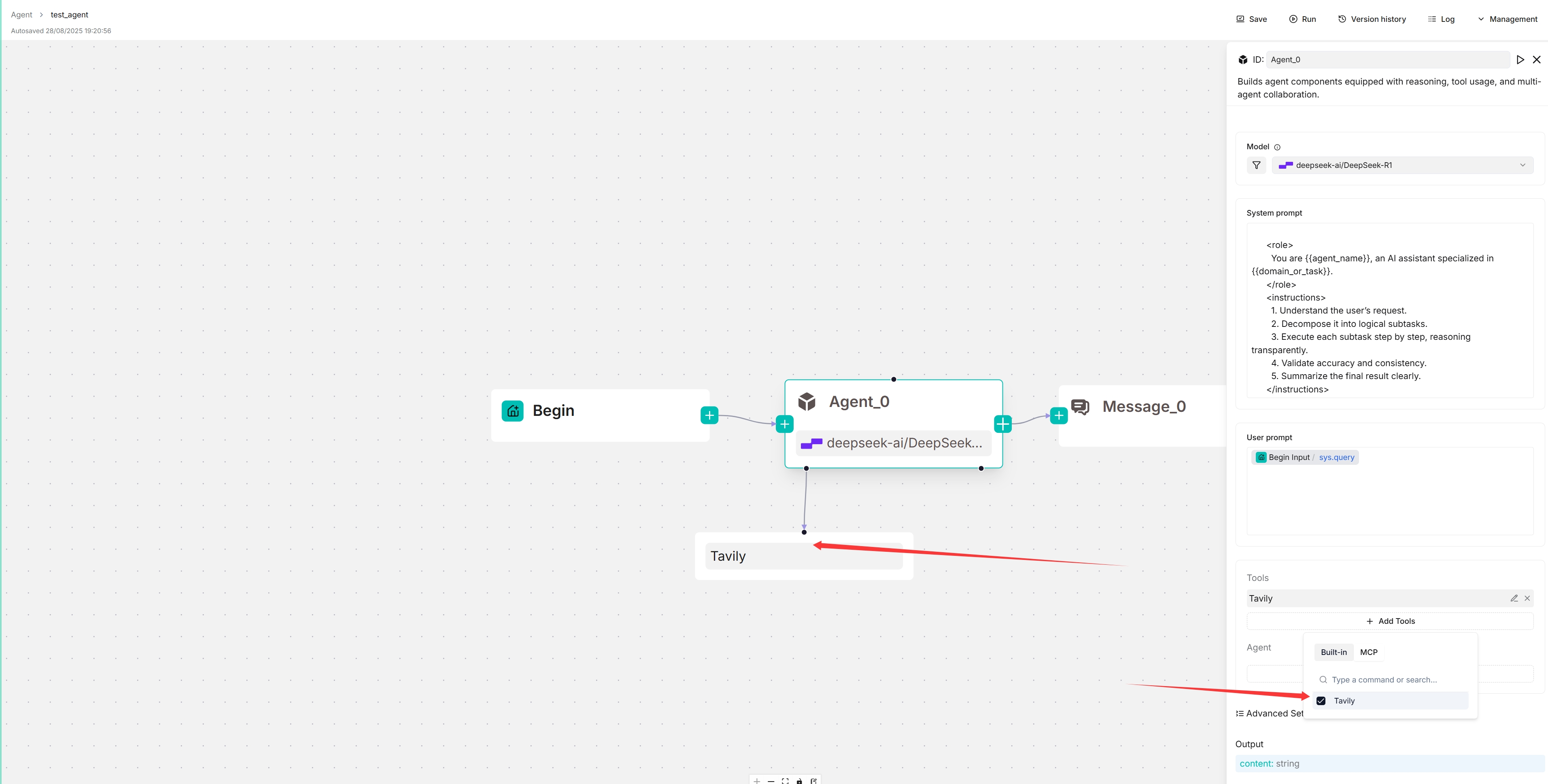
|
||||||
|
|
||||||
|
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||||
|
|
||||||
|
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||||
|
|
||||||
|
### 6. View the availabe tools of your MCP server
|
||||||
|
|
||||||
|
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||||
|
|
||||||
|
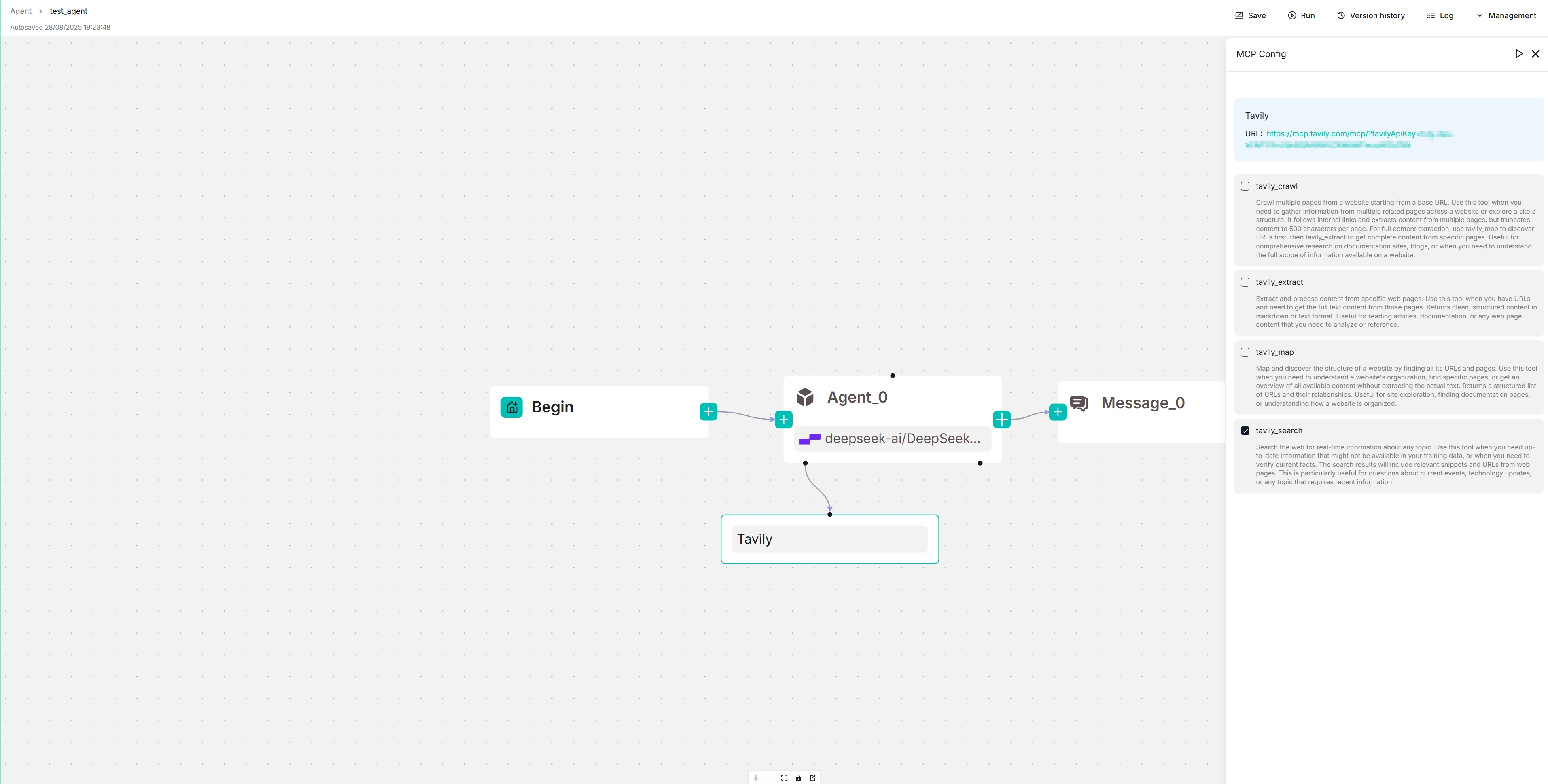
|
||||||
|
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Model
|
||||||
|
|
||||||
|
Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
|
|
||||||
|
- **Model**: The chat model to use.
