add docs
This commit is contained in:
8
docs/guides/agent/_category_.json
Normal file
8
docs/guides/agent/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Agents",
|
||||
"position": 3,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "RAGFlow v0.8.0 introduces an agent mechanism, featuring a no-code workflow editor on the front end and a comprehensive graph-based task orchestration framework on the backend."
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Agent Components",
|
||||
"position": 20,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "A complete reference for RAGFlow's agent components."
|
||||
}
|
||||
}
|
||||
233
docs/guides/agent/agent_component_reference/agent.mdx
Normal file
233
docs/guides/agent/agent_component_reference/agent.mdx
Normal file
@@ -0,0 +1,233 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /agent_component
|
||||
---
|
||||
|
||||
# Agent component
|
||||
|
||||
The component equipped with reasoning, tool usage, and multi-agent collaboration capabilities.
|
||||
|
||||
---
|
||||
|
||||
An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.5 onwards, an **Agent** component is able to work independently and with the following capabilities:
|
||||
|
||||
- Autonomous reasoning with reflection and adjustment based on environmental feedback.
|
||||
- Use of tools or subagents to complete tasks.
|
||||
|
||||
## Scenarios
|
||||
|
||||
An **Agent** component is essential when you need the LLM to assist with summarizing, translating, or controlling various tasks.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
1. Ensure you have a chat model properly configured:
|
||||
|
||||

|
||||
|
||||
2. If your Agent involves dataset retrieval, ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on an **Agent** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||
|
||||
### 2. Select your model
|
||||
|
||||
Click **Model**, and select a chat model from the dropdown menu.
|
||||
|
||||
:::tip NOTE
|
||||
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||
:::
|
||||
|
||||
### 3. Update system prompt (Optional)
|
||||
|
||||
The system prompt typically defines your model's role. You can either keep the system prompt as is or customize it to override the default.
|
||||
|
||||
|
||||
### 4. Update user prompt
|
||||
|
||||
The user prompt typically defines your model's task. You will find the `sys.query` variable auto-populated. Type `/` or click **(x)** to view or add variables.
|
||||
|
||||
In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents below), then you may also need to specify retrieved chunks using the `formalized_content` variable:
|
||||
|
||||
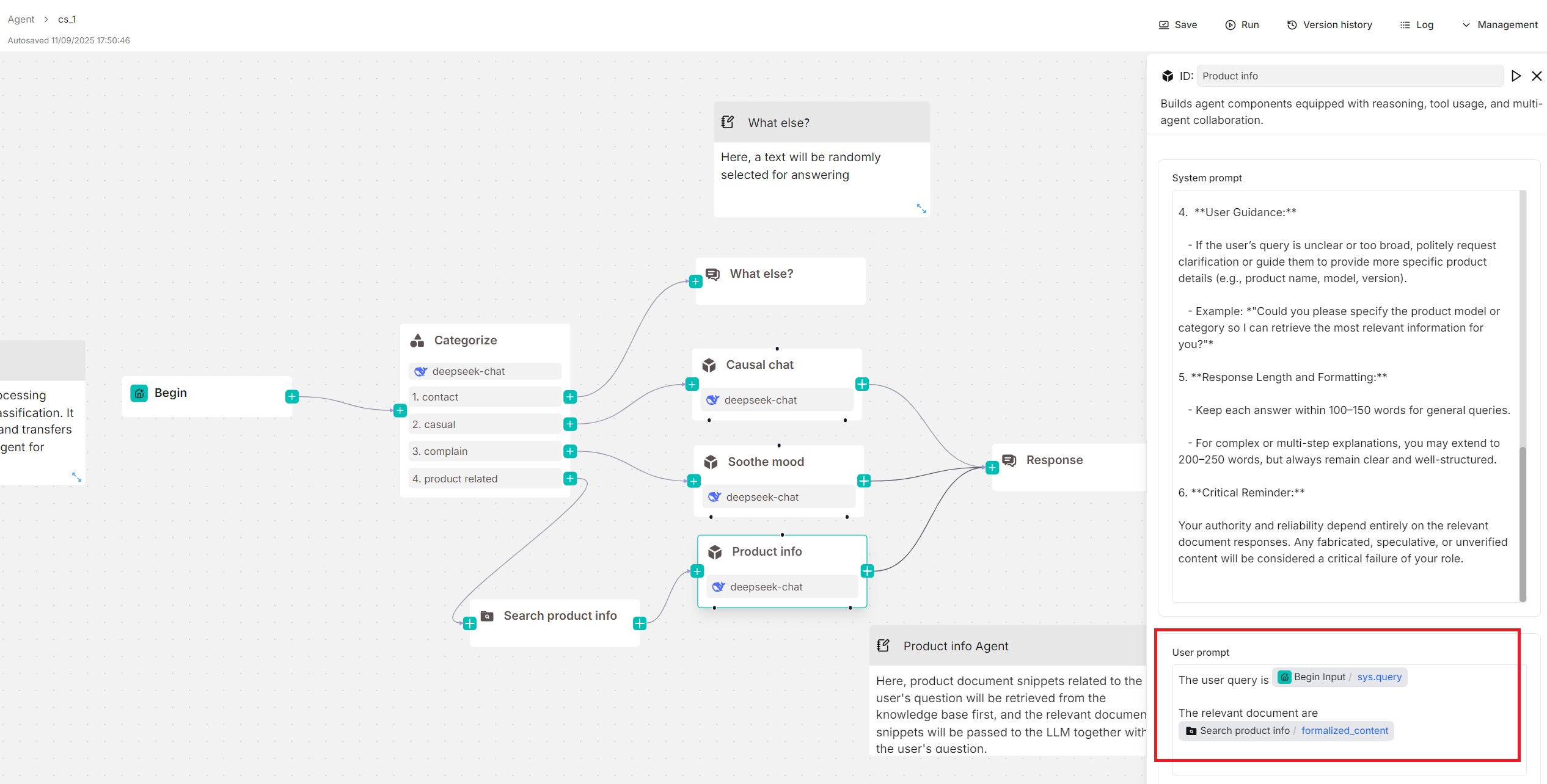
|
||||
|
||||
### 5. Skip Tools and Agent
|
||||
|
||||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||
|
||||
### 6. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Agent** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
## Connect to an MCP server as a client
|
||||
|
||||
:::danger IMPORTANT
|
||||
In this section, we assume your **Agent** will be configured as a planner, with a Tavily tool beneath it.
|
||||
:::
|
||||
|
||||
### 1. Navigate to the MCP configuration page
|
||||
|
||||