|
||||||
|
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||||
|
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||||
|
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||||
|
This parameter has three options:
|
||||||
|
- **Improvise**: Produces more creative responses.
|
||||||
|
- **Precise**: (Default) Produces more conservative responses.
|
||||||
|
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||||
|
- **Temperature**: The randomness level of the model's output.
|
||||||
|
Defaults to 0.1.
|
||||||
|
- Lower values lead to more deterministic and predictable outputs.
|
||||||
|
- Higher values lead to more creative and varied outputs.
|
||||||
|
- A temperature of zero results in the same output for the same prompt.
|
||||||
|
- **Top P**: Nucleus sampling.
|
||||||
|
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||||
|
- Defaults to 0.3.
|
||||||
|
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||||
|
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||||
|
- Defaults to 0.4.
|
||||||
|
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||||
|
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||||
|
- Defaults to 0.7.
|
||||||
|
- **Max tokens**:
|
||||||
|
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||||
|
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### System prompt
|
||||||
|
|
||||||
|
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering. However, please be aware that the system prompt is often used in conjunction with keys (variables), which serve as various data inputs for the LLM.
|
||||||
|
|
||||||
|
An **Agent** component relies on keys (variables) to specify its data inputs. Its immediate upstream component is *not* necessarily its data input, and the arrows in the workflow indicate *only* the processing sequence. Keys in a **Agent** component are used in conjunction with the system prompt to specify data inputs for the LLM. Use a forward slash `/` or the **(x)** button to show the keys to use.
|
||||||
|
|
||||||
|
#### Advanced usage
|
||||||
|
|
||||||
|
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||||
|
|
||||||
|
- `task_analysis` prompt block
|
||||||
|
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||||
|
- Reference design: [analyze_task_system.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_system.md) and [analyze_task_user.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_user.md)
|
||||||
|
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||||
|
- Input variables:
|
||||||
|
- `agent_prompt`: The system prompt.
|
||||||
|
- `task`: The user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent when delegating tasks.
|
||||||
|
- `tool_desc`: A description of the tools and sub_Agents that can be called.
|
||||||
|
- `context`: The operational context, which stores interactions between the Agent, tools, and sub-agents; initially empty.
|
||||||
|
- `plan_generation` prompt block
|
||||||
|
- This block creates a plan for the **Agent** component to execute next, based on the task analysis results.
|
||||||
|
- Reference design: [next_step.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/next_step.md)
|
||||||
|
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||||
|
- Input variables:
|
||||||
|
- `task_analysis`: The analysis result of the current task.
|
||||||
|
- `desc`: A description of the tools or sub-Agents currently being called.
|
||||||
|
- `today`: The date of today.
|
||||||
|
- `reflection` prompt block
|
||||||
|
- This block enables the **Agent** component to reflect, improving task accuracy and efficiency.
|
||||||
|
- Reference design: [reflect.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/reflect.md)
|
||||||
|
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||||
|
- Input variables:
|
||||||
|
- `goal`: The goal of the current task. It is the user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent.
|
||||||
|
- `tool_calls`: The history of tool calling
|
||||||
|
- `call.name`:The name of the tool called.
|
||||||
|
- `call.result`:The result of tool calling
|
||||||
|
- `citation_guidelines` prompt block
|
||||||
|
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||||
|
|
||||||
|
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||||
|
|
||||||
|
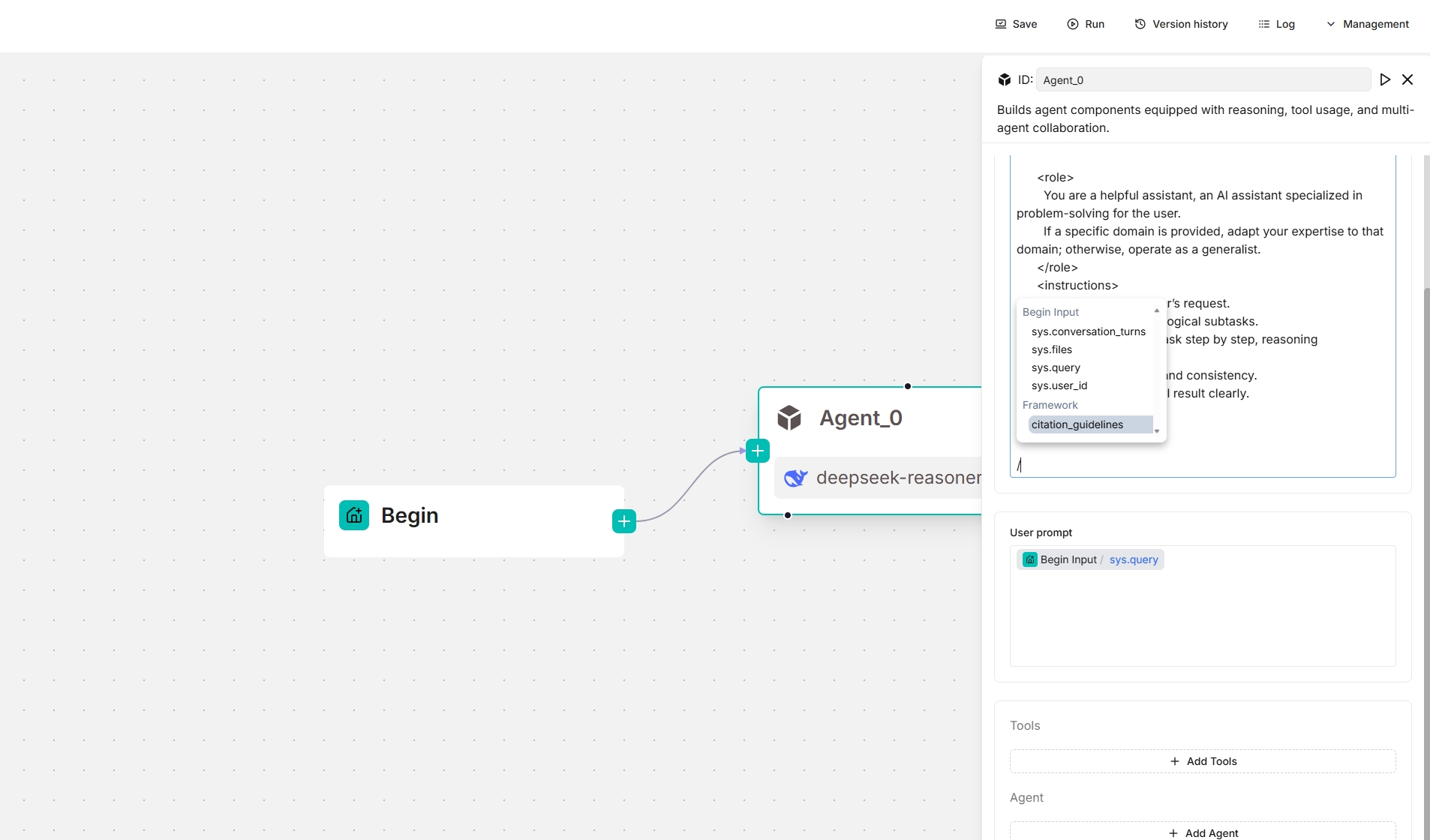
|
||||||
|
|
||||||
|
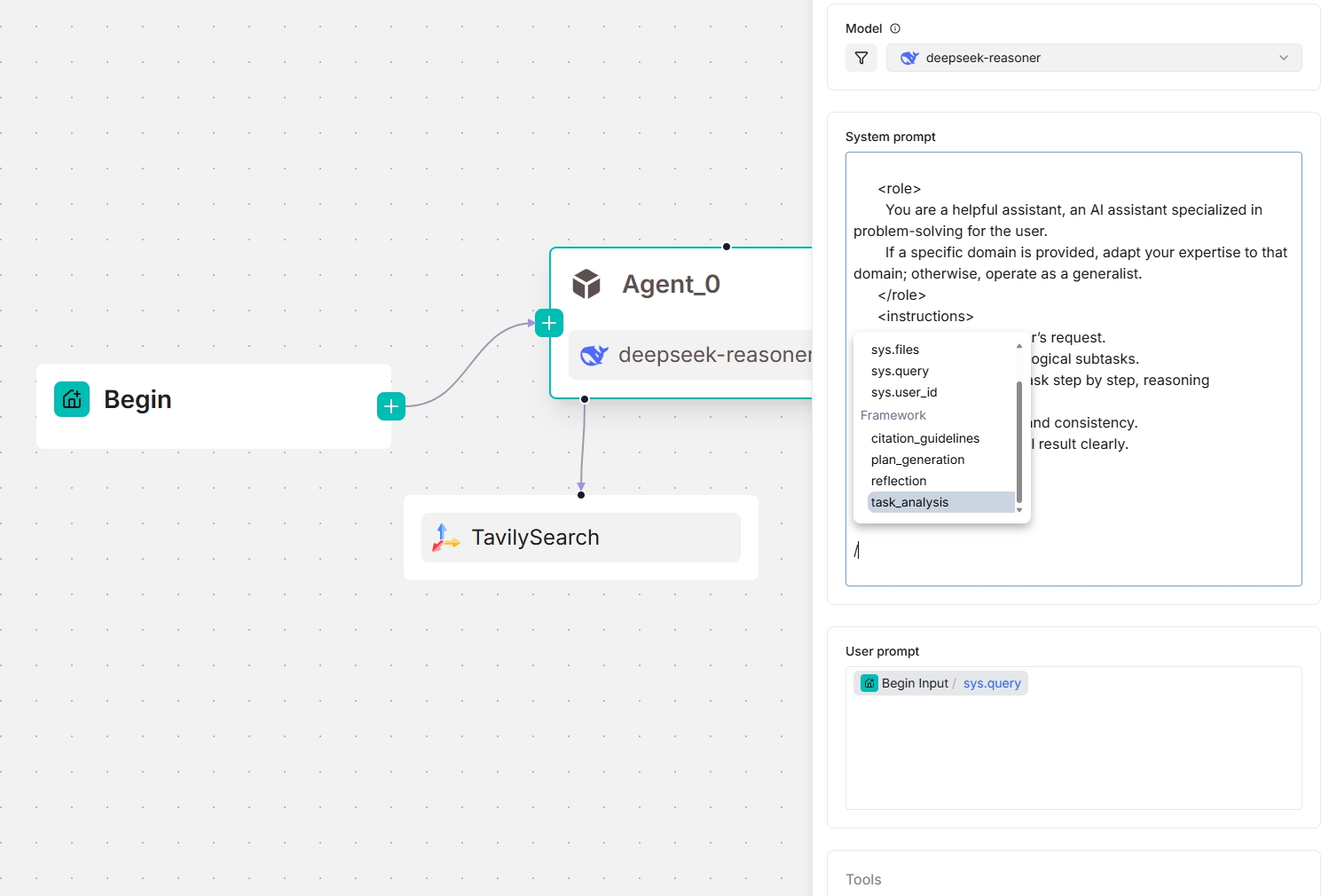
|
||||||
|
|
||||||
|
### User prompt
|
||||||
|
|
||||||
|
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||||
|
|
||||||
|
|
||||||
|
### Tools
|
||||||
|
|
||||||
|
You can use an **Agent** component as a collaborator that reasons and reflects with the aid of other tools; for instance, **Retrieval** can serve as one such tool for an **Agent**.
|
||||||
|
|
||||||
|
### Agent
|
||||||
|
|
||||||
|
You use an **Agent** component as a collaborator that reasons and reflects with the aid of subagents or other tools, forming a multi-agent system.
|
||||||
|
|
||||||
|
### Message window size
|
||||||
|
|
||||||
|
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||||||
|
|
||||||
|
:::tip IMPORTANT
|
||||||
|
This feature is used for multi-turn dialogue *only*.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Max retries
|
||||||
|
|
||||||
|
Defines the maximum number of attempts the agent will make to retry a failed task or operation before stopping or reporting failure.
|
||||||
|
|
||||||
|
### Delay after error
|
||||||
|
|
||||||
|