|
||||
|
||||
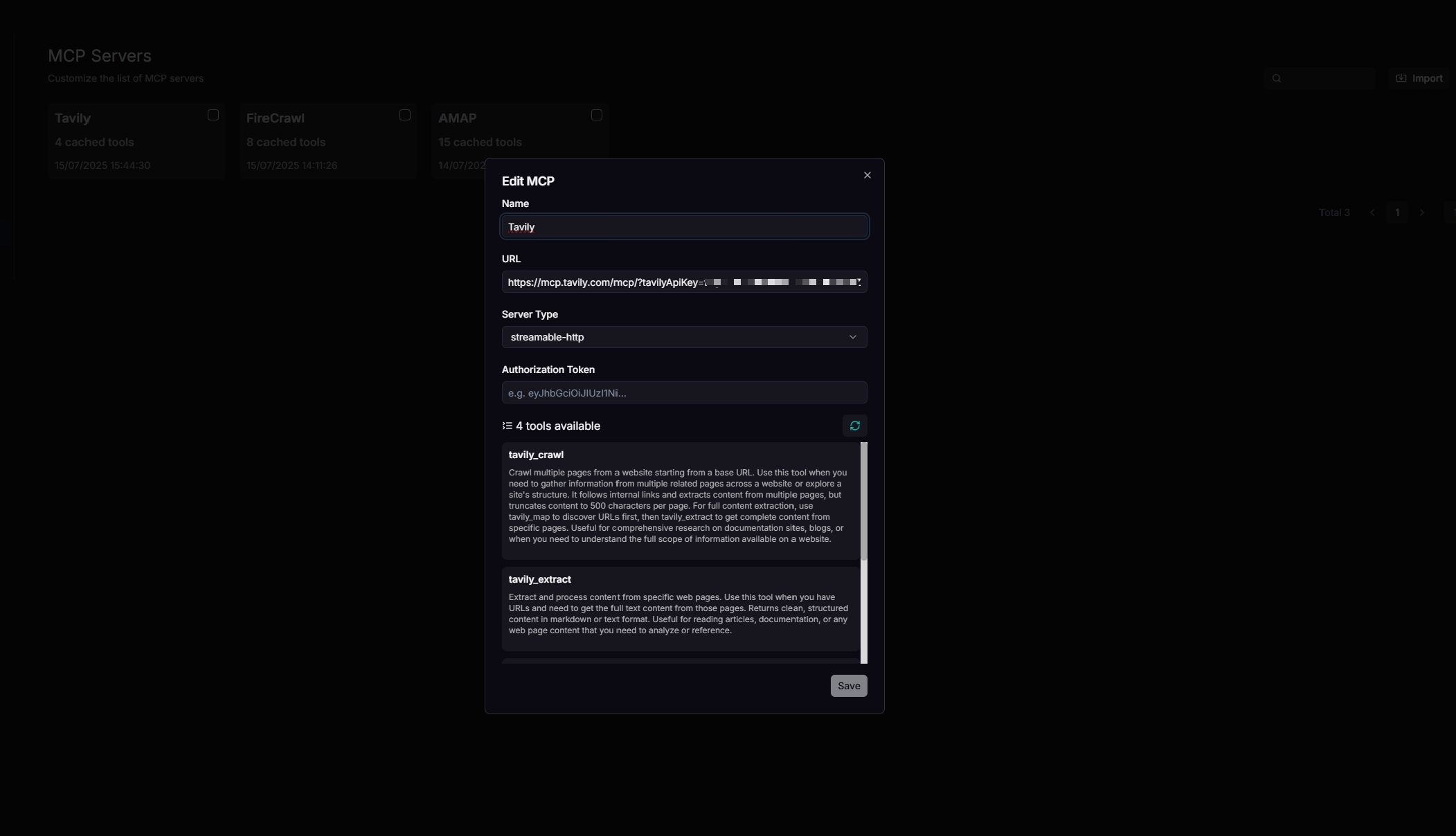
### 2. Configure your Tavily MCP server
|
||||
|
||||
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||
|
||||
|
||||
|
||||
### 3. Navigate to your Agent's editing page
|
||||
|
||||
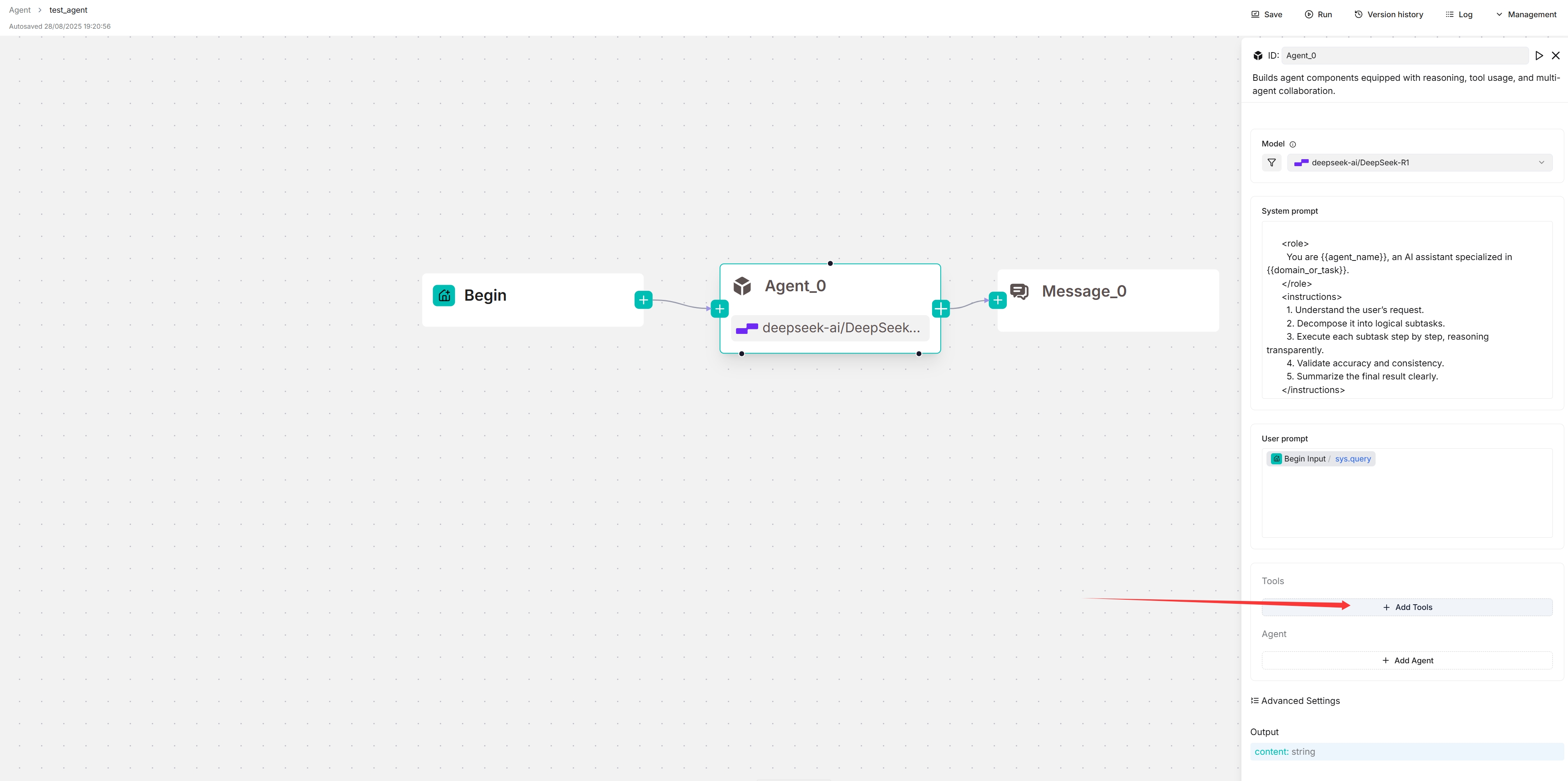
### 4. Connect to your MCP server
|
||||
|
||||
1. Click **+ Add tools**:
|
||||
|
||||
|
||||
|
||||
2. Click **MCP** to show the available MCP servers.
|
||||
|
||||
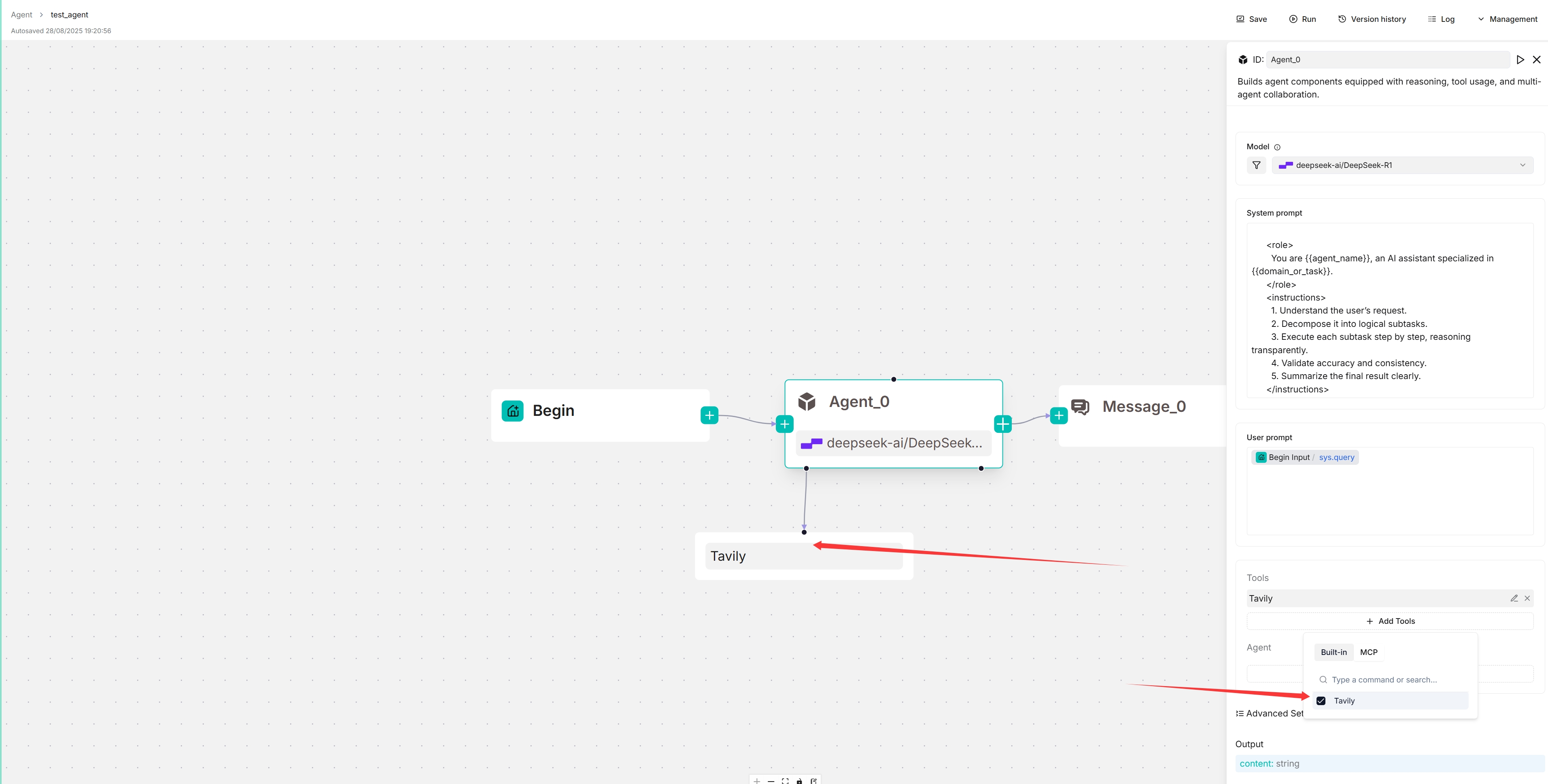
3. Select your MCP server:
|
||||
|
||||
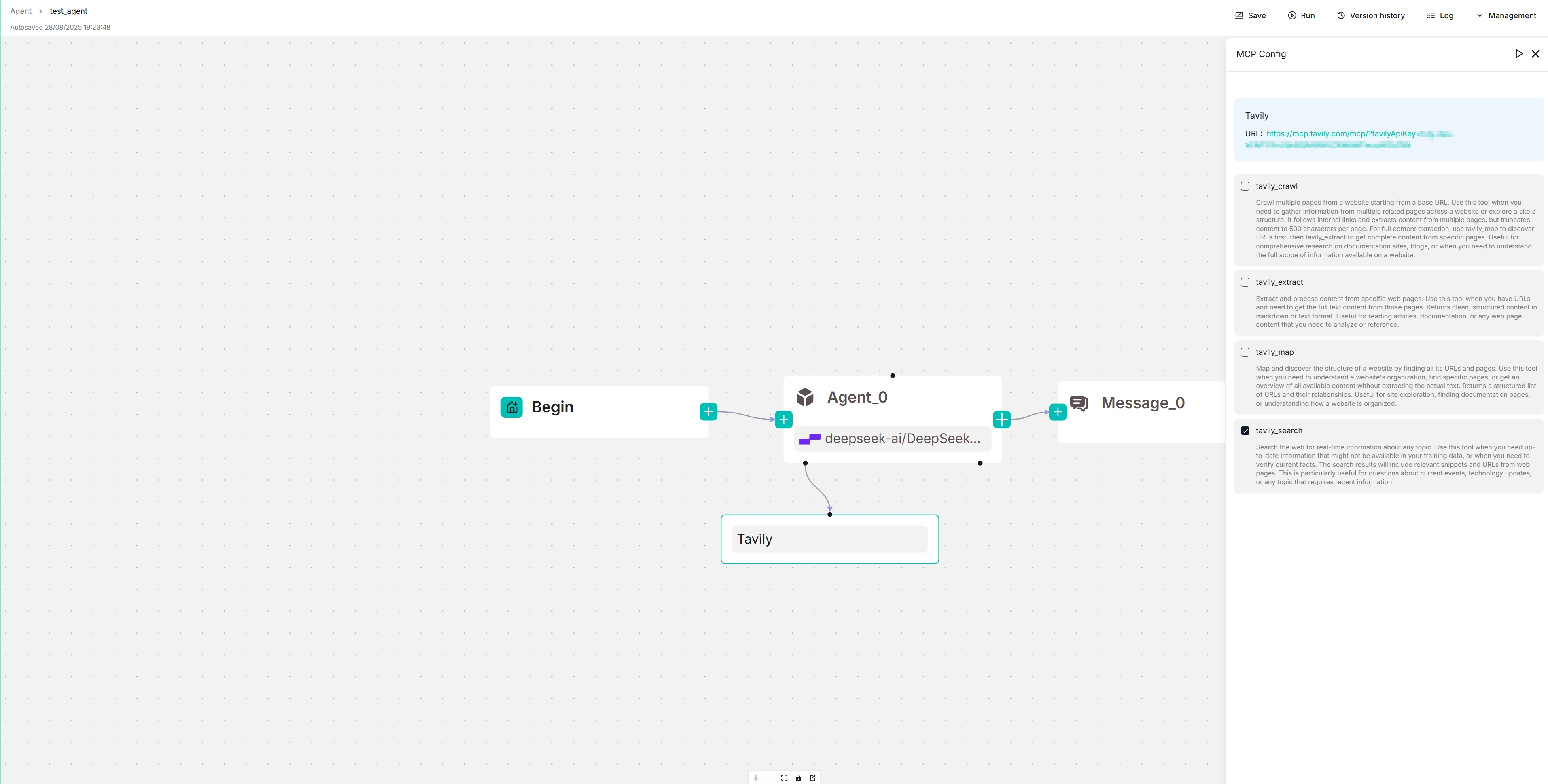
*The target MCP server appears below your Agent component, and your Agent will autonomously decide when to invoke the available tools it offers.*
|
||||
|
||||
|
||||
|
||||
### 5. Update system prompt to specify trigger conditions (Optional)
|
||||
|
||||
To ensure reliable tool calls, you may specify within the system prompt which tasks should trigger each tool call.
|
||||
|
||||
### 6. View the availabe tools of your MCP server
|
||||
|
||||
On the canvas, click the newly-populated Tavily server to view and select its available tools:
|
||||
|
||||
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
### Model
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
||||
:::
|
||||
|
||||
### System prompt
|
||||
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering. However, please be aware that the system prompt is often used in conjunction with keys (variables), which serve as various data inputs for the LLM.
|
||||
|
||||
An **Agent** component relies on keys (variables) to specify its data inputs. Its immediate upstream component is *not* necessarily its data input, and the arrows in the workflow indicate *only* the processing sequence. Keys in a **Agent** component are used in conjunction with the system prompt to specify data inputs for the LLM. Use a forward slash `/` or the **(x)** button to show the keys to use.