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||||
|
|
||||||
|
### Max reflection rounds
|
||||||
|
|
||||||
|
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
Increasing this value will significantly extend your agent's response time.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The global variable name for the output of the **Agent** component, which can be referenced by other components in the workflow.
|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### Why does it take so long for my Agent to respond?
|
||||||
|
|
||||||
|
See [here](../best_practices/accelerate_agent_question_answering.md) for details.
|
||||||
@@ -0,0 +1,57 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 5
|
||||||
|
slug: /await_response
|
||||||
|
---
|
||||||
|
|
||||||
|
# Await response component
|
||||||
|
|
||||||
|
A component that halts the workflow and awaits user input.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
An **Await response** component halts the workflow, initiating a conversation and collecting key information via predefined forms.
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
An **Await response** component is essential where you need to display the agent's responses or require user-computer interaction.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Guiding question
|
||||||
|
|
||||||
|
Whether to show the message defined in the **Message** field.
|
||||||
|
|
||||||
|
### Message
|
||||||
|
|
||||||
|
The static message to send out.
|
||||||
|
|
||||||
|
Click **+ Add message** to add message options. When multiple messages are supplied, the **Message** component randomly selects one to send.
|
||||||
|
|
||||||
|
### Input
|
||||||
|
|
||||||
|
You can define global variables within the **Await response** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+** to add a global variable, each with the following attributes:
|
||||||
|
|
||||||
|
- **Name**: _Required_
|
||||||
|
A descriptive name providing additional details about the variable.
|
||||||
|
- **Type**: _Required_
|
||||||
|
The type of the variable:
|
||||||
|
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||||
|
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||||
|
- **Dropdown options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set _at least_ one option for the dropdown menu.
|
||||||
|
- **file upload**: Requires the user to upload one or multiple files.
|
||||||
|
- **Number**: Accepts a number as input.
|
||||||
|
- **Boolean**: Requires the user to toggle between on and off.
|
||||||
|
- **Key**: _Required_
|
||||||
|
The unique variable name.
|
||||||
|
- **Optional**: A toggle indicating whether the variable is optional.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
To pass in parameters from a client, call:
|
||||||
|
|
||||||
|
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||||
|
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
||||||
|
:::
|
||||||
80
docs/guides/agent/agent_component_reference/begin.mdx
Normal file
80
docs/guides/agent/agent_component_reference/begin.mdx
Normal file
@@ -0,0 +1,80 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
slug: /begin_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Begin component
|
||||||
|
|
||||||
|
The starting component in a workflow.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
The **Begin** component sets an opening greeting or accepts inputs from the user. It is automatically populated onto the canvas when you create an agent, whether from a template or from scratch (from a blank template). There should be only one **Begin** component in the workflow.
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
A **Begin** component is essential in all cases. Every agent includes a **Begin** component, which cannot be deleted.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
Click the component to display its **Configuration** window. Here, you can set an opening greeting and the input parameters (global variables) for the agent.
|
||||||
|
|
||||||
|
### Mode
|
||||||
|
|
||||||
|
Mode defines how the workflow is triggered.
|
||||||
|
|
||||||
|
- Conversational: The agent is triggered from a conversation.
|
||||||
|
- Task: The agent starts without a conversation.
|
||||||
|
|
||||||
|
### Opening greeting
|
||||||
|
|
||||||
|
**Conversational mode only.**
|
||||||
|
|
||||||
|
An agent in conversational mode begins with an opening greeting. It is the agent's first message to the user in conversational mode, which can be a welcoming remark or an instruction to guide the user forward.
|
||||||
|
|
||||||
|
### Global variables
|
||||||
|
|
||||||
|
You can define global variables within the **Begin** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+ Add variable** to add a global variable, each with the following attributes:
|
||||||
|
|
||||||
|
- **Name**: _Required_
|
||||||
|
A descriptive name providing additional details about the variable.
|
||||||
|
- **Type**: _Required_
|
||||||
|
The type of the variable:
|
||||||
|
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||||
|
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||||
|
- **Dropdown options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set _at least_ one option for the dropdown menu.
|
||||||
|
- **file upload**: Requires the user to upload one or multiple files.
|
||||||
|
- **Number**: Accepts a number as input.
|
||||||
|
- **Boolean**: Requires the user to toggle between on and off.
|
||||||
|
- **Key**: _Required_
|
||||||
|
The unique variable name.
|
||||||
|
- **Optional**: A toggle indicating whether the variable is optional.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
To pass in parameters from a client, call:
|
||||||
|
|
||||||
|
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||||
|
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::note
|
||||||
|
You can tune document parsing and embedding efficiency by setting the environment variables `DOC_BULK_SIZE` and `EMBEDDING_BATCH_SIZE`.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### Is the uploaded file in a dataset?
|
||||||
|
|
||||||
|
No. Files uploaded to an agent as input are not stored in a dataset and hence will not be processed using RAGFlow's built-in OCR, DLR or TSR models, or chunked using RAGFlow's built-in chunking methods.
|
||||||
|
|
||||||
|
### File size limit for an uploaded file
|
||||||
|
|
||||||
|
There is no _specific_ file size limit for a file uploaded to an agent. However, note that model providers typically have a default or explicit maximum token setting, which can range from 8196 to 128k: The plain text part of the uploaded file will be passed in as the key value, but if the file's token count exceeds this limit, the string will be truncated and incomplete.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
The variables `MAX_CONTENT_LENGTH` in `/docker/.env` and `client_max_body_size` in `/docker/nginx/nginx.conf` set the file size limit for each upload to a dataset or **File Management**. These settings DO NOT apply in this scenario.
|
||||||
|
:::
|
||||||
109
docs/guides/agent/agent_component_reference/categorize.mdx
Normal file
109
docs/guides/agent/agent_component_reference/categorize.mdx
Normal file
@@ -0,0 +1,109 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 8
|
||||||
|
slug: /categorize_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Categorize component
|
||||||
|
|
||||||
|
A component that classifies user inputs and applies strategies accordingly.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A **Categorize** component is usually the downstream of the **Interact** component.
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
A **Categorize** component is essential when you need the LLM to help you identify user intentions and apply appropriate processing strategies.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Query variables
|
||||||
|
|
||||||
|
*Mandatory*
|
||||||
|
|
||||||
|
Select the source for categorization.
|
||||||
|
|
||||||
|
The **Categorize** component relies on query variables to specify its data inputs (queries). All global variables defined before the **Categorize** component are available in the dropdown list.
|
||||||
|
|
||||||
|
|
||||||
|
### Input
|
||||||
|
|
||||||
|
The **Categorize** component relies on input variables to specify its data inputs (queries). Click **+ Add variable** in the **Input** section to add the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||||
|
|
||||||
|
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||||
|
- A component ID under **Component Output**, or
|
||||||
|
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||||
|
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||||
|
|
||||||
|
### Model
|
||||||
|
|
||||||
|
Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
|
|
||||||
|
- **Model**: The chat model to use.
|
||||||
|
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||||
|
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||||
|
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||||
|
This parameter has three options:
|
||||||
|
- **Improvise**: Produces more creative responses.
|
||||||
|
- **Precise**: (Default) Produces more conservative responses.
|
||||||
|
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||||
|
- **Temperature**: The randomness level of the model's output.
|
||||||
|
Defaults to 0.1.
|
||||||
|
- Lower values lead to more deterministic and predictable outputs.
|
||||||
|
- Higher values lead to more creative and varied outputs.
|
||||||
|
- A temperature of zero results in the same output for the same prompt.
|
||||||
|
- **Top P**: Nucleus sampling.
|
||||||
|
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||||
|
- Defaults to 0.3.
|
||||||
|
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||||
|
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||||
|
- Defaults to 0.4.
|
||||||
|
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||||
|
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||||
|
- Defaults to 0.7.
|
||||||
|
- **Max tokens**:
|
||||||
|
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||||
|
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Message window size
|
||||||
|
|
||||||
|
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||||||
|
|
||||||
|
Defaults to 1.
|
||||||
|
|
||||||
|
:::tip IMPORTANT
|
||||||
|
This feature is used for multi-turn dialogue *only*. If your **Categorize** component is not part of a multi-turn dialogue (i.e., it is not in a loop), leave this field as-is.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Category name
|
||||||
|
|
||||||
|
A **Categorize** component must have at least two categories. This field sets the name of the category. Click **+ Add Item** to include the intended categories.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
You will notice that the category name is auto-populated. No worries. Each category is assigned a random name upon creation. Feel free to change it to a name that is understandable to the LLM.
|
||||||
|
:::
|
||||||
|
|
||||||
|
#### Description
|
||||||
|
|
||||||
|
Description of this category.
|
||||||
|
|
||||||
|
You can input criteria, situation, or information that may help the LLM determine which inputs belong in this category.
|
||||||
|
|
||||||
|
#### Examples
|
||||||
|
|
||||||
|
Additional examples that may help the LLM determine which inputs belong in this category.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
Examples are more helpful than the description if you want the LLM to classify particular cases into this category.
|
||||||
|
:::
|
||||||
|
|
||||||
|
Once a new category is added, navigate to the **Categorize** component on the canvas, find the **+** button next to the case, and click it to specify the downstream component(s).
|
||||||
|
|
||||||
|
|
||||||
|
#### Output
|
||||||
|
|
||||||
|
The global variable name for the output of the component, which can be referenced by other components in the workflow. Defaults to `category_name`.
|
||||||
40
docs/guides/agent/agent_component_reference/chunker_title.md
Normal file
40
docs/guides/agent/agent_component_reference/chunker_title.md
Normal file
@@ -0,0 +1,40 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 31
|
||||||
|
slug: /chunker_title_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Title chunker component
|
||||||
|
|
||||||
|
A component that splits texts into chunks by heading level.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A **Token chunker** component is a text splitter that uses specified heading level as delimiter to define chunk boundaries and create chunks.
|
||||||
|
|
||||||
|
## Scenario
|
||||||
|
|
||||||
|
A **Title chunker** component is optional, usually placed immediately after **Parser**.
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
Placing a **Title chunker** after a **Token chunker** is invalid and will cause an error. Please note that this restriction is not currently system-enforced and requires your attention.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Hierarchy
|
||||||
|
|
||||||
|
Specifies the heading level to define chunk boundaries:
|
||||||
|
|
||||||
|
- H1
|
||||||
|
- H2
|
||||||
|
- H3 (Default)
|
||||||
|
- H4
|
||||||
|
|
||||||
|
Click **+ Add** to add heading levels here or update the corresponding **Regular Expressions** fields for custom heading patterns.
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The global variable name for the output of the **Title chunker** component, which can be referenced by subsequent components in the ingestion pipeline.
|
||||||
|
|
||||||
|
- Default: `chunks`
|
||||||
|
- Type: `Array<Object>`
|
||||||
43
docs/guides/agent/agent_component_reference/chunker_token.md
Normal file
43
docs/guides/agent/agent_component_reference/chunker_token.md
Normal file
@@ -0,0 +1,43 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 32
|
||||||
|
slug: /chunker_token_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Token chunker component
|
||||||
|
|
||||||
|
A component that splits texts into chunks, respecting a maximum token limit and using delimiters to find optimal breakpoints.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A **Token chunker** component is a text splitter that creates chunks by respecting a recommended maximum token length, using delimiters to ensure logical chunk breakpoints. It splits long texts into appropriately-sized, semantically related chunks.
|
||||||
|
|
||||||
|
|
||||||
|
## Scenario
|
||||||
|
|
||||||
|
A **Token chunker** component is optional, usually placed immediately after **Parser** or **Title chunker**.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Recommended chunk size
|
||||||
|
|
||||||
|
The recommended maximum token limit for each created chunk. The **Token chunker** component creates chunks at specified delimiters. If this token limit is reached before a delimiter, a chunk is created at that point.
|
||||||
|
|
||||||
|
### Overlapped percent (%)
|
||||||
|
|
||||||
|
This defines the overlap percentage between chunks. An appropriate degree of overlap ensures semantic coherence without creating excessive, redundant tokens for the LLM.
|
||||||
|
|
||||||
|
- Default: 0
|
||||||
|
- Maximum: 30%
|
||||||
|
|
||||||
|
|
||||||
|
### Delimiters
|
||||||
|
|
||||||
|
Defaults to `\n`. Click the right-hand **Recycle bin** button to remove it, or click **+ Add** to add a delimiter.