|
||||
|
||||
#### Advanced usage
|
||||
|
||||
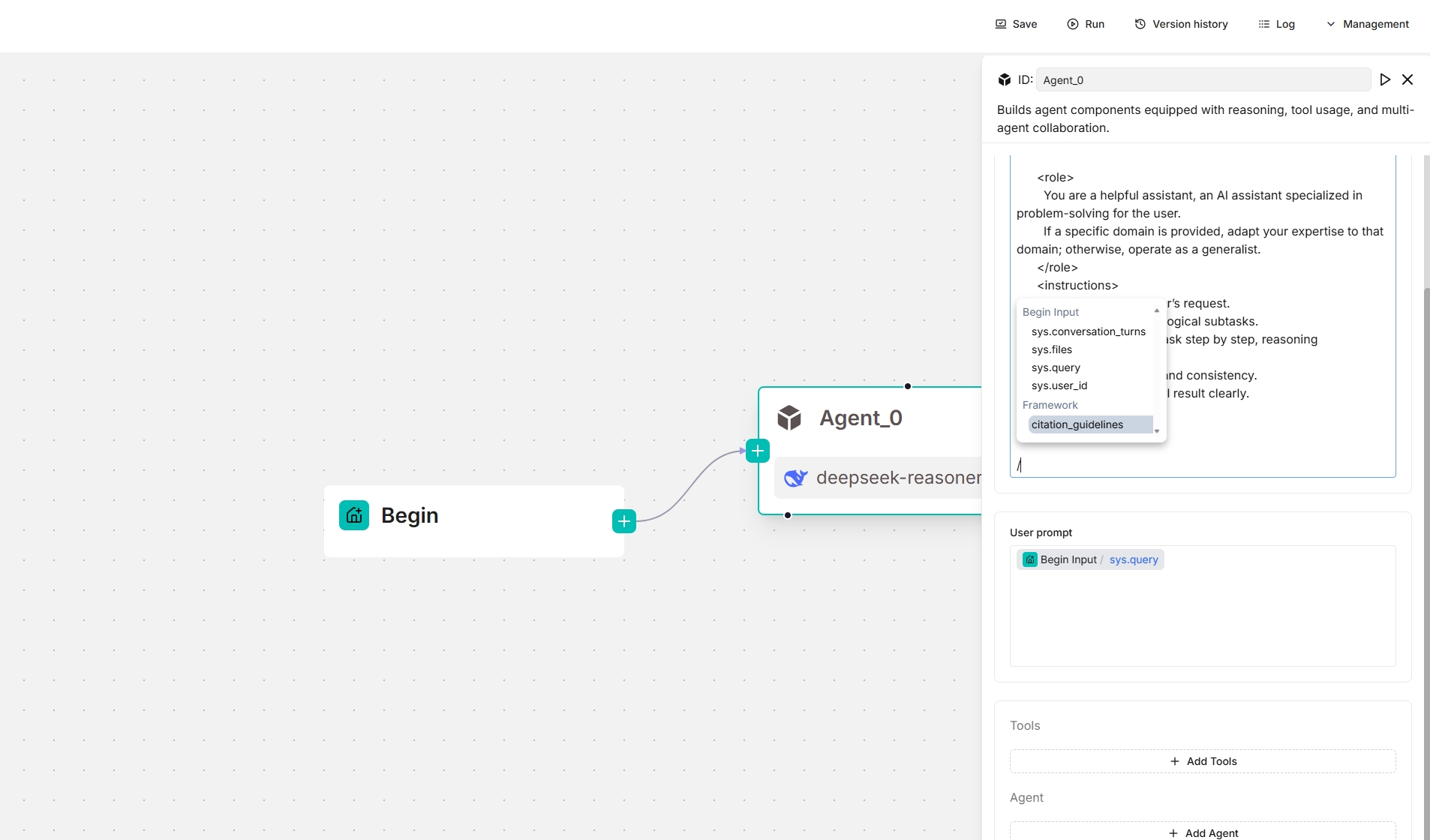
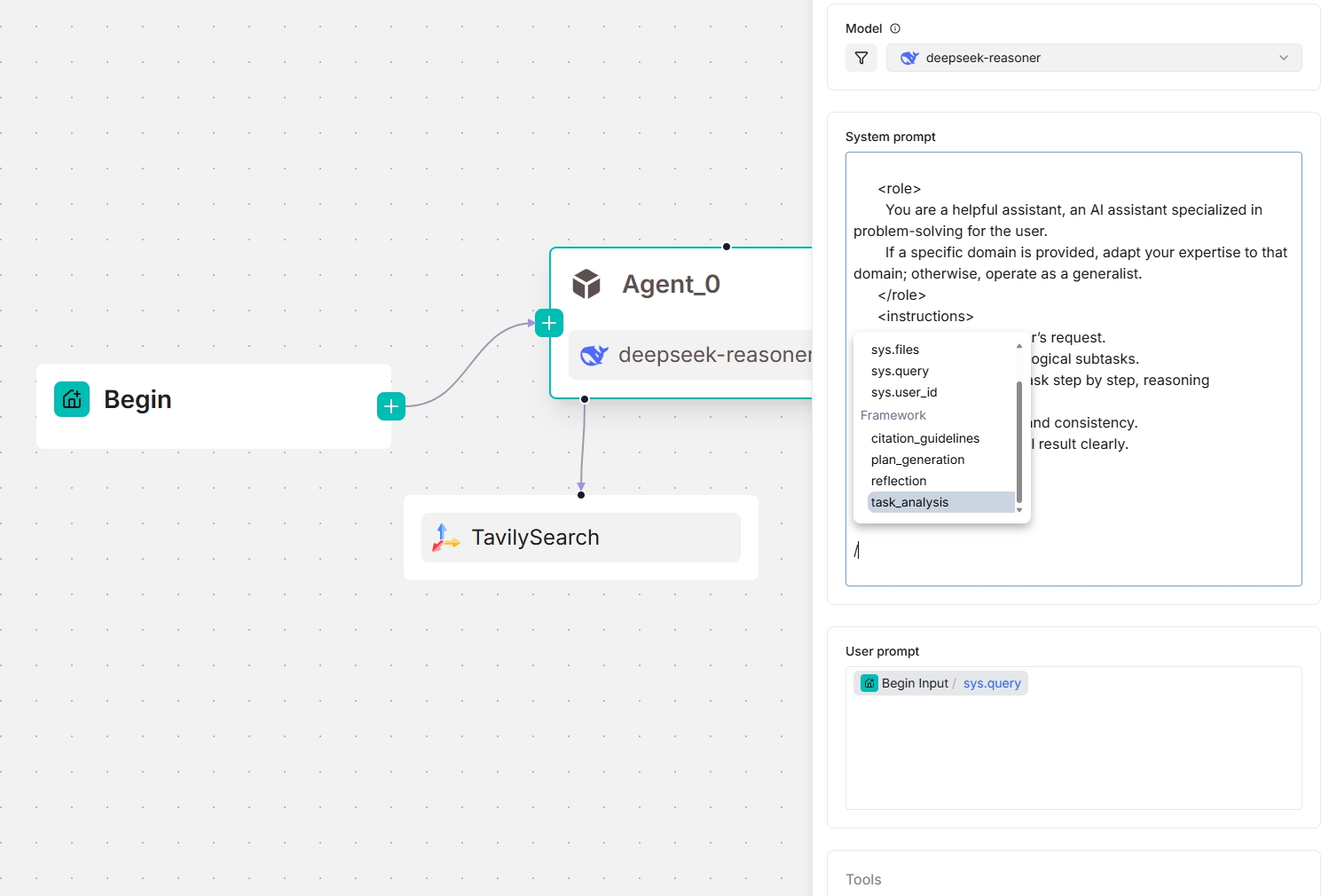
From v0.20.5 onwards, four framework-level prompt blocks are available in the **System prompt** field, enabling you to customize and *override* prompts at the framework level. Type `/` or click **(x)** to view them; they appear under the **Framework** entry in the dropdown menu.
|
||||
|
||||
- `task_analysis` prompt block
|
||||
- This block is responsible for analyzing tasks — either a user task or a task assigned by the lead Agent when the **Agent** component is acting as a Sub-Agent.
|
||||
- Reference design: [analyze_task_system.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_system.md) and [analyze_task_user.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/analyze_task_user.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `agent_prompt`: The system prompt.
|
||||
- `task`: The user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent when delegating tasks.
|
||||
- `tool_desc`: A description of the tools and sub_Agents that can be called.
|
||||
- `context`: The operational context, which stores interactions between the Agent, tools, and sub-agents; initially empty.
|
||||
- `plan_generation` prompt block
|
||||
- This block creates a plan for the **Agent** component to execute next, based on the task analysis results.
|
||||
- Reference design: [next_step.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/next_step.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `task_analysis`: The analysis result of the current task.
|
||||
- `desc`: A description of the tools or sub-Agents currently being called.
|
||||
- `today`: The date of today.
|
||||
- `reflection` prompt block
|
||||
- This block enables the **Agent** component to reflect, improving task accuracy and efficiency.
|
||||
- Reference design: [reflect.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/reflect.md)
|
||||
- Available *only* when this **Agent** component is acting as a planner, with either tools or sub-Agents under it.
|
||||
- Input variables:
|
||||
- `goal`: The goal of the current task. It is the user prompt for either a lead Agent or a sub-Agent. The lead Agent's user prompt is defined by the user, while a sub-Agent's user prompt is defined by the lead Agent.
|
||||
- `tool_calls`: The history of tool calling
|
||||
- `call.name`:The name of the tool called.
|
||||
- `call.result`:The result of tool calling
|
||||
- `citation_guidelines` prompt block
|
||||
- Reference design: [citation_prompt.md](https://github.com/infiniflow/ragflow/blob/main/rag/prompts/citation_prompt.md)
|
||||
|
||||
*The screenshots below show the framework prompt blocks available to an **Agent** component, both as a standalone and as a planner (with a Tavily tool below):*
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### User prompt
|
||||
|
||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||
|
||||
|
||||
### Tools
|
||||
|
||||
You can use an **Agent** component as a collaborator that reasons and reflects with the aid of other tools; for instance, **Retrieval** can serve as one such tool for an **Agent**.
|
||||
|
||||
### Agent
|
||||
|
||||
You use an **Agent** component as a collaborator that reasons and reflects with the aid of subagents or other tools, forming a multi-agent system.
|
||||
|
||||
### Message window size
|
||||
|
||||
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||||
|
||||
:::tip IMPORTANT
|
||||
This feature is used for multi-turn dialogue *only*.
|
||||
:::
|
||||
|
||||
### Max retries
|
||||
|
||||
Defines the maximum number of attempts the agent will make to retry a failed task or operation before stopping or reporting failure.
|
||||
|
||||
### Delay after error
|
||||
|
||||
The waiting period in seconds that the agent observes before retrying a failed task, helping to prevent immediate repeated attempts and allowing system conditions to improve. Defaults to 1 second.
|
||||
|
||||
### Max reflection rounds
|
||||
|
||||
Defines the maximum number reflection rounds of the selected chat model. Defaults to 1 round.
|
||||
|
||||
:::tip NOTE
|
||||
Increasing this value will significantly extend your agent's response time.
|
||||
:::
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Agent** component, which can be referenced by other components in the workflow.
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Why does it take so long for my Agent to respond?
|
||||
|
||||
See [here](../best_practices/accelerate_agent_question_answering.md) for details.
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
sidebar_position: 5
|
||||
slug: /await_response
|
||||
---
|
||||
|
||||
# Await response component
|
||||
|
||||
A component that halts the workflow and awaits user input.
|
||||
|
||||
---
|
||||
|
||||
An **Await response** component halts the workflow, initiating a conversation and collecting key information via predefined forms.
|
||||
|
||||
## Scenarios
|
||||
|
||||
An **Await response** component is essential where you need to display the agent's responses or require user-computer interaction.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Guiding question
|
||||
|
||||
Whether to show the message defined in the **Message** field.
|
||||
|
||||
### Message
|
||||
|
||||
The static message to send out.
|
||||
|
||||
Click **+ Add message** to add message options. When multiple messages are supplied, the **Message** component randomly selects one to send.
|
||||
|
||||
### Input
|
||||
|
||||
You can define global variables within the **Await response** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+** to add a global variable, each with the following attributes:
|
||||
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
The type of the variable:
|
||||
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||
- **Dropdown options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set _at least_ one option for the dropdown menu.
|
||||
- **file upload**: Requires the user to upload one or multiple files.
|
||||
- **Number**: Accepts a number as input.
|
||||
- **Boolean**: Requires the user to toggle between on and off.
|
||||
- **Key**: _Required_
|
||||
The unique variable name.
|
||||
- **Optional**: A toggle indicating whether the variable is optional.
|
||||
|
||||
:::tip NOTE
|
||||
To pass in parameters from a client, call:
|
||||
|
||||
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
||||
:::
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
||||
:::
|
||||
80
docs/guides/agent/agent_component_reference/begin.mdx
Normal file
80
docs/guides/agent/agent_component_reference/begin.mdx
Normal file
@@ -0,0 +1,80 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /begin_component
|
||||
---
|
||||
|
||||
# Begin component
|
||||
|
||||
The starting component in a workflow.
|
||||
|
||||
---
|
||||
|
||||
The **Begin** component sets an opening greeting or accepts inputs from the user. It is automatically populated onto the canvas when you create an agent, whether from a template or from scratch (from a blank template). There should be only one **Begin** component in the workflow.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Begin** component is essential in all cases. Every agent includes a **Begin** component, which cannot be deleted.
|
||||
|
||||
## Configurations
|
||||
|
||||
Click the component to display its **Configuration** window. Here, you can set an opening greeting and the input parameters (global variables) for the agent.
|
||||
|
||||
### Mode
|
||||
|
||||
Mode defines how the workflow is triggered.
|
||||
|
||||
- Conversational: The agent is triggered from a conversation.
|
||||
- Task: The agent starts without a conversation.
|
||||
|
||||
### Opening greeting
|
||||
|
||||
**Conversational mode only.**
|
||||
|
||||
An agent in conversational mode begins with an opening greeting. It is the agent's first message to the user in conversational mode, which can be a welcoming remark or an instruction to guide the user forward.
|
||||
|
||||
### Global variables
|
||||
|
||||
You can define global variables within the **Begin** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+ Add variable** to add a global variable, each with the following attributes:
|
||||
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
The type of the variable:
|
||||
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||
- **Dropdown options**: Requires the user to select a value for this variable from a dropdown menu. And you are required to set _at least_ one option for the dropdown menu.
|
||||
- **file upload**: Requires the user to upload one or multiple files.
|
||||
- **Number**: Accepts a number as input.
|
||||
- **Boolean**: Requires the user to toggle between on and off.
|
||||
- **Key**: _Required_
|
||||
The unique variable name.
|
||||
- **Optional**: A toggle indicating whether the variable is optional.
|
||||
|
||||
:::tip NOTE
|
||||
To pass in parameters from a client, call:
|
||||
|
||||
- HTTP method [Converse with agent](../../../references/http_api_reference.md#converse-with-agent), or
|
||||
- Python method [Converse with agent](../../../references/python_api_reference.md#converse-with-agent).
|
||||
:::
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you set the key type as **file**, ensure the token count of the uploaded file does not exceed your model provider's maximum token limit; otherwise, the plain text in your file will be truncated and incomplete.
|
||||
:::
|
||||
|
||||
:::note
|
||||
You can tune document parsing and embedding efficiency by setting the environment variables `DOC_BULK_SIZE` and `EMBEDDING_BATCH_SIZE`.
|
||||
:::
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### Is the uploaded file in a dataset?
|
||||
|
||||
No. Files uploaded to an agent as input are not stored in a dataset and hence will not be processed using RAGFlow's built-in OCR, DLR or TSR models, or chunked using RAGFlow's built-in chunking methods.
|
||||
|
||||
### File size limit for an uploaded file
|
||||
|
||||
There is no _specific_ file size limit for a file uploaded to an agent. However, note that model providers typically have a default or explicit maximum token setting, which can range from 8196 to 128k: The plain text part of the uploaded file will be passed in as the key value, but if the file's token count exceeds this limit, the string will be truncated and incomplete.
|
||||
|
||||
:::tip NOTE
|
||||
The variables `MAX_CONTENT_LENGTH` in `/docker/.env` and `client_max_body_size` in `/docker/nginx/nginx.conf` set the file size limit for each upload to a dataset or **File Management**. These settings DO NOT apply in this scenario.
|
||||
:::
|
||||
109
docs/guides/agent/agent_component_reference/categorize.mdx
Normal file
109
docs/guides/agent/agent_component_reference/categorize.mdx
Normal file
@@ -0,0 +1,109 @@
|
||||
---
|
||||
sidebar_position: 8
|
||||
slug: /categorize_component
|
||||
---
|
||||
|
||||
# Categorize component
|
||||
|
||||
A component that classifies user inputs and applies strategies accordingly.
|
||||
|
||||
---
|
||||
|
||||
A **Categorize** component is usually the downstream of the **Interact** component.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Categorize** component is essential when you need the LLM to help you identify user intentions and apply appropriate processing strategies.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Query variables
|
||||
|
||||
*Mandatory*
|
||||
|
||||
Select the source for categorization.
|
||||
|
||||
The **Categorize** component relies on query variables to specify its data inputs (queries). All global variables defined before the **Categorize** component are available in the dropdown list.
|
||||
|
||||
|
||||
### Input
|
||||
|
||||
The **Categorize** component relies on input variables to specify its data inputs (queries). Click **+ Add variable** in the **Input** section to add the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||
|
||||
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||
- A component ID under **Component Output**, or
|
||||
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||
|
||||
### Model
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creavity**.
|
||||
:::
|
||||
|
||||
### Message window size
|
||||
|
||||
An integer specifying the number of previous dialogue rounds to input into the LLM. For example, if it is set to 12, the tokens from the last 12 dialogue rounds will be fed to the LLM. This feature consumes additional tokens.
|
||||
|
||||
Defaults to 1.
|
||||
|
||||
:::tip IMPORTANT
|
||||
This feature is used for multi-turn dialogue *only*. If your **Categorize** component is not part of a multi-turn dialogue (i.e., it is not in a loop), leave this field as-is.
|
||||
:::
|
||||
|
||||
### Category name
|
||||
|
||||
A **Categorize** component must have at least two categories. This field sets the name of the category. Click **+ Add Item** to include the intended categories.
|
||||
|
||||
:::tip NOTE
|
||||
You will notice that the category name is auto-populated. No worries. Each category is assigned a random name upon creation. Feel free to change it to a name that is understandable to the LLM.
|
||||
:::
|
||||
|
||||
#### Description
|
||||
|
||||
Description of this category.
|
||||
|
||||
You can input criteria, situation, or information that may help the LLM determine which inputs belong in this category.
|
||||
|
||||
#### Examples
|
||||
|
||||
Additional examples that may help the LLM determine which inputs belong in this category.
|
||||
|
||||
:::danger IMPORTANT
|
||||
Examples are more helpful than the description if you want the LLM to classify particular cases into this category.
|
||||
:::
|
||||
|
||||
Once a new category is added, navigate to the **Categorize** component on the canvas, find the **+** button next to the case, and click it to specify the downstream component(s).
|
||||
|
||||
|
||||
#### Output
|
||||
|
||||
The global variable name for the output of the component, which can be referenced by other components in the workflow. Defaults to `category_name`.
|
||||
40
docs/guides/agent/agent_component_reference/chunker_title.md
Normal file
40
docs/guides/agent/agent_component_reference/chunker_title.md
Normal file
@@ -0,0 +1,40 @@
|
||||
---
|
||||
sidebar_position: 31
|
||||
slug: /chunker_title_component
|
||||
---
|
||||
|
||||
# Title chunker component
|
||||
|
||||
A component that splits texts into chunks by heading level.
|
||||
|
||||
---
|
||||
|
||||
A **Token chunker** component is a text splitter that uses specified heading level as delimiter to define chunk boundaries and create chunks.
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Title chunker** component is optional, usually placed immediately after **Parser**.
|
||||
|
||||
:::caution WARNING
|
||||
Placing a **Title chunker** after a **Token chunker** is invalid and will cause an error. Please note that this restriction is not currently system-enforced and requires your attention.
|
||||
:::
|
||||
|
||||
## Configurations
|
||||
|
||||
### Hierarchy
|
||||
|
||||
Specifies the heading level to define chunk boundaries:
|
||||
|
||||
- H1
|
||||
- H2
|
||||
- H3 (Default)
|
||||
- H4
|
||||
|
||||
Click **+ Add** to add heading levels here or update the corresponding **Regular Expressions** fields for custom heading patterns.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Title chunker** component, which can be referenced by subsequent components in the ingestion pipeline.
|
||||
|
||||
- Default: `chunks`
|
||||
- Type: `Array<Object>`
|
||||
43
docs/guides/agent/agent_component_reference/chunker_token.md
Normal file
43
docs/guides/agent/agent_component_reference/chunker_token.md
Normal file
@@ -0,0 +1,43 @@
|
||||
---
|
||||
sidebar_position: 32
|
||||
slug: /chunker_token_component
|
||||
---
|
||||
|
||||
# Token chunker component
|
||||
|
||||
A component that splits texts into chunks, respecting a maximum token limit and using delimiters to find optimal breakpoints.
|
||||
|
||||
---
|
||||
|
||||
A **Token chunker** component is a text splitter that creates chunks by respecting a recommended maximum token length, using delimiters to ensure logical chunk breakpoints. It splits long texts into appropriately-sized, semantically related chunks.
|
||||
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Token chunker** component is optional, usually placed immediately after **Parser** or **Title chunker**.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Recommended chunk size
|
||||
|
||||
The recommended maximum token limit for each created chunk. The **Token chunker** component creates chunks at specified delimiters. If this token limit is reached before a delimiter, a chunk is created at that point.
|
||||
|
||||
### Overlapped percent (%)
|
||||
|
||||
This defines the overlap percentage between chunks. An appropriate degree of overlap ensures semantic coherence without creating excessive, redundant tokens for the LLM.
|
||||
|
||||
- Default: 0
|
||||
- Maximum: 30%
|
||||
|
||||
|
||||
### Delimiters
|
||||
|
||||
Defaults to `\n`. Click the right-hand **Recycle bin** button to remove it, or click **+ Add** to add a delimiter.
|
||||
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Token chunker** component, which can be referenced by subsequent components in the ingestion pipeline.
|
||||
|
||||
- Default: `chunks`
|
||||
- Type: `Array<Object>`
|
||||
205
docs/guides/agent/agent_component_reference/code.mdx
Normal file
205
docs/guides/agent/agent_component_reference/code.mdx
Normal file
@@ -0,0 +1,205 @@
|
||||
---
|
||||
sidebar_position: 13
|
||||
slug: /code_component
|
||||
---
|
||||
|
||||
# Code component
|
||||
|
||||
A component that enables users to integrate Python or JavaScript codes into their Agent for dynamic data processing.
|
||||
|
||||
---
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Code** component is essential when you need to integrate complex code logic (Python or JavaScript) into your Agent for dynamic data processing.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
### 1. Ensure gVisor is properly installed
|
||||
|
||||
We use gVisor to isolate code execution from the host system. Please follow [the official installation guide](https://gvisor.dev/docs/user_guide/install/) to install gVisor, ensuring your operating system is compatible before proceeding.
|
||||
|
||||
### 2. Ensure Sandbox is properly installed
|
||||
|
||||
RAGFlow Sandbox is a secure, pluggable code execution backend. It serves as the code executor for the **Code** component. Please follow the [instructions here](https://github.com/infiniflow/ragflow/tree/main/sandbox) to install RAGFlow Sandbox.
|
||||
|
||||
:::tip NOTE
|
||||
If your RAGFlow Sandbox is not working, please be sure to consult the [Troubleshooting](#troubleshooting) section in this document. We assure you that it addresses 99.99% of the issues!
|
||||
:::
|
||||
|
||||
### 3. (Optional) Install necessary dependencies
|
||||
|
||||
If you need to import your own Python or JavaScript packages into Sandbox, please follow the commands provided in the [How to import my own Python or JavaScript packages into Sandbox?](#how-to-import-my-own-python-or-javascript-packages-into-sandbox) section to install the additional dependencies.
|
||||
|
||||
### 4. Enable Sandbox-specific settings in RAGFlow
|
||||
|
||||
Ensure all Sandbox-specific settings are enabled in **ragflow/docker/.env**.
|
||||
|
||||
### 5. Restart the service after making changes
|
||||
|
||||
Any changes to the configuration or environment *require* a full service restart to take effect.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Input
|
||||
|
||||
You can specify multiple input sources for the **Code** component. Click **+ Add variable** in the **Input variables** section to include the desired input variables.
|
||||
|
||||
### Code
|
||||
|
||||
This field allows you to enter and edit your source code.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If your code implementation includes defined variables, whether input or output variables, ensure they are also specified in the corresponding **Input** or **Output** sections.