|
||||||
|
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The global variable name for the output of the **Token chunker** component, which can be referenced by subsequent components in the ingestion pipeline.
|
||||||
|
|
||||||
|
- Default: `chunks`
|
||||||
|
- Type: `Array<Object>`
|
||||||
205
docs/guides/agent/agent_component_reference/code.mdx
Normal file
205
docs/guides/agent/agent_component_reference/code.mdx
Normal file
@@ -0,0 +1,205 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 13
|
||||||
|
slug: /code_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Code component
|
||||||
|
|
||||||
|
A component that enables users to integrate Python or JavaScript codes into their Agent for dynamic data processing.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
A **Code** component is essential when you need to integrate complex code logic (Python or JavaScript) into your Agent for dynamic data processing.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
### 1. Ensure gVisor is properly installed
|
||||||
|
|
||||||
|
We use gVisor to isolate code execution from the host system. Please follow [the official installation guide](https://gvisor.dev/docs/user_guide/install/) to install gVisor, ensuring your operating system is compatible before proceeding.
|
||||||
|
|
||||||
|
### 2. Ensure Sandbox is properly installed
|
||||||
|
|
||||||
|
RAGFlow Sandbox is a secure, pluggable code execution backend. It serves as the code executor for the **Code** component. Please follow the [instructions here](https://github.com/infiniflow/ragflow/tree/main/sandbox) to install RAGFlow Sandbox.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
If your RAGFlow Sandbox is not working, please be sure to consult the [Troubleshooting](#troubleshooting) section in this document. We assure you that it addresses 99.99% of the issues!
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 3. (Optional) Install necessary dependencies
|
||||||
|
|
||||||
|
If you need to import your own Python or JavaScript packages into Sandbox, please follow the commands provided in the [How to import my own Python or JavaScript packages into Sandbox?](#how-to-import-my-own-python-or-javascript-packages-into-sandbox) section to install the additional dependencies.
|
||||||
|
|
||||||
|
### 4. Enable Sandbox-specific settings in RAGFlow
|
||||||
|
|
||||||
|
Ensure all Sandbox-specific settings are enabled in **ragflow/docker/.env**.
|
||||||
|
|
||||||
|
### 5. Restart the service after making changes
|
||||||
|
|
||||||
|
Any changes to the configuration or environment *require* a full service restart to take effect.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Input
|
||||||
|
|
||||||
|
You can specify multiple input sources for the **Code** component. Click **+ Add variable** in the **Input variables** section to include the desired input variables.
|
||||||
|
|
||||||
|
### Code
|
||||||
|
|
||||||
|
This field allows you to enter and edit your source code.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
If your code implementation includes defined variables, whether input or output variables, ensure they are also specified in the corresponding **Input** or **Output** sections.
|
||||||
|
:::
|
||||||
|
|
||||||
|
#### A Python code example
|
||||||
|
|
||||||
|
```Python
|
||||||
|
def main(arg1: str, arg2: str) -> dict:
|
||||||
|
return {
|
||||||
|
"result": arg1 + arg2,
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### A JavaScript code example
|
||||||
|
|
||||||
|
```JavaScript
|
||||||
|
|
||||||
|
const axios = require('axios');
|
||||||
|
async function main(args) {
|
||||||
|
try {
|
||||||
|
const response = await axios.get('https://github.com/infiniflow/ragflow');
|
||||||
|
console.log('Body:', response.data);
|
||||||
|
} catch (error) {
|
||||||
|
console.error('Error:', error.message);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### Return values
|
||||||
|
|
||||||
|
You define the output variable(s) of the **Code** component here.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
If you define output variables here, ensure they are also defined in your code implementation; otherwise, their values will be `null`. The following are two examples:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The defined output variable(s) will be auto-populated here.
|
||||||
|
|
||||||
|
## Troubleshooting
|
||||||
|
|
||||||
|
### `HTTPConnectionPool(host='sandbox-executor-manager', port=9385): Read timed out.`
|
||||||
|
|
||||||
|
**Root cause**
|
||||||
|
|
||||||
|
- You did not properly install gVisor and `runsc` was not recognized as a valid Docker runtime.
|
||||||
|
- You did not pull the required base images for the runners and no runner was started.
|
||||||
|
|
||||||
|
**Solution**
|
||||||
|
|
||||||
|
For the gVisor issue:
|
||||||
|
|
||||||
|
1. Install [gVisor](https://gvisor.dev/docs/user_guide/install/).
|
||||||
|
2. Restart Docker.
|
||||||
|
3. Run the following to double check:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker run --rm --runtime=runsc hello-world
|
||||||
|
```
|
||||||
|
|
||||||
|
For the base image issue, pull the required base images:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker pull infiniflow/sandbox-base-nodejs:latest
|
||||||
|
docker pull infiniflow/sandbox-base-python:latest
|
||||||
|
```
|
||||||
|
|
||||||
|
### `HTTPConnectionPool(host='none', port=9385): Max retries exceeded.`
|
||||||
|
|
||||||
|
**Root cause**
|
||||||
|
|
||||||
|
`sandbox-executor-manager` is not mapped in `/etc/hosts`.
|
||||||
|
|
||||||
|
**Solution**
|
||||||
|
|
||||||
|
Add a new entry to `/etc/hosts`:
|
||||||
|
|
||||||
|
`127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager`
|
||||||
|
|
||||||
|
### `Container pool is busy`
|
||||||
|
|
||||||
|
**Root cause**
|
||||||
|
|
||||||
|
All runners are currently in use, executing tasks.
|
||||||
|
|
||||||
|
**Solution**
|
||||||
|
|
||||||
|
Please try again shortly or increase the pool size in the configuration to improve availability and reduce waiting times.
|
||||||
|
|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### How to import my own Python or JavaScript packages into Sandbox?
|
||||||
|
|
||||||
|
To import your Python packages, update **sandbox_base_image/python/requirements.txt** to install the required dependencies. For example, to add the `openpyxl` package, proceed with the following command lines:
|
||||||
|
|
||||||
|
```bash {4,6}
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✓ pwd # make sure you are in the right directory
|
||||||
|
/home/infiniflow/workspace/ragflow/sandbox
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✓ echo "openpyxl" >> sandbox_base_image/python/requirements.txt # add the package to the requirements.txt file
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✗ cat sandbox_base_image/python/requirements.txt # make sure the package is added
|
||||||
|
numpy
|
||||||
|
pandas
|
||||||
|
requests
|
||||||
|
openpyxl # here it is
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_python_0 /bin/bash # entering container to check if the package is installed
|
||||||
|
|
||||||
|
|
||||||
|
# in the container
|
||||||
|
nobody@ffd8a7dd19da:/workspace$ python # launch python shell
|
||||||
|
Python 3.11.13 (main, Aug 12 2025, 22:46:03) [GCC 12.2.0] on linux
|
||||||
|
Type "help", "copyright", "credits" or "license" for more information.
|
||||||
|
>>> import openpyxl # import the package to verify installation
|
||||||
|
>>>
|
||||||
|
# That's okay!
|
||||||
|
```
|
||||||
|
|
||||||
|
To import your JavaScript packages, navigate to `sandbox_base_image/nodejs` and use `npm` to install the required packages. For example, to add the `lodash` package, run the following commands:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✓ pwd
|
||||||
|
/home/infiniflow/workspace/ragflow/sandbox
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✓ cd sandbox_base_image/nodejs
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ npm install lodash
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ cd ../.. # go back to sandbox root directory
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||||
|
|
||||||
|
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_nodejs_0 /bin/bash # entering container to check if the package is installed
|
||||||
|
|
||||||
|
# in the container
|
||||||
|
nobody@dd4bbcabef63:/workspace$ npm list lodash # verify via npm list
|
||||||
|
/workspace
|
||||||
|
`-- lodash@4.17.21 extraneous
|
||||||
|
|
||||||
|
nobody@dd4bbcabef63:/workspace$ ls node_modules | grep lodash # or verify via listing node_modules
|
||||||
|
lodash
|
||||||
|
|
||||||
|
# That's okay!
|
||||||
|
```
|
||||||
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
@@ -0,0 +1,79 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 25
|
||||||
|
slug: /execute_sql
|
||||||
|
---
|
||||||
|
|
||||||
|
# Execute SQL tool
|
||||||
|
|
||||||
|
A tool that execute SQL queries on a specified relational database.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component.