|
||||
:::
|
||||
|
||||
#### A Python code example
|
||||
|
||||
```Python
|
||||
def main(arg1: str, arg2: str) -> dict:
|
||||
return {
|
||||
"result": arg1 + arg2,
|
||||
}
|
||||
```
|
||||
|
||||
#### A JavaScript code example
|
||||
|
||||
```JavaScript
|
||||
|
||||
const axios = require('axios');
|
||||
async function main(args) {
|
||||
try {
|
||||
const response = await axios.get('https://github.com/infiniflow/ragflow');
|
||||
console.log('Body:', response.data);
|
||||
} catch (error) {
|
||||
console.error('Error:', error.message);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
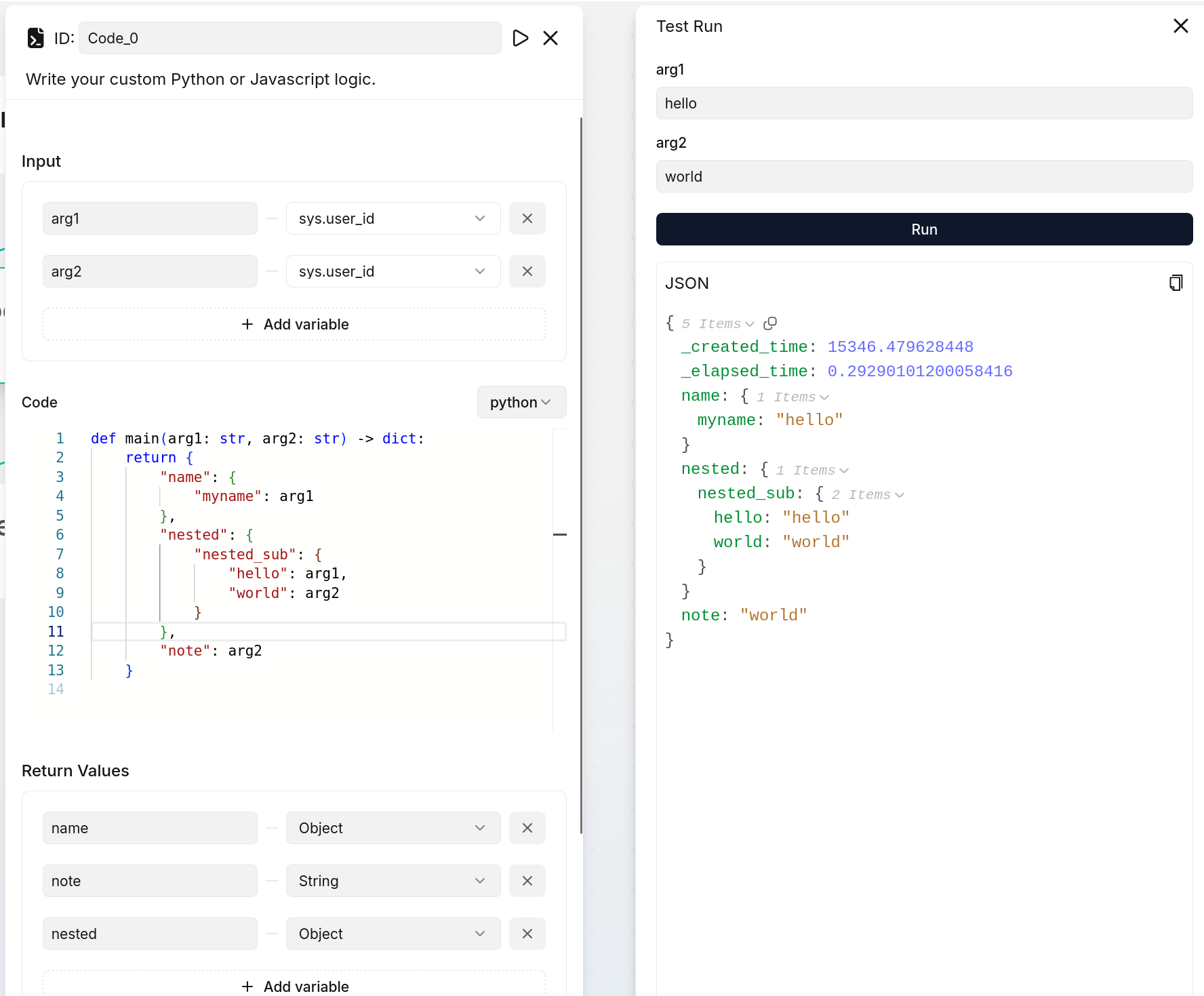
### Return values
|
||||
|
||||
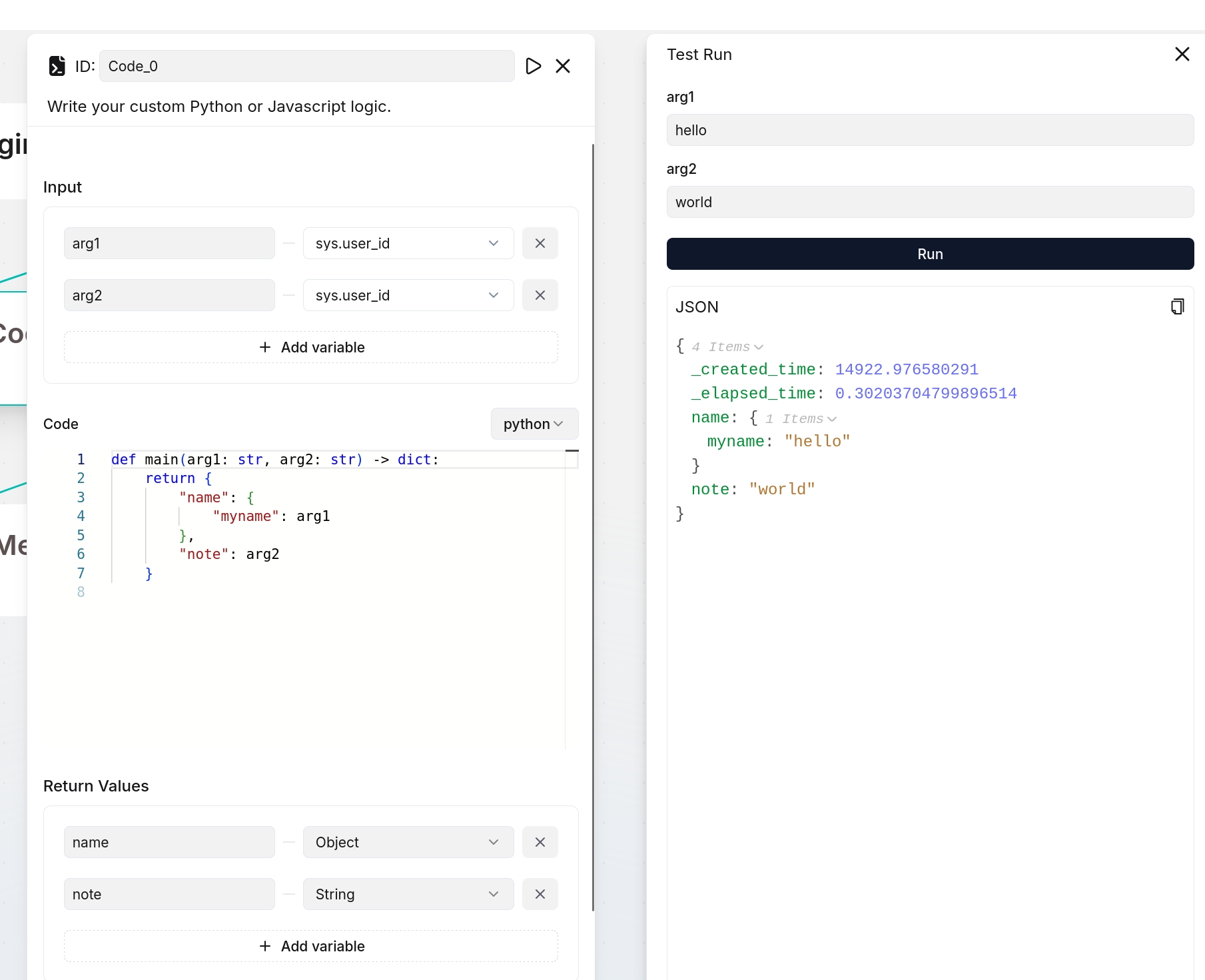
You define the output variable(s) of the **Code** component here.
|
||||
|
||||
:::danger IMPORTANT
|
||||
If you define output variables here, ensure they are also defined in your code implementation; otherwise, their values will be `null`. The following are two examples:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
:::
|
||||
|
||||
### Output
|
||||
|
||||
The defined output variable(s) will be auto-populated here.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### `HTTPConnectionPool(host='sandbox-executor-manager', port=9385): Read timed out.`
|
||||
|
||||
**Root cause**
|
||||
|
||||
- You did not properly install gVisor and `runsc` was not recognized as a valid Docker runtime.
|
||||
- You did not pull the required base images for the runners and no runner was started.
|
||||
|
||||
**Solution**
|
||||
|
||||
For the gVisor issue:
|
||||
|
||||
1. Install [gVisor](https://gvisor.dev/docs/user_guide/install/).
|
||||
2. Restart Docker.
|
||||
3. Run the following to double check:
|
||||
|
||||
```bash
|
||||
docker run --rm --runtime=runsc hello-world
|
||||
```
|
||||
|
||||
For the base image issue, pull the required base images:
|
||||
|
||||
```bash
|
||||
docker pull infiniflow/sandbox-base-nodejs:latest
|
||||
docker pull infiniflow/sandbox-base-python:latest
|
||||
```
|
||||
|
||||
### `HTTPConnectionPool(host='none', port=9385): Max retries exceeded.`
|
||||
|
||||
**Root cause**
|
||||
|
||||
`sandbox-executor-manager` is not mapped in `/etc/hosts`.
|
||||
|
||||
**Solution**
|
||||
|
||||
Add a new entry to `/etc/hosts`:
|
||||
|
||||
`127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager`
|
||||
|
||||
### `Container pool is busy`
|
||||
|
||||
**Root cause**
|
||||
|
||||
All runners are currently in use, executing tasks.
|
||||
|
||||
**Solution**
|
||||
|
||||
Please try again shortly or increase the pool size in the configuration to improve availability and reduce waiting times.
|
||||
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### How to import my own Python or JavaScript packages into Sandbox?
|
||||
|
||||
To import your Python packages, update **sandbox_base_image/python/requirements.txt** to install the required dependencies. For example, to add the `openpyxl` package, proceed with the following command lines:
|
||||
|
||||
```bash {4,6}
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ pwd # make sure you are in the right directory
|
||||
/home/infiniflow/workspace/ragflow/sandbox
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ echo "openpyxl" >> sandbox_base_image/python/requirements.txt # add the package to the requirements.txt file
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ cat sandbox_base_image/python/requirements.txt # make sure the package is added
|
||||
numpy
|
||||
pandas
|
||||
requests
|
||||
openpyxl # here it is
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_python_0 /bin/bash # entering container to check if the package is installed
|
||||
|
||||
|
||||
# in the container
|
||||
nobody@ffd8a7dd19da:/workspace$ python # launch python shell
|
||||
Python 3.11.13 (main, Aug 12 2025, 22:46:03) [GCC 12.2.0] on linux
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> import openpyxl # import the package to verify installation
|
||||
>>>
|
||||
# That's okay!
|
||||
```
|
||||
|
||||
To import your JavaScript packages, navigate to `sandbox_base_image/nodejs` and use `npm` to install the required packages. For example, to add the `lodash` package, run the following commands:
|
||||
|
||||
```bash
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ pwd
|
||||
/home/infiniflow/workspace/ragflow/sandbox
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ cd sandbox_base_image/nodejs
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ npm install lodash
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ cd ../.. # go back to sandbox root directory
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ make # rebuild the docker image, this command will rebuild the iamge and start the service immediately. To build image only, using `make build` instead.
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✗ docker exec -it sandbox_nodejs_0 /bin/bash # entering container to check if the package is installed
|
||||
|
||||
# in the container
|
||||
nobody@dd4bbcabef63:/workspace$ npm list lodash # verify via npm list
|
||||
/workspace
|
||||
`-- lodash@4.17.21 extraneous
|
||||
|
||||
nobody@dd4bbcabef63:/workspace$ ls node_modules | grep lodash # or verify via listing node_modules
|
||||
lodash
|
||||
|
||||
# That's okay!
|
||||
```
|
||||
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
79
docs/guides/agent/agent_component_reference/execute_sql.md
Normal file
@@ -0,0 +1,79 @@
|
||||
---
|
||||
sidebar_position: 25
|
||||
slug: /execute_sql
|
||||
---
|
||||
|
||||
# Execute SQL tool
|
||||
|
||||
A tool that execute SQL queries on a specified relational database.
|
||||
|
||||
---
|
||||
|
||||
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- A database instance properly configured and running.
|
||||
- The database must be one of the following types:
|
||||
- MySQL
|
||||
- PostgreSQL
|
||||
- MariaDB
|
||||
- Microsoft SQL Server
|
||||
|
||||
## Examples
|
||||
|
||||
You can pair an **Agent** component with the **Execute SQL** tool, with the **Agent** generating SQL statements and the **Execute SQL** tool handling database connection and query execution. An example of this setup can be found in the **SQL Assistant** Agent template shown below:
|
||||
|
||||
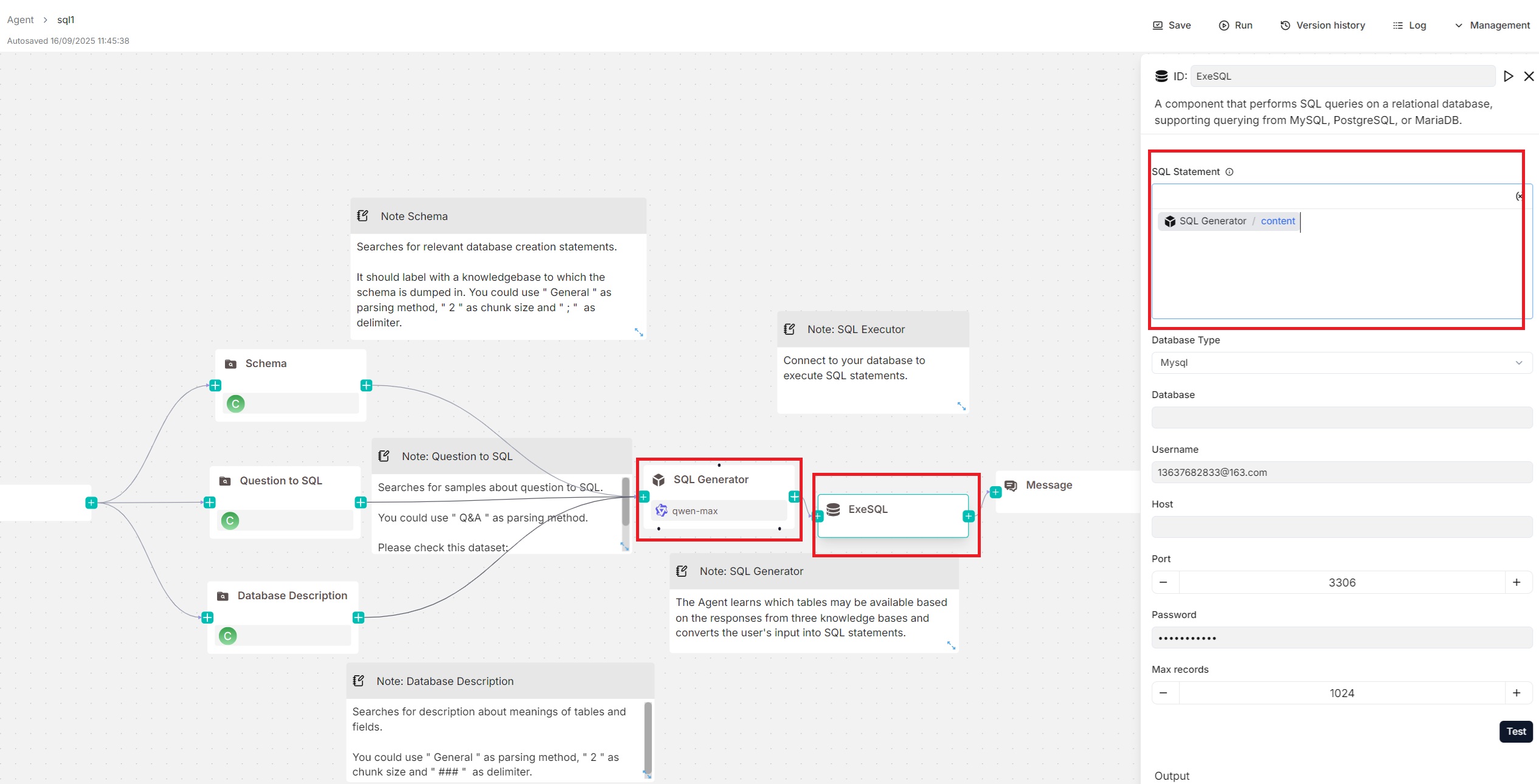
|
||||
|
||||
## Configurations
|
||||
|
||||
### SQL statement
|
||||
|
||||
This text input field allows you to write static SQL queries, such as `SELECT * FROM my_table`, and dynamic SQL queries using variables.
|
||||
|
||||
:::tip NOTE
|
||||
Click **(x)** or type `/` to insert variables.
|
||||
:::
|
||||
|
||||
For dynamic SQL queries, you can include variables in your SQL queries, such as `SELECT * FROM /sys.query`; if an **Agent** component is paired with the **Execute SQL** tool to generate SQL tasks (see the [Examples](#examples) section), you can directly insert that **Agent**'s output, `content`, into this field.
|
||||
|
||||
### Database type
|
||||
|
||||
The supported database type. Currently the following database types are available:
|
||||
|
||||
- MySQL
|
||||
- PostreSQL
|
||||
- MariaDB
|
||||
- Microsoft SQL Server (Myssql)
|
||||
|
||||
### Database
|
||||
|
||||
Appears only when you select **Split** as method.
|
||||
|
||||
### Username
|
||||
|
||||
The username with access privileges to the database.
|
||||
|
||||
### Host
|
||||
|
||||
The IP address of the database server.
|
||||
|
||||
### Port
|
||||
|
||||
The port number on which the database server is listening.
|
||||
|
||||
### Password
|
||||
|
||||
The password for the database user.
|
||||
|
||||
### Max records
|
||||
|
||||
The maximum number of records returned by the SQL query to control response size and improve efficiency. Defaults to `1024`.
|
||||
|
||||
### Output
|
||||
|
||||
The **Execute SQL** tool provides two output variables:
|
||||
|
||||
- `formalized_content`: A string. If you reference this variable in a **Message** component, the returned records are displayed as a table.
|
||||
- `json`: An object array. If you reference this variable in a **Message** component, the returned records will be presented as key-value pairs.
|
||||
29
docs/guides/agent/agent_component_reference/indexer.md
Normal file
29
docs/guides/agent/agent_component_reference/indexer.md
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
sidebar_position: 40
|
||||
slug: /indexer_component
|
||||
---
|
||||
|
||||
# Indexer component
|
||||
|
||||
A component that defines how chunks are indexed.
|
||||
|
||||
---
|
||||
|
||||
An **Indexer** component indexes chunks and configures their storage formats in the document engine.
|
||||
|
||||
## Scenario
|
||||
|
||||
An **Indexer** component is the mandatory ending component for all ingestion pipelines.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Search method
|
||||
|
||||
This setting configures how chunks are stored in the document engine: as full-text, embeddings, or both.
|
||||
|
||||
### Filename embedding weight
|
||||
|
||||
This setting defines the filename's contribution to the final embedding, which is a weighted combination of both the chunk content and the filename. Essentially, a higher value gives the filename more influence in the final *composite* embedding.
|
||||
|
||||
- 0.1: Filename contributes 10% (chunk content 90%)
|
||||
- 0.5 (maximum): Filename contributes 50% (chunk content 90%)
|
||||
65
docs/guides/agent/agent_component_reference/iteration.mdx
Normal file
65
docs/guides/agent/agent_component_reference/iteration.mdx
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /iteration_component
|
||||
---
|
||||
|
||||
# Iteration component
|
||||
|
||||
A component that splits text input into text segments and iterates a predefined workflow for each one.
|
||||
|
||||
---
|
||||
|
||||
An **Interaction** component can divide text input into text segments and apply its built-in component workflow to each segment.
|
||||
|
||||
|
||||
## Scenario
|
||||
|
||||
An **Iteration** component is essential when a workflow loop is required and the loop count is *not* fixed but depends on number of segments created from the output of specific agent components.
|
||||
|
||||
- If, for instance, you plan to feed several paragraphs into an LLM for content generation, each with its own focus, and feeding them to the LLM all at once could create confusion or contradictions, then you can use an **Iteration** component, which encapsulates a **Generate** component, to repeat the content generation process for each paragraph.
|
||||
- Another example: If you wish to use the LLM to translate a lengthy paper into a target language without exceeding its token limit, consider using an **Iteration** component, which encapsulates a **Generate** component, to break the paper into smaller pieces and repeat the translation process for each one.
|
||||
|
||||
## Internal components
|
||||
|
||||
### IterationItem
|
||||
|
||||
Each **Iteration** component includes an internal **IterationItem** component. The **IterationItem** component serves as both the starting point and input node of the workflow within the **Iteration** component. It manages the loop of the workflow for all text segments created from the input.
|
||||
|
||||
:::tip NOTE
|
||||
The **IterationItem** component is visible *only* to the components encapsulated by the current **Iteration** components.
|
||||
:::
|
||||
|
||||
### Build an internal workflow
|
||||
|
||||
You are allowed to pull other components into the **Iteration** component to build an internal workflow, and these "added internal components" are no longer visible to components outside of the current **Iteration** component.
|
||||
|
||||
:::danger IMPORTANT
|
||||
To reference the created text segments from an added internal component, simply add a **Reference** variable that equals **IterationItem** within the **Input** section of that internal component. There is no need to reference the corresponding external component, as the **IterationItem** component manages the loop of the workflow for all created text segments.
|
||||
:::
|
||||
|
||||
:::tip NOTE
|
||||
An added internal component can reference an external component when necessary.
|
||||
:::
|
||||
|
||||
## Configurations
|
||||
|
||||
### Input
|
||||
|
||||
The **Iteration** component uses input variables to specify its data inputs, namely the texts to be segmented. You are allowed to specify multiple input sources for the **Iteration** component. Click **+ Add variable** in the **Input** section to include the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||
|
||||
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||
- A component ID under **Component Output**, or
|
||||
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||
|
||||
### Delimiter
|
||||
|
||||
The delimiter to use to split the text input into segments:
|
||||
|
||||
- Comma (Default)
|
||||
- Line break
|
||||
- Tab
|
||||
- Underline
|
||||
- Forward slash
|
||||
- Dash
|
||||
- Semicolon
|
||||
21
docs/guides/agent/agent_component_reference/message.mdx
Normal file
21
docs/guides/agent/agent_component_reference/message.mdx
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /message_component
|
||||
---
|
||||
|
||||
# Message component
|
||||
|
||||
A component that sends out a static or dynamic message.
|
||||
|
||||
---
|
||||
|
||||
As the final component of the workflow, a Message component returns the workflow’s ultimate data output accompanied by predefined message content. The system selects one message at random if multiple messages are provided.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Messages
|
||||
|
||||
The message to send out. Click `(x)` or type `/` to quickly insert variables.
|
||||
|
||||
Click **+ Add message** to add message options. When multiple messages are supplied, the **Message** component randomly selects one to send.
|
||||
|
||||
17
docs/guides/agent/agent_component_reference/parser.md
Normal file
17
docs/guides/agent/agent_component_reference/parser.md
Normal file
@@ -0,0 +1,17 @@
|
||||
---
|
||||
sidebar_position: 30
|
||||
slug: /parser_component
|
||||
---
|
||||
|
||||
# Parser component
|
||||
|
||||
A component that sets the parsing rules for your dataset.
|
||||
|
||||
---
|
||||
|
||||
A **Parser** component defines how various file types should be parsed, including parsing methods for PDFs , fields to parse for Emails, and OCR methods for images.
|
||||
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Parser** component is auto-populated on the ingestion pipeline canvas and required in all ingestion pipeline workflows.
|
||||
145
docs/guides/agent/agent_component_reference/retrieval.mdx
Normal file
145
docs/guides/agent/agent_component_reference/retrieval.mdx
Normal file
@@ -0,0 +1,145 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /retrieval_component
|
||||
---
|
||||
|
||||
# Retrieval component
|
||||
|
||||
A component that retrieves information from specified datasets.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Retrieval** component is essential in most RAG scenarios, where information is extracted from designated datasets before being sent to the LLM for content generation. A **Retrieval** component can operate either as a standalone workflow module or as a tool for an **Agent** component. In the latter role, the **Agent** component has autonomous control over when to invoke it for query and retrieval.
|
||||
|
||||
The following screenshot shows a reference design using the **Retrieval** component, where the component serves as a tool for an **Agent** component. You can find it from the **Report Agent Using Knowledge Base** Agent template.
|
||||
|
||||
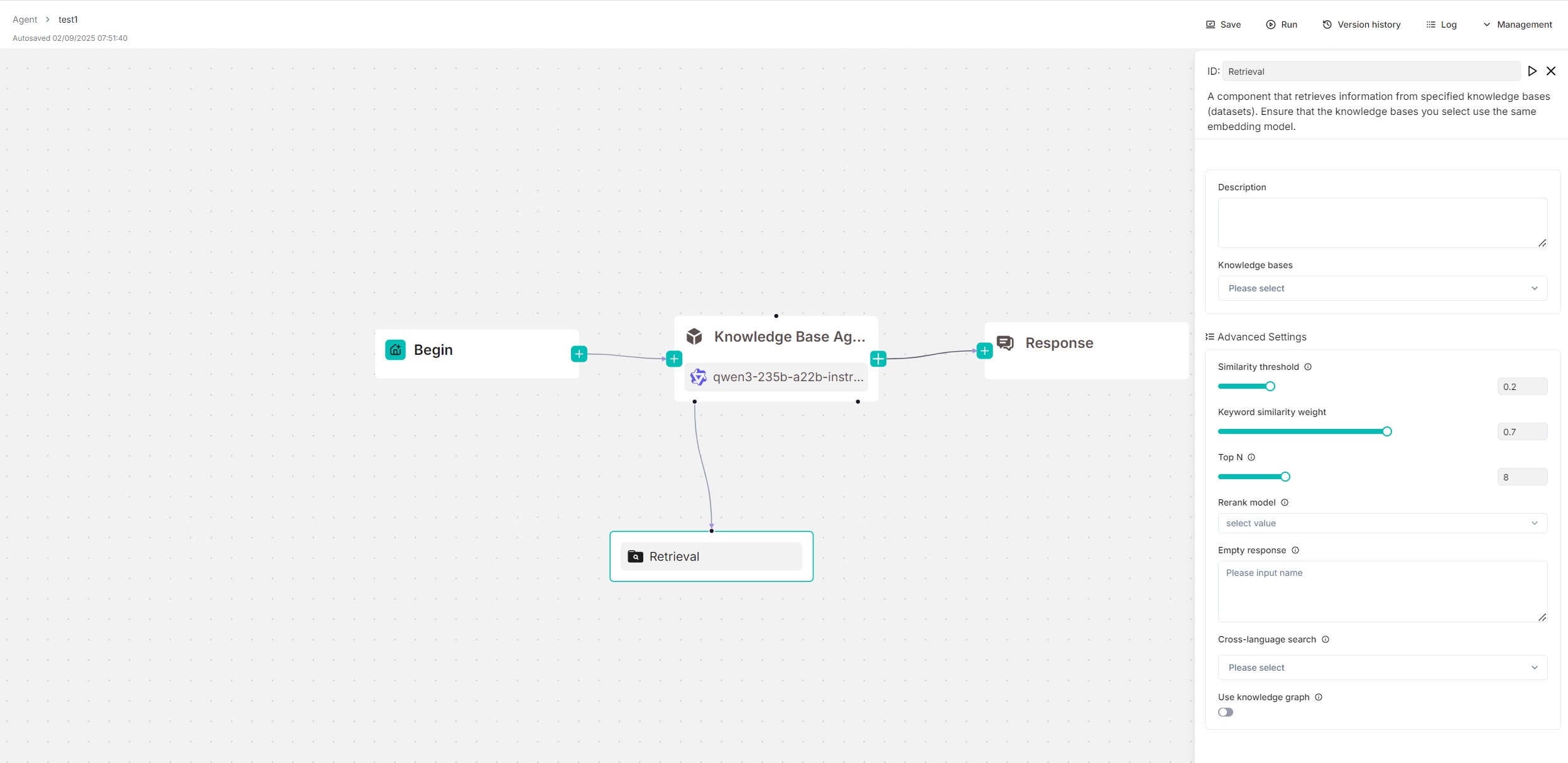
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Ensure you [have properly configured your target dataset(s)](../../dataset/configure_knowledge_base.md).