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
- A database instance properly configured and running.
|
||||||
|
- The database must be one of the following types:
|
||||||
|
- MySQL
|
||||||
|
- PostgreSQL
|
||||||
|
- MariaDB
|
||||||
|
- Microsoft SQL Server
|
||||||
|
|
||||||
|
## Examples
|
||||||
|
|
||||||
|
You can pair an **Agent** component with the **Execute SQL** tool, with the **Agent** generating SQL statements and the **Execute SQL** tool handling database connection and query execution. An example of this setup can be found in the **SQL Assistant** Agent template shown below:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### SQL statement
|
||||||
|
|
||||||
|
This text input field allows you to write static SQL queries, such as `SELECT * FROM my_table`, and dynamic SQL queries using variables.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
Click **(x)** or type `/` to insert variables.
|
||||||
|
:::
|
||||||
|
|
||||||
|
For dynamic SQL queries, you can include variables in your SQL queries, such as `SELECT * FROM /sys.query`; if an **Agent** component is paired with the **Execute SQL** tool to generate SQL tasks (see the [Examples](#examples) section), you can directly insert that **Agent**'s output, `content`, into this field.
|
||||||
|
|
||||||
|
### Database type
|
||||||
|
|
||||||
|
The supported database type. Currently the following database types are available:
|
||||||
|
|
||||||
|
- MySQL
|
||||||
|
- PostreSQL
|
||||||
|
- MariaDB
|
||||||
|
- Microsoft SQL Server (Myssql)
|
||||||
|
|
||||||
|
### Database
|
||||||
|
|
||||||
|
Appears only when you select **Split** as method.
|
||||||
|
|
||||||
|
### Username
|
||||||
|
|
||||||
|
The username with access privileges to the database.
|
||||||
|
|
||||||
|
### Host
|
||||||
|
|
||||||
|
The IP address of the database server.
|
||||||
|
|
||||||
|
### Port
|
||||||
|
|
||||||
|
The port number on which the database server is listening.
|
||||||
|
|
||||||
|
### Password
|
||||||
|
|
||||||
|
The password for the database user.
|
||||||
|
|
||||||
|
### Max records
|
||||||
|
|
||||||
|
The maximum number of records returned by the SQL query to control response size and improve efficiency. Defaults to `1024`.
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The **Execute SQL** tool provides two output variables:
|
||||||
|
|
||||||
|
- `formalized_content`: A string. If you reference this variable in a **Message** component, the returned records are displayed as a table.
|
||||||
|
- `json`: An object array. If you reference this variable in a **Message** component, the returned records will be presented as key-value pairs.
|
||||||
29
docs/guides/agent/agent_component_reference/indexer.md
Normal file
29
docs/guides/agent/agent_component_reference/indexer.md
Normal file
@@ -0,0 +1,29 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 40
|
||||||
|
slug: /indexer_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Indexer component
|
||||||
|
|
||||||
|
A component that defines how chunks are indexed.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
An **Indexer** component indexes chunks and configures their storage formats in the document engine.
|
||||||
|
|
||||||
|
## Scenario
|
||||||
|
|
||||||
|
An **Indexer** component is the mandatory ending component for all ingestion pipelines.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Search method
|
||||||
|
|
||||||
|
This setting configures how chunks are stored in the document engine: as full-text, embeddings, or both.
|
||||||
|
|
||||||
|
### Filename embedding weight
|
||||||
|
|
||||||
|
This setting defines the filename's contribution to the final embedding, which is a weighted combination of both the chunk content and the filename. Essentially, a higher value gives the filename more influence in the final *composite* embedding.
|
||||||
|
|
||||||
|
- 0.1: Filename contributes 10% (chunk content 90%)
|
||||||
|
- 0.5 (maximum): Filename contributes 50% (chunk content 90%)
|
||||||
65
docs/guides/agent/agent_component_reference/iteration.mdx
Normal file
65
docs/guides/agent/agent_component_reference/iteration.mdx
Normal file
@@ -0,0 +1,65 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 7
|
||||||
|
slug: /iteration_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Iteration component
|
||||||
|
|
||||||
|
A component that splits text input into text segments and iterates a predefined workflow for each one.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
An **Interaction** component can divide text input into text segments and apply its built-in component workflow to each segment.
|
||||||
|
|
||||||
|
|
||||||
|
## Scenario
|
||||||
|
|
||||||
|
An **Iteration** component is essential when a workflow loop is required and the loop count is *not* fixed but depends on number of segments created from the output of specific agent components.
|
||||||
|
|
||||||
|
- If, for instance, you plan to feed several paragraphs into an LLM for content generation, each with its own focus, and feeding them to the LLM all at once could create confusion or contradictions, then you can use an **Iteration** component, which encapsulates a **Generate** component, to repeat the content generation process for each paragraph.
|
||||||
|
- Another example: If you wish to use the LLM to translate a lengthy paper into a target language without exceeding its token limit, consider using an **Iteration** component, which encapsulates a **Generate** component, to break the paper into smaller pieces and repeat the translation process for each one.
|
||||||
|
|
||||||
|
## Internal components
|
||||||
|
|
||||||
|
### IterationItem
|
||||||
|
|
||||||
|
Each **Iteration** component includes an internal **IterationItem** component. The **IterationItem** component serves as both the starting point and input node of the workflow within the **Iteration** component. It manages the loop of the workflow for all text segments created from the input.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
The **IterationItem** component is visible *only* to the components encapsulated by the current **Iteration** components.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Build an internal workflow
|
||||||
|
|
||||||
|
You are allowed to pull other components into the **Iteration** component to build an internal workflow, and these "added internal components" are no longer visible to components outside of the current **Iteration** component.
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
To reference the created text segments from an added internal component, simply add a **Reference** variable that equals **IterationItem** within the **Input** section of that internal component. There is no need to reference the corresponding external component, as the **IterationItem** component manages the loop of the workflow for all created text segments.
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
An added internal component can reference an external component when necessary.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Input
|
||||||
|
|
||||||
|
The **Iteration** component uses input variables to specify its data inputs, namely the texts to be segmented. You are allowed to specify multiple input sources for the **Iteration** component. Click **+ Add variable** in the **Input** section to include the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||||
|
|
||||||
|
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||||
|
- A component ID under **Component Output**, or
|
||||||
|
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||||
|
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||||
|
|
||||||
|
### Delimiter
|
||||||
|
|
||||||
|
The delimiter to use to split the text input into segments:
|
||||||
|
|
||||||
|
- Comma (Default)
|
||||||
|
- Line break
|
||||||
|
- Tab
|
||||||
|
- Underline
|
||||||
|
- Forward slash
|
||||||
|
- Dash
|
||||||
|
- Semicolon
|
||||||
21
docs/guides/agent/agent_component_reference/message.mdx
Normal file
21
docs/guides/agent/agent_component_reference/message.mdx
Normal file
@@ -0,0 +1,21 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 4
|
||||||
|
slug: /message_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Message component
|
||||||
|
|
||||||
|
A component that sends out a static or dynamic message.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
As the final component of the workflow, a Message component returns the workflow’s ultimate data output accompanied by predefined message content. The system selects one message at random if multiple messages are provided.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Messages
|
||||||
|
|
||||||
|
The message to send out. Click `(x)` or type `/` to quickly insert variables.
|
||||||
|
|
||||||
|
Click **+ Add message** to add message options. When multiple messages are supplied, the **Message** component randomly selects one to send.
|
||||||
|
|
||||||
17
docs/guides/agent/agent_component_reference/parser.md
Normal file
17
docs/guides/agent/agent_component_reference/parser.md
Normal file
@@ -0,0 +1,17 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 30
|
||||||
|
slug: /parser_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Parser component
|
||||||
|
|
||||||
|
A component that sets the parsing rules for your dataset.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A **Parser** component defines how various file types should be parsed, including parsing methods for PDFs , fields to parse for Emails, and OCR methods for images.
|
||||||
|
|
||||||
|
|
||||||
|
## Scenario
|
||||||
|
|
||||||
|
A **Parser** component is auto-populated on the ingestion pipeline canvas and required in all ingestion pipeline workflows.
|
||||||
145
docs/guides/agent/agent_component_reference/retrieval.mdx
Normal file
145
docs/guides/agent/agent_component_reference/retrieval.mdx
Normal file
@@ -0,0 +1,145 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 3
|
||||||
|
slug: /retrieval_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Retrieval component
|
||||||
|
|
||||||
|
A component that retrieves information from specified datasets.