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on a **Retrieval** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Retrieval** component's search behavior.
|
||||
|
||||
### 2. Input query variable(s)
|
||||
|
||||
The **Retrieval** component depends on query variables to specify its queries.
|
||||
|
||||
:::caution IMPORTANT
|
||||
- If you use the **Retrieval** component as a standalone workflow module, input query variables in the **Input Variables** text box.
|
||||
- If it is used as a tool for an **Agent** component, input the query variables in the **Agent** component's **User prompt** field.
|
||||
:::
|
||||
|
||||
By default, you can use `sys.query`, which is the user query and the default output of the **Begin** component. All global variables defined before the **Retrieval** component can also be used as query statements. Use the `(x)` button or type `/` to show all the available query variables.
|
||||
|
||||
### 3. Select dataset(s) to query
|
||||
|
||||
You can specify one or multiple datasets to retrieve data from. If selecting mutiple, ensure they use the same embedding model.
|
||||
|
||||
### 4. Expand **Advanced Settings** to configure the retrieval method
|
||||
|
||||
By default, a combination of weighted keyword similarity and weighted vector cosine similarity is used for retrieval. If a rerank model is selected, a combination of weighted keyword similarity and weighted reranking score will be used instead.
|
||||
|
||||
As a starter, you can skip this step to stay with the default retrieval method.
|
||||
|
||||
:::caution WARNING
|
||||
Using a rerank model will *significantly* increase the system's response time. If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||
:::
|
||||
|
||||
### 5. Enable cross-language search
|
||||
|
||||
If your user query is different from the languages of the datasets, you can select the target languages in the **Cross-language search** dropdown menu. The model will then translates queries to ensure accurate matching of semantic meaning across languages.
|
||||
|
||||
|
||||
### 6. Test retrieval results
|
||||
|
||||
Click the **Run** button on the top of canvas to test the retrieval results.
|
||||
|
||||
### 7. Choose the next component
|
||||
|
||||
When necessary, click the **+** button on the **Retrieval** component to choose the next component in the worflow from the dropdown list.
|
||||
|
||||
|
||||
## Configurations
|
||||
|
||||
### Query variables
|
||||
|
||||
*Mandatory*
|
||||
|
||||
Select the query source for retrieval. Defaults to `sys.query`, which is the default output of the **Begin** component.
|
||||
|
||||
The **Retrieval** component relies on query variables to specify its queries. All global variables defined before the **Retrieval** component can also be used as queries. Use the `(x)` button or type `/` to show all the available query variables.
|
||||
|
||||
### Knowledge bases
|
||||
|
||||
Select the dataset(s) to retrieve data from.
|
||||
|
||||
- If no dataset is selected, meaning conversations with the agent will not be based on any dataset, ensure that the **Empty response** field is left blank to avoid an error.
|
||||
- If you select multiple datasets, you must ensure that the datasets you select use the same embedding model; otherwise, an error message would occur.
|
||||
|
||||
### Similarity threshold
|
||||
|
||||
RAGFlow employs a combination of weighted keyword similarity and weighted vector cosine similarity during retrieval. This parameter sets the threshold for similarities between the user query and chunks stored in the datasets. Any chunk with a similarity score below this threshold will be excluded from the results.
|
||||
|
||||
Defaults to 0.2.
|
||||
|
||||
### Vector similarity weight
|
||||
|
||||
This parameter sets the weight of vector similarity in the composite similarity score. The total of the two weights must equal 1.0. Its default value is 0.3, which means the weight of keyword similarity in a combined search is 1 - 0.3 = 0.7.
|
||||
|
||||
### Top N
|
||||
|
||||
This parameter selects the "Top N" chunks from retrieved ones and feed them to the LLM.
|
||||
|
||||
Defaults to 8.
|
||||
|
||||
|
||||
### Rerank model
|
||||
|
||||
*Optional*
|
||||
|
||||
If a rerank model is selected, a combination of weighted keyword similarity and weighted reranking score will be used for retrieval.
|
||||
|
||||
:::caution WARNING
|
||||
Using a rerank model will *significantly* increase the system's response time.
|
||||
:::
|
||||
|
||||
### Empty response
|
||||
|
||||
- Set this as a response if no results are retrieved from the dataset(s) for your query, or
|
||||
- Leave this field blank to allow the chat model to improvise when nothing is found.
|
||||
|
||||
:::caution WARNING
|
||||
If you do not specify a dataset, you must leave this field blank; otherwise, an error would occur.
|
||||
:::
|
||||
|
||||
### Cross-language search
|
||||
|
||||
Select one or more languages for cross‑language search. If no language is selected, the system searches with the original query.
|
||||
|
||||
### Use knowledge graph
|
||||
|
||||
:::caution IMPORTANT
|
||||
Before enabling this feature, ensure you have properly [constructed a knowledge graph from each target dataset](../../dataset/construct_knowledge_graph.md).
|
||||
:::
|
||||
|
||||
Whether to use knowledge graph(s) in the specified dataset(s) during retrieval for multi-hop question answering. When enabled, this would involve iterative searches across entity, relationship, and community report chunks, greatly increasing retrieval time.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Retrieval** component, which can be referenced by other components in the workflow.
|
||||
|
||||
|
||||
## Frequently asked questions
|
||||
|
||||
### How to reduce response time?
|
||||
|
||||
Go through the checklist below for best performance:
|
||||
|
||||
- Leave the **Rerank model** field empty.
|
||||
- If you must use a rerank model, ensure you use a SaaS reranker; if you prefer a locally deployed rerank model, ensure you start RAGFlow with **docker-compose-gpu.yml**.
|
||||
- Disable **Use knowledge graph**.
|
||||
50
docs/guides/agent/agent_component_reference/switch.mdx
Normal file
50
docs/guides/agent/agent_component_reference/switch.mdx
Normal file
@@ -0,0 +1,50 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /switch_component
|
||||
---
|
||||
|
||||
# Switch component
|
||||
|
||||
A component that evaluates whether specified conditions are met and directs the follow of execution accordingly.
|
||||
|
||||
---
|
||||
|
||||
A **Switch** component evaluates conditions based on the output of specific components, directing the flow of execution accordingly to enable complex branching logic.
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Switch** component is essential for condition-based direction of execution flow. While it shares similarities with the [Categorize](./categorize.mdx) component, which is also used in multi-pronged strategies, the key distinction lies in their approach: the evaluation of the **Switch** component is rule-based, whereas the **Categorize** component involves AI and uses an LLM for decision-making.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Case n
|
||||
|
||||
A **Switch** component must have at least one case, each with multiple specified conditions. When multiple conditions are specified for a case, you must set the logical relationship between them to either AND or OR.
|
||||
|
||||
Once a new case is added, navigate to the **Switch** component on the canvas, find the **+** button next to the case, and click it to specify the downstream component(s).
|
||||
|
||||
|
||||
#### Condition
|
||||
|
||||
Evaluates whether the output of specific components meets certain conditions
|
||||
|
||||
:::danger IMPORTANT
|
||||
When you have added multiple conditions for a specific case, a **Logical operator** field appears, requiring you to set the logical relationship between these conditions as either AND or OR.
|
||||
:::
|
||||
|
||||
- **Operator**: The operator required to form a conditional expression.
|
||||
- Equals (default)
|
||||
- Not equal
|
||||
- Greater than
|
||||
- Greater equal
|
||||
- Less than
|
||||
- Less equal
|
||||
- Contains
|
||||
- Not contains
|
||||
- Starts with
|
||||
- Ends with
|
||||
- Is empty
|
||||
- Not empty
|
||||
- **Value**: A single value, which can be an integer, float, or string.
|
||||
- Delimiters, multiple values, or expressions are *not* supported.
|
||||
|
||||
@@ -0,0 +1,38 @@
|
||||
---
|
||||
sidebar_position: 15
|
||||
slug: /text_processing
|
||||
---
|
||||
|
||||
# Text processing component
|
||||
|
||||
A component that merges or splits texts.
|
||||
|
||||
---
|
||||
|
||||
A **Text processing** component merges or splits texts.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Method
|
||||
|
||||
- Split: Split the text
|
||||
- Merge: Merge the text
|
||||
|
||||
### Split_ref
|
||||
|
||||
Appears only when you select **Split** as method.
|
||||
|
||||
The variable to be split. Type `/` to quickly insert variables.
|
||||
|
||||
### Script
|
||||
|
||||
Template for the merge. Appears only when you select **Merge** as method. Type `/` to quickly insert variables.
|
||||
|
||||
### Delimiters
|
||||
|
||||
The delimiter(s) used to split or merge the text.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the component, which can be referenced by other components in the workflow.
|
||||
|
||||
80
docs/guides/agent/agent_component_reference/transformer.md
Normal file
80
docs/guides/agent/agent_component_reference/transformer.md
Normal file
@@ -0,0 +1,80 @@
|
||||
---
|
||||
sidebar_position: 37
|
||||
slug: /transformer_component
|
||||
---
|
||||
|
||||
# Transformer component
|
||||
|
||||
A component that uses an LLM to extract insights from the chunks.
|
||||
|
||||
---
|
||||
|
||||
A **Transformer** component indexes chunks and configures their storage formats in the document engine. It *typically* precedes the **Indexer** in the ingestion pipeline, but you can also chain multiple **Transformer** components in sequence.
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Transformer** component is essential when you need the LLM to extract new information, such as keywords, questions, metadata, and summaries, from the original chunks.
|
||||
|
||||
## Configurations
|
||||
|
||||
### Model
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creavity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
- It is not necessary to stick with the same model for all components. If a specific model is not performing well for a particular task, consider using a different one.
|
||||
- If you are uncertain about the mechanism behind **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**, simply choose one of the three options of **Creativity**.
|
||||
:::
|
||||
|
||||
### Result destination
|
||||
|
||||
Select the type of output to be generated by the LLM:
|
||||
|
||||
- Summary
|
||||
- Keywords
|
||||
- Questions
|
||||
- Metadata
|
||||
|
||||
### System prompt
|
||||
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering.
|
||||
|
||||
:::tip NOTE
|
||||
The system prompt here automatically updates to match your selected **Result destination**.
|
||||
:::
|
||||
|
||||
### User prompt
|
||||
|
||||
The user-defined prompt. For example, you can type `/` or click **(x)** to insert variables of preceding components in the ingestion pipeline as the LLM's input.
|
||||
|
||||
### Output
|
||||
|
||||
The global variable name for the output of the **Transformer** component, which can be referenced by subsequent **Transformer** components in the ingestion pipeline.
|
||||
|
||||
- Default: `chunks`
|
||||
- Type: `Array<Object>`
|
||||
51
docs/guides/agent/agent_introduction.md
Normal file
51
docs/guides/agent/agent_introduction.md
Normal file
@@ -0,0 +1,51 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /agent_introduction
|
||||
---
|
||||
|
||||
# Introduction to agents
|
||||
|
||||
Key concepts, basic operations, a quick view of the agent editor.
|
||||
|
||||
---
|
||||
|
||||
:::danger DEPRECATED!
|
||||
A new version is coming soon.
|
||||
:::
|
||||
|
||||
## Key concepts
|
||||
|
||||
Agents and RAG are complementary techniques, each enhancing the other’s capabilities in business applications. RAGFlow v0.8.0 introduces an agent mechanism, featuring a no-code workflow editor on the front end and a comprehensive graph-based task orchestration framework on the back end. This mechanism is built on top of RAGFlow's existing RAG solutions and aims to orchestrate search technologies such as query intent classification, conversation leading, and query rewriting to:
|
||||
|
||||
- Provide higher retrievals and,
|
||||
- Accommodate more complex scenarios.
|
||||
|
||||
## Create an agent
|
||||
|
||||
:::tip NOTE
|
||||
|
||||
Before proceeding, ensure that:
|
||||
|
||||
1. You have properly set the LLM to use. See the guides on [Configure your API key](../models/llm_api_key_setup.md) or [Deploy a local LLM](../models/deploy_local_llm.mdx) for more information.
|
||||
2. You have a dataset configured and the corresponding files properly parsed. See the guide on [Configure a dataset](../dataset/configure_knowledge_base.md) for more information.
|
||||
|
||||
:::
|
||||
|
||||
Click the **Agent** tab in the middle top of the page to show the **Agent** page. As shown in the screenshot below, the cards on this page represent the created agents, which you can continue to edit.