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
A **Retrieval** component is essential in most RAG scenarios, where information is extracted from designated datasets before being sent to the LLM for content generation. A **Retrieval** component can operate either as a standalone workflow module or as a tool for an **Agent** component. In the latter role, the **Agent** component has autonomous control over when to invoke it for query and retrieval.
|
||||||
|
|
||||||
|
The following screenshot shows a reference design using the **Retrieval** component, where the component serves as a tool for an **Agent** component. You can find it from the **Report Agent Using Knowledge Base** Agent template.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Prerequisites
|
||||||
|
|
||||||
|
Ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||||
|
|
||||||
|
## Quickstart
|
||||||
|
|
||||||
|
### 1. Click on a **Retrieval** component to show its configuration panel
|
||||||
|
|
||||||
|
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Retrieval** component's search behavior.
|
||||||
|
|
||||||
|
### 2. Input query variable(s)
|
||||||
|
|
||||||
|
The **Retrieval** component depends on query variables to specify its queries.
|
||||||
|
|
||||||
|
:::caution IMPORTANT
|
||||||
|
- If you use the **Retrieval** component as a standalone workflow module, input query variables in the **Input Variables** text box.
|
||||||
|
- If it is used as a tool for an **Agent** component, input the query variables in the **Agent** component's **User prompt** field.
|
||||||
|
:::
|
||||||
|
|
||||||
|
By default, you can use `sys.query`, which is the user query and the default output of the **Begin** component. All global variables defined before the **Retrieval** component can also be used as query statements. Use the `(x)` button or type `/` to show all the available query variables.
|
||||||
|
|
||||||
|
### 3. Select dataset(s) to query
|
||||||
|
|
||||||
|
You can specify one or multiple datasets to retrieve data from. If selecting mutiple, ensure they use the same embedding model.
|
||||||
|
|
||||||
|
### 4. Expand **Advanced Settings** to configure the retrieval method
|
||||||
|
|
||||||
|
By default, a combination of weighted keyword similarity and weighted vector cosine similarity is used for retrieval. If a rerank model is selected, a combination of weighted keyword similarity and weighted reranking score will be used instead.
|
||||||
|
|
||||||
|
As a starter, you can skip this step to stay with the default retrieval method.
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
Using a rerank model will *significantly* increase the system's response time. If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### 5. Enable cross-language search
|
||||||
|
|
||||||
|
If your user query is different from the languages of the datasets, you can select the target languages in the **Cross-language search** dropdown menu. The model will then translates queries to ensure accurate matching of semantic meaning across languages.
|
||||||
|
|
||||||
|
|
||||||
|
### 6. Test retrieval results
|
||||||
|
|
||||||
|
Click the **Run** button on the top of canvas to test the retrieval results.
|
||||||
|
|
||||||
|
### 7. Choose the next component
|
||||||
|
|
||||||
|
When necessary, click the **+** button on the **Retrieval** component to choose the next component in the worflow from the dropdown list.
|
||||||
|
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Query variables
|
||||||
|
|
||||||
|
*Mandatory*
|
||||||
|
|
||||||
|
Select the query source for retrieval. Defaults to `sys.query`, which is the default output of the **Begin** component.
|
||||||
|
|
||||||
|
The **Retrieval** component relies on query variables to specify its queries. All global variables defined before the **Retrieval** component can also be used as queries. Use the `(x)` button or type `/` to show all the available query variables.
|
||||||
|
|
||||||
|
### Knowledge bases
|
||||||
|
|
||||||
|
Select the dataset(s) to retrieve data from.
|
||||||
|
|
||||||
|
- If no dataset is selected, meaning conversations with the agent will not be based on any dataset, ensure that the **Empty response** field is left blank to avoid an error.
|
||||||
|
- If you select multiple datasets, you must ensure that the datasets you select use the same embedding model; otherwise, an error message would occur.
|
||||||
|
|
||||||
|
### Similarity threshold
|
||||||
|
|
||||||
|
RAGFlow employs a combination of weighted keyword similarity and weighted vector cosine similarity during retrieval. This parameter sets the threshold for similarities between the user query and chunks stored in the datasets. Any chunk with a similarity score below this threshold will be excluded from the results.
|
||||||
|
|
||||||
|
Defaults to 0.2.
|
||||||
|
|
||||||
|
### Vector similarity weight
|
||||||
|
|
||||||
|
This parameter sets the weight of vector similarity in the composite similarity score. The total of the two weights must equal 1.0. Its default value is 0.3, which means the weight of keyword similarity in a combined search is 1 - 0.3 = 0.7.
|
||||||
|
|
||||||
|
### Top N
|
||||||
|
|
||||||
|
This parameter selects the "Top N" chunks from retrieved ones and feed them to the LLM.
|
||||||
|
|
||||||
|
Defaults to 8.
|
||||||
|
|
||||||
|
|
||||||
|
### Rerank model
|
||||||
|
|
||||||
|
*Optional*
|
||||||
|
|
||||||
|
If a rerank model is selected, a combination of weighted keyword similarity and weighted reranking score will be used for retrieval.
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
Using a rerank model will *significantly* increase the system's response time.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Empty response
|
||||||
|
|
||||||
|
- Set this as a response if no results are retrieved from the dataset(s) for your query, or
|
||||||
|
- Leave this field blank to allow the chat model to improvise when nothing is found.
|
||||||
|
|
||||||
|
:::caution WARNING
|
||||||
|
If you do not specify a dataset, you must leave this field blank; otherwise, an error would occur.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Cross-language search
|
||||||
|
|
||||||
|
Select one or more languages for cross‑language search. If no language is selected, the system searches with the original query.
|
||||||
|
|
||||||
|
### Use knowledge graph
|
||||||
|
|
||||||
|
:::caution IMPORTANT
|
||||||
|
Before enabling this feature, ensure you have properly [constructed a knowledge graph from each target dataset](../../dataset/construct_knowledge_graph.md).
|
||||||
|
:::
|
||||||
|
|
||||||
|
Whether to use knowledge graph(s) in the specified dataset(s) during retrieval for multi-hop question answering. When enabled, this would involve iterative searches across entity, relationship, and community report chunks, greatly increasing retrieval time.
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The global variable name for the output of the **Retrieval** component, which can be referenced by other components in the workflow.
|
||||||
|
|
||||||
|
|
||||||
|
## Frequently asked questions
|
||||||
|
|
||||||
|
### How to reduce response time?
|
||||||
|
|
||||||
|
Go through the checklist below for best performance:
|
||||||
|
|
||||||
|
- Leave the **Rerank model** field empty.
|
||||||
|
- If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||||
|
- Disable **Use knowledge graph**.
|
||||||
50
docs/guides/agent/agent_component_reference/switch.mdx
Normal file
50
docs/guides/agent/agent_component_reference/switch.mdx
Normal file
@@ -0,0 +1,50 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 6
|
||||||
|
slug: /switch_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Switch component
|
||||||
|
|
||||||
|
A component that evaluates whether specified conditions are met and directs the follow of execution accordingly.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A **Switch** component evaluates conditions based on the output of specific components, directing the flow of execution accordingly to enable complex branching logic.
|
||||||
|
|
||||||
|
## Scenarios
|
||||||
|
|
||||||
|
A **Switch** component is essential for condition-based direction of execution flow. While it shares similarities with the [Categorize](./categorize.mdx) component, which is also used in multi-pronged strategies, the key distinction lies in their approach: the evaluation of the **Switch** component is rule-based, whereas the **Categorize** component involves AI and uses an LLM for decision-making.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Case n
|
||||||
|
|
||||||
|
A **Switch** component must have at least one case, each with multiple specified conditions. When multiple conditions are specified for a case, you must set the logical relationship between them to either AND or OR.
|
||||||
|
|
||||||
|
Once a new case is added, navigate to the **Switch** component on the canvas, find the **+** button next to the case, and click it to specify the downstream component(s).
|
||||||
|
|
||||||
|
|
||||||
|
#### Condition
|
||||||
|
|
||||||
|
Evaluates whether the output of specific components meets certain conditions
|
||||||
|
|
||||||
|
:::danger IMPORTANT
|
||||||
|
When you have added multiple conditions for a specific case, a **Logical operator** field appears, requiring you to set the logical relationship between these conditions as either AND or OR.
|
||||||
|
:::
|
||||||
|
|
||||||
|
- **Operator**: The operator required to form a conditional expression.
|
||||||
|
- Equals (default)
|
||||||
|
- Not equal
|
||||||
|
- Greater than
|
||||||
|
- Greater equal
|
||||||
|
- Less than
|
||||||
|
- Less equal
|
||||||
|
- Contains
|
||||||
|
- Not contains
|
||||||
|
- Starts with
|
||||||
|
- Ends with
|
||||||
|
- Is empty
|
||||||
|
- Not empty
|
||||||
|
- **Value**: A single value, which can be an integer, float, or string.
|
||||||
|
- Delimiters, multiple values, or expressions are *not* supported.
|
||||||
|
|
||||||
@@ -0,0 +1,38 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 15
|
||||||
|
slug: /text_processing
|
||||||
|
---
|
||||||
|
|
||||||
|
# Text processing component
|
||||||
|
|
||||||
|
A component that merges or splits texts.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A **Text processing** component merges or splits texts.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Method
|
||||||
|
|
||||||
|
- Split: Split the text
|
||||||
|
- Merge: Merge the text
|
||||||
|
|
||||||
|
### Split_ref
|
||||||
|
|
||||||
|
Appears only when you select **Split** as method.
|
||||||
|
|
||||||
|
The variable to be split. Type `/` to quickly insert variables.
|
||||||
|
|
||||||
|
### Script
|
||||||
|
|
||||||
|
Template for the merge. Appears only when you select **Merge** as method. Type `/` to quickly insert variables.
|
||||||
|
|
||||||
|
### Delimiters
|
||||||
|
|
||||||
|
The delimiter(s) used to split or merge the text.
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The global variable name for the output of the component, which can be referenced by other components in the workflow.
|
||||||
|
|
||||||
80
docs/guides/agent/agent_component_reference/transformer.md
Normal file
80
docs/guides/agent/agent_component_reference/transformer.md
Normal file
@@ -0,0 +1,80 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 37
|
||||||
|
slug: /transformer_component
|
||||||
|
---
|
||||||
|
|
||||||
|
# Transformer component
|
||||||
|
|
||||||
|
A component that uses an LLM to extract insights from the chunks.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
A **Transformer** component indexes chunks and configures their storage formats in the document engine. It *typically* precedes the **Indexer** in the ingestion pipeline, but you can also chain multiple **Transformer** components in sequence.
|
||||||
|
|
||||||
|
## Scenario
|
||||||
|
|
||||||
|
A **Transformer** component is essential when you need the LLM to extract new information, such as keywords, questions, metadata, and summaries, from the original chunks.
|
||||||
|
|
||||||
|
## Configurations
|
||||||
|
|
||||||
|
### Model
|
||||||
|
|
||||||
|
Click the dropdown menu of **Model** to show the model configuration window.
|
||||||
|
|
||||||
|
- **Model**: The chat model to use.
|
||||||
|
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||||
|
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||||
|
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||||
|
This parameter has three options:
|
||||||
|
- **Improvise**: Produces more creative responses.
|
||||||
|
- **Precise**: (Default) Produces more conservative responses.
|
||||||
|
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||||
|
- **Temperature**: The randomness level of the model's output.
|
||||||
|
Defaults to 0.1.
|
||||||
|
- Lower values lead to more deterministic and predictable outputs.
|
||||||
|
- Higher values lead to more creative and varied outputs.
|
||||||
|
- A temperature of zero results in the same output for the same prompt.
|
||||||
|
- **Top P**: Nucleus sampling.
|
||||||
|
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||||
|
- Defaults to 0.3.
|
||||||
|
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||||
|
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||||
|
- Defaults to 0.4.
|
||||||
|
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||||
|
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||||
|
- Defaults to 0.7.
|
||||||
|
- **Max tokens**:
|
||||||
|
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||||
|
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creativity**.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### Result destination
|
||||||
|
|
||||||
|
Select the type of output to be generated by the LLM:
|
||||||
|
|
||||||
|
- Summary
|
||||||
|
- Keywords
|
||||||
|
- Questions
|
||||||
|
- Metadata
|
||||||
|
|
||||||
|
### System prompt
|
||||||
|
|
||||||
|
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering.
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
The system prompt here automatically updates to match your selected **Result destination**.
|
||||||
|
:::
|
||||||
|
|
||||||
|
### User prompt
|
||||||
|
|
||||||
|
The user-defined prompt. For example, you can type `/` or click **(x)** to insert variables of preceding components in the ingestion pipeline as the LLM's input.
|
||||||
|
|
||||||
|
### Output
|
||||||
|
|
||||||
|
The global variable name for the output of the **Transformer** component, which can be referenced by subsequent **Transformer** components in the ingestion pipeline.
|
||||||
|
|
||||||
|
- Default: `chunks`
|
||||||
|
- Type: `Array<Object>`
|
||||||
51
docs/guides/agent/agent_introduction.md
Normal file
51
docs/guides/agent/agent_introduction.md
Normal file
@@ -0,0 +1,51 @@
|
|||||||
|
---
|
||||||
|
sidebar_position: 1
|
||||||
|
slug: /agent_introduction
|
||||||
|
---
|
||||||
|
|
||||||
|
# Introduction to agents
|
||||||
|
|
||||||
|
Key concepts, basic operations, a quick view of the agent editor.
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
:::danger DEPRECATED!
|
||||||
|
A new version is coming soon.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Key concepts
|
||||||
|
|
||||||
|
Agents and RAG are complementary techniques, each enhancing the other’s capabilities in business applications. RAGFlow v0.8.0 introduces an agent mechanism, featuring a no-code workflow editor on the front end and a comprehensive graph-based task orchestration framework on the back end. This mechanism is built on top of RAGFlow's existing RAG solutions and aims to orchestrate search technologies such as query intent classification, conversation leading, and query rewriting to:
|
||||||
|
|
||||||
|
- Provide higher retrievals and,
|
||||||
|
- Accommodate more complex scenarios.
|
||||||
|
|
||||||
|
## Create an agent
|
||||||
|
|
||||||
|
:::tip NOTE
|
||||||
|
|
||||||
|
Before proceeding, ensure that:
|
||||||
|
|
||||||
|
1. You have properly set the LLM to use. See the guides on [Configure your API key](../models/llm_api_key_setup.md) or [Deploy a local LLM](../models/deploy_local_llm.mdx) for more information.
|
||||||
|
2. You have a dataset configured and the corresponding files properly parsed. See the guide on [Configure a dataset](../dataset/configure_knowledge_base.md) for more information.
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
Click the **Agent** tab in the middle top of the page to show the **Agent** page. As shown in the screenshot below, the cards on this page represent the created agents, which you can continue to edit.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
We also provide templates catered to different business scenarios. You can either generate your agent from one of our agent templates or create one from scratch:
|
||||||
|
|
||||||
|
1. Click **+ Create agent** to show the **agent template** page:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
2. To create an agent from scratch, click **Create Agent**. Alternatively, to create an agent from one of our templates, click the desired card, such as **Deep Research**, name your agent in the pop-up dialogue, and click **OK** to confirm.
|
||||||
|
|
||||||
|
*You are now taken to the **no-code workflow editor** page.*
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
3. Click the **+** button on the **Begin** component to select the desired components in your workflow.
|
||||||
|
4. Click **Save** to apply changes to your agent.
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user