|
||||
|
||||
|
||||
|
||||
We also provide templates catered to different business scenarios. You can either generate your agent from one of our agent templates or create one from scratch:
|
||||
|
||||
1. Click **+ Create agent** to show the **agent template** page:
|
||||
|
||||
|
||||
|
||||
2. To create an agent from scratch, click **Create Agent**. Alternatively, to create an agent from one of our templates, click the desired card, such as **Deep Research**, name your agent in the pop-up dialogue, and click **OK** to confirm.
|
||||
|
||||
*You are now taken to the **no-code workflow editor** page.*
|
||||
|
||||
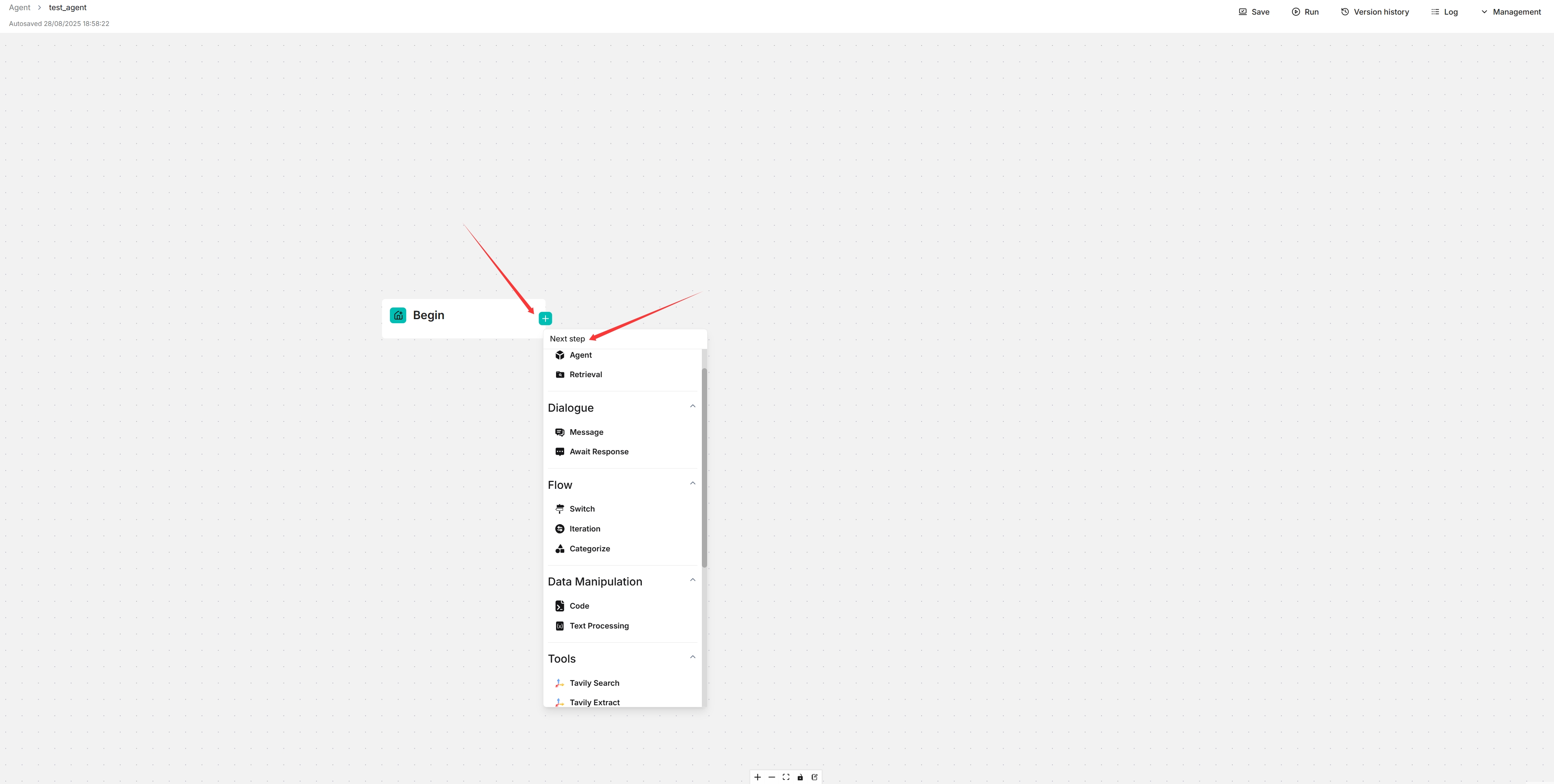
|
||||
|
||||
3. Click the **+** button on the **Begin** component to select the desired components in your workflow.
|
||||
4. Click **Save** to apply changes to your agent.
|
||||
8
docs/guides/agent/best_practices/_category_.json
Normal file
8
docs/guides/agent/best_practices/_category_.json
Normal file
@@ -0,0 +1,8 @@
|
||||
{
|
||||
"label": "Best practices",
|
||||
"position": 30,
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on Agent configuration."
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,58 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /accelerate_agent_question_answering
|
||||
---
|
||||
|
||||
# Accelerate answering
|
||||
|
||||
A checklist to speed up question answering.
|
||||
|
||||
---
|
||||
|
||||
Please note that some of your settings may consume a significant amount of time. If you often find that your question answering is time-consuming, here is a checklist to consider:
|
||||
|
||||
## Balance task complexity with an Agent’s performance and speed?
|
||||
|
||||
An Agent’s response time generally depends on many factors, e.g., the LLM’s capabilities and the prompt, the latter reflecting task complexity. When using an Agent, you should always balance task demands with the LLM’s ability.
|
||||
|
||||
- For simple tasks, such as retrieval, rewriting, formatting, or structured data extraction, use concise prompts, remove planning or reasoning instructions, enforce output length limits, and select smaller or Turbo-class models. This significantly reduces latency and cost with minimal impact on quality.
|
||||
|
||||
- For complex tasks, like multi-step reasoning, cross-document synthesis, or tool-based workflows, maintain or enhance prompts that include planning, reflection, and verification steps.
|
||||
|
||||
- In multi-Agent orchestration systems, delegate simple subtasks to sub-Agents using smaller, faster models, and reserve more powerful models for the lead Agent to handle complexity and uncertainty.
|
||||
|
||||
:::tip KEY INSIGHT
|
||||
Focus on minimizing output tokens — through summarization, bullet points, or explicit length limits — as this has far greater impact on reducing latency than optimizing input size.
|
||||
:::
|
||||
|
||||
## Disable Reasoning
|
||||
|
||||
Disabling the **Reasoning** toggle will reduce the LLM's thinking time. For a model like Qwen3, you also need to add `/no_think` to the system prompt to disable reasoning.
|
||||
|
||||
## Disable Rerank model
|
||||
|
||||
- Leaving the **Rerank model** field empty (in the corresponding **Retrieval** component) will significantly decrease retrieval time.
|
||||
- When using a rerank model, ensure you have a GPU for acceleration; otherwise, the reranking process will be *prohibitively* slow.
|
||||
|
||||
:::tip NOTE
|
||||
Please note that rerank models are essential in certain scenarios. There is always a trade-off between speed and performance; you must weigh the pros against cons for your specific case.
|
||||
:::
|
||||
|
||||
## Check the time taken for each task
|
||||
|
||||
Click the light bulb icon above the *current* dialogue and scroll down the popup window to view the time taken for each task:
|
||||
|
||||
|
||||
|
||||
| Item name | Description |
|
||||
| ----------------- | --------------------------------------------------------------------------------------------- |
|
||||
| Total | Total time spent on this conversation round, including chunk retrieval and answer generation. |
|
||||
| Check LLM | Time to validate the specified LLM. |
|
||||
| Create retriever | Time to create a chunk retriever. |
|
||||
| Bind embedding | Time to initialize an embedding model instance. |
|
||||
| Bind LLM | Time to initialize an LLM instance. |
|
||||
| Tune question | Time to optimize the user query using the context of the mult-turn conversation. |
|
||||
| Bind reranker | Time to initialize an reranker model instance for chunk retrieval. |
|
||||
| Generate keywords | Time to extract keywords from the user query. |
|
||||
| Retrieval | Time to retrieve the chunks. |
|
||||
| Generate answer | Time to generate the answer. |
|
||||
15
docs/guides/agent/embed_agent_into_webpage.md
Normal file
15
docs/guides/agent/embed_agent_into_webpage.md
Normal file
@@ -0,0 +1,15 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /embed_agent_into_webpage
|
||||
---
|
||||
|
||||
# Embed agent into webpage
|
||||
|
||||
You can use iframe to embed an agent into a third-party webpage.
|
||||
|
||||
1. Before proceeding, you must [acquire an API key](../models/llm_api_key_setup.md); otherwise, an error message would appear.
|
||||
2. On the **Agent** page, click an intended agent to access its editing page.
|
||||
3. Click **Management > Embed into webpage** on the top right corner of the canvas to show the **iframe** window:
|
||||
4. Copy the iframe and embed it into your webpage.
|
||||
|
||||
|
||||
116
docs/guides/agent/sandbox_quickstart.md
Normal file
116
docs/guides/agent/sandbox_quickstart.md
Normal file
@@ -0,0 +1,116 @@
|
||||
---
|
||||
sidebar_position: 20
|
||||
slug: /sandbox_quickstart
|
||||
---
|
||||
|
||||
# Sandbox quickstart
|
||||
|
||||
A secure, pluggable code execution backend designed for RAGFlow and other applications requiring isolated code execution environments.
|
||||
|
||||
## Features:
|
||||
|
||||
- Seamless RAGFlow Integration — Works out-of-the-box with the code component of RAGFlow.
|
||||
- High Security — Uses gVisor for syscall-level sandboxing to isolate execution.
|
||||
- Customisable Sandboxing — Modify seccomp profiles easily to tailor syscall restrictions.
|
||||
- Pluggable Runtime Support — Extendable to support any programming language runtime.
|
||||
- Developer Friendly — Quick setup with a convenient Makefile.
|
||||
|
||||
## Architecture
|
||||
|
||||
The architecture consists of isolated Docker base images for each supported language runtime, managed by the executor manager service. The executor manager orchestrates sandboxed code execution using gVisor for syscall interception and optional seccomp profiles for enhanced syscall filtering.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- Linux distribution compatible with gVisor.
|
||||
- gVisor installed and configured.
|
||||
- Docker version 24.0.0 or higher.
|
||||
- Docker Compose version 2.26.1 or higher (similar to RAGFlow requirements).
|
||||
- uv package and project manager installed.
|
||||
- (Optional) GNU Make for simplified command-line management.
|
||||
|
||||
## Build Docker base images
|
||||
|
||||
The sandbox uses isolated base images for secure containerised execution environments.
|
||||
|
||||
Build the base images manually:
|
||||
|
||||
```bash
|
||||
docker build -t sandbox-base-python:latest ./sandbox_base_image/python
|
||||
docker build -t sandbox-base-nodejs:latest ./sandbox_base_image/nodejs
|
||||
```
|
||||
|
||||
Alternatively, build all base images at once using the Makefile:
|
||||
|
||||
```bash
|
||||
make build
|
||||
```
|
||||
|
||||
Next, build the executor manager image:
|
||||
|
||||
```bash
|
||||
docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
```
|
||||
|
||||
## Running with RAGFlow
|
||||
|
||||
1. Verify that gVisor is properly installed and operational.
|
||||
|
||||
2. Configure the .env file located at docker/.env:
|
||||
|
||||
- Uncomment sandbox-related environment variables.
|
||||
- Enable the sandbox profile at the bottom of the file.
|
||||
|
||||
3. Add the following entry to your /etc/hosts file to resolve the executor manager service:
|
||||
|
||||
```bash
|
||||
127.0.0.1 es01 infinity mysql minio redis sandbox-executor-manager
|
||||
```
|
||||
|
||||
4. Start the RAGFlow service as usual.
|
||||
|
||||
## Running standalone
|
||||
|
||||
### Manual setup
|
||||
|
||||
1. Initialize the environment variables:
|
||||
|
||||
```bash
|
||||
cp .env.example .env
|
||||
```
|
||||
|
||||
2. Launch the sandbox services with Docker Compose:
|
||||
|
||||
```bash
|
||||
docker compose -f docker-compose.yml up
|
||||
```
|
||||
|
||||
3. Test the sandbox setup:
|
||||
|
||||
```bash
|
||||
source .venv/bin/activate
|
||||
export PYTHONPATH=$(pwd)
|
||||
uv pip install -r executor_manager/requirements.txt
|
||||
uv run tests/sandbox_security_tests_full.py
|
||||
```
|
||||
|
||||
### Using Makefile
|
||||
|
||||
Run all setup, build, launch, and tests with a single command:
|
||||
|
||||
```bash
|
||||
make
|
||||
```
|
||||
|
||||
### Monitoring
|
||||
|
||||
To follow logs of the executor manager container:
|
||||
|
||||
```bash
|
||||
docker logs -f sandbox-executor-manager
|
||||
```
|
||||
|
||||
Or use the Makefile shortcut:
|
||||
|
||||
```bash
|
||||
make logs
|
||||
```
|
||||
Reference in New Issue
Block a user